P104-100 矿卡跑 35B-A3B 大模型:从“电子垃圾”到“Token FREE”
一张被嫌弃的“以太坊矿卡”,8GB 显存,没有显示输出,连官方驱动都不认。
2026 年的今天,它却在 Ubuntu 上稳定跑起了 35B MoE 模型,prefill 51 t/s,生成 20 t/s。
—— 只要你不放弃它,它就不会放弃你。

可能P102更好。限于尺寸,只有P104合适。
引言:你以为它是垃圾,其实只是没遇到对的人
我最近掏了张 NVIDIA P104-100。准备替换古旧的GT960显卡。
听名字就知道,它是专门为以太坊挖矿设计的——没有显示接口,官方不提供 Linux 驱动,连二手贩子都嫌弃它“魔改”出身。
2026 年的今天,人人都在聊 RTX 5090、AMD AI 加速卡。我还在琢磨古旧的GTX960升级,没办法,AI不是我的核心业务,领导不批采购高端显卡。但960也太古早了,虽然我用它直通到虚拟机后,可以提升电子设计画图的效率,但2G显存貌似只费电,也干不了个啥。
况且,我是个本地智能体(微纳智能体/nanobot)热心用户,需要离线推理 30B+ 的大模型。云端 API 太贵,新卡买不起,但我有一个华硕 X99 老主板、i7-5960 处理器和 64GB 内存也还凑合的前同事淘汰的服务器让我折腾,上面还有一个亮机卡。不能浪费了不是。
硬着头皮上吧。
于是,我选择自费添加P104-100,最小代价的升级。我开始了长达两周的“挖坑 → 填坑 → 再挖坑”之旅。
这篇文章,就是我拿 nvidia-smi 和 llama-bench 伴着退货收货的啰嗦的实录。
一、硬件环境:寒碜,呵呵,没到极点
- GPU:NVIDIA P104-100 8GB(Pascal 架构,计算能力 6.1,以太坊矿卡,无显示输出)
- 主板:华硕 X99-A(PCIe 通道分配诡异)
- CPU:Intel i7-5960(也是当时很强的U了)
- 内存:64GB DDR4 (这个挺好,超出一般水平)
- OS:Ubuntu 24.04
- 目标模型:Qwen3.6-28B-A3B-Q4_K_M.gguf(MoE,总参 28B,激活约 3B,量化后 16GB)
- 软件:llama.cpp (自编译 with CUDA)
每次看到 nvidia-smi 里那个 P104-100 的名字,我都觉得它在嘲笑我:“你连显示器都接不上我,还想跑大模型?”
二、第一道坎:连驱动都装不上
P104 没有官方 Linux 驱动。
网上搜了一圈,找到了 NVIDIA-patcher 项目(第三方魔改驱动)。折腾了半天,终于装上了 580.142。
关键步骤:
- 下载官方 .run 驱动和NVIDIA-patcher 项目补丁包。
- 解压原厂驱动后用NVIDIA-patcher 项目补丁覆盖,然后安装驱动。
- 必须在 BIOS 里关闭 Secure Boot,否则驱动加载失败。
- 运行 sudo sh cuda_xxx.run,取消安装 Driver 选项(因为已经手动打补丁了)。
验证成功的那天,我看到 nvidia-smi 输出:
NVIDIA P104-100 8109 MiB
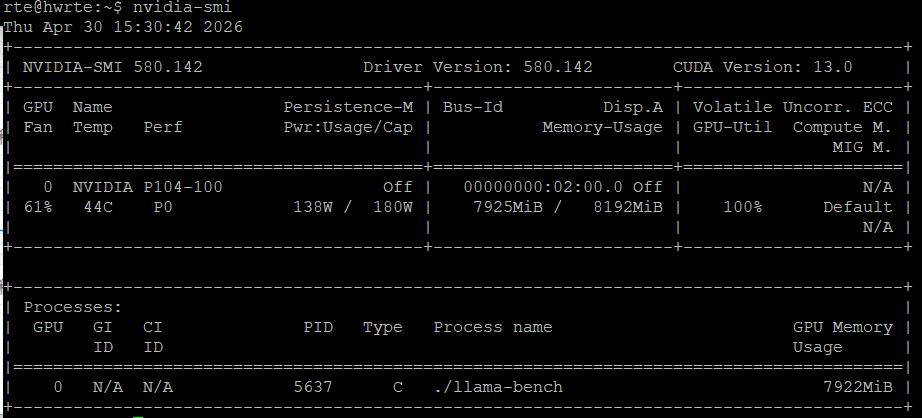
那一刻,我感觉自己像个修好了报废车的修车工,满手油污,但嘴角上扬。
三、第二道坎:llama.cpp 编译,共享内存炸了
高高兴兴 git clone,cmake -DGGML_CUDA=ON,make。
结果:
ptxas error: Entry function uses too much shared data (0xd100 bytes, 0xc000 max)
P104 的共享内存只有 48KB(0xc000),而 Flash Attention 的某个 tile 实例需要 53KB(320,256 那个)。
网上搜到的解决方案:
- 在 cmake 时添加 -DGGML_CUDA_FLASH_ATTN=OFF,彻底禁用 Flash Attention。
- 或者手动注释 ggml/src/ggml-cuda/fattn-tile.cuh 里所有包含 320,256 的行。
我选择了前者(省事)。编译成功的那一刻,我觉得已经通关了。
太天真了。
四、第三道坎:性能烂到想砸键盘
编译完,下载模型。设置 -ngl 0(纯 CPU),pp512 居然只有 6.63 t/s。
而之前我用 GTX 960(2GB)跑同样模型,纯 CPU 也有 45 t/s 啊!
