【图卷积网络】创始篇Semi-Supervised Classification with Graph Convolutional Networks
这个图神经网络,在对Graph的特征提取上,还是有很大作用!我们来看看吧
文章目录
摘要
我们提出了一种可扩展的半监督学习方法,用于处理图结构数据(graph-structured
)。
- 该方法基于一种高效图卷积神经网络变体,能够直接在**图(graphs)**上进行操作。
我们通过对谱图卷积spectral graph convolutions的局部一阶近似( localized first-order approximation)来论证所采用的卷积架构的合理性。我们的模型在图的边数上呈线性扩展,并能学习隐藏层表示,这些表示同时编码了局部图结构和节点的特征。
在引用网络和知识图谱数据集上的多项实验中,我们表明,与相关方法相比,我们的方法取得了显著的优势。
1. introduce
我们考虑 Graph(例如引用网络)中Node(例如文档)的分类问题,其中仅有一小部分节点具备标签。
这段文本主要阐述了基于图的本半监督学习(Graph-based Semi-supervised Learning, SSL)的核心数学框架,并指出了该框架中一个潜在的局限性。
1.1. 背景介绍:什么是半监督学习?
在开始之前,我们需要理解两个基本概念:
- 半监督学习 (Semi-supervised Learning, SSL):在机器学习中,通常我们面对两种情况:
- 监督学习:你有大量带标签的数据(例如:成千上万张标注了“猫”或“狗”的图片)。
- 无监督学习:你只有数据,没有标签(例如:只有图片,不知道每张图里是什么)。
- 半监督学习介于两者之间:你只有少量带标签的数据和大量无标签的数据。它的目标是利用大量无标签数据的结构信息来提高模型的预测性能。
- 图结构数据 (Graph Data):很多现实世界的数据不是独立的,而是相互关联的。比如社交网络中的人、引文网络中的论文、分子结构中的原子。我们可以将这些数据表示为“图”:节点(Nodes)代表实体,边(Edges)代表实体之间的关系。
文本的核心场景:作者正在讨论如何把“半监督学习”应用到“图结构数据”上。
1.2. 核心概念与假设
文本提出了一个关键假设,这是理解整个公式的基础:
平滑假设 (Smoothness Assumption)
“The formulation of Eq. 1 relies on the assumption that connected nodes in the graph are likely to share the same label.”
(公式1的构建依赖于这样一个假设:图中连接的节点很可能共享相同的标签。)
- 解释:如果两个人在社交网络上互为好友,他们很可能属于同一个群体(比如都喜欢同一种音乐)。在机器学习中,我们假设如果两个节点在图中相连,那么它们的输出预测值(标签概率)应该非常相似。
- 类比:就像地图上的颜色渲染。如果相邻的两个区域被涂成相似的颜色(平滑过渡),那么位于这两个区域中间的未知区域,颜色也应该是介于两者之间。
1.3. 数学公式深度拆解
文本给出了一个标准的图半监督学习损失函数:
L = L 0 + λ L r e g L = L_0 + \lambda L_{reg} L=L0+λLreg
L r e g = ∑ i , j A i j ∥ f ( X i ) − f ( X j ) ∥ 2 = f ( X ) T Δ f ( X ) L_{reg} = \sum_{i,j} A_{ij} \|f(X_i) - f(X_j)\|^2 = f(X)^T \Delta f(X) Lreg=i,j∑Aij∥f(Xi)−f(Xj)∥2=f(X)TΔf(X)
让我们逐项拆解:
A. L 0 L_0 L0:监督损失 (Supervised Loss)
- 含义:这是模型在已知标签的数据上犯错的程度。
- 作用:确保模型能准确预测那些已经知道答案的数据点。就像考试时,老师检查你是否做对了那几道有标准答案的例题。
B. λ \lambda λ:权衡因子 (Weighting Factor)
- 含义:这是一个超参数,用来平衡“准确性” ( L 0 L_0 L0) 和“结构一致性” ( L r e g L_{reg} Lreg) 的重要性。
- 作用:如果 λ \lambda λ 很大,模型会非常在意图的拓扑结构(邻居标签要一样);如果 λ \lambda λ 很小,模型更在意拟合已知标签,可能忽略图的结构信息。
C. L r e g L_{reg} Lreg:图拉普拉斯正则化项 (Graph Laplacian Regularization Term)
这是文本中最核心的部分,它强制模型输出在图上保持“平滑”。
-
A i j A_{ij} Aij (邻接矩阵):
- 如果节点 i i i 和节点 j j j 相连, A i j = 1 A_{ij}=1 Aij=1(或权重);如果不连, A i j = 0 A_{ij}=0 Aij=0。
- 它定义了谁和谁是邻居。
-
f ( X i ) f(X_i) f(Xi) 和 f ( X j ) f(X_j) f(Xj) (模型预测):
- f ( ⋅ ) f(\cdot) f(⋅) 通常是一个神经网络或可微函数,它接收节点特征 X X X,输出对该节点类别的预测值(比如概率)。
- ∥ f ( X i ) − f ( X j ) ∥ 2 \|f(X_i) - f(X_j)\|^2 ∥f(Xi)−f(Xj)∥2 计算的是两个相连节点的预测值之间的平方误差。
-
求和 ∑ i , j A i j ∥ . . . ∥ 2 \sum_{i,j} A_{ij} \|...\|^2 ∑i,jAij∥...∥2:
- 这个求和的意思是:把所有相连节点对的预测差异加起来。
- 目标:通过优化损失函数,我们要让这个总和变得越小越好。也就是说,我们要迫使相连节点的预测结果尽可能接近。这就是“平滑”的数学表达。
-
f ( X ) T Δ f ( X ) f(X)^T \Delta f(X) f(X)TΔf(X) (拉普拉斯算子形式):
- 这是一种更紧凑的矩阵写法,其中 Δ = D − A \Delta = D - A Δ=D−A 是未归一化的图拉普拉斯矩阵。
- D D D 是度矩阵(Degree Matrix),对角线上每个元素是该节点相连的边数(或权重和)。
- 在线性代数中,这种二次型 x T Δ x x^T \Delta x xTΔx 是衡量信号在图上变化剧烈程度的标准方法。变化越平缓,值越小。
1.4. 批判性分析:文本指出的局限性
文本的最后一段非常关键,它并没有一味吹捧这种方法,而是指出了其潜在缺陷:
“This assumption, however, might restrict modeling capacity, as graph edges need not necessarily encode node similarity, but could contain additional information.”
