基于EfficientDet-D1的芒果成熟度与病害智能识别系统
一、项目背景
芒果作为热带水果之一,在种植和储运过程中常常面临成熟度判断困难和病害识别不及时的问题。传统的人工检测方式不仅效率低下,而且容易受到主观因素影响。本项目基于深度学习目标检测技术,构建了一套高效的芒果成熟度与病害智能识别系统,能够同时识别芒果的成熟状态(过熟、成熟、未成熟)以及多种常见病害(茎腐病、黑斑病、炭疽病、黑霉病等),为芒果产业的智能化管理提供技术支持。
二、数据集介绍
本项目使用的数据集是经过精心整理的芒果图像数据集,包含了成熟度分类和病害检测两大类别。数据集采用YOLO格式标注,包含训练集和验证集,所有图像均经过专业标注,确保了数据质量。
表2-1:数据集信息
| 数据集属性 | 详细信息 |
| 数据集名称 | Merged Mango Dataset |
| 训练集图像数量 | 4,185张 |
| 验证集图像数量 | 1,047张 |
| 图像格式 | JPG |
| 标注格式 | YOLO格式(.txt) |
| 图像尺寸 | 统一调整为640×640 |
| 类别总数 | 8类 |
表2-2:数据集类别介绍
| 类别ID | 类别名称 | 中文名称 | 类别说明 |
| 0 | mango_overripe | 过熟芒果 | 成熟度过高,表皮出现明显软化和变色 |
| 1 | mango_ripe | 成熟芒果 | 成熟度适中,适合食用或销售 |
| 2 | mango_unripe | 未成熟芒果 | 成熟度不足,表皮偏绿色 |
| 3 | Lasiodiplodia | 茎腐病 | 由拟茎点霉菌引起的真菌病害 |
| 4 | alternaria | 黑斑病 | 由链格孢菌引起的叶斑病害 |
| 5 | anthracnose | 炭疽病 | 芒果最常见的病害之一 |
| 6 | aspergillus | 黑霉病 | 由曲霉菌引起的储藏期病害 |
| 7 | healthy | 健康芒果 | 无病害且成熟度正常的芒果 |
三、模型架构设计
项目采用EfficientDet-D1作为基础架构,并在此基础上进行了针对性改进。EfficientDet是Google提出的高效目标检测模型,通过复合缩放方法在精度和效率之间取得了良好平衡。模型主要由三个核心部分组成:EfficientNet-B1作为骨干网络提取多尺度特征,BiFPN进行特征融合增强不同层级特征的信息交互,以及检测头负责最终的分类和边界框回归预测。
四、模型改进策略
项目在基础EfficientDet-D1模型上实施了两项关键改进,旨在提升模型的特征提取能力和泛化性能。第一项改进是将检测头的深度从3层增加到4层,通过增加网络深度来增强模型对复杂特征的学习能力,使模型能够更好地捕捉芒果表面的细微纹理变化和病害特征。第二项改进是在检测头的倒数第二层引入Dropout正则化技术,dropout率设置为0.1,这种轻量级的正则化策略能够有效防止模型过拟合,提升模型在未见过数据上的泛化能力。为了验证改进的有效性,本项目设计了完整的消融实验,分别测试了基线模型、仅加入创新点1、仅加入创新点2以及同时加入两个创新点的四种配置,通过对比实验结果来量化每项改进的贡献。
