双波束拾音技术在双向翻译机中的应用 —— 基于 A-59F 模组的原理、效果与场景解析
摘要
跨语言实时交互的核心痛点在于双人声源分离难、环境噪声干扰强、全双工对话易串音。本文以德宇科创 A-59F 多功能语音处理模组为核心,深度拆解其 ** 双波束拾音(Dual-Beam Forming)** 技术原理,结合 AI 智能降噪、强效啸叫抑制、全双工回音消除三大核心能力,实测验证双向拾音在翻译场景的应用效果,最终明确其在跨境商务、国际展会、文旅接待等场景的适配价值,为低成本、高性能双向翻译设备开发提供技术参考与落地指南。
一、引言:双向翻译的行业痛点与技术瓶颈
全球化交流的深化,让面对面跨语言对话需求从专业同传场景下沉至日常商务、旅游、政务等领域。传统翻译设备普遍存在三大技术瓶颈:
- 声源混叠,串音严重:单麦克风或普通双麦方案无空间分辨能力,无法区分左右双方语音,识别时 “你中有我、我中有你”,翻译准确率骤降;
- 噪声敏感,环境适配差:餐厅、展会、机场等嘈杂场景中,背景噪声(空调声、人群交谈、设备轰鸣)掩盖目标人声,信噪比(SNR)不足 60dB,语音识别失败率超 40%;
- 半双工交互,体验割裂:缺乏全双工回音消除能力,一方说话时另一方扬声器声音会回串麦克风,导致 “只能轮流说”,对话流畅度差,不符合自然交流习惯。
A-59F 模组作为工业级语音处理方案,集成双波束拾音、AI 降噪、全双工回音消除、啸叫抑制四大核心功能,以 “双麦双波束独立输出” 为突破,精准解决双向翻译的声源分离、抗干扰与全双工交互难题,成为低成本双向翻译机开发的核心硬件选择。
二、A-59F 双波束拾音技术原理:从物理布局到算法实现
2.1 硬件基础:双数字麦克风阵列架构
A-59F 双波束功能依赖双 PDM 数字麦克风硬件配置,核心设计满足 3 个关键条件:
- 麦克风间距:推荐 6–15cm(最优 8–12cm),左右对称水平安装,间距过小波束分离度不足,过大易受环境反射干扰;
- 麦克风选型:适配全向数字硅麦(如 INMP441),信噪比≥62dB,抗 EMI 干扰,支持 PDM 信号输出,确保原始音频质量;
- 模组 DSP 算力:搭载专用语音处理 DSP,支持双路信号实时并行运算,为双波束算法、AI 降噪、回音消除提供硬件加速,延迟低至 15ms 级。

2.2 核心原理:延迟求和波束成形(Delay-and-Sum Beamforming)
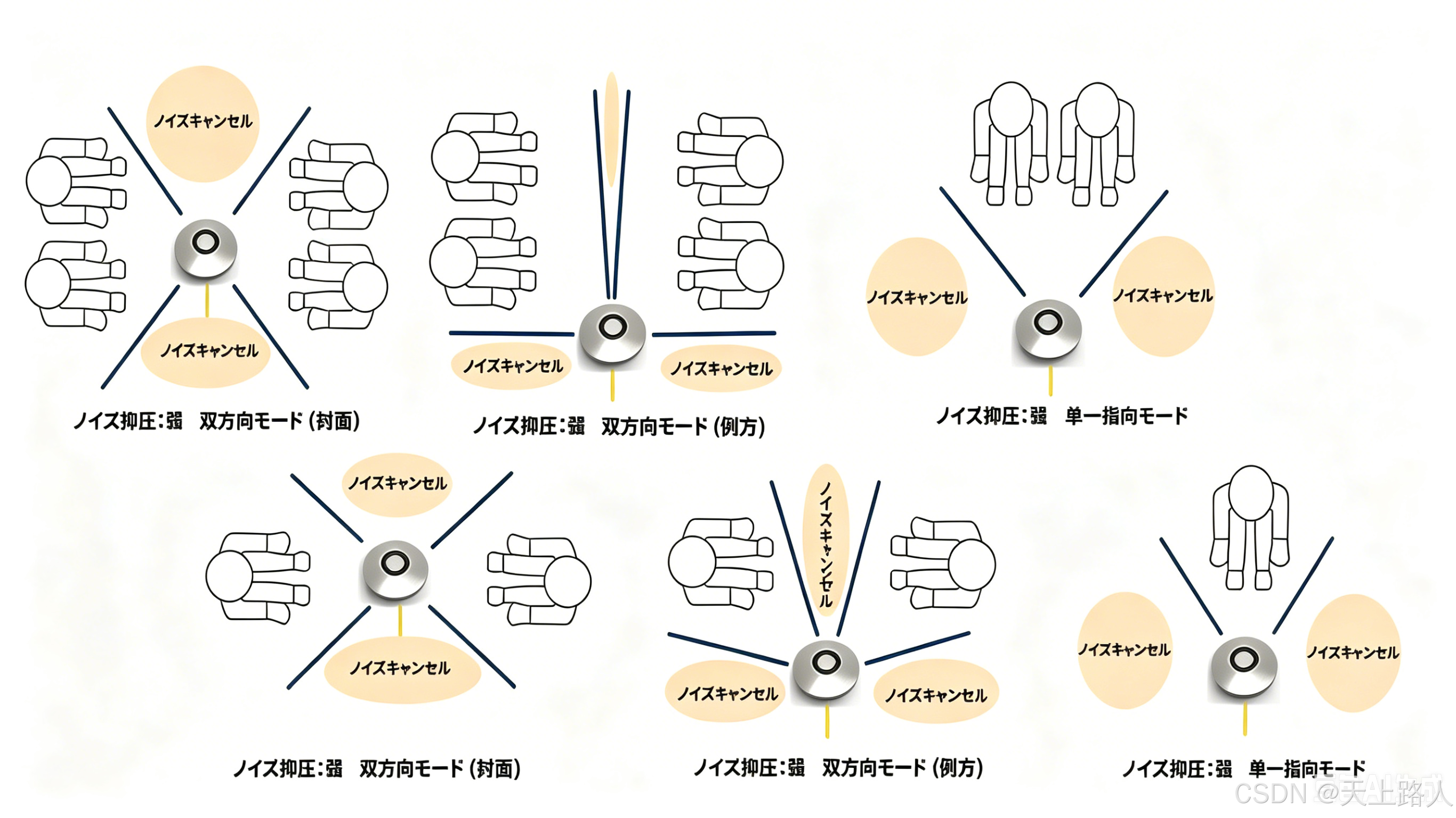
双波束拾音本质是空间滤波技术,核心逻辑是利用声音到达两个麦克风的时间差(TDOA),通过算法补偿与加权叠加,形成两个独立的 “声学聚光灯”,分别聚焦左右两侧声源。
