REMOTE SENSING-ORIENTED WORLD MODEL
ABSTRACT
世界模型通过预测和推理直接观测之外的世界状态,在人工智能领域展现出巨大潜力。然而,现有方法主要在合成环境或受限场景设置中进行评估,限制了其在具有广域空间覆盖和复杂语义的真实世界场景中的验证。与此同时,灾害响应和城市规划等遥感应用迫切需要具备空间推理能力的方法。本文通过提出首个面向遥感领域的世界建模框架,弥合了上述差距。我们将遥感世界建模形式化为方向条件下的空间外推任务,即模型在给定中心观测图像块和方向指令的条件下,生成语义一致的相邻图像块。为实现严格评估,我们构建了 RSWISE(Remote Sensing World-Image Spatial Evaluation)基准数据集,包含四类场景下的 1,600 个评估任务:通用场景、洪水场景、城市场景和乡村场景。RSWISE 将视觉保真度评估与基于 GPT-4o 的指令遵循能力评估相结合,并将 GPT-4o 作为语义评判器,以确保模型真正执行空间推理,而不是简单复制输入内容。随后,我们提出了 RemoteBAGEL,这是一个在遥感数据上针对空间外推任务进行微调的统一多模态模型。大量实验结果表明,RemoteBAGEL 在 RSWISE 基准上持续优于现有最先进的基线方法。
1 INTRODUCTION
世界模型已成为人工智能领域的前沿方向,并在机器人导航(Wu et al., 2023)和自动驾驶(Guan et al., 2025)等多种应用中展现出潜力。这类模型旨在从有限观测中学习环境的压缩潜在表示,并通过在该潜在空间中模拟底层动态过程,对未观测到的状态进行预测或推理(Ding et al., 2025)。然而,目前大多数世界模型研究仍局限于合成模拟器或受限场景设置。合成环境缺乏真实环境中的复杂性和不确定性,而受限场景设置则难以体现对大尺度空间结构的推理能力。因此,现有世界模型在真实世界空间推理任务中的有效性在很大程度上仍未得到充分验证。
遥感为世界模型提供了一个独特而强大的测试平台。卫星和航空影像天然编码了“世界级”结构,例如城市道路网络(Yu & Fang, 2023)、河流系统(Tomsett & Leyland, 2019)、农业镶嵌景观(Khanal et al., 2020)以及森林景观(Fassnacht et al., 2024)。与此同时,一些具有重要影响的应用场景——包括面向灾害响应的洪水预测(Nguyen et al., 2024)以及城市规划中的基础设施预测(Wellmann et al., 2020)——都需要对直接观测区域之外的空间进行推理。然而,当前大量遥感研究主要集中在分类(Li et al., 2022;Temenos et al., 2023)和语义分割(Sun et al., 2020;Zhang et al., 2023)等识别任务上,使得世界建模在该领域中的潜力尚未得到充分探索。
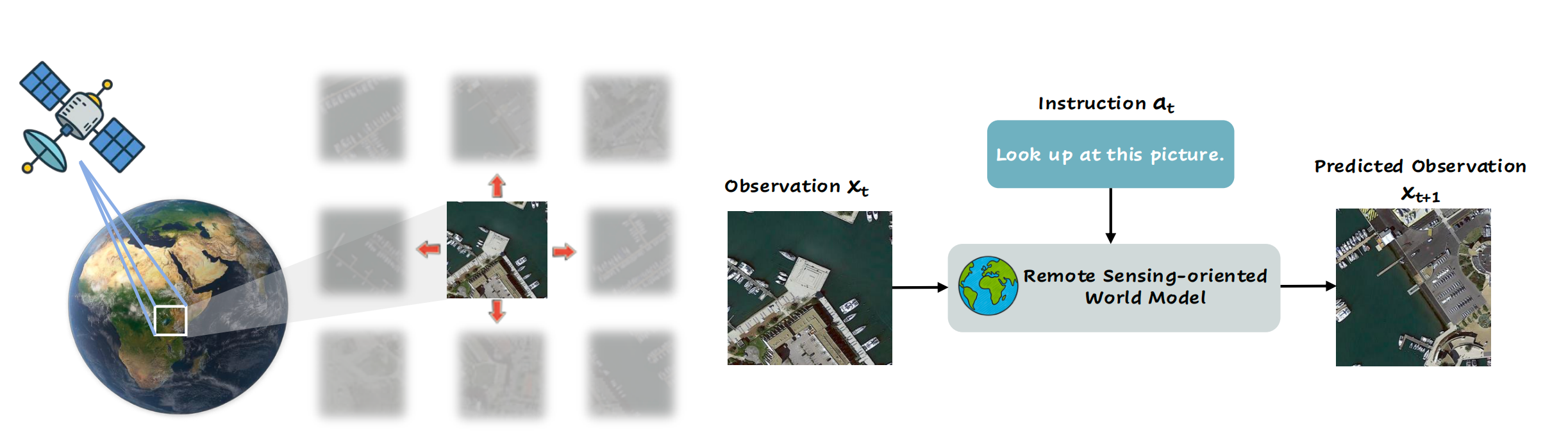
