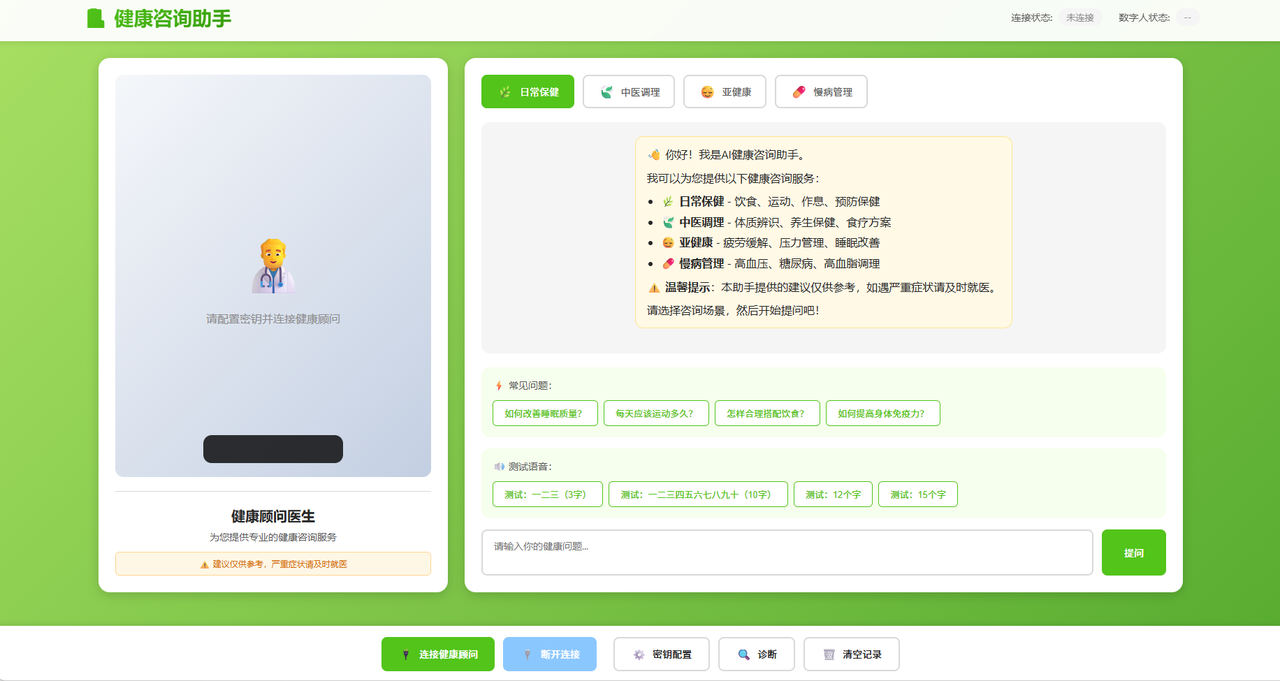
我给健康 Agent 装了个 3D 身体:从聊天框到具身智能的实战记录
当 AI 健康顾问从一串文字变成一个能说、能动、有表情的 3D 数字医生,交互体验发生了质变。这篇文章记录了我用魔珐星云 SDK 从零搭建「智能健康咨询数字员工」的完整过程。
一、一个问题:为什么 AI 看病总觉得"差点意思"?
最近这两年,AI 医疗类产品越来越多。打开手机,各类健康咨询 App 都能跟你聊上几句——你问"最近总是失眠怎么办",它能给你列一堆建议,从作息调整到穴位按摩应有尽有。
但说真的,你用几次就不想用了。原因很简单:太冷了。
一个真正的医生问诊是什么体验?医生会看着你、听你描述、在你说话时点头回应、思考时微微皱眉、给建议时语气坚定又温和——这些非语言信息占了人际沟通 55% 以上的权重(梅拉比安法则)。而现有的 AI 健康咨询呢?一个白色聊天框,一段灰色文字,连个表情都没有。
这不是 AI 不够聪明的问题,是表达方式的问题。 Agent 的"大脑"已经很强了,但它缺少一个"身体"——没有声音、没有表情、没有动作,所有的专业判断都被压缩成了一行行文字。
这也是我参加魔珐星云具身智能黑客松时想解决的问题:能不能给 AI 健康顾问一个 3D 的"身体",让它像一个真正的医生一样面对面和你交流?
二、单点技术的局限:为什么"拼积木"行不通?
