从零实现Transformer:第 3 部分 - 掩码多头注意力的掩码广播(Broadcasting of Masks in Masked Multi-Head Attention)
从零实现Transformer:第 3 部分 - 掩码多头注意力的掩码广播(Broadcasting of Masks in Masked Multi-Head Attention)
flyfish
以生成填充掩码 + 前瞻掩码的组合掩码 为例
1. 生成 Padding Mask(填充掩码)
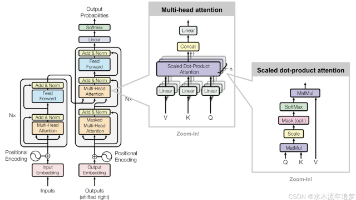
屏蔽序列中的填充占位符(pad_id=0) 填充的 0 是无效字符,模型不应该关注、学习这些无意义的占位符
2. 生成 Look-ahead Mask(前瞻掩码)
屏蔽当前位置之后的所有未来 token,解码器是自回归生成(一步步生成文本),绝对不能提前看到未来的词
3. 合并掩码
用 | 运算把两个掩码合二为一:
只要是「填充位」或「未来位」,统一屏蔽(True)
用处
输出形状:[batch, 1, seq_len, seq_len]
这个掩码直接传入解码器的多头自注意力层:
掩码为 True → 注意力分数置为负无穷,模型完全忽略该位置
掩码为 False → 正常计算注意力,模型可以关注该位置
import torch
def create_tgt_mask(tgt_ids, pad_id):
"""创建目标序列掩码(padding mask + look-ahead mask)"""
# 1. 2维padding掩码 [batch, seq_len]
padding_mask_2d = (tgt_ids == pad_id)
# 2. 升维适配注意力维度 -> [batch, 1, 1, seq_len]
tgt_padding_mask = padding_mask_2d.unsqueeze(1).unsqueeze(1)
# 3. 生成序列长度
tgt_seq_len = tgt_ids.shape[1]
# 4. 构造上三角前瞻掩码 [seq_len, seq_len]
# diagonal=1:主对角线上方为1,遮挡未来位置
look_ahead_mask = torch.triu(
torch.ones(tgt_seq_len, tgt_seq_len, device=tgt_ids.device),
diagonal=1
).bool()
# 5. 升维支持批量广播 -> [1, 1, seq_len, seq_len]
look_ahead_mask = look_ahead_mask.unsqueeze(0).unsqueeze(0)
# 6. 合并掩码:任意一个为True就遮挡
return tgt_padding_mask | look_ahead_mask
# 测试
if __name__ == "__main__":
pad_id = 0
# 2个batch,序列长度5,0为padding
tgt_ids = torch.tensor([
[1, 2, 3, 0, 0],
[4, 5, 0, 0, 0]
])
mask = create_tgt_mask(tgt_ids, pad_id)
print("最终掩码形状:", mask.shape) # torch.Size([2, 1, 5, 5])
print("掩码内容:\n", mask)
输出
最终掩码形状: torch.Size([2, 1, 5, 5])
掩码内容:
tensor([[[[False, True, True, True, True],
[False, False, True, True, True],
[False, False, False, True, True],
[False, False, False, True, True],
[False, False, False, True, True]]],
[[[False, True, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True]]]])
广播 = PyTorch 自动把 形状不同但兼容 的张量,复制拉伸成相同形状,然后再运算
两个张量形状
return tgt_padding_mask | look_ahead_mask
两个输入形状:
tgt_padding_mask:[B, 1, 1, S]→ 举例[2, 1, 1, 4]look_ahead_mask:[1, 1, S, S]→ 举例[1, 1, 4, 4]
广播目标:把两个张量都自动变成 [2, 1, 4, 4],再做 | 运算
广播规则
- 维度为
1的位置,可以自动复制扩展成任意大小 - 扩展后,两个张量形状完全一致,就能运算
例子1:最简单的2维广播
模拟:小张量自动拉伸
import torch
# 形状 [1,4] → 1行4列
a = torch.tensor([[True, False, True, False]])
# 形状 [4,4] → 4行4列
b = torch.ones(4,4).bool()
# 广播运算:a自动复制4行,变成[4,4],再和b运算
c = a | b
print("a形状:", a.shape)
print("b形状:", b.shape)
print("广播后运算结果形状:", c.shape) # 输出 [4,4]
[1,4] 自动扩成 [4,4]
例子2:3维广播(过渡)
# [2,1,4]
a = torch.rand(2,1,4).bool()
# [1,4,4]
b = torch.rand(1,4,4).bool()
# 自动广播成 [2,4,4]
c = a | b
print(c.shape) # [2,4,4]
例子3:模拟代码的4维广播
import torch
# 模拟两个掩码
B, S = 2, 4
# 1. padding掩码 [2,1,1,4]
tgt_pad_mask = torch.rand(B, 1, 1, S).bool()
# 2. 前瞻掩码 [1,1,4,4]
look_ahead_mask = torch.rand(1, 1, S, S).bool()