本文通过提出首个面向遥感领域的世界建模框架,弥合了上述差距。我们将遥感世界建模形式化为方向条件下的空间外推任务(该方向定义在图像网格坐标系中,包括上、下、左、右,而不是地理意义上的东、南、西、北等基准方向)。在该任务中,模型在给定中心观测图像块和方向指令的条件下,需要生成语义一致的相邻图像块。如图 1 所示,这一任务形式将空间转移过程明确建模为一种下一状态预测任务,要求模型对未观测到的世界结构进行推理。
然而,将世界模型引入遥感领域面临一个根本性的评估挑战,这一挑战源于现有评估范式的局限性。当前评估方法在两类不同的失效模式上存在关键的方法学缺陷。一方面,分布保真度指标,例如 Frechet Inception Distance(FID)(Heusel et al., 2017),能够衡量生成结果在统计意义上的真实感,但忽略了生成图像块是否遵循空间方向指令。因此,模型可能通过复制输入图像,或者生成视觉上合理但空间上不连贯的图像,获得具有误导性的较低 FID 分数。另一方面,基于大语言模型的语义评估方法,例如 World Knowledge-Informed Semantic Evaluation(WISE)(Niu et al., 2025),能够捕捉模型对指令语义的遵循情况,但缺乏对分布真实感的定量约束,因此难以检测细粒度问题,例如空间不连续或纹理不匹配等。
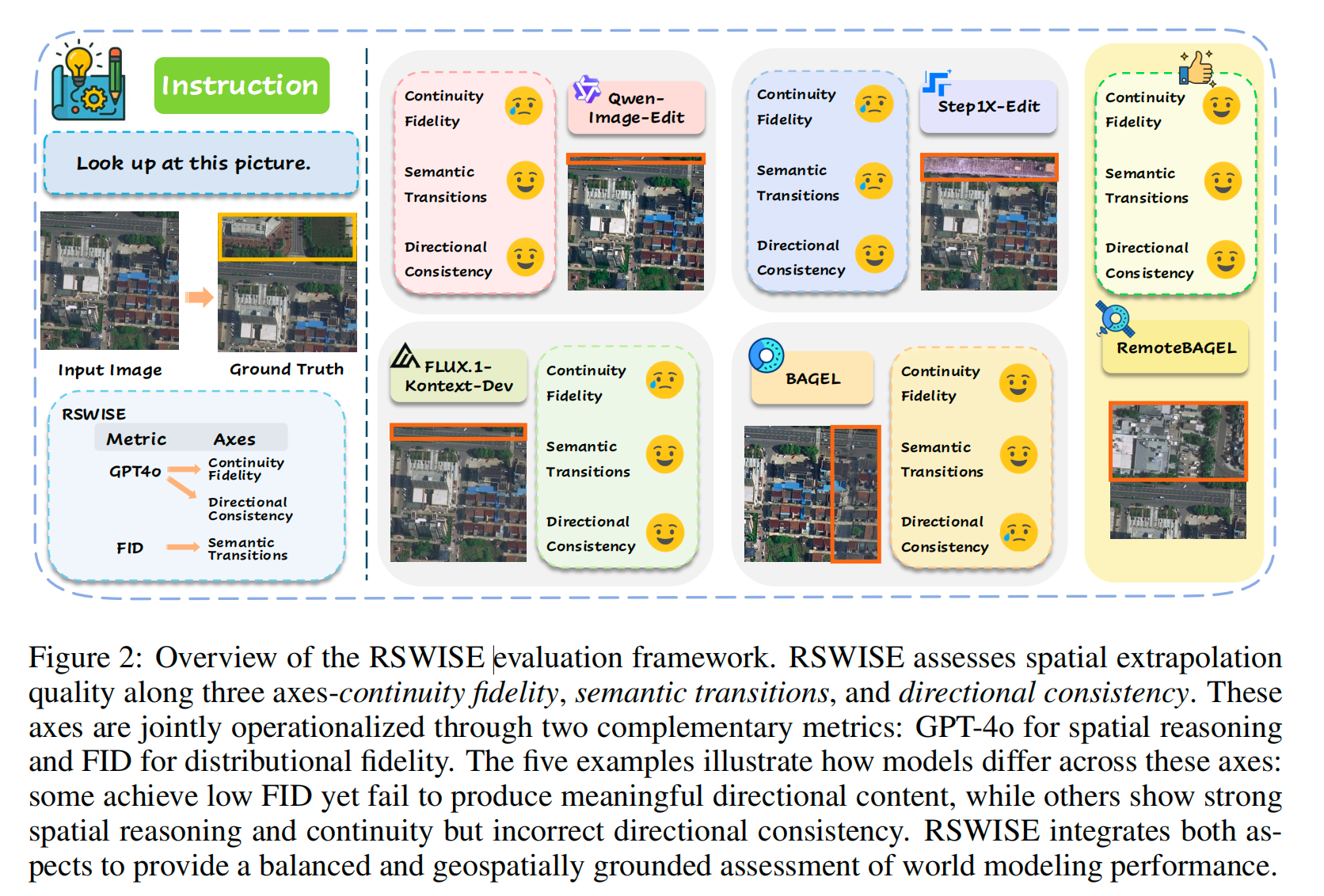
为克服这些局限性,我们提出了 RSWISE(Remote Sensing World-Image Spatial Evaluation),这是首个专门面向遥感世界模型设计的评估框架。RSWISE 通过一种双维度评估方法,将分布保真度与空间推理一致性结合起来。具体而言,RSWISE 使用 FID 来确保生成结果符合真实世界卫星影像的统计分布特征,同时利用 GPT-4o 评估生成的图像块是否能够呈现出新的、但在地理上合理的区域,并且与方向提示保持一致。如图 2 所示,相比单独使用 FID,RSWISE 能够更好地反映生成结果的地理空间对齐程度,从而为模型之间的公平比较和后续进展跟踪提供更加规范的评估基础。
基于 BAGEL(Deng et al., 2025)这一面向生成与理解的统一多模态模型,我们提出了 RemoteBAGEL,这是首个专门为方向条件空间外推任务设计的遥感世界模型。
与以往方法可能生成视觉上合理但空间上不一致的补全结果不同,RemoteBAGEL 显式地将生成过程与空间推理约束相结合。它主要由两个组成部分构成:
-
基于轨迹的数据构建流程:将原始卫星影像转换为带有方向指令的连续生成任务;
-
重建驱动的训练框架:在空间外推过程中强化地理连续性和语义一致性。
大量实验结果表明,RemoteBAGEL 在 RSWISE 基准上持续优于现有最先进的基线方法。
总之,本文的贡献主要包括以下三点:
-
我们提出了一种新的遥感世界建模问题定义,即将其形式化为方向条件下的空间外推任务;