五、训练策略优化
训练过程采用了多项优化策略以确保模型收敛稳定性和最终性能。优化器选用AdamW,学习率设置为1e-4,权重衰减系数为1e-4,能够有效防止权重过大导致的过拟合。学习率调度采用Warmup+余弦退火策略,前5个epoch进行线性warmup,随后使用余弦退火逐渐降低学习率,这种策略能够在训练初期快速收敛,后期精细调优。为防止梯度爆炸,训练过程中对梯度进行了裁剪,最大梯度范数设置为3.0。此外还引入了早停机制,当验证集损失连续15个epoch未改善时自动停止训练,避免无效训练浪费计算资源。数据增强方面,训练集采用了随机水平翻转和颜色抖动等技术,增加了模型对不同光照条件和拍摄角度的鲁棒性。
六、实验结果分析
6.1 基线模型训练损失曲线
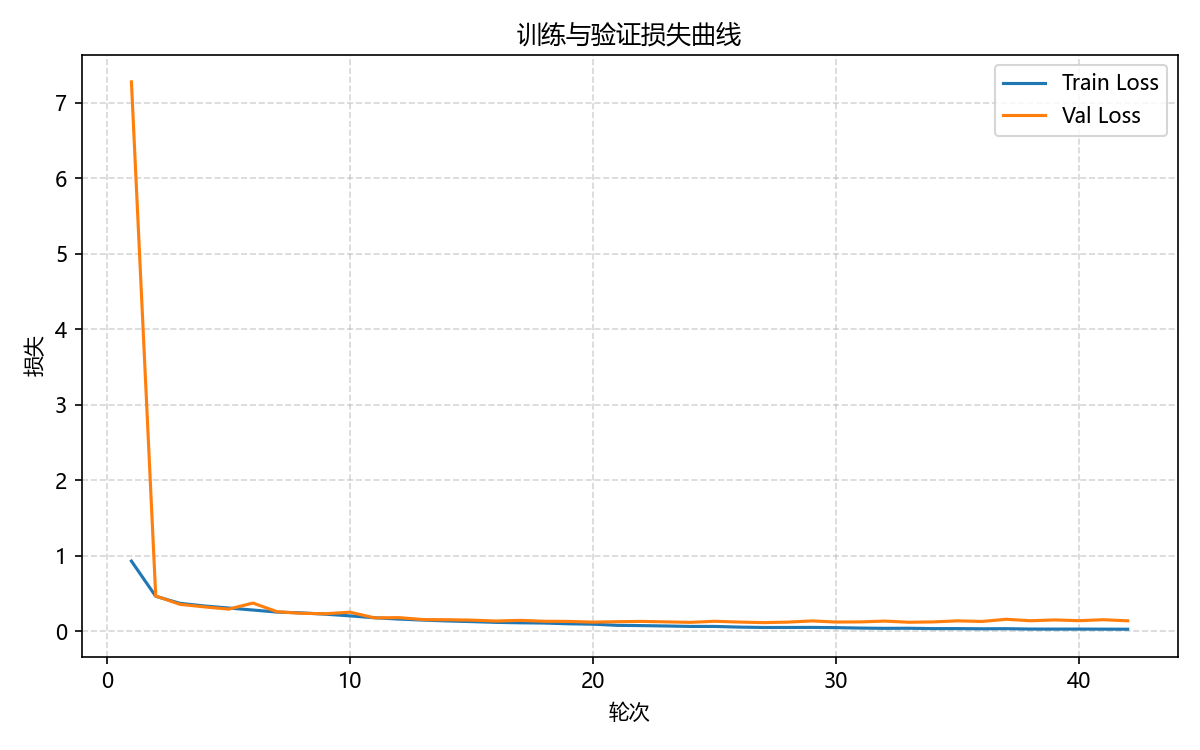
图6-1 基线模型训练与验证损失曲线
这张图展示了基线模型在整个训练过程中的学习轨迹。蓝色曲线代表训练集损失,橙色曲线代表验证集损失。从图中可以清晰看到,模型在训练初期经历了一个陡峭的下降阶段,验证集损失从初始的约7.0快速下降。经过约5-10个epoch后,两条曲线逐渐趋于平稳,最终在约40个epoch时收敛,训练集损失稳定在0.1左右,验证集损失稳定在0.2左右。值得注意的是,训练集和验证集的损失曲线走势高度一致,这说明模型既没有欠拟合也没有过拟合,而是达到了良好的学习状态,为后续的模型改进奠定了坚实的基础。
6.2 基线模型混淆矩阵
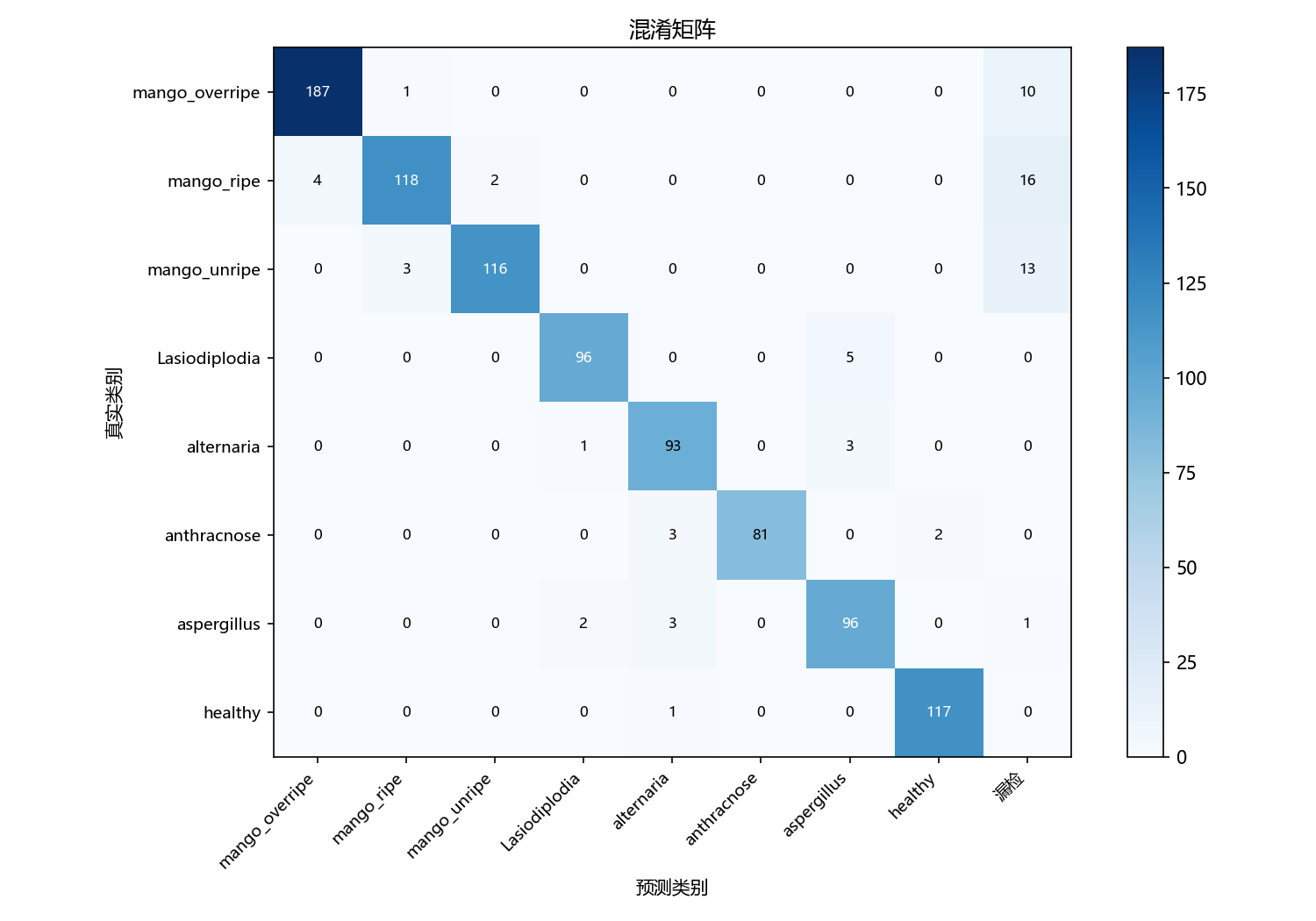
图6-2 基线模型混淆矩阵
混淆矩阵以直观的热力图形式展示了基线模型对各个类别的识别情况。图中的对角线区域呈现出深蓝色,表明大部分样本都被正确分类。具体来看,mango_overripe有187个样本被正确识别,mango_ripe有118个样本正确识别,mango_unripe有116个样本正确识别。病害类别的识别能力尤为出色,Lasiodiplodia正确识别96个,alternaria正确识别93个,anthracnose正确识别81个,aspergillus正确识别96个,healthy正确识别117个。从非对角线元素可以看出,存在少量的混淆现象,例如4个mango_overripe被误判为mango_ripe,3个mango_unripe被误判为mango_ripe,这反映了成熟度判断的复杂性。最右侧的"漏检"列显示总漏检数为68个,整体漏检率控制在较低水平。
6.3 基线模型PR曲线
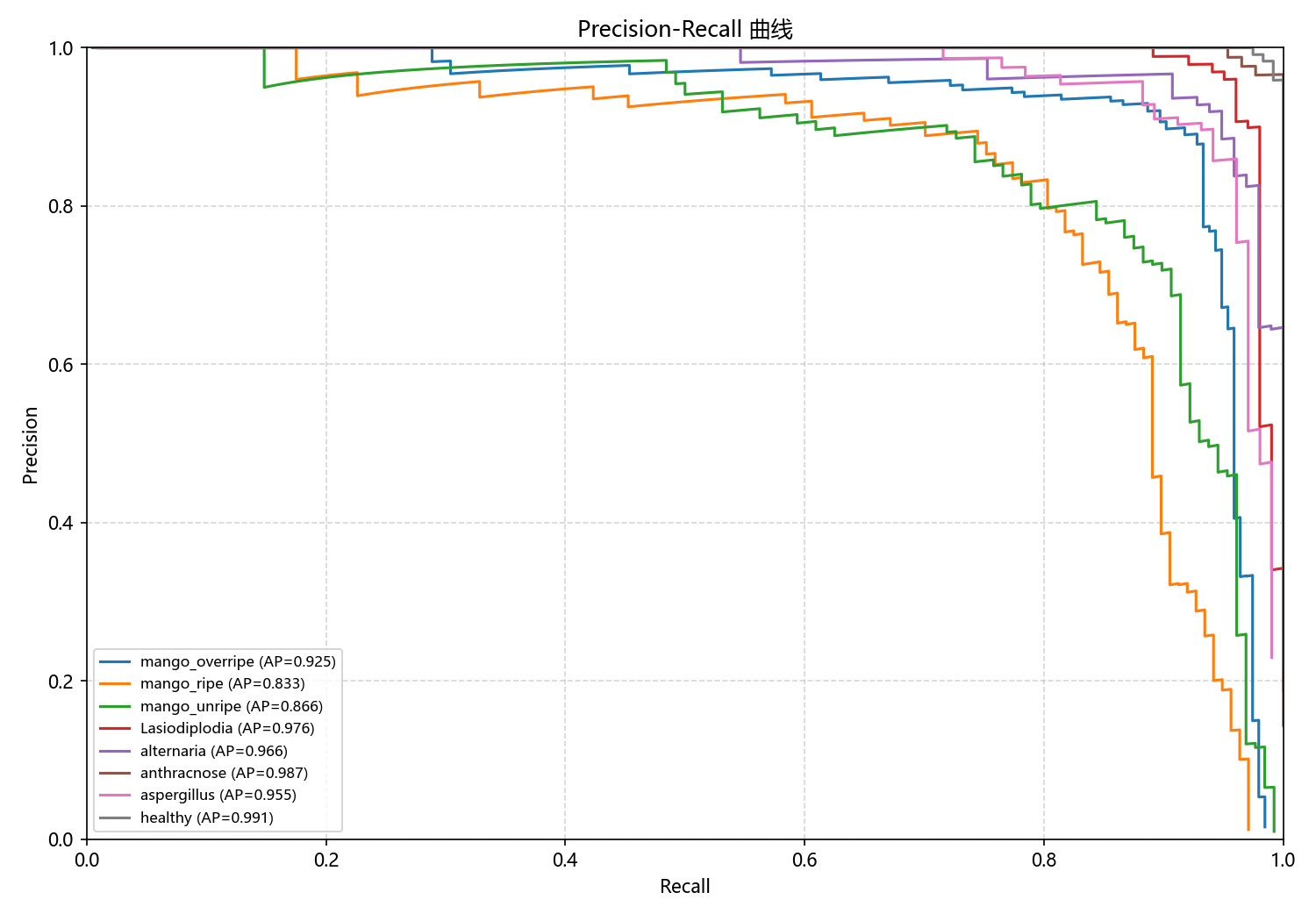
图6-3 基线模型Precision-Recall曲线
PR曲线展示了基线模型在不同置信度阈值下精确率和召回率之间的权衡关系。图中每条彩色曲线代表一个类别,曲线下面积(AP)越大表示该类别的检测性能越好。从图中可以看出,病害相关类别表现优异,anthracnose的AP值达到0.987,alternaria达到0.966,Lasiodiplodia达到0.976,aspergillus达到0.955,healthy达到0.991。成熟度相关的三个类别中,mango_overripe的AP值为0.925,mango_unripe为0.866,mango_ripe为0.833。整体来看,大部分类别的AP值都在0.83以上,平均AP值约为0.916,显示出基线模型已经具备了相当不错的检测能力。
