浅谈大模型微调
什么是大模型微调
大模型微调 (Fine-tuning) 是指在已经训练好的预训练模型基础上,利用特定领域的数据集进行二次训练,以使模型能够更好地适应特定任务或行业需求的过程
-
预训练:让大模型知道整个世界的所有背景知识,各学科、各行业的。
-
微调:预训练模型是一个非常大的、泛化的模型。通常这时候我们需要用微调方式来让它补充获得更多的行业专业知识
通俗一点来讲,微调就是
当你有了一些“独特”的数据。
如果这些数据:
-
满足你的独特需求(如电子女友)
-
不能公开的私域数据(如金融模型)
-
在某方面超越通用模型的准确度(如医疗模型)
那么,微调就可以帮你:
-
客制化 AI 行为(风格、语气、个性)
-
扩展领域知识(不能公开的知识)
-
优化特定任务的准确度(法律、医疗等)
在大模型的开发栈中,微调(Fine-tuning)位于“底层框架”与“上层应用”之间。
-
底层:PyTorch, CUDA, Transformers (理论基础);
-
中层(微调):基于基座模型(Base Model)进行参数调整,赋予模型特定能力(如对话、代码生成、垂直领域知识);
-
上层:RAG(检索增强)、Agent(智能体)、API 服务;
-
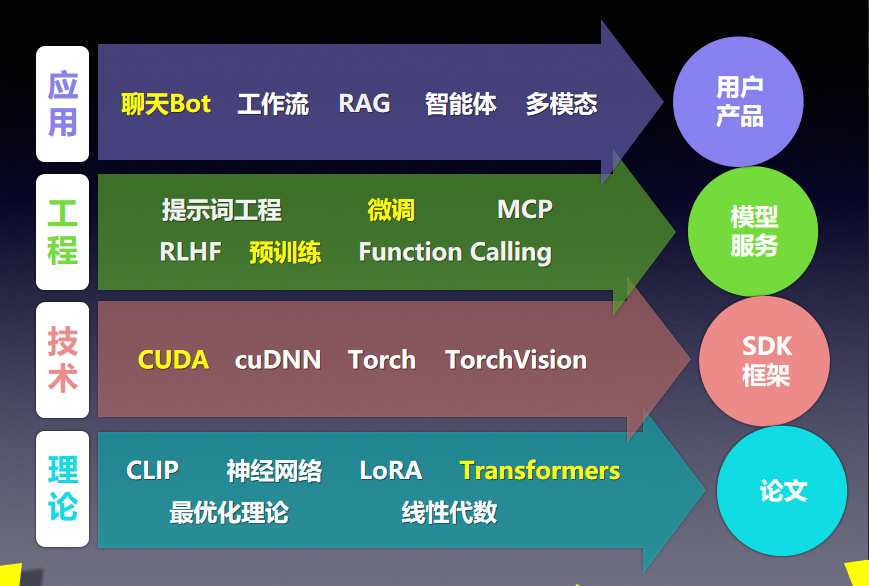
微调vsRAG
-
微调:把知识放到基座模型里面,知识跟模型变成一体的。
-
RAG:模型不变,知识放在另外一个地方,每次交互中去拿回来。
|
维度 |
微调 |
RAG |
|---|---|---|
|
服务组件 |
只有一个模型推理服务 |
存储服务 + 向量数据库 + 网络交互 |
|
工程健壮性 |
更健壮 |
组件多,容易出问题 |
|
响应速度 |
更快 |
多了检索过程 |
|
成本 |
推理需要GPU,还有训练成本 |
直接用API,成本低 |
|
知识更新 |
需要重新微调 |
知识库独立更新 |
|
模型更新 |
麻烦 |
换API即可 |
应用场景
|
微调 |
RAG |
|---|---|
|
封闭域(医疗、法律、景区) |
开放域 |
|
知识之间不能互相冲突 |
对数据逻辑性没有要求 |
|
知识相对固定、更新慢 |
更新速度没有限制 |
|
数据量相对小 |
数据量理论上无限大 |
|
准确度相对高 |
灵活性相对强 |
混合增强架构
RAG 侧重外部知识检索、解决知识更新与幻觉问题;微调侧重模型能力、风格、任务适配优化。实际业务场景中常常二者结合,兼顾知识库精准性与模型推理、对话能力。
微调的一般方法
-
设定产品目标,确定评估方法
-
选择基座模型
-
准备数据集
-
使用框架实现微调
选择基座模型
第一步:确定要推理什么样类型的任务
-
视觉类任务(生图)→ 视觉模型
-
编程任务 → 代码模型
-
医疗类 → 医疗领域的基座模型
第二步:选择 base 模型还是 instruct 模型?