-
我们提出了 RSWISE,这是首个综合性评估框架,包含双维度评价指标,并构建了覆盖四类代表性场景的 1,600 个评估任务基准;
-
我们开发了 RemoteBAGEL,这是首个专门面向遥感空间推理任务的世界模型,并取得了当前最先进的性能。
2 RELATED WORK
2.1 WORLD MODELS AND BENCHMARKS
世界模型通常可以从两个视角进行划分:一类模型旨在通过抽象世界的底层机制来理解世界;另一类模型则旨在通过模拟环境可能的演化过程来预测未来(Ding et al., 2025)。早期工作如 World Models(Ha & Schmidhuber, 2018)主要关注对外部世界进行抽象,以深入理解其底层机制;随后,PlaNet(Hafner et al., 2019)以及 Dreamer 系列工作(Hafner et al., 2020; 2022)引入了循环状态空间模型(Recurrent State-Space Models, RSSMs),用于支持完全在潜在空间中的前向预测。近年来的研究进一步将这一思想扩展到生成建模领域:例如,基于 Transformer 的模型 TransDreamer(Chen et al., 2024)和 Genie(Bruce et al., 2024);用于场景外推和可控驾驶的扩散模型及 VAE 驱动方法(Wang et al., 2025; Cai et al., 2023);以及 JEPA 系列方法(Assran et al., 2023),该系列将世界模型重新定义为自监督的抽象表示学习器。
除了这些面向特定任务的设计之外,新兴的统一多模态模型(Unified Multimodal Models, UMMs),例如 BAGEL(Deng et al., 2025)和 Qwen-Image-Edit(Wu et al., 2025),展现出同时支持感知与生成的能力。其中,感知指模型能够理解输入图像和方向指令,生成则指模型能够合成新的图像块。这种统一理解与生成的内在能力,包括学习输入的压缩表示、推理并生成新的状态,使得 UMMs 具备成为潜在基础世界模型的可能性。它们能够自然地处理多模态输入和复杂生成任务,从而避免了对多个独立模块化组件的依赖。本文探讨了当这类统一架构被扩展到遥感领域的空间推理与世界建模任务时,其具体表现如何。
尽管世界模型研究呈现出多样化发展,但评估仍然是一个核心挑战。现有基准,例如 VBench(Ji et al., 2024)、ChronoMagic-Bench(Yuan et al., 2024)、TC-Bench(Feng et al., 2024)和 WorldModelBench(Li et al., 2025),主要关注受控场景或合成场景设置,并未在真实世界背景下明确涉及遥感尺度上的空间连续性或地理空间语义。这一空白使得当前评估难以检验世界模型在真实世界结构上的推理能力,例如河流、道路或城乡过渡等空间结构。如表 1 所总结,这也限制了现有基准对遥感场景中世界建模能力的全面评估。