(然而,这种假设可能会限制模型的建模能力,因为图边不一定仅仅编码节点相似性,还可能包含其他信息。)
-
过度简化关系:
- 上述公式假设:连接 = 相似/同类。
- 现实情况:在复杂网络中,边的含义可能更多样。
- 互补关系:在电商购买图中,买牙膏的人往往也会买牙刷。他们标签不同(一个是牙膏买家,一个是牙刷买家?或者更复杂的属性),但他们有强连接。如果强制他们的预测值接近,模型反而会出错。
- 异配性 (Homophily vs. Heterophily):
- 同配网络(如Facebook好友):朋友通常相似。公式1有效。
- 异配网络(如竞争对手、买卖关系、某些生物相互作用网络):连接者往往不同。如果你强制他们相似,模型就会失效。
-
信息丢失:
- 如果图中的边不仅仅表示“相似性”,还包含方向、类型、强度等复杂信息,简单的 A i j A_{ij} Aij 加权平方差可能无法捕捉这些细微差别,从而导致“建模能力受限”(Restricted modeling capacity)。
1.5. 本文只用 L 0 L_0 L0 进行训练
在本研究中,我们使用神经网络模型 f ( X , A ) f(X, A) f(X,A) 直接对图结构进行编码,并在所有具有标签的节点上基于监督目标 L 0 L_0 L0 进行训练,从而避免在损失函数中引入显式的基于图的正则化项。将模型 f ( ⋅ ) f(\cdot) f(⋅) 以图的邻接矩阵作为条件输入,可使模型从监督损失 L 0 L_0 L0 中分布梯度信息,并使其能够同时学习有标签和无标签节点的代表性特征。
我们的贡献主要有两个方面。首先,我们提出了一种简单且性质良好的逐层传播规则,适用于直接在图结构上运行的神经网络模型,并展示了该规则如何从谱图卷积的一阶近似中推导而来(Hammond 等,2011)。其次,我们展示了基于图的神经网络模型可用于图中节点的快速且可扩展的半监督分类。在多个数据集上的实验表明,与当前最先进的半监督学习方法相比,我们的模型在分类精度和效率(以实际运行时间衡量)方面均表现出显著优势。
2. 核心公式、输入与输出
在本节中,我们为下文将使用的特定基于图结构的神经网络模型 f ( X , A ) f(\mathbf{X}, \mathbf{A}) f(X,A) 提供理论依据。我们考虑具有如下逐层传播规则的多层图卷积网络(GCN)。
GCN(图卷积网络)最核心、最常用的具体公式是其层间特征传播公式。对于第 l l l 层到第 l + 1 l+1 l+1 层,公式如下:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma\left( \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)} \right) H(l+1)=σ(D~−21A~D~−21H(l)W(l))
其中各符号的具体含义为:
- H ( l ) H^{(l)} H(l):第 l l l 层所有节点的特征矩阵(输入层 H ( 0 ) = X H^{(0)} = X H(0)=X,即初始节点特征矩阵)。
- A ~ \tilde{A} A~:添加了自环(Self-loop)的邻接矩阵,即 A ~ = A + I \tilde{A} = A + I A~=A+I( A A A 为原始邻接矩阵, I I I 为单位矩阵)。
- D ~ \tilde{D} D~: A ~ \tilde{A} A~ 对应的度矩阵(对角矩阵),其中对角线元素 D ~ i i = ∑ j A ~ i j \tilde{D}_{ii} = \sum_j \tilde{A}_{ij} D~ii=∑jA~ij。
- D ~ − 1 2 A ~ D ~ − 1 2 \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} D~−21A~D~−21:对称归一化后的邻接矩阵,用于归一化聚合的邻居特征,防止数值尺度不稳定。
- W ( l ) W^{(l)} W(l):第 l l l 层的可学习权重矩阵(网络参数)。
- σ ( ⋅ ) \sigma(\cdot) σ(⋅):非线性激活函数(如 ReLU)。
如果从**单个节点 i i i **的角度来看,其下一层特征 h i ( l + 1 ) h_i^{(l+1)} hi(l+1) 的更新公式可以展开写为:
h i ( l + 1 ) = σ ( ∑ j ∈ N ( i ) ∪ { i } 1 d ~ i d ~ j h j ( l ) W ( l ) ) h_i^{(l+1)} = \sigma\left( \sum_{j \in \mathcal{N}(i) \cup \{i\}} \frac{1}{\sqrt{\tilde{d}_i \tilde{d}_j}} h_j^{(l)} W^{(l)} \right) hi(l+1)=σ j∈N(i)∪{i}∑d~id~j1hj(l)W(l)
这里 N ( i ) \mathcal{N}(i) N(i) 是节点 i i i 的邻居集合, d ~ i \tilde{d}_i d~i 和 d ~ j \tilde{d}_j d~j 分别是节点 i i i 和 j j j 在添加自环后的度。
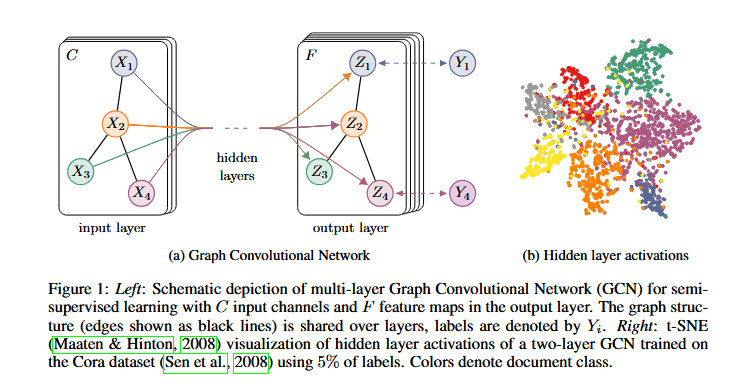
在 GCN(图卷积网络)的典型应用场景(尤其是那篇 ICLR 2017 的奠基性论文 Semi-Supervised Classification with Graph Convolutional Networks 所针对的节点分类任务)中,输入数据和真值的定义如下:
2.1. 输入数据 (Input Data)
GCN 的输入通常不是单一的向量或图像,而是整个图结构以及部分节点的特征,具体包含两个部分:
- 邻接矩阵 A A A (Adjacency Matrix):
- 描述了图中节点之间的连接关系(拓扑结构)。
- 尺寸为 N × N N \times N N×N( N N N 是节点总数)。如果节点 i i i 和节点 j j j 有边相连,则 A i j = 1 A_{ij}=1 Aij=1,否则为 0。
- 节点特征矩阵 X X X (Feature Matrix):
- 描述了每个节点自身的属性信息。
- 尺寸为 N × D N \times D N×D( D D D 是每个节点的特征维度)。每一行 X i X_i Xi 代表第 i i i 个节点的特征向量(例如引文网络中论文的词袋向量,或社交网络中用户的属性)。
注意:在半监督学习设置下,通常是所有节点都提供了特征矩阵 X X X 和邻接矩阵 A A A,但只有一部分节点(训练集)有标签。
2.2. 真值 / 标签 (Ground Truth / Labels)
- 定义:真值指的是我们希望模型预测的节点类别标签。
- 表示:通常是一个向量 Y Y Y,或者在半监督学习中是一个部分已知的标签集合 Y L Y_L YL(Labeled set)。
- 具体情况:
- 对于训练集节点(Labeled nodes):有具体的类别编号(例如:论文属于“物理”、“生物”或“计算机”类)。
- 对于测试集/验证集节点(Unlabeled nodes):真值是存在的(用于评估精度),但在训练时不提供给模型;模型需要通过图的结构和已知节点的标签来推断这些未知节点的标签。
总结
- 输入:图结构 ( A A A) + 所有节点的特征 ( X X X)。
- 输出:所有节点的预测类别(嵌入向量通过 Softmax 转为概率)。
- 真值:仅部分节点( Y L Y_L YL)的类别标签,损失函数(如交叉熵)仅在这些有标签的节点上计算。
2.3 Θ \Theta Θ(权重矩阵):是唯一需要更新的参数
1. 模型的内核
- Θ \Theta Θ(权重矩阵):是唯一需要更新的参数。
- 它相当于传统卷积神经网络(CNN)中的卷积核权重,或者全连接层中的 W W W。
- 在模型训练时,通过计算损失函数的梯度,利用梯度下降算法(如 Adam 优化器)不断对 Θ \Theta Θ 进行更新和迭代。
2. 数据的输入
- X X X(节点特征矩阵):是动态的输入量。
- 在网络的第一层, X X X 是图的初始节点特征(例如用户的属性、文本的 Embedding 等)。
- 随着网络层数的加深,后续层输入的是上一层计算出来的隐层特征(即 H ( l ) H^{(l)} H(l))。
- A A A(邻接矩阵 / 结构矩阵):是静态(或条件静态)的输入量。
- 它代表了图的拓扑结构(谁和谁相连)。
- 在传统的 GCN 中,图的结构在训练过程中是固定保持不变的。整个训练期间,常数矩阵 A ^ = D ~ − 1 / 2 A ~ D ~ − 1 / 2 \hat{A} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} A^=D~−1/2A~D~−1/2 只需要在最开始计算一次,之后作为常量直接参与矩阵乘法。
3. 引入切比雪夫多项式近似–>解决谱图计算的复杂
传统的基于谱图理论(Spectral Graph Theory)的方法计算成本极高,引入了切比雪夫多项式近似(Chebyshev Polynomial Approximation),从而使得在大规模图上应用卷积神经网络成为可能。
3.1. 核心概念解析:什么是“图上的谱卷积”?
