从零实现Transformer:第 3 部分 - 掩码多头注意力(Masked Multi-Head Attention)可视化直观展示掩码的作用
从零实现Transformer:第 3 部分 - 掩码多头注意力(Masked Multi-Head Attention)可视化直观展示掩码的作用
flyfish
使用的缩写
| 缩写 | 完整英文 | 中文 |
|---|---|---|
| tgt | Target | 目标 |
| pad | Padding | 填充 |
| seq | Sequence | 序列 |
| len | Length | 长度 |
| attn | Attention | 注意力 |
| dim | Dimension | 维度 |
| dtype | Data Type | 数据类型 |
| triu | Triangle Upper | 上三角 |
| inf | Infinity | 无穷 |
| nan | Not A Number | 非数值 |
| MHA | Multi-Head Attention | 多头注意力 |
| q/k/v | Query / Key / Value | 查询/键/值 |
实现使用的方法
从零实现 Transformer:第 0 部分 - 基础( Foundations)squeeze / unsqueeze 修改张量的维度结构(shape)
从零实现 Transformer:第 0 部分 - 基础( Foundations)view 重塑形状 和 transpose 交换维度顺序
在 Transformer 解码器/文本生成 任务中:目标序列 = 模型需要学习生成的标准答案序列
tgt_ids = torch.tensor([[1, 2, 3, 0]])
就是模型的目标输出序列。
tgt_ids
tgt = Target 目标
ids = Token IDs / Identifiers
Target Token IDs 解码器目标序列的 Token ID 列表
在英文翻译为中文的任务中,tgt_ids 是目标语言(中文)的词汇表索引数字序列(不是原始中文文本,是文本数字化后的张量),是 Transformer 解码器的输入标签。
在英文翻译为中文的任务中,tgt_ids 是目标语言(中文)的词汇表索引数字序列(不是原始中文文本,是文本数字化后的张量),是Transformer解码器的输入标签。
英译中:英文 = 源语言 (src),中文 = 目标语言 (tgt)src_ids:英文句子 → 数字化后的英文词表索引tgt_ids:中文句子 → 数字化后的中文词表索引
1. 形状含义
[ [1,2,3,0] ]
外层 [] → batch_size=1(一次只处理1条句子)
内层 [1,2,3,0] → 序列长度 seq_len=4(1条句子有4个token)
2. 数字是什么?
这些数字不是普通数字,是词表索引 (Token ID)
把「单词/字符」映射成数字,比如:
1 → the
2 → cake
3 → is
0 → 【填充符 PAD】
所以这个序列对应的真实文本是:the cake is [填充]
3. 最后一位 0 是什么?
0 = pad_id(填充符号)
- 真实有效单词只有:
the cake is(3个) - 为了让序列长度统一成
4,强行补了一个无意义的 0 - 这个 0 没有任何语义,模型必须忽略它(这就是
padding mask的作用)
Masked MHA(掩码多头注意力),这个目标序列的用途:
- 模型生成这个序列时,只能看前面的词(look-ahead mask)
- 模型必须忽略最后一个 0(padding mask)
- 最终掩码会屏蔽:未来的词 + 填充符 0
规则
- 不是每个序列最后一个都必须是 0(padding)
- 0 是填充符,只给「短序列」补在末尾,长序列末尾没有 0
- 所有填充符 100% 都在序列的最后面,绝对不会出现在中间/开头
设定:最大序列长度 = 4,pad_id=0
批量输入 3条不同长度的目标序列:
| 原始真实序列(有效token) | 长度 | 补0后最终序列 | 末尾是否有0? |
|---|---|---|---|
| [1,2] | 2 | [1,2,0,0] | 有(补了2个) |
| [1,2,3] | 3 | [1,2,3,0] | 有(补了1个) |
| [1,2,3,4] | 4 | [1,2,3,4] | 无0 |
问题:每个序列的最后一个都是 padding 0 吗?
不是!