2.2 REMOTE SENSING MODELS
遥感(Remote Sensing, RS)通过卫星和航空平台获取地球观测数据,生成的影像能够编码不同环境中的光谱变化和大尺度空间结构(Li et al., 2019)。传统上,大量遥感研究主要集中在面向识别的任务上,包括土地覆盖分类和语义分割(Sun et al., 2020;Zhang et al., 2023)。尽管近年来已经出现了大规模遥感基础模型,例如 SkySense(Guo et al., 2024)和 SpectralGPT(Hong et al., 2024),它们在学习可迁移表征方面表现出色,但这些方法很少尝试进行空间延续,或对大尺度地理空间结构进行推理。然而,生成式人工智能正在成为遥感领域的一个新兴方向,其中扩散模型已被应用于超分辨率、去云以及基于元数据条件的图像合成等任务(Huang et al., 2025)。
在这些生成式方法中,包括 Text2Earth(Liu et al., 2025a)和 EMRDM(Liu et al., 2025c),研究重点仍主要局限于图像块内部的图像合成或修复,而不是对地表潜在结构进行建模,或预测未观测到的世界状态。因此,我们将世界建模作为遥感领域的一种新范式进行探索,并提出 RemoteBAGEL,以显式地将统一多模态生成能力与地球观测数据中固有的空间推理需求结合起来。
3 THE RSWISE BENCHMARK
设计概述。 RSWISE 的目标是为遥感世界模型提供一个综合性的评估框架,直接应对地理空间场景中的空间推理挑战。该框架主要由三个部分构成:
- 方向性空间外推的统一任务定义;
- 覆盖多种条件的多场景数据集;
- 双维度评价指标,用于联合评估生成结果的保真度与空间推理能力。
3.1 SPATIAL CONTINUATION SPECIFICATION

评价维度。 为了刻画空间外推任务的复杂性,RSWISE 定义了三个互补的评价维度:
- 连续性保真度:要求生成的图像块能够在边界处延续地理结构,例如道路、河流、植被斑块等;
- 语义过渡合理性:要求模型能够在异质区域之间生成合理的变化,例如从城市到乡村、从陆地到水域等;
- 方向一致性:要求生成结果严格遵循给定的方向指令。
这些评价维度能够确保评估不再仅仅关注图像是否“看起来真实”,而是直接考察模型的空间推理能力。
3.2 DATASET CURATION
该基准数据集包含 1,600 个经过筛选的评估样本,均匀分布在四类场景中:通用场景、洪水场景、城市场景和乡村场景。数据来源于三个公开数据集:用于通用场景的 Sky-SA(Zhu et al., 2025)、用于洪水事件的 FloodNet(Rahnemoonfar et al., 2021),以及用于城市和乡村景观的 LoveDA(Wang et al., 2021)。
