从扩音啸叫到通话回音,现代语音系统为何越来越依赖智能声学DSP
在现代语音设备中,用户最无法接受的问题,往往不是“声音不够大”,而是声音一旦变大,系统立刻开始尖叫、回音、断续甚至无法正常通话。
这种问题广泛存在于:会议扩音系统 小蜜蜂扩音器 门禁对讲 视频会议 车载蓝牙 智能语音终端 工业广播设备

尤其随着设备越来越小型化,麦克风与扬声器之间的距离不断缩短,高增益、高灵敏度与系统稳定性之间的矛盾也变得越来越突出。
很多人习惯把这些问题统称为“啸叫”,但实际上,扩音系统中的啸叫,与全双工通话中的回音失稳,并不是同一种技术问题。
而A-59F的意义,正在于它同时解决了这两种长期困扰行业的核心声学难题。
扩音啸叫:本地扩声系统中的声学正反馈
在扩音系统中,最典型的问题就是“啸叫”。其本质,是一种声学正反馈现象。
当麦克风拾取到讲话人的声音后,声音经过功放放大,再由扬声器播放出来,而扬声器播放出的声音又再次进入麦克风时,系统内部就形成了一个完整的声音闭环。
如果这个闭环中的某个频率增益超过稳定阈值,那么该频率的能量就会不断叠加,最终形成持续性的高频自激振荡,也就是人们听到的尖锐啸叫。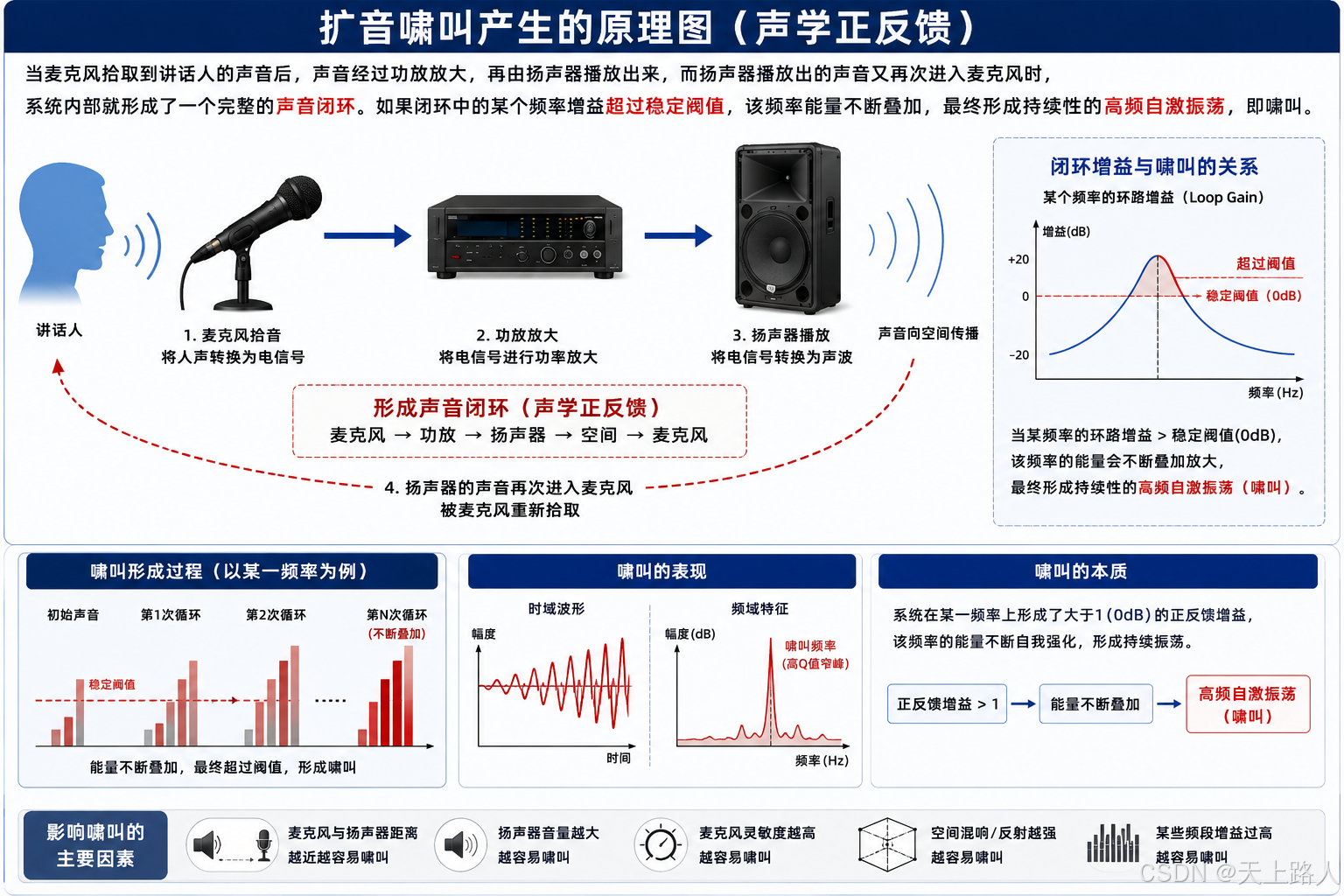
这种问题在传统扩音器、小蜜蜂、导游机以及教学扩声系统中极为常见。
因此,传统设备通常只能被迫:降低麦克风灵敏度 减小喇叭音量 拉远麦克风与喇叭距离 使用固定频点陷波 ,但这些方法本质上只是妥协。
因为一旦降低灵敏度,拾音距离就会缩短;降低音量又会影响扩声效果;而固定频点陷波则容易破坏声音本身的自然度。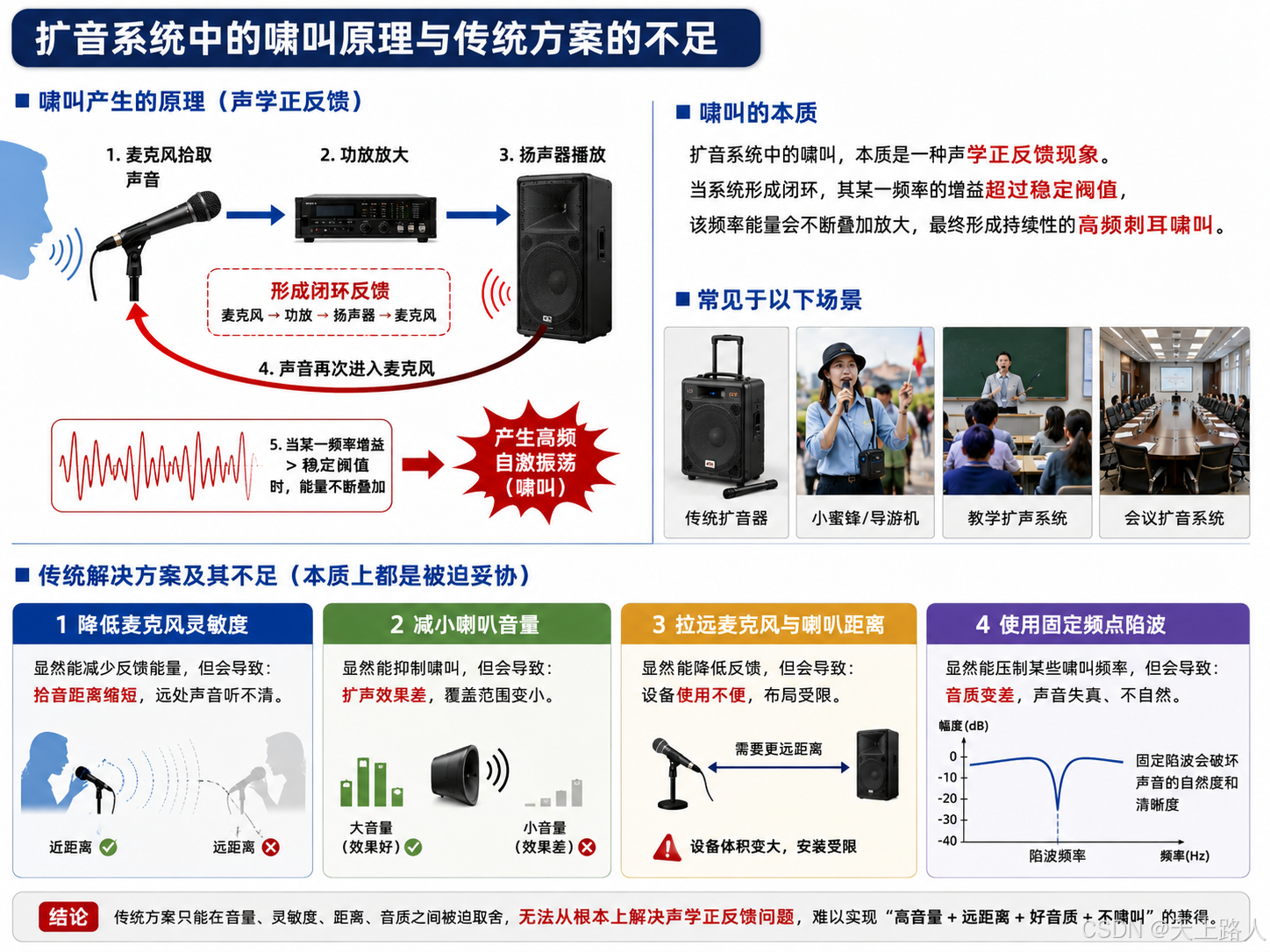
A-59F 如何解决扩音啸叫
A-59F针对扩音系统,并不是简单地“压制某个频率”。
它采用的是完整的低延迟数字声学反馈抑制架构。
