Kubernetes v1.23.1 升级到 v1.27.x 详细指南
·
目录
1. 升级策略与版本选择
1.1 推荐升级路径
Kubernetes 支持逐次小版本升级,不能跨多个大版本直接升级。
当前版本: v1.23.1
推荐目标版本: v1.27.x(最新稳定版之一)
升级路径:
v1.23.1 → v1.24.x → v1.25.x → v1.26.x → v1.27.x
1.2 为什么选择 v1.27.x?
✅ 长期支持:v1.27 是较新的稳定版本
✅ 兼容性:与大多数现有应用兼容
✅ 安全性:包含最新的安全补丁
✅ 功能:支持最新的 K8s 特性
1.3 重要变更提醒
从 v1.23 到 v1.27 的主要变更:
| 版本 | 重要变更 |
|---|---|
| v1.24 | 移除 dockershim,必须使用 containerd 或 CRI-O |
| v1.25 | PodSecurityPolicy (PSP) 被移除,改用 Pod Security Admission |
| v1.26 | 一些 API 版本废弃 |
| v1.27 | 继续优化性能和稳定性 |
⚠️ 关键注意:如果您的集群使用 Docker 作为容器运行时,必须先迁移到 containerd!
2. 升级前准备
2.1 备份重要数据
# 在所有 master 节点执行
# 1. 备份 etcd 数据
ETCDCTL_API=3 etcdctl snapshot save /data/backup/etcd-snapshot-$(date +%Y%m%d).db \
--endpoints=https://192.168.91.18:2379 \
--cacert=/etc/etcd/ssl/ca.pem \
--cert=/etc/etcd/ssl/server.pem \
--key=/etc/etcd/ssl/server-key.pem
# 2. 备份 Kubernetes 配置文件
cp -r /etc/kubernetes /data/backup/kubernetes-backup-$(date +%Y%m%d)
# 3. 备份证书
cp -r /etc/etcd /data/backup/etcd-backup-$(date +%Y%m%d)
# 4. 记录当前集群状态
kubectl get nodes -o wide > /data/backup/nodes-before-upgrade.txt
kubectl get pods --all-namespaces -o wide > /data/backup/pods-before-upgrade.txt
kubectl version > /data/backup/k8s-version-before.txt
2.2 检查集群健康状态
# 检查所有节点状态
kubectl get nodes
# 检查核心组件
kubectl get pods -n kube-system
# 检查是否有失败的 Pod
kubectl get pods --all-namespaces | grep -v Running
# 检查集群事件
kubectl get events --all-namespaces --sort-by='.lastTimestamp' | tail -20
2.3 检查容器运行时
# 确认使用的容器运行时
kubectl get nodes -o jsonpath='{.items[*].status.nodeInfo.containerRuntimeVersion}'
# 示例输出:
# docker://24.0.7 docker://24.0.7 containerd://1.6.4
# 如果是 Docker,需要先迁移到 containerd
# 查看 Docker 版本
docker version
⚠️ 重要提示:
- 当前集群中 master-1、master-2 使用 Docker,node-1 使用 containerd
- 必须在升级前将所有 Docker 节点迁移到 containerd
- v1.24+ 不再支持 Docker(移除了 dockershim)
2.4 从 Docker 迁移到 containerd
步骤1:在所有使用 Docker 的节点上安装 containerd
在 master-1、master-2 上执行:
# 1. 安装 containerd
#下载安装包
wget https://d.frps.cn/file/kubernetes/containerd/cri-containerd-cni-1.6.4-linux-amd64.tar.gz
#解压安装包 直接给对应目录替换调
[root@node-3 ~]# tar zxvf cri-containerd-cni-1.6.4-linux-amd64.tar.gz -C /
# 2. 创建 containerd 配置目录
[root@demo ~]# mkdir -p /etc/containerd
# 3. 生成默认配置文件
[root@demo ~]# containerd config default | sudo tee /etc/containerd/config.toml
# 4. 修改配置文件
#修改数据存储目录
[root@node-3 etc]# sed -ri 's@^(root).*@\1 = "/data/containerd"@g' /etc/containerd/config.toml
[root@node-3 etc]# grep '/data/containerd' /etc/containerd/config.toml
root = "/data/containerd"
#修改containerd沙盒镜像
[root@node-3 etc]# grep sandbox_image /etc/containerd/config.toml
sandbox_image = "registry.k8s.io/pause:3.6"
[root@node-3 etc]# sudo sed -ri 's@(sandbox_image).*@\1 = "registry.aliyuncs.com/google_containers/pause:3.9"@g' /etc/containerd/config.toml
[root@node-3 etc]# grep sandbox_image /etc/containerd/config.toml
