LangChain - V1.0
文章目录
LangChain - V1.0
官方文档:https://docs.langchain.com/
大模型的种类 - 补充
| 大模型的种类 | 特点 | 常用大模型 |
|---|---|---|
| 通用语言模型 | 通用能力强,文本推理,文本生成,深度思考等 | DeepSeek, Qwen3, Kimi-K2, MiniMax-M2, GPT-4.5, Claude 3系列,等等 |
| 多模态模型 | 多模态支持(文本/图像/音频/视频),跨媒体理解能力强 | GPT-4o, Qwen3-VL, Qwen3-Omni, GLM-4.5V 等 |
| 文本嵌入模型 | 将文本转换成计算机能理解的数值向量,对文本进行降维处理 | BGE系列(small, base, large),OpenAI Embedding, Qwen3-Embedding 等 |
| 多模态嵌入模型 | 将文本、图像、音频、视频等不同模态的数据向量化到同一个向量空间中 | GME-Qwen3-VL, OpenAI-CLIP, Chinese-CLIP 等 |
| 多模态解析模型 | 负责解析复杂结构的数据 | DeepSeek-OCR, Dolphin, Dots.OCR, MonkeyOCR, Unstructured 等 |
| 垂直领域大模型 | 专注于某一个领域的复杂问题,如蛋白质结构预测 | DeepMind-AlphaFold, 360安全大模型,讯飞星火4.0(医疗)等 |
大模型平台推荐
| 名字 | 地址 | 特点 |
|---|---|---|
| 百炼平台 | https://bailian.console.aliyun.com/ | 国内的模型很全面 |
| 智普 AI | https://open.bigmodel.cn/ | 最新的 4.5 和 4.6,还有搜索工具 |
| Xiaqai 中转商 | https://xiaoai.plus/register?aff=3TIp | 国外的模型很丰富 |
| Kimi | https://platform.moonshot.cn/docs/overview | 月之暗面,有潜力,有搜索工具 |
LangChain 与 LangGraph 1.0 概述
起源与发展
LangChain 于 2022 年 10 月 左右由机器学习工程师 Harrison Chase 发起。最初是 Harrison 的一个副业,当时他大约写了 800 行代码,是一个体量不大的单文件 Python 包,于同年秋季发布到了个人的 GitHub 账户上。在 2024 年初,LangChain 发布了其更底层的方式编排——多智能体逻辑。
2025 年 10 月 20 日,LangChain 团队正式发布 LangChain 1.0 与 LangGraph 1.0 —— 这是这两大框架的首个主要版本,标志着 AI Agent 开发正式进入"工程化"阶段。
官方定义
Harrison 本人曾这样定义:
“LangChain 是一个构建 LLM 应用程序的框架,但这说法很模糊,也不够具体。我认为部分原因在于 LangChain 的功能实在太丰富了,所以很难用一句话具体说明。”
本质与核心价值
LangChain 本质上是一个用于构建大型模型驱动应用的开源框架,它通过标准化的接口将语言模型(LLM)与外部工具、数据存储、工作流逻辑等组件串联起来,让开发者无需从零搭建复杂的集成架构,就能快速构建具备 “思考、记忆、行动” 能力的智能体(Agent)。
不同于直接调用 LLM API 的简单开发模式,LangChain 的核心价值在于解决了大规模应用中的三大痛点:
-
"信息孤岛"问题
通过检索模块连接私有数据、互联网信息等外部资源,弥补大模型知识库的局限性。 -
"行动能力缺失"问题
通过工具调用机制让模型能够操作数据库、执行代码、发送邮件等实际任务。 -
"上下文断裂"问题
通过记忆模块保存对话历史和中间状态,支持复杂的多轮交互和长期任务。
LangChain 1.0 vs LangGraph 1.0:分工与定位
-
LangChain
构建 AI 智能体的最核心方式。提供标准的工具调用架构、供应商无关设计和可插拔的中间件系统,让开发者高效构建通用 Agent。 -
LangGraph
一个底层运行时框架,专为需要长期运行、可控且高定制化的生产级智能体设计。
LangChainV1.0的Agent是构建在LangGraph 之上,以提供持久的执行、流、人机交互、持久性等。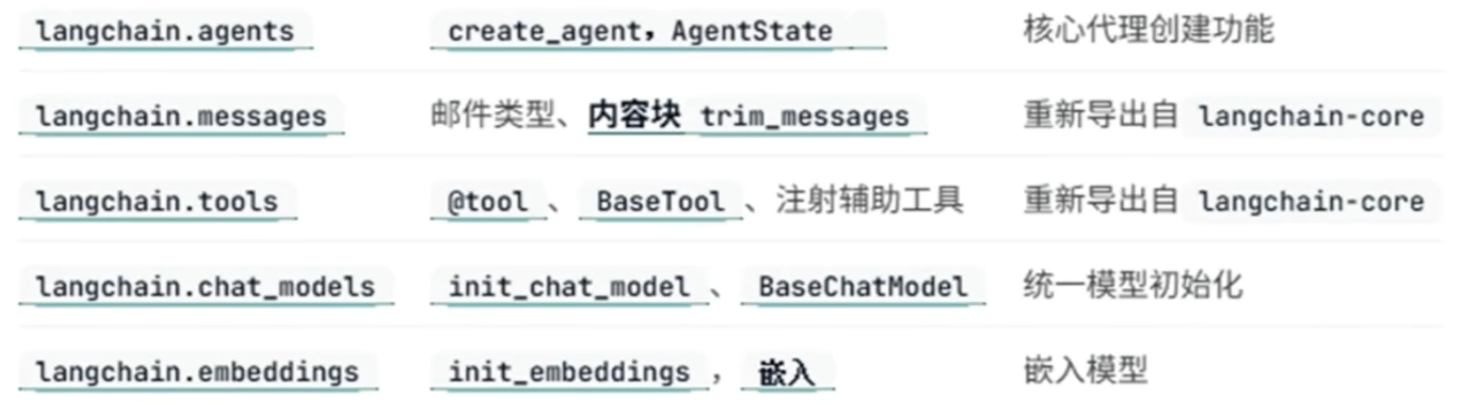
LangChain 1.0重大革新
LangChain 1.0 的更新并非简单的功能叠加,而是基于生产级应用需求的底层重构。其核心革新可以概括为“更统一、更可控、更生产就绪”三大特性,具体体现在以下几个方面:
一、核心入口:create_agent() 统一 Agent 构建流程
在 LangChain 1.0 之前,开发者构建 Agent 主要依赖 create_react_agent() 方法,该方法需要手动配置提示词模板、工具列表、执行器等多个组件,且不同类型的 Agent(如 React Agent、Self-Ask Agent)有着不同的构建接口,学习成本高且代码复用性差。
1.0 版本彻底重构了 Agent 层,推出了 create_agent() 作为构建智能体的标准入口,其核心优势在于:
-
底层封装 LangGraph 执行机制:
