前端转全栈 —— 前后端部署指南(小白也能看懂)
DeepSeek AI 助手部署指南

项目描述
- 上一篇文章是前后端一把梭,现在是连部署也一起干了
- 真实购买的服务器,100%实战,不玩虚的
- 这是第二个全栈项目,整体还是不难的,重点讲一下部署
- 简单来说,接入了deepseek大模型,可以进行问答,效果如图所示:
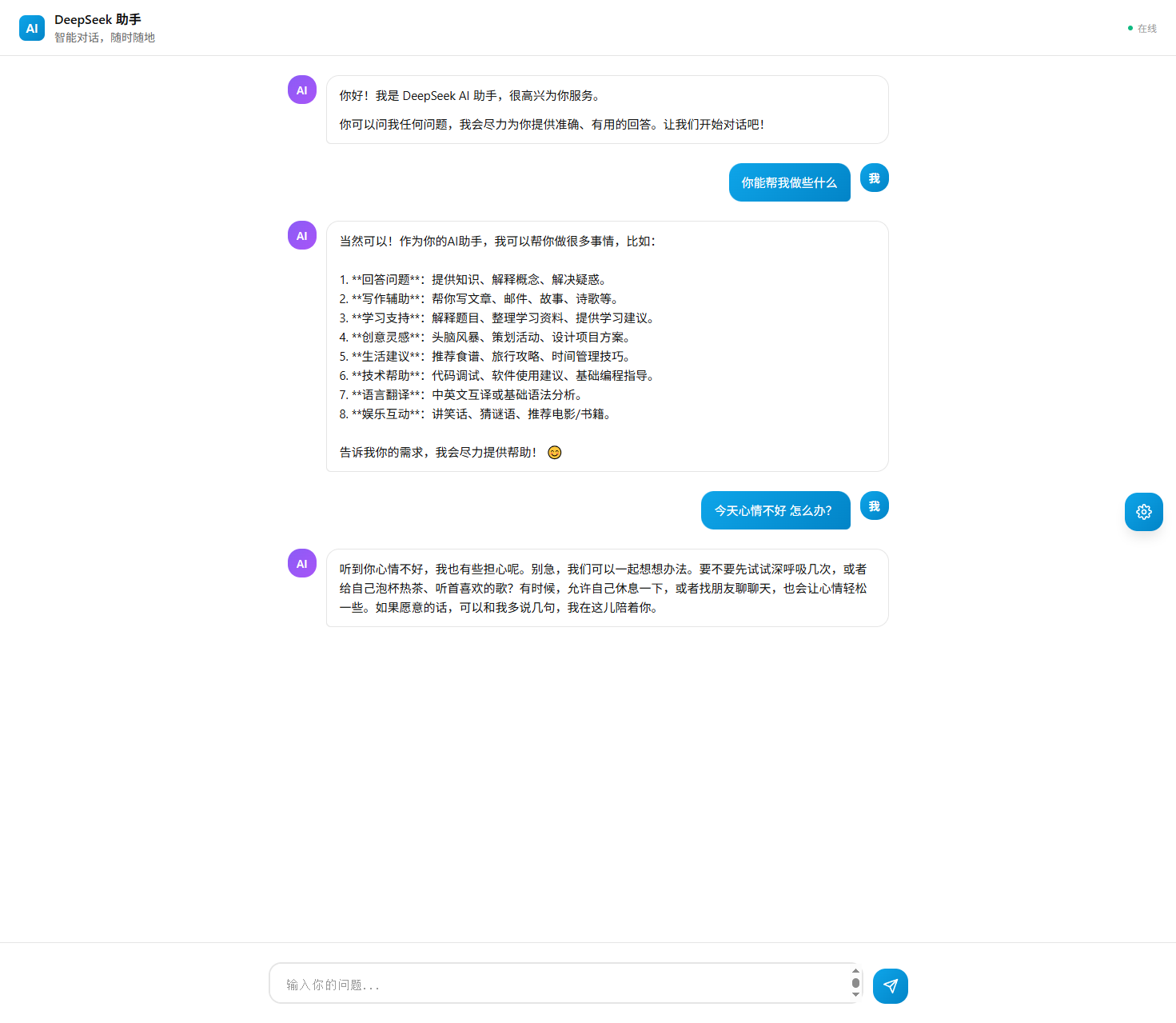
- 当然,也可以进行一些配置
本文档记录了从 0 到 1 的完整部署流程,包括前端静态部署、后端服务部署,以及部署过程中踩过的坑和解决方案。
适用人群:前端开发,对 Linux / Nginx / Python 不太熟悉的新手。
部署环境:阿里云 ECS + 宝塔面板 + Ubuntu/Debian 系统。
一、准备工作
1.1 你需要什么
| 项目 | 说明 |
|---|---|
| 一台云服务器 | 阿里云 / 腾讯云 / 其他,需要有公网 IP |
| 宝塔面板 | 安装在服务器上,用于可视化管理网站和文件 |
| 项目代码 | testAI.html、backend.py、requirements.txt、.env.example |
| DeepSeek API Key | 在 platform.deepseek.com 申请 |
1.2 项目架构简介
用户浏览器
│
▼
Nginx(80/8080 端口) ←── 前端静态文件(testAI.html)
│
└── /api/* 请求转发到 ──► Flask 后端(5000 端口)
│
▼
DeepSeek API
为什么需要 Nginx?