为了理解这段话,我们需要先拆解其中的几个关键术语:
A. 图信号 (Graph Signal, x x x)
- 定义:在深度学习中,我们通常处理图像(像素矩阵)或序列数据。但在图中,每个节点都有一个特征向量。如果我们将所有节点的标量特征收集起来,就形成了一个长度为 N N N(节点总数)的向量 x x x。
- 类比:想象一个社交网络,每个用户(节点)有一个年龄(标量)。所有人的年龄组成一个列表,这就是信号 x x x。
B. 图拉普拉斯矩阵 (Graph Laplacian, L L L)
- 定义:文本中给出公式 L = I N − D − 1 / 2 A D − 1 / 2 L = I_N - D^{-1/2} A D^{-1/2} L=IN−D−1/2AD−1/2。这是图论中最重要的矩阵之一,它描述了图的结构(谁连接谁)。
- A A A 是邻接矩阵(记录连接关系)。
- D D D 是对角度矩阵(记录每个节点的连接数)。
- 作用:类似于图像中的二阶导算子,拉普拉斯矩阵捕捉了数据的平滑性或变化率。
C. 傅里叶变换与特征分解 (Fourier Transform & Eigendecomposition)
- 经典信号处理:在普通信号处理中,卷积定理告诉我们:时域中的卷积等于频域中的乘积。即 y ^ = g ^ ⋅ x ^ \hat{y} = \hat{g} \cdot \hat{x} y^=g^⋅x^。
- 图上的推广:在图上,我们使用拉普拉斯矩阵 L L L 的特征分解来定义“频域”。
- L = U Λ U T L = U \Lambda U^T L=UΛUT。
- U U U 是特征向量矩阵(相当于傅里叶基)。
- Λ \Lambda Λ 是对角矩阵,包含特征值(相当于频率)。
- 谱卷积公式 (Eq. 3):
g θ ∗ x = U g θ ( Λ ) U T x g_\theta * x = U g_\theta(\Lambda) U^T x gθ∗x=Ugθ(Λ)UTx
这里, U T x U^T x UTx 是将信号变换到频域(图傅里叶变换), g θ ( Λ ) g_\theta(\Lambda) gθ(Λ) 是在频域中应用滤波器(乘以参数),最后 U ( … ) U (\dots) U(…) 是变换回空域。
3.2. 核心痛点:为什么原始方法不可行?
文本明确指出直接计算公式 (3) 存在两个致命问题:
- 特征分解昂贵:计算拉普拉斯矩阵 L L L 的特征分解(Eigendecomposition)复杂度很高,对于大型图(数百万节点)来说,这在计算上是不可行的(Prohibitively expensive)。
- 矩阵乘法昂贵:即使有了 U U U,计算 U g θ U T x U g_\theta U^T x UgθUTx 需要矩阵与向量的乘法。由于 U U U 是 N × N N \times N N×N 的全连接矩阵,其复杂度为 O ( N 2 ) O(N^2) O(N2)。对于稀疏图(通常只有少量边),这种全连接运算完全浪费了图结构的稀疏性优势。
3.3. 解决方案:切比雪夫多项式近似
为了解决上述问题,作者引用了 Hammond et al. (2011) 的工作,提出用切比雪夫多项式来近似滤波器函数 g θ ( Λ ) g_\theta(\Lambda) gθ(Λ)。
A. 泰勒/多项式近似思想
既然滤波器是特征值 Λ \Lambda Λ 的函数,我们可以像用多项式近似任意光滑函数一样,用切比雪夫多项式 T k ( x ) T_k(x) Tk(x) 的线性组合来近似它。
B. 公式 (4) 和 (5) 的推导
- 近似公式:
g θ ′ ( Λ ) ≈ ∑ k = 0 K θ k ′ T k ( Λ ~ ) g_{\theta'}(\Lambda) \approx \sum_{k=0}^{K} \theta'_k T_k(\tilde{\Lambda}) gθ′(Λ)≈k=0∑Kθk′Tk(Λ~)
这里,滤波器不再是一个需要计算的矩阵函数,而变成了 K + 1 K+1 K+1 个系数 θ k ′ \theta'_k θk′ 的加权和。 - 代入卷积公式:
将近似式代入卷积公式,利用谱定理的性质 ( U Λ U T ) k = U Λ k U T (U \Lambda U^T)^k = U \Lambda^k U^T (UΛUT)k=UΛkUT,我们可以将频域运算转回空域操作:
g θ ′ ∗ x ≈ ∑ k = 0 K θ k ′ T k ( L ~ ) x g_{\theta'} * x \approx \sum_{k=0}^{K} \theta'_k T_k(\tilde{L}) x gθ′∗x≈k=0∑Kθk′Tk(L~)x
其中 L ~ = 2 λ m a x L − I N \tilde{L} = \frac{2}{\lambda_{max}} L - I_N L~=λmax2L−IN 是归一化后的拉普拉斯矩阵。
C. 关键优势 1:K-局部化 (K-localized)
这是这段话最核心的洞见之一。
- 含义: T k ( L ~ ) T_k(\tilde{L}) Tk(L~) 是拉普拉斯矩阵的 k k k 次多项式。在图结构中,矩阵的幂 L k L^k Lk 表示距离中心节点恰好 k k k 步的节点之间的连接关系。
- 直观理解:如果滤波器是拉普拉斯矩阵的 K K K 阶多项式,那么最终每个节点的新特征,只取决于它距离在 K K K 步以内的邻居节点的特征。
- 例子:如果 K = 1 K=1 K=1,这是直接邻居(一阶邻域);如果 K = 2 K=2 K=2,这是邻居的邻居(二阶邻域)。
- 意义:这解释了为什么 GCN 通常是“局部”的。它不需要看全图,只需要看局部感受野。
D. 关键优势 2:切比雪夫多项式三项递推公式–>计算复杂度降低
- 复杂度:由于 L L L 是稀疏矩阵(大多数元素为0),矩阵向量乘法 L x Lx Lx 的复杂度是 O ( ∣ E ∣ ) O(|E|) O(∣E∣),其中 ∣ E ∣ |E| ∣E∣ 是边的数量。
- 对比: O ( ∣ E ∣ ) O(|E|) O(∣E∣) 远小于 O ( N 2 ) O(N^2) O(N2)。对于大多数图数据, ∣ E ∣ |E| ∣E∣ 通常与 N N N 成线性或接近线性关系,而不是平方关系。
- 结果:这使得在大规模图上训练神经网络变得可行。
理解利用切比雪夫多项式三项递推公式进行高效计算,核心在于理解它如何将一个高复杂度的矩阵乘法问题,转化为低复杂度的矩阵与向量相乘问题。
以下从空间、时间以及具体计算流的角度进行深度拆解:
D.1. 核心数学转换
传统的矩阵级数计算中,如果要计算 K K K 次多项式:
f ( L ) x = ( θ 0 I + θ 1 L + θ 2 L 2 + ⋯ + θ K L K ) x f(L)x = (\theta_0 I + \theta_1 L + \theta_2 L^2 + \dots + \theta_K L^K)x f(L)x=(θ0I+θ1L+θ2L2+⋯+θKLK)x 直接计算需要先算出矩阵的幂(如 L 2 , L 3 , … , L K L^2, L^3, \dots, L^K L2,L3,…,LK)。矩阵与矩阵相乘的计算复杂度高达 O ( N 3 ) \mathcal{O}(N^3) O(N3),这在海量节点的图结构中是不可接受的。
切比雪夫递推法通过定义一个中间向量 x ˉ k = T k ( L ~ ) x \bar{x}_k = T_k(\tilde{L})x xˉk=Tk(L~)x,将公式改写为:
g θ ⋆ x ≈ ∑ k = 0 K θ k x ˉ k g_\theta \star x \approx \sum_{k=0}^{K} \theta_k \bar{x}_k gθ⋆x≈k=0∑Kθkxˉk
D.2. 局部向量递推(不需要算矩阵幂)
利用切比雪夫的递推性质,中间向量 x ˉ k \bar{x}_k xˉk 的求解变成了纯粹的向量迭代:
- 第 0 步: x ˉ 0 = T 0 ( L ~ ) x = x \bar{x}_0 = T_0(\tilde{L})x = x xˉ0=T0(L~)x=x
- 第 1 步: x ˉ 1 = T 1 ( L ~ ) x = L ~ x \bar{x}_1 = T_1(\tilde{L})x = \tilde{L}x xˉ1=T1(L~)x=L~x
- 第 k k k 步: x ˉ k = 2 L ~ x ˉ k − 1 − x ˉ k − 2 \bar{x}_k = 2\tilde{L}\bar{x}_{k-1} - \bar{x}_{k-2} xˉk=2L~xˉk−1−xˉk−2
在计算 x ˉ k \bar{x}_k xˉk 时,我们不需要计算矩阵乘矩阵 L ⋅ L L \cdot L L⋅L,而是计算矩阵乘向量 L ~ ⋅ x ˉ k − 1 \tilde{L} \cdot \bar{x}_{k-1} L~⋅xˉk−1。
D.3. 为什么说它“高效”?## 稀疏矩阵乘向量(SpMV)的超低复杂度
由于图的邻接矩阵 A A A 和拉普拉斯矩阵 L L L 通常是高度稀疏的(边数 ∣ E ∣ |\mathcal{E}| ∣E∣ 远小于 N 2 N^2 N2)。
- 矩阵与矩阵相乘( L ⋅ L L \cdot L L⋅L)的复杂度是 O ( N 3 ) \mathcal{O}(N^3) O(N3)。
- 稀疏矩阵与向量相乘( L ~ ⋅ x ˉ \tilde{L} \cdot \bar{x} L~⋅xˉ)的复杂度仅为 O ( ∣ E ∣ ) \mathcal{O}(|\mathcal{E}|) O(∣E∣)(即边的数量)。
- 计算到第 K K K 阶的总复杂度仅为 O ( K ∣ E ∣ ) \mathcal{O}(K|\mathcal{E}|) O(K∣E∣),呈线性增长。
D.4极低的空间占用
计算过程中,内存中永远只需要同时保留三个向量:当前步 x ˉ k \bar{x}_k xˉk、上一步 x ˉ k − 1 \bar{x}_{k-1} xˉk−1 和上上步 x ˉ k − 2 \bar{x}_{k-2} xˉk−2。一旦计算出 x ˉ k \bar{x}_k xˉk,前一步的累加结果就会被加到最终的目标特征中,旧向量即可被销毁或覆盖。
D.5. 形象的“消息传递”理解
在图神经网络(GNN)的语境下,这个递推过程是一步步向外扩展聚合的过程:
- x ˉ 0 \bar{x}_0 xˉ0 是节点自身的初始特征。
- x ˉ 1 = L ~ x \bar{x}_1 = \tilde{L}x xˉ1=L~x 是节点聚合了其 1 阶邻居(直接相连的邻居)的信息。
- x ˉ 2 = 2 L ~ x ˉ 1 − x ˉ 0 \bar{x}_2 = 2\tilde{L}\bar{x}_1 - \bar{x}_0 xˉ2=2L~xˉ1−xˉ0 是利用 1 阶邻居已经聚合好的信息,进一步推算出 2 阶邻居 的信息,同时减去自身特征( x ˉ 0 \bar{x}_0 xˉ0)以校正重叠。
每次迭代仅仅是邻居之间进行了一次局部消息传递,无需全局计算。
3.4. 在机器学习史上的地位
这是 GCN (Graph Convolutional Network) 的理论基石之一。
- 从谱方法到空间方法:早期的图神经网络(如 Bruna et al.)完全依赖谱方法,速度慢且难以并行。这段文字展示了如何通过多项式近似,将复杂的谱卷积转化为高效的邻域聚合操作。
- 后续发展:Defferrard et al. (2016) 确实利用这种 K K K-阶局部化定义了 CNN。而 Kipf & Welling 的原始 GCN 论文实际上是该方法的一个特例(取 K = 1 K=1 K=1,即只考虑直接邻居,并使用一阶近似)。
为什么 GCN 有效
- 为什么 GCN 有效? 因为它利用图的局部结构。通过限制多项式的阶数 K K K,模型强制只关注局部信息,这符合许多图数据(如社交网络、分子结构)中“近朱者赤”的假设。
- 超参数 K K K 的作用: K K K 决定了模型的感受野大小。 K = 1 K=1 K=1 计算最快但忽略高阶信息; K K K 越大,计算越慢,但能捕获更全局的结构信息,同时也容易面临过平滑(Over-smoothing)的问题(即深层网络中节点特征变得一模一样)。
3.5. 什么是切比雪夫多项式
Q1: 什么是切比雪夫多项式?为什么用它?
- A: 切比雪夫多项式是一组在区间 [ − 1 , 1 ] [-1, 1] [−1,1] 上振荡的正交多项式。它们在函数逼近理论中非常好用,因为它们的数值稳定性比标准幂级数(如 x k x^k xk)更好,收敛速度更快。简单来说,用很少的项就能很好地近似复杂的滤波器函数。
Q2: λ m a x \lambda_{max} λmax 是什么?为什么要重新缩放?
- A: λ m a x \lambda_{max} λmax 是拉普拉斯矩阵的最大特征值。切比雪夫多项式定义在区间 [ − 1 , 1 ] [-1, 1] [−1,1] 上。我们需要通过线性变换 L ~ = 2 λ m a x L − I N \tilde{L} = \frac{2}{\lambda_{max}} L - I_N L~=λmax2L−IN,将 L L L 的特征值映射到 [ − 1 , 1 ] [-1, 1] [−1,1] 区间内,这样才能合法地应用切比雪夫多项式。
Q3: 这种方法有缺点吗?