create_agent()默认基于 LangGraph 引擎实现,将“模型调用 → 工具决策 → 工具执行 → 结果整合”的闭环流程封装为高阶接口,开发者无需关注底层的图执行逻辑,只需传入核心组件即可快速构建 Agent。这种设计不仅简化了代码,还提升了流程的稳定性和可扩展性,支持复杂的分支逻辑和循环执行。 -
告别繁琐的提示词模板:旧版本需要从 LangChain Hub 导入大段的提示词模板,包含工具调用格式、对话历史注入等复杂配置,且模型容易出现格式输出错误。1.0 版本中,开发者只需传入简洁的
system_prompt(系统提示词),LangChain 会自动结合工具信息、对话上下文生成完整的提示词,大幅降低了提示词设计的难度。 -
兼容 Function Calling 标准:
create_agent()原生支持 OpenAI 定义的 Function Calling 标准,能够自动将工具信息转化为结构化的函数描述,传递给支持该标准的 LLM。在国内模型中,通过 API 对这一特性的适配性最佳,这也是很多开发者选择其作为 LangChain 默认模型的重要原因。
二、扩展了 middleware(中间件)
旧版本中,开发者若想自定义 Agent 的执行逻辑(如添加日志记录、敏感信息过滤、用户确认步骤等),需要修改核心代码或通过复杂的钩子函数(Hook)实现,不仅难度大,还容易破坏原有流程的稳定性。LangChain 1.0 引入的 middleware(中间件) 机制,彻底解决了这一问题。
中间件的作用
中间件本质上是一组可插拔的钩子函数,能够嵌入到 Agent 的执行流程中,对每个步骤进行自定义处理,且无需修改 Agent 的核心逻辑。其工作原理类似于 Web 开发中的中间件,通过“链式调用”的方式依次处理请求和响应,实现功能的灵活扩展。
中间件能做什么?
-
监控
通过日志记录、分析和调试跟踪代理行为 -
修改
转换提示、工具选择和输出格式 -
控制
添加重试、回退和提前终止逻辑 -
施行
应用速率限制、护栏和 PII 检测
内置的中间件
LangChain 1.0 提供了多个内置中间件,覆盖生产环境中的常见需求:
-
人机交互中间件:在工具执行前暂停流程,让用户批准、编辑或拒绝工具调用请求,适用于涉及敏感操作(如转账、发送邮件)的场景,提升应用的安全性。
-
脱敏中间件:自动识别并过滤对话中的电子邮件、电话号码、身份证号等敏感信息,确保符合数据隐私法规,避免用户信息泄露。
-
记忆优化中间件:自动裁剪过长的对话历史,防止令牌溢出错误,同时保持关键信息不丢失,提升长期运行会话的性能。
自定义中间件
开发者也可以自定义中间件,通过连接到 Agent 循环中的多个节点(如 before_model、wrap_tool_call、after_tool 等),实现个性化需求。例如,自定义一个日志中间件,记录每次工具调用的参数、结果和执行时间,用于后续的性能分析和问题排查。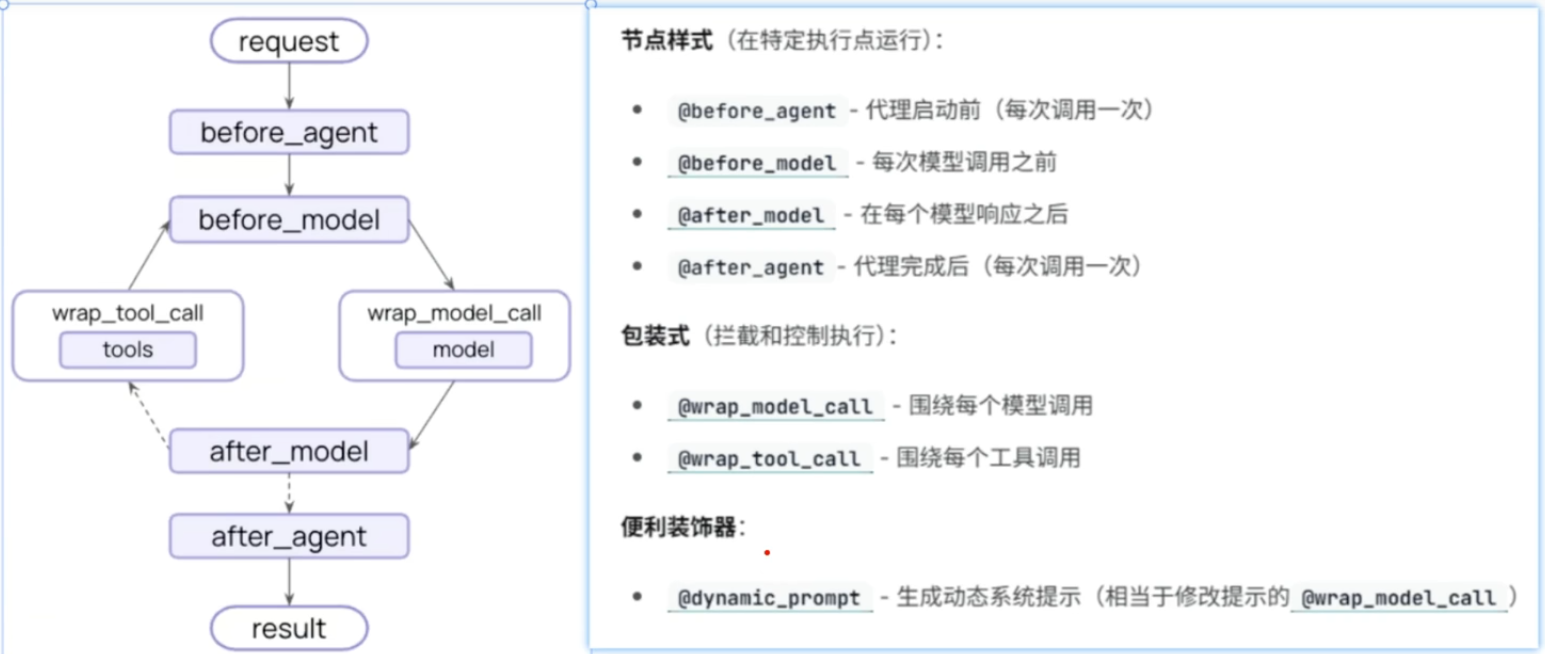
三、标准化和旧版本兼容
-
标准化内容块:所有 LLM 输出(文本、工具调用、引用、推理轨迹)统一为
.content_blocks结构,无论使用哪个厂商的模型,输出格式保持一致,彻底解决了跨模型开发中的格式兼容问题。 -
结构化输出集成:将 JSON Schema 等结构化输出能力直接集成到主循环中,无需额外的 LLM 调用,不仅降低了延迟和成本,还提升了结构化输出的准确性。
-
向后兼容与功能迁移:为了照顾旧版本用户,LangChain 将
create_react_agent()、LLMChain、ConversationBufferMemory等旧功能迁移至langchain-classic包中,开发者可以逐步迁移代码,避免一次性重制风险。
LangChainV1.0中Agent开发的核心组件
1. Agent(智能体)的定义
| 特性 | AIGC(如 ChatGPT) | AI Agent(如 Manus、Operator) |
|---|---|---|
| 核心能力 | 内容生成 | 任务规划与自主执行 |
| 交互模式 | 被动响应,依赖提示词 | 主动规划,自主决策 |
| 输出结果 | 建议、方案、内容(需人工后续处理) | 可交付的最终成果(如已发送的邮件、整理好的报表) |
| 与外界交互 | 有限,主要通过文本 | 强大,可通过工具调用操作现实世界系统 |
LangChain Agent 的架构与核心能力
LangChain 本质上是一个具备动态决策能力的智能执行框架,它通过大型语言模型(LLM)作为“大脑”,协调和调度各种工具来完成复杂任务。与传统的预定义流程软件不同,Agent 能够根据实际情况自主做出决策,将单一的工具调用转化为灵活的问题解决能力。
LLM Agent 在循环中运行工具以实现目标。Agent 运行直到满足停止条件 —— 即当模型发出最终输出或达到迭代限制时停止迭代。LangChain 中 Agent 的架构由多个精密协作的组件构成,形成了一个完整的决策-执行-反馈循环系统。
Agent 的核心价值
Agent 的核心价值在于其三重核心能力:动态任务路由、生态化工具集成和全周期记忆管理。
-
动态任务路由:使 Agent 能够根据输入内容自动规划执行路径,灵活切换工具调用逻辑。
-
生态化工具集成:让 Agent 可以访问 300+ 预置工具接口,覆盖搜索引擎、数据计算、数据库交互等众多领域。
-
全周期记忆管理:使 Agent 能同时维护短期对话上下文与长期知识存储,支持复杂任务的跨轮次协作。