Nginx 是服务器的"门卫+前台"。浏览器只能通过 HTTP 端口访问服务器,Nginx 负责:
- 把访问页面的请求直接返回
testAI.html - 把发送消息的请求(
/api/chat)转发给后端的 Python 程序 - 没有 Nginx,用户打不开页面,前端和后端也无法正常通信。
二、前端静态部署(Nginx)
2.1 上传前端文件
- 登录宝塔面板(
http://你的服务器IP:8888) - 点击左侧 “文件”
- 进入
/www/wwwroot/目录 - 点击 “新建文件夹”,命名为
deepseek-ai - 进入
deepseek-ai文件夹 - 点击 “上传”,把
testAI.html上传到该目录
2.2 创建网站
- 点击左侧 “网站”
- 点击 “添加站点”
- 填写信息:
- 域名:填你的服务器公网 IP(例如
39.xx.x.xxx) - 根目录:
/www/wwwroot/deepseek-ai - 其他保持默认
- 域名:填你的服务器公网 IP(例如
- 点击 “提交”
2.3 修改 Nginx 配置文件
- 在网站列表找到刚创建的站点,点击 “设置”
- 点击左侧 “配置文件”
- 把内容替换为以下配置:
server {
# 监听 80 端口(HTTP 默认端口)
listen 80;
# 匹配所有请求(没有域名时用下划线)
server_name _;
# 网站根目录
root /www/wwwroot/deepseek-ai;
# 默认首页文件
index testAI.html;
# 处理所有页面请求
location / {
# 尝试匹配文件,找不到就返回 testAI.html(支持前端路由)
try_files $uri $uri/ /testAI.html;
}
# 把 /api/ 开头的请求转发给后端 Flask(5000端口)
location /api/ {
proxy_pass http://127.0.0.1:5000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
# 健康检查接口也转发给后端
location /health {
proxy_pass http://127.0.0.1:5000/health;
}
}
- 点击 “保存”
2.4 阿里云安全组开放端口
宝塔里配置好了,但阿里云还有一层"防火墙"(安全组),默认只开放 22 端口。需要手动开放 80 端口。
- 登录 阿里云控制台
- 搜索 “云服务器 ECS”,找到你的服务器
- 点击 “安全组” → “管理规则”
- 点击 “手动添加”,填写:
- 优先级:
1 - 协议:
TCP - 端口范围:
80/80 - 源:
0.0.0.0/0(允许所有 IP 访问) - 描述:
HTTP访问
- 优先级:
- 点击 “保存”
如果 80 端口仍无法访问,可以临时把 Nginx 配置里的
listen 80;改成listen 8080;,同时安全组开放8080端口,浏览器访问http://IP:8080。
2.5 验证前端
浏览器访问 http://你的服务器IP,能看到 AI 聊天页面即表示前端部署成功。
此时发送消息会报错,因为后端还没部署,下一步继续。
三、后端服务部署(Flask + Gunicorn)
3.1 上传后端代码
- 宝塔面板 → “文件”
- 进入
/www/wwwroot/deepseek-ai - 点击 “上传”,把以下文件上传:
backend.py(后端主程序)requirements.txt(Python 依赖列表).env.example(环境变量模板)
- 把
.env.example重命名为.env - 双击打开
.env,把DEEPSEEK_API_KEY改成你的真实 API Key:
DEEPSEEK_API_KEY=sk-xxxxxxxxx # ← 改成你的真实 Key
DEEPSEEK_URL=https://api.deepseek.com/v1/chat/completions
FLASK_ENV=production
PORT=5000
3.2 安装 Python 虚拟环境
- 宝塔面板 → “终端”
- 依次执行以下命令:
# 进入项目目录
cd /www/wwwroot/deepseek-ai
# 创建虚拟环境(隔离项目依赖,不影响系统 Python)
python3 -m venv venv
命令解释:
python3 -m venv venv:在当前目录创建一个叫venv的虚拟环境- 虚拟环境就像给项目单独建了一个"小房间",里面安装的包不会影响系统环境
遇到的问题:ensurepip 不可用
现象:
The virtual environment was not created successfully because ensurepip is not available.