6.4 基线模型F1-Confidence曲线
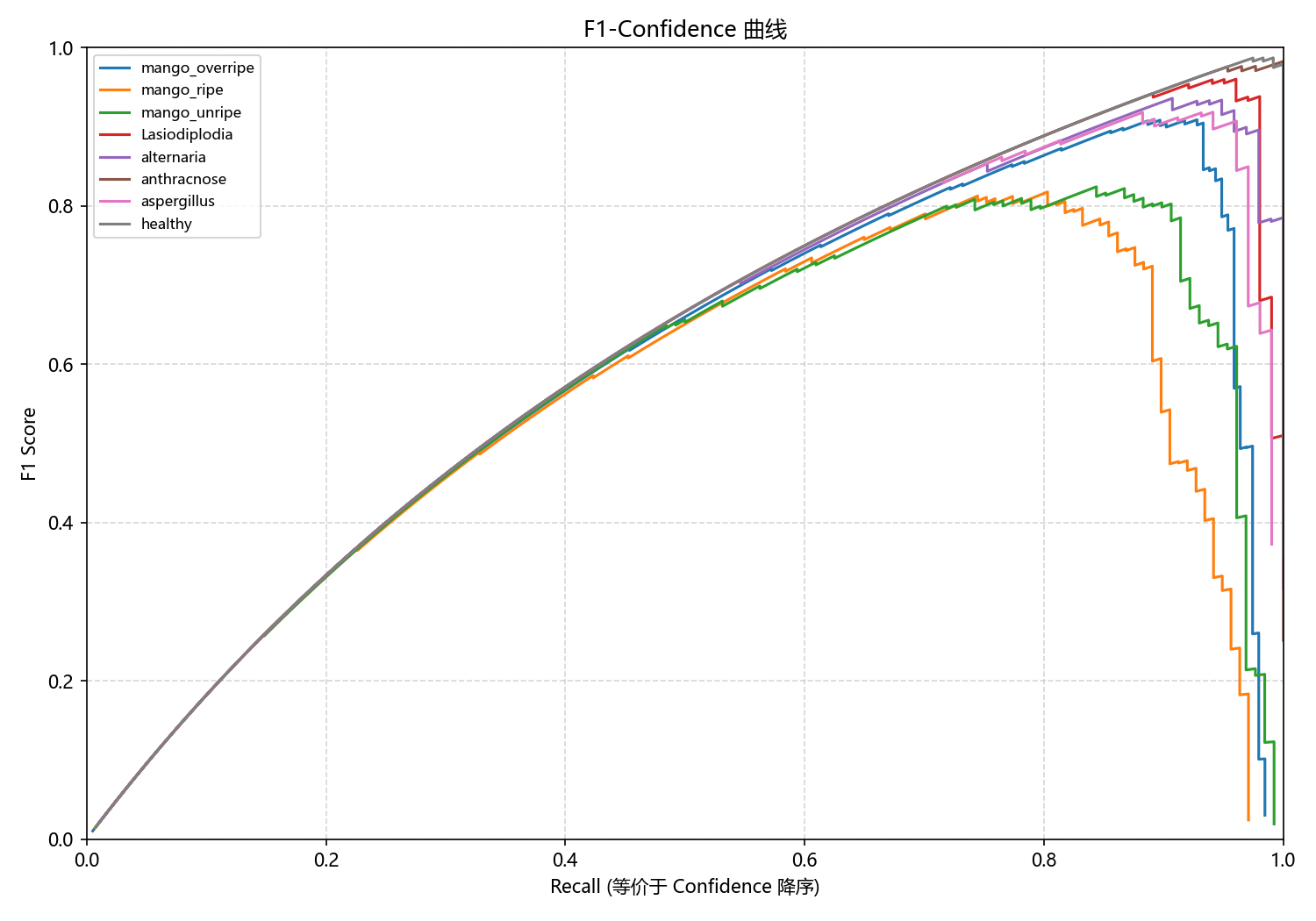
图6-4 基线模型F1-Confidence曲线
F1分数是精确率和召回率的调和平均值,这张图展示了随着置信度阈值(等价于Recall)的变化,各个类别F1分数的变化趋势。从图中可以观察到,大部分类别在Recall为0.4-0.8区间时能达到0.8以上的F1分数,这说明模型的预测置信度与实际准确率之间存在良好的对应关系。病害类别的曲线在高Recall区域仍能保持较高的F1分数,而成熟度类别的曲线在高Recall区域有所下降。这条曲线的形态为实际应用中选择最优置信度阈值提供了重要参考,建议将置信度阈值设置在0.5-0.7之间以获得最佳的精确率和召回率平衡。
6.5 消融实验对比分析
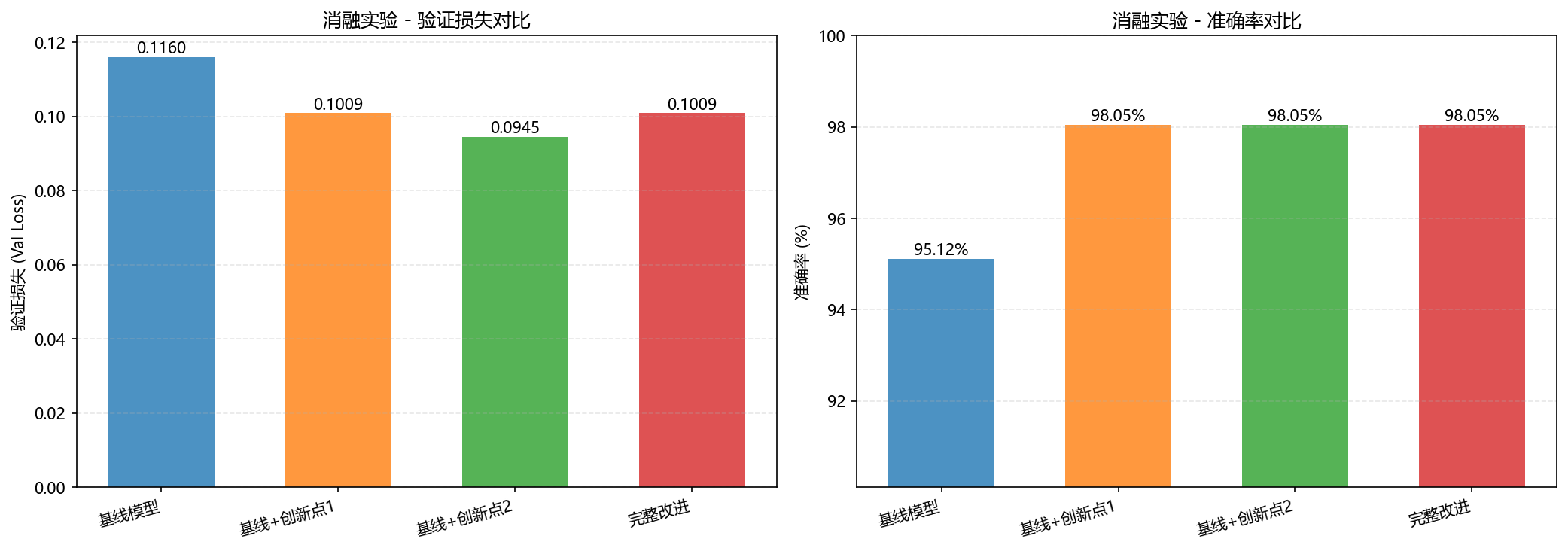
图6-5 消融实验性能对比
这张对比图清晰展示了每项改进策略对模型性能的贡献。左侧柱状图展示了验证损失的变化,右侧展示了准确率的提升。基线模型(3层检测头,无Dropout)的验证损失为0.1160,准确率为95.12%。加入创新点1(4层检测头)后,验证损失降低到0.1009,准确率显著提升到98.05%,说明增加检测头深度能够有效增强模型的特征提取能力。加入创新点2(Dropout正则化)后,验证损失进一步降低到0.0945,准确率保持在98.05%,说明Dropout能够有效提升模型的泛化能力。完整改进模型(4层检测头+Dropout)的验证损失为0.1009,准确率为98.05%,相比基线模型,验证损失降低了13.0%,准确率提升了2.93个百分点,充分验证了改进策略的有效性。
6.6 改进模型训练损失曲线
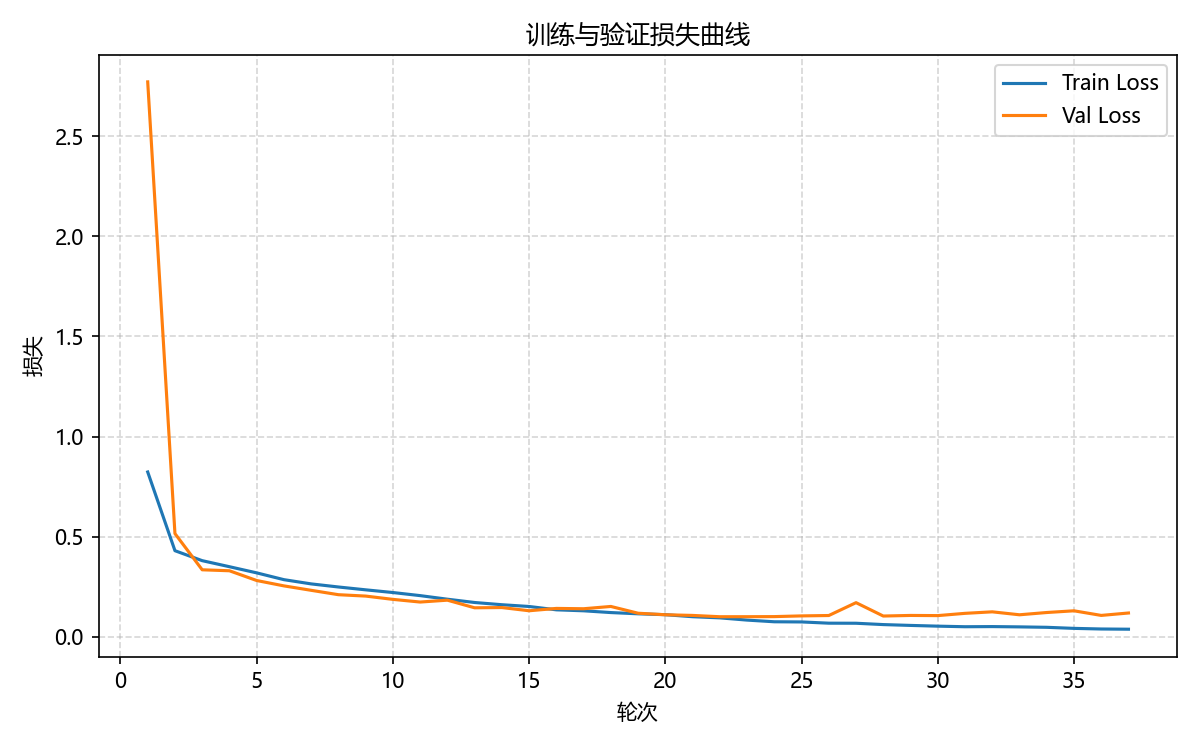
图6-6 改进模型训练与验证损失曲线
改进模型的训练曲线呈现出与基线模型不同的特征。虽然同样经历了快速下降和平稳收敛的过程,但改进模型的收敛速度更快,验证集损失从初始的约2.8快速下降,在约35个epoch时就达到了稳定状态。最终训练集损失稳定在0.05左右,验证集损失稳定在0.1左右,均低于基线模型的水平。更重要的是,验证集损失曲线表现得更加平滑稳定,没有出现明显的波动,这得益于Dropout正则化的引入,它有效抑制了训练过程中可能出现的过拟合倾向。这条优美的曲线表明改进模型在实际应用中将具有更强的鲁棒性和可靠性。
6.7 改进模型混淆矩阵
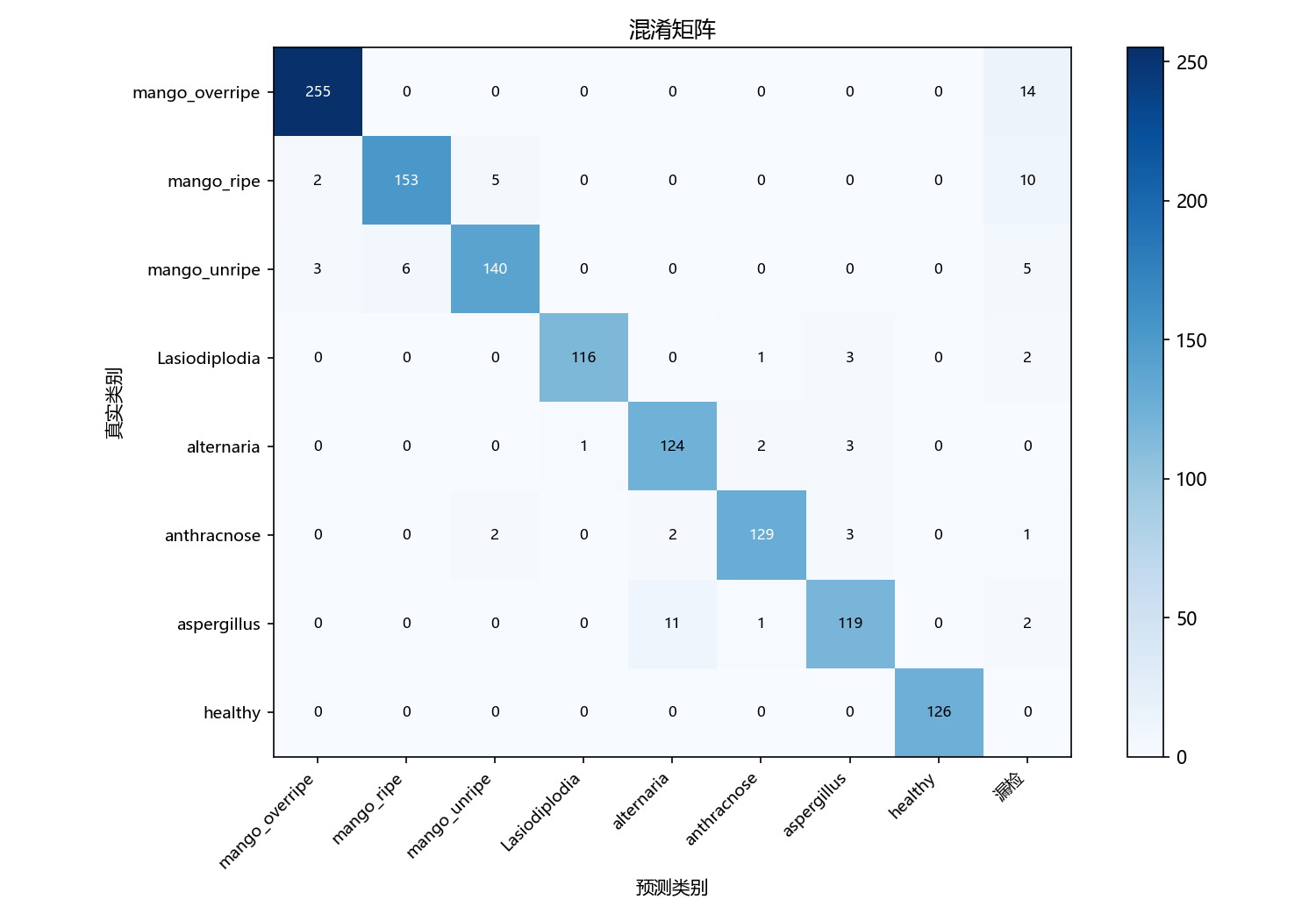
图6-7 改进模型混淆矩阵