这种架构使得 Agent 不像传统程序那样按预定流程执行,而是更像一位智能项目经理,能够:
- 接收任务需求后拆解目标(Planner 角色)
- 根据任务类型匹配最优工具(Router 角色)
- 调度工具按步骤执行(Executor 角色)
- 整合结果生成交付物
核心组件详解
模型 (Model)
Model 是 Agent 的“大脑”,负责推理和决策过程。在 LangChain 1.0 中,Model 被抽象为统一的接口,可以与多种后端 LLM 提供商协同工作,包括 OpenAI、Anthropic、Google 等。Model 的核心职责是分析当前状态和用户请求,决定是否需要调用工具以及调用哪些工具,并解析工具返回结果以形成最终响应。Model 的推理过程通常基于思维链 (Chain-of-Thought) 模式,将复杂问题分解为多个思考步骤。
工具 (Tools)
Tools 是 Agent 与外部世界交互的能力扩展接口,每个工具封装了一个特定功能,如搜索引擎查询、数据库操作、代码执行等。在 LangChain 中,工具既有大量预置选项(如搜索引擎集成、数学计算、文档检索等),也支持开发者自定义扩展。一个良好设计的工具应遵循功能单一性、输入验证和异常处理原则。从架构角度看,工具将 Agent 的认知能力与具体执行能力分离,使得 Agent 可以专注于决策而非实现细节。
记忆 (Memory)
Memory 为 Agent 提供上下文感知能力,使其能够记住之前的交互历史并基于上下文做出决策。LangChain 中的记忆系统分为:
- 短期记忆:维护当前对话的上下文
- 长期记忆:支持跨对话会话的知识持久化
在 LangChain 1.0 中,记忆系统与 LangGraph 的状态管理深度融合,支持更复杂和结构化的状态存储。
AgentExecutor
在 LangChain 1.0 的架构中,AgentExecutor 继续扮演执行协调器的关键角色,负责迭代运行代理直至满足停止条件。新版本中,AgentExecutor 基于 LangGraph 构建,获得了更强大的流程控制能力:
- 循环控制:通过
max_iterations参数防止无限循环 - 异常处理:可配置的解析错误处理
- 可观测性:通过
verbose参数输出详细执行日志
Agent 的工作流程与决策循环
具体流程如下:
-
输入解析:Agent 首先接收用户输入,解析其意图和关键参数。输入解析器负责标准化用户请求,提取可供工具使用的结构化参数。
-
LLM 推理:解析后的输入与当前状态(包括记忆和历史记录)一起传递给 LLM 进行推理。LLM 基于预设的提示词模板分析情况,决定下一步行动——直接回答还是调用工具。
-
工具调用:如果 LLM 决定调用工具,AgentExecutor 会执行相应的工具函数,并获取执行结果。工具调用可能涉及外部 API 访问、数据库查询或计算操作等。
-
观察与迭代:工具返回的结果作为“观察”被反馈给 Agent,这些信息与之前的状况一起形成新的上下文,传递给 LLM 进行下一轮推理。这个循环持续进行,直到 LLM 认为已获得足够信息来生成最终答案。
2.LLM模型组件
LangChain 支持所有主要模型提供商,包括 OpenAI、Anthropic、Google、Azure、AWS Bedrock等。每个提供商都提供具有不同功能的各种模型。
一、各种供应商的大模型调用
国内外的各种大模型都可以直接使用 ChatOpenAI 类来负责调用。
标准化参数
在构建 ChatModels 时,我们有一些标准化参数:
- model:模型名称
- temperature:采样温度
- timeout:请求超时
- max_tokens:生成的最大令牌数
- max_retries:请求重试的最大次数
- api_key:大模型供应商的 API 密钥
- base_url:发送请求的端点
二、流式输出
大多数模型都可以在生成输出内容时流式传输其输出。通过逐步显示输出,流式传输显著改善了用户体验,特别是对于较长的响应。
stream() 与 invoke() 相反,invoke() 在模型生成完整响应后返回单个 AIMessage,而 stream() 返回多个 AIMessageChunk 对象,每个对象包含输出文本的一部分。重要的是,流中的每个块都设计为通过求和收集到完整消息中。
三、速率限制
许多聊天模型提供商对给定时间段内可以进行的调用次数施加限制。如果达到速率限制,通常会收到来自提供商的速率限制错误响应,并且需要等待才能发出更多请求。
为了帮助管理速率限制,聊天模型集成接受可在初始化期间提供的参数,以控制发出请求的速率。通过 rate_limiter 参数来设置。
LangChain 内置 InMemoryRateLimiter。此限制器是线程安全的,可以由同一进程中的多个线程共享。
from langchain.core.rate_limiter import InMemoryRateLimiter
rate_limiter = InMemoryRateLimiter(
requests_per_second=0.1, # 1 request every 10s
check_every_n_seconds=0.1, # Check every 100ms whether allowed to make a request
max_bucket_size=10, # Controls the maximum burst size.
