谷歌面试官:“以后面试都允许用 Gemini。” 我:“那还考什么?” 面试官:“考你会不会被 AI 带沟里。”
代码面开 AI,不是开卷考
今天鸭鸭刷到一条挺有意思的招聘新闻。
外媒 Business Insider 报道称,谷歌内部文件显示,从今年下半年起,计划在软件工程师招聘的“代码理解”面试环节,允许候选人使用谷歌官方认证的 AI 助手;试点阶段将统一使用自研模型 Gemini。谷歌发言人向媒体证实了这一安排。
报道里写得很具体:候选人要在现有代码库里做阅读、排错和优化;面试官会重点看“AI 应用熟练度”,包括提示词工程、对 AI 输出结果的核验,以及调试能力。谷歌把整套新流程定调为“人为主导、AI 辅助”,说是想更贴近生成式 AI 时代工程师的真实工作状态。
试点会先落在美国部分团队,面向初、中级岗位,谷歌云以及平台与设备等业务线会先试。如果跑得顺,再扩到更多业务和地区。
嗯,读到这儿很多人第一反应可能是:那不就是开卷吗。
但鸭鸭想先把话说在前面:
允许带 Gemini 进考场,不等于题目变简单。它更像把考场从“默写语法”挪到“带一个会瞎编的实习生一起干活”。你不会验,他写得越快,你死得越快。
为啥鸭鸭会这么看?
第一,代码理解本来就不是比谁敲得快。陌生仓库里找 bug、理调用链、判断一次改动会不会牵一发而动全身,这些活以前靠手写思路;现在多了一条:你得判断 AI 给你的“捷径”是不是在抄近道抄进沟里。
第二,报道里提到的考核点,其实是在把工程师拆成两半。一半是“会不会指挥 AI”,提示词怎么写、上下文怎么给、约束怎么说清楚;另一半是“敢不敢签字”,AI 改完你敢不敢说这版能合、能发、能背锅。缺一半,面试里都会露馅。
第三,这事不是谷歌一家自嗨。报道里还提到,澳大利亚公司 Canva 早在 2025 年 6 月就要求相关岗位候选人在技术面试里必须用 Copilot、Cursor 或 Claude 这类工具。美国 AI 编程公司 Cognition 也对 Business Insider 表示,已经把 AI 使用纳入面试流程,还把“面试禁用 AI”比作“让孩子不带计算器参加数学考试”。行业方向很直白:以后默认工作流里就有 AI,面试还在假装没有 AI,反而失真。