原因:Ubuntu/Debian 系统默认没有安装创建虚拟环境所需的模块。
解决:
# 安装 python3-venv 包
apt install python3.12-venv -y
# 如果提示权限不足,加 sudo
sudo apt install python3.12-venv -y
安装完成后,重新执行创建虚拟环境的命令:
python3 -m venv venv
3.3 安装 Python 依赖
# 激活虚拟环境(进入"小房间")
source venv/bin/activate
# 安装项目依赖
pip install -r requirements.txt
命令解释:
source venv/bin/activate:激活虚拟环境,之后pip和python命令都会使用虚拟环境中的版本pip install -r requirements.txt:按照 requirements.txt 里的列表自动安装 Flask、requests、gunicorn
requirements.txt 内容说明:
Flask>=2.0.0 # Web 框架,提供 HTTP 服务
requests>=2.0.0 # HTTP 客户端,用于调用 DeepSeek API
gunicorn>=20.0.0 # Python WSGI 服务器,比 Flask 自带服务器更稳定
3.4 启动后端服务
先测试能否正常启动
# 在虚拟环境中运行后端(前台运行,方便看日志)
python backend.py
如果看到类似 Running on http://0.0.0.0:5000,说明后端代码没问题。
按 Ctrl + C 停止,接下来用 Gunicorn 在后台运行。
使用 Gunicorn 后台启动
# 用 nohup 让进程在后台运行,关闭终端也不会停止
# 日志输出到 app.log
nohup gunicorn --bind 0.0.0.0:5000 --workers 2 backend:app > app.log 2>&1 &
命令解释:
nohup:忽略挂断信号,终端关闭后程序继续运行gunicorn:生产级 Python Web 服务器--bind 0.0.0.0:5000:绑定到服务器的 5000 端口,允许外网访问(Nginx 会通过内网转发过来)--workers 2:启动 2 个工作进程,能同时处理多个请求backend:app:加载backend.py文件中的app对象(Flask 实例)> app.log 2>&1:把正常运行日志和错误日志都写入app.log&:放到后台执行
遇到的问题:端口被占用
现象:日志里反复出现:
[ERROR] Connection in use: ('0.0.0.0', 5000)
[ERROR] connection to ('0.0.0.0', 5000) failed: [Errno 98] Address already in use
原因:之前测试启动的后端进程没有关闭,或者多次执行了启动命令,多个进程抢占了 5000 端口。
解决:
# 查看占用 5000 端口的进程
lsof -i :5000
# 杀掉所有 gunicorn 和 python 后端进程
pkill -f gunicorn
pkill -f "python backend.py"
# 清理旧日志
rm -f app.log
# 重新启动
source venv/bin/activate
nohup gunicorn --bind 0.0.0.0:5000 --workers 2 backend:app > app.log 2>&1 &
# 确认只有一个进程在跑
lsof -i :5000
3.5 验证后端是否正常运行
在宝塔终端执行:
# 测试健康检查接口
curl http://127.0.0.1:5000/health
正常返回:
{"status": "healthy", "timestamp": 1234567890, "version": "1.0.0"}
再测试聊天接口:
curl -X POST http://127.0.0.1:5000/api/chat \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "user", "content": "你好"}]}'
如果返回了 DeepSeek 的回复,说明后端完全正常。
四、完整功能验证
- 打开浏览器,访问
http://你的服务器IP - 在聊天框输入消息,点击发送
- 如果能看到 AI 回复,说明前后端联动成功!
五、常见问题速查
Q1:浏览器访问 IP 显示"没有找到站点"
原因:Nginx 没有匹配到对应的站点。
排查:
- 检查宝塔网站列表里的域名是否和你访问的 IP 一致
- 检查 Nginx 配置文件的
server_name是否填了_(匹配所有) - 检查阿里云安全组是否开放了对应端口
Q2:前端页面能打开,但发送消息报错 500
原因:后端内部错误。
排查:
# 查看最新错误日志
cat /www/wwwroot/deepseek-ai/app.log
- 检查
.env里的DEEPSEEK_API_KEY是否已填入真实 Key - 检查后端进程是否还在跑:
lsof -i :5000
Q3:阿里云安全组已经开放端口,但还是访问不了
原因:宝塔面板本身也有防火墙。
排查:宝塔面板 → “安全” → 检查是否放行了对应端口。
Q4:服务器重启后后端不工作了
原因:nohup 启动的进程不会随系统开机自动启动。
解决:服务器重启后,重新执行启动命令:
cd /www/wwwroot/deepseek-ai
source venv/bin/activate
nohup gunicorn --bind 0.0.0.0:5000 --workers 2 backend:app > app.log 2>&1 &
如果需要开机自动启动,可以在宝塔安装 Supervisor 插件来管理进程。
六、文件目录结构
部署完成后,服务器上的文件结构应该是这样:
/www/wwwroot/deepseek-ai/
├── testAI.html # 前端页面
├── backend.py # Flask 后端主程序
├── requirements.txt # Python 依赖列表
├── .env # 环境变量配置(含 API Key)
├── venv/ # Python 虚拟环境目录
│ ├── bin/
│ └── lib/
└── app.log # 后端运行日志
七、技术栈总结
| 层级 | 技术 | 作用 |
|---|---|---|
| 前端 | HTML + CSS + JS | 用户交互界面 |
| Web 服务器 | Nginx | 静态文件托管、反向代理、端口转发 |
| 后端框架 | Flask | 提供 REST API |
| WSGI 服务器 | Gunicorn | 生产环境运行 Flask |
| 代理服务 | DeepSeek API | AI 大模型对话能力 |
1. 希望本文能对大家有所帮助,如有错误,敬请指出
2. 原创不易,还请各位客官动动发财的小手支持一波(关注、评论、点赞、收藏)
3. 拜谢各位!后续将继续奉献优质好文


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)