Java 集合进阶:ConcurrentHashMap、HashSet、LinkedHashMap、TreeMap 和 fail-fast 一篇讲清
上一篇我们梳理了 Java 集合框架的基础,包括 ArrayList、LinkedList、HashMap 的底层结构和扩容机制。
这一篇继续往下看更高频的内容:
- 为什么 HashMap 线程不安全?
- 多线程下为什么推荐 ConcurrentHashMap?
- JDK 7 和 JDK 8 的 ConcurrentHashMap 有什么区别?
- HashSet 底层是什么?
- 为什么重写 equals 必须重写 hashCode?
- LinkedHashMap 和 TreeMap 适合什么场景?
- 什么是 fail-fast?
- 遍历集合时怎么安全删除元素?
这些问题在 Java 后端面试里非常常见,尤其是 ConcurrentHashMap,基本属于集合并发部分的核心。
一、为什么 HashMap 线程不安全?
HashMap 没有同步控制。
多线程同时操作 HashMap 时,可能出现:
数据覆盖 size 统计不准 扩容时数据异常 读取到不一致数据
比如两个线程同时往同一个桶里 put 数据,可能一个线程的结果覆盖另一个线程。
所以多线程共享 Map 时,不应该直接使用 HashMap。
单线程普通 key-value 场景用 HashMap 没问题;多线程并发读写时,就要换成线程安全的实现。
二、多线程下应该用什么 Map?
常用:
ConcurrentHashMap
它是线程安全的,并且并发性能比 Hashtable 和 Collections.synchronizedMap() 更好。
原因是它不是简单地给整个 Map 加一把大锁,而是尽量减小锁粒度。
可以这样记:
HashMap:单线程普通场景 ConcurrentHashMap:多线程并发场景
三、ConcurrentHashMap 和 Hashtable 有什么区别?
| 对比 | ConcurrentHashMap | Hashtable |
|---|---|---|
| 线程安全 | 是 | 是 |
| 锁粒度 | 较细 | 整个方法加锁 |
| 性能 | 更好 | 较差 |
| null key/value | 不允许 | 不允许 |
| 是否推荐 | 推荐 | 基本不推荐 |
Hashtable 很老,很多方法直接加了 synchronized,锁粒度粗,并发性能差。
现在多线程 Map 基本优先考虑 ConcurrentHashMap。
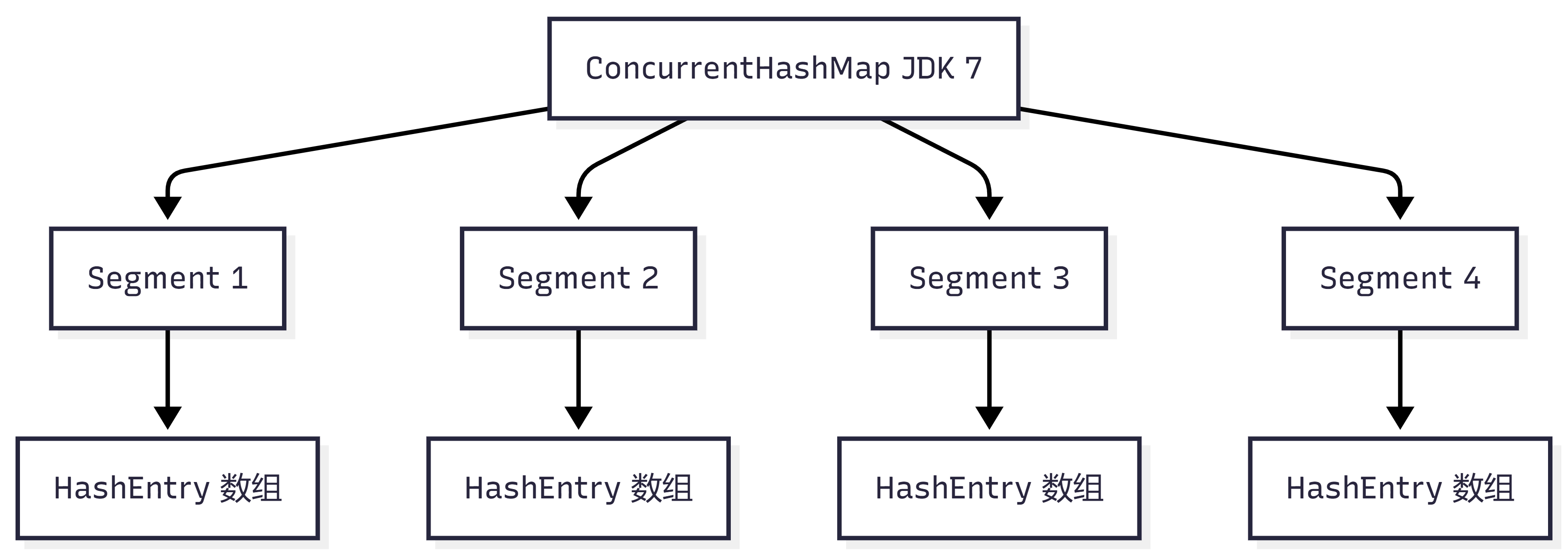
四、JDK 7 的 ConcurrentHashMap 怎么实现?