-
Base 模型:预训练完直接给我们的,本质上是文章续写器
-
Instruct 模型:已经被人家微调了一些的版本,起码有对话能力
主流基座模型
1. Llama 系列(Meta)
-
任何开源工具都一定支持 Llama,生态最强。
-
架构稳定
2. 通义千问(阿里)
-
更新很快
-
对微调最友好
-
各种尺寸齐备。有小于 1B 的迷你模型,可以跑在边缘设备上
-
默认说中文,不会出现中文问英文答的情况
3. 6-2-3 Phi(微软)
-
中文问可能英文答
-
更新较慢
4 Gemma(Google)
-
原生支持多模态功能,融合文本-图像-音频-视频处理能力
-
采用滑动窗口注意力和 GQA 技术,推理速度极快,适合高并发场景
-
中文幻觉比较严重
5 GLM(智谱)
-
ChatGLM 5.1 的文科表现很惊艳
-
小模型更新较停滞
6 Deepseek(深度求索)
-
在理科方面很强,逻辑推理天花板
-
性价比极高
数据集准备
数据获取方式
-
甲方提供
-
生产数据(产线、服务器、电子病历)
-
网络抓取
-
公开数据集(Hugging Face、ModelScope)
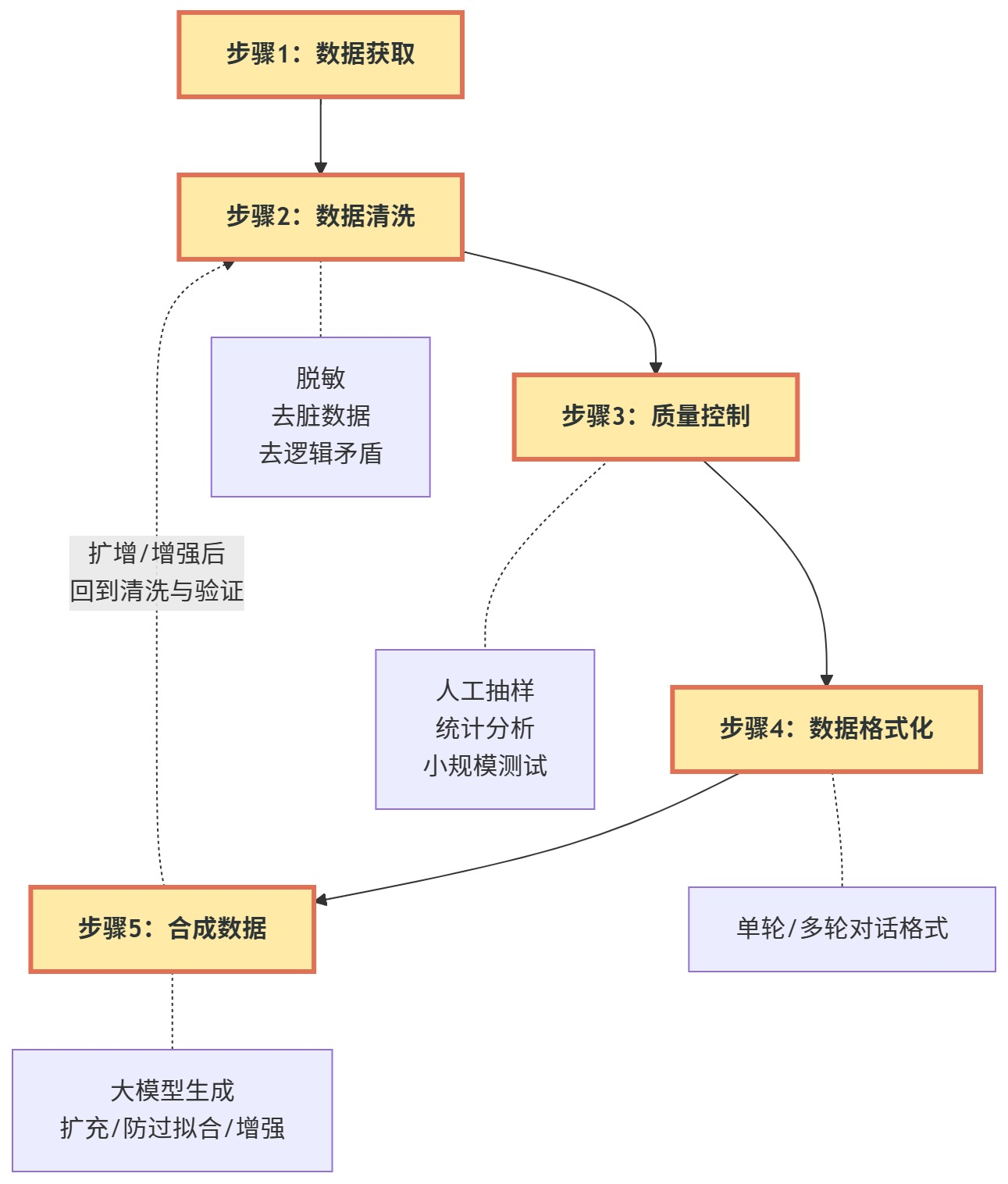
数据清洗
以下数据需要被清理掉:
-
HTML 标签、URL 链接
-
广告、垃圾信息、无意义的特殊字符
-
重复内容
-
逻辑矛盾的内容(1+1=2和1+1=3)
质量控制
-
人工抽样——几百条以内,每条都看一眼
-
统计分析——用 pandas 统计长度分布,找出异常数据
-
小规模测试——调一下试试效果
数据格式化
不同基座模型的对话格式不一样,下面以ChatML的对话格式举例
单轮对话
[
{
"messages": [
{"role": "system", "content": "你是一个乐于助人的数学助手。"},
{"role": "user", "content": "什么是勾股定理?"},
{"role": "assistant", "content": "勾股定理指出:直角三角形两条直角边的平方和等于斜边的平方。即 a² + b² = c²。"}
]
},
{
"messages": [
{"role": "user", "content": "推荐一本好书"},
{"role": "assistant", "content": "我推荐《百年孤独》,这是加西亚·马尔克斯的魔幻现实主义代表作。"}
]
},
{
"messages": [
{"role": "system", "content": "你是一个编程专家,只回答代码相关的问题。"},