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"
#containerd开启cgroup功能
#当主机使用 systemd 作为 init 系统时,启用这个选项可以使容器资源管理(CPU/内存等)与 systemd 更好地集成
[root@node-3 etc]# sed -ri 's@(SystemdCgroup).*@\1 = true@g' /etc/containerd/config.toml
[root@node-3 etc]# grep SystemdCgroup /etc/containerd/config.toml
SystemdCgroup = true
#containerd设置registry配置目录
#指定 containerd 查找容器镜像仓库证书(TLS 配置)的目录,如配置私有镜像仓库(如 Harbor、Nexus)的 TLS 证书时
[root@node-3 opt]# sed -ri 's@(config_path).*@\1 = "/etc/containerd/certs.d"@g' /etc/containerd/config.toml
[root@node-3 opt]# grep config_path /etc/containerd/config.toml
config_path = "/etc/containerd/certs.d"
# 5. 配置镜像加速器(推荐:使用 certs.d 目录结构)
# containerd 1.5+ 推荐使用 /etc/containerd/certs.d/<registry>/hosts.toml
# 创建 docker.io 镜像加速配置
mkdir -p /etc/containerd/certs.d/docker.io
cat > /etc/containerd/certs.d/docker.io/hosts.toml <<EOF
server = "https://docker.io"
[host."https://k0jntw7k.mirror.aliyuncs.com"]
capabilities = ["pull", "resolve"]
[host."https://docker.m.daocloud.io"]
capabilities = ["pull", "resolve"]
[host."https://dockerpull.com"]
capabilities = ["pull", "resolve"]
[host."https://docker.registry.cyou"]
capabilities = ["pull", "resolve"]
[host."https://atomhub.openatom.cn"]
capabilities = ["pull", "resolve"]
[host."https://docker.1panel.live"]
capabilities = ["pull", "resolve"]
[host."https://hub.rat.dev"]
capabilities = ["pull", "resolve"]
[host."https://docker.awsl9527.cn"]
capabilities = ["pull", "resolve"]
[host."https://do.nark.eu.org"]
capabilities = ["pull", "resolve"]
[host."https://docker.ckyl.me"]
capabilities = ["pull", "resolve"]
[host."https://hub.uuuadc.top"]
capabilities = ["pull", "resolve"]
[host."https://docker.chenby.cn"]
capabilities = ["pull", "resolve"]
EOF
#重启containerd生效
systemctl restart containerd
systemctl status containerd
ctr version
#测试
crictl pull nginx
nerdctl --insecure-registry pull nginx
# 8. 验证镜像加速配置
crictl info | grep -A 20 "registry"
步骤2:配置 crictl 工具
# 1. 下载 crictl(与 Kubernetes 版本匹配)
wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.23.0/crictl-v1.23.0-linux-amd64.tar.gz
tar -zxvf crictl-v1.23.0-linux-amd64.tar.gz
mv crictl /usr/local/bin/
chmod +x /usr/local/bin/crictl
# 2. 配置 crictl
cat > /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
# 3. 验证 crictl
crictl info
crictl images
步骤3:迁移现有镜像(可选但推荐)
# 列出 Docker 中的所有镜像
docker images | grep -v REPOSITORY
# 将重要镜像导出并导入到 containerd
# 例如:
docker save nginx:latest | ctr -n k8s.io images import -
docker save pause:3.9 | ctr -n k8s.io images import -
# 验证镜像已导入
ctr -n k8s.io images ls | grep nginx
步骤4:修改 kubelet 配置
# 1. 备份 kubelet 配置
cp /etc/systemd/system/kubelet.service /etc/systemd/system/kubelet.service.bak