JDK 7 使用的是:
Segment 分段锁
结构大致是:
ConcurrentHashMap
├── Segment 1
├── Segment 2
├── Segment 3
└── Segment 4
每个 Segment 类似一个小的 HashMap。
不同线程操作不同 Segment 时,可以并发执行。
也就是说,JDK 7 的核心是:
分段锁,降低锁冲突
图示如下:
五、JDK 8 的 ConcurrentHashMap 怎么实现?
JDK 8 放弃了 Segment 分段锁,改为:
数组 + 链表 + 红黑树 CAS + synchronized
它的结构和 JDK 8 的 HashMap 类似,但在并发控制上做了处理。
put 时大致逻辑:
桶为空:CAS 插入 桶不为空:锁住桶头节点 synchronized
也就是说,它只锁当前桶,不锁整个 Map。
流程图:
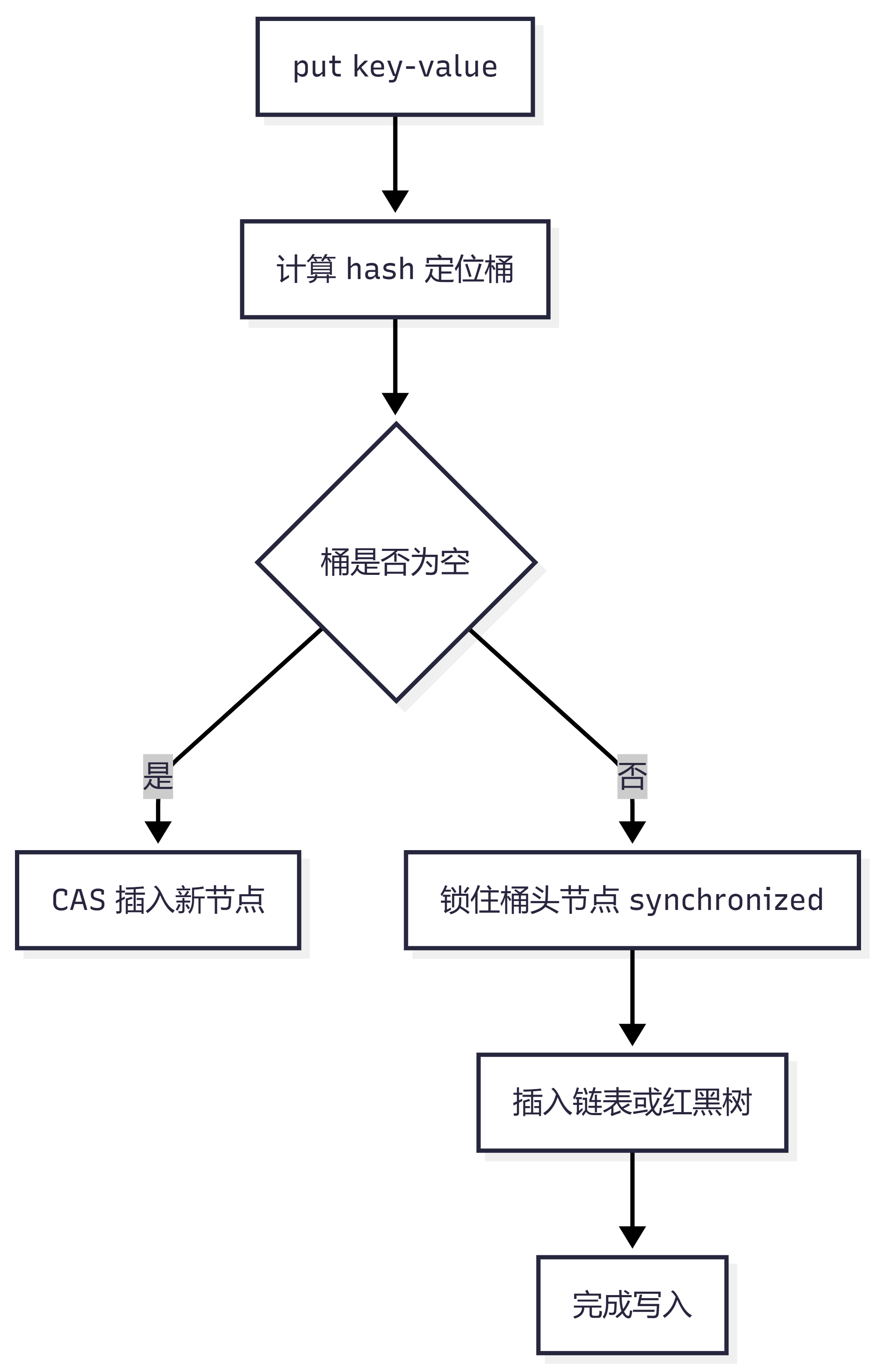
这就是 JDK 8 ConcurrentHashMap 并发性能好的关键:
读操作基本无锁 写操作只锁局部桶
六、ConcurrentHashMap 为什么用 synchronized,不用 ReentrantLock?
JDK 8 中,synchronized 已经做了很多优化,比如:
偏向锁 轻量级锁 锁膨胀
虽然后续 JDK 对锁实现又有调整,但总体来说,synchronized 已经不是早期那种“很慢”的印象了。
另外,使用 synchronized 锁住桶头节点有几个好处:
代码更简单 内存开销更低 JVM 可以持续优化
所以 JDK 8 的 ConcurrentHashMap 选择了 CAS + synchronized 的方式。
七、ConcurrentHashMap 的 get 需要加锁吗?
通常不需要。
get 主要依赖:
volatile
CAS
内存可见性设计
它可以在不加锁的情况下读取数据。
这也是 ConcurrentHashMap 并发性能好的原因之一:
读操作基本无锁 写操作只锁局部桶
如果读多写少,ConcurrentHashMap 的优势会更加明显。
八、ConcurrentHashMap 为什么不允许 null key 和 null value?
因为多线程环境下,null 会带来歧义。
比如:
map.get("name") == null
这可能表示两种情况:
1. key 不存在 2. key 存在,但 value 就是 null
在并发环境下,这种判断会很混乱。
所以 ConcurrentHashMap 直接禁止 null key 和 null value。
这样当 get 返回 null 时,就可以明确表示:
这个 key 不存在
九、HashMap 为什么允许 null?
HashMap 是普通的非线程安全 Map,主要用于单线程场景。
它允许:
一个 null key 多个 null value
null key 会放在某个固定位置,通常可以理解为数组下标 0 的桶里。
但多线程的 ConcurrentHashMap 为了避免并发歧义,不允许 null。
十、HashSet 底层是什么?
