infoGCN++的理解4——数据预处理之去噪的pkl转npz
文章目录
- 一、前言
- 二、根据skeleton文件名生成元数据
- 三、seq_transformation.py
- 二、utils.py
一、前言
上一篇去噪之后我们会得到raw_denoised_joints.pkl,这一篇首先要根据skeleton文件名生成元数据(一些txt文件),然后运行seq_transformation.py。注意预处理的脚本都要在data/ntu路径下运行。
seq_transformation.py将去噪后的骨架数据(.pkl)进行归一化、对齐、划分,生成可直接用于模型训练的 .npz 数据集,并支持两种官方评估协议(Cross-Subject 和 Cross-View)。
25 个关节点顺序(Kinect v2)
0: SpineBase(脊柱底部)
1: SpineMid(脊柱中部)
2: Neck(颈部)
3: Head(头部)
4: ShoulderLeft(左肩)
5: ElbowLeft(左肘)
6: WristLeft(左腕)
7: HandLeft(左手)
8: ShoulderRight(右肩)
9: ElbowRight(右肘)
10: WristRight(右腕)
11: HandRight(右手)
12: HipLeft(左髋)
13: KneeLeft(左膝)
14: AnkleLeft(左踝)
15: FootLeft(左脚)
16: HipRight(右髋)
17: KneeRight(右膝)
18: AnkleRight(右踝)
19: FootRight(右脚)
20: SpineShoulder(脊柱肩膀处)
21: HandTipLeft(左手指尖)
22: ThumbLeft(左手拇指)
23: HandTipRight(右手指尖)
24: ThumbRight(右手拇指)
二、根据skeleton文件名生成元数据
import os
# 路径配置
stat_dir = './data/ntu/statistics'
skes_name_file = os.path.join(stat_dir, 'skes_available_name.txt')
# 输出文件路径
setup_file = os.path.join(stat_dir, 'setup.txt')
camera_file = os.path.join(stat_dir, 'camera.txt')
performer_file = os.path.join(stat_dir, 'performer.txt')
replication_file = os.path.join(stat_dir, 'replication.txt')
label_file = os.path.join(stat_dir, 'label.txt')
# 读取所有文件名
with open(skes_name_file, 'r') as f:
skes_names = [line.strip() for line in f]
# 初始化列表
setups = []
cameras = []
performers = []
replications = []
labels = []
for name in skes_names:
# 示例:S001C002P006R001A008
# 使用 split 方法提取各字段
parts = name.split('C')
setup = int(parts[0][1:]) # S001 -> 1
rest = parts[1]
camera_str, rest = rest[:3], rest[3:] # 002
camera = int(camera_str)
performer_str, rest = rest.split('P')[1][:3], rest.split('P')[1][3:] # 006
performer = int(performer_str)
replication_str, rest = rest.split('R')[1][:3], rest.split('R')[1][3:] # 001
replication = int(replication_str)
label_str = rest.split('A')[1][:3] # 008
label = int(label_str)
setups.append(setup)
cameras.append(camera)
performers.append(performer)
replications.append(replication)
labels.append(label)
# 写入各个文件
with open(setup_file, 'w') as f:
for val in setups:
f.write(f"{val}\n")
print(f"Generated {setup_file}")
with open(camera_file, 'w') as f:
for val in cameras:
f.write(f"{val}\n")
print(f"Generated {camera_file}")
with open(performer_file, 'w') as f:
for val in performers:
f.write(f"{val}\n")
print(f"Generated {performer_file}")
with open(replication_file, 'w') as f:
for val in replications:
f.write(f"{val}\n")
print(f"Generated {replication_file}")
with open(label_file, 'w') as f:
for val in labels:
f.write(f"{val}\n")
print(f"Generated {label_file}")
print("\nAll statistics files have been created successfully.")
这段代码的功能是:从 NTU RGB+D 数据集的视频文件名中,批量提取出各个属性字段(场景、相机、表演者、重复次数、动作类别),并将它们分别保存到不同的文本文件中,方便后续训练或分析时直接读取使用。
下面按模块逐步解释:
1. 路径与文件准备
stat_dir = './data/ntu/statistics'
skes_name_file = os.path.join(stat_dir, 'skes_available_name.txt')
# 输出文件路径
setup_file = os.path.join(stat_dir, 'setup.txt')
camera_file = os.path.join(stat_dir, 'camera.txt')
performer_file = os.path.join(stat_dir, 'performer.txt')
replication_file = os.path.join(stat_dir, 'replication.txt')
label_file = os.path.join(stat_dir, 'label.txt')
skes_available_name.txt是一个纯文本文件,每行一个视频样本的文件名(不含扩展名),例如:S001C002P006R001A008- 之后生成的
setup.txt、camera.txt等,分别用于存储对应属性的数值(每行一个整数)。
2. 读取所有文件名
with open(skes_name_file, 'r') as f:
skes_names = [line.strip() for line in f]
- 按行读取,去掉行末的换行符,将所有文件名存入列表
skes_names。
3. 解析文件名 —— 核心逻辑
NTU 数据集的命名规则固定为:S{场景号}C{相机号}P{表演者号}R{重复次数}A{动作类别}
例如:S001C002P006R001A008 表示 场景1,相机2,6号表演者,第1次重复,动作类别8。
代码通过逐步拆解字符串来提取这些数字:
for name in skes_names:
parts = name.split('C') # 按 'C' 分割,例如 ['S001', '002P006R001A008']
setup = int(parts[0][1:]) # parts[0] 取 "S001",[1:] 去掉首字母 'S',再转整数 → 1
rest = parts[1] # rest = "002P006R001A008"
camera_str, rest = rest[:3], rest[3:] # 前3位是相机号 "002",剩余部分 "P006R001A008"
camera = int(camera_str) # 转整数 → 2
# 接着处理表演者:用 'P' 分割 rest,取分割结果的第2部分
performer_str, rest = rest.split('P')[1][:3], rest.split('P')[1][3:]
# rest.split('P') → ['', '006R001A008'],[1] 为 '006R001A008'
# 前3位是表演者号 "006",剩余 "R001A008" 重新赋给 rest
performer = int(performer_str) # → 6
# 同样处理重复次数:用 'R' 分割
replication_str, rest = rest.split('R')[1][:3], rest.split('R')[1][3:]
# rest.split('R') → ['', '001A008'],[1] 为 '001A008'
# 前3位 "001",剩余 "A008"
replication = int(replication_str) # → 1
# 最后处理动作类别:用 'A' 分割
label_str = rest.split('A')[1][:3] # rest.split('A') → ['', '008'],[1] 取 "008"
label = int(label_str) # → 8
# 将解析出的数值分别追加到对应列表
setups.append(setup)
cameras.append(camera)
performers.append(performer)
replications.append(replication)
labels.append(label)
解析技巧总结:
- 固定宽度(如相机号是3位)直接用切片
[:3]; - 有字母前缀的字段(如
P、R、A)则用对应字母做split,取结果的第[1]部分; - 每次提取完一个字段后,把剩余字符串重新赋值给
rest,保持流水线处理。
4. 写入各属性文件
with open(setup_file, 'w') as f:
for val in setups:
f.write(f"{val}\n")
# ... 对 cameras, performers, replications, labels 重复相同操作
- 将列表中的每个整数按行写入对应的
.txt文件。 - 写入完成后打印生成提示,最后输出“所有统计文件已创建成功”。
5. 最终生成的文件
运行后,会在 ./data/ntu/statistics/ 目录下产生:
setup.txt—— 每行一个场景编号camera.txt—— 每行一个相机编号performer.txt—— 每行一个表演者编号replication.txt—— 每行一个重复次数label.txt—— 每行一个动作类别标签
这些文件可以配合骨架数据文件(如 .skeleton 文件)使用,直接按行索引取对应标签,方便做数据加载和划分训练/测试集。
潜在注意事项
- 该解析完全依赖文件名的固定格式,如果后期数据集出现不同命名(如位数变化),代码可能需要调整。
- 列表顺序与原始文件名顺序一致,因此后续生成的标签文件与骨架数据保证一一对应。
三、seq_transformation.py
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
# 导入必要的库
import sys
sys.path.append(r"E:\reset\my_infogcn") # 将项目根目录添加到系统路径,便于导入自定义模块
