day21_聚类算法
写在前面
我发现AI写的比我好多了......我将化身审稿人
本篇文章主要内容是由hermes接入DeepSeek-V4-flash生成的。我负责给定知识框架、知识点。优化内容、排版。
部分示例图片用豆包生成。
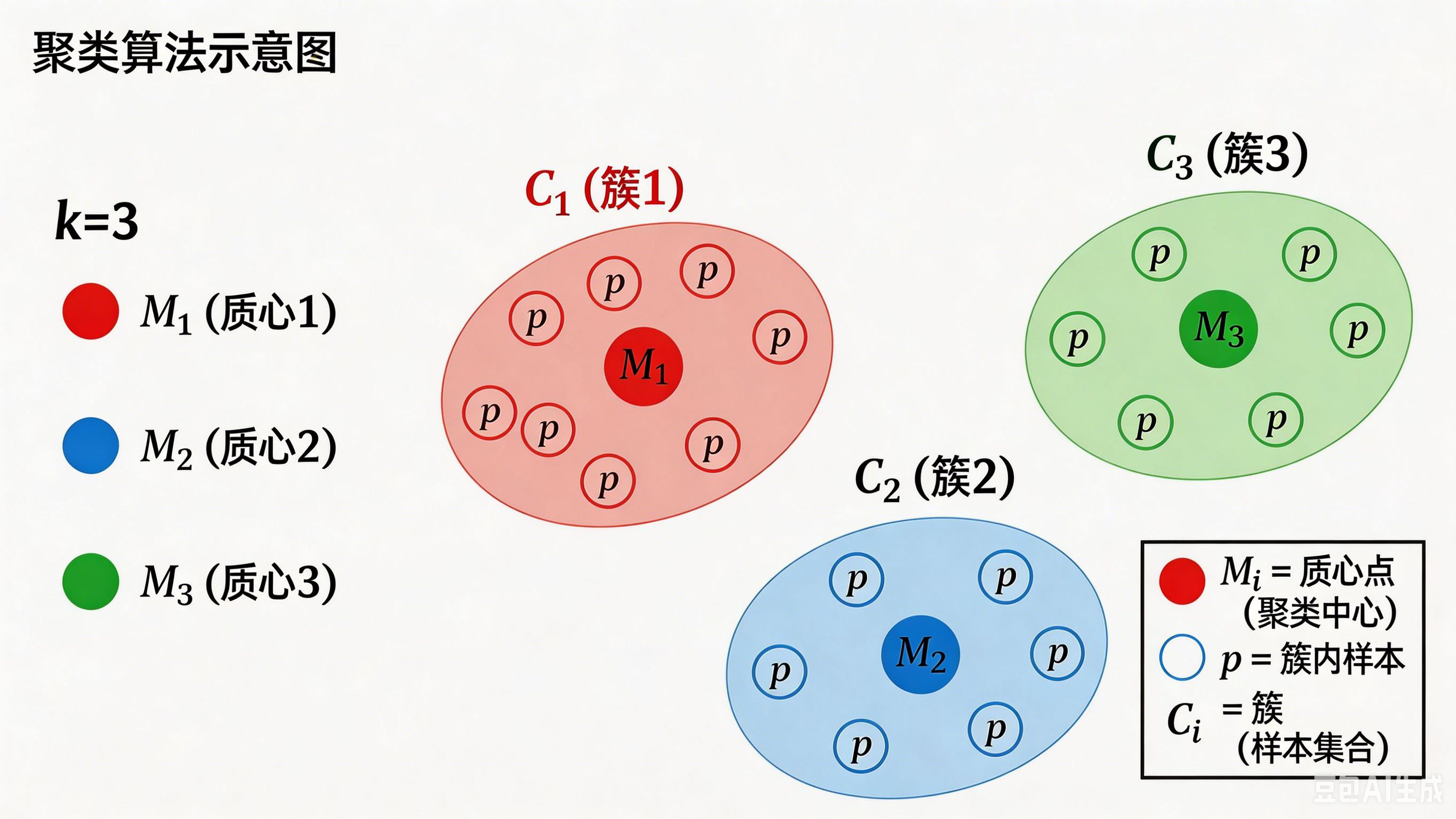
一、聚类算法
1.概念
聚类算法是一种无监督学习方法,目的是把数据划分为若干簇,使得同一簇内的样本相似度高,不同簇间的样本差异大。
聚类算法的核心是根据样本间的相似性来分类,最常用的相似度计算方式是欧氏距离法。
使用不同的聚类准则,得到的聚类结果也不同。举个例子,动物园里的动物可以按不同方式分类:

2.应用场景
聚类的本质就是自动发现数据内在的结构,不需要人工打标签。
-
用户画像、广告推荐 — 将用户分成不同的兴趣群体,定向推送
-
搜索引擎的流量推荐 — 对搜索结果聚类,提高推荐准确性
-
恶意流量识别 — 将异常流量聚成一簇,方便检测
-
基于位置信息的商业推送 — 按地理位置聚类用户
3.聚类算法分类
根据不同的角度,聚类算法可以分成不同的类型:
按颗粒度分类
-
粗聚类 — 分成较大的簇
-
细聚类 — 分成较小的簇
按实现方法分类
| 类型 | 代表算法 | 核心思想 |
|---|---|---|
| 基于划分的聚类 | K-means | 按照质心(簇的中心位置,通过均值计算)分类 |
| 基于层次的聚类 | DIANA、AGNES | 自顶向下分裂(DIANA)或自底向上合并(AGNES) |
| 基于密度的聚类 | DBSCAN | 按样本点的密度来聚类,能发现任意形状的簇 |
| 基于图的聚类 | 谱聚类(Spectral Clustering) | 基于图论,利用样本间的相似度图来聚类 |
K-means是我们这篇的主角,也是最经典的聚类算法。
二、聚类评估方法
聚类问题不同于分类问题——我们没有“正确”的标签来测试模型。那么,我们应该如何评估聚类模型的好坏呢?