# 广播运算!
final_mask = tgt_pad_mask | look_ahead_mask
# 打印形状
print("padding掩码形状:", tgt_pad_mask.shape) # [2,1,1,4]
print("前瞻掩码形状:", look_ahead_mask.shape) # [1,1,4,4]
print("广播后最终形状:", final_mask.shape) # [2,1,4,4]
代码里用到的
输入参数
# 2个句子,每个句子最长5个词
tgt_ids = torch.tensor([
[1, 2, 3, 0, 0], # 第1个样本:有效词3个,后2个是填充0
[4, 5, 0, 0, 0] # 第2个样本:有效词2个,后3个是填充0
])
pad_id = 0 # 0代表填充位
批次大小 B = 2
序列长度 S = 5
标准掩码维度:[batch, num_heads, seq_q, seq_k]
最终维度是 [2, 1, 5, 5]
[2, 1, 5, 5]
= [批次B, 头数H, 查询序列长Q, 键序列长K]
- 2:一次性处理 2 个句子(batch=2)
- 1:代码里没做多头,默认 1 个注意力头
- 5:Query 向量数量 = 目标序列长度 = 5
- 5:Key 向量数量 = 目标序列长度 = 5
代码里的广播
tgt_padding_mask形状:[2, 1, 1, 5]look_ahead_mask形状:[1, 1, 5, 5]- PyTorch 自动广播 把两个张量都拉伸为
[2, 1, 5, 5],再做|运算
掩码内容
最终掩码 = 前瞻掩码 或 填充掩码True = 遮挡(不让看)False = 允许看
1. 前瞻掩码(固定不变,所有样本共用)
torch.triu(..., diagonal=1) 生成固定上三角矩阵:
# 5x5 前瞻掩码(对角线以上全是True,遮挡未来词)
[
[F, T, T, T, T], # 第1个词:只能看自己,不能看后面4个
[F, F, T, T, T], # 第2个词:能看自己+前1个,不能看后面3个
[F, F, F, T, T], # 第3个词:能看自己+前2个,不能看后面2个
[F, F, F, F, T], # 第4个词:能看自己+前3个,不能看后面1个
[F, F, F, F, F] # 第5个词:能看所有前面的词
]
2. 填充掩码(每个样本不一样)
样本1 [1,2,3,0,0]:第4、5位是填充 → 掩码 [F,F,F,T,T]
样本2 [4,5,0,0,0]:第3、4、5位是填充 → 掩码 [F,F,T,T,T]
最终合并结果
样本1 输出(第一块 5x5)
[[False, True, True, True, True],
[False, False, True, True, True],
[False, False, False, True, True],
[False, False, False, True, True], # 第4位是填充,永久遮挡
[False, False, False, True, True]] # 第5位是填充,永久遮挡
前3行:只受前瞻掩码影响
后2行:前瞻掩码 + 填充掩码 双重遮挡
样本2 输出(第二块 5x5)
[[False, True, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True], # 第3位是填充,永久遮挡
[False, False, True, True, True], # 第4位是填充,永久遮挡
[False, False, True, True, True]] # 第5位是填充,永久遮挡
前2行:只受前瞻掩码影响
后3行:前瞻掩码 + 填充掩码 双重遮挡
简单的流程就是
- 维度
[2,1,5,5][2个句子, 1个注意力头, 每个句子5个Query, 每个句子5个Key] - 掩码内容
上三角的True= 遮挡未来词(前瞻掩码)
后半列的True= 遮挡填充0(填充掩码) - 两者合并,就是看到的输出
不用广播的写法
import torch
def create_tgt_mask_no_broadcast(tgt_ids, pad_id):
"""创建目标序列掩码(无广播版,手动扩展维度)"""
B, S = tgt_ids.shape # 直接获取批次B=2,序列长S=5
# 1. 2维padding掩码 [batch, seq_len] → [2,5]
padding_mask_2d = (tgt_ids == pad_id)
# 2. 升维 → [B, 1, 1, S] → [2,1,1,5]
tgt_padding_mask = padding_mask_2d.unsqueeze(1).unsqueeze(1)
# ============== 替代广播 ==============
# 把第3维(seq_q)从 1 复制成 S → 形状变成 [B,1,S,S] = [2,1,5,5]
tgt_padding_mask = tgt_padding_mask.repeat(1, 1, S, 1)
# 3. 构造上三角前瞻掩码 [S, S] → [5,5]
look_ahead_mask = torch.triu(
torch.ones(S, S, device=tgt_ids.device),
diagonal=1
).bool()
# 4. 升维 → [1, 1, S, S] → [1,1,5,5]
look_ahead_mask = look_ahead_mask.unsqueeze(0).unsqueeze(0)
# ============== 替代广播 ==============
# 把第0维(batch)从 1 复制成 B → 形状变成 [B,1,S,S] = [2,1,5,5]
look_ahead_mask = look_ahead_mask.repeat(B, 1, 1, 1)
# 6. 两个掩码形状完全一致,直接运算(无任何广播)
return tgt_padding_mask | look_ahead_mask
# 测试
if __name__ == "__main__":
pad_id = 0
tgt_ids = torch.tensor([
[1, 2, 3, 0, 0],
[4, 5, 0, 0, 0]
])
# 运行无广播版本
mask = create_tgt_mask_no_broadcast(tgt_ids, pad_id)
print("最终掩码形状:", mask.shape) # 依旧是 torch.Size([2, 1, 5, 5])
print("掩码内容:\n", mask)
输出
最终掩码形状: torch.Size([2, 1, 5, 5])
掩码内容:
tensor([[[[False, True, True, True, True],
[False, False, True, True, True],
[False, False, False, True, True],
[False, False, False, True, True],
[False, False, False, True, True]]],
[[[False, True, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True]]]])

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)