周志华-《机器学习》
第一章 绪论
总体介绍了机器学习的概念与过程。重点有在于对归纳偏好的理解:
归纳偏好:就是机器对某类假设的偏好,在输出此类结果时,模型会得到“奖励”,进而不断学习进化。而在比较两种不同算法的误差时,作者引入了“没有免费午餐”定理(NFL定理)。定理的结论可理解为,不同算法的期望性能是相同的,总误差与学习算法无关!但这一结论是在理想前提下,即所有问题出现的概率相同的前提下进行的数学证明,和实际情况有很大差异。因此,NFL定理的启发在于让我们认识到,只谈论什么样的算法更高级没有意义,重点在于结合实际问题,关注算法与问题是否相匹配。
补充:对NFL定理的通俗理解
假设我们有一个学习任务,比如分类任务,我们希望找到一个最优的机器学习算法。如果我们对所有可能的数据分布进行考虑,那么:
- 对于某些数据分布,某种算法可能表现很好(比如深度神经网络在大规模图像分类任务上表现出色)。
- 但是对于另一些数据分布,另一种算法可能更优(比如决策树在某些结构化数据上的表现可能优于深度学习)。
- 如果考虑所有可能的任务,那么所有算法的表现在整体上是一样的,因为没有哪种方法能够在所有情况下都超越其他方法。
第二章 模型评估与选择
2.1 经验误差与过拟合
错误率 E=a/m (m为样本数,有a个样本错误) 精度=1-错误率
过拟合:过于严格,必须完全符合标准(没拒斥就不算树叶)
欠拟合:过于宽泛,有一点相似就认为符合标准(只要是绿色的就是树叶)
过拟合一般是由于机器学习能力过强引起的,欠拟合则相反,且欠拟合往往更容易克服。
2.2 评估方法
设定总数据集D,训练集S和测试集T,常见的有三种方法:
2.2.1 留出法
将数据集D分为S,T,S,T无重合,用S作训练,T做测试
2.2.2 交叉验证法
将数据集D平均分为k给互斥子集(D1,D2……,Dk),每次采用k-1个子集作为训练集,剩下的1个做训练,总共可测试k次,最终取k此测验后的平均值。
2.2.3 自助法
设D共包含m个样本,每次随机挑选样本后放回,可重复选取,重复执行m次。求样本在m此采样过程中不会被采到的概率为(1-1/m)^m,m趋于正无穷时该值趋于1/e
再用这三种测试方法测试后,还需要进行参数调节,选择最好的算法。选择之后还需对模型进行评判,评判标准即为性能度量。性能度量包括上文提到的错误率和精度。除了错误率和精度之外,还有用来处理二分类问题的查准率和查全率,数学定义如图所示
这两者可通俗理解为:
-
查全率:所有“真的目标”,被你找到的比例(有没有漏网之鱼?)
-
查准率:你找到的“目标”,真的是目标的比例(有没有误报?)
为了平衡模型“找全”和“找准”二者间的关系,做出了P-R曲线图,横轴是查全率(R),纵轴是查准率(P)。PR曲线图可以直观地反映两种学习器性能的关系,通常来讲,曲线越“靠右上”,模型越好。最理想情况是曲线直接走到右上角(R=100%,P=100%),现实中不可能,但曲线越靠近右上角,说明模型在“找全”和“找准”之间平衡得越好。若一个学习器A的P-R曲线被另一个学习器B的P-R曲线完全包住,则称:B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。但曲线下的面积是很难进行估算的,所以衍生出了“平衡点”,即当P=R时的取值,平衡点的取值越高,性能更优。
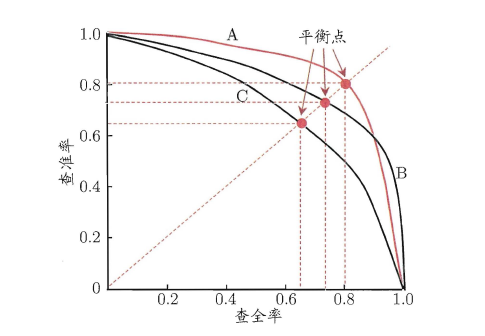
2.3.3 ROC与AUC
ROC与AUC为两个类型的曲线
ROC 曲线是一个以假阳性率(FPR)为横轴、真阳性率(TPR)为纵轴的曲线图。
-
横轴 FPR(False Positive Rate)
FPR=FPFP+TNFPR=FP+TNFP表示在所有真实为负类的样本中,被模型错判成正类的比例。
-
纵轴 TPR(True Positive Rate,也叫召回率、灵敏度)
TPR=TPTP+FNTPR=TP+FNTP - 读取方法则为:曲线越贴近左上角,说明 TPR 高而 FPR 低,模型越好。若曲线贴着对角线(从 (0,0) 到 (1,1)),则相当于随机猜测。
而AUC就是 ROC 曲线下方的面积
代价敏感错误率与代价曲线