1.SSE(TheSumOfSquaresDueToError)——误差平方和
SSE衡量的是每个样本到其质心距离平方和,公式如下:
其中表示簇,
表示聚类中心个数,
表示簇内的样本,
表示质心点
SSE的特点
-
SSE 越小,表示数据点越接近它们的中心,聚类效果越好
-
SSE 只考虑了簇内聚程度,没有考虑簇间分离程度
-
随着k增大,SSE会一直变小(每个点都成为自己的质心时SSE=0),所以不能只看SSE选k
2.肘部法
既然SSE会随着K值增大一直减少,那么如何确定最佳K值?
肘部法的流程是,遍历k=1到n,每次聚类后计算SSE,然后绘制SSE随k变化的曲线。
在曲线中会出现一个拐点,这个拐点处的k值就是最佳聚类数。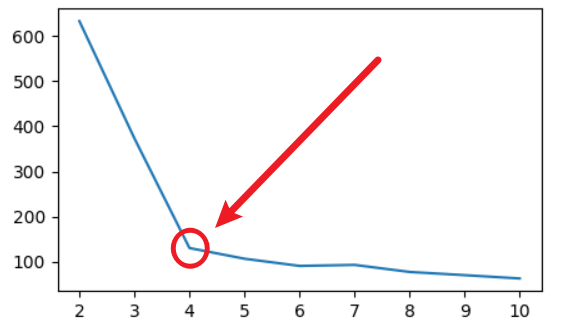
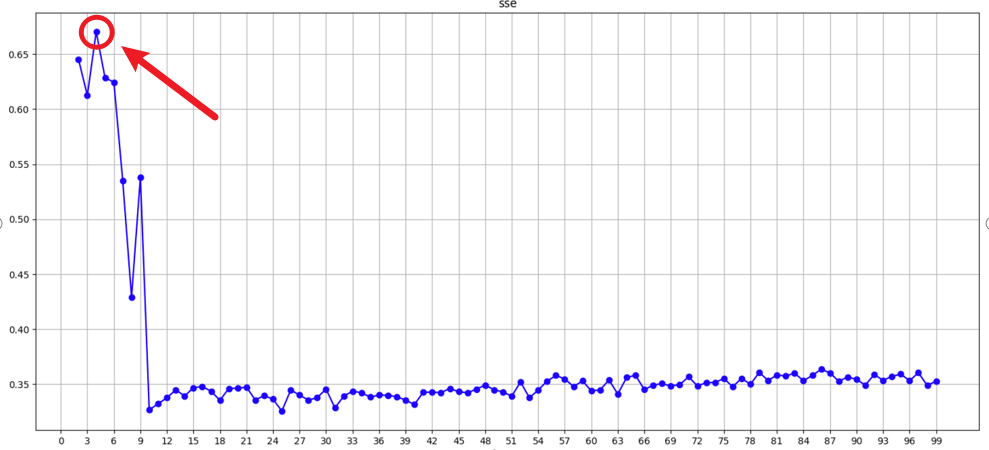
3.SC轮廓系数(SilhouetteCoefficient)
与SSE不同,SC轮廓系数同时考虑了两个因素:
-
簇内聚程度 — 簇内的样本距离越小越好
-
簇间分离程度 — 不同簇间的样本距离越大越好
SC轮廓系数公式为:
其中是每个样本到簇内其他样本距离的平均值;
是每个样本到距离最近的另一个簇内的所有样本的平均值。
特点:
-
结果范围:[-1, 1]
-
越接近1越好,表示样本远离相邻簇且在自己的簇内很紧密
-
接近0表示样本在两个簇的边界上
-
负值表示样本可能被分错了簇
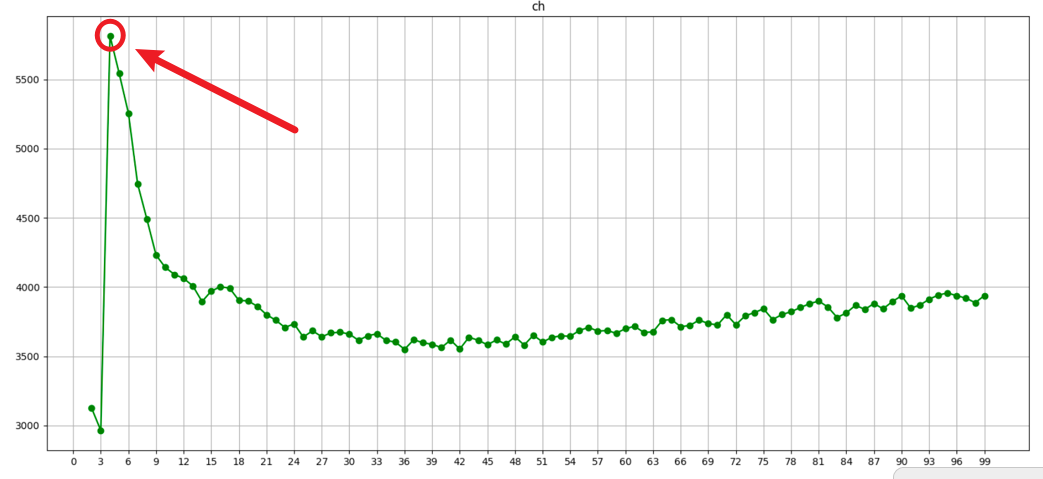
4.CH系数(Calinski-HarabaszIndex)
CH系数同时考虑了三个因素:
-
簇内聚程度 — 类别内部数据的距离平方和(SSW)越小越好
-
簇间离散程度 — 类别之间的距离平方和(SSB)越大越好
-
质心的个数 — 聚类种类数越少越好
公式如下:
特点:
-
CH分数 越高,聚类效果越好
-
它的目标是:用尽量少的类别聚类尽量多的样本,同时获得较好的聚类效果
5.三种评估方法对比
| 方法 | 衡量内容 | 好坏标准 | 适用场景 |
|---|---|---|---|
| SSE | 簇内聚程度 | 越小越好 | 配合肘部法确定k值 |
| SC系数 | 簇内聚程度 + 簇间分离程度 | [-1, 1],越大越好 | 综合评估聚类质量 |
| CH系数 | 簇内聚程度 + 簇间分离程度 + 质心个数 | 越大越好 | 快速评估,计算效率高 |
三、实操案例
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score, calinski_harabasz_score