# 2. 修改 kubelet 服务文件,指定 containerd 作为容器运行时
# 编辑 /etc/systemd/system/kubelet.service
# 找到 ExecStart 行,添加或修改以下参数:
# --container-runtime=remote
# --container-runtime-endpoint=unix:///run/containerd/containerd.sock
[root@node-3 ~]# cat /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/kubernetes/kubernetes
After=containerd.service
Requires=containerd.service
[Service]
WorkingDirectory=/var/lib/kubelet
ExecStart=/usr/local/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/cfg/kubelet-bootstrap.kubeconfig --cert-dir=/etc/kubernetes/ssl --kubeconfig=/etc/kubernetes/cfg/kubelet.config --config=/etc/kubernetes/cfg/kubelet.json --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.2 --alsologtostderr=true --logtostderr=false --log-dir=/var/log/kubernetes --container-runtime=remote --container-runtime-endpoint=unix:///var/run/containerd/containerd.sock --v=2
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
#3 修改 kubelet 配置使用 systemd cgroup 驱动
# 确保/etc/kubernetes/cfg/kubelet.json包含以下配置:
# cgroupDriver: systemd
# 如果没有,添加或修改:
sed -i 's/cgroupDriver: cgroupfs/cgroupDriver: systemd/g' /etc/kubernetes/cfg/kubelet.json
# 4. 重新加载 systemd 配置
systemctl daemon-reload
步骤5:重启 kubelet
# 1. 停止 Docker(先停止 kubelet)
systemctl stop kubelet
systemctl stop docker
# 2. 启动 kubelet(使用 containerd)
systemctl start kubelet
# 3. 验证 kubelet 状态
systemctl status kubelet
journalctl -u kubelet -f | tail -20
# 4. 检查节点状态(在 master 节点执行)
kubectl get nodes
# 应该看到 CONTAINER-RUNTIME 变为 containerd://1.6.x
步骤6:验证迁移
# 1. 检查容器运行时
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.nodeInfo.containerRuntimeVersion}{"\n"}{end}'
# 应该显示:
# master-1 containerd://1.6.4
# master-2 containerd://1.6.4
# node-1 containerd://1.6.4
# 2. 检查 Pod 是否正常运行
kubectl get pods --all-namespaces
# 3. 测试创建新 Pod
kubectl run test-containerd --image=nginx:latest --restart=Never
kubectl get pods test-containerd
kubectl logs test-containerd
kubectl delete pod test-containerd
# 4. 检查 crictl
crictl pods
crictl containers
步骤7:禁用 Docker(可选)
# 如果确认一切正常,可以禁用 Docker
systemctl disable docker
systemctl stop docker
# 注意:不要卸载 Docker,保留以便紧急回滚
# 如果需要完全移除:
# yum remove -y docker-ce docker-ce-cli containerd.io
步骤8:在所有 Docker 节点重复上述步骤
# 按照顺序迁移:
# 1. master-1(先迁移一个 Master 测试)
# 2. master-2
# 3. 其他使用 Docker 的 worker 节点
# 每迁移一个节点后验证:
kubectl get nodes
kubectl get pods --all-namespaces
2.5 迁移后的验证
# 1. 确认所有节点都使用 containerd
kubectl get nodes -o wide
# 2. 检查核心组件 Pod
kubectl get pods -n kube-system
# 3. 测试集群功能
kubectl create namespace test-migration
kubectl run nginx-test --image=nginx:latest -n test-migration
kubectl get pods -n test-migration
kubectl delete namespace test-migration
# 4. 检查事件日志
kubectl get events --all-namespaces --sort-by='.lastTimestamp' | tail -20
迁移完成标志:
- ✅ 所有节点的 CONTAINER-RUNTIME 显示为
containerd://x.x.x - ✅ 所有系统 Pod 正常运行
- ✅ 可以正常创建和删除 Pod
- ✅ 应用无异常
注意事项:
- 迁移过程中会有短暂的 Pod 重启
- 建议在业务低峰期进行
- 保留 Docker 以便紧急回滚
- 迁移完成后,再进行 K8s 版本升级
