Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better
知识隔离视觉-语言-动作模型:快速训练、快速运行、更好地泛化
"在本文中,我们在包含连续扩散或流匹配动作专家的 VLA 背景下研究了这个问题,结果表明,天真地包含此类专家会严重损害训练速度和知识转移。我们对各种设计选择及其对性能和知识转移的影响进行了广泛的分析,并提出了一种在 VLA 训练期间隔离 VLM 主干的技术,以缓解这一问题。"
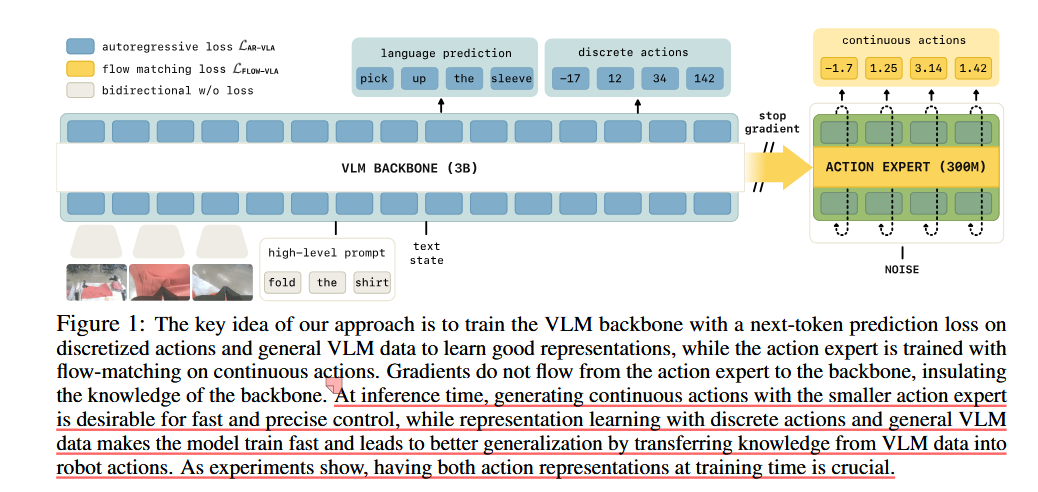
"在推理时,使用较小的动作专家生成连续动作对于快速和精确的控制来说是可取的,而使用离散动作和通用 VLM 数据进行表示学习可以使模型训练快速,并通过将 VLM 数据中的知识转移到机器人动作中来实现更好的泛化。实验表明,在训练时拥有两种动作表示至关重要。"
解读:表示学习?两种?论文想让 VLM backbone 通过“离散动作 token + VLM 数据”学到适合机器人控制的内部表征,同时让 action expert 通过 flow matching 学会输出连续动作。 所谓两种动作表示,就是 离散动作 token 表示 和 连续动作 chunk 表示。
“在这项工作中,我们观察到,先前对具有连续输出的 VLM 进行微调的方法可能会导致训练动态明显变差,因为它们依赖于训练信号的连续适配器(例如扩散头)的梯度,这或许并不令人意外。这会降低它们解释语言命令的能力以及生成的 VLA 策略的整体性能。为了应对这一挑战,我们提出了一个解决这些问题的培训方案,我们将其称为知识隔离。知识隔离背后的关键思想是用离散动作微调 VLM 主干,同时使动作专家产生连续动作(例如,通过流匹配或扩散),而不将其梯度传播回 VLM 主干。我们在图 1 中对此进行了说明。实际上,离散动作标记提供了一种替代学习信号,该信号不受动作专家未初始化权重的影响,这样 VLM 仍然可以学习机器人控制的适当表示,但不会因动作专家的梯度而造成干扰。这种方法还有其他优点:首先,使用下一个标记预测使模型学习得更快、更稳定。其次,使用行动专家仍然可以实现快速推理。第三,我们的方法使我们能够在通用视觉语言数据上共同训练模型,将 VLA 的优势带回到我们的模型中。”
“我们的工作将 π0.5 的方法形式化,并将其扩展以开发单阶段训练方案,其中 VLM 主干适用于具有离散令牌的机器人控制,而动作专家同时接受训练以产生连续动作,从而提供两全其美的效果。我们在实验中严格消除了知识保存和协同培训的不同机制。因此,我们提出了第一个 VLA 配方,可以快速训练、保留 VLM 知识并支持具有连续动作输出的高频控制。”
“VLM 预训练没有足够有关于机器人的表征,导致冻结不起作用。直观上,维护 VLM 预训练知识并避免上述问题的最简单方法是冻结预训练权重,仅训练新添加的机器人专用权重。然而,当前的 VLM 并未使用机器人数据进行预先训练。因此,正如我们在实验中所示,当它们的表示被冻结时,不足以训练高性能策略。”
解读:这里的意思是说冻结VLM不足以训练高性能策略。
“我们考虑了一些措施来克服第 2 节中概述的先前 VLA 方法的局限性。 4. 特别是,我们建议: 1. 同时联合训练自回归和流匹配动作预测模型(联合训练)。该模型使用(较小的)动作专家来生成连续动作,以便在测试时进行快速推理。自回归目标仅在训练时用作表示学习目标,这使得模型训练速度更快。 2. 在非动作数据集(例如通用视觉语言数据和机器人规划数据)上协同训练模型(VLM 数据协同训练)。对这些数据源进行训练可确保模型在适应 VLA 时损失更少的知识。 3. 停止动作专家和骨干权重之间的梯度流。这样,当将预训练的 VLM 调整为 VLA 时,动作专家新初始化的权重不会干扰预训练的权重。”
“同时预测(参见(2)中的 LAR-VLA)和流量匹配损失(参见(3)中的 LFLOW-VLA),即”

“其中 α 是损失乘数,通过流匹配的动作预测与标准语言建模损失进行权衡。 M l 是语言损失掩码(指示令牌流中应当应用语言损失的位置)并且M act 是动作掩码指示符,指定是否应当针对给定示例预测动作。这种损失结构使我们能够灵活地混合和匹配来自不同模式的数据的协同训练。特别是,我们将 VLM 数据(仅具有图像和文本注释)与仅动作数据(其中任务是基于图像和文本的动作预测)以及组合的语言和动作预测任务(其中我们仅采用动作数据并另外使用机器人下一步应该做什么的语言描述对其进行注释)相结合[53]。正如我们将看到的,以这种方式混合不同模式的数据可以增强生成的 VLA 中的知识转移。 lˆ包含文本(语言)标记和 FAST 标记化动作标记。至关重要的是,我们设置注意力掩码 A,使得离散的 FAST 动作标记不能关注连续的动作标记,反之亦然。我们在实验中观察到,这个联合训练目标让我们结合了两全其美:我们在训练过程中通过使用 FAST 动作标记学习良好的表示来获得快速收敛,并且仍然通过几个流程集成步骤获得连续动作的快速推理。”
解说:这里的操作就是把标准语言建模损失与动作预测流匹配结合在一起,然后通过指示符来确定最终的损失值。

在5.2这里说的一件事就是要在训练时通过设置梯度流来实现:
离散 FAST action loss ───────→ 更新 backbone
语言 / VLM loss ───────→ 更新 backbone
continuous flow loss ───────→ 更新 action expert
continuous flow loss ─X─────→ 不更新 backbone
实验板块的话就是在证明一个训练机制:用离散动作监督保护和适配 VLM backbone,用 stop-gradient 防止连续 action expert 破坏预训练知识,再用 VLM 数据增强语义泛化,最终实现训练快、推理快、语言跟随更好、真实机器人泛化更稳。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)