从零实现Transformer:第 3 部分 - 多头注意力分数维度布局
从零实现Transformer:第 3 部分 - 多头注意力分数维度布局(Dimension Layout of Attention Scores in Multi-Head Attention)
flyfish
[B, H, Q, K]
名称
按顺序:
- B = Batch Size
批次维度 / 批量维度 - H = Head Num / Num Heads
多头维度 / 注意力头数维度 - Q = Query Sequence Length
查询序列长度 - K = Key Sequence Length
键序列长度
Q:Query 向量总个数 = 查询侧的序列长度
K:Key 向量总个数 = 键侧的序列长度
再来一遍
BBB:batch_size,一批有多少条样本
HHH:num_heads,多头注意力有多少个独立注意力头
QQQ:Query 向量的总数量(Query 序列长度)
KKK:Key 向量的总数量(Key 序列长度)
注意力分数,是每一个 Query向量和每一个 Key向量两两算匹配相似度
两两组合,天然形成一张:QQQ 行 × KKK 列 的分数表
矩阵乘法 Q=KTQ ={K}^{T}Q=KT
设单头简化看(先不管H、B):
R\boldsymbol{\mathbb{R}}R = 全体实数包含:整数、小数、正数、负数、浮点数(神经网络里所有数值都属于实数)
- 每个输入序列,映射得到:
Q∈RQ×dQ \in \mathbb R^{Q \times d}Q∈RQ×d :有 QQQ 个Query向量,每个向量维度 ddd
K∈RK×dK \in \mathbb R^{K \times d}K∈RK×d :有 KKK 个Key向量,每个向量维度 ddd
格式:
R行数×列数\mathbb{R}^{\boldsymbol{行数} \times \boldsymbol{列数}}R行数×列数
含义:所有 m行、d列 的实数矩阵 构成的空间
-
Key 最后两维转置
KT∈Rd×KK^{T} \in \mathbb R^{d \times K}KT∈Rd×K -
矩阵相乘:
score=Q ⋅ KT{score} = Q \;\cdot\; K^{T}score=Q⋅KT
RQ×d × Rd×K ⟹ RQ×K\mathbb R^{Q \times d} \;\times\; \mathbb R^{d \times K} \implies {\mathbb R^{Q \times K}}RQ×d×Rd×K⟹RQ×K
这就是为什么最后一定是 [Q,K][Q, K][Q,K] 二维矩阵,是线性代数矩阵乘法硬性决定的行列数。
结果行数 = Query向量个数 QQQ
结果列数 = Key向量个数 KKK
套上 batch 和多头,就变成完整四维:
[B,H,Q,d]@[B,H,d,K] ⟹ [B,H,Q,K][B, H, Q, d] \mathbin{@} [B, H, d, K] \implies \boldsymbol{[B, H, Q, K]}[B,H,Q,d]@[B,H,d,K]⟹[B,H,Q,K]
import torch
# 假设:单条样本、单头
Q_len = 4 # 一共有 4 个 Query向量
K_len = 4 # 一共有 4 个 Key向量
dim = 8 # 每个向量的特征维度
# 构造 Q、K
Q = torch.randn(1, 1, Q_len, dim) # [B=1, H=1, Q=4, d=8]
K = torch.randn(1, 1, K_len, dim) # [B=1, H=1, K=4, d=8]
# K 最后两维转置
K_T = K.transpose(-2, -1) # [1, 1, 8, 4]
# 两两相似度打分
score = Q @ K_T # 矩阵相乘
print("Q shape:", Q.shape)
print("K_T shape:", K_T.shape)
print("相似度分数矩阵 shape [B,H,Q,K]:", score.shape)
输出
Q shape: torch.Size([1, 1, 4, 8])
K_T shape: torch.Size([1, 1, 8, 4])
相似度分数矩阵 shape [B,H,Q,K]: torch.Size([1, 1, 4, 4])
Decoder 自注意力:自己的序列既当 Query、也当 Key
Q=K=序列长度SQ=K=序列长度SQ=K=序列长度S所以分数矩阵就是 [B,H,S,S][B, H, S, S][B,H,S,S]
举例子
1 符号
设:
一个序列里一共有 nnn 个 token,这里的 nnn就是后面的Qnum、KnumQ_{num}、K_{num}Qnum、Knum都是指:向量的个数 = 序列长度
经过线性变换后,每个 token 对应 1 个向量
每个向量的特征维度 = ddd
2 Query 举例
Q∈Rn×d\boldsymbol Q \in \mathbb R^{\boldsymbol{n} \times d}Q∈Rn×d
含义:一共有 n\boldsymbol{n}n 个 Query 向量,每个向量长度是 ddd
这里的例子
序列长度(token个数) n=4\boldsymbol{n = 4}n=4
每个向量维度 d=3\boldsymbol{d = 3}d=3
那:
Q∈R4×3\boldsymbol Q \in \mathbb R^{\boldsymbol{4 \times 3}}Q∈R4×3
写成数字矩阵
Q=[q1q2q3q4]=[1.12.23.34.45.56.67.78.89.91.22.33.4]\boldsymbol Q =\begin{bmatrix} \boldsymbol q_1 \\ \boldsymbol q_2 \\ \boldsymbol q_3 \\ \boldsymbol q_4 \end{bmatrix} =\begin{bmatrix} 1.1 & 2.2 & 3.3 \\ 4.4 & 5.5 & 6.6 \\ 7.7 & 8.8 & 9.9 \\ 1.2 & 2.3 & 3.4 \end{bmatrix} Q=