查看 containerd 是否已安装
containerd --version

3. 升级步骤(二进制部署)
3.1 第一阶段:v1.23.1 → v1.24.x
步骤1:下载 v1.24.x 二进制文件
# 在所有节点创建下载目录
mkdir -p /opt/k8s/upgrade
cd /opt/k8s/upgrade
# 下载 Kubernetes v1.24.17(v1.24 最后一个稳定版本)
wget https://dl.k8s.io/v1.24.17/kubernetes-server-linux-amd64.tar.gz
# 解压
tar -zxvf kubernetes-server-linux-amd64.tar.gz
# 验证文件
ls kubernetes/server/bin/
# 应该看到: kube-apiserver, kube-controller-manager, kube-scheduler, kubelet, kube-proxy 等
步骤2:升级 Master 节点(逐个进行)
在 master-1 上执行:
#1.升级kube-apiserver
# 停止 kube-apiserver
systemctl stop kube-apiserver
#备份旧版本
cp /usr/local/bin/kube-apiserver /usr/local/bin/kube-apiserver.bak.v1.23
# 替换为新版本
cp /opt/k8s/upgrade/kubernetes/server/bin/kube-apiserver /usr/local/bin/kube-apiserver
chmod +x /usr/local/bin/kube-apiserver
#启动 kube-apiserver
systemctl start kube-apiserver
#等待服务启动
sleep 10
systemctl status kube-apiserver
#遇到报错查看日志
journalctl -u kube-apiserver -n 50 --no-pager
#我这里需要移除 --insecure-port、--enable-swagger-ui、--feature-gates 参数
vim /etc/kubernetes/cfg/kube-apiserver.cfg
systemctl start kube-apiserver
#2. 升级 kube-controller-manager
systemctl stop kube-controller-manager
cp /usr/local/bin/kube-controller-manager /usr/local/bin/kube-controller-manager.bak.v1.23
cp /opt/k8s/upgrade/kubernetes/server/bin/kube-controller-manager /usr/local/bin/kube-controller-manager
chmod +x /usr/local/bin/kube-controller-manager
#移除废弃参数--port=0
#参数--address=0.0.0.0 改为 --bind-address=0.0.0.0
vim /etc/kubernetes/cfg/kube-controller-manager.cfg
systemctl start kube-controller-manager
# 3. 升级 kube-scheduler
systemctl stop kube-scheduler
cp /usr/local/bin/kube-scheduler /usr/local/bin/kube-scheduler.bak.v1.23
cp /opt/k8s/upgrade/kubernetes/server/bin/kube-scheduler /usr/local/bin/kube-scheduler
chmod +x /usr/local/bin/kube-scheduler
#参数--address=0.0.0.0 改为 --bind-address=0.0.0.0
vim /etc/kubernetes/cfg/kube-scheduler.cfg
systemctl start kube-scheduler
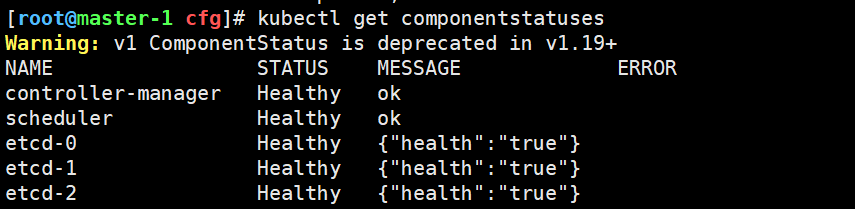
# 4. 验证 Master 组件
kubectl get componentstatuses
# 或者
kubectl get --raw='/readyz?verbose'
在 master-2 和 master-3 上重复上述步骤:
# 依次对 master-2、master-3 执行相同操作
# 确保每次只升级一个 Master 节点
步骤3:升级 Worker 节点(逐个进行)
# 1. master节点执行,驱逐节点上的 Pod
kubectl drain node-3 --ignore-daemonsets --delete-emptydir-data --force
# 2. node节点停止 kubelet 和 kube-proxy
systemctl stop kubelet
systemctl stop kube-proxy
# 3. node节点停止 备份旧版本
cp /usr/local/bin/kubelet /usr/local/bin/kubelet.bak.v1.23
cp /usr/local/bin/kube-proxy /usr/local/bin/kube-proxy.bak.v1.23
# 4. master-1拷贝新版本到node节点
scp /opt/k8s/upgrade/kubernetes/server/bin/kubelet 192.168.91.23:/usr/local/bin/kubelet
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-proxy 192.168.91.23:/usr/local/bin/kube-proxy
# 5.node节点 启动服务
systemctl start kubelet
systemctl start kube-proxy
# 6. node节点 验证节点状态
systemctl status kubelet