一开始我想得很简单:接一个大模型生成文字,用 TTS 转成语音,再套个 3D 模型做口型——不就行了?实际做下来才发现,这三个环节各自为战,拼在一起处处是坑。
LLM 只管"说什么",不管"怎么说"
大模型输出的是纯文本 token。同样一句"建议您每天运动 30 分钟",模型输出的字符串不带任何语气、表情和手势信息。但在真实问诊场景里,医生说这句话时会微笑、会做手势比划——这些非语言信号才是建立信任感的关键。
TTS 和 3D 模型的同步是个黑洞
加上 TTS 确实有了声音,但口型同步怎么做?预生成整段音频再匹配口型,延迟至少 1-2 秒;用音素实时驱动,精度又不够,嘴唇和声音对不上。用户一看就知道是假的,信任感直接归零。
云端渲染碰上健康咨询场景的"不可能三角"
健康咨询的交互节奏很特别——用户问完之后,需要等 AI 想完、说完一整段话,中间还可能追问打断。这对实时性要求很高。而传统数字人采用云端集中渲染方案,核心流程是由云端 GPU 完成画面生成,再将结果下发至终端呈现。这种方式强依赖网络、延迟高、无法实时打断,仅适用于低交互场景。
想象一下:你在社区健康小屋,跟数字医生说到一半,画面卡住不动了——这种体验还不如看文字。
三、魔珐星云的解法:参数流 + 端侧渲染
魔珐星云没有在传统方案上缝缝补补,而是从底层换了一条技术路线:参数流驱动,端侧渲染。
传输的不是画面,是"指令"
传统方案传视频流——每秒 30 帧 1080p 需要 2-4 Mbps。魔珐星云传的是参数:骨骼旋转角度、表情权重、口型系数,全是浮点数。数据量从 Mbps 降到 KB 级,差了三个数量级。
这意味着三件事:
- 端到端响应约 500/ms——用户问完,数字医生几乎是秒回
- 天然支持流式——LLM 吐出第一个 token,口型参数就跟着生成,端侧立刻渲染。不需要等整段回答写完
- 多维度独立控制——口型、表情、肢体、视线参数互不耦合,可以并发驱动
渲染在本地做,不在云端做
参数推到用户设备上之后,渲染在哪里完成?在设备本地的 GPU 上。2025-2026 年的消费级芯片完全扛得住 1080p@30fps 的 3D 渲染。瑞芯微 RK3588 这种百元级国产芯片就能跑。
这对健康咨询场景特别关键——社区健康小屋、企业医务室这些地方,网络条件参差不齐。云端集中渲染方案在弱网下直接崩,但 KB 级的参数流在 4G 下都稳得很。
端到端三层架构
多模态感知层(听到用户的问题)
↓
大模型 + 智能体认知层(分析症状、给出建议)
↓
多模态具身表达层(用语音+口型+表情+动作"说"出来)
表达层被独立 解耦 是这套架构最聪明的设计。开发者自由选择 LLM(我用了魔搭社区的 Qwen),魔珐星云只负责最后一步——把文本变成可感知的具身表达。不强绑任何模型厂商,开发者的选择权完全在自己手里。
四、实战:我用魔珐星云 SDK 做了一个 AI 健康数字员工
理论说完了,下面是我实际做的项目——智能健康咨询数字员工。项目已开源在 GitHub,下面是完整的技术拆解。
完整代码:https://github.com/S05dh11/health-advisor-assistant
SDK 文档:https://xingyun3d.com/developers/52-183
项目架构
我采用纯前端 SPA 架构,模块化拆分为五个部分:
health-advisor-assistant/