import os
import os.path as osp
import numpy as np
import pickle
import logging
import h5py
from sklearn.model_selection import train_test_split
from utils import create_aligned_dataset # 导入自定义工具函数,用于生成多模态数据
# ---------- 路径配置 ----------
# root_path = './' # 当前工作目录作为根路径
root_path = r'E:\reset\my_infogcn\data\ntu' # 相对路径比较容易出问题,可以改成你自己的绝对路径
stat_path = osp.join(root_path, 'statistics') # 统计文件所在文件夹
setup_file = osp.join(stat_path, 'setup.txt') # 场景编号文件
camera_file = osp.join(stat_path, 'camera.txt') # 相机编号文件
performer_file = osp.join(stat_path, 'performer.txt') # 表演者编号文件
replication_file = osp.join(stat_path, 'replication.txt') # 重复次数文件
label_file = osp.join(stat_path, 'label.txt') # 动作类别标签文件
skes_name_file = osp.join(stat_path, 'skes_available_name.txt') # 可用样本文件名列表
denoised_path = osp.join(root_path, 'denoised_data') # 存放去噪后数据的文件夹
raw_skes_joints_pkl = osp.join(denoised_path, 'raw_denoised_joints.pkl') # 去噪后的骨架数据(pickle格式)
frames_file = osp.join(denoised_path, 'frames_cnt.txt') # 每个样本的有效帧数
save_path = './' # 输出文件保存路径
# 如果保存路径不存在则创建
if not osp.exists(save_path):
os.mkdir(save_path)
# ---------- 函数定义 ----------
def remove_nan_frames(ske_name, ske_joints, nan_logger):
"""
移除骨架序列中包含 NaN 的帧,并记录被移除的帧信息。
参数:
ske_name: 样本文件名(用于日志标识)
ske_joints: 形状为 [帧数, 关节维数] 的骨架数组
nan_logger: 日志记录器
返回:
仅含有效帧的骨架数组
"""
num_frames = ske_joints.shape[0] # 总帧数
valid_frames = [] # 用于收集有效帧的索引
# 遍历每一帧
for f in range(num_frames):
if not np.any(np.isnan(ske_joints[f])):
# 如果该帧没有任何关节点为 NaN,则为有效帧,保留其索引
valid_frames.append(f)
else:
# 如果有 NaN,记录是哪些关节点为 NaN
nan_indices = np.where(np.isnan(ske_joints[f]))[0]
nan_logger.info('{}\t{:^5}\t{}'.format(ske_name, f + 1, nan_indices))
# 只返回有效帧的数据
return ske_joints[valid_frames]
def seq_translation(skes_joints):
"""
对每个骨架序列进行平移归一化(序列级):
以当前序列中第一个有效演员的第一帧的脊椎中点(joint-2)为原点,
将整个序列进行平移,使不同序列的位置对齐。
"""
for idx, ske_joints in enumerate(skes_joints):
num_frames = ske_joints.shape[0] # 当前序列的帧数
# 判断是一人(75维)还是两人(150维)
num_bodies = 1 if ske_joints.shape[1] == 75 else 2
# 如果是双人,找到两人各自完全缺失(全0)的帧
if num_bodies == 2:
missing_frames_1 = np.where(ske_joints[:, :75].sum(axis=1) == 0)[0] # 第一个演员缺失帧的索引
missing_frames_2 = np.where(ske_joints[:, 75:].sum(axis=1) == 0)[0] # 第二个演员缺失帧的索引
cnt1 = len(missing_frames_1)
cnt2 = len(missing_frames_2)
# 寻找第一个演员第一个非全0的帧,作为参考帧
i = 0
while i < num_frames:
if np.any(ske_joints[i, :75] != 0):
break
i += 1
# 将该参考帧的 joint-2 (索引3:6) 作为新的坐标原点
origin = np.copy(ske_joints[i, 3:6])
# 将每一帧都减去这个原点(平移),使脊柱中点对齐到原点
for f in range(num_frames):
if num_bodies == 1:
ske_joints[f] -= np.tile(origin, 25) # 单人:25个关节点需要平移
else:
ske_joints[f] -= np.tile(origin, 50) # 双人:50个关节点需要平移
# 双人情况下,之前全0的缺失帧平移后可能会变成非0,需要还原为全0
if (num_bodies == 2) and (cnt1 > 0):
ske_joints[missing_frames_1, :75] = np.zeros((cnt1, 75), dtype=np.float32)
if (num_bodies == 2) and (cnt2 > 0):
ske_joints[missing_frames_2, 75:] = np.zeros((cnt2, 75), dtype=np.float32)
skes_joints[idx] = ske_joints # 更新列表中的序列
return skes_joints
def frame_translation(skes_joints, skes_name, frames_cnt):
"""
帧级归一化(本脚本中未被调用,作为备用处理方式):
除平移外,还利用脊柱两关节的距离进行尺度归一化。
"""
# 配置日志记录器
nan_logger = logging.getLogger('nan_skes')
nan_logger.setLevel(logging.INFO)
nan_logger.addHandler(logging.FileHandler("./nan_frames.log"))
nan_logger.info('{}\t{}\t{}'.format('Skeleton', 'Frame', 'Joints'))
for idx, ske_joints in enumerate(skes_joints):
num_frames = ske_joints.shape[0]
# 计算每一帧中 spine base (joint-1) 到 spine (joint-21) 的距离
j1 = ske_joints[:, 0:3]
j21 = ske_joints[:, 60:63]
dist = np.sqrt(((j1 - j21) ** 2).sum(axis=1)) # 形状为 [帧数,]
for f in range(num_frames):
origin = ske_joints[f, 3:6] # 当前帧的 joint-2 作为原点
if (ske_joints[f, 75:] == 0).all():
# 只有第一个人的数据
ske_joints[f, :75] = (ske_joints[f, :75] - np.tile(origin, 25)) / \
dist[f] + np.tile(origin, 25)
else:
# 有两人数据,同时处理
ske_joints[f] = (ske_joints[f] - np.tile(origin, 50)) / \
dist[f] + np.tile(origin, 50)
ske_name = skes_name[idx]
# 移除含有 NaN 的帧,并更新有效帧数
ske_joints = remove_nan_frames(ske_name, ske_joints, nan_logger)
frames_cnt[idx] = num_frames
skes_joints[idx] = ske_joints
return skes_joints, frames_cnt
def align_frames(skes_joints, frames_cnt):
"""
将所有骨骼序列对齐到相同的帧数(最大帧数)。
并将单人数据扩展为双人维度(150维),保持输入维度统一。
参数:
skes_joints: 骨骼序列列表
frames_cnt: 每个序列的有效帧数数组
返回:
对齐后的数组,形状 [样本数, 最大帧数, 150]
"""
num_skes = len(skes_joints) # 样本总数
max_num_frames = frames_cnt.max() # 所有序列中的最大帧数
# 初始化全零数组,作为最终对齐结果
aligned_skes_joints = np.zeros((num_skes, max_num_frames, 150), dtype=np.float32)
for idx, ske_joints in enumerate(skes_joints):
num_frames = ske_joints.shape[0] # 当前序列实际帧数
num_bodies = 1 if ske_joints.shape[1] == 75 else 2 # 判断人数
if num_bodies == 1:
# 单人:将75维复制一份,右边填充0,形成150维(第二个人全0)
aligned_skes_joints[idx, :num_frames] = np.hstack((ske_joints,
np.zeros_like(ske_joints)))
else:
# 双人:直接放入
aligned_skes_joints[idx, :num_frames] = ske_joints
return aligned_skes_joints
def one_hot_vector(labels):
"""
将整数标签转换成 one-hot 编码向量。
参数:
labels: 整数标签列表,元素值范围 0~59
返回:
二维数组,形状 [样本数, 60]
"""
num_skes = len(labels)
labels_vector = np.zeros((num_skes, 60)) # 初始化全0矩阵
for idx, l in enumerate(labels):
labels_vector[idx, l] = 1 # 对应类别位置置为1
return labels_vector
def split_train_val(train_indices, method='sklearn', ratio=0.05):
"""
从训练集中随机划分出一部分作为验证集(未在主流程中调用)。
提供两种实现方式,效果相同。
"""
if method == 'sklearn':
# 使用 sklearn 的 train_test_split 随机划分
return train_test_split(train_indices, test_size=ratio, random_state=10000)
else:
# 使用 numpy 手动打乱后按比例切分
np.random.seed(10000)
np.random.shuffle(train_indices)
val_num_skes = int(np.ceil(0.05 * len(train_indices)))
val_indices = train_indices[:val_num_skes]
train_indices = train_indices[val_num_skes:]
return train_indices, val_indices
def split_dataset(skes_joints, label, performer, camera, evaluation, save_path):
"""
根据评估协议(CS 或 CV)划分训练集和测试集,保存为 .npz 文件。
"""
# 获取按主体/相机划分的训练和测试索引
train_indices, test_indices = get_indices(performer, camera, evaluation)
# 可选的从训练集中进一步划分验证集(这里注释掉了,不启用)
# m = 'sklearn'
# train_indices, val_indices = split_train_val(train_indices, m)
# 过滤掉超出实际样本数的索引(防止数据文件不匹配导致越界)
num_samples = len(skes_joints)
train_indices = train_indices[train_indices < num_samples]
test_indices = test_indices[test_indices < num_samples]
# 提取训练和测试集的标签
train_labels = label[train_indices]
test_labels = label[test_indices]
# 提取训练和测试集的骨架数据
train_x = skes_joints[train_indices]
test_x = skes_joints[test_indices]
# 将标签转换为 one-hot 编码
train_y = one_hot_vector(train_labels)
test_y = one_hot_vector(test_labels)
# 保存为 .npz 文件,例如 NTU60_CS.npz
save_name = 'NTU60_%s.npz' % evaluation
np.savez(save_name, x_train=train_x, y_train=train_y, x_test=test_x, y_test=test_y)
# (注释部分)也可以保存为 .h5 格式,如果不需要可忽略
# h5file = h5py.File(osp.join(save_path, 'NTU_%s.h5' % (evaluation)), 'w')
# h5file.create_dataset('x', data=skes_joints[train_indices])
# h5file.create_dataset('y', data=train_one_hot_labels)
# h5file.create_dataset('valid_x', data=skes_joints[val_indices])
# h5file.create_dataset('valid_y', data=val_one_hot_labels)
# h5file.create_dataset('test_x', data=skes_joints[test_indices])
# h5file.create_dataset('test_y', data=test_one_hot_labels)
# h5file.close()
def get_indices(performer, camera, evaluation='CS'):
"""
根据 NTU 官方评估协议返回训练和测试样本的索引。
CS (Cross-Subject): 按表演者 ID 划分
CV (Cross-View): 按相机 ID 划分
"""
test_indices = np.empty(0, dtype=int)
train_indices = np.empty(0, dtype=int)
if evaluation == 'CS':
# CS 协议规定的训练主体 ID
train_ids = [1, 2, 4, 5, 8, 9, 13, 14, 15, 16,
17, 18, 19, 25, 27, 28, 31, 34, 35, 38]
# CS 协议规定的测试主体 ID
test_ids = [3, 6, 7, 10, 11, 12, 20, 21, 22, 23,
24, 26, 29, 30, 32, 33, 36, 37, 39, 40]
# 收集测试集索引
for idx in test_ids:
temp = np.where(performer == idx)[0]
test_indices = np.hstack((test_indices, temp)).astype(int)
# 收集训练集索引
for train_id in train_ids:
temp = np.where(performer == train_id)[0]
train_indices = np.hstack((train_indices, temp)).astype(int)
else: # CV
train_ids = [2, 3]
test_ids = 1
# 测试集:相机 1 的所有样本
temp = np.where(camera == test_ids)[0]
test_indices = np.hstack((test_indices, temp)).astype(int)
# 训练集:相机 2 和 3 的所有样本
for train_id in train_ids:
temp = np.where(camera == train_id)[0]
train_indices = np.hstack((train_indices, temp)).astype(int)
return train_indices, test_indices
# ---------- 主程序入口 ----------
if __name__ == '__main__':
# 1. 从统计文件中加载元数据
camera = np.loadtxt(camera_file, dtype=int) # 每个样本对应的相机ID(1,2,3)
performer = np.loadtxt(performer_file, dtype=int) # 每个样本对应的表演者ID(1~40)
label = np.loadtxt(label_file, dtype=int) - 1 # 动作标签(原始1~60,转为0~59,便于one-hot)
frames_cnt = np.loadtxt(frames_file, dtype=int) # 每个样本的原始有效帧数
skes_name = np.loadtxt(skes_name_file, dtype=str) # 每个样本的文件名(字符串)
# 2. 从 pkl 文件加载去噪后的骨架数据(列表形式,每个元素为一个序列的数组)
with open(raw_skes_joints_pkl, 'rb') as fr:
skes_joints = pickle.load(fr)
# 3. 序列级平移:将所有序列对齐到第一个有效演员第一帧的 spine 中点
skes_joints = seq_translation(skes_joints)
# 4. 帧对齐:将所有序列填充/截断到最大帧数,且维度统一为150(双人格式)
skes_joints = align_frames(skes_joints, frames_cnt)
# 5. 针对两种评估协议分别生成数据集文件
evaluations = ['CS', 'CV']
for evaluation in evaluations:
split_dataset(skes_joints, label, performer, camera, evaluation, save_path)
# 6. 调用自定义工具函数生成包含 joint, bone, motion 等模态的对齐数据集
# create_aligned_dataset(file_list=['NTU60_CS.npz', 'NTU60_CV.npz'])
create_aligned_dataset(file_list=['NTU60_CS.npz', 'NTU60_CV.npz'])
这段代码是 NTU RGB+D 60类动作识别数据集的预处理流水线,主要功能如下:
整体目标
将去噪后的骨架数据(.pkl)进行归一化、对齐、划分,生成可直接用于模型训练的 .npz 数据集,并支持两种官方评估协议(Cross-Subject 和 Cross-View)。
核心流程
-
加载数据
- 读取统计文件(相机ID、表演者ID、标签、帧数、样本名)。
- 从
raw_denoised_joints.pkl加载去噪后的骨架序列列表(每个序列形状[T, 75/150])。
-
序列平移 (
seq_translation)- 以每个序列第一个有效演员第一帧的脊柱中点(joint-2)为原点,对所有帧做平移,消除不同样本的位置差异。
- 双人场景中保持缺失帧全零。
-
帧对齐 (
align_frames)- 将所有序列填充或截断至最大帧数(通常300),统一输出形状
[样本数, 最大帧数, 150]。 - 单人骨架复制为双人维度(第二人全零),保证输入维度一致。
- 将所有序列填充或截断至最大帧数(通常300),统一输出形状
-
划分数据集 (
split_dataset)- 根据
get_indices获取训练/测试索引(CS按表演者,CV按相机)。 - 过滤越界索引,提取骨架和标签,标签转为 one-hot 编码。
- 保存为
NTU60_CS.npz和NTU60_CV.npz,包含x_train, y_train, x_test, y_test。
- 根据
-
后续处理
- 调用
create_aligned_dataset生成含关节、骨骼、运动等模态的增强数据。
- 调用
输出
NTU60_CS.npz:Cross-Subject 协议的训练/测试数据。NTU60_CV.npz:Cross-View 协议的训练/测试数据。
关键设计
- 保留双人结构,单人数据复制补零,便于模型统一处理。
- 使用 one-hot 标签,支持60类分类。
- 严格遵循 NTU 官方评估协议划分,确保可比性。
问题1
seq_translation里面 将该参考帧的 joint-2 (索引3:6) 作为新的坐标原点 origin = np.copy(ske_joints[i, 3:6]) 这个索引3:6是 什么东西?为什么是索引3:6?origin长什么样?后面np.tile是什么?为什么要将每一帧都减去这个原点(平移),使脊柱中点对齐到原点?为什么双人情况下,之前全0的缺失帧平移后可能会变成非0,需要还原为全0
回答1
下面逐点解释 seq_translation 函数中的这些细节:
1. origin = np.copy(ske_joints[i, 3:6]) 中的索引 3:6
NTU 数据集的骨架有 25 个关节点,每个关节点用 3 个坐标 (x, y, z) 表示,所以一帧中单个人的数据长度为 75。
这 75 个数的排列顺序是:[x₀, y₀, z₀, x₁, y₁, z₁, x₂, y₂, z₂, ... , x₂₄, y₂₄, z₂₄]
- 关节 0(索引 0):坐标在
0:3 - 关节 1(索引 1):坐标在
3:6 - 关节 2(索引 2):坐标在
6:9 - …
代码注释写的是 “new origin: joint‑2”,但这里取的切片是 3:6,也就是关节 1(从 0 开始数)的坐标。
这是因为在 NTU 的官方说明/部分文献中,关节编号有时从 1 开始,“joint‑2” 指的其实是第二个关节点,即 脊柱中部(middle of the spine),它在 0‑based 索引中为 1,存储位置恰好是 3:6。
结论:
origin取的是脊柱中部关节(index 1)的 (x, y, z)。
2. origin 长什么样?