尽管该基准构建自三个公开数据集,但最终形成的数据集具有显著的多样性:它涵盖了多个城市和地理上不同区域采集的影像,覆盖了从超高分辨率无人机影像(约 1.5 cm GSD)到 0.3 m GSD 卫星影像的广泛空间分辨率范围,并包含超过 1,700 个不同语义类别,涉及多种土地覆盖类型。这些特征确保 RSWISE 能够在多样化的地理空间结构下评估空间外推能力,而不是局限于狭窄或特定数据集的分布。
地理空间场景分类:
-
General 通用场景:包括山地、森林、海岸线和混合地形等多样化景观,用作跨不同地形条件的基础评估场景。
-
Flood 洪水场景:面向灾害响应场景,包含被淹没区域和受扰动的土地覆盖,用于测试模型在动态环境扰动下的鲁棒性。
-
Urban 城市场景:包含密集建成环境、道路网络和建筑布局,用于挑战模型对结构化空间模式的推理能力。
-
Rural 乡村场景:包含农业区域、自然植被以及空间分布较规则或半规则的乡村景观,用于评估模型在自然和农业空间模式中的一致性。
对于每一类场景,大幅卫星影像会被划分为 3 × 3 的重叠图像块网格。其中,每个图像块在水平方向和垂直方向上与其相邻图像块约有 66.7% 的重叠区域,以确保边界一致性并保留空间自相关性。随后,将起始图像块与其四个方向上的相邻图像块进行配对,即上、下、左、右方向,从而形成评估三元组。方向指令被统一为固定提示语,例如:
“Look at what is below this picture”
“查看这张图像下方的内容”
这样可以保证不同模型之间的评估公平性。数据筛选标准包括云层覆盖阈值、分辨率一致性以及时间对齐等因素。最后,通过一个质量保证流程生成每个类别 400 个评估样本。该流程结合了自动化伪影检测、人工地理一致性检查以及均衡采样,以确保数据质量和场景分布的合理性。
3.3 RSWISE EVALUATION METRICS
三个评价维度——连续性保真度、语义过渡合理性和方向一致性——规定了空间外推任务应从哪些概念层面进行评估。因此,在 RSWISE 中,这些概念维度被进一步落实为两个互补的评价指标:分布保真度和空间推理能力。其中,分布保真度用于衡量生成图像块与真实卫星影像统计特征之间的一致性;空间推理能力则用于评估生成图像块是否遵循指定的外推方向。这些指标为上述概念框架提供了具体的实现方式,确保模型的真实性和推理能力能够被联合评估。
分布保真度。
我们采用 FID 来量化生成图像块与真实卫星影像统计特征之间的匹配程度。对于遥感应用而言,FID 能够反映生成内容是否符合特定场景下的地理分布特征,例如城市密度、植被覆盖或地形模式。为了便于综合评分,FID 值被全局归一化为:同时对该指标进行反向处理,使得数值越高代表性能越好。这一变换保证了不同场景之间的可比性,并使其能够与基于推理的评分无缝结合。
空间推理。
我们使用 GPT-4o 作为外部评估器,判断生成图像块是否体现了沿指定方向的有效空间外推。有效的生成结果包括地理特征的连续延伸,例如河流、道路、山脊的延续;合理的土地利用过渡,例如从城市到郊区、从森林到农业区域;以及自然边界的渐进变化,例如海岸线、流域分界线等。