├── index.html # 单页面入口
├── css/style.css # 全部样式(健康主题绿色调)
├── js/
│ ├── config.js # 密钥管理(localStorage 存取)
│ ├── avatar.js # 数字人 SDK 封装(核心,634 行)
│ ├── ai.js # AI 对话(魔搭 Qwen 流式调用)
│ ├── ui.js # UI 交互(消息渲染、状态更新)
│ └── main.js # 入口初始化
└── server.js # Node.js 静态文件服务器
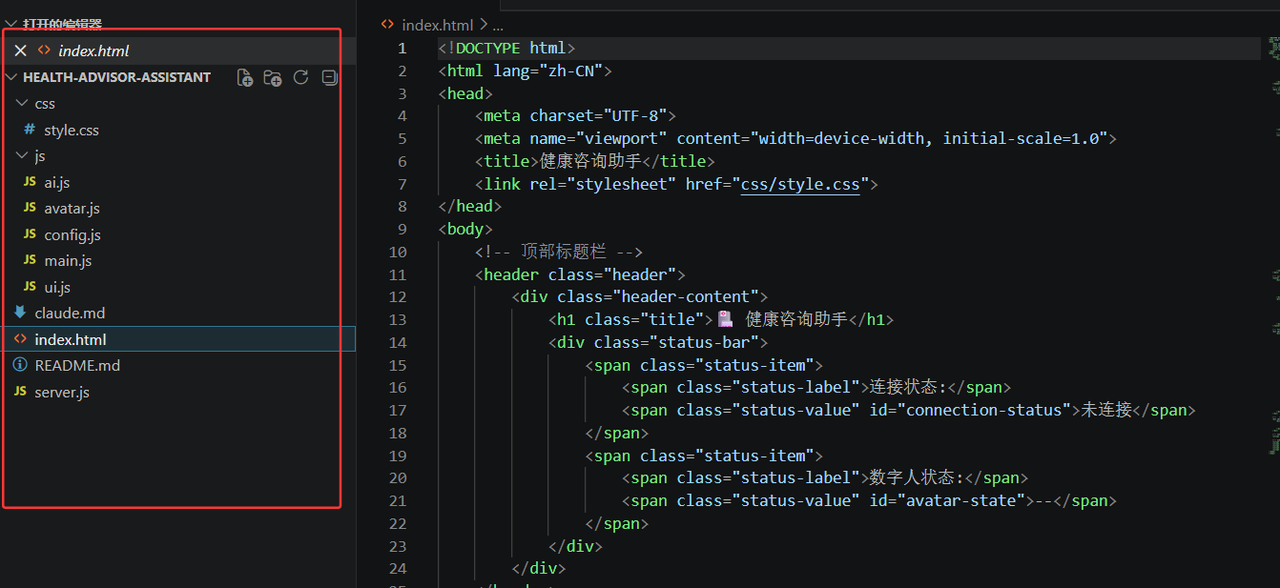
第一步:SDK 连接与初始化
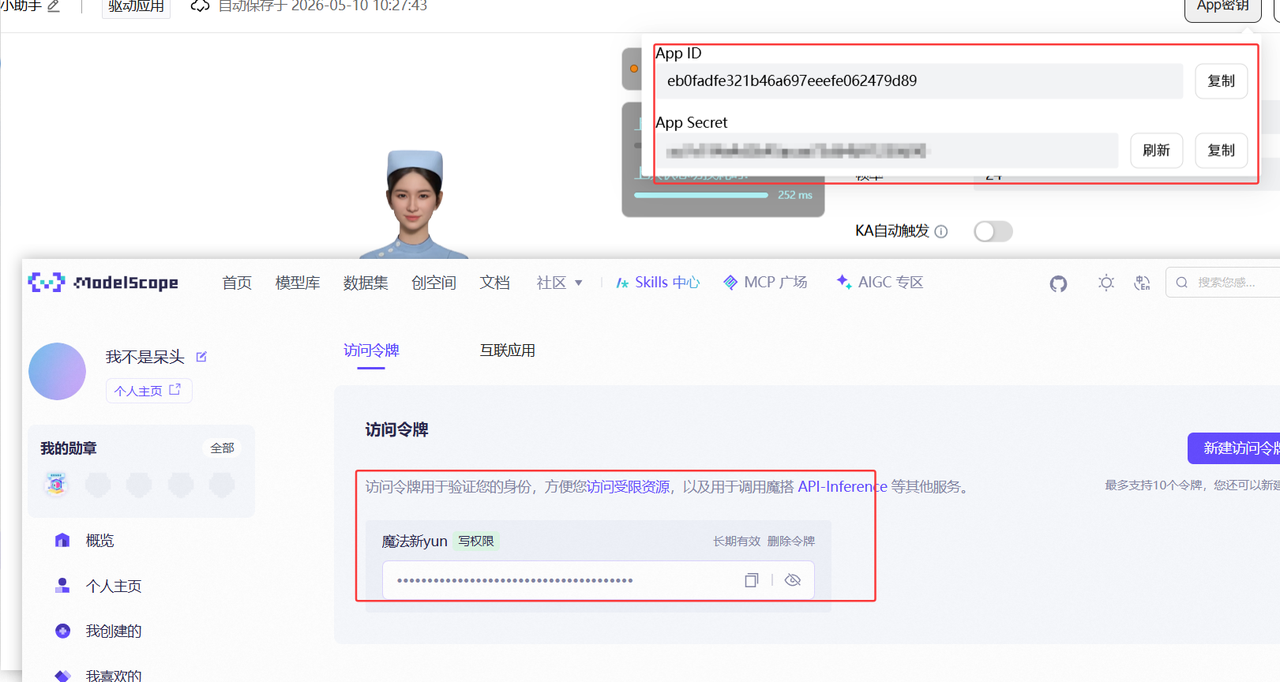
在魔珐星云官网注册、创建「具身驱动应用」、选择数字人形象(我选了超写实医生形象)后,拿到 App ID 和 App Secret。然后是 SDK 的初始化连接,核心代码在 avatar.js 的 connect() 方法中:
// avatar.js - 连接数字人
async connect(config, onProgress) {
// 清空容器,创建包装元素
const container = document.querySelector('#avatar-container');
container.innerHTML = '<div id="xmov-avatar-wrapper" style="width:100%;height:100%;"></div>';
// 创建 SDK 实例
this.sdk = new XmovAvatar({
containerId: '#xmov-avatar-wrapper',
appId: config.appId,
appSecret: config.appSecret,
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
// 状态变化回调 —— 驱动界面更新
onStateChange: (state) => {
this.currentState = state;
UI.updateAvatarState(state);
},
// 语音播放状态回调 —— 监控数字人说话状态
onVoiceStateChange: (status) => {
console.log('数字人语音状态:', status); // start / end
},
enableLogger: false
});
// 初始化(会下载模型资源)
await this.sdk.init({
onDownloadProgress: (progress) => {
onProgress && onProgress(progress);
}
});
// 等待连接稳定
await this.sleep(3000);
this.connected = true;
}
几个注意点:
init()首次会下载数字人模型和动作资源,需要展示进度条安抚用户等待- 连接完成后需要等待约 3 秒让 SDK 状态稳定,否则后续操作可能失败
onStateChange和onVoiceStateChange这两个回调是后续状态管理和流式语音驱动的关键,后面会展开讲