第四,皮查伊在 2026 年 4 月 22 日谷歌 Cloud Next 活动上说过,谷歌内部约 75% 的新代码由 AI 生成。这个数字不是用来吓唬人的,是用来解释公司为什么要改面试题。公司真正想问的是:当 AI 能吐出海量代码时,你还剩下什么不可替代的判断力。
那这事儿对正在准备面试的人意味着啥?
鸭鸭说几句实在话。
- 别把“会用 AI”理解成“会点生成”:面试里更值钱的是你怎么拆问题、怎么限定 AI 的发挥范围、怎么对输出做对照验证。会点生成的人一抓一把,敢验收的人不多。
- 刻意练“读陌生代码 + 小步验证”:给自己找一段不熟悉的开源模块,先用 AI 生成三种改法,再逐条对照测试用例、边界条件和性能影响。练的是肌肉记忆,不是 prompt 玄学。
- 准备一两个“AI 翻过车”的真实例子:面试里能讲清楚你怎么发现 AI 给的建议不靠谱、你怎么纠偏,比背八股更像高级工程师。
- 心态上把它当成开卷里的闭卷:卷子是开的,评分标准没开。公司要的是你能不能把 AI 的产出变成可上线的结果。
大家怎么看?如果国内大厂跟进“代码理解环节允许官方 AI”,你觉得公平吗,还是更卷了?欢迎评论区聊聊~
……
今天鸭鸭和大家分享一道 AI 大模型面试题。
【什么是大模型微调?与预训练的核心区别是什么? 】
回答重点
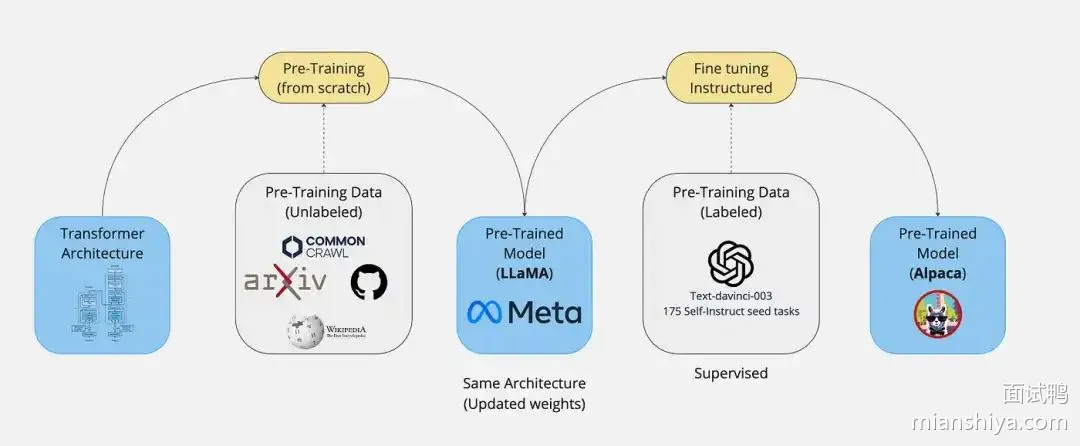
大模型微调就是在预训练模型的基础上,用特定任务的数据对模型做二次训练,让它从"通才"变成某个领域的"专家"。
跟预训练的核心区别有三点:
1)目标不同。预训练是让模型学通用的语言理解能力,在几百 GB 甚至几 TB 的通用语料上训练,比如维基百科、书籍、网页。微调是让模型适应特定任务,比如情感分析、代码生成、医疗问答,用的是跟任务相关的小规模标注数据
2)数据规模差异大。预训练动辄用几万亿 token 的数据,训练成本是几百万甚至上千万美元。微调可能只需要几千到几十万条标注样本,几张 A100 跑几个小时就能搞定
3)学习方式不同。预训练主要是自监督学习,让模型预测下一个 token 或者还原被遮盖的词,不需要人工标注。微调通常是监督学习,需要输入输出配对的标注数据
扩展知识
为什么需要微调
