我们做了一个让大模型「先想再算」的推理框架,Token消耗减少7倍,AIME准确率反而更高
·
最近把我们组的工作整理开源了,趁热写篇介绍,顺便聊聊这个方向我们踩过的一些坑。欢迎大家私信我进行讨论,进一步展开合作(也欢迎对高效的结构化推理感兴趣的学弟学妹来交流)
先说一个让我们困扰很久的问题
现在主流的大模型推理,不管是CoT还是ToT,本质上都是在一条很长的生成链上又规划又计算,Planning和Execution混在一起。
这带来两个问题:
- 算力分配不合理。规划阶段需要多样性,执行阶段需要精确性,但模型对两者一视同仁,在"2+2等于几"这种步骤上花的token和在"选哪条路"上花的一样多。
- Test-time scaling很贵。想多采样几次?那每次都得把完整的推理链(动辄几万token)跑一遍,成本直接×N。
直觉上这两件事本就不该混在一起。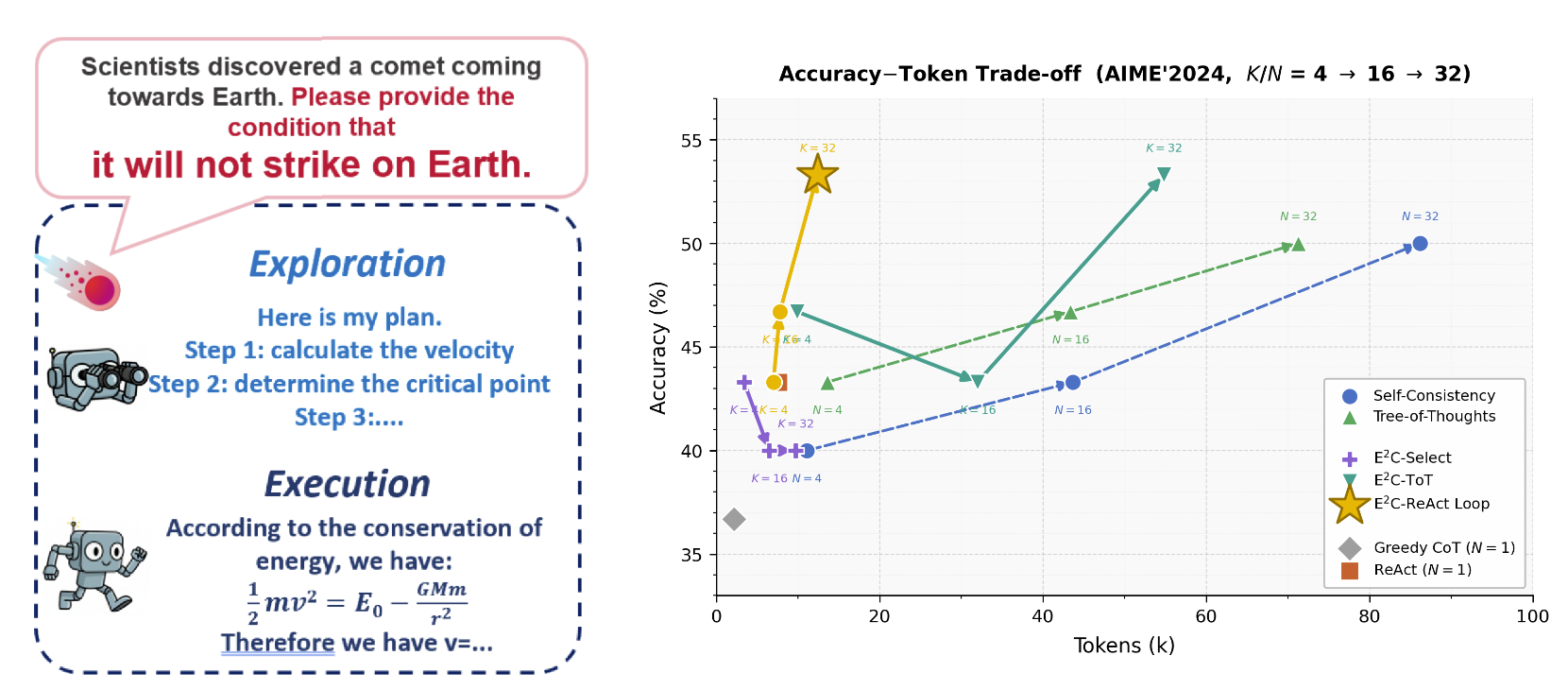
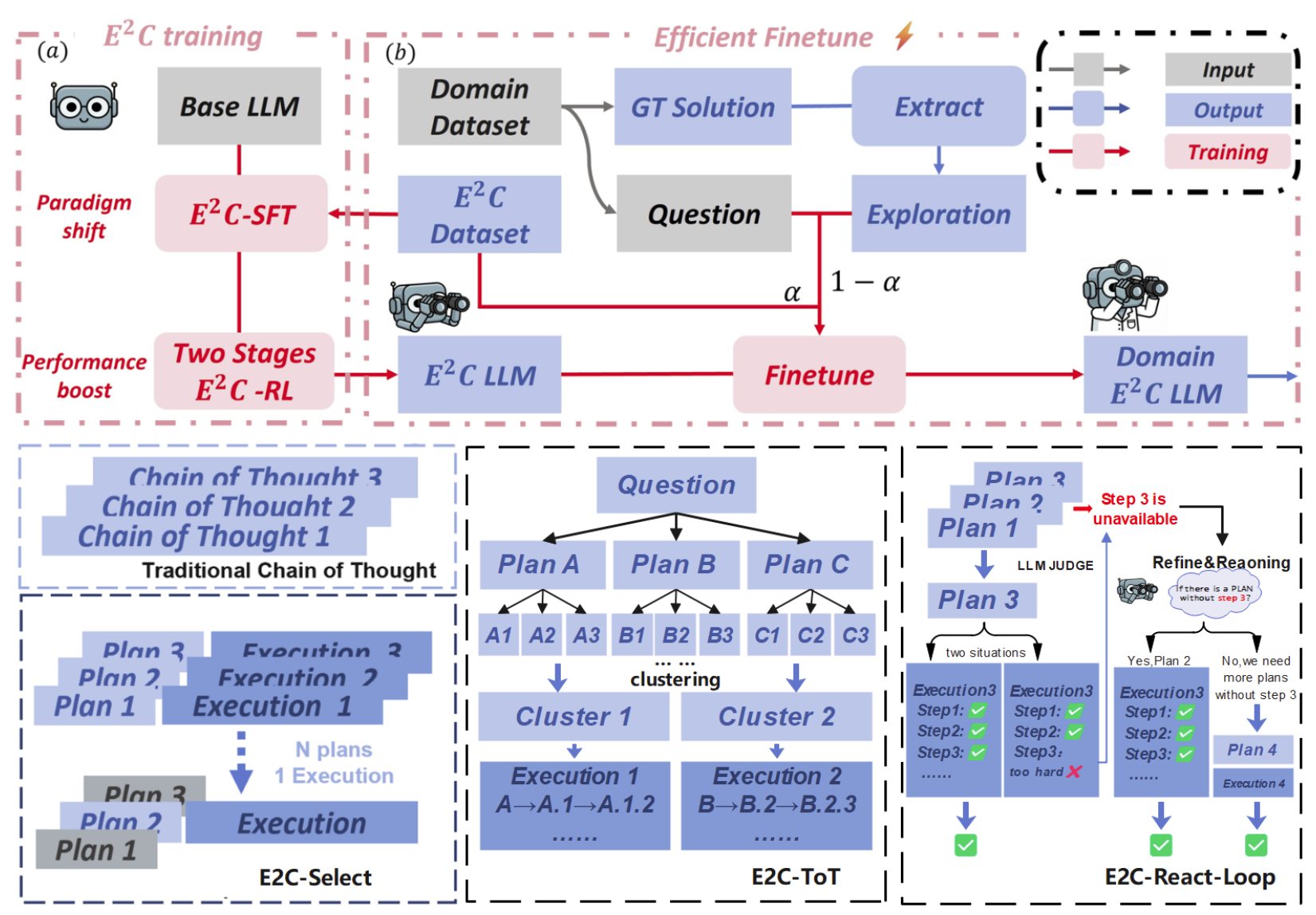
E2C的核心思路
我们提出的 Explore-Execute Chain(E2C) 做的事情其实不复杂:把一个模型的推理过程在结构上拆成两段。
EXPLORATION PHASE: ← ~1k tokens,随机采样,生成高层规划 分析题目,列举可行策略,选定最有前途的一条
EXECUTION PHASE: ← ~10k tokens,确定性执行,忠实跑完规划 按照上面定下来的方向,一步一步算出答案
不是两个模型,就是一个模型,但通过SFT+RL把这个结构训进去,让它自然地先探索再执行。
这样做有什么好处?
Test-time scaling的时候,只需要在短短的Exploration段采多次样就够了,不用每次都跑完整链。计算量大约是原来的 1/8。
数字说话
数学推理(Qwen3-8B,Pass@1 取8次平均):
| 方法 | AIME’24 | AIME’25 | MATH500 | AMC23 | 平均 |
|---|---|---|---|---|---|
| Qwen3-8B + GRPO | 36.9 | 34.4 | 88.2 | 79.3 | 59.6 |
| Qwen3-8B + E2C (SFT+RL) | 40.6 | 33.8 | 87.7 | 80.3 | 61.5 |
Test-time scaling(AIME 2024,预算K/N=32):
| 方法 | 准确率 | Token消耗 |