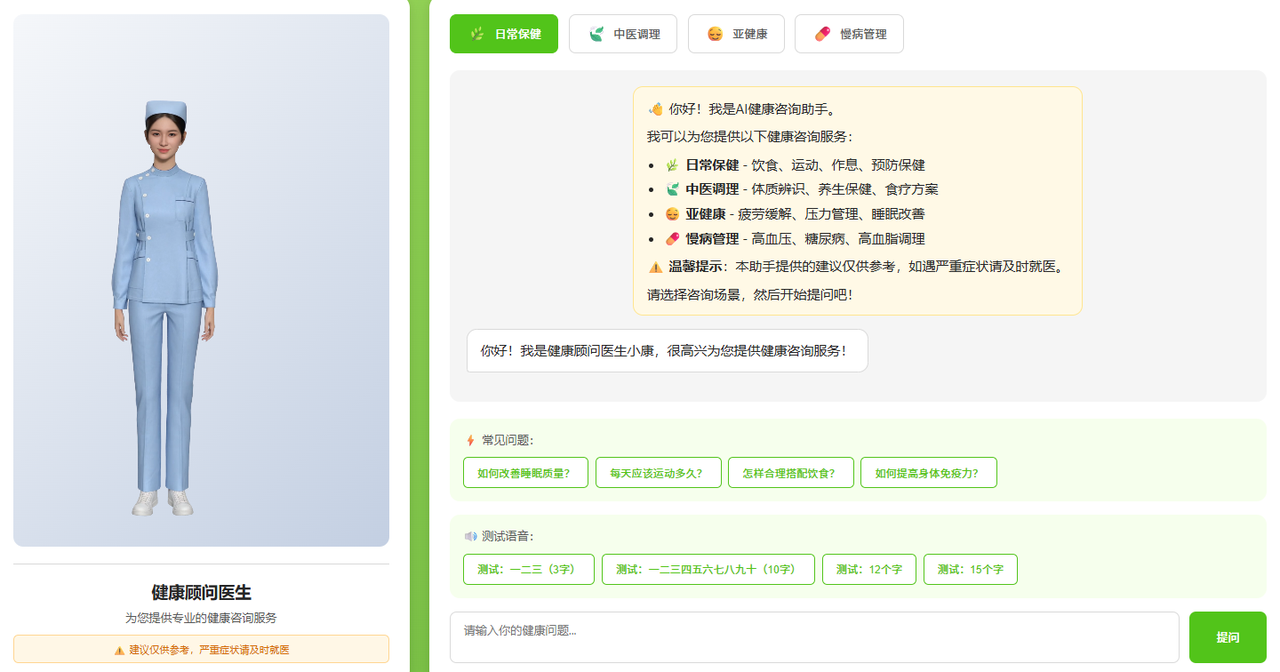
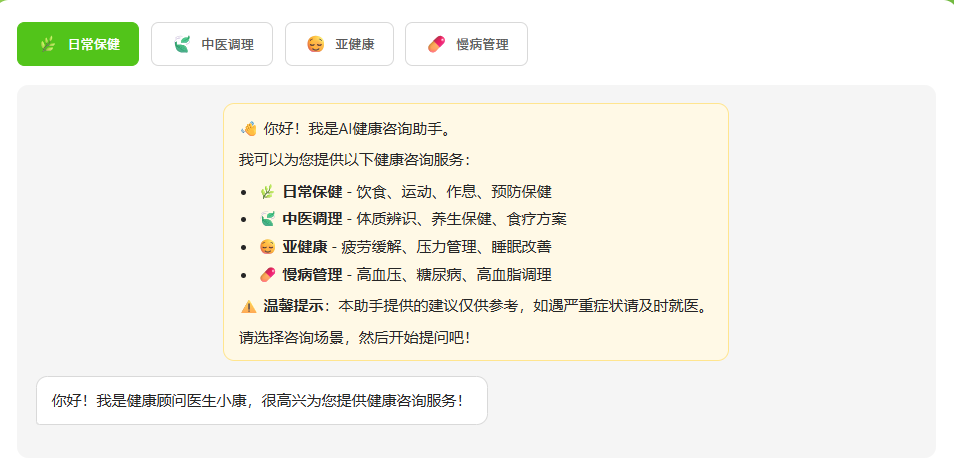
第二步:对话场景设计
健康咨询不是通用聊天,需要专业分诊。我设计了四个独立场景,每个场景有自己的角色人设和系统提示词:
| 场景 | 角色名 | 专业领域 | 风格 |
|---|---|---|---|
| 日常保健 | 健康顾问小康 | 饮食、运动、作息、预防保健 | 专业亲和,实用易懂 |
| 中医调理 | 中医医师康康 | 体质辨识、养生保健、食疗方案 | 温和细致,传统与现代结合 |
| 亚健康调理 | 调理专家小康 | 疲劳缓解、压力管理、睡眠改善 | 关怀体贴,循序渐进 |
| 慢病管理 | 管理顾问小康 | 高血压、糖尿病、高血脂 | 严谨专业,注重长期管理 |
每个场景独立的系统提示词定义在 ai.js 中:
// ai.js - 四个场景的系统提示词
SCENE_PROMPTS: {
daily: `你是健康顾问医生小康。
⚠️ 重要限制:每次回答必须控制在50字以内。
⚠️ 免责声明:建议仅供参考,严重症状请及时就医。
专业领域:饮食营养、运动健身、作息管理、预防保健。
咨询风格:专业亲和,实用易懂。
简洁回答,给出可操作的具体建议。`,
tcm: `你是中医调理医师康康。
⚠️ 重要限制:每次回答必须控制在50字以内。
⚠️ 免责声明:建议仅供参考,严重症状请及时就医。
专业领域:体质辨识、养生保健、食疗方案、经络调理。
咨询风格:温和细致,传统与现代结合。
简洁回答,注重整体调理。`,
// ... 亚健康、慢病管理场景类似
}
场景切换的交互也很简单——用户点击顶部四个 Tab 按钮,ai.js 的 setScene() 方法切换当前场景和提示词,ui.js 同步更新界面上的角色信息和快捷问题:
// ui.js - 场景切换
initSceneButtons() {
this.elements.sceneBtns.forEach(btn => {
btn.addEventListener('click', () => {
// 更新按钮状态
this.elements.sceneBtns.forEach(b => b.classList.remove('active'));
btn.classList.add('active');
// 切换场景(更新提示词和角色信息)
AI.setScene(btn.dataset.scene);
// 更新快捷问题列表
this.updateQuickQuestions();
});
});
}
第三步:AI 对话流式对接
对话模块的核心是用 SSE 流式调用魔搭社区的 Qwen 模型,边生成边更新 UI。这是 ai.js 中 chat() 方法的核心逻辑:
// ai.js - 流式对话
async chat(userMessage, apiKey, onMessage, onComplete, onError) {
const systemPrompt = this.SCENE_PROMPTS[this.currentScene];
const response = await fetch('https://api-inference.modelscope.cn/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': Bearer ${apiKey}
