YOLO26: 摄像头秒变“透视眼“,AI 一眼看穿每个关节,本地就能跑!
关键词:YOLO26 · 姿态估计 · 关键点检测 · 边缘计算 · 实时推理 · 免费开源
你的动作,AI 比你更清楚
健身镜纠正你的深蹲姿势,游戏体感捕捉你的挥拳动作,医疗康复系统记录患者每一次关节活动——这些场景背后,都藏着同一项技术:人体姿态估计(Pose Estimation)。
通俗来说,就是让 AI 盯着摄像头画面,实时找出你身上 17 个关键点——鼻子、双肩、双肘、双腕、双髋、双膝、双踝——然后把它们连成一幅"活的骨架图",描述你此刻的每一个姿态。
这件事听起来简单,但要做到实时、准确、还能跑在没有独显的普通电脑甚至手机芯片上,就非常考验技术了。

YOLO26,完全免费开源。其中的姿态估计版本 YOLO26-pose,几行 Python 代码就能跑起来,普通笔记本也能实时推理,堪称目前最易用的姿态识别方案之一。
它和之前的 YOLO 有什么不一样?
YOLO 系列大家可能都听说过,每隔一段时间就会出新版本。但 YOLO26 这一代,做了几件很不一样的事。
① 去掉了一个"老大难"步骤,推理延迟直接确定了
过去所有目标检测模型,输出结果前都要跑一步叫 NMS(非极大值抑制) 的后处理——简单说就是把重叠的框过滤掉,只留最好的那一个。听起来没什么,但这一步会带来不可预测的额外延迟,在边缘设备(比如树莓派、工业相机)上尤其要命。
YOLO26 直接把 NMS 从流程里删掉了。一次前向传播,直接出结果,干净利落。对开发者来说,部署时少了一个需要调参的环节,延迟也变得完全可预测。
② 关键点定位更聪明:会"承认自己不确定"
这是 YOLO26-pose 最有意思的创新。
以前的关键点检测,模型给出的是一个固定坐标——"你的肘关节在这个像素"。但现实很复杂:人被遮挡了、光线很差、动作太快……这些情况下模型其实并不"确定"关节在哪,强行给一个坐标反而引入误差。
YOLO26-pose 引入了 RLE(残差对数似然估计),换了个思路:不直接预测坐标,而是对关键点的空间分布建模。遮挡越严重,预测范围越分散;目标清晰时,预测就非常集中。这样在复杂场景下反而更准。
③ CPU 推理速度提升约 43%,没有 GPU 也能用
对比上一代 YOLOv8-pose 和 YOLO11-pose,YOLO26-pose 在 CPU 上的推理速度提升幅度约 43%。这意味着就算你的电脑没有独立显卡,一样可以流畅运行实时姿态识别。
性能数据:从超轻量到超高精
YOLO26-pose 提供五个版本,覆盖从树莓派到服务器的全场景需求:
|
模型 |
参数量 |
mAP(姿态) |
CPU 延迟 |
T4 GPU 延迟 |
|
YOLO26n-pose(最轻) |
2.9M |
57.2 |
40.3ms |
1.8ms |
|
YOLO26s-pose |
10.4M |
63.0 |
85.3ms |
2.7ms |
|
YOLO26m-pose |
21.5M |
68.8 |
218ms |
5.0ms |
|
YOLO26l-pose |
25.9M |
70.4 |
275ms |
6.5ms |
|
YOLO26x-pose(最强) |
57.6M |
71.6 |
565ms |
12.2ms |
测试数据来自 COCO Keypoints val2017 数据集,输入分辨率 640×640。
重点看 Nano 版本:参数量仅 290 万,在 T4 GPU 上每帧只需 1.8 毫秒,实时摄像头应用完全不是问题。如果你只是想在自己电脑上跑跑看,Nano 或 Small 版本就够了。
三行代码,跑起来
安装只需一条命令:
pip install ultralytics对图片推理,展示骨架:from ultralytics import YOLOmodel = YOLO("yolo26n-pose.pt") # 自动下载预训练模型results = model("your_image.jpg")results[0].show() # 弹窗显示带骨架的图片视频流同样支持,逐帧处理、实时输出:results = model("your_video.mp4", stream=True)for r in results:r.show()
就这些。模型权重会自动下载,不需要手动配置任何东西。

实际测了 6 种场景,效果怎么样?
光看数据不够直观,下面是用 Nano 版本(最轻量)在真实视频上的测试结果:
健身房:深蹲、推举、举重
骨骼模型能清晰捕捉站姿和体态,左右对称性、关节角度、动作幅度一目了然。对健身 App 和私人教练工具来说,这个效果完全够用。