systemctl status kube-proxy
# 7. master节点执行取消节点隔离
kubectl uncordon node-3
# 8. 等待节点就绪
kubectl wait --for=condition=Ready node/node-1 --timeout=300s
在 node-2 和 node-3 上重复上述步骤。
步骤4:验证 v1.24 升级
# 检查所有节点版本
kubectl get nodes
# 应该显示 VERSION 为 v1.24.17
# 检查所有 Pod 正常运行
kubectl get pods --all-namespaces

步骤5:部署nginx测试
cat nginx.yaml
# 1. PVC 定义
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nginx-data-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: managed-nfs-storage # 动态存储类在这里指定
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
#基于标签关联pod,会关联env=test或者env=prod的pod
selector:
matchExpressions:
- key: env
values:
- "test"
- "prod"
operator: In
template:
metadata:
#为pod设置了两个标签
labels:
app: nginx
env: test
spec:
containers:
- name: nginx
image: nginx:1.22.1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumes:
- name: data
persistentVolumeClaim:
claimName: nginx-data-pvc # 引用上面创建的 PVC
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
# 指定svc的类型为NodePort,也就是在默认的ClusterIP基础之上多监听所有worker节点的端口而已。
type: NodePort
# 基于标签选择器关联Pod
selector:
app: nginx
# 配置端口映射
ports:
# 指定Service服务本身的端口号
- port: 80
# 后端Pod提供服务的端口号
targetPort: 80
kubectl apply -f nginx.yaml
#我这里报错了,排错步骤如下
#pod处于pending
kubectl get pods
#发现是pvc的问题
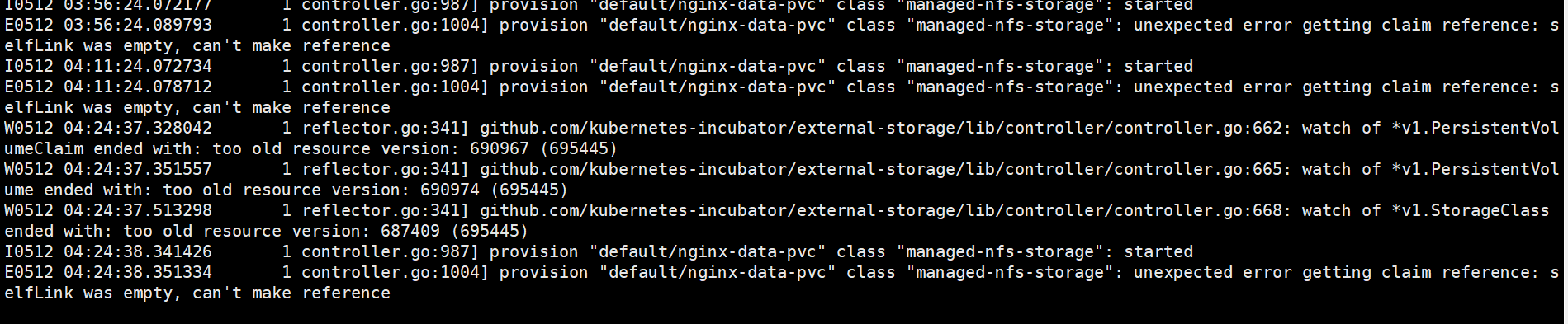
kubectl describe pod nginx-66c66bbdd9-l9t52
#查看日志发现是旧版本的 nfs-client-provisioner 依赖 selfLink 来引用 PVC,新版本禁用了 selfLink 字段
kubectl logs -n default nfs-client-provisioner-56cc478696-xkjwr -f
步骤6:升级nfs
#先删除之前的nfs
kubectl delete storageclass managed-nfs-storage
kubectl delete deployment nfs-client-provisioner
#创建新的nfs
[root@master-1 nfs]# cat nfs-class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
archiveOnDelete: "false"
reclaimPolicy: Delete
volumeBindingMode: Immediate
[root@master-1 nfs]# cat nfs-deployment.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
spec:
selector:
matchLabels:
app: nfs-client-provisioner
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
imagePullPolicy: IfNotPresent
# 使用兼容 K8s v1.24+ 的新版本镜像
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.91.19
- name: NFS_PATH
value: /ifs/kubernetes
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
volumes:
- name: nfs-client-root
nfs:
server: 192.168.91.19
path: /ifs/kubernetes
[root@master-1 nfs]# cat nfs-rabc.yaml
kind: ServiceAccount
apiVersion: v1
metadata:
name: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
kubectl apply -f .
#部署完之后发现nginx已经部署好了

3.2 第二阶段:v1.24.x → v1.25.x
升级步骤(与 v1.24 类似)
# 1. 下载 v1.25.16(v1.25 最后一个稳定版本)
cd /opt/k8s/upgrade
wget https://dl.k8s.io/v1.25.16/kubernetes-server-linux-amd64.tar.gz
tar -zxvf kubernetes-server-linux-amd64.tar.gz
# 2. 按照第一阶段的步骤,依次升级:
# - Master 节点(master-1 → master-2 → master-3)
#1.升级kube-apiserver
# 停止 kube-apiserver
systemctl stop kube-apiserver