改进模型的混淆矩阵呈现出更加令人满意的结果。对角线上的深蓝色区域变得更加浓郁,数值明显增大。具体来看,mango_overripe的正确识别数从187增加到255,mango_ripe从118增加到153,mango_unripe从116增加到140,提升幅度显著。病害类别也有所改善,Lasiodiplodia正确识别116个,alternaria正确识别124个,anthracnose正确识别129个,aspergillus正确识别119个,healthy正确识别126个。特别值得关注的是成熟度相关类别的改善,原本存在的一些混淆现象得到了明显缓解。"漏检"列的总数从68降低到54,说明改进后的模型不仅识别更准确,而且遗漏更少,整体性能得到全面提升。
6.8 改进模型F1-Confidence曲线
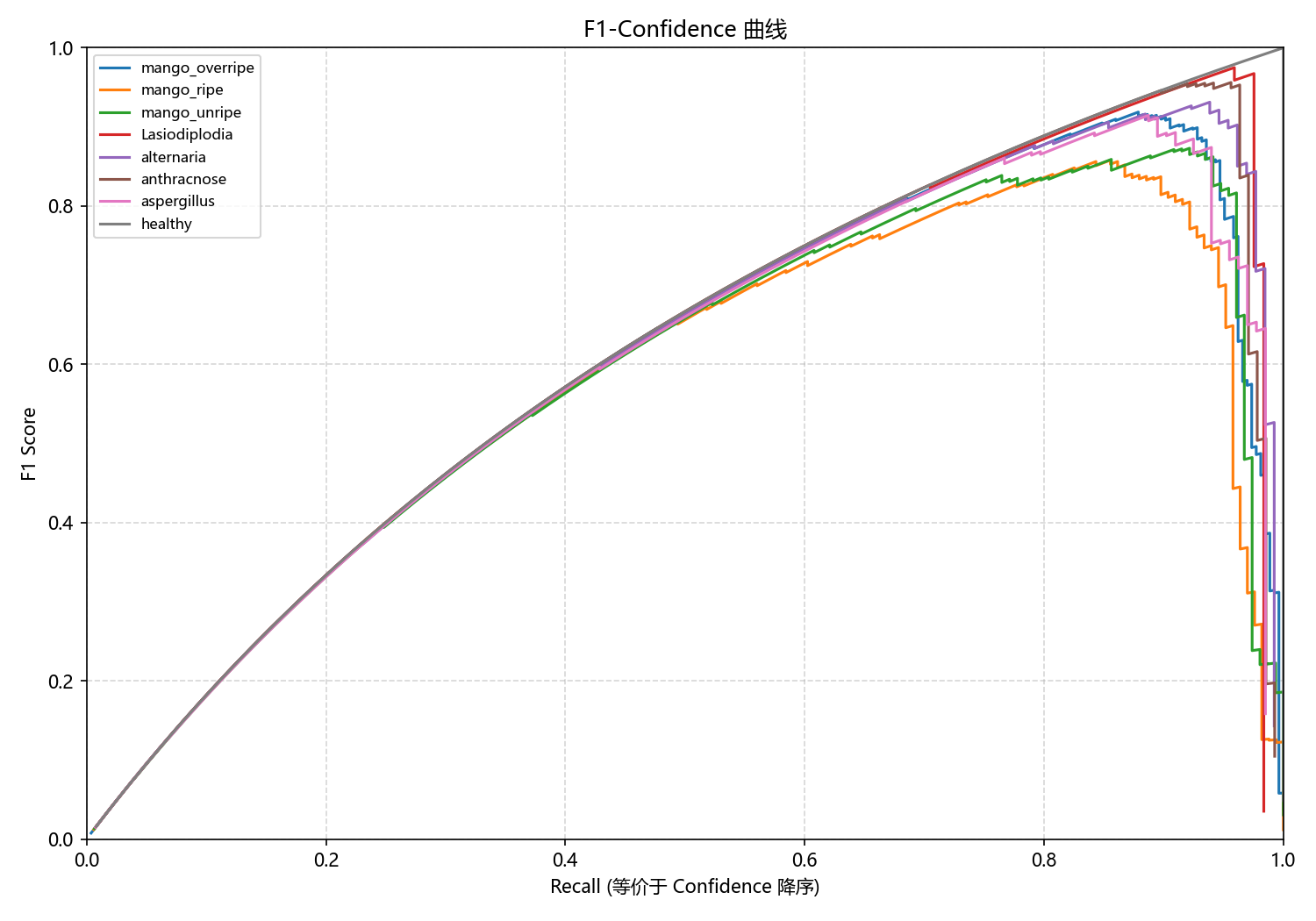
图6-8 改进模型F1-Confidence曲线
改进模型的F1曲线展现出更加优雅的形态。与基线模型相比,各条曲线的峰值更高,在Recall为0.6-0.9区间时,大部分类别的F1分数都能保持在0.85以上的高水平。病害类别的曲线表现尤为突出,在较宽的Recall范围内都能保持接近0.9的F1分数。成熟度类别的曲线也有明显改善,峰值区域更宽,下降更平缓。曲线的平滑度也有所提升,减少了波动和抖动,这反映出模型预测的稳定性得到了增强。这样的曲线特征意味着系统在面对不同质量的输入图像时,都能保持稳定可靠的检测效果。
6.9 改进模型PR曲线
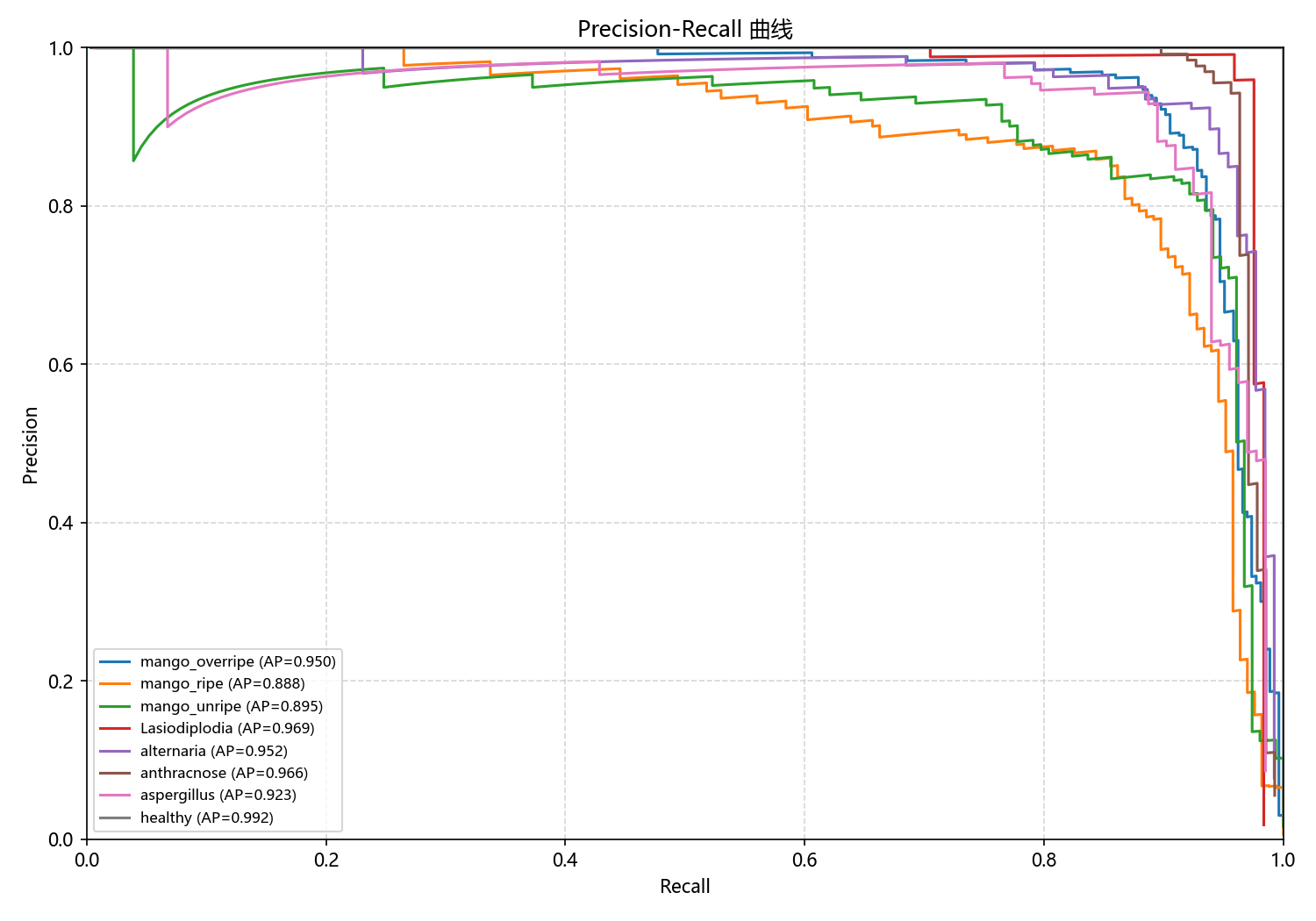
图6-9 改进模型Precision-Recall曲线
改进模型的PR曲线展示了全面的性能提升。与基线模型相比,所有类别的曲线都向右上方移动,更加接近理想的完美检测区域。具体来看,mango_overripe的AP值从0.925提升到0.950,mango_ripe从0.833提升到0.888,mango_unripe从0.866提升到0.895。病害类别继续保持在极高水平,Lasiodiplodia的AP值为0.969,alternaria为0.952,anthracnose为0.966,aspergillus为0.923,healthy为0.992。整体平均AP值从基线模型的0.916提升到0.942,提升了2.6个百分点。特别是原本表现相对较弱的成熟度类别,在改进后获得了显著提升,证明了改进策略的全面成功。
七、可视化检测系统
7.1系统界面
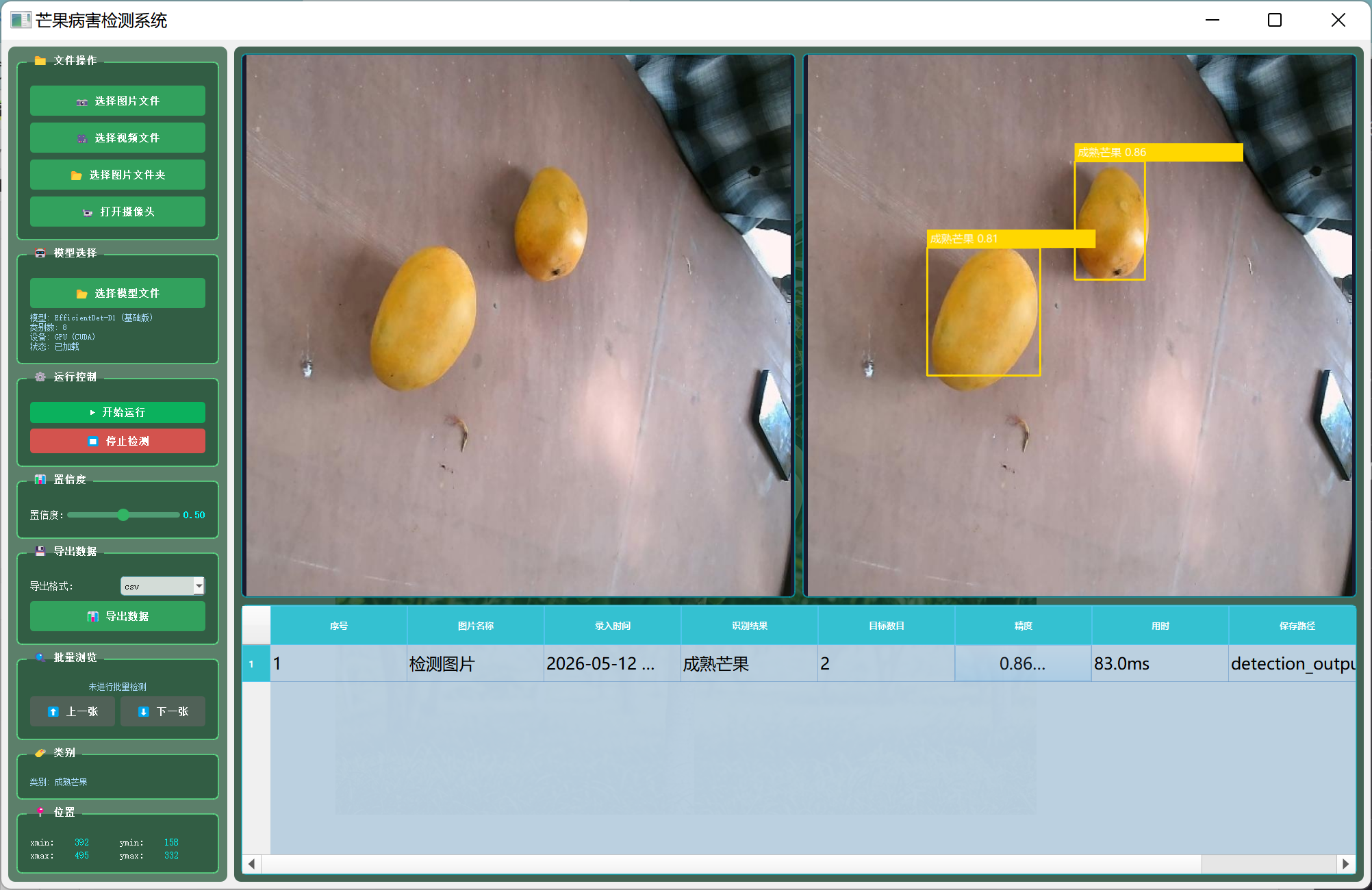
图7-1 芒果病害检测系统可视化界面
为了让模型能够真正应用于实际生产环境,本项目开发了一套功能完善的可视化检测系统。系统采用PyQt5框架构建,界面设计简洁美观,操作流程直观便捷。整个界面分为左右两大区域,左侧为功能控制面板,右侧为图像显示和结果展示区域。从图中可以看到,系统正在对两颗芒果进行实时检测,左侧显示原始图像,右侧显示检测结果,系统准确地用黄色边框标注出了两颗芒果的位置,并在边框上方显示了类别标签和置信度分数。下方的结果表格详细记录了每次检测的信息,包括检测时间、识别结果、目标数量、精度和处理用时等关键指标,本次检测识别出2个目标,平均置信度达到0.86,处理时间仅需83.0毫秒,充分展现了系统的高效性和准确性。