预训练模型虽然能力强,但它学的是通用知识,面对特定场景还是差点意思。比如用 GPT 直接做法律合同审查,它可能连行业术语都理解不准;用它做客服问答,回复风格可能跟公司调性对不上。
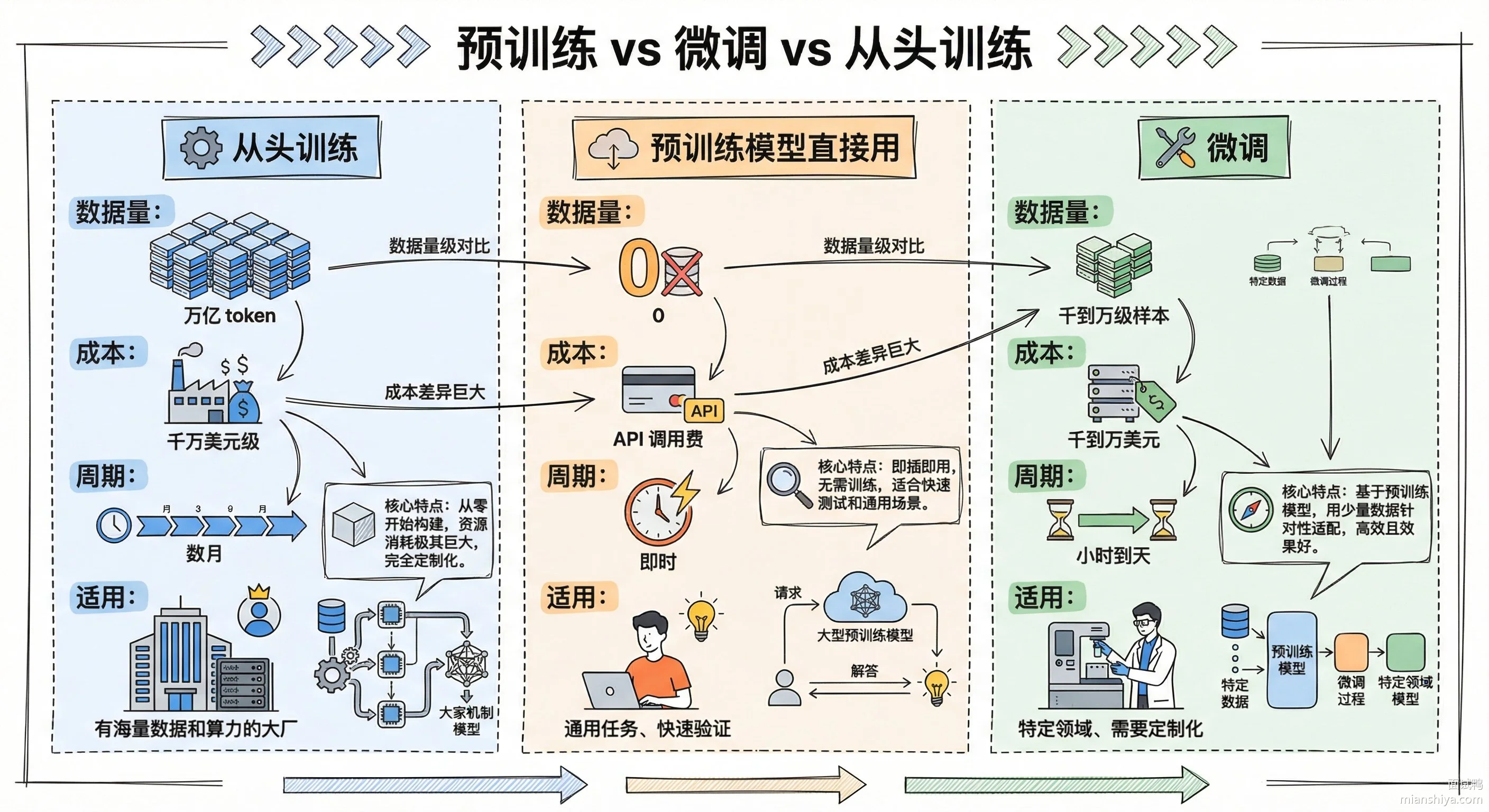
微调就是一个性价比极高的中间方案,不用从零开始训练,也不用忍受通用模型在特定场景的平庸表现。
主流微调策略
1)全参数微调,把模型所有参数都拿出来重新训练。效果最好,但成本也最高。一个 70B 参数的模型,光加载到 GPU 就需要 140GB 显存,还得额外留空间存梯度和优化器状态,没有几十张顶级显卡根本跑不动
2)部分参数微调,冻结大部分层,只训练最后几层或者特定模块。减少了计算量,但效果往往不如全参数微调
3)参数高效微调 PEFT,这是现在的主流做法。核心思路是往原模型里插入少量可训练参数,原模型参数全部冻结。LoRA 是最流行的一种,它在 attention 层的权重矩阵旁边加两个低秩矩阵,训练时只更新这两个小矩阵。一个 7B 的模型用 LoRA 微调,可训练参数可能只有几百万,显存占用直接降一个数量级
LoRA 的原理
LoRA 基于一个假设:微调时权重的变化量是低秩的,不需要更新整个大矩阵。
原本要更新的权重矩阵 W 是 d×d 的,比如 4096×4096,有 1600 多万参数。LoRA 把变化量分解成两个小矩阵 A 和 B 的乘积,A 是 d×r,B 是 r×d,r 一般取 8 或 16。这样可训练参数从 d² 降到 2dr,压缩了几百倍。
推理时把 LoRA 矩阵合并回原权重,不增加任何推理延迟。而且可以给同一个基座模型挂不同的 LoRA 权重,实现多任务切换。
微调数据的质量比数量重要
搞微调最容易踩的坑就是迷信数据量。其实几千条高质量数据的效果往往比几万条噪声数据好。Alpaca 当年只用了 52000 条数据就把 LLaMA 调成了能聊天的模型。
高质量数据的标准:指令清晰、回答准确、覆盖多样场景、格式一致。与其花时间爬更多数据,不如花时间清洗和筛选已有数据。
篇幅有限,更多 AI 大模型 相关面试题可以进入面试鸭进行查阅。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)