# 替换为新版本
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-apiserver 192.168.91.18:/usr/local/bin/kube-apiserver
#启动
systemctl start kube-apiserver
#2. 升级 kube-controller-manager
systemctl stop kube-controller-manager
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-controller-manager 192.168.91.18:/usr/local/bin/kube-controller-manager
#移除废弃参数--experimental-cluster-signing-duration
vim /etc/kubernetes/cfg/kube-controller-manager.cfg
systemctl start kube-controller-manager
# 3. 升级 kube-scheduler
systemctl stop kube-scheduler
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-scheduler 192.168.91.18:/usr/local/bin/kube-scheduler
#参数--address=0.0.0.0 改为 --bind-address=0.0.0.0
vim /etc/kubernetes/cfg/kube-scheduler.cfg
systemctl start kube-scheduler
systemctl status kube-scheduler
# 4. 验证 Master 组件
kubectl get componentstatuses
# 或者
kubectl get --raw='/readyz?verbose'
# - Worker 节点(node-1 → node-2 → node-3)
# 01. master节点执行,驱逐节点上的 Pod
kubectl drain node-3 --ignore-daemonsets --delete-emptydir-data --force
# 02. node节点停止 kubelet 和 kube-proxy
systemctl stop kubelet
systemctl stop kube-proxy
# 03. master-1拷贝新版本到node节点
scp /opt/k8s/upgrade/kubernetes/server/bin/kubelet 192.168.91.23:/usr/local/bin/kubelet
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-proxy 192.168.91.23:/usr/local/bin/kube-proxy
# 04.node节点 启动服务
systemctl start kubelet
systemctl start kube-proxy
systemctl status kubelet
systemctl status kube-proxy
# 05. master节点执行取消节点隔离
kubectl uncordon node-3
# 3. 每个节点升级后验证
kubectl get nodes
kubectl get pods --all-namespaces
3.3 第三阶段:v1.25.x → v1.26.x
# 1. 下载 v1.26.15(v1.26 最后一个稳定版本)
cd /opt/k8s/upgrade
wget https://dl.k8s.io/v1.26.15/kubernetes-server-linux-amd64.tar.gz
tar -zxvf kubernetes-server-linux-amd64.tar.gz
# 2. 按照之前的步骤升级所有节点
#master节点
# 01 升级kube-apiserver
# 停止 kube-apiserver
systemctl stop kube-apiserver
# 替换为新版本
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-apiserver 192.168.91.20:/usr/local/bin/kube-apiserver
#遇到报错查看日志
journalctl -u kube-apiserver -n 50 --no-pager
#我这里需要移除--alsologtostderr、--logtostderr 、 --log-dir 参数
vim /etc/kubernetes/cfg/kube-apiserver.cfg
systemctl start kube-apiserver
# 02 升级 kube-controller-manager
systemctl stop kube-controller-manager
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-controller-manager 192.168.91.20:/usr/local/bin/kube-controller-manager
#移除废弃参数--alsologtostderr、--logtostderr 、 --log-dir
vim /etc/kubernetes/cfg/kube-controller-manager.cfg
systemctl start kube-controller-manager
# 03. 升级 kube-scheduler
systemctl stop kube-scheduler
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-scheduler 192.168.91.20:/usr/local/bin/kube-scheduler
#移除废弃参数--alsologtostderr、--logtostderr 、 --log-dir
vim /etc/kubernetes/cfg/kube-scheduler.cfg
systemctl start kube-scheduler
systemctl status kube-scheduler