origin 是一个形状为 (3,) 的一维 NumPy 数组,例如:array([0.12, -0.05, 1.23])
代表从摄像头坐标系下,该关节在参考帧中的三维空间位置。
3. np.tile(origin, 25) 是什么?
np.tile(origin, 25) 将长度为 3 的 origin 重复 25 次,得到一个长度为 75 的数组:
[x, y, z, x, y, z, ..., x, y, z] ← 重复 25 组
这 75 个数正好对应 25 个关节的坐标。
这样做的目的是:对单人的 75 维骨架向量执行逐元素减法,即:
ske_joints[f] -= np.tile(origin, 25)
等价于:将当前帧的所有 25 个关节坐标都减去同一个 origin。
双人时则是 np.tile(origin, 50),得到 150 维向量,用于同时平移两个人的 50 个关节。
4. 为什么要把每一帧都减去 origin(使脊柱中点对齐到原点)?
这是平移归一化,目的是消除不同样本间的空间位置差异。
- 同一个动作,由不同的表演者在不同位置、距离相机不同远近录制,其脊柱中点的全局坐标差异很大。
- 我们只关心姿态的相对变化(关节之间的相对位置),而不是人在房间里的绝对位置。
- 通过将每一帧的脊柱中点(joint‑2)平移到原点,相当于把 “人的中心”固定到坐标系原点,使得所有序列在一个统一的空间参考系下,便于模型学习动作模式。
简单说:去掉“人站在哪里”的信息,只保留“肢体怎么动”的信息。
5. 为什么双人情况下,之前全 0 的缺失帧平移后会变成非 0,需要还原为全 0?
双人骨架的存储方式是:前 75 维 = 第一个人,后 75 维 = 第二个人。
如果某帧中某个人不存在(例如只有一个人表演),该部分会被置为全 0,表示“缺失”。
平移操作是整帧减去的,即:
ske_joints[f] -= np.tile(origin, 50) # 同时对前后两个 75 维块做平移
这会使得原本全 0 的缺失块变成 -origin 非零值,失去了“缺失”的语义。
因此,在平移之后,需要重新将那些原本全 0 的缺失帧区域强制置零,以保证:
- 存在的人:坐标经过平移归一化;
- 缺失的人:仍然是全 0,模型能够识别该人不可见。
这样既完成了归一化,又保留了关于人物是否存在的有效信息。
问题2
ske_joints[missing_frames_1, :75] = np.zeros((cnt1, 75), dtype=np.float32) 这个missing_frames_1是可能有多个索引吗?那cnt1对应是什么?
回答2
是的,missing_frames_1 可以包含多个索引,它是一个一维 NumPy 数组,存放所有满足条件的帧编号。
missing_frames_1 如何得到?
missing_frames_1 = np.where(ske_joints[:, :75].sum(axis=1) == 0)[0]
ske_joints[:, :75]取出该序列所有帧的前 75 维(即第一个演员的关节点数据)。.sum(axis=1)计算每一帧前 75 维的和。== 0判断和是否为 0(即该演员在该帧所有关节坐标全为 0)。np.where(...)返回满足条件的元素的索引,[0]取出第一个元素(即行索引数组)。
因此 missing_frames_1 是一个整数数组,例如 [3, 7, 8],表示第 3、7、8 帧中第一个演员是缺失的。
cnt1 是什么?
cnt1 = len(missing_frames_1)
cnt1 就是第一个演员缺失的帧数,一个标量整数。例如上面 missing_frames_1 = [3, 7, 8],则 cnt1 = 3。
赋值语句如何工作?
ske_joints[missing_frames_1, :75] = np.zeros((cnt1, 75), dtype=np.float32)
这里利用了 NumPy 的高级索引(fancy indexing):
- 左侧
ske_joints[missing_frames_1, :75]会选中missing_frames_1中所有索引对应的行,以及前 75 列。 - 右侧
np.zeros((cnt1, 75))生成一个形状为(缺失帧数, 75)的全零数组,与选中的子数组形状完全一致。 - 赋值后,所有缺失帧的第一个演员数据都被一次性覆盖为全零。
如果 cnt1 = 0(即没有缺失帧),则 missing_frames_1 为空数组,该行代码不会进行任何赋值(因为左右形状都是 (0, 75),相当于空操作,但更早的 if cnt1 > 0 判断已经阻止了这种情况)。
因此,这段代码高效地将所有原本全零的缺失帧在平移后可能产生的非零值重新清零,确保缺失演员依然表示为全零。
问题3
split_dataset函数中
将标签转换为 one-hot 编码
train_y = one_hot_vector(train_labels)
test_y = one_hot_vector(test_labels)
one-hot 编码是什么?为什么要将标签转换为 one-hot 编码?
回答3
One-hot 编码(独热编码)是将类别标签转换为向量的表示方法,向量长度等于总类别数,只有对应类别位置的元素为 1,其余全为 0。
例如在 NTU-60 数据集中有 60 个动作类,标签为整数 0~59。若某个样本的标签是 8,它的 one-hot 向量为:
[0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
↑ 第 8 位为 1(索引从0计)
为什么在动作识别中要把标签转为 one-hot 编码?
-
匹配常见分类损失函数(如交叉熵)
在 PyTorch 或 TensorFlow 中,nn.CrossEntropyLoss可以直接接收整数标签(内部自动进行 one-hot 转换);但在 NumPy/训练框架手动实现或使用某些老版本 API 时,需要显式提供 one-hot 向量。这里的代码将标签转为 one-hot 后存入.npz文件,可能是为了让数据加载后直接就能用于需要概率分布的损失函数(如 MSE 或手动交叉熵)。 -
便于后续计算准确率、概率输出
模型输出通常是 60 维向量(每个类的预测概率),one-hot 向量可以直接与输出计算误差,也能很简单地通过argmax还原为类别。 -
兼容某些模型/框架的要求
部分图卷积网络(如 InfoGCN)或预训练流程可能需要标签以 one-hot 形式输入(比如用于蒸馏、多模态融合、或是某些损失函数设计)。 -
标准化数据存储
提前转为 one-hot 后,训练脚本从.npz加载数据时不用再做转换,简化后续处理,减少重复代码。
问题4
解释一下split_train_val函数以及它的语法
回答4
split_train_val 函数用于从训练集索引中随机划分出一部分作为验证集,帮助在模型训练时监控过拟合、调整超参数。虽然主流程中它被注释掉了,但其实现展示了两种常见的划分写法,下面详细解释。
函数定义与参数
def split_train_val(train_indices, method='sklearn', ratio=0.05):
train_indices: 训练样本的整数索引(一维数组,例如np.ndarray)。method: 字符串,指定划分方式,可选'sklearn'或'numpy'。ratio: 验证集占训练集的比例,默认为0.05(5%)。
返回值:(新的训练索引, 验证索引),两个数组。
两种实现方式的语法与细节
方式一:使用 sklearn(默认)
if method == 'sklearn':
return train_test_split(train_indices, test_size=ratio, random_state=10000)
train_test_split来自sklearn.model_selection,专门用于随机划分数据集。- 参数:
train_indices:要划分的数组。test_size=0.05:验证集的比例。random_state=10000:随机种子,保证每次划分结果相同(可复现)。
