Dolphin-CN-Dialect正式发布:同样的数据,换一种配方,让ASR听懂更多中国话
今天,海天瑞声携手清华大学电子工程系语音与音频技术实验室(SATLab),正式发布Dolphin-CN-Dialect汉语多方言语音识别模型!
获取渠道
体验地址
·非流式识别: https://www.modelscope.cn/studios/haitianruisheng/dolphin_fangyang/summary
·非流式识别带热词:https://www.modelscope.cn/studios/haitianruisheng/dolphin_fangyan_reci/summary
模型与代码地址
·Github:https://github.com/DataoceanAI/Dolphin
·ModelScope:https://modelscope.cn/organization/DataoceanAI
·HuggingFace:https://huggingface.co/DataoceanAI
技术报告
http://arxiv.org/abs/2605.08961
推理代码SDK
https://pypi.org/project/dataoceanai-dolphin/
Dolphin-CN-Dialect是一款面向汉语多方言、多口音、真实场景优化的新一代语音识别模型,它并非简单扩大模型规模,而是在Dolphin系列模型基础上,围绕数据配方、tokenizer、训练稳定性、流式转写、热词增强和部署效率做了一次系统升级,破解主流ASR模型方言识别率断崖下跌的行业难题。
主流语音识别模型在普通话场景已表现优异,但切换至方言和地区口音时识别率大幅下降,核心原因并非模型参数不足,而是训练数据分布严重不均衡:普通话数据充足,方言样本天然稀缺,简单混合训练只会让模型持续偏向普通话。Dolphin-CN-Dialect通过temperature-based sampling重塑训练分布,让低资源方言在训练中被真正“看见”,而非被普通话数据淹没。
Dolphin-CN-Dialect核心特性
· All-in-one多方言覆盖
单模型支持21类汉语方言/地区口音,覆盖普通话、台湾普通话、四川话、吴语、闽南语等全场景中文语音,无需切换多模型即可完成识别。
·精准高效的轻量识别
0.4B小参数模型实现性能与效率的均衡,21个方言/口音测试集平均CER达到5.74%,对应平均准确率约94.3%;实现38%的方言识别准确率提升和16.3%的整体CER相对降低,标准普通话性能仅有约0.2%的轻微波动。

·流式转写+双模式热词增强
支持流式+非流式一体化推理,适配实时字幕、会议转写、客服质检、录音整理等全业务场景;搭载encoder-level上下文偏置与prompt-based两种热词增强方案,精准适配方言场景、噪声场景、长尾词场景。
·训练机制全面优化
通过训练机制优化缓解loss spike、修复短音频漏字问题;数据管线I/O吞吐从50MB/s提升至约800MB/s,减少GPU空转。· 低资源方言专项优化基于temperature-based sampling平衡训练数据分布,让稀缺方言样本获得充分训练,在吴语、闽南语等高难度方言上实现显著识别提升。
关键技术方法
·为中文方言重新设计数据配方
使用与Dolphin V1一致的训练数据底座,通过temperature-based sampling在Natural Sampling和Uniform Sampling之间做平滑,让低资源方言被更多学习,同时保留高资源普通话数据的稳定性。
配方优化后多方言测试集平均WER从8.04降至5.62,相对下降30.1%;宁夏、湖北、陕西、河南、山西、天津、山东等方言测试集均有明显提升。训练数据仅使用DataoceanAI中文数据集,覆盖标准普通话和22类汉语方言/地区口音,结合AISHELL、约10,000小时WenetSpeech、KeSpeech、Common Voice公开数据增强泛化能力。

