RAG向量存储原理(余弦相似度、欧氏距离、ANN近似最近邻、HNSW原理、混合检索)
文章目录
- 深入理解 RAG 向量存储原理
- 一、什么是 RAG?
- 二、RAG 的核心流程
- 三、什么是向量(Vector)
- 四、Embedding 的本质
- 五、向量空间(Vector Space)
- 六、为什么高维向量能表达语义
- 七、Chunk(文本切块)为什么重要
- 八、向量数据库到底存什么
- 九、向量检索原理
- 十、常见相似度算法
- 1. Cosine Similarity(最常见)
- 2. Euclidean Distance
- 3. Dot Product
- 十一、为什么向量检索这么快
- 十二、ANN(近似最近邻)
- 十三、HNSW 原理(最常见)
- 十四、向量数据库有哪些
- 十五、向量数据库 vs 传统数据库
- 十六、Hybrid Search(混合检索)
- 十七、RAG 的核心问题
- 十八、典型 RAG 架构
- 十九、为什么 RAG 现在这么重要
- 二十、总结
深入理解 RAG 向量存储原理
随着大语言模型(LLM)越来越强,RAG(Retrieval-Augmented Generation,检索增强生成)已经成为 AI 应用中的核心架构之一。
无论是 AI 知识库、企业问答机器人、文档助手,还是 AI 搜索系统,背后几乎都离不开:
- 向量化(Embedding)
- 向量数据库(Vector Store)
- 相似度检索(Similarity Search)
很多人第一次接触 RAG 时,都会有几个疑问:
- 为什么文本能变成向量?
- 向量数据库到底存了什么?
- 为什么“语义相近”的内容能被搜索到?
- 向量检索和传统数据库查询有什么区别?
这篇文章会从底层原理出发,系统讲清楚 RAG 向量存储的工作机制。
一、什么是 RAG?
RAG(Retrieval-Augmented Generation):
本质上是:
“先检索,再让大模型生成答案”
传统 LLM 的问题:
- 训练数据有时间截止
- 不知道企业私有知识
- 容易幻觉(Hallucination)
- 无法实时更新知识
RAG 的解决思路:
用户问题
↓
向量检索相关知识
↓
把知识拼接进 Prompt
↓
LLM 基于知识生成答案
核心思想:
不让模型“硬记忆”,而是“动态查资料”
二、RAG 的核心流程
完整流程通常如下:
原始文档
↓
文本切块(Chunking)
↓
Embedding 向量化
↓
存入向量数据库
↓
用户提问
↓
Query 向量化
↓
向量相似度检索
↓
返回 TopK 文本
↓
拼接 Prompt
↓
LLM 生成最终答案
这里最核心的一步:
文本 → 向量
以及:
向量之间如何比较相似度
三、什么是向量(Vector)
在 RAG 中:
文本会被转换成:
一组高维数字
例如:
“猫喜欢吃鱼”
↓
[0.123, -0.882, 0.451, ...]
这组数字:
- 可能是 384 维
- 768 维
- 1024 维
- 1536 维
本质:
用数学空间表达“语义”
四、Embedding 的本质
Embedding 模型会学习:
语义相近 → 向量距离接近
例如:
“如何安装 Python”
“Python 安装教程”
虽然文字不同:
但语义接近。
Embedding 后:
向量距离也会接近
而:
“如何安装 Python”
“今天天气不错”
距离就会很远。
五、向量空间(Vector Space)
可以把向量理解成:
语义坐标
例如二维空间:
猫 (1,2)
狗 (1,3)
汽车(9,8)
猫和狗距离近:
语义相近
猫和汽车距离远:
语义差异大
真实世界中:
不是二维。
而是:
几百维甚至上千维
六、为什么高维向量能表达语义
Embedding 模型本质上是神经网络。
训练过程中:
模型会学习:
词语之间的上下文关系
例如:
苹果:
- 水果
- 公司
Embedding 会结合上下文理解。
例如:
Apple released new chips
与:
I ate an apple
会得到不同语义向量。
七、Chunk(文本切块)为什么重要
RAG 通常不会:
整本书直接向量化
而是:
切成小块
例如:
每 500 token 一个 chunk
原因:
1. 提高检索精度
用户问题:
“数据库连接池原理”
如果整个文档太大:
相关内容会被稀释。
2. 控制上下文长度
LLM 的 Context Window 有限制。
例如:
- 8K
- 32K
- 128K tokens
不能无限塞文档。
3. 提高召回率
小 chunk 更容易:
精准命中
八、向量数据库到底存什么
很多人误以为:
存的是文本
其实通常存:
{
id,
vector,
text,
metadata
}
例如:
{
"id": "chunk-001",
"vector": [0.12, -0.55, ...],
"text": "连接池用于复用数据库连接",
"metadata": {
"source": "db.md",
"page": 3
}
}
真正用于检索的是:
vector
text 只是附带返回。
九、向量检索原理
当用户提问:
“为什么需要连接池?”