},
body: JSON.stringify({
model: 'Qwen/Qwen2.5-7B-Instruct',
messages: [
{ role: 'system', content: systemPrompt },
{ role: 'user', content: userMessage }
],
stream: true,
temperature: 0.7,
max_tokens: 800
})
});
// SSE 流式解析
const reader = response.body.getReader();
const decoder = new TextDecoder();
let fullResponse = '';
while (true) {
const { done, value } = await reader.read();
if (done) { onComplete(fullResponse); break; }
const chunk = decoder.decode(value, { stream: true });
const lines = chunk.split('\n');
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = line.slice(6);
if (data === '[DONE]') { onComplete(fullResponse); return; }
const parsed = JSON.parse(data);
const content = parsed.choices?.[0]?.delta?.content;
if (content) {
fullResponse += content;
onMessage(content); // 逐 token 更新 UI
}
}
}
}
}
流式输出让用户在 AI 思考的瞬间就能看到回答在"打字"般逐步出现,而不是干等几秒钟突然蹦出一大段文字。这在前端是基础的体验优化,但后面你会发现,流式输出和数字人语音的结合才是真正的重头戏。
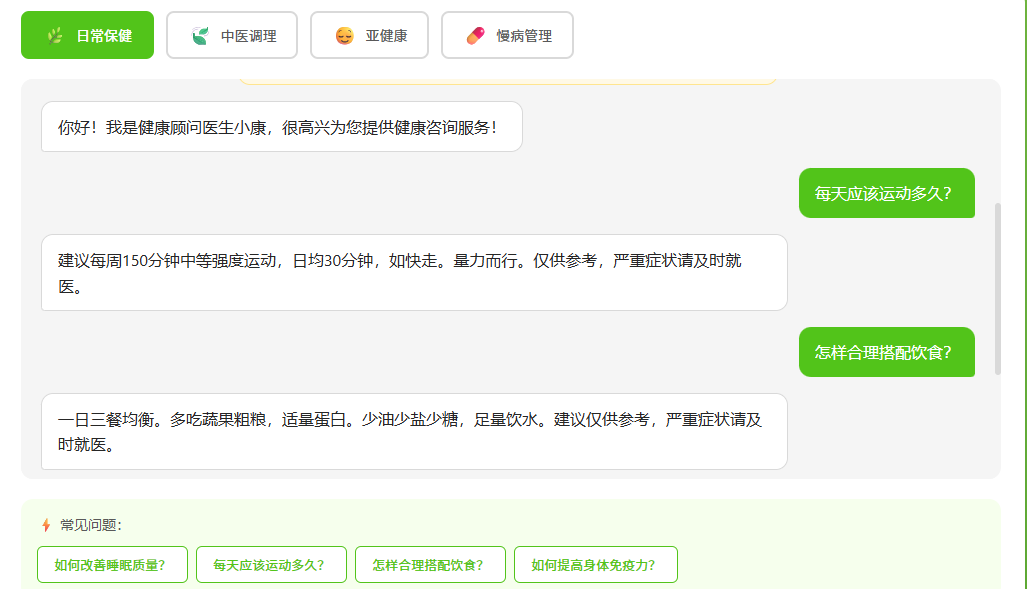
第四步:数字人状态机设计
这是整个项目最关键的交互设计。我实现了一套状态机,让数字人的行为和对话流程严格同步:
用户提问 → listen(倾听中)→ think(思考中)→ speak(说话中)→ idle(待机)
在 ui.js 的 handleSendMessage() 方法中,状态流转是这样的:
// ui.js - 发送消息的核心流程(简化版)
async handleSendMessage() {
const message = input.value.trim();
// 添加用户消息气泡
this.addMessage('user', message);
this.setSendButtonDisabled(true);
let assistantMessage = '';
const messageElement = this.addMessage('assistant', '');
// 调用 AI,流式更新气泡
await AI.chat(
