ArXiv 26 S2M框架:从掩码中提取结构化文本,实现零成本多模态遥感变化检测
一、 研究背景与动机
在遥感变化检测(RSCD)领域,一个核心挑战是如何区分真正有意义的语义变化(如建筑损毁)和那些视觉上相似但无关的变化(如农田变为裸土)。传统的单模态深度学习方法仅依赖视觉信息,当不同类型的变化在图像上呈现相似纹理时,模型很容易混淆,这限制了其性能上限。

为了解决这个问题,近期研究开始引入文本作为辅助信息。但这些多模态方法普遍存在缺陷:要么依赖人工标注,成本高昂;要么使用大语言模型生成描述,这不仅会引入噪声和不准确性,还带来了巨大的计算开销。作者敏锐地发现,变化检测数据集中自带的“真值掩码(ground-truth mask)”本身就蕴含了丰富、精确的结构化信息——变化发生在哪里、前后地物类型是什么、变化的方式以及涉及对象的数量。然而,这些宝贵的“免费”信息从未被显式地提取和利用。本文的动机正是要零成本地将这些掩码中隐含的语义信息“翻译”成结构化的文本,为模型提供高质量、无噪声的多模态监督。
为帮助大家更好地复现,我整理了这篇论文的完整架构图 + 核心算法和零上手复现教程
关注公众号“遥感AI科研”,后台回复“B466”
二、 核心方法
-
整体思路:通过从变化检测的掩码(mask)中自动提取结构化文本信息,为视觉模型提供多模态监督,以解决语义模糊性问题。
-
关键公式/步骤:
-
语义四元组提取:该方法的核心是将每个变化区域的信息归纳为一个语义四元组
T(L, C, T, Q),分别代表位置(Where)、类别(What)、类型(How)和数量(How many)。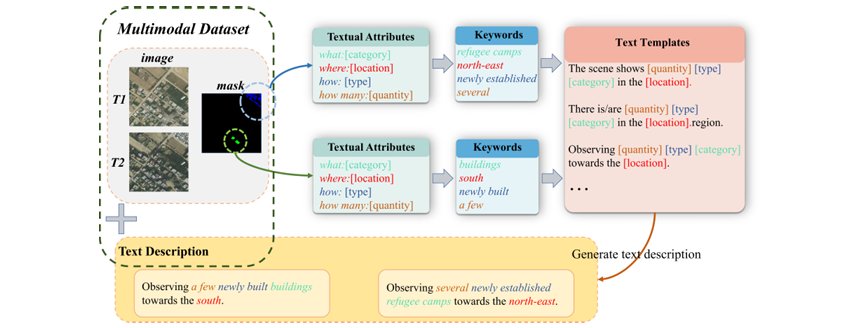
-
位置(Direction):通过计算变化区域掩码的质心来确定。质心坐标
(cx, cy)计算如下: 其中N是变化区域的总像素数。随后根据质心在3x3网格中的位置,将其映射为“东北”、“中心”等九个方位之一。 -
数量(Quantity):根据变化区域的像素总数
N,通过预设阈值划分为“单个”、“少数”、“若干”、“多个”四个等级。 -
类别(Category)与类型(Type):直接从数据集的类别标注中获取,如“建筑”和“被摧毁”。
-
-
两阶段训练策略:
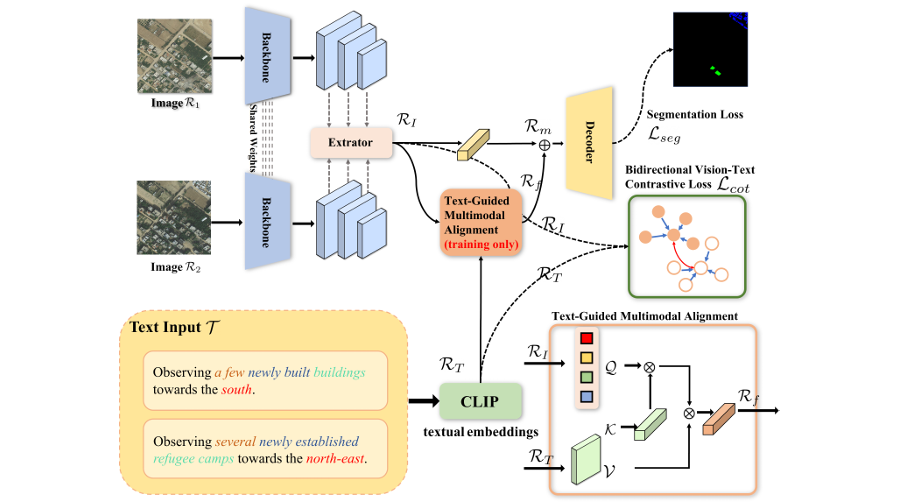
-
阶段一:仅使用图像进行视觉骨干网络(基于MC-DiSNet)的预训练,以学习领域特定的视觉表征。
-
阶段二:引入文本信息。将生成的结构化文本通过预训练的CLIP文本编码器转换为文本嵌入
RT,并设计一个文本引导的多模态对齐模块,通过交叉注意力机制将文本特征与视觉特征RI融合。
-
-
-
技术实现要点:
-
语义一致性与多样性:通过将提取的四元组信息填入5个不同的固定文本模板,随机选择其一生成描述,增加了语言多样性,防止模型对特定句式过拟合,同时保证了核心语义的统一。