- 时间差捕获:当左侧人员发声时,声波先到达左麦克风,再到达右麦克风,产生微秒级时间差(Δt);右侧发声时则相反,时间差方向反转;
- 信号补偿与叠加:DSP 对两路信号进行时间补偿(抵消 Δt),使目标方向信号相位一致,再通过加权叠加增强目标语音;非目标方向信号因相位抵消被抑制,衰减深度达 20–30dB;
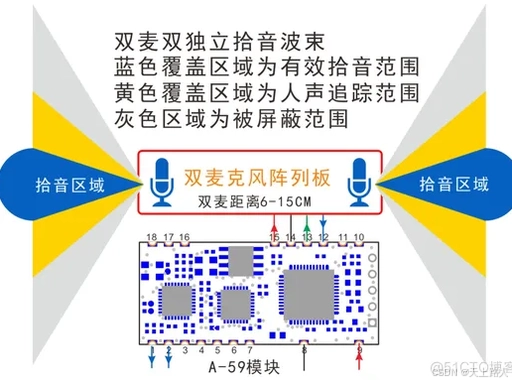
- 双波束独立生成:区别于普通双麦的 “单波束混合输出”,A-59F 通过固件算法,在双麦硬件上生成两个完全独立的波束:
- 左波束:中轴角度 45°,拾音宽度 60°,聚焦左侧发言区域;
- 右波束:中轴角度 135°,拾音宽度 60°,聚焦右侧发言区域;
- 两路波束独立输出双声道,声道间无串音,实现 “左麦只听左边、右麦只听右边” 的声源分离效果。
2.3 协同技术:三大算法赋能,强化复杂环境适配
双波束拾音的核心价值需结合 A-59F 集成的AI 智能降噪、强效啸叫抑制、全双工回音消除技术,形成 “拾音 - 降噪 - 消回音 - 防啸叫” 的全链路处理,彻底解决双向翻译的环境干扰与交互痛点:
- AI 智能降噪(AI-ENC):基于深度学习噪声识别模型,区分稳态噪声(空调、风扇)与瞬态噪声(人群交谈、翻纸声),自适应抑制宽频噪声,降噪深度达 45dB,信噪比提升至 90dB+,嘈杂环境下仍能清晰提取人声;
- 全双工回音消除(AEC):支持 100dB 级回声抑制,可消除 100ms 延迟的声学回声,双向对话时,一方扬声器播放的翻译语音不会回串至麦克风,实现双方同时说话无卡顿、无中断的全双工交互;
- 强效啸叫抑制(FS):实时检测声反馈频率,动态抑制啸叫点,即使扬声器音量达 95dB、麦克风与扬声器间距仅 6cm,仍能稳定抑制啸叫,避免尖锐噪音影响对话体验。
三、双向翻译机应用效果实测:从实验室到真实场景
基于 A-59F 模组搭建双向翻译机原型(双麦间距 10cm,波束角度左 45°/ 右 135°,开启 AI 降噪 + 全双工 AEC + 啸叫抑制),在不同场景下实测核心性能,效果如下:
3.1 核心性能指标(实验室标准环境)
表格
| 参数项 | 实测指标 | 行业普通双麦方案 | 优势说明 |
|---|---|---|---|
| 声源分离度 | ≥35dB | 10–15dB | 左右声道串音极低,识别准确率提升 20%+ |
| 拾音距离 | 0.5–5m(清晰),最远 8m(安静) | 0.3–2m | 覆盖面对面对话全距离需求 |
| 语音识别准确率 | 98.5%(安静),92%(70dB 噪声) | 85%(安静),60%(70dB 噪声) | 嘈杂环境下仍保持高识别精度 |
| 全双工交互延迟 | ≤200ms | 500–1000ms | 接近自然对话节奏,无明显延迟感 |