)
model = init_chat_model(
model="gpt-5",
model_provider="openai",
rate_limiter=rate_limiter
)
四、模型的输出格式化
大型语言模型能够生成任意文本。这使得模型能够适当地响应广泛的输入范围,但对于某些用例,限制大型语言模型的输出为特定格式或结构是有用的。这被称为结构化输出。
例如,如果输出要存储在关系数据库中,如果模型生成遵循定义的模式或格式的输出,将会容易得多。最常见的输出格式将是 JSON,尽管其他格式如 YAML 也可能很有用。
.with_structured_output()
为了方便,一些 LangChain 聊天模型支持 .with_structured_output() 方法。该方法只需要一个模式作为输入,并返回一个字典或 Pydantic 对象。通常,这个方法仅在支持下面描述的更高层次的模型上存在,并将在内部使用其中一种。它负责导入合适的输出解析器并将模式格式化为模型所需的正确格式。
from pydantic import BaseModel, Field
class Movie(BaseModel):
"""电影详情"""
title: str = Field(..., description="电影标题")
year: int = Field(..., description="电影发行年份")
director: str = Field(..., description="电影导演")
rating: float = Field(..., description="电影评分(满分10分)")
model_with_structure = llm.with_structured_output(Movie)
response = model_with_structure.invoke("提供电影《盗梦空间》的详细信息")
print(response)
SimpleJsonOutputParser
创建聊天提示模板,要求模型以特定格式回答问题
prompt = ChatPromptTemplate.from_template(
"尽你所能回答用户的问题。"
# 基本指令
'你必须给输出一个包含"title","year","director","rating"键的JSON对象。其中"title"代表:电影标题;"year"代表:电影发行年份;"director"代表:电影导演的名字;"rating"代表:"question"'
)
chain = prompt | llm | SimpleJsonOutputParser()
resp = chain.invoke({"question": "提供电影《盗梦空间》的详细信息?"})
print(resp)
3. 创建 Agent 项目和本地测试环境
LangChain 给我们提供了 Studio + LangSmith 集成的测试环境,使用 Studio 在本地可视化、交互和调试您的 Agent。
Studio 是一个专门的 Agent IDE,支持对实现智能体服务器 API 协议的代理系统进行可视化、交互和调试。Studio 还集成了跟踪、评估和提示工程。
一、安装 LangGraph CLI
# Python >= 3.11 is required.
pip install --upgrade "langgraph-cli[inmem]"
二、配置 LangSmith 的环境变量
在项目的根目录中创建一个文件并填写必要的 API 密钥。我们需要将环境变量设置为您从 LangSmith 获得的 API 密钥。(注:个人使用即可,企业一般不会使用)
https://eu.smith.langchain.com/o/6ac82ff5-69ab-4338-ae1d-e52e0637433c/settings/apikeys
三、创建LangGraph配置文件
在应用程序的目录中,创建一个配置文件:langgraph.json
{
"dependencies": ["."],
"graphs": {
"agent": "./src/agent.py:agent"
},
"env": ".env"
}
目录结构:
my-app/
├── src/
│ └── agent.py
├── .env
└── langgraph.json
四、编写你的智能体项目代码
from langchain.agents import create_agent
def send_email(to: str, subject: str, body: str):
"""发送邮件"""
email = {
"to": to,
"subject": subject,
"body": body
}
# ... 邮件发送逻辑
return f"邮件已发送至 {to}"
agent = create_agent(
"gpt-4o",
tools=[send_email],
system_prompt="你是一个邮件助手。请始终使用 send_email 工具。"
)
五、安装依赖项
在新 LangGraph 应用的根目录中,安装依赖项:
# 先拷贝pyproject.toml到项目目录下
pip install -e .