HashSet 底层其实是 HashMap。
你添加元素:
set.add("A");
底层类似:
map.put("A", PRESENT);
其中 "A" 是 key,PRESENT 是一个固定的 Object 对象。
所以 HashSet 去重,本质上依赖的是:
HashMap 的 key 不重复
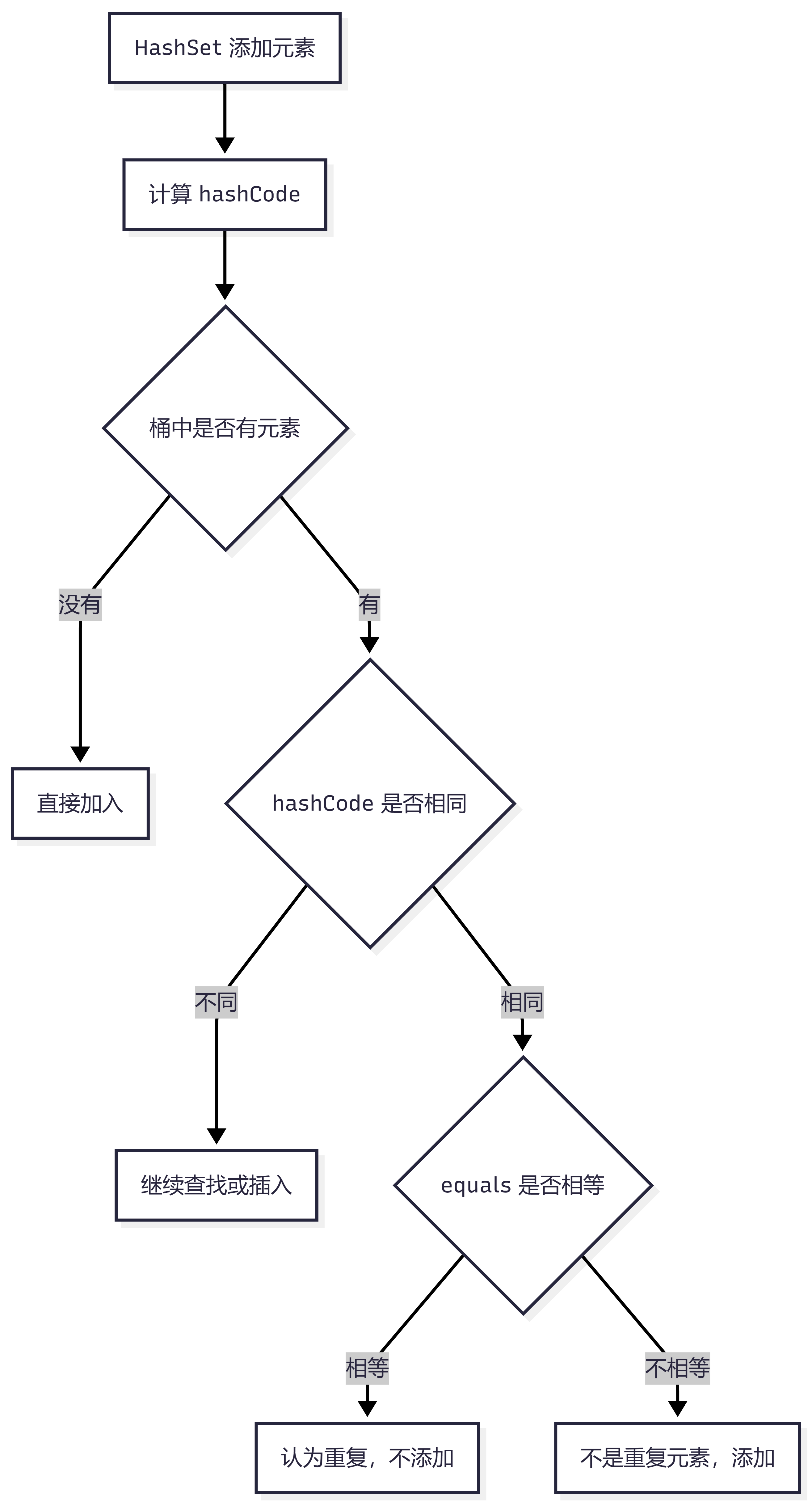
十一、HashSet 如何判断元素重复?
依赖两个方法:
hashCode() equals()
判断流程:
先比较 hashCode 如果 hashCode 不同,认为不是同一个元素 如果 hashCode 相同,再用 equals 比较
流程图:
所以自定义对象放入 HashSet 时,必须正确重写:
equals() hashCode()
否则去重可能失效。
十二、为什么重写 equals 必须重写 hashCode?