- A: 有。
- 基固定:这种方法依赖于固定的拉普拉斯矩阵特征基。如果图结构发生变化(动态图),每次都需要重新计算或近似,比较麻烦。
- 全局基依赖:虽然计算是局部的,但切比雪波基本身是全图的函数。相比之下,后来的 “Spatially Convolutional GCN”(如 ChebNet 之后的一些变体)试图完全摆脱全局谱基,直接在空间域定义卷积核。
3.6、如果上面没看懂,我一段话说清楚
图卷积计算用切比雪夫多后就不需要分解特征矩阵了!
完全不需要分解特征矩阵(拉普拉斯矩阵)了。这也是切比雪夫多项式引入图卷积(ChebNet)最核心的贡献。
可以从以下两个对立的视角来理解这个变革:
3.6.1. 传统的谱域图卷积(需要分解)
最早的谱域图卷积(如 Bruna 的初代模型)定义在傅里叶变换域中:
- 必须对拉普拉斯矩阵进行特征值分解: L = U Λ U T L = U \Lambda U^T L=UΛUT,得到特征向量矩阵 U U U。
- 卷积计算公式为: g θ ⋆ x = U g θ ( Λ ) U T x g_\theta \star x = U g_\theta(\Lambda) U^T x gθ⋆x=Ugθ(Λ)UTx。
- 致命缺陷:分解大矩阵的计算复杂度高达 O ( N 3 ) \mathcal{O}(N^3) O(N3)( N N N 为节点数)[3]。当图有几万个节点时,计算直接崩溃,无法实用。
3.6.2. 引入切比雪夫多项式后(无需分解)
通过切比雪夫近似,公式被重写为: g θ ⋆ x ≈ ∑ k = 0 K θ k T k ( L ~ ) x g_\theta \star x \approx \sum_{k=0}^{K} \theta_k T_k(\tilde{L}) x gθ⋆x≈∑k=0KθkTk(L~)x。
- 算子直接作用:切比雪夫多项式的自变量直接变成了矩阵 L ~ \tilde{L} L~ 本身,而不是它的特征值对角阵 Λ \Lambda Λ [3]。
- 巧妙避开 U U U:由于 T k ( L ~ ) T_k(\tilde{L}) Tk(L~) 直接对矩阵进行多项式运算,整个计算过程中完全不需要提取特征向量 U U U 和特征值 Λ \Lambda Λ。
- 复杂度暴跌:结合上一问提到的三项递推关系,计算完全转变为稀疏矩阵与向量的乘法,复杂度直接从 O ( N 3 ) \mathcal{O}(N^3) O(N3) 降到了 O ( K ∣ E ∣ ) \mathcal{O}(K|\mathcal{E}|) O(K∣E∣) [3]。
切比雪夫多项式成功做到了“在谱域(频域)定义卷积,但在空域(节点域)进行局部计算”。它在数学上保留了谱域严谨的滤波性质,在工程上彻底甩掉了矩阵特征分解的包袱。
4. LAYER-WISE 逐层线性模型
Kipf 和 Welling 在 2017 年的经典论文中,正是通过将 ChebNet 的切比雪夫多项式阶数限制为 (K=1)(一阶截断),并进行了一系列的数学简化,从而推导出了最广为人知的 GCN(图卷积网络) 公式。
假设我们将层间的卷积操作限制为 K = 1(参见公式 (5)),即一个关于拉普拉斯矩阵 L 呈线性、因而也是关于图拉普拉斯谱呈线性的函数。
整个推导过程非常漂亮,仅需以下 4 个核心步骤:
4.1. 限制 K = 1 K=1 K=1 并带入递推公式
ChebNet 的原始公式为: g θ ⋆ x ≈ ∑ k = 0 K θ k T k ( L ~ ) x g_\theta \star x \approx \sum_{k=0}^{K} \theta_k T_k(\tilde{L}) x gθ⋆x≈∑k=0KθkTk(L~)x。
当限定 K = 1 K=1 K=1 时(即只考虑中心节点和 1 阶邻居),公式展开为:
g θ ⋆ x ≈ θ 0 T 0 ( L ~ ) x + θ 1 T 1 ( L ~ ) x g_\theta \star x \approx \theta_0 T_0(\tilde{L})x + \theta_1 T_1(\tilde{L})x gθ⋆x≈θ0T0(L~)x+θ1T1(L~)x
根据切比雪夫递推定义 T 0 ( L ~ ) = I N T_0(\tilde{L})=I_N T0(L~)=IN 且 T 1 ( L ~ ) = L ~ T_1(\tilde{L})=\tilde{L} T1(L~)=L~,带入得:
g θ ⋆ x ≈ θ 0 x + θ 1 L ~ x g_\theta \star x \approx \theta_0 x + \theta_1 \tilde{L} x gθ⋆x≈θ0x+θ1L~x
4.2. 谱范围缩放简化
回想缩放拉普拉斯矩阵的公式: L ~ = 2 λ max L − I N \tilde{L} = \frac{2}{\lambda_{\max}} L - I_N L~=λmax2L−IN。
Kipf 假设图的最大特征值 λ max ≈ 2 \lambda_{\max} \approx 2 λmax≈2(在经验上,经过归一化的拉普拉斯矩阵其特征值范围通常在 [ 0 , 2 ] [0, 2] [0,2] 之间)。
带入 λ max = 2 \lambda_{\max} = 2 λmax=2,公式简化为:
L ~ ≈ L − I N \tilde{L} \approx L - I_N L~≈L−IN
再将 L = I N − D − 1 / 2 A D − 1 / 2 L = I_N - D^{-1/2} A D^{-1/2} L=IN−D−1/2AD−1/2 带入上式,常数项 I N I_N IN 刚好抵消:
L ~ ≈ − D − 1 / 2 A D − 1 / 2 \tilde{L} \approx - D^{-1/2} A D^{-1/2} L~≈−D−1/2AD−1/2
4.3. 合并参数以防止过拟合
将简化后的 L ~ \tilde{L} L~ 带回第 1 步的展开式中:
g θ ⋆ x ≈ θ 0 x − θ 1 ( D − 1 / 2 A D − 1 / 2 ) x g_\theta \star x \approx \theta_0 x - \theta_1 \left( D^{-1/2} A D^{-1/2} \right) x gθ⋆x≈θ0x−θ1(D−1/2AD−1/2)x 此时方程有两个独立的参数 θ 0 \theta_0 θ0 和 θ 1 \theta_1 θ1。为了防止多层网络堆叠时发生过拟合,并进一步约束参数空间,Kipf 提出了一个大胆的假设,令 θ = θ 0 = − θ 1 \theta = \theta_0 = -\theta_1 θ=θ0=−θ1。
公式随之简化为:
g θ ⋆ x ≈ θ ( I N + D − 1 / 2 A D − 1 / 2 ) x g_\theta \star x \approx \theta \left( I_N + D^{-1/2} A D^{-1/2} \right) x gθ⋆x≈θ(IN+D−1/2AD−1/2)x
4.4. 再归一化技巧 (Renormalization Trick)
注意到矩阵 I N + D − 1 / 2 A D − 1 / 2 I_N + D^{-1/2} A D^{-1/2} IN+D−1/2AD−1/2 的特征值范围现在变成了 [ 0 , 2 ] [0, 2] [0,2]。如果将这个算子多层堆叠(深层网络),其特征值在矩阵多遍相乘后会发生数值爆炸或梯度消失。
为了解决这个问题,Kipf 引入了“增加自连接”的再归一化技巧:
- 给原图的邻接矩阵加上单位阵,定义自连接邻接矩阵: A ~ = A + I N \tilde{A} = A + I_N A~=A+IN。
- 对应的自连接度矩阵为: D ~ i i = ∑ j A ~ i j \tilde{D}_{ii} = \sum_j \tilde{A}_{ij} D~ii=∑jA~ij。
- 用新的矩阵对整体进行对称归一化,即替换为: D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} D~−1/2A~D~−1/2。
4.5 输入X进行计算
这段文本出自图神经网络(Graph Neural Networks, GNN)领域的经典文献,极有可能是 Kipf 和 Welling 在 2016 年发表的论文《Semi-Supervised Classification with Graph Convolutional Networks》(GCN,图卷积网络)中的一部分。