评估器会根据空间连贯性、方向准确性和地理合理性,在 ([0, 10]) 范围内进行评分,随后将其归一化为:该指标会显式惩罚那些只是复制输入纹理、而没有生成新的且方向一致内容的模型。
RSWISE 综合评分。
最终评分通过加权求和的方式,将分布保真度和空间推理能力结合起来:
其中,(m) 表示模型,(s) 表示场景。我们为空间推理能力分配更高权重,同时保留分布保真度作为生成结果真实性的约束。RSWISE 默认采用一种具有代表性的权重设置。关于权重方案的详细验证和敏感性分析,请参见附录 C。
4 REMOTE SENSING-ORIENTED WORLD MODEL
我们提出了 RemoteBAGEL,这是一种遥感世界模型,能够通过动作条件下的图像块补全实现方向条件空间外推。我们的方法包含两个主要组成部分:
- 基于轨迹的数据构建流程:将未标注的卫星影像转换为动作条件下的连续生成任务;
- 以重建为核心的训练目标与模型架构:使模型能够进行可控的空间外推。
我们首先介绍动作条件下的任务形式化定义,随后详细说明训练方法和模型架构概述。
4.1 ARCHITECTURE OVERVIEW
如图 4(c) 所示,我们的架构采用了一种统一的生成框架。其中,输入图像块首先通过视觉编码器进行特征提取,而方向动作则被转换到一个可学习的嵌入空间中。随后,这两类表示通过跨模态注意力和自注意力机制进行融合,以捕捉空间语义依赖关系。融合后的特征进一步输入生成式解码器,用于合成指定方向上的地理相邻图像块。这种条件控制范式能够对空间外推过程进行精确的方向控制,同时保持源图像中固有的结构连续性和语义一致性。
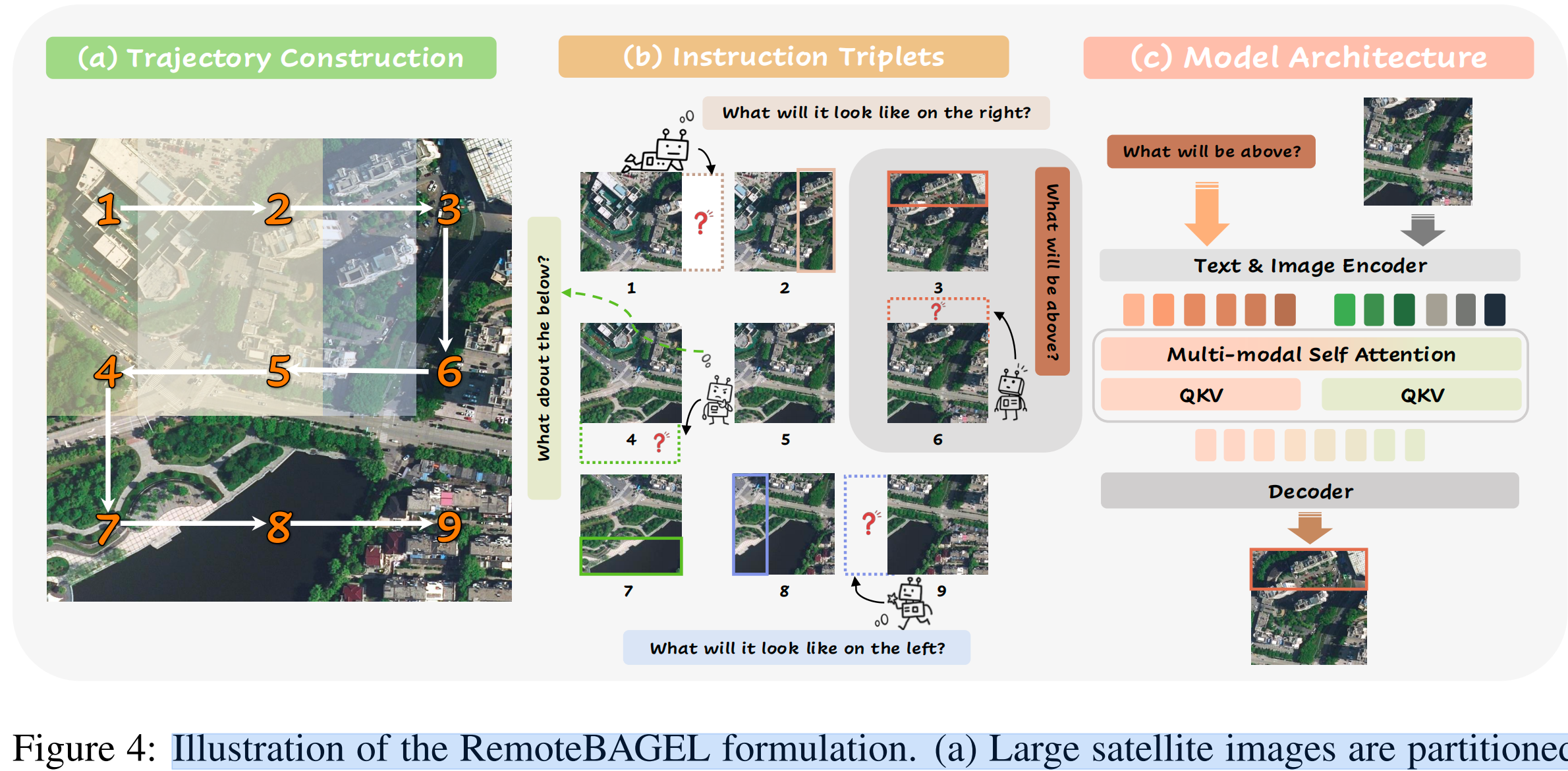
4.2 ACTION-CONDITIONED DATA CONSTRUCTION

4.3 ACTION-CONDITIONED TRAINING

5 EXPERIMENT AND RESULTS
5.1 EXPERIMENTAL SETTING
实现细节。 我们在 10,080 个动作条件训练样本上对 BAGEL-7B 进行微调,使用 (4 \times) H100(80GB)GPU,训练时间约为 20 小时。为了保证公平比较,所有五个模型在完整的 1,600 个基准测试任务上的推理均采用严格的 zero-shot 设置。整个评估过程共计约 8,000 次运行,使用 (10 \times) A100(80GB)GPU,计算时间约为 8 小时。
5.2 MAIN RESULTS
我们的评估结果显示,在所测试的模型之间存在清晰的性能层级。RemoteBAGEL 在四个基准场景中均显著优于所有基线模型,并在通用场景和乡村场景中取得了接近最优的分数(约 95 分)。尽管 BAGEL 本身具有较强的多模态基础能力,但 RemoteBAGEL 相比 BAGEL(58–64 分)仍实现了显著提升。这一性能差距表明,面向特定领域的适配对于遥感任务至关重要,因为通用视觉语言模型难以充分捕捉卫星影像中固有的空间连贯性和结构模式。此外,分布外测试(Out-of-Distribution, OOD)进一步表明,RemoteBAGEL 在未见过的飓风场景中也具备较强的泛化能力,详细结果见附录 G。
