大模型入门-应用篇5-亿级向量的快速检索
🚀 揭秘推荐系统与RAG:如何快速完成亿级向量检索?
在现代的推荐系统或 RAG(检索增强生成)业务中,我们不可避免地需要用到 ANN (Approximate Nearest Neighbor,近似最近邻) 检索 。
最简单直接的方法是将用户的 Query 向量与数据库中的每一个向量进行遍历对比,这被称为“暴力计算” 。这种方法精度最高,但效率极低,且面临着非常严峻的存储问题。
让我们算一笔账:假设一个向量用 1024 维的 float32(4字节)表示,那么单个向量的内存占用就是 4 Byte×10244 \text{ Byte} \times 10244 Byte×1024 。如果库里有一千万个向量,所占用的总内存高达:
1000w×4 Byte×1024=38 GB1000w \times 4 \text{ Byte} \times 1024 = 38 \text{ GB}1000w×4 Byte×1024=38 GB
暴力计算通常只适用于对精度要求极高的场景(例如公安系统的人脸搜索)。但在个性化推荐或 RAG 文本召回中,我们需要的是毫秒级的快速且大致精准的检索 。因此,我们急需解决两大痛点:
-
如何快速找到 Top 相近的向量(毫秒级响应)?
-
如何高效地存储海量向量?
本文将深入拆解业界最经典的 ANN 算法之一:IVFPQ。它是倒排索引(Inverted File)与乘积量化(Product Quantization)技术的完美结合 。
一、 倒排索引 (Inverted File - IVF)
在传统的文本搜索(如 Elasticsearch)中,倒排索引的逻辑是:先对句子分词,记录所有词项集合,然后构建倒排列表,记录每个词项出现在哪些文档中(空间换时间) 。
但在向量检索中,IVF (倒排) 的含义是在聚类中心上做一层索引。它的本质是记录向量库中的每个向量属于哪一个聚类簇 。
实现逻辑:直接对库里所有的向量做 KMeans 聚类。假设簇心个数为 1024,就把库中向量划分为 1024 类 。
检索加速:当新的 Query 向量到来时,先计算它与 1024 个簇心的距离,找出距离最近的 Top N 个簇,然后只与这 Top N 个簇里的向量计算距离 。
⚠️ 注意:IVF 仅仅通过“剪枝”减少了计算次数,并没有减少单次距离计算的维度,也没有降低向量的存储空间 。要解决存储问题,我们必须引入 PQ。
二、 乘积量化 (Product Quantization - PQ)
PQ 是解决存储和计算效率的核心利器。它的核心思想是:将全样本的距离计算,转化为到聚类(子空间)中心的距离计算 。PQ 的构建 (Pre-train) 分为两步:切分聚类与量化编码。
1. 切分与聚类
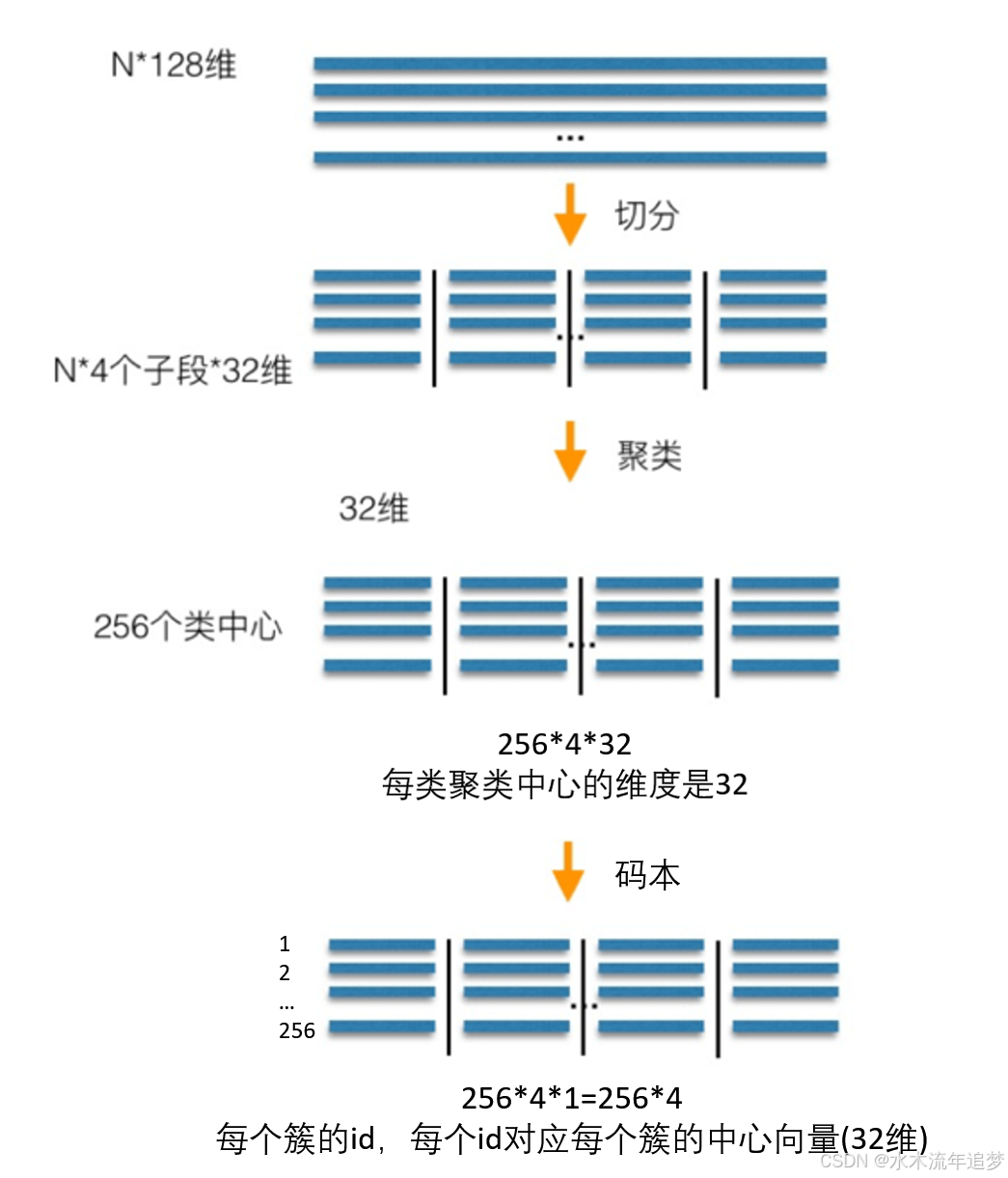
假设我们有一个包含 NNN 个 128 维向量的数据库,设定一个超参数 MMM:
- 我们将这 128 维的向量平均切分为 MMM 段(这里设 M=4M=4M=4)。
- 那么,这 NNN 个向量就被切分成了 N×4N \times 4N×4 个子段,每个子段是 32 维的短向量 。
接下来,对于切分出来的 4 个子空间,分别使用聚类算法将每个子空间内的短向量聚成 K=256K=256K=256 个类 。
-
每个聚类中心就是一个 32 维的子向量 。
-
这 256 个聚类中心分别用一个唯一的 ID (
clusterid) 表示 。 -
一个子空间内所有的
clusterid,就构成了一个专属于该子空间的 码本 (Codebook) 。
2. 量化编码