以下是对这段文本的详细解读,包括背景、概念拆解、数学含义、复杂度分析以及直观类比。
4.5.1. 背景与核心概念
这段文字描述的是图卷积网络(GCN)中“层”(Layer)的核心计算公式。它展示了如何将一个输入信号(数据)通过一种特定的数学变换,转换成一个新的信号表示。
在传统的深度学习(如处理图像的 CNN)中,数据通常是网格状的(Grid),像素有固定的邻居。但在图(Graph)数据中,节点(Node)之间的连接是不规则的。GCN 的目标是让模型能够处理这种非欧几里得空间的数据。
关键术语解析:
-
X ∈ R N × C X \in \mathbb{R}^{N \times C} X∈RN×C (输入信号):
- N N N: 图中节点的数量。
- C C C: 每个节点的特征维度(Channel)。例如,如果你有一个社交网络, X X X 可以表示每个用户的年龄、性别、职业等特征组成的向量。
- 意义: 这是原始数据,形状为 N N N 行(每个节点一行)和 C C C 列(每个特征一列)。
-
Z ∈ R N × F Z \in \mathbb{R}^{N \times F} Z∈RN×F (卷积后的信号/输出):
- F F F: 滤波器的数量,也就是输出特征图的维度。
- 意义: 这是经过卷积操作后提取出的新特征。模型通过这 F F F 个滤波器学习到了节点的新表示。
-
A ~ \tilde{A} A~ (归一化的邻接矩阵):
- 虽然文中没直接定义 A ~ \tilde{A} A~,但在 GCN 上下文中, A ~ = A + I \tilde{A} = A + I A~=A+I,其中 A A A 是原始邻接矩阵(表示谁连接谁), I I I 是单位矩阵(表示节点自己也连接自己,即“自环”)。
- 意义: 它定义了图的拓扑结构(谁和谁有关系)。
-
D ~ \tilde{D} D~ (度矩阵的对角矩阵):
- D ~ \tilde{D} D~ 是一个对角矩阵,其对角线上的元素 D ~ i i \tilde{D}_{ii} D~ii 等于第 i i i 个节点的度数(即该节点连接的边数,包括自环)。
- 意义: 用于对邻接矩阵进行归一化,防止某些连接很多节点的数值过大,影响训练稳定性。
-
D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} D~−1/2A~D~−1/2 (归一化拉普拉斯相关项):
- 这是 GCN 的核心 trick。它类似于信号处理中的低通滤波器,允许低频信号(即邻居节点之间相似的特征)通过,从而聚合邻居的信息。
- 直观理解: 如果一个节点和它的邻居有很多连接,这个结构会确保聚合时不会偏向度数高的节点。
-
Θ ∈ R C × F \Theta \in \mathbb{R}^{C \times F} Θ∈RC×F (滤波器参数/权重矩阵):
- 这是模型需要学习的可训练参数。
- 意义: 它决定了如何将输入的 C C C 维特征线性组合成 F F F 维的新特征。这就好比卷积核(Kernel)在全连接网络中的角色。
4.5.2. 公式逐层拆解
公式 (8) 为:
Z = D ~ − 1 / 2 A ~ D ~ − 1 / 2 X Θ Z = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} X \Theta Z=D~−1/2A~D~−1/2XΘ
我们可以从左到右,或者从右到左来理解这个计算过程。通常理解方式是从内向外:
-
第一步:线性变换 ( X Θ X \Theta XΘ)
- 首先,我们对每个节点的特征进行线性变换。
- X X X 是 ( N × C ) (N \times C) (N×C), Θ \Theta Θ 是 ( C × F ) (C \times F) (C×F)。
- 结果是一个中间矩阵 ( N × F ) (N \times F) (N×F)。这一步就像是 CNN 中的“卷积核”在滑动窗口内做的点积操作,但这里是对所有节点同时做的全局线性投影。
-
第二步:消息聚合与归一化 ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 … \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} \dots D~−1/2A~D~−1/2…)
- 接下来,矩阵 D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} D~−1/2A~D~−1/2 作用在上一步的结果上。
- A ~ \tilde{A} A~ 的作用是将邻居的信息聚合到当前节点上(如果 i i i 和 j j j 相连, A i j A_{ij} Aij 非零,信息就会流动)。
- D ~ − 1 / 2 \tilde{D}^{-1/2} D~−1/2 的作用是归一化。它确保聚合是平均的或加权平均的,而不是简单的求和,从而避免度数高的节点主导梯度更新。
-
最终结果 Z Z Z:
- 得到的 Z Z Z 就是新的节点嵌入(Node Embedding)。现在每个节点不仅拥有自己的原始特征,还融合了其邻居的信息,并且特征维度从 C C C 变成了 F F F。
4.5.3. 复杂度分析:为什么高效?
文中提到:
“This filtering operation has complexity O ( ∣ E ∣ F C ) O(|E|FC) O(∣E∣FC), as A ~ X \tilde{A}X A~X can be efficiently implemented as a product of a sparse matrix with a dense matrix.”
- ∣ E ∣ |E| ∣E∣: 图中边的数量。
- 复杂度 O ( ∣ E ∣ F C ) O(|E|FC) O(∣E∣FC):
- 如果我们要做完整的矩阵乘法, A ~ \tilde{A} A~ 是 N × N N \times N N×N 的稠密矩阵,那么复杂度将是 O ( N 2 ⋅ something ) O(N^2 \cdot \text{something}) O(N2⋅something),这对于大规模图来说太慢了。
- 但是,图通常是稀疏的(Sparse)。大多数节点之间没有连接。因此, A ~ \tilde{A} A~ 是一个稀疏矩阵。
- 在计算 A ~ X \tilde{A}X A~X 时,我们只需要遍历存在的边。对于每条边,我们进行少量的向量运算。
- 具体来说,每个边涉及 F × C F \times C F×C 的运算量(或者是 F × 1 F \times 1 F×1 如果优化得当,但文中强调了 C C C 和 F F F 的交互)。总体复杂度与边数 ∣ E ∣ |E| ∣E∣ 成正比,而不是节点数 N N N 的平方。这使得 GCN 可以扩展到数百万个节点的大图上。
4.5.4. 直观类比:社交网络中的“意见领袖”效应
为了帮助理解,我们可以用一个社交网络的例子:
- 场景: 假设 X X X 是每个用户喜欢的音乐类型(比如向量 [摇滚, 爵士, 流行] 的评分)。
- Θ \Theta Θ (滤波器): 这是一个转换器,比如它专门学习“寻找那些喜欢摇滚的人”。
- A ~ \tilde{A} A~ (连接关系): 谁是谁的朋友。
- D ~ − 1 / 2 … \tilde{D}^{-1/2} \dots D~−1/2… (归一化): 平均邻居的观点。
过程:
- 线性变换: 首先,我们看每个用户本身,提取出他们偏好的“摇滚特征”。
- 图卷积: 然后,我们查看这个用户的每个朋友。我们收集朋友们的“摇滚特征”。
- 归一化: 如果某个用户有 1000 个朋友,我们不会把这 1000 个朋友的偏好直接相加(那样数值会爆炸),而是计算平均值。
- 输出 Z Z Z: 最终,这个用户的新特征 Z Z Z 不仅包含他原本的喜好,还包含了“他朋友们的喜好平均值”。这意味着,即使他自己没听摇滚,如果他朋友都爱听摇滚,系统也会认为他可能喜欢摇滚。
这就是**“同质性假设”(Homophily Assumption)**:与你相连的人,往往和你相似。GCN 通过这种机制,把局部结构信息编码进了节点的特征中。
4.5.5. 潜在问题与读者疑问解答
Q1: 为什么公式里要有 D ~ − 1 / 2 \tilde{D}^{-1/2} D~−1/2 而不是 D ~ − 1 \tilde{D}^{-1} D~−1?
