基于QWEN3、3.5训练Lora
背景
在做很多分类任务时,实际项目中的情况很多而且复杂,不可能将每种示例都放入到提示词中,同时为了让模型能更好的做任务,所以使用Lora。结论是很不错,在一定程度上也节省了一些token
TIP:不同架构的和参数的模型不能共用一个Lora,哪怕是同一系列(我尝试了不同平台:A100->p800,A100 3.5B->A100 122B)
一、准备
- conda环境
- LLaMA-Factory 0.9.5.dev0
- A100-80G*4
- 相关模型:Qwen3-235B-A22B-Instruct-2507-FP8、Qwen3.5-35B-A3B、Qwen3.5-122B-A10B
- 训练数据集、测试数据集
二、开始
# 创建训练环境
conda create -n llamafactory python=3.12 -y
# 下载对应Lora的基础模型(你实际项目的基座模型,这里一定要注意使用基础模型训练的Lora基本不能跨模型使用,即便是同一系列的)
# 下载llamafactory代码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e . pip install -r requirements/metrics.txt# 数据集格式(我的是对话形式分类所以用对话模版,这一步用模型生成、通过工程化替换固定提示词就好。最好还是根据项目实际情况收集客户特征问题后再泛化)
保存好数据路径(配置在data_info.json中):数据目录/训练数据.json
[
{