只有长度 < 最大长度的短序列,末尾才会补0;
长度刚好等于最大长度的序列,末尾是正常token,没有0。
绝对不会把0插在序列中间(比如 [1,0,2,3]);
绝对不会把0放在开头(比如 [0,1,2,3]);
有效token在前,填充0在后。
tgt_ids = torch.tensor([[1, 2, 3, 0]])
这条序列有效长度3,最大长度4 → 补1个0在最后;
如果是完整长度4的序列:torch.tensor([[1,2,3,4]]) → 末尾无0。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
# --------------------- 1. 目标掩码生成函数---------------------
def create_tgt_mask(tgt_ids, pad_id):
"""创建目标序列掩码(padding mask + look-ahead mask)"""
# 2维布尔掩码 [batch, seq_len]
padding_mask_2d = (tgt_ids == pad_id)
# 升维为 [batch, 1, 1, seq_len] (标准Transformer掩码维度)
tgt_padding_mask = padding_mask_2d.unsqueeze(1).unsqueeze(1)
# look-ahead mask 防止看到未来token [1, 1, seq_len, seq_len]
tgt_seq_len = tgt_ids.shape[1]
look_ahead_mask = torch.triu(torch.ones(tgt_seq_len, tgt_seq_len, device=tgt_ids.device), diagonal=1).bool()
look_ahead_mask = look_ahead_mask.unsqueeze(0).unsqueeze(0)
# 合并掩码:任意一个为True则屏蔽
return tgt_padding_mask | look_ahead_mask
# --------------------- 2. 带掩码的缩放点积注意力(MHA基础)---------------------
def scaled_dot_product_attention(q, k, v, mask=None):
"""
Masked Scaled Dot-Product Attention(Transformer公式)
q/k/v shape: [batch, n_heads, seq_len, d_k]
mask shape: [batch, 1, seq_len, seq_len]
"""
d_k = q.size(-1)
# 1. 计算Q*K^T
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
# 2. 应用掩码:mask=True的位置赋值为-∞,softmax后变为0
if mask is not None:
attn_scores = attn_scores.masked_fill(mask, -1e9)
# 3. Softmax归一化得到注意力权重
attn_weights = torch.softmax(attn_scores, dim=-1)
# 4. 乘以V得到输出
output = torch.matmul(attn_weights, v)
return output, attn_scores, attn_weights
# --------------------- 3. 可视化函数(绘制掩码/注意力分数矩阵)---------------------
def visualize_matrix(matrix, title, is_mask=False):
"""热力图可视化矩阵"""
plt.figure(figsize=(6, 5))
# 掩码用布尔值,注意力用浮点值
data = matrix.cpu().numpy() if not is_mask else matrix.cpu().numpy().astype(int)
# 绘制热力图
im = plt.imshow(data, cmap='Blues' if is_mask else 'viridis')
plt.title(title, fontsize=14)