message, apiKey,
// onMessage - 逐 token 更新 UI + 流式喂给数字人
(chunk) => {
assistantMessage += chunk;
this.updateMessage(messageElement, assistantMessage);
Avatar.feedStreamChunk(chunk); // 流式喂给数字人(详见第五步)
},
// onComplete - AI 回复完毕,结束流式语音
(fullMessage) => {
this.updateMessage(messageElement, fullMessage);
Avatar.endStreamingSpeak(); // 标记说完
this.setSendButtonDisabled(false);
}
);
}
第五步:流式语音驱动——让数字人和 AI 同步"开口"
前面的步骤中,AI 的回答是一边生成一边更新 UI 的。但数字人的语音呢?如果等 AI 全部说完再让数字人开口,用户要盯着聊天框等好几秒——体验不够好。
翻看 SDK 文档(1.4 节),我发现 speak() 方法原生支持流式调用:
speak(ssml: string, is_start: boolean, is_end: boolean): void
三个参数的含义:
- 第一次调用:
is_start = true, is_end = false—— 告诉 SDK"我要开始说话了" - 中间每次调用:
is_start = false, is_end = false—— 继续追加内容 - 最后一次调用:
is_start = false, is_end = true—— 告诉 SDK"说完了"
这意味着我们可以把 LLM 的流式 token 直接对接到数字人的语音流——AI 边想,数字人边说。核心代码在 avatar.js 中:
// avatar.js - 流式语音驱动
startStreamingSpeak() {
this.speakBuffer = '';
this.isFirstSpeak = true;
}
feedStreamChunk(text) {
if (!this.connected || !this.sdk) return;
this.speakBuffer += text;
// 首次调用前积攒一小段内容(官方最佳实践)
// 保证数字人的消耗速度慢于大模型的输出速度,避免"追尾"
if (this.isFirstSpeak && this.speakBuffer.length < 15) {
return;
}
if (this.isFirstSpeak) {
this.sdk.speak(this.speakBuffer, true, false); // is_start = true
this.speakBuffer = '';
this.isFirstSpeak = false;
} else {
this.sdk.speak(text, false, false); // 追加内容
}
}
endStreamingSpeak() {
if (!this.connected || !this.sdk) return;
if (this.speakBuffer.length > 0) {