这不对,肯定是哪里出了问题。
运行 sudo lspci -vvv -s 05:00.0 | grep LnkSta,看到:
LnkSta: Speed 2.5GT/s, Width x1 (downgraded)
PCIe 居然降级到了 x1,速度只有 1.0!
难怪 prefill 那么慢,数据都堵在 PCIe 通道上了。
五、第四道坎:与 PCIe 降级死磕
5.1 清洁金手指,换插槽
先拔下来,用橡皮擦擦了擦金手指,重新插回第一条 PCIe x16 槽。
重启,lspci 依然 x1。
再换到第二条槽,还是 x1。
5.2 BIOS 里疯狂设置
华硕 X99 的 BIOS 里,我找到了 Advanced → System Agent Configuration → NB PCI-E Configuration。
- 把对应插槽的 Link Speed 从 Auto 强制为 Gen3。
- 找到 PCIe Slot Bandwidth(如果有),设为 x4 Mode。
- 禁用 ASPM(省电模式)。
保存重启。
奇迹出现了:
LnkSta: Speed 2.5GT/s, Width x4
宽度恢复成了 x4!虽然速度还是 2.5GT/s(PCIe 1.0),但这已经让 prefill 速度从 9 t/s 飙到了 38 t/s。
我差点在工位上喊出来。
重要插曲:后来我试着把卡换到 PCIe 3.0 x16_3 插槽(主板标称支持 3.0),但 lspci 显示 LnkCap 最大依然是 2.5GT/s。
这说明 这张 P104 的 VBIOS 本身锁死了 PCIe 1.0 速度——矿卡的常见手段。
所以插槽不用再换了,x4 宽度已经是最好的结果。
六、性能调优:从 9 t/s 到 51 t/s
6.1 逐层逼近显存极限
我开始用 llama-bench 逐层测试 -ngl(GPU 卸载层数)。从 4 层开始,每加 2 层测一次,同时用 nvidia-smi 监控显存。
|
ngl |
pp512 (t/s) |
tg128 (t/s) |
显存占用 |
备注 |
|
4 |
8.03 |
14.12 |
~3.5GB |
PCIe 瓶颈巨大 |
|
8 |
9.01 |
14.79 |
~4.5GB |
提升缓慢 |
|
10 |
36.18 |
15.29 |
~6GB |
宽度 x4 后跃升 |
|
12 |
38.18 |
17.91 |
~7GB |
稳定 |
|
16 |
42.31 |
19.09 |
~7.8GB |
接近满载 |
|
18 |
51.00 |
20.22 |
~8.0GB |
临界点 |
|
19 |
OOM |
OOM |
溢出 |
直接退出 |
-ngl 18 是最佳点,显存接近满载但未溢出,prefill 达到 51 t/s,生成 20.2 t/s。
那一刻,我看着 nvidia-smi 里 P104 满载但没有溢出的状态,觉得这张矿卡终于被“打通了任督二脉”。
6.2 KV Cache 量化:意外收获
我发现显存紧张时,KV Cache 的数据类型(-ctk)会影响稳定性。于是对比了 q4_0、q8_0 和 f16:
|
type_k |
pp512 (t/s) |
tg128 (t/s) |
显存占用趋势 |
|
q4_0 |
50.84 |
20.20 |
最低,稳定 |
|
q8_0 |
51.00 |
20.22 |
中等,最稳 |
|
f16 |
50.35 |
19.54 |
最高,略抖 |
结论:q8_0 与 f16 性能几乎无差异,但显存占用更低,是混合卸载场景下的首选。q4_0 可作为极端情况下的“急救包”。
最终启动命令:
./main -m Qwen3.6-28B-A3B-Q4_K_M.gguf \
-ngl 18 \
-ctk q8_0 \
-t 8 \
--no-mmap \
--numa
七、性能对比:矿卡 vs 纯 CPU vs 小模型
为了让读者有个直观感受,我把之前测试的几种配置放在一起对比:
|
配置 |
模型 |
显存占用 |
prefill (t/s) |
生成 (t/s) |
|
纯 CPU (ngl=0) |
35B MoE |
0GB |
6.63 |
8.36 |
|
优化前 (ngl=12, x1 PCIe) |