这是最核心的降维操作!
对于库里的任何一个原始向量,我们将其分为 4 段,分别计算每段距离对应子空间中最近的簇心 ID 。
-
于是,这 4 段 32 维的浮点数向量,就被映射成了 4 个
clusterid(整数) 。 -
例如,某个向量被量化后变成了
[124, 56, 132, 222]。
存储收益:原本 NNN 个 128 维的 float 向量,现在只需要用 N×4N \times 4N×4 维的整数 ID 来表示 !这使得存储空间呈现指数级下降。

三、 在线检索计算:SDC 与 ADC
完成了 PQ 的离线构建后,当在线接收到一个查询请求时,我们如何快速计算距离?业界主要有 SDC 和 ADC 两种计算方式 。
1. SDC (Symmetric Distance Computation) - 对称距离计算
逻辑:将查询向量 xxx 转为量化后的 q(x)q(x)q(x),将库中向量 yyy 转为 q(y)q(y)q(y) 。
计算:由于 xxx 和 yyy 都被转换为了由簇心 ID 表示的向量(升维拼接为128维的聚类中心向量) ,两两聚类中心之间的距离在离线构建时就已经计算好并存在表里了 。
优缺点:在线计算 distance(q(x), q(y)) 时只需极速查表,效率极高。但由于 xxx 到 q(x)q(x)q(x)、yyy 到 q(y)q(y)q(y) 经历了两次量化转换,量化误差较大 。
2. ADC (Asymmetric Distance Computation) - 非对称距离计算
逻辑:查询向量 xxx 不进行量化,只使用未经压缩的 Query 向量与库中已被量化为 q(y)q(y)q(y) 的向量计算距离 。
- 计算步骤:
-
将 128 维的 Query 分为 4 段 32 维子向量 。
-
计算 Query 的每一段与对应码本中 256 个簇心的距离,生成一张 4×2564 \times 2564×256 的距离预计算表 。
-
遍历库中向量 yyy 时(例如 y=[124,56,132,222]y = [124, 56, 132, 222]y=[124,56,132,222]),直接查表得到
d1(与 ID 124 的距离)、d2(与 ID 56 的距离)、d3、d4。 -
最终距离计算:
d = d1 + d2 + d3 + d4。
- 性能对比:
ADC:只需 4×2564 \times 2564×256 次短向量距离计算 + 4×N4 \times N4×N 次查表求和 。
暴力计算:需要 NNN 次 128 维长向量距离计算 。
- 随着 NNN 的增长,ADC 的速度优势呈现碾压级 。
优缺点:distance(x, q(y)) 只存在 yyy 到 q(y)q(y)q(y) 一次量化误差,精确度更高 ,但查表加上实时生成查询距离表的操作使得速度略逊于 SDC 。
四、 工业界最佳实践:组合拳出击
在真实的生产环境中(如推荐系统、RAG),我们通常不会单一使用某种算法,而是采用一套组合漏斗 :
-
第一层(粗筛):先使用倒排索引(IVF)进行粗量化聚类,快速定位到 Query 可能属于的少数几个相似簇 。
-
第二层(近似计算):在定位到的簇中,使用 PQ (乘积量化) 的 ADC 距离计算方式,快速检索出 TopK 个近似结果 。
-
第三层(精排):获取 TopK 对应的原始向量,针对这极少数的候选集进行暴力精确计算,最终输出准确率最高的结果 。
通过这套机制,我们完美实现了在亿级向量库中毫秒级且高精度的检索。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)