// 把缓冲区剩余内容作为最后一次 speak 发出
this.sdk.speak(this.speakBuffer, this.isFirstSpeak, true);
}
}
整个流式语音的交互流程:
用户提问 → listen → think
→ AI 开始流式输出,积攒约 15 字
→ speak(is_start=true) → 数字人开口说话
→ 后续 token 逐个 speak(is_start=false, is_end=false)
→ AI 输出结束 → speak(is_end=true) → 数字人说完
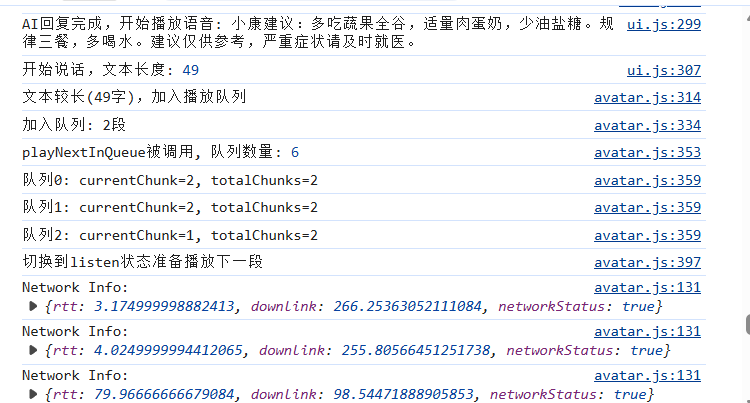
这比"等 AI 全部写完再开口"的体验好很多——用户几乎感觉不到等待,AI 想到什么数字人就在说什么。关键的设计决策有三个:
- 用 SDK 原生的 is_start / is_end 参数控制流式起止,而不是自己造轮子做分段队列——SDK 内部已经处理好了流式拼接和状态管理
- 首次 speak 前积攒约 15 字——这是官方文档推荐的最佳实践,让数字人的消耗速度慢于大模型的输出速度,避免"追尾"导致语音断续
- 流式对接让 AI “想到哪说到哪”——用户不再需要等 AI 想完,第一个 token 出来约 1 秒后数字人就开口了
官方文档:
speak()的流式调用详见 SDK 文档 1.4 节注意事项:
- 一次完整的 speak(is_end=true)结束后,下一次 speak 前建议用
interactive_idle()或listen()做一次状态切换onVoiceStateChange回调会抛出start/end事件,可用于监控语音播放状态
最终效果
把上面这些组装到一起,最终的交互流程是:
- 用户在右侧输入健康问题(或点击快捷问题)
- AI 流式生成回答,文字气泡逐步显示
- AI 边流式生成,数字医生边"说"——有口型、有语音、有动作,无需等待
- 底部字幕实时同步,用户既能听到也能看到
- 说完后回到待机状态,等待下一个问题
五、SDK 开发与落地方式总结
通过这个项目的实战,我总结一下魔珐星云 SDK 的开发和落地要点:
接入门槛低。 整个项目我用纯前端技术(HTML/CSS/原生 JS)就搞定了,没有 Webpack、没有框架依赖。SDK 通过 CDN 引入,API 就是 new XmovAvatar() → init() → speak() 三步走,前端开发者半小时就能跑通。
表达层独立解耦。这是我认为星云架构最核心的设计优势。ai.js 负责对接任意大模型,avatar.js 负责对接星云 SDK,两个模块通过回调函数连接,互不耦合。这意味着你可以把 Qwen 换成 DeepSeek、换成 GPT,只需要改 ai.js,数字人驱动层完全不用动。星云不是传统数字人渲染引擎,而是 AI 具身表达的基础设施——传统方案是"渲染+下发",星云是"参数+端侧",架构底层就不同。
落地路径清晰。 这个项目虽然是个黑客松 Demo,但它的落地路径很明确:
- 企业医务室:部署一台大屏 + RK3588 主板(百元级),直接跑 Android 版本
- 社区健康小屋:现有设备不换硬件,嵌入 Web 版本
- 药店咨询台:一台平板即可,4G 网络就能稳定运行
- 健康管理平台:SDK 嵌入现有 App,给 AI 客服加上"身体"