·更适合中文的tokenizer设计
词表规模从40,000降至18,173;中文采用字符级建模,适配CTC-AED联合架构单调对齐;英文及字母语言保留BPE subword建模,兼顾表达能力与词表效率。 引入任务token、时间戳token、方言/地区token,额外预留80个方言token slot,为后续扩展更多地区语音预留空间。
·训练稳定性与工程优化
将BatchNorm替换为LayerNorm,缓解变长语音和异构数据带来的loss spike;针对流式CTC解码短音频漏字问题,补充短音频和尾部随机截断增强,删除错误从9.17降至3.66;数据管线优化后I/O吞吐从50MB/s提升至约800MB/s。
模型效果
我们对Dolphin-CN-Dialect在21类汉语方言/口音、标准普通话、真实场景语音、热词增强等维度进行了系统评估,结果显示:
·汉语方言/口音
21类方言/口音平均CER 5.74%;相较Paraformer_zh平均CER从22.76%降至5.74%,相对降低约74.8%;相较Qwen3-ASR-0.6B从12.74%降至5.74%,相对降低约54.9%;相较FunASR-Nano-2512从12.73%降至5.74%,相对降低约54.9%;相较FireRed-AED 1.2B从6.85%降至5.74%,相对降低约16.2%。
在多个高难度方言表现上,Dolphin-CN-Dialect 的优势更加明显。吴语CER为9.49%,优于Qwen3-ASR-0.6B的18.25%和FunASR-Nano-2512的17.77%;闽南语CER为20.74%,优于Qwen3-ASR-0.6B的38.64%、FunASR-Nano-2512的55.36%和FireRed-AED 1.2B的30.73%;上海话CER为7.81%,接近 FireRed-AED 1.2B的7.43%。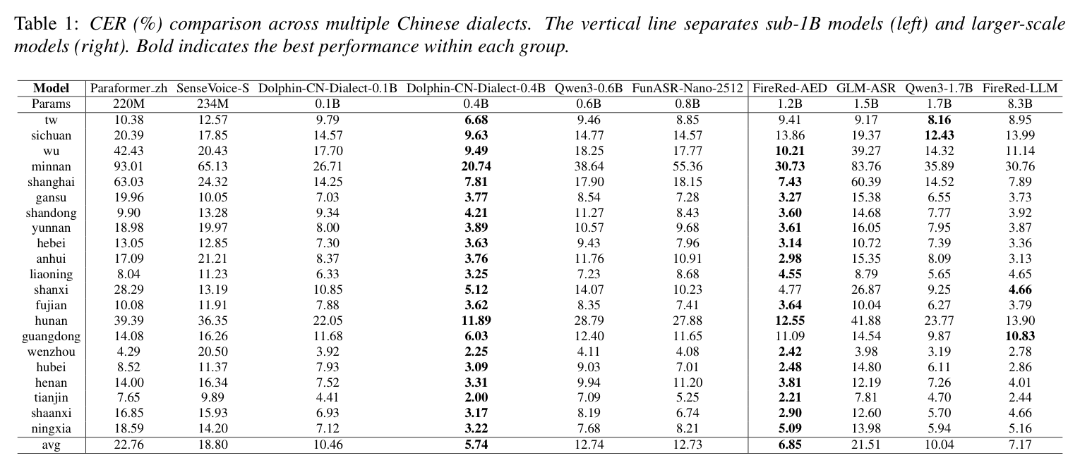
·标准普通话与地区口音
在KeSpeech 与Common Voice台湾普通话测试集上,Dolphin-CN-Dialect-0.4B 分别取得5.04%、5.62%的CER。作为仅0.4B参数量的轻量模型,它在同梯队(≤0.8B)中拿下双测试集最优表现,性能全面超越 Qwen3-0.6B、FunASR-Nano-2512等更大参数量模型,甚至优于1.7B的Qwen3-1.7B,展现出极高的参数效率。同时,优异的测试结果也印证了模型对真实录音、自然表达与地区口音的强泛化能力,完美匹配多方言优化目标。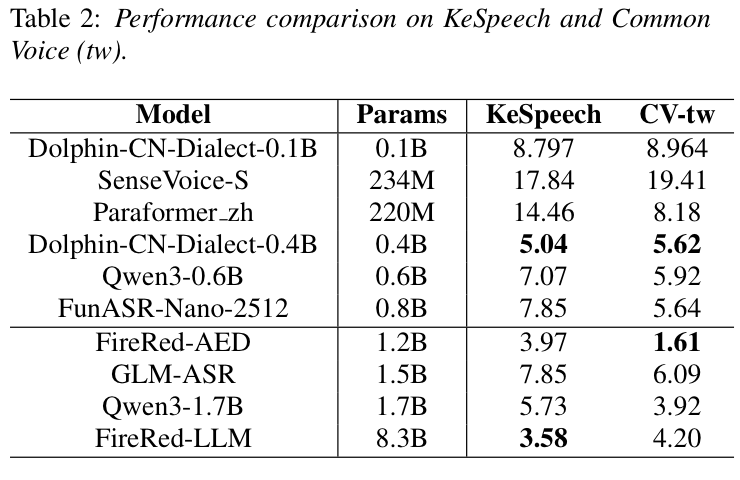
·热词增强效果在encoder-level热词实验中,Dolphin-CN-Dialect-0.4B在AISHELL上将BWER降至4.82,在 Common Voice 上将BWER降至9.46,均优于 Paraformer_zh。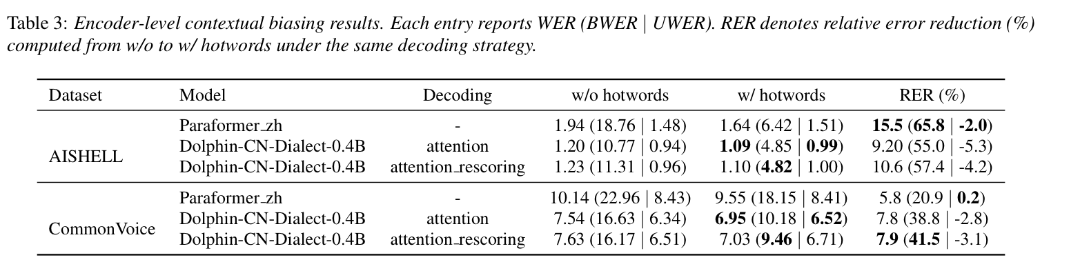
在 Common Voice prompt-based 热词实验中,WER 从 7.11 降至 6.08,BWER 从 15.22 降至 6.79,BWER 相对降低 55.4%。
·真实场景适配
适配方言、口音、噪声、长尾词等复杂中文语音环境,低资源方言识别无明显短板。
我们希望Dolphin-CN-Dialect的发布,能够补齐汉语方言语音识别的短板,让语音识别不只听懂标准普通话,更能听懂更真实的中国话,推动多方言语音技术在日常沟通、办公协作、行业服务等场景的普及与落地。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)