运动对抗:快速动作 + 身体遮挡
运动场景是姿态估计里最难处理的——动作快、姿态非标准、队员互相遮挡、还有球和球网挡住视线。
测试结果:两位主要运动员的骨骼都被捕捉到了,但当两人身体高度重叠时,防守队员的下半身骨架出现了少量线条缠绕;站在围栏后面的背景人物没有被检测到。这是单阶段检测器在密集遮挡场景下的预期局限,实际部署时需要注意。
舞蹈:大幅度、高速度的全身运动
大幅摆臂、快速旋转、全身协调——YOLO26 单阶段推理的速度优势在这里体现得最明显,不会因为动作太快而"跟丢"骨架。
跳跃:从蹲伏到起跳到落地的完整序列
直立帧里骨架追踪非常稳定。有一个小问题:在身体完全倒置的瞬间(比如空翻),检测效果会下降——因为训练数据里这种姿势出现得很少。不过实际应用中,加一个简单的时序平滑就能弥补这几帧的缺失。
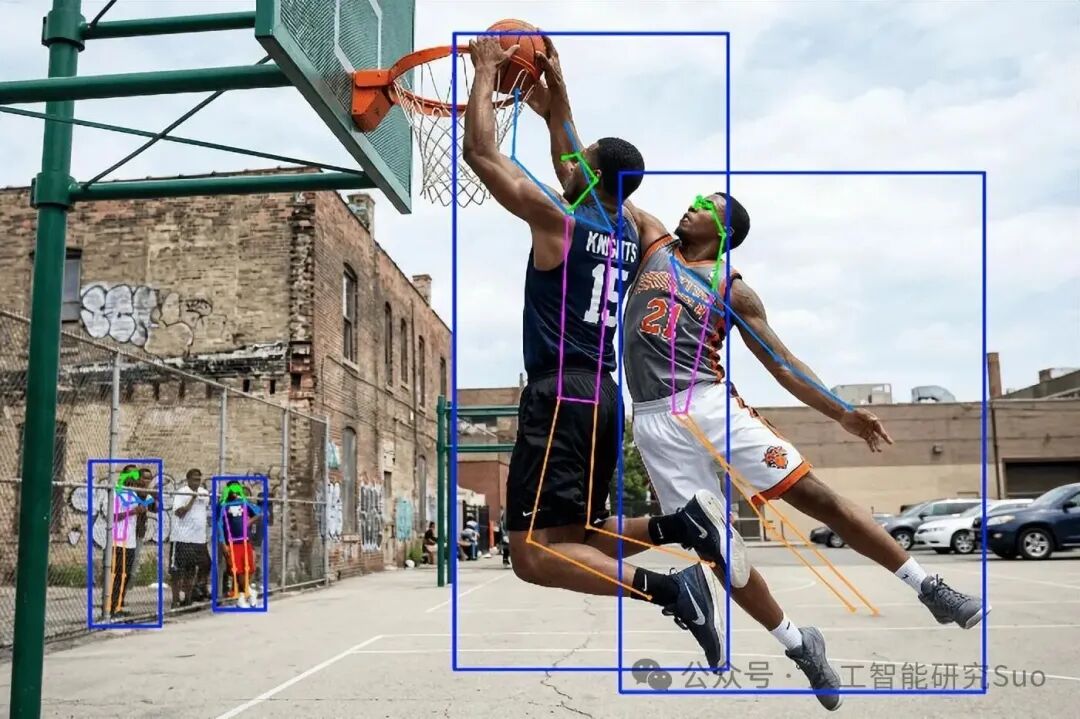
跑酷:移动镜头 + 多人 + 跳跃
这是难度最高的场景:镜头在动、画面里两个人、景深差异大、还有空中飞跃的瞬间。结果:视频大部分时间两个人的骨架都正确对应,关节位置稳定,即使运动员在空中也没有出现骨架"跳人"的情况。
瑜伽:多人 + 边界框辅助
两位练习者在画面中靠得很近,做站立和平衡类姿势。带上边界框显示后,能清楚看到每个骨架属于哪个人,即使两人靠近,骨架也始终正确归属,没有出现"张冠李戴"。
能用来做什么?
说了这么多,YOLO26-pose 到底能拿来做什么实际的东西?
- 健身 App / AI 私教
:实时检测动作标准性,统计重复次数,给出纠错反馈
- 运动员训练分析
:追踪关节角度,量化板球、棒球、游泳等项目的技术动作
- 医疗康复
:测量患者关节活动范围,记录随时间的康复进展
- 体感游戏 / AR 互助
:手势和肢体控制,低延迟是核心需求
- 安防预警
:检测跌倒、异常姿势、危险行为
- 动作捕捉 / 动画制作
:用关键点数据驱动 3D 角色动画,比传统 marker 方案便宜得多

YOLO 系列的"减法哲学"
YOLO26 这一代的核心逻辑,其实是在做减法——
去掉 NMS,去掉 DFL,去掉那些在边缘设备上"拖后腿"的模块;然后用 RLE 提升关键点精度,用 MuSGD 优化器稳定训练,用 STAL 改善小目标识别。
减掉的是复杂度,留下的是速度和确定性。
对于普通开发者和独立创作者来说,这意味着:不需要高配服务器,不需要写复杂的后处理代码,pip 一条命令装好,几行代码就能把姿态识别集成进自己的项目里。
T4 GPU 每帧 1.8 毫秒、CPU 也能跑、完全免费开源——YOLO26-pose 目前是实时人体姿态估计领域里门槛最低、性价比最高的选择之一,值得每一个对计算机视觉感兴趣的人试一试。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)