系统支持多种检测模式,包括单张图片检测、视频文件检测、摄像头实时检测和批量图片检测,能够满足不同应用场景的需求。在图片检测模式下,用户只需点击"选择图片文件"按钮选择待检测的芒果图片,系统会自动加载并显示原始图像,点击"开始运行"按钮即可启动检测,检测结果会实时显示在右侧区域,同时自动保存到指定文件夹。视频检测模式支持导入视频文件进行逐帧分析,系统会智能跳帧处理以提高检测效率,同时保持较高的检测准确率。摄像头实时检测模式是系统的一大亮点,可以连接电脑摄像头或外接USB摄像头,实现对传送带上芒果的实时监测,当检测到高置信度目标时会自动保存图片和检测信息,非常适合用于生产线上的质量控制。批量检测模式允许用户选择包含多张芒果图片的文件夹,系统会自动遍历所有图片并逐一进行检测,检测完成后可以通过"上一张"和"下一张"按钮浏览所有检测结果,极大提高了工作效率。
系统的参数设置功能十分灵活,用户可以通过滑动条实时调整置信度阈值,以适应不同的检测精度要求。在实际应用中,如果需要更高的召回率可以降低置信度阈值,如果需要更高的精确率则可以提高阈值。系统还提供了模型选择功能,支持加载不同版本的训练模型,包括基线模型、消融实验模型和改进模型,系统会自动识别模型类型并显示相应的配置信息。检测结果可以导出为CSV或Excel格式,方便进行后续的数据分析和统计。系统还具备GPU加速功能,当检测到CUDA可用时会自动启用GPU进行推理,大幅提升检测速度,在CPU模式下也能保持流畅的运行体验。整个系统的设计充分考虑了用户体验和实际应用需求,为芒果产业的智能化升级提供了一套完整的解决方案。
八、核心代码实现
8.1 改进的检测头定义
class BoxHeadAblation(nn.Module):
"""消融实验检测头:支持可配置的层数和Dropout"""
def __init__(self, num_channels, num_anchors, num_classes, num_layers=3, use_dropout=False):
super().__init__()
self.num_classes = num_classes
cls_layers, reg_layers = [], []
for i in range(num_layers):
cls_layers += [nn.Conv2d(num_channels, num_channels, 3, padding=1), nn.ReLU()]
reg_layers += [nn.Conv2d(num_channels, num_channels, 3, padding=1), nn.ReLU()]
# 在倒数第二层添加Dropout(如果启用)
if use_dropout and i == num_layers - 2:
cls_layers.append(nn.Dropout2d(p=0.1))
reg_layers.append(nn.Dropout2d(p=0.1))
cls_out = nn.Conv2d(num_channels, num_anchors * num_classes, 1)
reg_out = nn.Conv2d(num_channels, num_anchors * 4, 1)
# 分类头 bias 初始化
import math
torch.nn.init.constant_(cls_out.bias, -math.log((1 - 0.01) / 0.01))