六、在 Studio 中运行您的agent
启动本地的 Agent 服务器:
langgraph dev
您的智能体程序将通过 Studio UI 访问:
http://127.0.0.1:2024
https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024
4. 工具的定义
工具是 Agent 调用以执行操作的组件。它们通过让模型通过定义明确的输入和输出与世界交互来扩展模型功能。
在构建 Agent 时,您需要为其提供一个它可以调用的工具列表。工具还包括几个组件:
| 属性 | 类型 | 描述 |
|---|---|---|
| 名称 | str | 在提供给 LLM 或代理的一组工具中必须是唯一的。 |
| 描述 | str | 描述工具的作用。被 LLM 或代理用作上下文。 |
| args_schema | pydantic.BaseModel | 可选但推荐,如果使用回调处理程序则为必需。它可用于为预期参数提供更多信息(例如,少量示例)或验证。 |
| return_direct | boolean | 仅与代理相关。当为 True 时,在调用给定工具后,代理将停止并将结果直接返回给用户。 |
注意: 如果工具具有精心选择的名称、描述和
args_schema,模型将表现得更好。
创建工具的方式
LangChain 支持以下几种方式创建工具:
- Tool 装饰器函数 —— 这是最常见的方式。
- 从 BaseTool 子类化 —— 这是最灵活的方法,它提供了最大的控制程度,但代价是需要付出更多的努力和编写更多的代码。
- 从 MCP 的服务端获得工具
一、@Tool装饰器定义工具
见文章末代码仓库
二、继承BaseTool定义工具
见文章末代码仓库
三、从MCP服务器端获得工具
见文章末代码仓库
5. 案例:基于Agent的Text-To-SQL Agent
见文章末代码仓库
Agent 工作流程
用户输入自然语言问题
↓
问题重写与关键词提取
↓
Schema回忆与表关系解析
↓
SQL查询生成 ←─────┐
↓ │
SQL语法验证 │
↓ │
否 ─────────────┘
是
↓
语义一致性校验
↓
否 ─────────────┘
是
↓
执行查询
↓
结果转换为自然语言
↓
返回最终回答
开发 Agent 的流程
- 准备好数据库和配置数据连接,安装各种依赖库:
sqlalchemy、psycopg2-binary、loguru。 - 开发一个数据库操作的类:负责和数据库打交道
- 开发四个工具
- 开发一个 Agent
- 运行智能体
- 结合FastAPI生成可视化测试界面
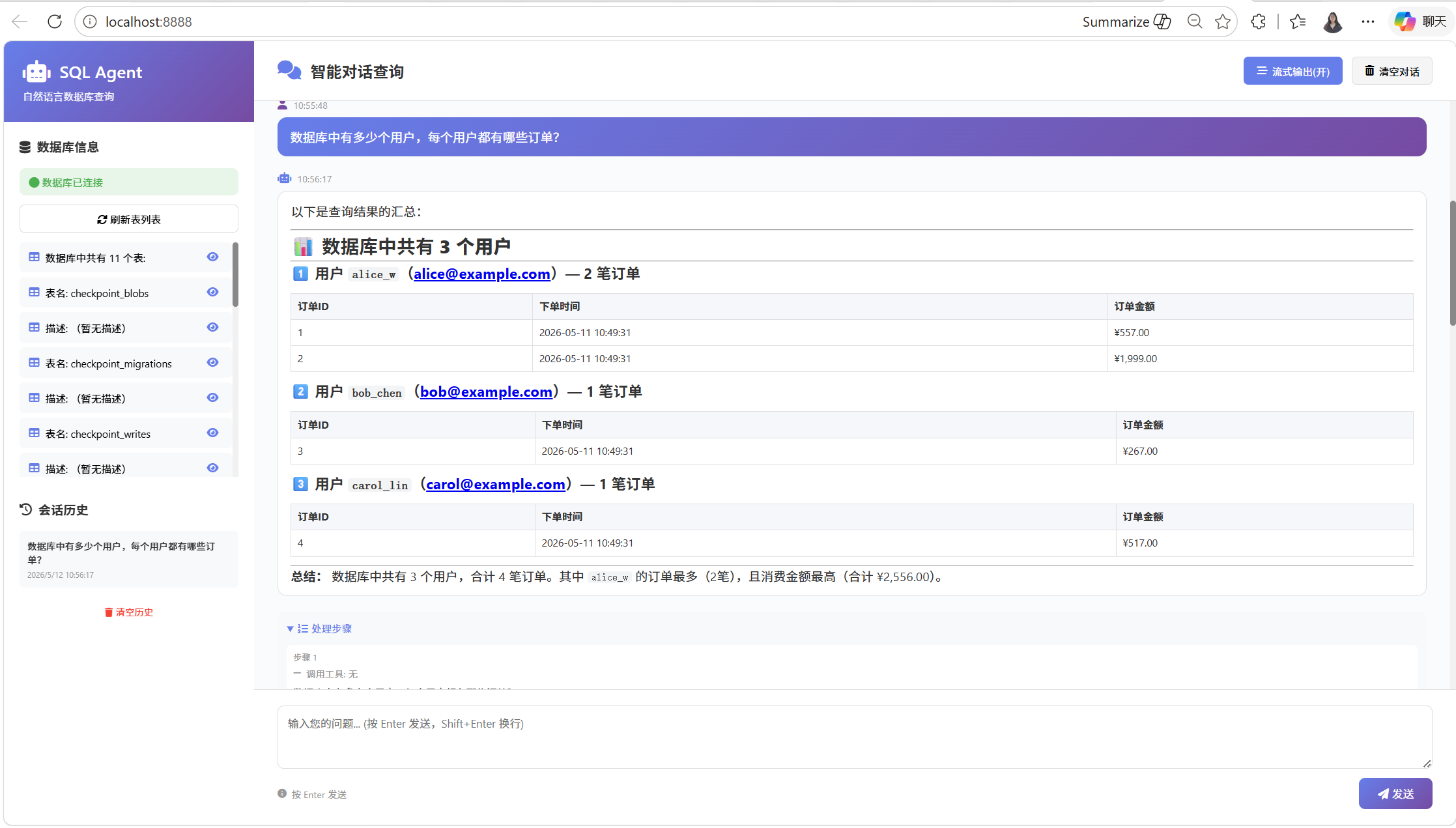
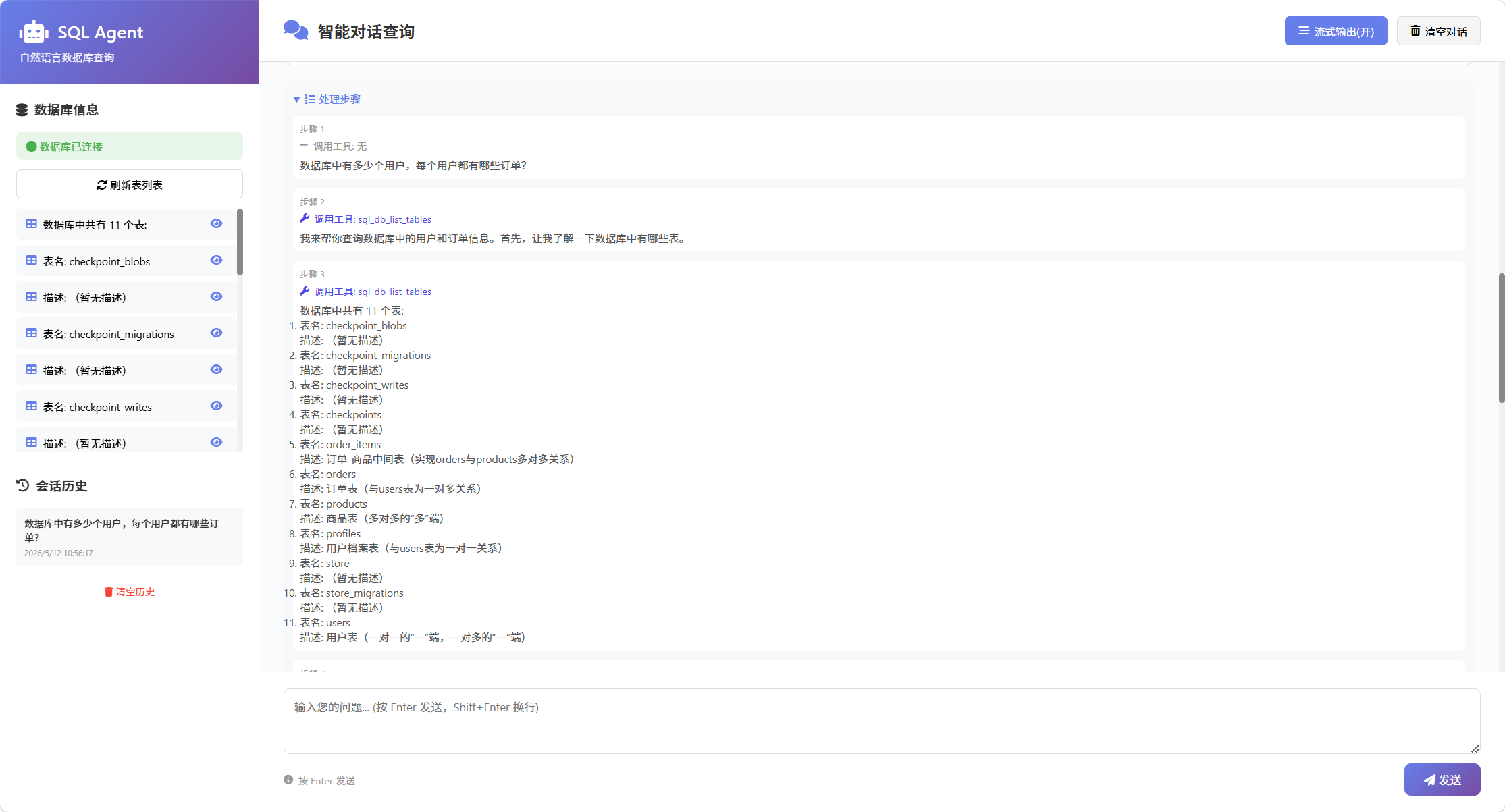
6、Agent 的消息和状态
一、四种消息类型
在 Agent 系统中,消息类型与基础 LLM 对话类似,但功能更丰富:
| 消息类型 | 作用 | 示例场景 |
|---|---|---|
SystemMessage |