"messages": [
{
"role": "system",
"content": "作为xxx你要xxxx"
},
{
"role": "user",
"content": "今天的销售额是多少"
},
{
"role": "assistant",
"content": "0"
}
]
}
...
]
# 配置数据集
vi LLaMA-Factory/data/data_info.json
"router_classification": {
"file_name": "数据目录/训练数据.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
}
# 启动webui进行训练
export CUDA_VISIBLE_DEVICES=4,5,6,7 llamafactory-cli webui
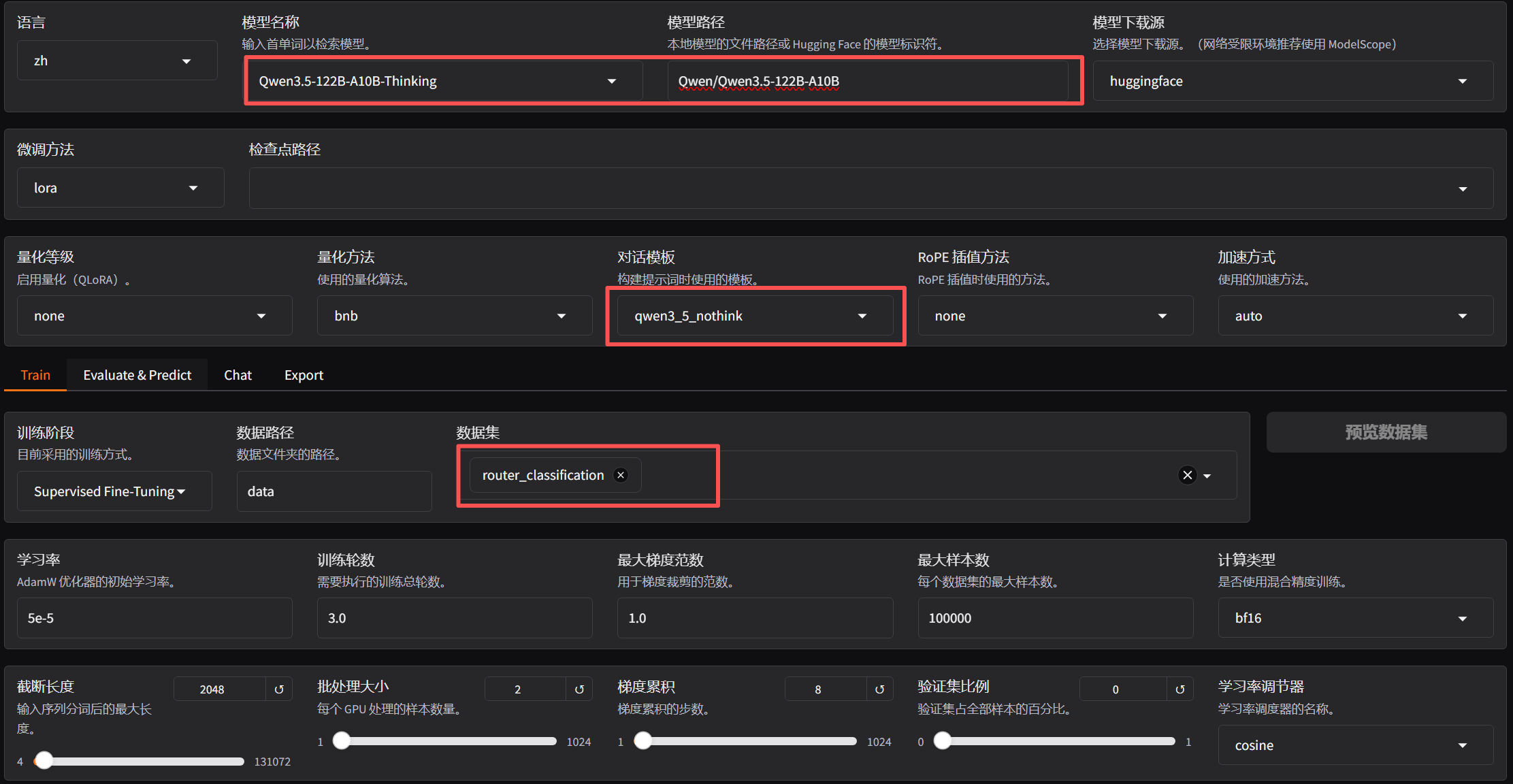
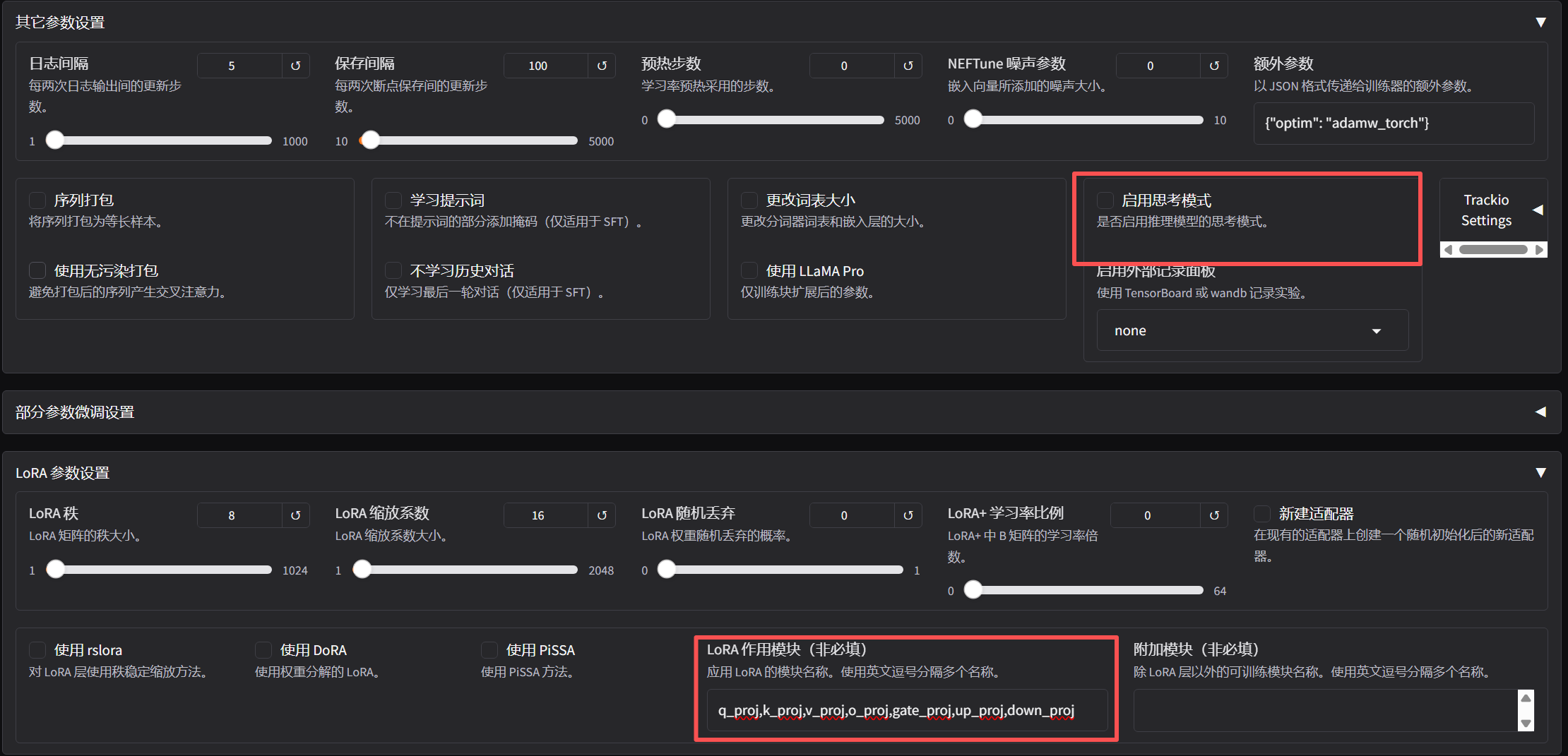
# 配置训练参数
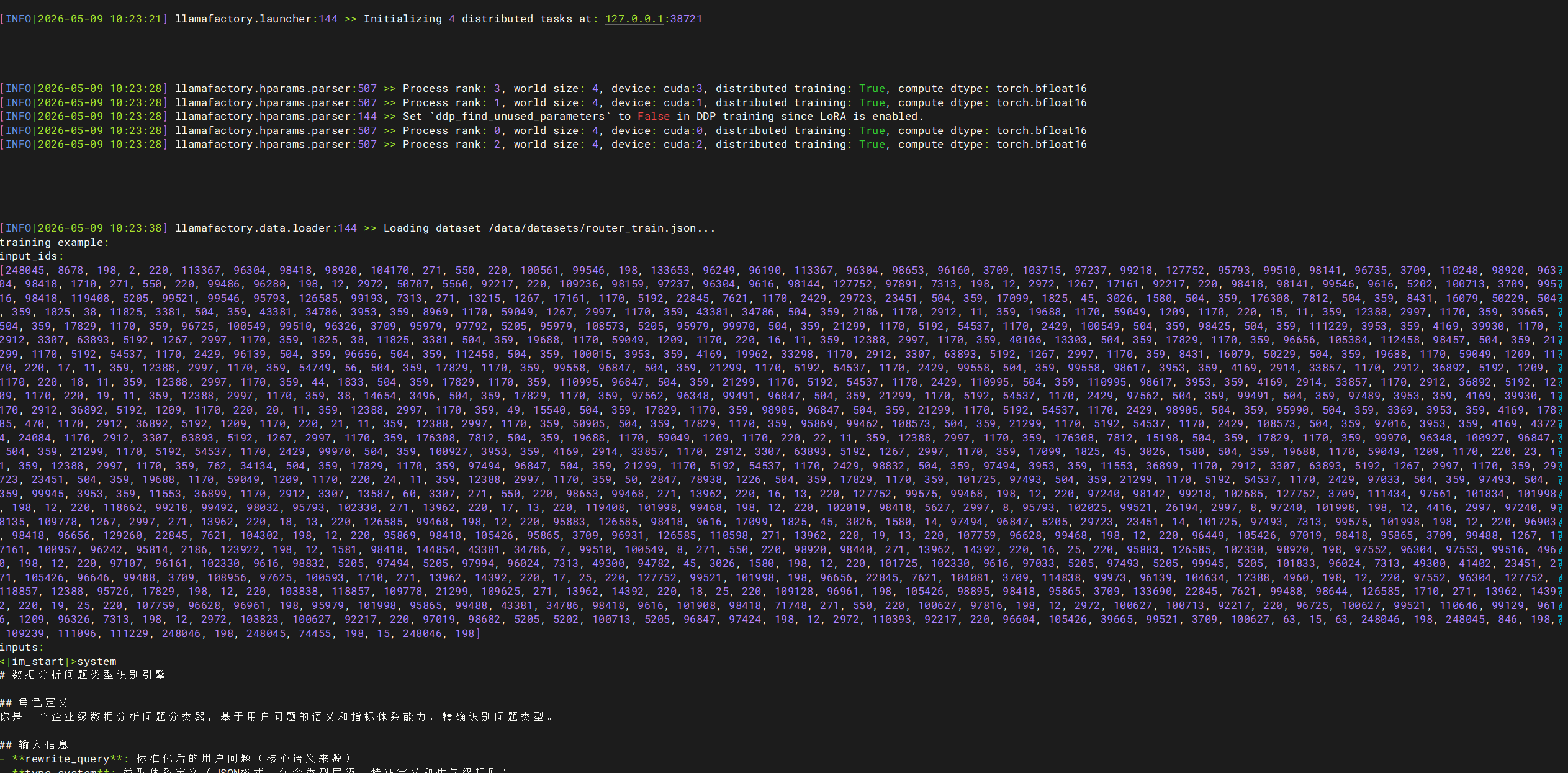
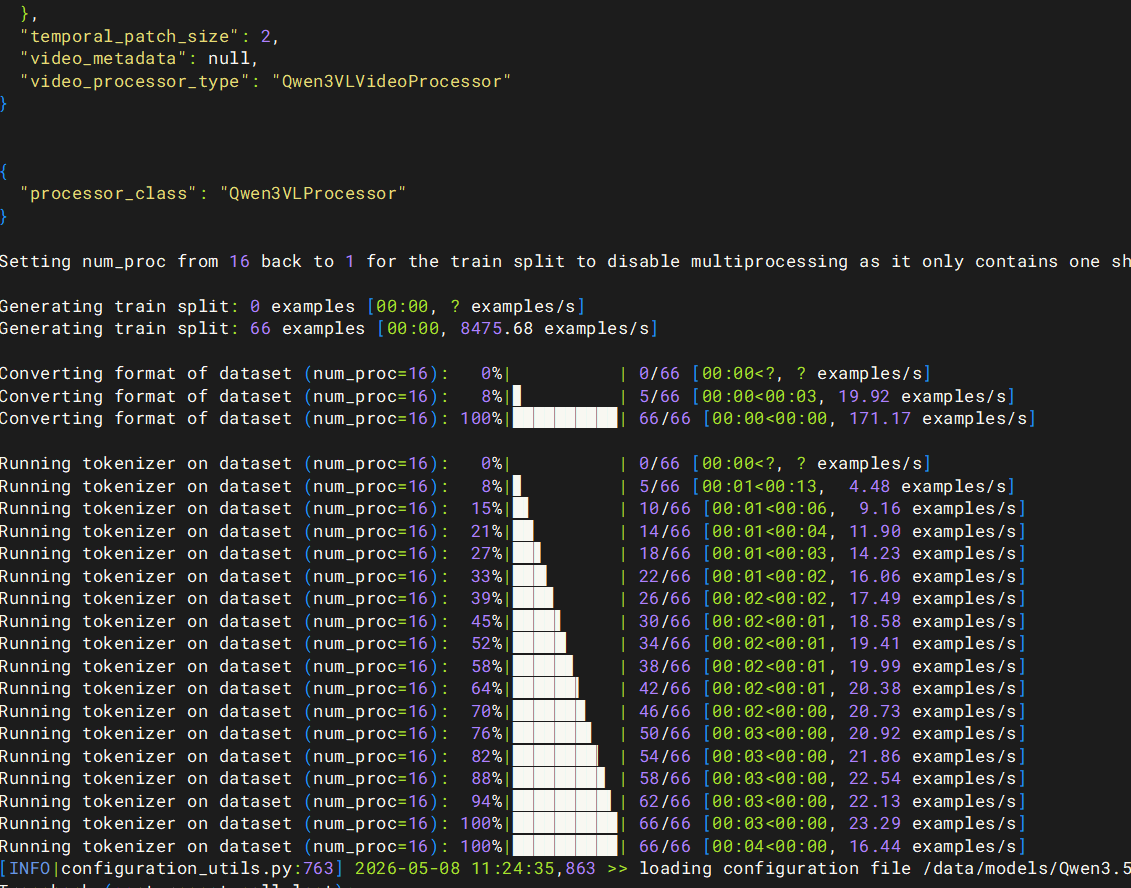
# 训练过程
# 测试
点击chat、使用huggerface加载模型(这个版本的vllm要求是0.14-0.17,我的不在所以用hf了),在【检查点路径】选择刚才训练好的Lora,加载模型,成功后先使用训练的系统提示词和你准备的测试问题进行测试看,同步可以减少系统提示词进行测试