|---|---|---|
| Self-Consistency | 50.0% | 86.2k |
| Tree-of-Thoughts | 50.0% | 71.3k |
| E2C-ReAct Loop | 53.3% | 12.4k |
| 准确率更高,Token只用了ToT的1/7不到。 |
领域迁移(医疗QA):
只微调Exploration段(EF-SFT),用的数据token量是完整SFT的3.5%,部分医疗benchmark准确率提升最高14.5%。
开源资源
- 代码:github.com/OliverZ-dot/Explore-Execute-Chain
- 模型(4B / 8B):huggingface.co/TingheOliver/Explore-Execute-Chain-Qwen
- 数据集:huggingface.co/datasets/TingheOliver/Explore-Execute-Chain-Datasets
- 论文:arxiv.org/abs/2509.23946
快速上手
环境要求:Python 3.10+,PyTorch 2.1+,推理至少需要16GB显存(单卡)。
git clone https://github.com/OliverZ-dot/Explore-Execute-Chain.git
cd Explore-Execute-Chain
pip install -r verl/requirements.txt
跑一个例题(8B模型,HuggingFace直接拉权重):
python example_inference.py \
--model_path TingheOliver/Explore-Execute-Chain-Qwen \
--subfolder Qwen3-8B-E2C-SFT-RL \
--problem "Find all prime numbers p such that p^2 + 2 is also prime."
也有交互式demo,内置了数学/医疗/代码几类例题可以直接选:
python example_interactive.py
国内访问HuggingFace慢的话,数据下载脚本支持hf-mirror:
bash scripts/prepare_all_data.sh --mirror

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)