设置 Agent 的全局行为、角色、规则 | SystemMessage("You are a coding assistant that uses tools.") |
HumanMessage |
用户输入,可包含多模态内容 | HumanMessage("帮我查一下明天的天气") |
AIMessage |
Agent 的思考输出或对用户的回复 | AIMessage("我将调用天气API来查询...") |
ToolMessage / FunctionMessage |
工具执行后的结果返回给 Agent | ToolMessage("北京明天晴,25°C", tool_call_id="xxx") |
二、典型消息流转顺序
HumanMessage(用户提问)
↓
AIMessage(Agent 决定调用工具)
↓
ToolMessage(工具返回结果)
↓
AIMessage(Agent 基于结果生成最终回答)
三、完整消息流示例
from langchain_core.messages import (
SystemMessage,
HumanMessage,
AIMessage,
ToolMessage
)
# 1. 系统消息:设置角色
system_msg = SystemMessage(
"你是一个天气助手,可以调用天气查询工具。"
)
# 2. 用户消息
human_msg = HumanMessage(
"北京明天天气怎么样?"
)
# 3. Agent 决定调用工具(模拟)
ai_msg_1 = AIMessage(
content="我需要调用 get_weather 工具来查询北京明天的天气。",
tool_calls=[
{
"name": "get_weather",
"args": {
"city": "北京",
"date": "明天"
},
"id": "call_001"
}
]
)
# 4. 工具返回结果
tool_msg = ToolMessage(
content="北京明天晴,气温18°C~28°C,风力2级。",
tool_call_id="call_001"
)
# 5. Agent 生成最终回复
ai_msg_2 = AIMessage(
"根据查询结果,北京明天天气晴朗,气温18°C到28°C,适合外出活动。"
)
# 完整消息列表
messages = [
system_msg,
human_msg,
ai_msg_1,
tool_msg,
ai_msg_2
]
四、使用 invoke 调用模型
from langchain_openai import ChatOpenAI
from langchain_core.messages import (
SystemMessage,
HumanMessage
)
model = ChatOpenAI(model="gpt-4")
# 一次完整对话
response = model.invoke([
SystemMessage("你是一个专业的编程助手。"),
HumanMessage("Python 中如何读取 CSV 文件?")