三、报错信息
1.模版不匹配【按照chat模版填写】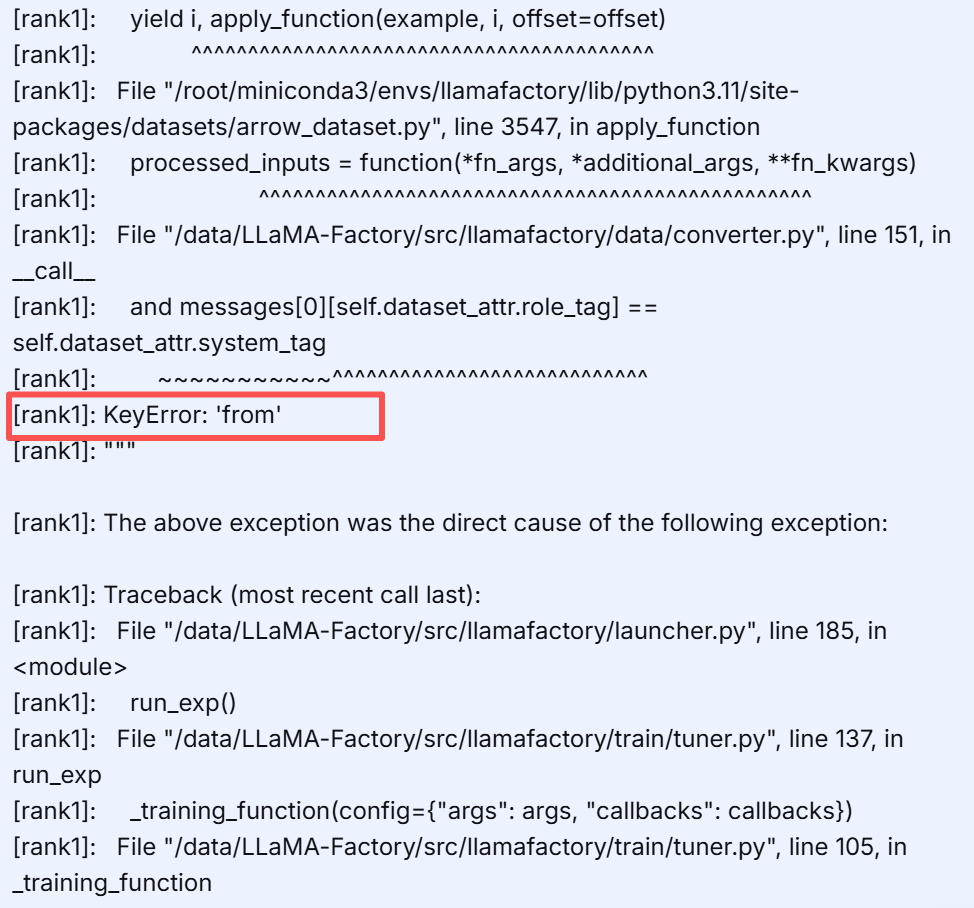
四、VLLM中使用
在启动VLLM时加入
--enable-lora \
--lora-modules question-type=Lora路径
调用时
curl http://localhost:9001/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "question-type",
"messages": [{"role": "user", "content": "xxxx"}]
}'

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)