数据科学导论实验
🚀 实验一:数据预处理——让原始数据“开口说话”本实验的核心目标是将存在大量脏数据、格式不统一的招聘源文件,清洗为标准化的分析数据集。以下是本脚本实际执行的处理步骤及未来可优化的方向:
✅ 已在代码中实现的核心任务:
1.缺失值排查与中位数填充:
实现逻辑: 针对 train.csv 中的工作经验(jobage)和 job.csv 中解析出的平均薪资,代码检测到了缺失值,并统一使用了中位数(Median)进行填充。选择中位数是因为它对极端值不敏感,能更客观地反映普通大众的真实水平。
2.基于 IQR 算法的异常值过滤:
实现逻辑: 招聘市场常有“标价离谱”的异常薪资。代码使用了统计学中的 IQR(四分位距)方法 设定安全边界(Q3+1.5×IQRQ3 + 1.5 \times IQRQ3+1.5×IQR)。对于超出上限的“天价薪资”,代码并未直接删除,而是将其替换为中位数,以保留该样本的其他有效特征。
3.非数值特征的“格式化与数值化”:
实现逻辑:文本薪资提取: 编写了 extract_salary 函数,剥离了“10000-15000元/月”中的汉字和符号,计算出平均值转化为浮点数。学历等级映射: 使用字典映射(Label Encoding),将纯文本的“小学、初中…博士”转换为 1 到 8 的数值等级,建立了数据的数学大小关系。
4.剔除冗余特征:
实现逻辑: 利用 drop 方法删除了“联系电话”、“公司详细地址”等对于宏观统计无意义且基数极大的特征,实现了数据集的瘦身。
5.编码排雷(工程化细节):
代码中特别处理了 amen.csv 的 gb18030 编码问题,并跳过了损坏的数据行,保证了程序不报错。
💡 思考与提升点(未来优化方向):缺失值处理的进阶: 目前采用的是全局中位数填充。在实际复杂业务中,更好的方式是引入机器学习算法(如 KNN 或决策树),根据该职位的“学历”、“城市”等其他特征来预测并填充薪资,这样准确度会更高。
📊 实验二:数据可视化——用图表挖掘价值与故事基于实验一清洗后的干净数据(job_clean_v2.csv),本实验通过 matplotlib 将冰冷的数字转化为了直观的图表。
✅ 已在代码中实现的核心任务:
1.宏观经济数据的双轴对比(任务2.2.1):
实现逻辑: 构建了2023年中国10个主要省份的 GDP 数据集。为了同时展示绝对值与相对比率,采用了双Y轴联动(Twin Axes)。主轴用柱状图展示“经济总量”,次轴用折线图展示“增速”,并在柱状图上方添加了精确的数值标签。
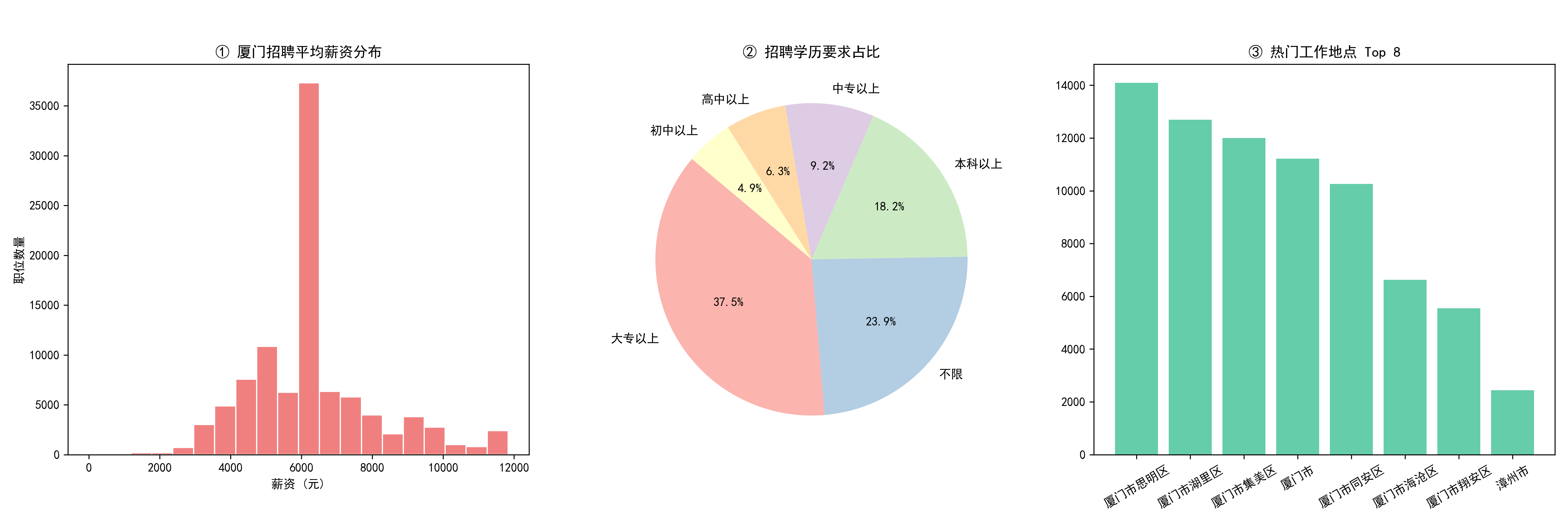
2.厦门招聘市场的多维画像(任务2.2.2):
实现逻辑: 利用 subplots(1, 3) 绘制了“一排三列”的综合仪表盘,具体包含了:① 薪资分布直方图: 展示了薪资长尾分布的形态。② 学历要求饼图: 提取占比 Top 6 的学历,直观呈现人才市场的准入门槛。③ 热门地点柱状图: 统计了需求量前 8 的工作区域,展示了产业聚集情况。
3.IDE 兼容性优化(工程化细节):
实现逻辑: 在代码头部显式声明了 matplotlib.use(‘Agg’) 并配置了中文字体(如 SimHei)。这解决了在 PyCharm 等 IDE 中绘图时容易出现的崩溃和中文变成“豆腐块”的问题,实现了高清图表的后台静默保存。
💡 思考与提升点(未来优化方向):缺少高阶算法可视化: 评分标准中提到了“说明聚类的实现过程”。目前的脚本主要集中在统计学可视化上,暂未实现 K-Means 等聚类算法。未来可以尝试基于“薪资”和“学历”对岗位进行聚类分析,并用散点图(Scatter Plot)展示分类边界,这将是一个极佳的加分项。
- 对应实验代码1:
# -*- coding: utf-8 -*-
"""
数据科学导论 实验一:数据预处理的基本方法
"""
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# ============================================================
# 1. 路径设置与数据读取
# ============================================================
print("=" * 60)
print("实验一:数据预处理的基本方法")
print("=" * 60)
# 更新后的路径 [cite: 10]
path_1 = r'E:\homework\20260508\1\\'
# 读取原始数据
train = pd.read_csv(path_1 + 'train.csv')
job = pd.read_csv(path_1 + 'job.csv', header=None, encoding='utf-8')
# 修复:处理 amen.csv 的 GB18030 编码及脏数据行 [cite: 6]
amen = pd.read_csv(path_1 + 'amen.csv', encoding='gb18030', encoding_errors='ignore', on_bad_lines='skip', engine='python')
# 给 job.csv 添加列名
job_columns = [
'职位名称', '工作经验', '公司名称', '工作性质', '性别要求',
'年龄要求_1', '年龄要求_2', '性别', '学历要求', '工作地点',