- A: 在原始的谱图卷积理论中,为了保持对称性和数值稳定性,使用对称归一化 D ~ − 1 / 2 A ~ D ~ − 1 / 2 \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} D~−1/2A~D~−1/2 更为常见。这保证了变换矩阵的特征值范围可控,有助于神经网络的收敛。虽然 D ~ − 1 A ~ \tilde{D}^{-1} \tilde{A} D~−1A~(随机游走归一化)也可以使用,但对称归一化在 GCN 中表现更好。
Q2: F F F 和 C C C 有什么关系?
- A: C C C 是输入特征维度, F F F 是输出特征维度。通常 F F F 会大于 C C C(升维以提取更多特征)或者小于 C C C(降维以压缩信息)。如果 F = 1 F=1 F=1,则变成标量输出。
Q3: 这个公式包含激活函数吗?
- A: 不包含。这个公式 (8) 仅仅描述了线性变换和聚合部分。在实际的 GCN 层中,通常会在后面加一个非线性激活函数(如 ReLU):
Z = σ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 X Θ ) Z = \sigma(\tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} X \Theta) Z=σ(D~−1/2A~D~−1/2XΘ)
文本仅展示了线性部分,可能是为了强调滤波操作的复杂性或作为后续方程的铺垫。
4.6 总结最终的 GCN 算子
将其扩展到多通道特征 X X X(矩阵)和多卷积核权重 W W W(替代标量 θ \theta θ),就得到了教科书级别的 GCN 单层前向传播公式:
H ( l + 1 ) = σ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ( l ) W ( l ) ) H^{(l+1)} = \sigma \left( \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} H^{(l)} W^{(l)} \right) H(l+1)=σ(D~−1/2A~D~−1/2H(l)W(l))
核心总结: Kipf 通过将 ChebNet 截断到 K = 1 K=1 K=1,成功把复杂的切比雪夫级数运算变成了一次对“包含自身在内的邻居”的加权求和。这使得图卷积从繁重的数学逼近彻底演化成了直观、高效的消息传递(Message Passing)机制。
5 半监督的节点分类
在提出了一种简洁而灵活的模型 $ f(X, A) $,以实现在图上的高效信息传播之后,我们可以回到半监督节点分类的问题。
底层图结构的数据 X X X 、邻接矩阵 A A A、模型 f ( X , A ) f(X, A) f(X,A)
在下文中,我们考虑使用两层图卷积网络(GCN)对具有对称邻接矩阵 A(二进制或加权)的图进行半监督节点分类。我们首先在预处理阶段计算 A ^ = D ~ − 1 / 2 A ~ D ~ − 1 / 2 \hat{A} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} A^=D~−1/2A~D~−1/2。随后,前向模型的形式如下: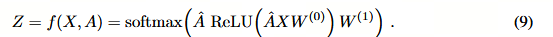
A. 权重矩阵与网络结构
文本中提到了两个权重矩阵:
- W ( 0 ) ∈ R C × H W^{(0)} \in \mathbb{R}^{C \times H} W(0)∈RC×H:这是输入层到隐藏层的权重矩阵。
- C C C 通常代表输入特征的维度(例如,节点的特征数)。
- H H H 代表隐藏层中的特征映射(feature maps)数量,也就是隐藏层的神经元数量。
- 含义:这个矩阵负责将原始输入数据转换为隐藏层能够处理的高阶特征。
- W ( 1 ) ∈ R H × F W^{(1)} \in \mathbb{R}^{H \times F} W(1)∈RH×F:这是隐藏层到输出层的权重矩阵。
- F F F 代表输出类别的数量(例如,如果是分类猫、狗、鸟,则 F = 3 F=3 F=3)。
- 含义这个矩阵负责将隐藏层学到的特征映射到最终的预测结果上。
B. Softmax 激活函数
文本定义了 Softmax函数:
softmax ( x i ) = exp ( x i ) Z , Z = ∑ i exp ( x i ) \text{softmax}(x_i) = \frac{\exp(x_i)}{Z}, \quad Z = \sum_i \exp(x_i) softmax(xi)=Zexp(xi),Z=i∑exp(xi)
- 作用:它将神经网络输出的任意实数转换成了概率分布。
- “按行应用”(row-wise):在矩阵运算中,这意味着对于每一个数据样本(每一行),Softmax 都会确保该样本属于各个类别的概率之和为 1。
- 为什么需要它? 在多分类问题中,我们需要知道样本属于类别 1 的概率是多少,属于类别 2 的概率是多少,且所有概率加起来必须等于 1。Softmax 完美实现了这一点。
C. 交叉熵损失函数 (Cross-Entropy Loss)
文本给出了损失函数公式 (10):
L = − ∑ l ∈ Y L ∑ f = 1 F Y l f ln Z l f L = - \sum_{l \in Y_L} \sum_{f=1}^{F} Y_{lf} \ln Z_{lf} L=−l∈YL∑f=1∑FYlflnZlf
- Y L Y_L YL:标记为“已标注节点索引”的集合。这意味着我们只利用那些有标签的数据来计算错误率(这是半监督学习的关键,见下文)。
- Y l f Y_{lf} Ylf:这是“真实标签”。如果节点 l l l 真正属于类别 f f f,则 Y l f = 1 Y_{lf}=1 Ylf=1,否则为 0(One-hot 编码)。
- Z l f Z_{lf} Zlf:这是模型预测节点 l l l 属于类别 f f f 的概率(经过 Softmax 处理后)。
- ln \ln ln:自然对数。
- 含义:交叉熵衡量的是“模型预测的概率分布”与“真实标签分布”之间的距离。
- 如果模型预测某类概率很高( Z l f Z_{lf} Zlf 接近 1),而真实标签也是该类( Y l f = 1 Y_{lf}=1 Ylf=1),则 − ln ( 1 ) = 0 - \ln(1) = 0 −ln(1)=0,损失很小。
- 如果模型预测某类概率很低,但真实标签确实是该类,则 ln ( 小数字 ) \ln(\text{小数字}) ln(小数字) 是一个很大的负数,取负号后损失 L L L 变得很大。
- 目标:训练模型让损失 L L L 最小化,即让预测概率无限接近真实标签。
5.2. 训练方法与背景
A. 半监督多类分类 (Semi-supervised Multi-class Classification)
- 背景:在图学习或数据集中,往往只有少数节点有标签(例如,知道某些人的职业),而大多数节点没有标签。