])
print(response.content)
7、定义 Agent 的状态(State)
Agent 的状态(State)用于记录当前会话中的所有关键信息,用于:
- 上下文管理
- 工具调用追踪
- 推理过程控制
- 错误恢复
- 多步任务执行
一、常见状态字段
| 字段 | 说明 |
|---|---|
messages |
存储全部历史消息 |
intermediate_steps |
记录 Agent 执行的工具步骤 |
current_goal |
当前正在处理的任务目标 |
remaining_steps |
剩余可执行推理步数 |
tool_call_id |
当前工具调用 ID |
error_flag |
错误标记 |
二、LangGraph 风格状态定义
from typing import List, Tuple, TypedDict, Annotated
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
# 自动合并消息
messages: Annotated[
List[BaseMessage],
add_messages
]
# 工具执行过程
intermediate_steps: List[
Tuple[str, dict, str]
]
# 剩余步数
remaining_steps: int
# 当前目标
current_goal: str
# 错误标志
error_flag: bool
# 初始化状态
initial_state: AgentState = {
"messages": [],
"intermediate_steps": [],
"remaining_steps": 25,
"current_goal": "",
"error_flag": False
}
三、完整状态更新流程
from langchain_core.messages import (
HumanMessage,
ToolMessage
)
class SimpleAgent:
def __init__(self, model, max_steps=10):
self.model = model
self.state = {
"messages": [],
"intermediate_steps": [],
"remaining_steps": max_steps,
"current_goal": "",
"error_flag": False
}
def run(self, user_input: str):
# 1. 添加用户消息
self.state["messages"].append(
HumanMessage(user_input)
)
while self.state["remaining_steps"] > 0:
# 2. 调用模型
response = self.model.invoke(
self.state["messages"]
)
self.state["messages"].append(response)
# 3. 检查是否调用工具
if hasattr(response, "tool_calls") and response.tool_calls:
for tool_call in response.tool_calls:
# 记录工具调用
self.state["intermediate_steps"].append({
"tool": tool_call["name"],
"input": tool_call["args"],
"output": None
})
# 执行工具
tool_result = self.execute_tool(tool_call)
# 添加 ToolMessage
self.state["messages"].append(
ToolMessage(
content=tool_result,
tool_call_id=tool_call["id"]
)
)
# 更新执行结果
self.state["intermediate_steps"][-1]["output"] = tool_result
# 步数减少
self.state["remaining_steps"] -= 1
return self.state["messages"][-1].content
def execute_tool(self, tool_call):
return (
f"执行了 {tool_call['name']},"
f"参数:{tool_call['args']}"
)
四、Dataclass 风格状态定义(推荐)
from dataclasses import dataclass, field
from typing import List
from langchain_core.messages import BaseMessage
@dataclass
class AgentState:
messages: List[BaseMessage] = field(default_factory=list)
intermediate_steps: List[dict] = field(default_factory=list)
remaining_steps: int = 25
current_goal: str = ""
error_flag: bool = False
def add_message(self, message: BaseMessage):
self.messages.append(message)
def add_step(
self,
tool_name: str,
tool_input: dict,
tool_output: str = None
):
self.intermediate_steps.append({
"tool": tool_name,
"input": tool_input,
"output": tool_output
})
def decrement_steps(self):
self.remaining_steps -= 1
def is_exhausted(self) -> bool:
return (
self.remaining_steps <= 0
or self.error_flag
)
# 使用示例
state = AgentState()
state.add_message(
HumanMessage("帮我计算 123 + 456")
)
state.add_step(
"calculator",
{"expression": "123+456"},
"579"
)
print(state.intermediate_steps)
8、Agent 中的记忆存储
记忆(Memory)是 Agent 实现:
- 连续对话
- 个性化
- 长期学习
- 多轮任务
的核心机制。
一、短期记忆(Short-Term Memory)
作用
在当前会话中保持上下文连续。
特点
| 项目 | 内容 |
|---|---|
| 生命周期 | 单次会话 |
| 存储位置 | 内存 |
| 容量 | 中等 |
| 速度 | 快 |
基础实现
from langchain_core.messages import (
HumanMessage,
AIMessage
)
conversation_history = []
def chat_with_memory(user_input: str, model):
# 添加用户消息
conversation_history.append(
HumanMessage(user_input)
)
# 调用模型
response = model.invoke(conversation_history)
# 保存回复
conversation_history.append(
AIMessage(response.content)
)
return response.content
滑动窗口记忆
from collections import deque
from langchain_core.messages import (
HumanMessage,
AIMessage
)
class SlidingWindowMemory:
def __init__(self, max_turns: int = 10):
self.max_turns = max_turns
self.messages = deque(
maxlen=max_turns * 2
)
def add_user_message(self, content: str):
self.messages.append(
HumanMessage(content)
)
def add_ai_message(self, content: str):
self.messages.append(
AIMessage(content)
)
def get_context(self):
return list(self.messages)
def clear(self):
self.messages.clear()
摘要记忆
class SummarizingMemory:
def __init__(
self,
model,
max_tokens: int = 2000
):
self.model = model
self.max_tokens = max_tokens
self.messages = []
self.summary = ""
def add_message(self, message):
self.messages.append(message)
if self.estimate_tokens() > self.max_tokens:
self._generate_summary()
def estimate_tokens(self):
total_chars = sum(
len(m.content)
for m in self.messages
if hasattr(m, "content")
)
return total_chars // 4
def _generate_summary(self):
history_text = "\n".join([
m.content
for m in self.messages[:-4]
])
prompt = f"请总结以下对话:\n{history_text}"
response = self.model.invoke([
HumanMessage(prompt)
])
self.summary = response.content
# 保留最近消息
self.messages = self.messages[-4:]
def get_context_with_summary(self):
context = []
if self.summary:
context.append(
SystemMessage(
f"历史摘要:{self.summary}"
)
)
context.extend(self.messages)
return context
二、长期记忆(Long-Term Memory)
作用
跨会话保存:
- 用户偏好
- 历史知识
- 任务结果
- 用户画像
使用 Chroma 实现长期记忆
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
class LongTermMemory:
def __init__(
self,
collection_name: str = "agent_memory"
):
self.embeddings = OpenAIEmbeddings()
self.vector_store = Chroma(
collection_name=collection_name,
embedding_function=self.embeddings,
persist_directory="./chroma_memory"
)
def add_memory(
self,
content: str,
metadata: dict = None
):
doc = Document(
page_content=content,
metadata=metadata or {}
)
self.vector_store.add_documents([doc])
def search_memory(
self,
query: str,
k: int = 5
):
return self.vector_store.similarity_search(
query,
k=k
)
def get_relevant_context(
self,
user_query: str,
k: int = 3
) -> str:
memories = self.search_memory(user_query, k)
if not memories:
return ""
context_parts = ["【相关历史记忆】"]
for i, mem in enumerate(memories, 1):
context_parts.append(
f"{i}. {mem.page_content}"
)
return "\n".join(context_parts)
使用示例
memory_store = LongTermMemory()