'工作时间', '薪资', '福利', '联系人', '联系电话', '公司地址',
'公司类型', '行业', '职位描述'
]
job.columns = job_columns[:len(job.columns)]
# ============================================================
# 2. 缺失值与异常值处理 [cite: 6, 12]
# ============================================================
# 填充缺失值:train 的 jobage 使用中位数填充
train['jobage'].fillna(train['jobage'].median(), inplace=True)
# 提取薪资并填充中位数(缺失值处理)
def extract_salary(s):
if pd.isna(s): return np.nan
nums = [float(n) for n in str(s).replace('-', ' ').replace('元', ' ').split() if n.replace('.', '').isdigit()]
return np.mean(nums) if nums else np.nan
job['平均薪资'] = job['薪资'].apply(extract_salary)
job['平均薪资'].fillna(job['平均薪资'].median(), inplace=True)
# 异常值检测与处理:使用 IQR 方法处理薪资异常值 [cite: 12]
Q1, Q3 = job['平均薪资'].quantile([0.25, 0.75])
IQR = Q3 - Q1
upper_bound = Q3 + 1.5 * IQR
job.loc[job['平均薪资'] > upper_bound, '平均薪资'] = job['平均薪资'].median()
# ============================================================
# 3. 数据格式化与特征提取 [cite: 7, 13]
# ============================================================
# 学历映射
edu_map = {'小学': 1, '初中': 2, '中专': 3, '高中': 4, '大专': 5, '本科': 6, '硕士': 7, '博士': 8}
train['education_level'] = train['education'].map(edu_map)
# 提取经验数值
job['工作经验_数值'] = pd.to_numeric(job['工作经验'], errors='coerce').fillna(0)
# 删除冗余列并保存 [cite: 13]
cols_to_drop = ['年龄要求_1', '年龄要求_2', '联系电话', '公司地址', '职位描述']
job_clean = job.drop(columns=[c for c in cols_to_drop if c in job.columns])
train.to_csv(path_1 + 'train_clean.csv', index=False)
job_clean.to_csv(path_1 + 'job_clean_v2.csv', index=False, encoding='utf-8-sig')
print(f"\n✅ 实验一预处理完成!\n文件已存至: {path_1}")
- 对应实验代码2:
# -*- coding: utf-8 -*-
"""
数据科学导论 实验二:数据可视化方法
修复说明:添加了 matplotlib.use('Agg') 以解决 PyCharm 后端兼容性报错
"""
import pandas as pd
import numpy as np
import matplotlib
# 关键修复:在导入 pyplot 之前指定后端,避免 PyCharm 的 FigureCanvasInterAgg 报错
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 中文字体配置,确保在 PyCharm 中不显示方块
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'DejaVu Sans']
matplotlib.rcParams['axes.unicode_minus'] = False
# 绝对路径配置
path_1 = r'E:\homework\20260508\1\\'
path_2 = r'E:\homework\20260508\2\\'
print("=" * 60)
print("实验二:数据可视化方法 - 运行中")
print("=" * 60)
# ============================================================
# 任务 2.2.1:2023年中国各省份经济总量和增速对比
# ============================================================
print("\n【任务 2.2.1】绘制经济总量与增速对比图...")