因为 HashSet、HashMap 会先用 hashCode 定位桶,再用 equals 判断是否相等。
如果两个对象 equals 相等,但 hashCode 不同,它们可能被放到不同桶里。
这样 HashSet 就会认为它们不是重复元素。
规则一定要记住:
equals 相等,hashCode 必须相等
hashCode 相等,equals 不一定相等
示例:
class User {
private Long id;
private String name;
// 如果只重写 equals,不重写 hashCode,
// 放入 HashSet 时可能无法正确去重
}十三、LinkedHashMap 有什么特点?
LinkedHashMap 继承自 HashMap,但额外维护了一条双向链表。
它可以保持顺序:
插入顺序 访问顺序
常见用途:
需要按插入顺序遍历 Map 实现 LRU 缓存
比如你希望遍历结果和插入顺序一致,就可以使用 LinkedHashMap。
如果开启访问顺序模式,每次访问元素后,会把它移动到链表尾部,这就可以用来实现简单 LRU 缓存。
十四、TreeMap 底层是什么?
TreeMap 底层是红黑树。
特点:
key 有序 增删查时间复杂度 O(logN) 默认按 key 的自然顺序排序
也可以传入自定义比较器:
Map<Integer, String> map = new TreeMap<>((a, b) -> b - a);如果需要排序的 Map,可以使用 TreeMap。
十五、HashMap、LinkedHashMap、TreeMap 怎么选?
可以这样记:
| 类型 | 适合场景 |
|---|---|
| HashMap | 普通 key-value,追求查询性能 |
| LinkedHashMap | 需要保持插入顺序或访问顺序 |
| TreeMap | 需要按照 key 排序 |
| ConcurrentHashMap | 多线程并发场景 |
面试回答时,最好结合场景说,而不是只背概念。
比如:
如果只是普通查询,用 HashMap; 如果遍历时要保持插入顺序,用 LinkedHashMap; 如果 key 要自动排序,用 TreeMap; 如果多线程并发读写,用 ConcurrentHashMap。
十六、TreeSet 底层是什么?
TreeSet 底层是 TreeMap。
TreeSet 的元素会作为 TreeMap 的 key。
所以 TreeSet 具有:
不重复 自动排序
如果自定义对象放入 TreeSet,需要:
实现 Comparable 或传入 Comparator
否则对象之间无法比较大小,可能会报错。
十七、什么是 fail-fast?
fail-fast 是 Java 集合的一种快速失败机制。
当你遍历集合时,如果直接修改集合结构,可能抛出:
ConcurrentModificationException
例如:
for (String s : list)
{
if ("a".equals(s)) {
list.remove(s);
}
}这类代码通常会出问题。
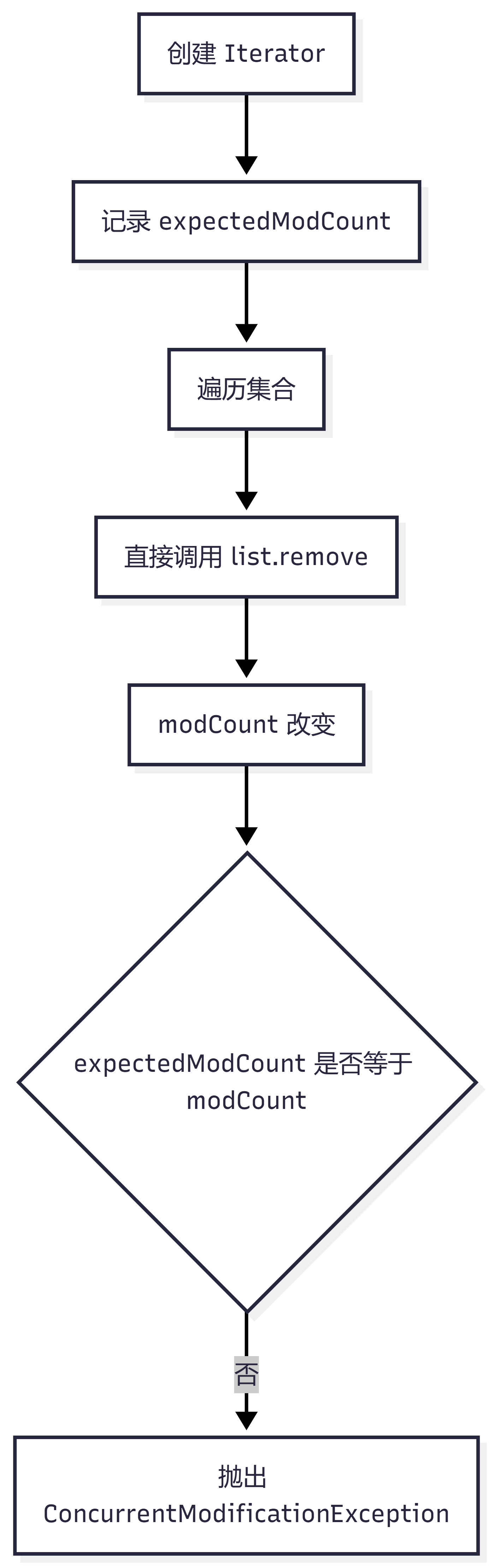
十八、为什么遍历集合时删除元素会报错?