端侧渲染让规模化部署成为可能。 传统方案每路独占 GPU,10 路并发就要一台 A100。而星云的端侧渲染方案,服务器只做轻量级参数生成,10 路、100 路、1000 路的成本差距极小。对于需要全国铺开的企业级场景(比如连锁药店的 AI 药师),这个成本结构才是可持续的。
六、实际体验与总结
做完这个项目,说说我最真实的感受。
数字人让 AI 健康咨询从"查资料"变成了"问诊"。 同样一条建议"建议每天运动 30 分钟",文字版本你扫一眼就滑走了;但当一个穿白大褂的数字医生看着你、微笑着、用温和的语气说出来,你的感受是完全不同的——你会更认真地听、更愿意照做。这就是具身表达的价值:不是更好看,而是更可信。
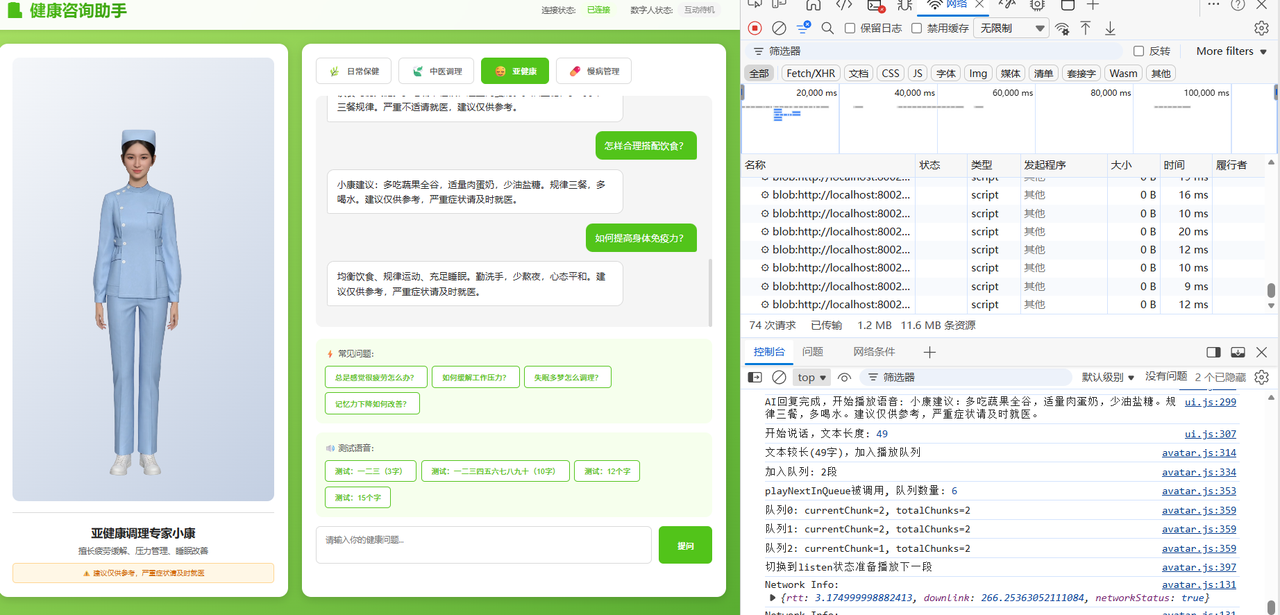
SDK 开发体验流畅。 魔珐星云 JS SDK 的 API 设计很直觉:状态机(idle/listen/think/speak)+ speak 方法 + 回调事件,三个核心概念覆盖了绝大多数场景。不需要懂 3D 渲染、不需要懂骨骼动画,前端开发者就能上手。整个项目的核心难点不在 SDK 接入,而在于业务逻辑(流式语音对接、场景切换),SDK 原生的 speak 流式支持让数字人"边听边说"变得很简洁,确实做到了"开发者友好"。
参数流 + 端侧渲染的组合是正确的工程选择。 在开发过程中我深刻感受到——如果用云端集中渲染方案,我连本地调试都会被延迟和卡顿折磨。但实际上,数字人的响应非常即时,语音和口型天然同步(因为都是同一份参数驱动的),弱网下也不受影响。这不是优化出来的体验,是架构选择决定的体验。
当然也有不足。 在开发中我发现一些值得改进的地方:
- SDK 的流式 speak 调用在弱网环境下偶尔会出现语音断续,期待后续版本在网络自适应方面有更好的表现
- 当前 speak 流式调用结束后,下一次调用前需要手动切换状态(interactive_idle 或 listen),如果 SDK 能在内部自动处理状态重置会更方便
- 50 字的回答限制对于复杂健康咨询来说还是太短了,后续需要放开限制并优化长文本的流式体验
但我相信这些都是平台快速迭代中会解决的问题。
最后我想说:具身智能不是一个炫酷的噱头,而是 Agent 的必然形态。 当 AI 从"幕后大脑"变成"台前医生",用户的信任感、接受度和依从性都会发生质的变化。魔珐星云做的事情,本质上是为这个转变提供基础设施——让每一块存量屏幕、每一个 AI Agent,都能以最低成本获得一个可信的"身体"。
而作为开发者,你要做的就是接过 SDK,给自己的 Agent 装上这个身体。整个过程,比你想的要简单得多。
项目开源地址: https://github.com/S05dh11/health-advisor-assistant
魔珐星云 SDK 文档: https://xingyun3d.com/developers/52-183
专属链接https://xingyun3d.comutm_campaign=daily&utm_source=jixinghuiKoc82

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 60
60 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)