- 策略:损失函数 L L L 只对集合 Y L Y_L YL(有标签的节点)求和。未标注的节点不参与损失计算,但它们的特征可以通过网络的权重更新间接影响模型(通常通过传播机制,虽然这段文本主要讲前向传播和损失计算)。
B. 批梯度下降 (Batch Gradient Descent)
- 定义:每次更新权重时,使用整个数据集中所有标注样本的梯度来计算平均值。
- 优点:梯度方向稳定,收敛路径平滑,能确保找到全局最优解(对于凸优化问题)或更稳定的局部最优解。
- 缺点/限制:计算量大,内存占用高。
- 适用条件:文本指出,“只要数据集能装进内存(fit in memory),这是一种可行的选择”。
C. 内存效率与稀疏表示
- 稀疏矩阵 A A A:这里提到的 A A A 通常指图的邻接矩阵(Adjacency Matrix)。在大型图中,绝大多数节点之间没有连接,因此矩阵大部分是 0。
- 内存复杂度 O ( ∣ E ∣ ) O(|E|) O(∣E∣): ∣ E ∣ |E| ∣E∣ 是边的数量。使用稀疏存储格式(如 CSR 或 CSC)时,我们只存储非零元素(即存在的连接),因此内存消耗与边数成正比,而不是节点数的平方( N 2 N^2 N2)。这使得处理大规模图成为可能。
D. Dropout 正则化
- 目的:防止过拟合(Overfitting)。
- 机制:在训练过程中,随机“丢弃”(设为零)一部分神经元。这迫使网络不依赖于特定的神经元组合,从而学习到更鲁棒的特征。
- 引用:Srivastava et al., 2014 是提出 Dropout 技术的经典论文。
6、图卷积(Graph Convolution)与传统计算机视觉中的图像卷积(Image Convolution)最核心的区别
在传统 CV(如 CNN)中,卷积核(相当于 A A A)才是需要学习的参数;但在图卷积(GCN)中,结构矩阵 A A A 却是固定的输入。
造成这种反直觉现象的原因,是因为图像(Image)和图(Graph)的空间几何结构不同。我们可以从以下三个维度来彻底理清两者的本质区别:
6.1. 卷积核参数的“寄生”对象不同
- 图像卷积 (CNN):图像具有网格规则性(Grid Structure)。每个像素周围的邻居结构永远是一样的(如 3 × 3 3 \times 3 3×3 的九宫格)。
- 因为结构是固定的、平凡的,我们不需要把“结构”当成输入。
- 我们学习的是九宫格里每个相对位置的权重(上、下、左、右的权重)。这 9 个数字就是可学习的参数。
- 图卷积 (GCN):图具有非欧几里得不规则性(Non-Euclidean Structure)。每个节点的邻居数量、连接方式都是千差万别的(节点 A 有 2 个邻居,节点 B 有 1000 个邻居)。
- 因为拓扑结构太复杂,我们必须把“谁和谁连、怎么连”作为输入数据(即 A A A)显式地喂给模型。
- 既然 A A A 已经决定了信息的流动通道,那我们学习的 Θ \Theta Θ,则是针对特征通道(Channel)的变换矩阵。
6.2. 两种卷积的等价对应关系
为了让你更直观地理解,我们可以把图像卷积写成矩阵形式。实际上,图像卷积可以看作是图卷积的一种特例:
| 概念 | 传统图像卷积 (CNN) | 图卷积 (GCN) |
|---|---|---|
| 空间拓扑 | 隐含在像素网格中(规则九宫格) | 显式写在邻接矩阵 A A A 中(不规则网络) |
| 参数角色 | 卷积核 W W W 是参数(决定空间哪个位置更重要) | 映射矩阵 Θ \Theta Θ 是参数(决定特征哪个通道更重要) |
| 参数更新 | 更新卷积核,使其学会识别特定空间模式(如边缘、纹理) | 更新特征权重,使其学会如何将邻居聚合过来的信息转化为有用的高阶特征 |
6.3. GCN 为什么要这样设计?(参数共享的无奈)
如果像你所想,把图的邻接矩阵 A A A 里面的每个元素都变成可学习的参数,会发生什么?
- 如果图有 N N N 个节点, A A A 的大小就是 N × N N \times N N×N。
- 这意味着参数量将高达 O ( N 2 ) \mathcal{O}(N^2) O(N2)。当图有 100 万个节点时,参数量多到根本无法训练。
- 更致命的是,这样的参数无法泛化。如果你训练好了一个模型,突然加入了一个新节点,或者要把模型用到另一个全新的图上,由于 A A A 的尺寸变了,原本学到的参数直接报废。
而通过将参数放在 Θ \Theta Θ(大小为 [ C , F ] [C, F] [C,F],仅与输入/输出特征维度有关,与节点数 N N N 无关)中,GCN 完美实现了参数共享:无论图有多大、节点怎么增加,所有节点和边在聚合信息时,使用的都是同一套 Θ \Theta Θ。
GCN 学习特征通道的变换规律
- CNN 的卷积:在固定的空间网格上,学习空间的加权模式。
- GCN 的图卷积:在输入的复杂拓扑结构( A A A)上,学习特征通道的变换规律( Θ \Theta Θ)。
6.4 CV卷积是 输出 = A X + b \text{输出} =AX+b 输出=AX+b,GCN是 输出 = A ^ X Θ \text{输出} = \hat{A} X \Theta 输出=A^XΘ
A X + b AX+b AX+b 与 X Θ X\Theta XΘ 并不冲突,它们是正交的
A X + b AX+b AX+b 属于空间聚合(Aggregation),而 X Θ X\Theta XΘ 属于特征变换(Transformation)。
在完整的 GCN 公式中,这两者是同时存在的:
输出 = A ^ X Θ \text{输出} = \hat{A} X \Theta 输出=A^XΘ
- 其中 A ^ = D ~ − 1 / 2 A ~ D ~ − 1 / 2 \hat{A} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} A^=D~−1/2A~D~−1/2,维度是 [ N , N ] [N, N] [N,N](表示节点间的邻接关系)。
- 计算顺序(结合律): A ^ X Θ = ( A ^ X ) Θ = A ^ ( X Θ ) \hat{A} X \Theta = (\hat{A} X) \Theta = \hat{A} (X \Theta) A^XΘ=(A^X)Θ=A^(XΘ)。
无论是先做空间聚合再做特征变换,还是先做特征变换再做空间聚合,数学结果完全一致:
- A ^ ( X Θ ) \hat{A} (X \Theta) A^(XΘ):先把每个节点的 C C C 维特征通过 Θ \Theta Θ 映射到 F F F 维,再让邻居节点之间进行加权求和( A A A 的作用)。
- ( A ^ X ) Θ (\hat{A} X) \Theta (A^X)Θ:先让邻居节点之间对 C C C 维特征进行加权求和,再将聚合后的结果通过 Θ \Theta Θ 映射到 F F F 维。
A X AX AX 负责处理节点与节点之间的信息流动(横向聚合),而 X Θ X\Theta XΘ 负责处理通道与通道之间的特征变换(纵向投影)。它们分工明确,互不干扰。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)