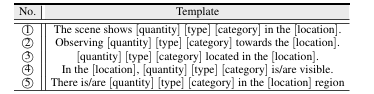
表1
- 训练策略:模型优化的目标函数由两部分组成:
-
标准的分割损失
L_seg,用于监督像素级的变化预测。 -
双向视觉-文本对比损失
L_cot,用于对齐视觉和文本特征。该损失通过拉近匹配的图文对特征、推远不匹配的图文对特征,迫使模型学习跨模态的语义一致性。其核心公式为:
-
-
三、 实验验证与效果
-
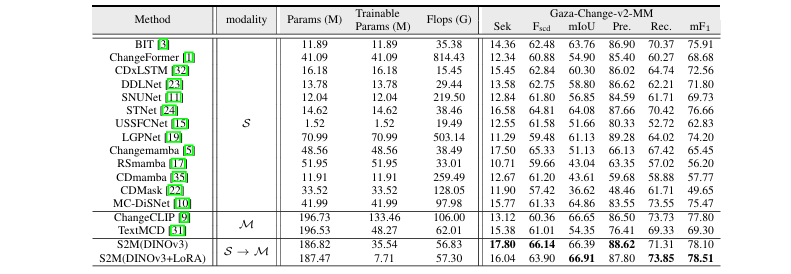
主实验对比:该方法在三个数据集上进行了评估:新建的Gaza-Change-v2、LEVIR-CD和WHU-CD。在核心的Gaza-Change-v2多分类任务上(参见 表2),S2M方法显著优于所有基线模型,包括基于大模型的多模态方法。其
Sek指标达到17.80%,Fscd达到66.14%,性能全面领先。在LEVIR-CD和WHU-CD二元变化检测任务上,同样取得了SOTA或有竞争力的结果。
-
深入分析:
-
消融实验:论文通过 ablation study 验证了文本信息的有效性。如 表4 所示,为多个基线模型加入S2M生成的文本信息后,其召回率(Recall)和综合指标(mF1, mIoU)均有显著提升,证明了文本信息能有效减少漏检。
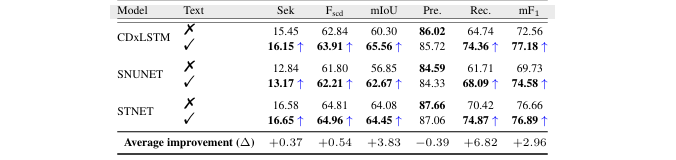
表4
-
属性分析:表5 对“位置、类别、类型、数量”四个文本属性进行了组合消融,分析了不同属性组合对模型性能的影响,结果表明不同属性间存在互补和权衡关系。
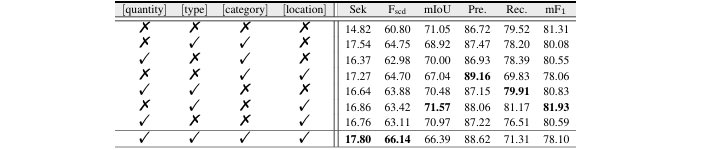
表5
-
可视化分析:图5 的定性比较结果显示,S2M方法能够更完整地检测出微小变化目标,并且在面对视觉上易混淆的场景时,产生的误报(红色区域)明显少于其他方法。
-
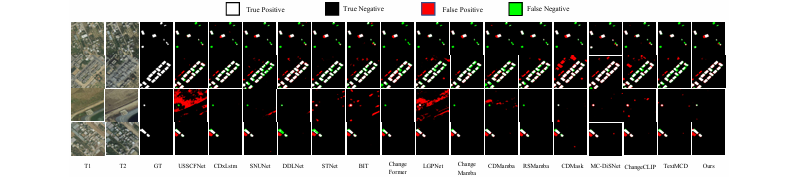
图5
-
结论与价值:论文的主要贡献是提出了S2M框架,它首次证明了可以零成本地从现有掩码标签中提取高质量的结构化文本,从而将单模态数据“升级”为多模态数据。该方法有效解决了遥感变化检测中的类间相似性难题,且其原理可以推广到任何带有类别标注的变化检测数据集中。
四、小编总结
这篇论文的核心思想非常巧妙,它没有像常规方法那样寻求外部数据(如引入大模型或进行新标注),而是“向内求”,挖掘了现有数据中被忽视的价值。其提出的S2M框架,本质上是为变化检测掩码(Mask)赋予了“说话”的能力,将隐性的、结构化的语义信息显式化为文本。通过一个双向对比学习的训练范式,模型成功地利用这些“免费”的文本来指导视觉特征的学习,有效区分了那些“看起来一样,但意义不同”的变化。这种“零成本、高性能”的理念,为资源受限场景下的多模态研究提供了极具启发性的新思路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)