q1q2q3q4
=
1.14.47.71.22.25.58.82.33.36.69.93.4
解释:
一共 4 行 → 对应 4 个 Query 向量(4个token各生成一个query)
一共 3 列 → 每一个 Query 向量本身是 3维
q1\boldsymbol q_1q1 是第1个token的query向量,q2\boldsymbol q_2q2 第2个……
3 Key 一模一样套格式
K∈Rn×d\boldsymbol K \in \mathbb R^{\boldsymbol{n} \times d}K∈Rn×d
含义:一共有 n\boldsymbol{n}n 个 Key 向量,每个向量长度是 ddd
同样例子:n=4, d=3n=4,\ d=3n=4, d=3
K∈R4×3\boldsymbol K \in \mathbb R^{4 \times 3}K∈R4×3
K=[k1k2k3k4]=[0.10.20.30.40.50.60.70.80.91.01.11.2]\boldsymbol K =\begin{bmatrix} \boldsymbol k_1 \\ \boldsymbol k_2 \\ \boldsymbol k_3 \\ \boldsymbol k_4\end{bmatrix} =\begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ 0.7 & 0.8 & 0.9 \\ 1.0 & 1.1 & 1.2 \end{bmatrix} K= k1k2k3k4 = 0.10.40.71.00.20.50.81.10.30.60.91.2
4行 = 4个Key向量
3列 = 每个Key向量是3维
4 最后一定是 [Qnum, Knum][Q_{num},\ K_{num}][Qnum, Knum] 矩阵
注意力公式:
Score=Q⋅KT\boldsymbol{Score} = \boldsymbol Q \cdot \boldsymbol K^\mathrm TScore=Q⋅KT
- Q: R4×3\boldsymbol Q:\ \mathbb R^{4 \times 3}Q: R4×3
- 对 K 转置:KT: R3×4\boldsymbol K^\mathrm T:\ \mathbb R^{\boldsymbol{3 \times 4}}KT: R3×4
矩阵乘法规则:
(4×3) × (3×4) ⟹ 4×4(4 \times 3)\ \times\ (3 \times 4) \implies \boldsymbol{4 \times 4}(4×3) × (3×4)⟹4×4
结果 4行 = 原来 Query 的数量(4个query)
结果 4列 = 原来 Key 的数量(4个key)
矩阵里每一个元素:某一个Query 和 某一个Key 的相似度打分
所以打分矩阵就是:
Score∈RQnum×Knum\boldsymbol{Score} \in \mathbb R^{\boldsymbol{Q_{num}} \times \boldsymbol{K_{num}}}Score∈RQnum×Knum
5 带Batch、多头
批量 + 多头后:
BBB:批次大小
HHH:注意力头数
Qnum=4, d=3Q_{num}=4,\ d=3Qnum=4, d=3
Q∈RB, H, 4, 3K∈RB, H, 4, 3 \begin{aligned} \boldsymbol Q &\in \mathbb R^{B,\ H,\ \boldsymbol{4},\ 3} \\ \boldsymbol K &\in \mathbb R^{B,\ H,\ \boldsymbol{4},\ 3} \end{aligned} QK∈RB, H, 4, 3∈RB, H, 4, 3
相乘:
Q @ K.transpose(−2,−1)⇒RB, H, 4, 4Q \; @ \; K.transpose(-2,-1) \quad\Rightarrow\quad \mathbb R^{B,\ H,\ \boldsymbol{4},\ \boldsymbol{4}} Q@K.transpose(−2,−1)⇒RB, H, 4, 4
序列有 4 个 token
Query 序列长度 = 4
自动就有 4 个 Query 向量
四维第三维就是 4
Key 同理:
Key 序列长度 = 4 → 4 个 Key 向量 → 四维第四维就是 4
相乘后:
[B,H,4,3]@[B,H,3,4]⇒[B,H,4,4][B,H,4,3] \mathbin{@} [B,H,3,4] \Rightarrow \boldsymbol{[B,H,4,4]}[B,H,4,3]@[B,H,3,4]⇒[B,H,4,4]
最后两维:[Query序列长, Key序列长] 或者说 [Query Sequence Length, Key Sequence Length]
import torch
# n=4个向量,每个向量d=3维
Q = torch.tensor([
[1.1, 2.2, 3.3],
[4.4, 5.5, 6.6],
[7.7, 8.8, 9.9],
[1.2, 2.3, 3.4]
])
K = torch.tensor([
[0.1, 0.2, 0.3],
[0.4, 0.5, 0.6],
[0.7, 0.8, 0.9],
[1.0, 1.1, 1.2]
])
print("Q shape:", Q.shape) # [4, 3]
print("K shape:", K.shape) # [4, 3]
score = Q @ K.t()
print("相似度分数矩阵 shape:", score.shape) # 输出 [4, 4]
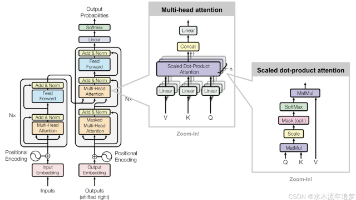
在Masked Multi-Head Attention 中 [B, H, Q, K] 也就是mask 的维度 [batch, num_heads, seq_q, seq_k]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)