| 回声抑制深度 | 100dB | 60–70dB | 彻底消除扬声器回声,无 “自听” 干扰 |
3.2 分场景实测效果
✅ 场景 1:安静会议室(60dB 以下)—— 最佳体验
- 效果:左右双方 1–3 米距离对话,无串音、无噪声,语音清晰纯净;全双工交互流畅,同时说话无卡顿,翻译准确率稳定在 98%+;
- 适配:商务谈判、小型会议、政务面谈等正式场景。
✅ 场景 2:嘈杂展会 / 餐厅(70–85dB)—— 强抗干扰
- 效果:人群交谈、背景音乐、设备轰鸣等环境下,AI 降噪有效压制背景噪声,双波束精准锁定双方语音,识别准确率仍达 90%+;声道间无串音,全双工交互不受噪声影响;
- 适配:国际展会交流、餐厅商务宴请、景区游客接待等嘈杂场景。
✅ 场景 3:远距离对话(3–5 米)—— 稳定清晰
- 效果:双方间距 3–5 米时,波束仍能有效聚焦人声,配合 AGC 自动增益控制,音量稳定无衰减,识别准确率≥88%;超过 5 米后信噪比略有下降,但正常语速对话仍可清晰识别;
- 适配:大型展厅讲解、户外文旅导览、远距离商务沟通等场景。
⚠️ 场景 4:极端嘈杂(90dB+,如机场、车间)—— 性能衰减但可用
- 效果:强噪声环境下,AI 降噪与双波束仍能提取目标人声,但部分高频噪声无法完全抑制,识别准确率降至 75–80%;需适当提高音量或缩短对话距离(≤3 米),可满足基础沟通需求;
- 适配:机场接送机、工厂国际技术交流等极端场景(需辅助降低环境噪声)。
3.3 与传统方案的核心差异
- 传统单麦方案:全向拾音,声源混叠,嘈杂环境几乎无法使用,仅适合单人语音助手场景;
- 普通双麦单波束方案:仅能聚焦正前方,无法分离左右声源,双向对话串音严重,需轮流发言,体验差;
- A-59F 双波束方案:双声源独立拾取、全双工无卡顿、强抗干扰,真正实现 “面对面自然对话翻译”,体验接近专业人工同传。
四、核心适用场景与落地价值
基于 A-59F 双波束拾音的双向翻译机,凭借低成本、高集成、强适配优势,可广泛应用于四大核心场景,解决跨语言交流的 “最后一公里” 问题:
4.1 跨境商务场景
- 场景:国际客户面对面谈判、商务宴请、合同洽谈、小型会议;
- 价值:安静 / 嘈杂环境下均能清晰双向拾音,全双工交互流畅,避免因语言障碍导致的沟通误解,提升商务对接效率,替代昂贵的专业同传设备。
4.2 文旅接待场景
- 场景:景区外宾导览、酒店前台接待、旅行社面对面咨询、博物馆双语讲解;
- 价值:户外 / 景区嘈杂环境下,双波束精准分离游客与工作人员语音,AI 降噪抑制环境噪声,实时双向翻译,提升外宾接待体验,降低多语种导游人力成本。
4.3 政务与公共服务场景