- 返回值:
(X_train, X_test)——此处X_train和X_test就是划分后的训练索引和验证索引。 - 语法特点:一行搞定,简洁可靠,且
scikit-learn内部实现了分层划分等额外功能(但这里只传入单一数组,等价于随机打乱后切分)。
方式二:手动用 numpy 实现
else:
np.random.seed(10000) # 固定随机种子
np.random.shuffle(train_indices) # 原地打乱数组
val_num_skes = int(np.ceil(0.05 * len(train_indices))) # 计算验证集大小
val_indices = train_indices[:val_num_skes] # 前 val_num_skes 个作为验证集
train_indices = train_indices[val_num_skes:] # 剩余作为新训练集
return train_indices, val_indices
逐步分析:
-
np.random.seed(10000)
为 NumPy 随机数生成器设置种子,确保每次运行打乱顺序一致。 -
np.random.shuffle(train_indices)shuffle是原地操作(in-place),直接改变train_indices数组的元素顺序,返回None。- 这里需要注意:传入的
train_indices会被修改(若不希望修改原数组,需提前复制)。 - 打乱后,数组中的元素随机排列。
-
int(np.ceil(0.05 * len(train_indices)))0.05 * len(...):计算验证集样本数量(可能为小数)。np.ceil(...):向上取整,保证验证集至少 1 个样本(即便总数很少)。int(...):转换为整数类型。
-
切片操作:
train_indices[:val_num_skes]:前val_num_skes个作为验证索引。train_indices[val_num_skes:]:后面的作为新的训练索引。
-
返回
(train_indices, val_indices)。
注意:这种方式直接修改了传入的 train_indices 数组,函数外部的原数组也会被改变。如果需要保留原始顺序,应在函数内部先复制一份:indices = train_indices.copy()。
两种方式的等价性
作者在注释中提到两种方法“得到了相同的性能”,因为它们本质上都是:
- 固定随机种子,
- 随机打乱顺序,
- 按比例切片。
sklearn 的 train_test_split 默认也是先洗牌(如果 shuffle=True,且不进行分层时),因此结果完全一致。
总结
split_train_val 提供了一种从训练集中划出验证集的灵活方法,便于在骨骼动作识别等任务中微调模型超参数。其语法设计展示了 Python 函数参数的默认值、条件分支、以及 NumPy 和 scikit-learn 的互操作性,是一段典型而实用的数据划分工具代码。
二、utils.py
create_aligned_dataset` 函数
def create_aligned_dataset(file_list=['data/ntu/NTU60_CS.npz', 'data/ntu/NTU60_CV.npz']):
"""
为给定的 .npz 数据集生成骨架对齐版本。
对齐过程:将骨架旋转到基于脊柱和双肩定义的标准坐标系,消除拍摄视角差异。
"""
for file in file_list:
# 加载原始数据集,包含 x_train, y_train, x_test, y_test
org_data = np.load(file)
splits = ['x_train', 'x_test'] # 需要对齐的骨架集
aligned_set = {} # 用于暂存对齐后的结果
for split in splits:
data = org_data[split] # 形状 (N, T, 150)
N, T, _ = data.shape # N: 样本数, T: 最大帧数
# --- 将展平的数据重构为骨架结构 ---
# 原始 150 维 = 2人 × 25关节 × 3坐标(x,y,z)
# reshape 为 (N, T, 2, 25, 3) 后,再 transpose 为 (N, 3, T, 25, 2)
# 最终维度含义:(样本, 坐标C=3, 帧T, 关节V=25, 人数M=2)
data = data.reshape((N, T, 2, 25, 3)).transpose(0, 4, 1, 3, 2)
# --- 对骨架进行空间对齐 ---
# align_skeleton 期望输入形状 (N, C, T, V, M)
aligned_data = align_skeleton(data) # 输出形状相同仍为 (N, 3, T, 25, 2)
# --- 将对齐后的数据转换回原始扁平格式 ---
# transpose 回 (N, T, 25, 2, 3) → (N, T, 2, 25, 3),再 reshape 为 (N, T, 150)
aligned_data = aligned_data.transpose(0, 2, 4, 3, 1).reshape(N, T, -1)
aligned_set[split] = aligned_data
# 保存对齐后的数据集,标签保持不变
np.savez(file.replace('.npz', '_aligned.npz'),
x_train=aligned_set['x_train'],
y_train=org_data['y_train'],
x_test=aligned_set['x_test'],
y_test=org_data['y_test'])
总结
该函数的作用是消除不同样本间由于拍摄角度造成的骨架朝向差异。
它读取预先生成的 NTU60 数据集(CS/CV 划分),对训练集和测试集的骨架数据进行空间旋转对齐,将对齐后的数据保存为新文件(文件名加 _aligned 后缀),标签不变。
关键维度变化
| 步骤 | 操作 | 形状变化 | 含义说明 |
|---|---|---|---|
| 1 | 原始数据加载 | (N, T, 150) |
N 样本,T 帧,每帧 150 维(2人 × 25关节 × 3坐标) |
| 2 | reshape |
(N, T, 2, 25, 3) |
分离出人数 M=2,关节数 V=25,坐标 C=3 |
| 3 | transpose(0,4,1,3,2) |
(N, 3, T, 25, 2) |
调整为 (N, C, T, V, M),适配 align_skeleton 的输入格式 |
| 4 | align_skeleton |
同输入 (N, 3, T, 25, 2) |
对每个样本、每个人的所有帧进行旋转对齐 |
| 5 | transpose(0,2,4,3,1) |
(N, T, 2, 25, 3) |
恢复为“帧优先”的布局:(N, T, M, V, C) |
| 6 | reshape(N, T, -1) |
(N, T, 150) |
展平回原始扁平格式,供模型使用 |
整个过程中 T(最大帧数)保持不变,N(样本数)不变,只是将每个关节的 (x,y,z) 坐标旋转到了一个统一的标准方向。
align_skeleton` 函数
def align_skeleton(data):
"""
对齐骨架:根据第一帧的脊柱和左右髋连线,构造局部坐标系,旋转所有帧使朝向统一。
输入: data (N, C, T, V, M) C=3, V=25, M=2
输出: 相同形状的对齐数据
"""
N, C, T, V, M = data.shape
trans_data = np.zeros_like(data) # (N, 3, T, 25, 2)
for i in tqdm(range(N)):
for p in range(M):