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'SimSun']
plt.rcParams['axes.unicode_minus'] = False
# 1. 获取数据
data = make_blobs(n_samples=1000, n_features=2,
centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=66)
x = data[0]
y = data[1]
# 2. 遍历不同的k值,计算三种评估指标
k_list = [i for i in range(2, 11)]
sse_list = []
sc_list = []
ch_list = []
for k in k_list:
# 创建模型并预测
model = KMeans(n_clusters=k)
y_pred = model.fit_predict(x)
# 存储SSE结果
sse_list.append(model.inertia_)
# 存储SC结果
sc_list.append(silhouette_score(x, y_pred))
# 存储CH结果
ch_list.append(calinski_harabasz_score(x, y_pred))
# 3. 绘图展示三个指标随k值的变化
fig = plt.figure(figsize=(20, 20))
# SSE图
fig.add_subplot(311)
plt.plot(k_list, sse_list, marker='o')
plt.title("k值和SSE关系图")
plt.ylabel("SSE值")
# 可以看到在k=4处出现拐点,下降趋缓
# SC图
fig.add_subplot(312)
plt.plot(k_list, sc_list, marker='o')
plt.title("k值和SC关系图")
plt.ylabel("SC值")
# 可以看到在k=4处SC取最大值
# CH图
fig.add_subplot(313)
plt.plot(k_list, ch_list, marker='o')
plt.title("k值和CH关系图")
plt.xlabel("k值")
plt.ylabel("CH值")
# 可以看到在k=4处CH取最大值
plt.show()
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)