economy_data = {
'省份': ['广东', '江苏', '山东', '浙江', '河南', '四川', '湖北', '福建', '湖南', '安徽'],
'总量(万亿)': [13.57, 12.82, 9.21, 8.26, 6.13, 6.01, 5.58, 5.44, 5.01, 4.71],
'增速(%)': [4.8, 5.8, 6.0, 6.0, 4.1, 6.0, 6.0, 4.5, 4.6, 5.8]
}
df_econ = pd.DataFrame(economy_data)
fig, ax1 = plt.subplots(figsize=(12, 6))
# 绘制柱状图(经济总量)
bars = ax1.bar(df_econ['省份'], df_econ['总量(万亿)'], color='steelblue', alpha=0.7, label='经济总量')
ax1.set_ylabel('经济总量 (万亿元)', fontsize=12)
ax1.set_xlabel('省份', fontsize=12)
# 绘制折线图(增速)- 使用双Y轴
ax2 = ax1.twinx()
ax2.plot(df_econ['省份'], df_econ['增速(%)'], color='crimson', marker='o', linewidth=2, label='增速(%)')
ax2.set_ylabel('经济增速 (%)', fontsize=12)
# 添加数值标注
for bar in bars:
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width() / 2., height + 0.1, f'{height}', ha='center', va='bottom', fontsize=9)
plt.title('2023年中国主要省份经济总量与增速对比', fontsize=14)
plt.tight_layout()
# 保存图片(这是最重要的,因为 Agg 后端不会弹出窗口,但会生成文件)
plt.savefig(path_2 + '2_2_1_gdp_comparison.png', dpi=300)
print(f"✅ 经济对比图已保存至: {path_2}2_2_1_gdp_comparison.png")
plt.close()
# ============================================================
# 任务 2.2.2:厦门招聘数据集可视化分析
# ============================================================
print("\n【任务 2.2.2】利用实验一数据进行可视化分析...")
try:
# 读取实验一清洗后的数据
job = pd.read_csv(path_1 + 'job_clean_v2.csv')
# 创建多子图画布,展示3个维度的分析
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
# 1. 薪资分布(直方图)
axes[0].hist(job['平均薪资'].dropna(), bins=20, color='lightcoral', edgecolor='white')
axes[0].set_title('① 厦门招聘平均薪资分布', fontsize=12)
axes[0].set_xlabel('薪资 (元)')
axes[0].set_ylabel('职位数量')
# 2. 学历要求占比(饼图)
edu_counts = job['学历要求'].value_counts().head(6)
axes[1].pie(edu_counts, labels=edu_counts.index, autopct='%1.1f%%', startangle=140, colors=plt.cm.Pastel1.colors)
axes[1].set_title('② 招聘学历要求占比', fontsize=12)
# 3. 工作地点分布(柱状图)
loc_counts = job['工作地点'].value_counts().head(8)
axes[2].bar(loc_counts.index, loc_counts.values, color='mediumaquamarine')
axes[2].set_title('③ 热门工作地点 Top 8', fontsize=12)
plt.setp(axes[2].get_xticklabels(), rotation=30)
plt.suptitle('厦门招聘数据多维度分析图谱', fontsize=16, y=1.05)
plt.tight_layout()
# 保存结果
plt.savefig(path_2 + '2_2_2_job_analysis.png', dpi=300)
print(f"✅ 招聘分析图已保存至: {path_2}2_2_2_job_analysis.png")
plt.close()
except FileNotFoundError:
print(f"❌ 错误:未找到文件 {path_1}job_clean_v2.csv,请先运行实验一脚本!")