系统会:
Step1:问题向量化
Query
↓
Embedding
↓
Query Vector
Step2:与数据库向量比较
计算:
向量距离
Step3:找到最相近的 TopK
例如:
Top 3 chunks
十、常见相似度算法
向量检索核心:
如何衡量“距离”
1. Cosine Similarity(最常见)
余弦相似度:
方向越接近
相似度越高
核心思想:
不关注长度,只关注方向
非常适合语义搜索。
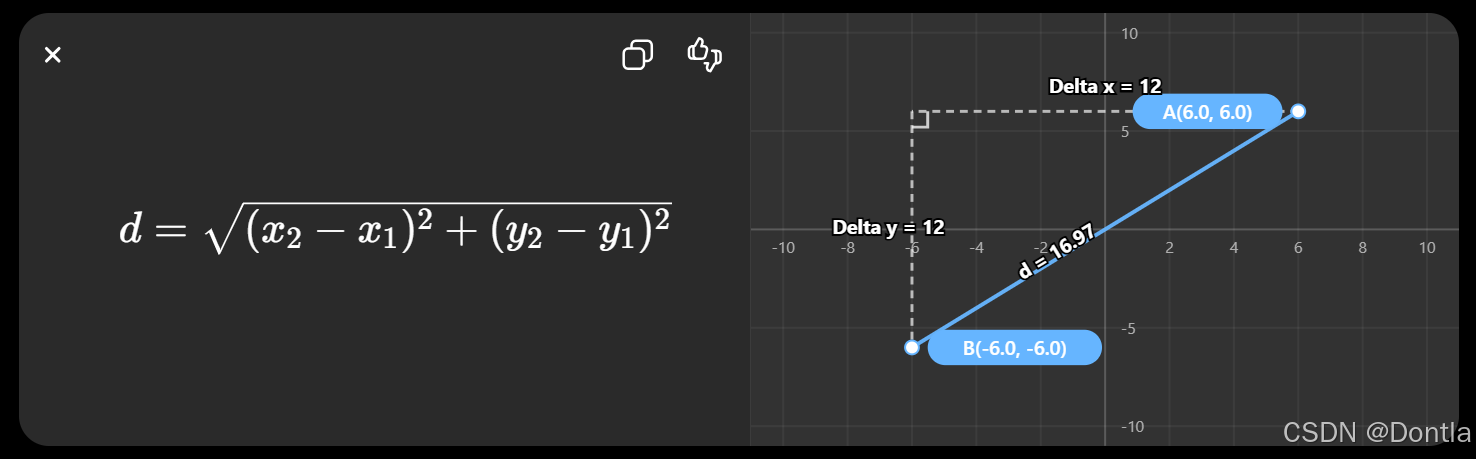
2. Euclidean Distance
欧氏距离:
空间中的直线距离
类似:
二维坐标距离公式
d = ( x 2 − x 1 ) 2 + ( y 2 − y 1 ) 2 d=\sqrt{(x_2-x_1)^2+(y_2-y_1)^2} d=(x2−x1)2+(y2−y1)2
3. Dot Product
点积:
向量乘积
计算快。
很多 GPU 检索优化都会使用。
十一、为什么向量检索这么快
问题来了:
如果:
1 亿条向量
逐个比较:
非常慢
因此向量数据库会使用:
ANN(Approximate Nearest Neighbor)
近似最近邻搜索。
十二、ANN(近似最近邻)
核心思想:
不用精确比较所有向量
而是:
快速找到“足够近”的向量
牺牲少量精度:
换取巨大性能提升。
十三、HNSW 原理(最常见)
很多向量数据库都使用:
HNSW
全称:
Hierarchical Navigable Small World
核心思想:
构建向量图
类似:
社交网络
向量之间建立“邻居关系”。
检索时:
从高层快速跳跃
↓
逐渐逼近目标
特点:
- 查询快
- 精度高
- 非常适合 RAG
十四、向量数据库有哪些
常见向量数据库:
| 数据库 | 特点 |
|---|---|
| Milvus | 分布式能力强 |
| Qdrant | Rust 编写,现代化 |
| Weaviate | AI Native |
| Pinecone | 云原生 SaaS |
| Chroma | 轻量本地开发 |
| FAISS | Meta 开源库 |
| pgvector | PostgreSQL 插件 |
十五、向量数据库 vs 传统数据库
传统数据库:
SELECT * FROM docs
WHERE title = 'Python'
是:
精确匹配
而向量数据库:
语义匹配
即使:
文本完全不同
也能检索到。
例如:
“如何安装 Python”
也能搜到:
“Python 环境配置教程”
十六、Hybrid Search(混合检索)
现代 RAG 往往不是:
只做向量搜索
而是:
关键词 + 向量
例如:
- BM25
- Full Text Search
- Vector Search
组合。
原因:
纯向量搜索有时会:
- 召回错误
- 忽略关键术语
- 数字匹配不稳定
混合搜索能提升准确率。
十七、RAG 的核心问题
RAG 并不是“接个向量库”那么简单。
真正难点:
1. Chunk 切分
切太大:
召回不精准
切太小:
上下文丢失
2. Embedding 模型选择
不同模型:
- 多语言能力
- 代码能力
- 中文能力
差异巨大。
3. Recall(召回)
检索不到正确知识:
LLM 再强也没用。
4. Re-ranking
很多系统会:
先粗召回
↓
再重排序
提升结果质量。
十八、典型 RAG 架构
现代 RAG 通常:
用户问题
↓
Query Rewrite
↓
Embedding
↓
Hybrid Search
↓
TopK Recall
↓
Rerank
↓
Prompt Assemble
↓
LLM
高级系统还会加入:
- Query Expansion
- Graph RAG
- Agentic RAG
- Multi-hop Retrieval
十九、为什么 RAG 现在这么重要
因为:
LLM ≠ 数据库
LLM:
擅长:
- 推理
- 生成
- 总结
不擅长:
- 精确知识存储
- 实时更新
- 企业私有数据
RAG:
本质上是在给 LLM:
外挂知识系统
二十、总结
RAG 向量存储核心思想:
把语义转换成数学空间
然后通过:
向量距离
实现:
语义检索
整个过程本质是:
文本
↓
Embedding
↓
高维向量
↓
相似度搜索
↓
召回知识
↓
LLM生成答案
真正让 RAG 强大的:
不是“大模型”。
而是:
高质量检索
因为:
检索质量,决定最终回答质量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)