从底层逻辑了解AI
目录
1.3 市面上主流大模型盘点:GPT、Claude、Gemini到底区别在哪?
3.2 另一个概念:Context Window(上下文窗口)
前言:写给完全不懂技术的普通人
现在打开手机、电脑,随处可见AI:聊天机器人、AI绘图、自动写文案、智能办公助手、自动化工作流……所有人都在喊AI,网上充斥着各种专业名词:LLM、Token、Context、Agent、MCP、微调、提示词。
绝大多数人只会单纯使用AI工具,只知道“输入文字、AI给出答案”,却永远搞不懂AI到底怎么思考、为什么能听懂人话、为什么会胡说八道、为什么有上下文限制。
本篇博客,我会从最底层、最基础的名词开始,拆解当下所有主流AI技术。看完后,你将能彻底看透AI底层逻辑。
一.LLM
1.1 到底什么是LLM?
LLM(Large Language Model,大语言模型):一个学习了海量人类文字,会按人类语言逻辑,自动预测下一个字的超级神经网络。
抛开所有复杂概念,所有大模型(GPT、Claude、Gemini、通义千问、文心一言),本质只做一件事:根据上文,猜下一个最合理的字。
举个最简单的例子:
你输入:今天天气很___
正常人下意识会填:好、差、冷、热。
LLM的工作逻辑一模一样:它不会像人类一样“理解”这句话的含义,只会凭借海量学习数据,计算出下一个字的出现概率,概率最高的字,就是它输出的答案。
有一部分人对AI有一个错误的认知:AI有思想、有智商、能自主思考、拥有意识。但是实际上,AI没有意识、没有情绪、不会主动思考,它只是一台极致擅长接龙的概率机器。
你看到的流畅对话、逻辑文案、深度分析,全部是它一字一字、按概率逐字拼接出来的结果。
1.2 LLM的灵魂:Transformer
搞懂LLM,必须先理解Transformer。它是现代AI的基石,没有Transformer,就没有如今的大模型时代。
1.2.1 Transformer是什么?
2017年,谷歌发布一篇名为《Attention Is All You Need》的论文,推出了Transformer架构。这是近十年人工智能领域最重要、最伟大的发明,没有之一。
Transformer是一套特殊的神经网络结构,专门用来处理文字序列,核心能力是看清全文、判断文字之间的关联。
1.2.2 为什么它能碾压旧技术?
在Transformer诞生前,老式AI读句子只能从左到右逐个读取,读完后面忘了前面,无法捕捉长距离文字关系。比如句子:“小明把雨伞借给了小红,因为她淋雨了”,老式AI分不清“她”指代谁。
而Transformer搭载了自注意力机制,可以做到以下三点:首先,在一句话里,任意两个字、词互相建立关联;其次,自动判断词语权重,分清主次关系;最后,远距离文字也能精准联动,不会丢失信息。
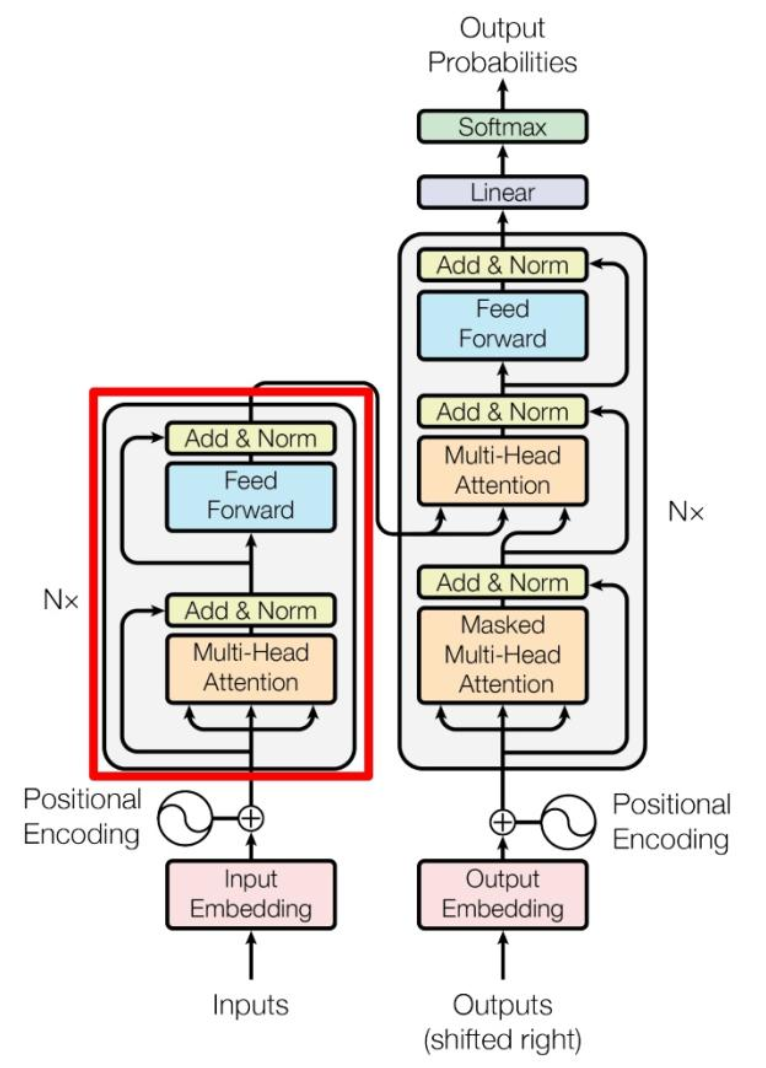