在扩音防啸叫模式下,A-59F的整体处理延迟仅为15ms,这意味着DSP能够在极短时间内完成:回授频率检测 ,相位分析 ,动态增益调节,自适应频率抑制
从而在啸叫真正形成之前,就提前阻断声学反馈能量的持续积累。与传统固定陷波器不同,A-59F会实时分析整个空间中的声学变化,包括:环境反射,空间混响,麦克风位置变化,喇叭音量变化,并动态建立当前环境下的反馈模型。因此,即使设备工作环境不断变化,系统依然能够保持较高稳定性。更重要的是,A-59F内部集成了AI环境降噪算法。系统能够主动识别:风噪,空调噪声,机械振动,敲击声,电流底噪并对这些非语音信号进行实时压制,仅保留主要人声频段。
这意味着系统内部的无效能量被显著降低,从而进一步提高整个扩音系统的稳定裕量。
因此,A-59F能够让设备在更高音量、更高灵敏度条件下,依然保持稳定自然的扩音效果。
通话啸叫:真正的问题其实是回音循环
与扩音啸叫不同,全双工通话中的“啸叫”,本质上其实属于回音失控。
它更多出现在:门禁对讲,视频会议,车载通话,银行客服,远程会议系统中。
当远端声音从本地扬声器播放出来后,又重新进入本地麦克风,并再次发送回远端设备时,双方系统之间就会形成“回音循环”。
如果AEC回音消除能力不足,那么回音会在两端设备之间不断叠加,最终形成:尖叫 啸叫 抢话 断续 无法全双工通话,
这种问题与扩音啸叫最大的区别在于:它不再是单纯的本地声学正反馈,而是“通信链路中的回音循环失稳”。因此,仅仅降低音量或者减小增益,并不能真正解决问题。
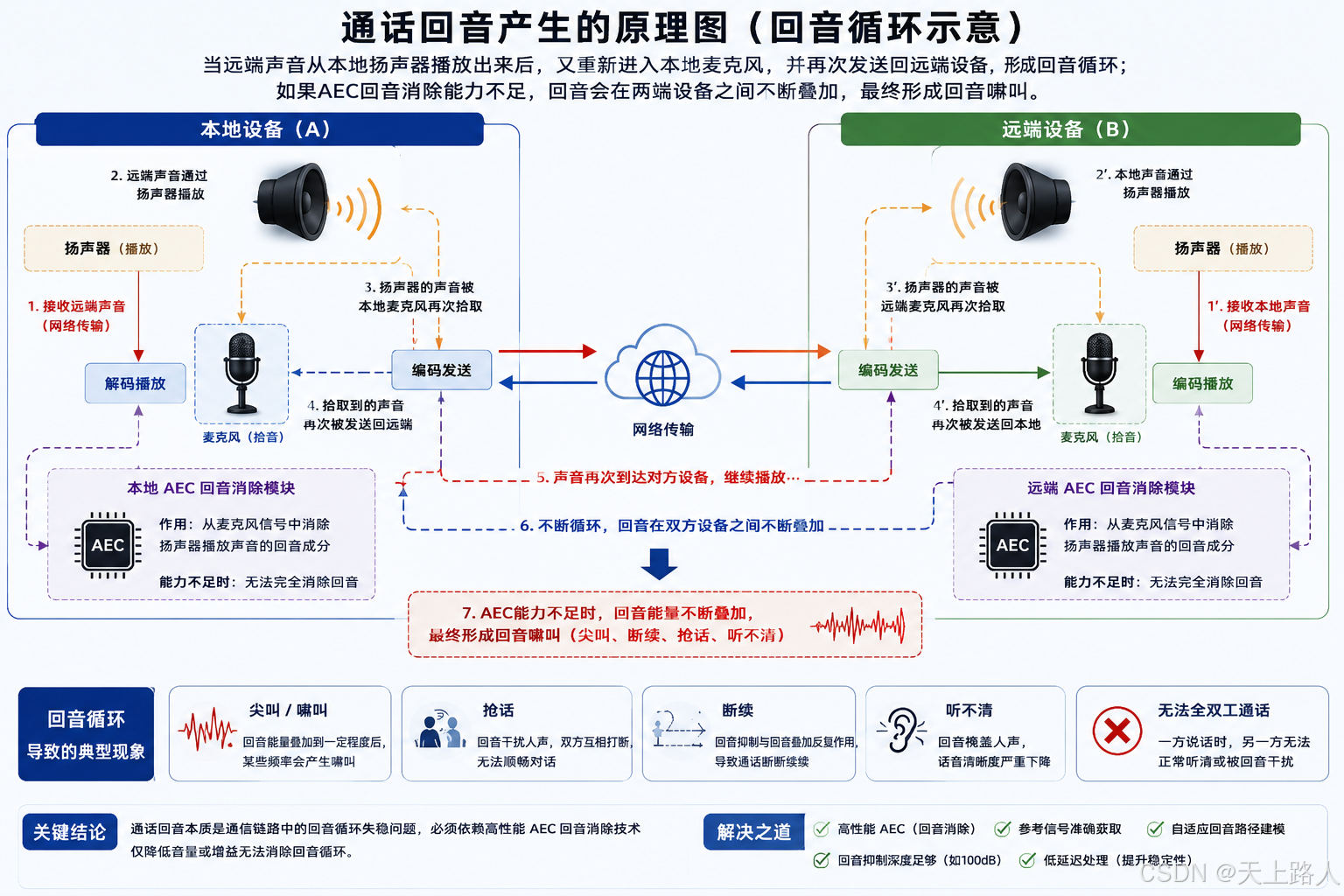
A-59F 的全双工AEC回音消除机制
A-59F内部集成高性能AEC全双工回音消除算法,其回音消除能力最高可达100dB,并支持最大100ms空间回音延迟补偿。
系统通过参考信号输入机制,实时获取功放输出或者DAC输出的参考音频,再由DSP动态建立:扬声器到麦克风之间的传播路径,空间反射模型,相位变化,延迟变化,混响特性随后,系统会从麦克风信号中实时减去预测出的回音成分,仅保留真实的人声部分。