5.3 RESULT ANALYSIS
失效模式分析。 图 5 中的定性分析揭示了不同类别模型存在的不同失效模式。虽然 BAGEL 能够生成视觉上较为合理的结果,但它有时会违反空间一致性,例如生成错误的方向,或者忽略几何结构规律。不过,与其他基线方法相比,BAGEL 仍然展现出一定的空间推理潜力。值得注意的是,尽管一些基线方法同样采用了统一架构,但它们未能有效地将冻结的大语言模型(LLM)骨干网络中的常识知识传递到视觉生成过程中。因此,这些方法主要表现得像是“外观编辑器”,生成的结果往往只是模仿输入图像的纹理,而缺乏真正的空间外推能力。BAGEL 通过更好的多模态对齐,在一定程度上缓解了这一问题,但由于缺乏遥感领域的专门约束与地理空间知识支撑,它仍然存在不足。具体而言,它难以将抽象的方向 token 映射到卫星影像中复杂的空间语义结构。相比之下,RemoteBAGEL 的优越性能表明,我们的微调策略成功弥合了这一差距。该策略使模型能够内化地理空间先验,并将基础模型本身具备的推理能力有效迁移到方向感知的空间世界建模任务中。
视觉保真度分析。图 6(a) 比较了 BAGEL 和 RemoteBAGEL 在四类场景中的 FID 分布。RemoteBAGEL 在所有设置下都表现出更优的视觉保真度,体现为更低的 FID 分数和更小的方差。不过,不同场景中的提升幅度存在明显差异。在通用场景和乡村场景中,提升最为显著,FID 降幅超过 20%。这主要是因为重复性的农业模式和较为均质的纹理能够从遥感领域特定训练中获得明显收益。城市场景中,RemoteBAGEL 也取得了中等但稳定的提升。道路和建筑等几何规则结构为模型提供了较强的空间线索,但较高的方差也表明,模型在捕捉细粒度城市多样性方面仍然面临挑战。洪水场景对两个模型而言都是最具挑战性的,其改进幅度最小。这是因为洪水边界往往不规则且动态变化,难以通过系统性的模式学习进行准确建模。这些结果表明,相比高度变化或短暂存在的现象,具有结构化特征和丰富重复模式的环境更适合生成式建模。
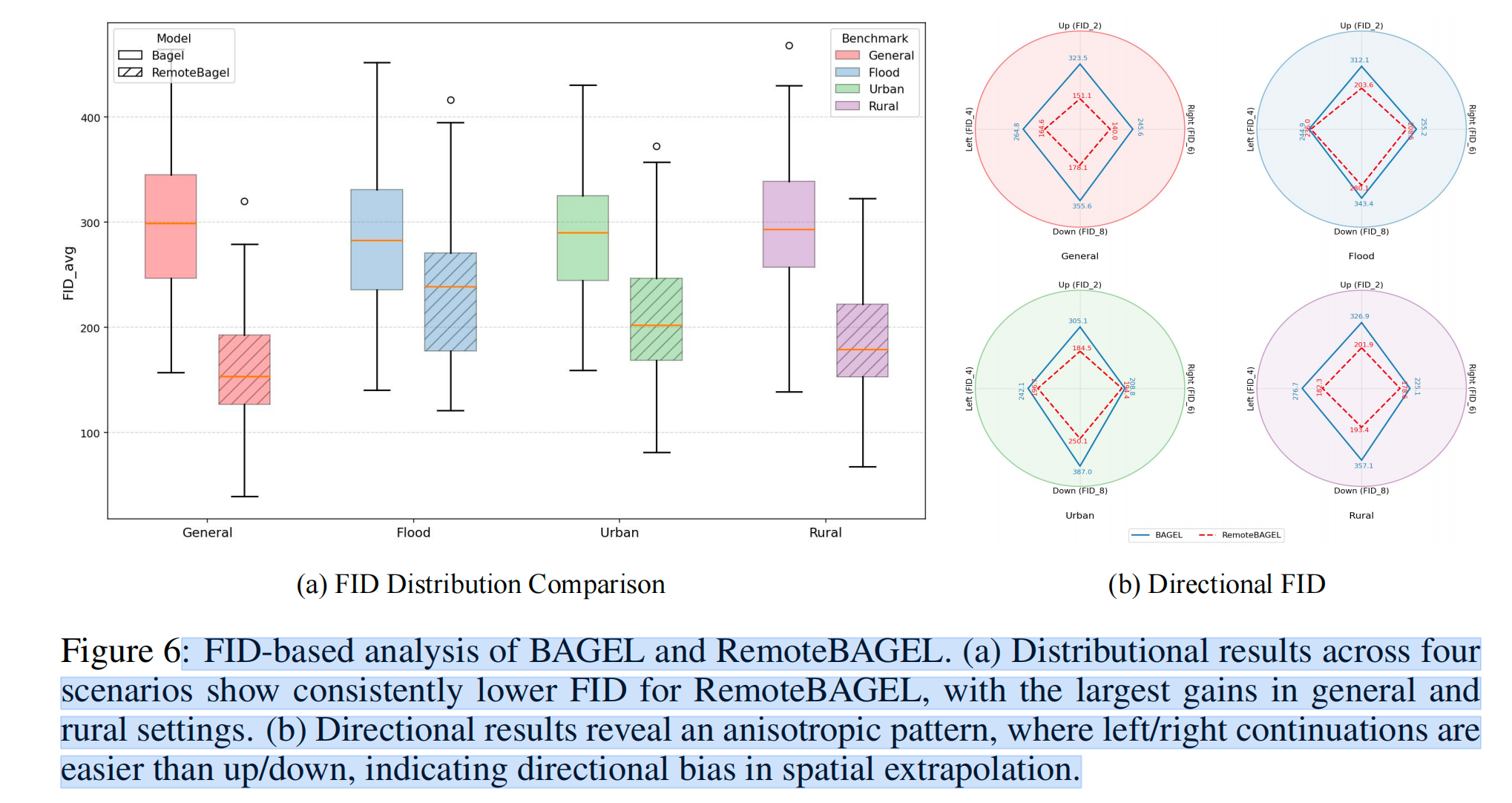
方向延续分析。图 6(b) 展示了一种各向异性的性能模式,即水平方向的空间延续效果始终优于垂直方向。我们认为,这种不对称性来自物理成像因素与模型归纳偏置之间的共同作用。从物理因素来看,太阳方位角的变化以及卫星的极轨运行路径,会在垂直轴方向上引入更大的辐射和几何不一致性,使得垂直方向的外推目标天然比水平方向更难预测;相比之下,水平方向上的光照条件通常更加稳定。从模型角度来看,这种各向异性可能反映了预训练大语言模型骨干网络中空间先验分布的不均衡。在通用多模态语料中,水平方向关系,例如阅读顺序、全景布局等,通常比垂直方向关系具有更强的连续性和更明确的逻辑联系。因此,left/right 方向 token 可能比 up/down 方向 token 更容易激活模型内部更稳健的空间推理模式。这种由遥感领域本身带来的困难因素,例如光照和卫星轨道影响,与模型层面的归纳偏置,例如较弱的垂直方向先验,共同导致了图中观察到的性能差距。