上面的方法中,将学习器的犯错同等对待,但在现实生活中,将正例预测成假例与将假例预测成正例的代价常常是不一样的。以二分类为例,由此引入了“代价矩阵”(cost matrix)。
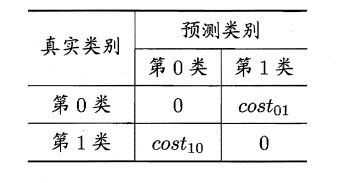
在非均等错误代价下,我们希望的是最小化“总体代价”,这样“代价敏感”的错误率为:
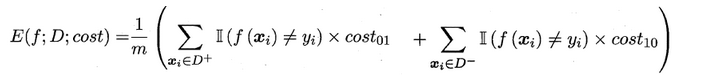
同样对于ROC曲线,在非均等错误代价下,演变成了“代价曲线”,代价曲线横轴是取值在[0,1]之间的正例概率代价,式中p表示正例的概率,纵轴是取值为[0,1]的归一化代价。
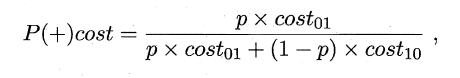
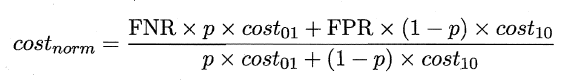
代价曲线的绘制很简单:设ROC曲线上一点的坐标为(TPR,FPR) ,则可相应计算出FNR,然后在代价平面上绘制一条从(0,FPR) 到(1,FNR) 的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC 曲线土的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价,如图所示:
第九章 聚类
9.1 聚类任务
聚类的本质是将一组样本划分为若干簇,使得簇内样本尽可能相似,而簇间样本尽可能不同,是一种无监督的学习方法。第一节引入了聚类的概念,可以举个例子来理解。
举例理解:假设有一项旨在评估新治疗方案的患者研究。在研究期间,患者会报告他们每周出现症状的次数以及症状的严重程度。研究人员可以使用聚类分析将具有类似治疗响应的患者划分到不同的群组。图 1 展示了将模拟数据分组为三个集群的一种可能方式。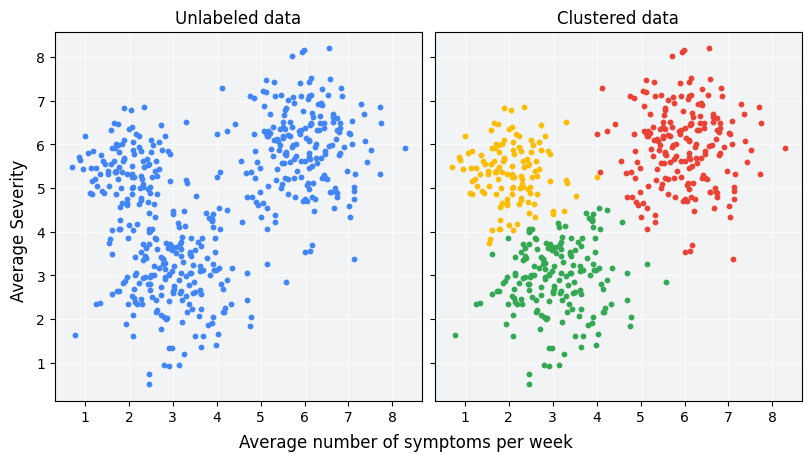
图 1:未标记示例分为三个集群(模拟数据)
9.2 性能度量
一般聚类有两类性能度量指标:外部指标和内部指标。
外部指标:将聚类结果与某个参考模型进行比较
外部指标可理解为再有参考答案的条件下(知道什么样的西瓜是好西瓜,只是没告诉电脑)选择的方法,此时可用其来对比分析
-
JC系数(Jaccard Coefficient):看“两个组重叠的部分”——比如电脑分的组A和真实组B,重叠的样本数越多,JC系数越高(范围0~1,1是完美)。
-
FM指数(Fowlkes-Mallows Index):调和平均JC系数的“重叠比例”——比如组A和B的重叠样本数,除以“组A独有的样本数+组B独有的样本数”,值越高越好。
-
Rand指数:看“所有样本对的一致性”——比如两个样本在真实组里是一组,在电脑组里也是一组,这样的“一致对”越多,Rand指数越高。
通俗理解外部指标:有10个西瓜,真实组是“好瓜(5个)、坏瓜(5个)”,电脑分成“组1(4个好瓜+1个坏瓜)、组2(1个好瓜+4个坏瓜)”。JC系数是“重叠的好瓜数(4+4?不,是组1和真实好瓜的重叠是4,组2和真实坏瓜的重叠是4)除以(重叠+组1独有的坏瓜+组2独有的好瓜)”——算出来是8/(8+1+1)=0.8,说明分得好。
内部指标:直接考察,不参考其他模型
大多数时候不知道正确答案是什么样的,此时要用内部指标
-
DB指数(Davies-Bouldin Index):看“簇内的紧凑度”和“簇间的分离度”——比如簇内样本的距离越小(越紧凑),簇间中心的距离越大(越分离),DB指数越小,聚类越好。
-
Dunn指数:看“最小的簇间距离”和“最大的簇内距离”——比如两个簇之间的最近样本距离越大,簇内最远样本距离越小,Dunn指数越大,聚类越好。
通俗理解内部指标:电脑把西瓜分成“组1(青绿、蜷缩)”和“组2(浅白、硬挺)”。组1里的西瓜都很像(簇内距离小),组1和组2的西瓜差很多(簇间距离大),DB指数就会很小,说明聚类好。
9.3 距离计算
距离计算是电脑评判聚类后样本的相似性的方法,有如下几种方式
1. 闵可夫斯基距离——最通用距离模板
这是所有距离的基础公式
distmk(xi,xj)=(u=1∑d∣xiu−xju∣p)1/p
-