因此,即使在:大功率喇叭,小空间设备,高灵敏麦克风,复杂混响环境下,A-59F依然能够维持稳定自然的全双工通话。
真正实现:边说边听,而不是互相抢话。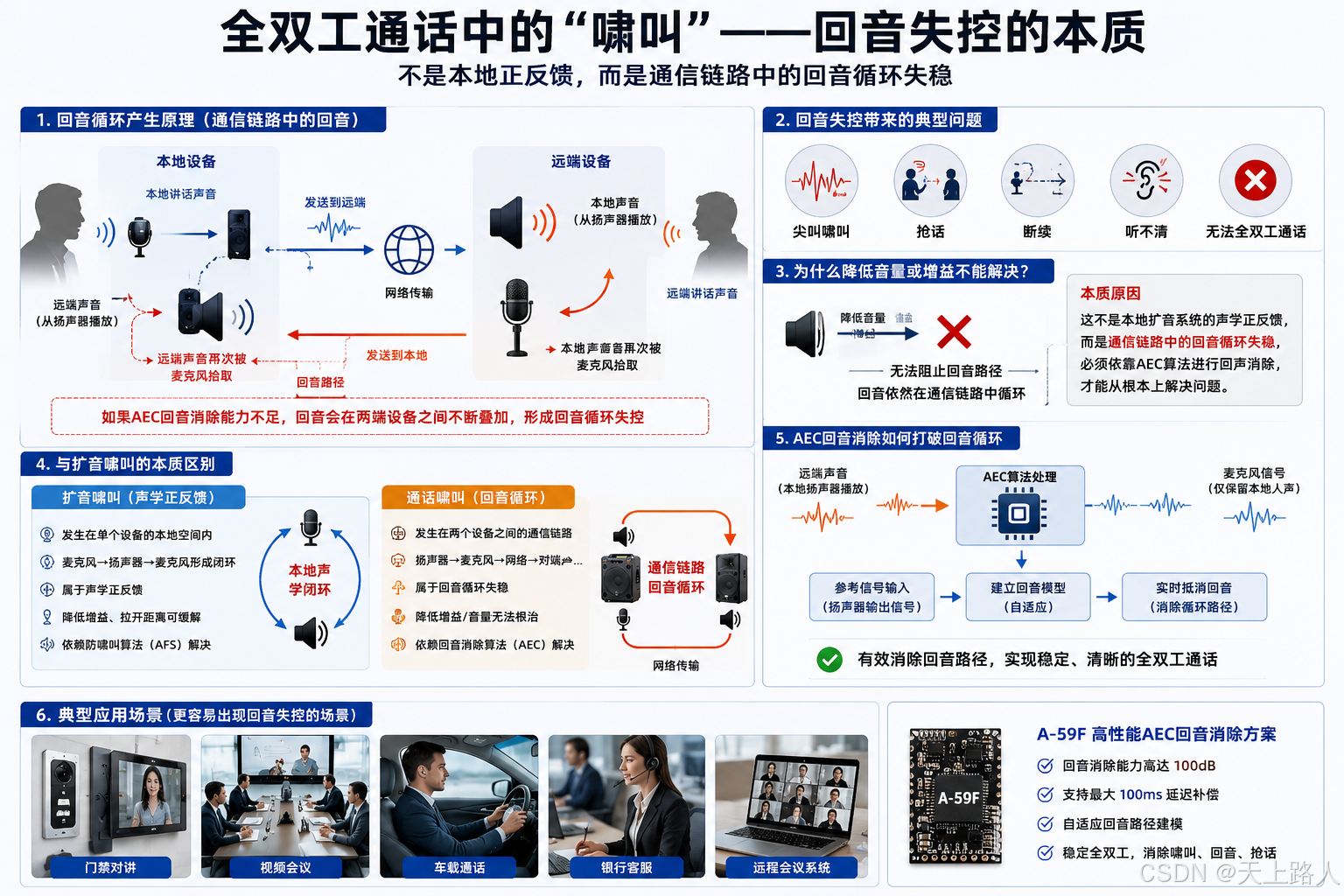
现代语音设备的发展方向,已经不再是简单“把声音放大”。而是要求:更远的拾音距离,更大的音量,更小的设备体积,更复杂的环境适应能力,更自然的全双工体验,传统模拟音频架构已经越来越难满足这些需求。而A-59F通过:AI环境降噪,自适应防啸叫,全双工AEC.数字DSP处理.波束定向拾音
构建了一整套现代智能声学处理架构。它真正解决的,不仅仅是“声音能不能放出来”。
而是:在复杂环境下,声音是否依然能够保持稳定、清晰、自然与可用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)