# 取出第i个样本、第p个人的所有帧 -> (C, T, V) = (3, T, 25)
sample = data[i][..., p]
# --- 计算局部坐标系的三个正交轴 (基于第一帧 t=0) ---
# 轴1:脊柱方向,从脊柱基部(0)指向脊柱中部(1)
v1 = sample[:, 0, 1] - sample[:, 0, 0] # (3,) - (3,) = (3,)
if np.linalg.norm(v1) <= 0.0:
continue # 零向量异常,跳过
v1 = v1 / np.linalg.norm(v1) # 单位化 -> (3,)
# 轴2参考向量:左右髋连线,从左髋(12)减右髋(16) -> 从右髋指向左髋的方向
v2_ = sample[:, 0, 12] - sample[:, 0, 16] # (3,) - (3,) = (3,)
# 将 v2_ 中与 v1 平行分量去掉,得到与脊柱正交的髋部方向
# 点积 (v1·v2_) 是标量,乘v1得投影向量 (3,)
proj_v2_v1 = np.dot(v1.T,v2_)*v1/np.linalg.norm(v1)
# proj_v2_v1 = np.dot(v1.T, v2_) * v1 # v1已是单位向量,无需再除模长
# v2 = v2_-np.squeeze(proj_v2_v1)
v2 = v2_ - proj_v2_v1 # (3,) - (3,) = (3,)
v2 = v2 / np.linalg.norm(v2) # 单位化 -> (3,)
# 轴3:由前两轴叉积得到,保证右手系
v3 = np.cross(v2, v1) # (3,) x (3,) = (3,)
v3 = v3 / np.linalg.norm(v3) # 单位化 -> (3,)
# 将三个轴向量转为列向量,方便拼成旋转矩阵
v1 = np.reshape(v1, (3, 1)) # (3,1)
v2 = np.reshape(v2, (3, 1)) # (3,1)
v3 = np.reshape(v3, (3, 1)) # (3,1)
# 旋转矩阵 R = [v2, v3, v1],列是标准基在原坐标系下的表示
R = np.hstack([v2, v3, v1]) # (3,1)拼成 (3,3)
# 对所有帧应用旋转(左乘 R^{-1} 将坐标转到新坐标系)
for t in range(T):
# sample[:, t, :] 是第t帧所有关节坐标,形状 (3, 25)
# R^{-1} @ (3,25) -> (3,25)
trans_sample = np.linalg.inv(R) @ sample[:, t, :] # (3,3) @ (3,25) = (3,25)
trans_data[i, :, t, :, p] = trans_sample # (3,25) 填入输出
return trans_data
这段代码的本质是:给每个动作片段"立正站好"。
想象你有一堆人在做同样的动作,但有人面向东、有人面向西、有人斜着站。如果你想比较他们的动作,得先把所有人都"摆正"——让每个人的脊柱都垂直向上,髋部都水平对齐。这就是这段代码在做的事。
1. 数据形状:一个"四维录像带"
输入 data 的形状是 (N, 3, T, 25, 2),可以这么理解:
| 维度 | 含义 | 形象比喻 |
|---|---|---|
| N | 样本数 | N 段不同的动作视频 |
| 3 | x, y, z | 三维空间坐标 |
| T | 帧数 | 每段视频有 T 个时间点 |
| 25 | 关节点 | 每帧有 25 个身体关键点(头、肩、肘、腕…) |
| 2 | 人数 | 每帧最多 2 个人(比如双人互动) |
所以 data[i][..., p] 就是第 i 段视频里第 p 个人的全部动作。
2. 构造"身体坐标系":以第一帧为基准
代码在第一帧(t=0)上"测绘"出这个人的身体本地坐标系,就像给每个人身上安装了一个隐形的"三脚架"。
第一根轴 v1:脊柱方向(“天轴线”)
v1 = sample[:, 0, 1] - sample[:, 0, 0]
- 关节 0 是脊柱基部(尾椎附近)
- 关节 1 是脊柱中部(胸口附近)
v1就是从下往上的脊柱方向,代表这个人"头顶朝向哪"
🎯 形象理解:想象一根筷子从尾椎插到胸口,
v1就是这根筷子的方向。
第二根轴 v2:髋部左右(“地平线”)
v2_ = sample[:, 0, 12] - sample[:, 0, 16]
- 关节 12 是左髋,关节 16 是右髋
v2_是从左髋指向右髋的原始方向
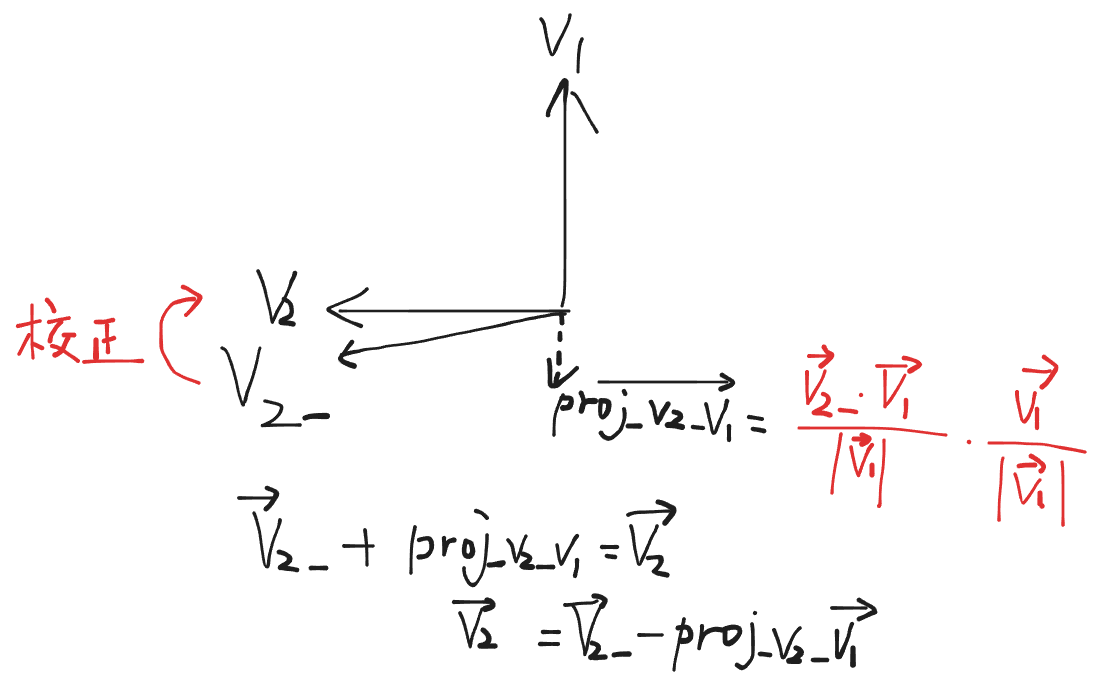
但这里有个问题:人站立时髋部连线不一定完全水平,可能有点上翘或前倾(比如弓背时)。所以代码做了一步**“掰正”**:
proj_v2_v1 = np.dot(v1.T, v2_) * v1 / np.linalg.norm(v1)
v2 = v2_ - proj_v2_v1
🎯 形象理解:把
v2_投影到v1上,就像把一根斜着的棍子往"天轴线"上靠,去掉那个倾斜分量,剩下的就是纯粹的水平左右方向。好比把一张歪了的桌子腿锯掉斜角,让它真正水平。
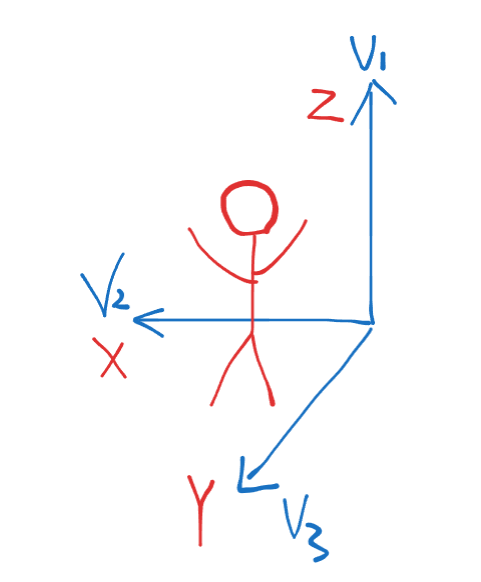
第三根轴 v3:前后方向(“右手定则”)
v3 = np.cross(v2, v1)
🎯 形象理解:伸出右手,食指指向
v2(左),中指指向v1(上),大拇指的方向就是v3(前)。这是数学上的右手螺旋定则,保证坐标系不"手性相反"(不会左右镜像)。
3. 拼成旋转矩阵:把"身体坐标系"变成标准方向
R = np.hstack([v2, v3, v1])
这里三列分别是:
- 第 1 列
v2→ 新坐标系的 X 轴(身体的左右) - 第 2 列
v3→ 新坐标系的 Y 轴(身体的前后) - 第 3 列
v1→ 新坐标系的 Z 轴(身体的上下)
🎯 形象理解:
R是一张"转换表",告诉你:在这个人原来的世界里,"左右/前后/上下"分别对应绝对空间的哪个方向。
4. 旋转所有帧:把所有人"摆正"
trans_sample = np.linalg.inv(R) @ sample[:, t, :]
这是最关键的一步。R 是"从身体坐标系看世界坐标系的转换矩阵",那么 R^{-1}(R 的逆矩阵)就是**“从世界坐标系看身体坐标系的转换矩阵”**。
🎯 形象理解:想象一个人面朝东北斜着站,你手里有一个"校正框"(
R^{-1})。你把框套在他身上,转一转,他就变成了面朝正前方、站得笔直的标准姿势。不管原来朝向哪里,经过这一转,所有人的脊柱都朝上,髋部都水平,面朝同一个方向。
对每一帧 t 都做这个操作,所以整个动作序列都被统一到了同一个"标准身体坐标系"下。
5. 形象总结
| 步骤 | 生活比喻 |
|---|---|
| 取脊柱 | 找到人的"头顶到尾椎的中轴线" |
| 取髋部 | 找到人的"左右胯骨连线" |
| 正交化 | 把歪掉的胯骨连线"掰平",确保 truly 水平 |
| 叉积得第三轴 | 用右手定则确定"面朝哪" |
| 拼旋转矩阵 | 制作一个"校正框" |
| 逐帧旋转 | 把整个人像转魔方一样转到标准朝向 |
最终效果:原本东倒西歪的各种动作样本,全部变成了"立正站好"的统一姿态。这样后续做动作识别、相似度比较时,就不会因为"朝向不同"而误判了。
问题1
v1 = v1/np.linalg.norm(v1)
v2_ = sample[:,0,12]-sample[:,0,16]
proj_v2_v1 = np.dot(v1.T,v2_)*v1/np.linalg.norm(v1) #这个地方求投影的公式我忘了是怎么样的
v2 = v2_-np.squeeze(proj_v2_v1) # np.squeeze是什么意思?为什么要np.squeeze
v2 = v2/(np.linalg.norm(v2))
v3 = np.cross(v2,v1)/(np.linalg.norm(np.cross(v2,v1))) # np.cross是什么意思?是求与v2、v1正交的轴吗?