#node节点
# 01. master节点执行,驱逐节点上的 Pod
kubectl drain node-3 --ignore-daemonsets --delete-emptydir-data --force
# 02. node节点停止 kubelet 和 kube-proxy
systemctl stop kubelet
systemctl stop kube-proxy
# 03. master-1拷贝新版本到node节点
scp /opt/k8s/upgrade/kubernetes/server/bin/kubelet 192.168.91.23:/usr/local/bin/kubelet
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-proxy 192.168.91.23:/usr/local/bin/kube-proxy
# 04.node节点 启动服务
systemctl start kubelet
systemctl start kube-proxy
systemctl status kubelet
systemctl status kube-proxy
# 05. master节点执行取消节点隔离
kubectl uncordon node-3
3.4 第四阶段:v1.26.x → v1.27.x
# 1. 下载 v1.27.16(v1.27 最新稳定版本)
cd /opt/k8s/upgrade
wget https://dl.k8s.io/v1.27.16/kubernetes-server-linux-amd64.tar.gz
tar -zxvf kubernetes-server-linux-amd64.tar.gz
# 2. 按照之前的步骤升级所有节点
#master节点
# 01 升级kube-apiserver
# 停止 kube-apiserver
systemctl stop kube-apiserver
# 替换为新版本
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-apiserver 192.168.91.20:/usr/local/bin/kube-apiserver
systemctl start kube-apiserver
systemctl status kube-apiserver
# 02 升级 kube-controller-manager
systemctl stop kube-controller-manager
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-controller-manager 192.168.91.20:/usr/local/bin/kube-controller-manager
systemctl start kube-controller-manager
systemctl status kube-controller-manager
# 03. 升级 kube-scheduler
systemctl stop kube-scheduler
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-scheduler 192.168.91.20:/usr/local/bin/kube-scheduler
systemctl start kube-scheduler
systemctl status kube-scheduler
# node节点
# 01. master节点执行,驱逐节点上的 Pod
kubectl drain node-1 --ignore-daemonsets --delete-emptydir-data --force
# 02. node节点停止 kubelet 和 kube-proxy
systemctl stop kubelet
systemctl stop kube-proxy
# 03. master-1拷贝新版本到node节点
scp /opt/k8s/upgrade/kubernetes/server/bin/kubelet 192.168.91.21:/usr/local/bin/kubelet
scp /opt/k8s/upgrade/kubernetes/server/bin/kube-proxy 192.168.91.21:/usr/local/bin/kube-proxy
# 04.node节点 启动服务
systemctl start kubelet
systemctl start kube-proxy
systemctl status kubelet
systemctl status kube-proxy
# 05. master节点执行取消节点隔离
kubectl uncordon node-1
4. 验证升级
4.1 检查集群版本
# 查看所有节点版本
kubectl get nodes -o wide

4.2 检查核心组件
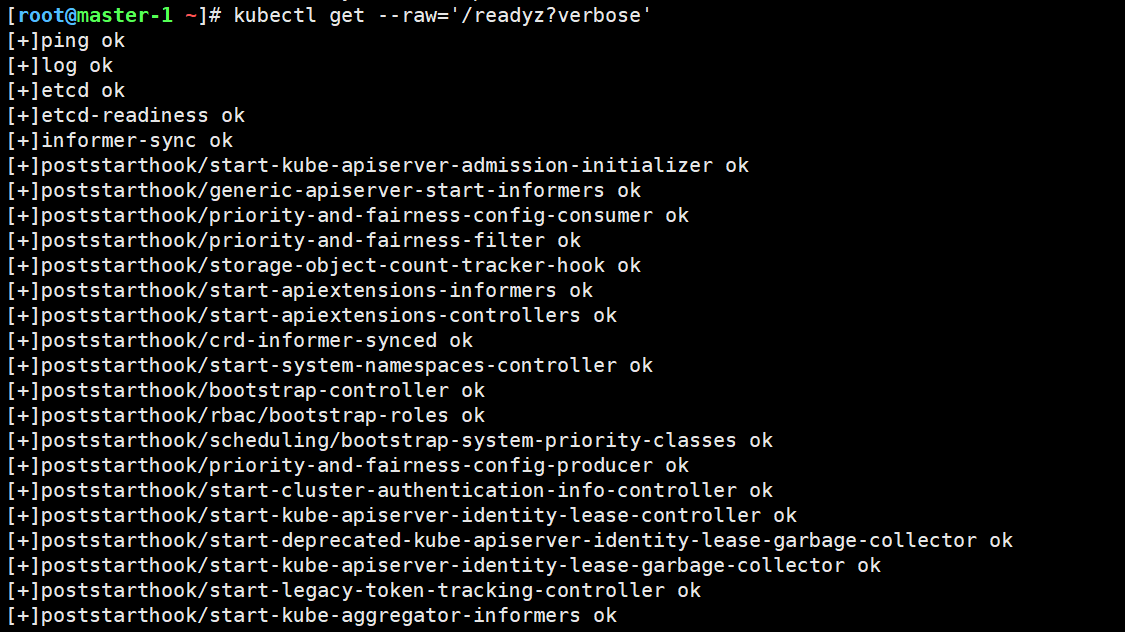
# 检查组件状态
kubectl get --raw='/readyz?verbose'
# 应该全部显示:ok
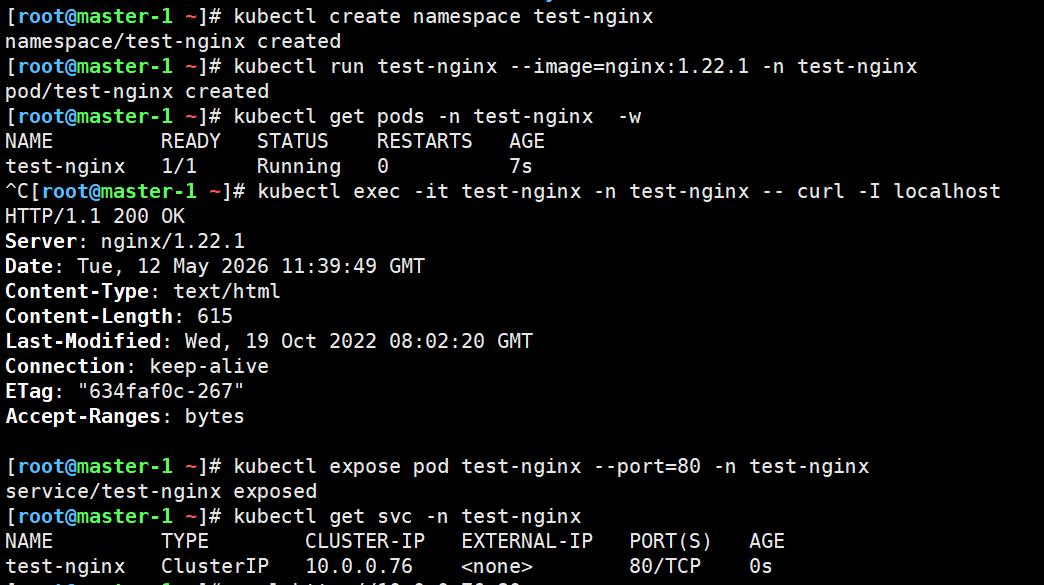
4.3 功能测试
# 1. 部署测试应用
kubectl create namespace test-nginx
kubectl run test-nginx --image=nginx:1.22.1 -n test-nginx
# 2. 检查 Pod 状态
kubectl get pods -n test-nginx -w
# 3. 测试网络
kubectl exec -it test-nginx -n test-nginx -- curl -I localhost
# 4. 测试 Service
kubectl expose pod test-nginx --port=80 -n test-nginx
kubectl get svc -n test-nginx
# 5. 清理测试资源
kubectl delete namespace test-nginx
4.4 检查应用兼容性
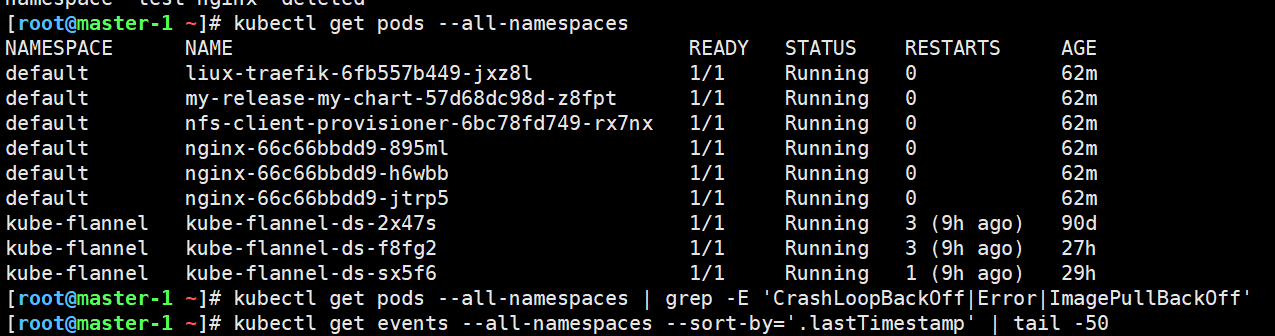
# 检查所有命名空间的 Pod
kubectl get pods --all-namespaces