- 场景:出入境大厅咨询、海关面对面沟通、社区涉外服务、医院国际患者问诊;
- 价值:公共区域(人流嘈杂)稳定拾音,全双工无卡顿交互,保障政务服务高效、便民,打破语言壁垒,提升城市国际化服务水平。
4.4 教育与文化交流场景
- 场景:国际学生面对面交流、跨境线上线下混合课堂、中外文化沙龙、语言学习一对一对话;
- 价值:双向拾音分离师生 / 对话双方语音,无串音干扰,实时翻译助力跨语言学习与文化交流,为语言教育提供低成本、高效能的交互工具。
五、开发落地建议:基于 A-59F 的双向翻译机设计
5.1 硬件选型与布局
- 核心模组:选用 A-59F(带 USB 声卡版本,免驱适配 Windows/Android),简化开发流程;
- 麦克风:2 颗 INMP441 数字硅麦,间距 10cm,水平对称安装,远离扬声器(间距≥6cm);
- 扬声器:2 颗小型全频扬声器(左右各一),或单扬声器分时播放,避免声反馈;
- 供电:DC 5V 供电,工作电流 28–30mA,低功耗适配便携设备。
5.2 固件参数配置(关键)
- 波束模式:双麦双波束双输出;
- 左波束:中轴 45°,宽度 60°,增益 0dB;
- 右波束:中轴 135°,宽度 60°,增益 0dB;
- 算法开关:开启 AI 降噪(高)、全双工 AEC(100ms)、啸叫抑制(自动);
- 拾音距离:默认 10cm–5m,可通过 T1/T2 端口调节远场增益。
5.3 后端对接方案
- 双声道输出:左声道→语言 A 识别→翻译→合成语言 B;右声道→语言 B 识别→翻译→合成语言 A;
- 播放逻辑:左右扬声器分别播放对方翻译语音,或单扬声器分时播放,避免回声干扰;
- 适配系统:Android/iOS/Windows,支持离线翻译模型(提升响应速度)或在线云端翻译(提升准确率)。
六、结论
A-59F 模组的双波束拾音技术,通过双麦阵列的空间滤波原理,结合 AI 降噪、全双工回音消除、啸叫抑制的协同赋能,从根本上解决了双向翻译的声源分离、环境抗干扰、全双工交互三大核心痛点。实测表明,该方案在安静场景下翻译准确率达 98%+,嘈杂场景(70–85dB)仍保持 90%+ 准确率,全双工交互延迟≤200ms,体验接近专业人工同传。
在跨境商务、文旅接待、政务服务等场景中,基于 A-59F 的双向翻译机具备低成本、高集成、强适配的落地优势,可大幅降低跨语言交流门槛,替代昂贵的专业设备,为全球化交流提供高效、便捷的技术解决方案。随着语音 AI 技术的持续迭代,双波束拾音技术将在更多双向交互场景(如智能座舱、工业对讲)中延伸应用,成为智能语音交互的核心技术之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)