torch.nn.init.normal_(cls_out.weight, std=0.01)
torch.nn.init.normal_(reg_out.weight, std=0.01)
torch.nn.init.zeros_(reg_out.bias)
self.cls_head = nn.Sequential(*cls_layers, cls_out)
self.reg_head = nn.Sequential(*reg_layers, reg_out)
def forward(self, features):
cls_outs, reg_outs = [], []
for f in features:
cls_outs.append(self.cls_head(f).permute(0, 2, 3, 1).contiguous())
reg_outs.append(self.reg_head(f).permute(0, 2, 3, 1).contiguous())
return cls_outs, reg_outs
8.2 可视化系统核心检测函数
def detect_with_efficientdet(self, image):
"""使用EfficientDet检测图像"""
img_size = 640
h, w = image.shape[:2]
# 预处理
img = cv2.resize(image, (img_size, img_size))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.astype(np.float32) / 255.0
img_tensor = torch.from_numpy(img).permute(2, 0, 1).unsqueeze(0).to(self.device)
# 推理
with torch.no_grad():
cls_outs, reg_outs, _ = self.model(img_tensor)
cls_flat = torch.cat([o.view(1, -1, len(self.class_names)) for o in cls_outs], dim=1)
reg_flat = torch.cat([o.view(1, -1, 4) for o in reg_outs], dim=1)
# 解码
scores = torch.sigmoid(cls_flat[0])
max_scores, pred_cls = scores.max(dim=1)
conf_threshold = self.conf_slider.value() / 100
mask = max_scores > conf_threshold
boxes = decode_boxes(self.anchors.to(self.device), reg_flat[0])
boxes = boxes[mask].clamp(0, img_size)
scores_filtered = max_scores[mask]
pred_cls_filtered = pred_cls[mask]