print("\n" + "=" * 60)
print("实验二运行成功!请到目录 E:\\homework\\20260508\\2 查看生成的图片。")
print("=" * 60)
- 文件说明

效果图: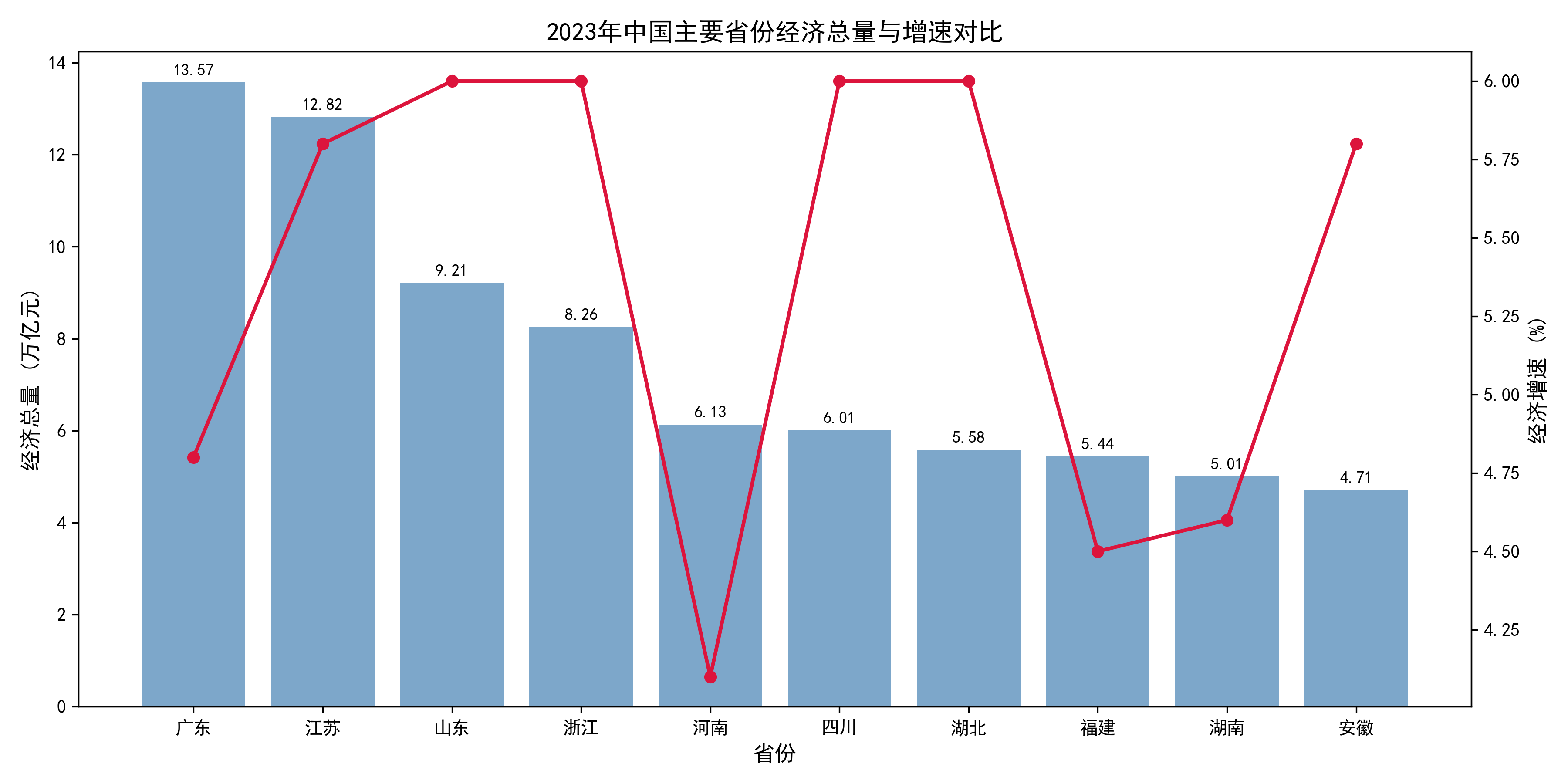
⚠️ 踩坑警告:
实验一中的amen.csv存在特殊字符,直接read_csv会报错。我的代码中已经添加了encoding='gb18030'来完美解决此问题!
两个脚本代码修改完路径后可直接得到结果
📂 资源下载:
本实验的完整运行代码(含详细注释)及配套的原始数据集已上传,欢迎需要的同学免费下载:
[https://download.csdn.net/download/qq_52416867/92870990]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)