源代码这两句我不理解:
proj_v2_v1 = np.dot(v1.T,v2_)*v1/np.linalg.norm(v1)
v2 = v2_-np.squeeze(proj_v2_v1)
回答1
这三个问题都触及了线性代数在代码里的具体落地,我逐个拆解:
1. 投影公式 proj_v2_v1
数学原理
把向量 v2_ 投影到 v1 方向上的标准公式是:
proj v 1 ( v 2 _ ) = v 2 _ ⋅ v 1 ∥ v 1 ∥ 2 ⋅ v 1 \text{proj}_{\mathbf{v_1}}(\mathbf{v_2\_}) = \frac{\mathbf{v_2\_} \cdot \mathbf{v_1}}{\|\mathbf{v_1}\|^2} \cdot \mathbf{v_1} projv1(v2_)=∥v1∥2v2_⋅v1⋅v1
如果 v1 已经是单位向量(前面做了 v1 = v1/||v1||),那么 ∥ v 1 ∥ = 1 \|\mathbf{v_1}\| = 1 ∥v1∥=1,公式简化为:
proj v 1 ( v 2 _ ) = ( v 2 _ ⋅ v 1 ) ⋅ v 1 \text{proj}_{\mathbf{v_1}}(\mathbf{v_2\_}) = (\mathbf{v_2\_} \cdot \mathbf{v_1}) \cdot \mathbf{v_1} projv1(v2_)=(v2_⋅v1)⋅v1
代码对应
np.dot(v1.T, v2_) # 对应数学上的点积 v2_ · v1,结果是一个标量
* v1 # 标量 × 向量 v1,方向与 v1 相同,长度被缩放
/ np.linalg.norm(v1) # 再除以 v1 的模长
注意:因为前面已经 v1 = v1/np.linalg.norm(v1) 把 v1 单位化了,所以这里 np.linalg.norm(v1) 实际上就是 1.0。除以它等于没除,是多余的,但也不会错。
如果
v1没有提前单位化,那代码就有 bug 了——应该除以np.linalg.norm(v1)**2(模长的平方),而不是只除以np.linalg.norm(v1)。
形象理解
想象 v1 是一根笔直的电线杆,v2_ 是一根斜着的木棍。投影就是把木棍的影子投到电线杆上,得到一段与电线杆重合的线段。代码做的就是算出这段影子的长度和方向,然后把它从原木棍上抠掉,剩下的就是垂直于电线杆的分量(即 v2)。
2. np.squeeze 是什么意思?为什么要用?
作用
np.squeeze() 把数组里所有长度为 1 的维度删掉。
| 输入形状 | squeeze 后 |
形象解释 |
|---|---|---|
(3, 1) |
(3,) |
3 行 1 列的"竖条" → 压扁成 1D 数组 |
(1, 3) |
(3,) |
1 行 3 列的"横条" → 压扁成 1D 数组 |
(1, 3, 1, 1) |
(3,) |
把所有"1"都删掉 |
为什么要用在这里?
问题在于 NumPy 的广播机制(broadcasting) 和形状不匹配。
如果代码执行到这一步时,v1 已经被提前 reshape 成了列向量 (3, 1)(而不是原来的 (3,)),那么:
np.dot(v1.T, v2_) # v1.T 是 (1,3),v2_ 是 (3,) → 结果可能是 (1,) 或标量
* v1 # 再乘 v1(3,1) → 结果变成 (3, 1) 的二维列向量
此时 proj_v2_v1 的形状是 (3, 1),而 v2_ 的形状是 (3,)。虽然 NumPy 广播规则下有时能自动处理,但经常会在某些操作里报 ValueError: operands could not be broadcast together,或者得到意料之外的 (3, 3) 广播结果。
np.squeeze(proj_v2_v1) 就是强制把它从 (3, 1) 压回 (3,),确保和 v2_ 形状一致,可以安全地做逐元素减法。
如果你确定
v1还是 1D(3,),squeeze其实可有可无;但如果前面不小心把v1reshape 成了(3,1),那squeeze就是救命稻草。
3. np.cross 是什么意思?是求正交轴吗?
数学原理
np.cross(v2, v1) 计算的是叉积(Cross Product)。
叉积的结果是一个新向量,它同时垂直于 v2 和 v1。也就是说:
v 3 = v 2 × v 1 ⇒ v 3 ⊥ v 2 且 v 3 ⊥ v 1 \mathbf{v_3} = \mathbf{v_2} \times \mathbf{v_1} \quad\Rightarrow\quad \mathbf{v_3} \perp \mathbf{v_2} \text{ 且 } \mathbf{v_3} \perp \mathbf{v_1} v3=v2×v1⇒v3⊥v2 且 v3⊥v1
方向怎么定?右手定则
伸出你的右手:
- 食指指向
v2的方向(身体的左右方向) - 中指指向
v1的方向(身体的上下方向) - 大拇指翘起的方向就是
v3的方向(身体的前后方向)
这就是右手坐标系,保证三个轴不会拧成"左手系"(避免镜像翻转)。
代码里的作用
v3 = np.cross(v2, v1) / (np.linalg.norm(np.cross(v2, v1)))
因为 v2 和 v1 已经单位化且互相垂直,它们的叉积长度理论上已经是 1,但浮点运算可能有微小误差,所以再除一次模长做保险单位化。
形象理解
v2(左右)和 v1(上下)像两根筷子搭成一个"十"字,但还缺一根垂直于桌面的筷子才能把三维空间撑起来。np.cross 就是自动算出这第三根筷子的方向,而且确保三根筷子构成一个标准的、不歪的坐标架。
一句话总结
| 代码片段 | 本质作用 |
|---|---|
np.dot(...) * v1 / norm(v1) |
求 v2_ 在 v1 方向上的"影子"(投影) |
np.squeeze(...) |
把 (3,1) 列向量压扁成 (3,),防止形状冲突 |
np.cross(v2, v1) |
用右手定则生成同时垂直于 v2 和 v1 的第三根轴 |
问题2
投影公式怎么理解?我怎么好像没学过这个公式
回答2
你可能学过,只是当时叫**“力的分解"或者"求影子长度”**,没叫"向量投影"这个名字。
1. 先忘掉公式,看影子
想象一个场景:
正午的太阳直射下来(光线垂直地面),你拿一根斜着的竹竿(
v2_)立在电线杆(v1)旁边。竹竿在电线杆上投下的影子,就是
v2_在v1方向上的投影。
代码要干的事:把竹竿拆成两部分
- 一部分顺着电线杆(投影,要去掉的部分)
- 另一部分垂直于电线杆(我们想要的
v2)
2. 影子长度怎么算?(核心直觉)
假设:
- 电线杆
v1高 1 米(已单位化) - 竹竿
v2_长 2 米,与电线杆夹角 60°
影子有多长?
初中物理/几何就会算:
影子长度 = 2 × cos ( 60 ° ) = 1 米 \text{影子长度} = 2 \times \cos(60°) = 1 \text{ 米} 影子长度=2×cos(60°)=1 米
这个 长度 × cosθ,就是标量投影(只有长度,没有方向)。
3. 从几何到代数:为什么公式是那个样子?