# 添加长期记忆
memory_store.add_memory(
"用户喜欢 Python 编程,正在学习 FastAPI",
metadata={
"user_id": "zhangsan",
"topic": "preferences"
}
)
# 搜索记忆
context = memory_store.get_relevant_context(
"我想实现用户登录"
)
print(context)
三、工作记忆(Working Memory)
作用
存储当前任务执行过程中的:
- 中间结果
- 工具状态
- 临时变量
- 待执行步骤
工作记忆实现
import time
class WorkingMemory:
def __init__(self):
self.current_task = None
self.task_steps = []
self.pending_tools = []
self.partial_results = {}
self.variables = {}
def start_task(self, task_name: str):
self.current_task = task_name
self.task_steps = []
self.pending_tools = []
self.partial_results = {}
self.variables = {}
def add_step(
self,
step_name: str,
input_data: dict,
output_data=None
):
self.task_steps.append({
"step": step_name,
"input": input_data,
"output": output_data,
"timestamp": time.time()
})
def set_variable(self, name: str, value):
self.variables[name] = value
def get_variable(self, name: str):
return self.variables.get(name)
def store_tool_result(
self,
tool_name: str,
result
):
self.partial_results[tool_name] = result
def get_tool_result(self, tool_name: str):
return self.partial_results.get(tool_name)
def clear(self):
self.current_task = None
self.task_steps = []
self.pending_tools = []
self.partial_results = {}
self.variables = {}
9、三种记忆整合
from dataclasses import dataclass, field
from typing import List, Dict, Any
from langchain_core.messages import (
BaseMessage,
SystemMessage
)
@dataclass
class IntegratedAgentState:
# 短期记忆
short_term: List[BaseMessage] = field(
default_factory=list
)
# 工作记忆
working: Dict[str, Any] = field(
default_factory=dict
)
# 长期记忆引用
long_term_refs: List[str] = field(
default_factory=list
)
session_id: str = ""
user_id: str = ""
remaining_steps: int = 25
def add_to_short_term(
self,
message: BaseMessage
):
self.short_term.append(message)
# 最多保留20条
if len(self.short_term) > 20:
self.short_term = self.short_term[-20:]
def update_working(
self,
key: str,
value: Any
):
self.working[key] = value
def get_working(
self,
key: str,
default=None
):
return self.working.get(key, default)
def add_long_term_ref(
self,
memory_id: str
):
self.long_term_refs.append(memory_id)
def clear_working(self):
self.working.clear()
def get_context_for_model(
self,
long_term_memories: List[str]
):
messages = []
# 长期记忆
if long_term_memories:
context_str = (
"相关记忆:\n"
+ "\n".join(long_term_memories)
)
messages.append(
SystemMessage(context_str)
)
# 短期记忆
messages.extend(self.short_term)
# 工作记忆
if self.working:
working_str = (
f"当前任务状态:{self.working}"
)
messages.append(
SystemMessage(working_str)
)
return messages
10、记忆管理最佳实践
1. 滑动窗口
class SlidingWindowBuffer:
def __init__(
self,
max_length: int = 10
):
self.buffer = []
self.max_length = max_length
def add(self, item):
self.buffer.append(item)
if len(self.buffer) > self.max_length:
self.buffer.pop(0)
def get(self):
return self.buffer.copy()
2. 摘要压缩
class SummaryMemory:
def __init__(
self,
model,
threshold: int = 8
):
self.model = model
self.threshold = threshold
self.messages = []
self.summary = ""
def add(self, msg):
self.messages.append(msg)
if len(self.messages) > self.threshold * 2:
self._compress()
def _compress(self):
old_messages = self.messages[:-4]
text = "\n".join([
m.content
for m in old_messages
if hasattr(m, "content")
])
response = self.model.invoke([
HumanMessage(f"总结:{text}")
])
self.summary = response.content
self.messages = self.messages[-4:]
def get_context(self):
result = []
if self.summary:
result.append(
SystemMessage(
f"历史摘要:{self.summary}"
)
)
result.extend(self.messages)
return result
3. 异步记忆存储
from concurrent.futures import ThreadPoolExecutor
class AsyncMemoryStore:
def __init__(self):
self.executor = ThreadPoolExecutor(
max_workers=2
)
self.pending_writes = []
def add_memory_async(
self,
content: str,
memory_store
):
future = self.executor.submit(
memory_store.add_memory,
content
)
self.pending_writes.append(future)
return future
def flush(self):
for future in self.pending_writes:
future.result()
self.pending_writes.clear()
4. TTL 过期记忆
import time
class TTLMemory:
def __init__(
self,
default_ttl_seconds: int = 86400
):
self.memories = {}
self.default_ttl = default_ttl_seconds
def add(
self,
key: str,
value: str,
ttl_seconds: int = None
):
expiry = time.time() + (
ttl_seconds or self.default_ttl
)
self.memories[key] = {
"value": value,
"expiry": expiry
}
def get(self, key: str):
item = self.memories.get(key)
if item and item["expiry"] > time.time():
return item["value"]
elif key in self.memories:
del self.memories[key]
return None
def cleanup_expired(self):
now = time.time()
expired_keys = [
k
for k, v in self.memories.items()
if v["expiry"] <= now
]
for k in expired_keys:
del self.memories[k]
return len(expired_keys)
5、记忆类型对比表
| 记忆类型 | 生命周期 | 存储位置 | 容量 | 访问速度 | 典型用途 |
|---|---|---|---|---|---|
| 工作记忆 | 单次任务 | 内存变量 | 极小 | 极快 | 工具调用中间结果 |
| 短期记忆 | 单次会话 | 内存列表 | 中等 | 快 | 对话上下文 |
| 摘要记忆 | 单次会话 | 内存字符串 | 小 | 快 | 压缩历史 |
| 长期记忆 | 跨会话 | 向量数据库 | 极大 | 中等 | 用户偏好、知识库 |
6、Agent 记忆架构图(文字版)
┌──────────────────────────────────────────────┐
│ Agent │
│ │
│ ┌───────────────┐ ┌────────────────┐ │
│ │ 工作记忆 │ │ 短期记忆 │ │
│ │ │ │ │ │
│ │ • 当前目标 │ │ • 最近消息 │ │
│ │ • 工具状态 │ │ • 对话历史 │ │
│ │ • 中间结果 │ │ • 用户回复 │ │
│ └───────────────┘ └───────┬────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────┐ │
│ │ 摘要记忆 │ │
│ │ │ │
│ │ • 历史压缩 │ │
│ └───────┬────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────┐ │
│ │ 长期记忆 │ │
│ │ │ │
│ │ • Chroma │ │
│ │ • FAISS │ │
│ │ • Pinecone │ │
│ │ │ │
│ │ 存储: │ │
│ │ • 用户偏好 │ │
│ │ • 历史摘要 │ │
│ │ • 知识事实 │ │
│ │ • 任务结果 │ │
│ └──────────────────────────────────────┘ │
└──────────────────────────────────────────────┘
【代码仓库】https://github.com/monkeyhlj/LLM_development_learning
【参考】https://docs.langchain.com/
【参考】https://www.bilibili.com/video/BV1Uhz4BWEEw

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)