{"role": "user", "content": "Python中如何反转字符串?"},
{"role": "assistant", "content": "可以使用切片:`text[::-1]`。例如:`'hello'[::-1]` 返回 `'olleh'`。"}
]
}
]多轮对话
[
{
"messages": [
{"role": "system", "content": "你是一个健康顾问,提供专业的健康建议。"},
{"role": "user", "content": "每天应该喝多少水?"},
{"role": "assistant", "content": "一般建议成年人每天饮水 1.5-2 升,约 8 杯水。运动或天气炎热时需要增加。"},
{"role": "user", "content": "喝水太多会有问题吗?"},
{"role": "assistant", "content": "会的。过量饮水可能导致低钠血症,建议根据口渴感和尿液颜色来判断水分是否充足。"}
]
}
]ChatML 格式说明
|
字段 |
类型 |
说明 |
|
|
array |
对话消息数组 |
|
|
string |
消息发送者角色: |
|
|
string |
消息内容 |
合成数据(数据扩增)
合成数据就是 “用大模型生成的数据,而不是从现实世界中采集的真实数据”。
合成数据的目的:
-
从已有模板扩充数据:只有 100 条真实对话,用大模型模仿风格再生成 200 条,凑成 300 条
-
多样化数据,避免过拟合:训练集只有“香蕉”,让大模型生成“苹果、梨、橙子”的描述,让模型见过更广的分布
-
增强数据,补充细节:一条真实回答有 60 分(有语法错误、逻辑跳跃),让大模型重写成 90 分的清晰答案,用来微调
生成后的数据仍然要走清洗和验证流程,不能直接喂给微调。
合成数据的步骤:
-
选择高质量数据作为种子数据集
-
设计提示模版
-
生成合成数据,查看效果
-
调整温度参数
-
修改提示模版
-
提升种子数据
-
-
清洗验证数据
合成数据提示词样例:
请根据下面的种子数据的例子,生成20条类似的指令-回答对,涵盖不同类型的任务,如问答、分析、写作等。生成的数据应符合以下要求:
1. 指令应该用中文陈述,长度在1-2句话
2. 可以包含一个可选的上下文输入,提供指令所需的背景信息
3. 回答应该严格由根据指令生成,力求完整、准确、简洁
4. 数据格式为:
{"instruction": "指令", "input": "上下文(选填)", "output": "回答"}
种子例子:
{"instruction": "介绍三种常见的云计算服务模式", "input": "", "output": "三种常见的云计算服务模式是:\n1. IaaS(基础设施即服务):用户可以租用云提供商的IT基础设施资源,如服务器、存储、网络等,并在其上部署自己的应用。\n2. PaaS(平台即服务):云提供商提供软件开发平台,包括操作系统、开发工具、数据库等,用户在平台上开发、运行和管理自己的应用。\n3. SaaS(软件即服务):云提供商通过网络提供各种应用软件,用户可以直接使用,无需购买、安装和维护。"}
{"instruction": "对比三国演义中曹操和刘备的性格特点", "input": "", "output": "曹操和刘备是三国演义中两位重要的角色,他们的性格特点对比鲜明:\n曹操:\n- 足智多谋,善于权谋算计,是个政治和军事天才\n- 雄心勃勃,志向远大,一心想统一全国\n- 不拘小节,用人唯才,提拔了很多优秀将领\n- 冷酷无情,为达目的不择手段,杀伐决断\n\n刘备:\n- 仁德厚道,宽容大度,关心百姓疾苦\n- 志向平和,有克己复礼、以德服人的儒家思想\n- 善于用人,招揽和团结了大批英雄豪杰\n- 韬光养晦,善于隐忍,不轻易显露锋芒\n\n总的来说,曹操代表着雄才大略的君王型人物,而刘备代表着仁厚宽容的仁君形象,两人的性格特点形成了鲜明的对比。"}
请根据以上要求生成20条指令数据。
微调框架
什么是微调框架:
微调框架就是针对大语言模型(LLM/AI 大模型)做二次定制化训练的全套工具链与开发框架。如果没有框架,微调就需要从零开始写 PyTorch/TensorFlow 代码来处理分布式计算、显存优化、梯度裁剪等复杂的底层数学逻辑。
主流微调框架
-
DeepSpeed(微软)
-
Unsloth
-
ms-swift(阿里)
-
Transformers(Hugging Face)
常见问题
1. 微调需要准备多大的数据集?
取决于你的产品需求:
-
简单需求:10-20条就够了
-
复杂需求:取决于有多少专业知识
实际上数据量是次要的,真正重要的是数据质量,100 万条质量参差不齐的海量数据,微调效果可能不如 1,000 条人工精选的“黄金数据”,数据质量决定了微调后模型的效果上限。
2. 可以进行多次微调吗?
可以,但最好不要,
多次微调会覆盖之前的知识,导致灾难性遗忘。而且,更新数据会很麻烦,删除数据会更麻烦。
3. 微调调的是什么?
调的是基座模型里的参数——很小一部分百分比的参数
总的来讲:微调的本质就是有了独特的数据,能表达独特的需求。而微调效果好不好,取决于数据能不能准确、全面地反映产品需求

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)