增强 for 底层使用的是 Iterator。
Iterator 会记录一个期望修改次数:
expectedModCount
集合本身有一个实际修改次数:
modCount
如果遍历过程中直接调用集合的 remove,modCount 变了,但 expectedModCount 没有同步更新。
Iterator 发现两者不一致,就抛出异常。
流程如下:
十九、遍历时如何安全删除元素?
方式一:使用 Iterator 自己的 remove 方法。
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
if ("a".equals(s)) {
iterator.remove();
}
}方式二:使用 Java 8 的 removeIf。
list.removeIf(s -> "a".equals(s));
不要在增强 for 里直接:
list.remove(s);
二十、这一组怎么串起来讲?
可以这样回答:
HashMap 适合单线程普通 key-value 场景,但线程不安全。
多线程下应该使用 ConcurrentHashMap。
JDK 7 的 ConcurrentHashMap 使用 Segment 分段锁;
JDK 8 改为数组 + 链表 + 红黑树,并通过 CAS 和 synchronized 保证并发安全。 它的 get 通常不加锁,put 时桶为空用 CAS,桶不为空锁住桶头节点,所以并发性能更好。
HashSet 底层是 HashMap,通过 key 去重,所以自定义对象要重写 equals 和 hashCode。
LinkedHashMap 可以维护插入顺序或访问顺序,TreeMap 基于红黑树实现 key 排序。
遍历集合时不能直接修改结构,否则可能触发 fail-fast,应该使用 Iterator.remove 或 removeIf。
总体流程图

总结
这一组可以按下面这条线来记:
HashMap 线程不安全,多线程用 ConcurrentHashMap。
JDK 7 ConcurrentHashMap 是 Segment 分段锁。
JDK 8 是 CAS + synchronized,锁粒度到桶。 ConcurrentHashMap 的 get 通常不加锁。
ConcurrentHashMap 不允许 null,是为了避免并发环境下的歧义。
HashSet 底层是 HashMap,去重依赖 equals 和 hashCode。 equals 相等,hashCode 必须相等;hashCode 相等,equals 不一定相等。
LinkedHashMap 可以保持插入顺序或访问顺序。
TreeMap 基于红黑树,按 key 排序。 TreeSet 底层是 TreeMap。
fail-fast 是遍历时检测并发修改的机制。
安全删除用 Iterator.remove 或 removeIf。
这一组重点背:ConcurrentHashMap JDK7/JDK8 区别、CAS + synchronized、get 不加锁、为什么不允许 null、HashSet 底层、equals/hashCode、LinkedHashMap、TreeMap、fail-fast
📌 码字不易,技术干货深度复盘!
如果这篇文章帮你看清了 MyBatis-Plus 查询的底层底细,别忘了 点赞、关注、收藏 三连走一波!支持作者不迷路,更多底层源码干货持续输出中!🚀
让我们一起学习面试知识,拿到自己想要的offer!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)