# 检查是否有 CrashLoopBackOff 或 Error 状态的 Pod
kubectl get pods --all-namespaces | grep -E 'CrashLoopBackOff|Error|ImagePullBackOff'
# 检查事件
kubectl get events --all-namespaces --sort-by='.lastTimestamp' | tail -50
5. 回滚方案
如果升级后出现问题,可以快速回滚。
5.1 回滚单个节点
# 1. 驱逐节点
kubectl drain <node-name> --ignore-daemonsets --delete-emptydir-data --force
# 2. 停止服务
systemctl stop kubelet
systemctl stop kube-proxy
# 如果是 master 节点
systemctl stop kube-apiserver
systemctl stop kube-controller-manager
systemctl stop kube-scheduler
# 3. 恢复旧版本二进制文件
cp /data/backup/k8s-binaries-YYYYMMDD/kubelet /usr/local/bin/kubelet
cp /data/backup/k8s-binaries-YYYYMMDD/kube-proxy /usr/local/bin/kube-proxy
# 如果是 master 节点
cp /data/backup/k8s-binaries-YYYYMMDD/kube-apiserver /usr/local/bin/kube-apiserver
cp /data/backup/k8s-binaries-YYYYMMDD/kube-controller-manager /usr/local/bin/kube-controller-manager
cp /data/backup/k8s-binaries-YYYYMMDD/kube-scheduler /usr/local/bin/kube-scheduler
# 4. 启动服务
systemctl start kubelet
systemctl start kube-proxy
# 如果是 master 节点
systemctl start kube-apiserver
systemctl start kube-controller-manager
systemctl start kube-scheduler
# 5. 取消节点隔离
kubectl uncordon <node-name>
6. 常见问题
6.1 节点无法就绪
问题:升级后节点一直处于 NotReady 状态
解决:
# 检查 kubelet 日志
systemctl status kubelet
journalctl -u kubelet -f
# 常见原因:
# 1. 证书过期 - 重新生成证书
# 2. 配置不兼容 - 检查 kubelet 配置文件
# 3. 容器运行时问题 - 检查 containerd/docker 状态
# 检查容器运行时
systemctl status containerd
6.2 Pod 无法启动
问题:Pod 处于 ContainerCreating 或 Error 状态
解决:
# 查看 Pod 详情
kubectl describe pod <pod-name> -n <namespace>
# 查看事件
kubectl get events -n <namespace> --sort-by='.lastTimestamp'
# 检查节点资源
kubectl top nodes
kubectl describe node <node-name>
6.3 API Server 无法启动
问题:kube-apiserver 启动失败
解决:
# 查看日志
journalctl -u kube-apiserver -f
# 检查配置文件
vim /etc/kubernetes/cfg/kube-apiserver.cfg
# 检查证书
ls -la /etc/kubernetes/ssl/
# 检查端口占用
netstat -tuln | grep 6443
6.4 网络插件问题
问题:Pod 间网络不通
解决:
# 检查网络插件 Pod
kubectl get pods -A | grep -E 'flannel|calico|weave'
# 重启网络插件
kubectl delete pod -n kube-flannel -l app=<network-plugin>
6.5 镜像拉取失败
问题:Pod 报 ImagePullBackOff
解决:
# 检查镜像仓库连接
crictl pull <image-name>
nerdctl -n k8s.io pull nginx
# 检查镜像加速器配置
vim /etc/containerd/certs.d/docker.io/hosts.toml
附录:升级检查清单
升级前
- 备份 etcd 数据
- 备份 Kubernetes 配置
- 备份证书
- 检查集群健康状态
- 确认容器运行时(Docker → containerd)
- 通知用户维护窗口
- 准备回滚方案
升级中
- 逐个升级 Master 节点
- 每升级一个节点后验证
- 逐个升级 Worker 节点
- 监控 Pod 状态
升级后
- 验证所有节点版本一致
- 检查核心组件状态
- 测试基本功能(部署、网络、存储)
- 检查应用兼容性
- 监控系统资源
- 观察 24-48 小时
总结
推荐升级路径:v1.23.1 → v1.24.17 → v1.25.16 → v1.26.15 → v1.27.16
关键注意事项:
- ✅ 必须逐个小版本升级,不能跳跃
- ✅ v1.24+ 必须使用 containerd,不再支持 Docker
- ✅ 每次只升级一个节点,确保集群高可用
- ✅ 升级前务必备份 etcd 和配置文件
- ✅ 准备好回滚方案
文档参考:
- 官方升级指南:https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
- 版本变更说明:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)