35B MoE |
~7GB |
9.76 |
14.99 |
|
最终方案 (ngl=18, x4 PCIe, q8_0) |
35B MoE |
~8GB |
51.0 |
20.2 |
|
9B 稠密 (ngl=99) |
9B |
~5GB |
538 |
29.6 |
结论:
- 同是 35B MoE,优化后 prefill 速度是优化前的 5.2 倍,生成速度提升 35%。
- 35B MoE 的生成速度(20 t/s)略低于 9B 稠密(29.6 t/s),不过智商略高一些。
- 8G老卡用户,可以随意选择 7-9B 稠密,或者35B-A3B MoE。
- 不得不说,P104跑9B模型真香,奈何我对9B模型已无兴趣。
八、踩坑总结(血泪清单)
|
问题 |
解决方案 |
|
驱动装不上 |
使用 NVIDIA-patcher 魔改驱动,关闭 Secure Boot |
|
编译共享内存超限 |
cmake -DGGML_CUDA_FLASH_ATTN=OFF |
|
PCIe 降级 x1 |
BIOS 强制设置插槽宽度为 x4,速度 Gen3,禁用 ASPM |
|
显存不足 OOM |
用 -ngl xx 逐层测试,找到临界点(18 层) |
|
prefill 速度慢 |
先解决 PCIe 宽度问题;宽度正常后即使速度低也能接受 |
|
生成速度低 |
P104 显存带宽 192GB/s,20 t/s 是上限,接受它 |
|
KV Cache 占显存 |
使用 -ctk q8_0,性能几乎无损,节省显存 |
九、老卡不是不能战,而是要用对姿势
这次折腾让我明白了几件事:
- 矿卡也能跑大模型。只要肯花时间调试驱动、编译、PCIe、显存,它就能焕发第二春。
- MoE 模型是老卡救星。35B MoE 激活参数少,显存压力小,智商还高。
- PCIe 宽度比速度更重要。x4 宽度即使只有 PCIe 1.0 速度,也能让 prefill 跑出 50+ t/s。
- -ngl 需要精细调优。从 4 到 18,每增加一层都可能带来惊喜,也可能 OOM。
- KV Cache 量化是隐形福利。q8_0 不降速但省显存,必须用。
最后,我想对还在用老旧显卡的朋友说:
别急着扔,先试试 MoE 模型 + 精细调参。也许你的“电子垃圾”还能再战三年。
至于我?
这张 P104 会继续在我的机箱里服役,为我的龙虾智能体默默推理,20tps的速度大致和amd HX370 小主机(~25tps)的相当,应付本地养龙虾是足够的。
它没有 RTX 5090 的快,但它有 100 块就能买到的最高性价比的倔强。
矿卡不死,只是换了一种活法。
附录:部分测试数据
点击展开 llama-bench 原始输出
# 修复 PCIe 之前(x1 宽度)
ngl=12: pp512 9.76 t/s, tg128 14.99 t/s
# 修复 PCIe 之后(x4 宽度),未指定 type_k(默认 f16)
ngl=10: pp512 36.18, tg128 15.29
ngl=12: pp512 38.18, tg128 17.91
ngl=16: pp512 42.31, tg128 19.09
ngl=18: pp512 44.79, tg128 20.16
# 最终优化(-ctk q8_0, ngl=18)
ngl=18, q8_0: pp512 51.00, tg128 20.22
ngl=18, q4_0: pp512 50.84, tg128 20.20
ngl=18, f16: pp512 50.35, tg128 19.54
# ngl=19 尝试
直接 OOM,进程退出
后记:
现在,我的龙虾智能体每天都要调用这张矿卡推理几百次。它没让我失望——虽然没有飞快,但稳定、廉价、完全离线。实现了Token FREE
这也许就是 DIY 的乐趣:用最垃圾的硬件,榨出最实用的性能。
如果你也有一张 P104,或者你有不能升级显卡的够强的主机,不妨试试这篇文章里的方法。
万一成功了呢?
那不就是花小钱: 88元+12元折腾费+无价(免费的)人工 ,办大事:引进一个7X24全科硕士小助理么。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)