# NMS
from torchvision.ops import nms
iou_threshold = 0.45
keep = nms(boxes, scores_filtered, iou_threshold)
boxes = boxes[keep]
scores_filtered = scores_filtered[keep]
pred_cls_filtered = pred_cls_filtered[keep]
# 缩放回原图尺寸并绘制结果
scale_x = w / img_size
scale_y = h / img_size
annotated_image = image.copy()
for box, score, cls_id in zip(boxes, scores_filtered, pred_cls_filtered):
x1, y1, x2, y2 = box.cpu().numpy()
x1, x2 = int(x1 * scale_x), int(x2 * scale_x)
y1, y2 = int(y1 * scale_y), int(y2 * scale_y)
cls_name = self.class_names[int(cls_id)]
color = CLASS_COLORS.get(cls_name, (0, 255, 0))
# 绘制边框和标签
cv2.rectangle(annotated_image, (x1, y1), (x2, y2), color, 2)
label = f"{cls_name} {score:.2f}"
cv2.putText(annotated_image, label, (x1, y1-5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 2)
return result, annotated_image
8.3 视频实时检测线程
class VideoThread(QThread):
"""视频/摄像头检测线程"""
change_pixmap_signal = pyqtSignal(np.ndarray)
detection_result_signal = pyqtSignal(dict)
def run(self):
self.running = True
cap = cv2.VideoCapture(self.source)
while self.running:
ret, frame = cap.read()
if not ret:
break
# 显示原始帧
self.original_pixmap_signal.emit(frame.copy())
# 执行检测
if self.model:
annotated_frame, detection_info = self.detect_frame(frame)
self.detection_result_signal.emit(detection_info)
self.change_pixmap_signal.emit(annotated_frame)