plt.xlabel('Key Sequence', fontsize=12)
plt.ylabel('Query Sequence', fontsize=12)
# 标注矩阵数值
for i in range(data.shape[0]):
for j in range(data.shape[1]):
text = plt.text(j, i, f'{data[i, j]:.2f}' if not is_mask else int(data[i, j]),
ha="center", va="center", color="white" if data[i, j] > 0.5 else "black")
plt.colorbar(im)
plt.tight_layout()
plt.show()
# --------------------- 4. 测试:batch_size=1,直观演示 ---------------------
if __name__ == "__main__":
# 超参数配置
batch_size = 1 # 单批次,方便可视化
seq_len = 4 # 目标序列长度
d_k = 8 # 注意力头维度
pad_id = 0 # 填充符ID
# 模拟目标序列:[1,2,3,0] → 最后一位是padding
tgt_ids = torch.tensor([[1, 2, 3, 0]])
print("目标序列 shape:", tgt_ids.shape, "值:", tgt_ids)
# 1. 生成最终掩码
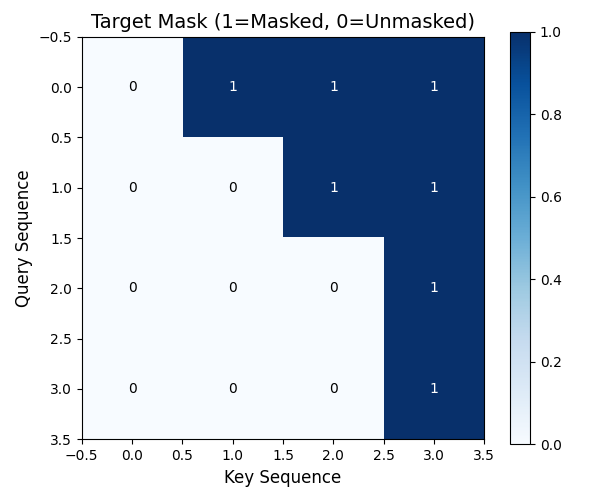
final_mask = create_tgt_mask(tgt_ids, pad_id)
# 压缩维度:[1,1,4,4] → [4,4] 方便可视化
mask_vis = final_mask.squeeze(0).squeeze(0)
print("最终掩码 shape:", final_mask.shape, "可视化shape:", mask_vis.shape)
visualize_matrix(mask_vis, "Target Mask (1=Masked, 0=Unmasked)", is_mask=True)
# 2. 模拟随机生成 Q, K, V (单头注意力,n_heads=1)
q = torch.randn(batch_size, 1, seq_len, d_k)
k = torch.randn(batch_size, 1, seq_len, d_k)
v = torch.randn(batch_size, 1, seq_len, d_k)
# 3. 执行 Masked 注意力计算
output, attn_scores, attn_weights = scaled_dot_product_attention(q, k, v, final_mask)
# 4. 可视化:原始注意力分数 + 掩码后注意力权重
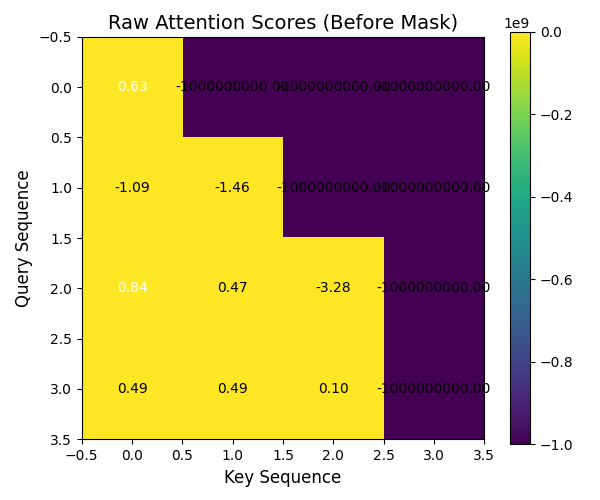
attn_scores_vis = attn_scores.squeeze(0).squeeze(0)
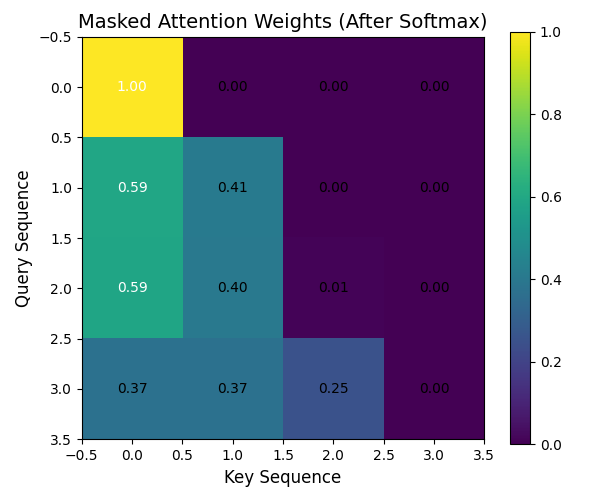
attn_weights_vis = attn_weights.squeeze(0).squeeze(0)
print("原始注意力分数 shape:", attn_scores_vis.shape)
visualize_matrix(attn_scores_vis, "Raw Attention Scores (Before Mask)")
print("掩码后注意力权重 shape:", attn_weights_vis.shape)
visualize_matrix(attn_weights_vis, "Masked Attention Weights (After Softmax)")
参考
从零实现Transformer:第 3 部分 - 掩码多头注意力的掩码广播(Broadcasting of Masks in Masked Multi-Head Attention)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 33
33 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)