p=1:曼哈顿距离(Manhattan Distance)------画正方形。
-
p=2:欧氏距离(Euclidean Distance)——直线距离。
2. 余弦距离——只看方向,不看大小
distcos(xi,xj)=1−∣xi∣∣xj∣xiTxj
通俗理解:有两篇文章,一篇是“机器学习入门”,一篇是“机器学习进阶”——它们的词向量长度不同,但方向很像(都在讲机器学习)。这时候用余弦距离
3. 处理非数值属性-VDM距离
如果属性是“无序的”(比如西瓜的“色泽”:青绿、乌黑、浅白;“根蒂”:蜷缩、稍蜷、硬挺),不能直接算欧氏距离(比如“青绿”和“乌黑”差多少?)。这时候用VDM距离(Value Difference Metric)——看“属性值在不同簇中的分布”(暂未完全理解)
9.4 圆形聚类
原型聚类即“基于原型的聚类”(prototype-based clustering),原型表示模板的意思,就是通过参考一个模板向量或模板分布的方式来完成聚类的过程,常见的K-Means便是基于簇中心来实现聚类,混合高斯聚类则是基于簇分布来实现聚类。
核心思想:每个簇有一个“原型”(比如中心、均值),把样本分到“离自己最近的原型”所在的簇。就像你分西瓜时,先想“好瓜的中心特征是青绿+蜷缩”,然后把符合这个特征的西瓜放一起。
1.两个代表算法
代表算法1:k-means(k均值)
步骤:
-
选k个初始中心(算便找几个有代表性的)
-
分配样本:(分析所有剩余样本,看每一个和哪个代表性样本更像,并加入那个组中)
-
更新中心:(取加入新样本后的组的平均值)
-
重复2-3步:(数学递归,直到变为常数)。
代表算法2:DBSCAN——“找高密度区域”
k-means的缺点是“只能分凸簇”,DBSCAN解决了这个问题——它基于密度:簇是“高密度连通区域”(比如一群挤在一起的西瓜,中间没有空隙)。
DBSCAN的核心概念(用“派对”比喻):
-
ε-邻域:一个人周围ε范围内的所有人(比如你周围1米内的人);
-
核心对象:ε-邻域内有足够多的人(比如你周围1米内有5个人,你是“核心人物”);
-
密度直达:核心人物的ε-邻域内的人(比如你是核心,你旁边的小明是密度直达);
-
密度可达:通过核心人物链式传递(比如你是核心→小明是核心→小红是核心,小红就是你密度可达的);
-
密度相连:两个人都能密度可达同一个核心人物(比如你和小明都能密度可达小红,你们就是密度相连的)。
步骤:
-
找所有“核心对象”(比如西瓜中,周围ε范围内有MinPts个西瓜的);
-
从任意一个核心对象出发,把所有“密度可达”的西瓜分成一组;
-
剩下最特殊的无法分组的西瓜就是“噪声”。
优点:不用指定簇数(k-means要你先想“分几组”),能分任意形状的簇(比如环形、弧形的西瓜),还能自动找噪声(最特殊的)。
2. 密度聚类——“不管形状,只管密度”
其实DBSCAN就是密度聚类的代表,刚才已经讲过,这里再总结:适合“簇形状不规则”的场景(比如客户按“消费频率+金额”的分布是环形,k-means分不好,DBSCAN能分对)。
3. 层次聚类
核心思想:找出一个核心对象所有密度可达的样本集合形成簇。
两种方向:
-
凝聚式(自底向上):最常用——一开始每个样本是一个簇,然后合并最像的两个簇,直到所有样本变成一个簇。
-
分裂式(自顶向下):反过来——一开始所有样本是一个簇,然后分裂最不像的部分,直到每个簇只有一个样本。
怎么合并/分裂? 看“簇间距离”:
-
最小距离(Single-Link):两个簇中“最近的两个样本”的距离(比如簇A的西瓜x和簇B的西瓜y最近,就合并A和B)——容易形成“链式簇”(比如A-B-C-D连成一条线)。
-
最大距离(Complete-Link):两个簇中“最远的两个样本”的距离(比如簇A的最远西瓜和簇B的最远西瓜很远,就不合并)——容易形成“紧凑簇”(比如圆形的簇)。
-
平均距离(Average-Link):两个簇中所有样本对的平均距离(比如簇A的3个西瓜和簇B的2个西瓜,算6个距离的平均)——平衡最小和最大距离。
优点:不用指定簇数,而且树状图很直观。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)