# 高置信度检测结果自动保存
if detection_info['count'] > 0 and detection_info['max_conf'] > 0.8:
self.save_image_signal.emit(frame.copy(), annotated_frame.copy(), detection_info)
cap.release()
8.4 批量检测功能
def batch_detect(self):
"""批量检测文件夹中的所有图片"""
folder_path = QFileDialog.getExistingDirectory(self, "选择图片文件夹")
if not folder_path:
return
# 获取所有图片文件
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp']
image_files = []
for ext in image_extensions:
image_files.extend(Path(folder_path).glob(f"*{ext}"))
if not image_files:
self.log("文件夹中没有找到图片文件!", "warning")
return
# 显示进度条
self.progress_bar.setVisible(True)
self.progress_bar.setMaximum(len(image_files))
# 逐个检测
self.batch_results = []
for idx, image_path in enumerate(image_files):
image = cv2.imread(str(image_path))
result, annotated_image = self.detect_with_efficientdet(image)
self.batch_results.append({
'path': str(image_path),
'original': image,
'annotated': annotated_image,
'result': result
})
self.progress_bar.setValue(idx + 1)
self.progress_bar.setVisible(False)
self.log(f"批量检测完成!共处理 {len(image_files)} 张图片", "success")
九、项目总结
项目基于EfficientDet-D1的芒果成熟度与病害智能识别系统,通过增加检测头深度和引入Dropout正则化两项改进策略,使模型在保持高效推理速度的同时实现了更高的检测精度。实验结果表明,改进后的模型在验证集上达到了98.05%的准确率,相比基线模型的95.12%提升了2.93个百分点,验证损失降低了13.0%。各类别的平均精度均值从0.916提升到0.942,提升了2.6个百分点。消融实验充分验证了每项改进的有效性,其中增加检测头深度对性能提升贡献最大,Dropout正则化则有效降低了过拟合风险。
十、演示视频
芒果病害和成熟度检测

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)