5.4 ABLATION STUDIES
我们通过受控消融实验验证了关键设计选择的有效性,详细结果见附录 F。表 3 的结果突出体现了三点发现:
提示语形式。图像网格对齐的方向指令,例如 “up/down”,显著优于地理方位指令,例如 “north/south”。与图像相对坐标相比,模型对地理方向术语的响应较弱,难以准确执行具体的方向命令。
空间重叠。较高的空间重叠比例,即 66.7%,对于保持地理空间一致性至关重要。降低重叠比例会在推理过程中破坏边界连续性,同时也会阻碍模型在训练阶段学习有效的跨边界空间转移模式。
方向条件。显式的方向 token 是必要的。去除方向 token 后,模型性能大幅下降至 58.7,导致生成结果趋于随机,模型无法根据指令明确生成对应方向上的内容。
5.5 VALIDITY OF GPT-BASED EVALUATION
我们通过两项研究验证了GPT-4o指标的科学严谨性:多轮运行稳定性(平均标准差0.026)和人工一致性(Spearman ρ =0.72)。这些结果证实了基于GPT的指标是一种可靠且与专家标准一致的语义评估工具,对于区分真正的空间推理与视觉抄袭至关重要。详细统计数据见附录E。
5.6 MULTI-STEP EXTRAPOLATION
图 7 展示了模型在连续多步空间外推下的性能表现。RemoteBAGEL 在早期步骤,例如 Step 1,中能够与真实结果(GT)保持较高的视觉一致性和结构一致性。然而,随着外推过程继续进行,例如 Step 3–4,生成结果中开始出现明显漂移:边界变得模糊,纹理出现重复,几何结构也逐渐发生扭曲。这种性能退化主要源于累积误差传播。在每一步外推中,模型都会以上一步自己生成的结果作为新的条件输入,因此早期生成中的微小局部偏差会随着步骤增加而不断放大,最终导致生成结果逐渐偏离真实的空间布局。此外,连续多步生成过程中缺乏全局约束,也进一步削弱了长距离空间一致性,造成结构不一致问题不断累积。总体而言,RemoteBAGEL 具有较强的短距离空间延续能力,但在长距离递归生成中仍受到误差累积和上下文漂移的限制。

6 CONCLUSION
本研究首次提出了遥感领域的世界模型构建框架。我们将方向条件空间外推定义为一项创新任务,建立了采用双维度评估的 RSWISE 基准,并开发了RemoteBAGEL模型——该模型在空间推理任务中实现了业界领先性能。研究结果表明,世界模型能够以兼具语义一致性和分布一致性的方式,精准捕捉遥感数据中的大规模地理空间结构。相关未来应用及潜在影响详见附录H。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)