公式:
proj = v 2 _ ⋅ v 1 ∥ v 1 ∥ 2 ⋅ v 1 \text{proj} = \frac{\mathbf{v2\_} \cdot \mathbf{v1}}{\|\mathbf{v1}\|^2} \cdot \mathbf{v1} proj=∥v1∥2v2_⋅v1⋅v1
拆开看,它其实就三步:
第一步:点积求"影子长度"
v 2 _ ⋅ v 1 = ∥ v 2 _ ∥ ∥ v 1 ∥ cos θ \mathbf{v2\_} \cdot \mathbf{v1} = \|\mathbf{v2\_}\| \|\mathbf{v1}\| \cos\theta v2_⋅v1=∥v2_∥∥v1∥cosθ
这等于:竹竿长度 × 电线杆长度 × cos夹角
第二步:除以电线杆长度的平方
v 2 _ ⋅ v 1 ∥ v 1 ∥ 2 = ∥ v 2 _ ∥ cos θ ∥ v 1 ∥ \frac{\mathbf{v2\_} \cdot \mathbf{v1}}{\|\mathbf{v1}\|^2} = \frac{\|\mathbf{v2\_}\| \cos\theta}{\|\mathbf{v1}\|} ∥v1∥2v2_⋅v1=∥v1∥∥v2_∥cosθ
这等于:影子长度 ÷ 电线杆长度,得到一个比例系数(纯数字,无单位)。
如果电线杆是 1 米(单位向量),那这就是影子长度本身。
第三步:乘以电线杆方向
⋯ × v 1 \cdots \times \mathbf{v1} ⋯×v1
把刚才那个数字(比例系数)乘回电线杆向量,就得到了带方向的影子向量——它指向和 v1 相同的方向,长度正好是影子长度。
4. 对照代码
# 数学:proj = (v2_·v1 / ||v1||^2) * v1
# 代码:
proj_v2_v1 = np.dot(v1.T, v2_) * v1 / np.linalg.norm(v1)
这里有个小问题:代码里 v1 前面已经单位化了(v1 = v1/np.linalg.norm(v1)),所以 np.linalg.norm(v1) 实际上是 1。
严格来说,如果 v1 没提前单位化,这里应该除以 np.linalg.norm(v1)**2(平方),而不是只除以一次 norm(v1)。
但因为前面已经单位化了,除以 1 等于没除,所以结果碰巧是对的——只是写法不够严谨。
5. 一句话总结
投影 = “影子长度” × “电线杆方向”
代码先算 np.dot(v1.T, v2_) 得到影子相关的数,再乘 v1 赋予方向,最后从原向量 v2_ 里扣掉这个影子,剩下的就是垂直分量 v2。
这就是你中学可能学过的**“正交分解”**,只是当时没往向量投影这个名字上想。
问题3
没理解你第3点什么逻辑,按照我的理解,假设v1和v2是钝角关系,它们的投影就是v1的反向延长线P跟v2的夹角theta1, cos(theta1)=p/v2, 可得p=v2乘以cos(theta1),cos(theta1)怎么求?它是有定义吗?
回答3
你的直觉完全正确,而且比很多人想得还深!钝角时投影确实是负的,方向与 v1 相反。 这个"反向延长线上的影子"的理解非常到位。
你卡在的地方其实是:cosθ 不用你单独去求角度再算,点积 a·b 的定义本身就自带了 cosθ。
1. 你熟悉的定义,换个名字
你学过这个吧?
a ⋅ b = ∣ a ∣ ∣ b ∣ cos θ \mathbf{a} \cdot \mathbf{b} = |\mathbf{a}| |\mathbf{b}| \cos\theta a⋅b=∣a∣∣b∣cosθ
这就是**点积(内积)**的定义。它直接告诉你:
cos θ = a ⋅ b ∣ a ∣ ∣ b ∣ \cos\theta = \frac{\mathbf{a} \cdot \mathbf{b}}{|\mathbf{a}| |\mathbf{b}|} cosθ=∣a∣∣b∣a⋅b
不需要先算角度 θ,再查表求 cos。 只要算出点积,除以两个向量的长度,自然得到 cosθ。
2. 套到你的钝角场景
假设 v1 和 v2_ 夹角是钝角(比如 120°):
| 步骤 | 计算 | 结果 |
|---|---|---|
| 点积 | v2_ · v1 |
负数(因为 cos120° = -0.5) |
| 影子长度 | `(v2_ · v1) / | v1 |
| 投影向量 | ... * v1 |
与 v1 反向 |
所以那个"反向延长线上的点 P"自动就出来了,不需要你额外判断钝角还是锐角。点积的符号自带方向信息:
- 点积 > 0 → 锐角,投影与
v1同向 - 点积 = 0 → 直角,投影为零
- 点积 < 0 → 钝角,投影与
v1反向(就是你说的反向延长线)
3. 回到投影公式:其实就两步
你理解的 p = |v2| × cosθ 是对的。代码公式只是把它包装成了向量形式:
proj = ( v 2 _ ⋅ v 1 ∣ v 1 ∣ ) ⏟ 带符号的影子长度 p × v 1 ∣ v 1 ∣ ⏟ v1 的单位方向 \text{proj} = \underbrace{\left(\frac{\mathbf{v2\_} \cdot \mathbf{v1}}{|\mathbf{v1}|}\right)}_{\text{带符号的影子长度 } p} \times \underbrace{\frac{\mathbf{v1}}{|\mathbf{v1}|}}_{\text{v1 的单位方向}} proj=带符号的影子长度 p (∣v1∣v2_⋅v1)×v1 的单位方向 ∣v1∣v1
拆开看:
- 分子
v2_ · v1=|v2_||v1|cosθ - 除以
|v1|后 =|v2_|cosθ→ 这就是你熟悉的 p(可正可负!) - 再乘
v1/|v1|→ 给 p 配上方向(v1 的正向或反向)
4. 形象总结
点积就像一把自动测角仪兼计算器。你不需要知道 θ 具体是多少度,也不需要查 cos 表,只要做一遍点积,它自动把 “长度 × cosθ” 的结果(带正负号)塞给你。
钝角时它自动给你负数,负数乘上 v1 的方向,自然指向反向延长线——完全吻合你的直觉。
所以不是"cos 怎么求、有没有定义"的问题,而是:点积的定义已经把 cos 包进去了,你算点积的时候就已经同时算出了 cosθ。
问题4
但是源代码是np.dot(v1.T,v2_) 而不是np.dot(v2_, v1),为什么?
回答4
数学上没区别,代码写 v1.T 是作者在用"矩阵乘法"的数学记号表达习惯。
1. 数学上:点积天然满足交换律
v 1 ⋅ v 2 _ = v 2 _ ⋅ v 1 \mathbf{v_1} \cdot \mathbf{v_2\_} = \mathbf{v_2\_} \cdot \mathbf{v_1} v1⋅v2_=v2_⋅v1
所以 np.dot(v1, v2_)、np.dot(v2_, v1)、np.dot(v1.T, v2_) 在这个场景下数值结果完全一样。
2. 那为什么源代码偏要写 v1.T?
因为这是线性代数课本上的标准写法:
v 1 ⊤ v 2 _ \mathbf{v_1}^\top \mathbf{v_2\_} v1⊤v2_
在数学教材里:
- 向量默认是列向量(竖着写的)
- 求内积时,要先把左边那个转置成行向量,再乘以右边的列向量
- 这样写出来是标准的矩阵乘法形式:
(1×3) · (3×1) = 标量
作者写 np.dot(v1.T, v2_) 其实是在模仿这个数学记号,尽管 NumPy 里 1D 数组转置 .T 并不会改变形状。
3. 关键前提:v1 此时还是 1D 的 (3,)
看源代码顺序:
v1 = v1 / np.linalg.norm(v1) # 此时 v1 是 1D,shape=(3,)
# ...
proj_v2_v1 = np.dot(v1.T, v2_) * v1 # v1.T 对 1D 数组无效,还是 (3,)
v1 要到很后面才被 reshape 成 (3,1),所以此时 v1.T 纯粹是写法上的仪式感,实际效果和 np.dot(v2_, v1) 没任何区别。
4. 如果 v1 已经 reshape 了呢?
假设 v1 被提前变成了 (3, 1) 的列向量:
| 写法 | 实际运算 | 结果形状 |
|---|---|---|
np.dot(v1.T, v2_) |
(1,3) @ (3,) |
(1,) |
np.dot(v2_, v1) |
(3,) @ (3,1) |
(1,) |
结果仍然一样,但数学意义不同:
v1.T @ v2_→ 行向量乘列向量(标准内积写法)v2_ @ v1→ 向量乘矩阵(NumPy 自动把v2_当行向量)
一句话总结
写
v1.T不是 NumPy 语法需要,而是数学审美习惯——作者在用"行向量乘列向量"的矩阵乘法形式表达内积。因为点积有交换律,所以写v2_在前还是在后,结果都一样。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0


 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)