1.2.3 拆解Transformer核心结构
Transformer可以拆解为以下几个部分:
① 编码器(Encoder):读懂
作用:完整理解输入内容,吃透语义、语法、逻辑,常见于翻译、分类类模型。
② 解码器(Decoder):生成
作用:按逻辑逐字生成文字,我们日常聊天、写文案、问答的AI,全部只用解码器架构。
③ 自注意力机制:核心大脑
它会给句子里每个词打分,判断关联紧密程度。例如句子:猫咪趴在窗台晒太阳,它很舒服。机制会精准判定“它”高度关联“猫咪”,和窗台、太阳无关联,这就是AI读懂指代的底层逻辑。
④ 位置编码:分清语序
Transformer本身无法识别文字顺序,位置编码会给每个字标注位置编号,让AI分清“我打他”和“他打我”的区别。
1.2.4 Transformer架构图
1.3 市面上主流大模型盘点:GPT、Claude、Gemini到底区别在哪?
了解完底层架构,我们盘点市面上最火的大模型,理清它们的定位、优缺点。
1.3.1 绝对鼻祖:OpenAI GPT系列
GPT是全世界第一个普及、商业化成功的大语言模型,也是所有AI行业的领路人。
它的底层逻辑极简纯粹:只用Transformer解码器,专注文字生成,不搞复杂多余结构。每一代都在扩大参数、优化训练数据、强化逻辑推理。GPT系列的优势极其明显,它是通用能力天花板,逻辑推理、创意生成、代码编写、多语言处理能力均衡强悍,生态最完善,适配绝大多数AI工具。但同时,对比市面上的其他AI,它的上下文窗口中等,超长文本处理成本偏高,偶尔也会出现幻觉,但是,随着GPT系列的更新,它的严谨程度也越来越高了。
1.3.2 严谨学霸:Anthropic Claude
Claude主打安全、严谨、超长上下文,是职场办公、资料分析的首选模型。
它有以下几个特点,上下文窗口极大,可一次性读取几十万字文档、整本书籍;幻觉概率偏低;合规性强,价值观端正,拒绝违规内容的判定更严格。但是,它的创意发散能力弱于GPT,脑洞、趣味创作、灵活改写表现一般。
1.3.3 图像黑马:Google Gemini
谷歌作为Transformer的发明者,Gemini是其巅峰力作,主打多模态全能。
它的优势主要体现在这几点:图文音视频全能解析,识图、解析图表、识别视频内容能力顶尖;数学、理科、逻辑推理硬核强悍,专业学术能力突出;免费版能力出色,性价比高。但是,它的对话流畅度、人性化语感略逊于GPT,中文本土化优化稍弱,且在使用的过程中,出现幻觉的情况较多。
1.3.4 国产主流模型
国内所有大模型均基于Transformer架构二次开发,适配中文语境:
阿里通义千问在办公、文案、中文理解优化出色;百度文心一言在本土化知识、实时资讯适配性强;DeepSeek的代码能力强悍,开源免费,适合技术开发者;而我们日常使用最多的豆包,极致轻量化,通俗易懂,贴合普通人日常使用。
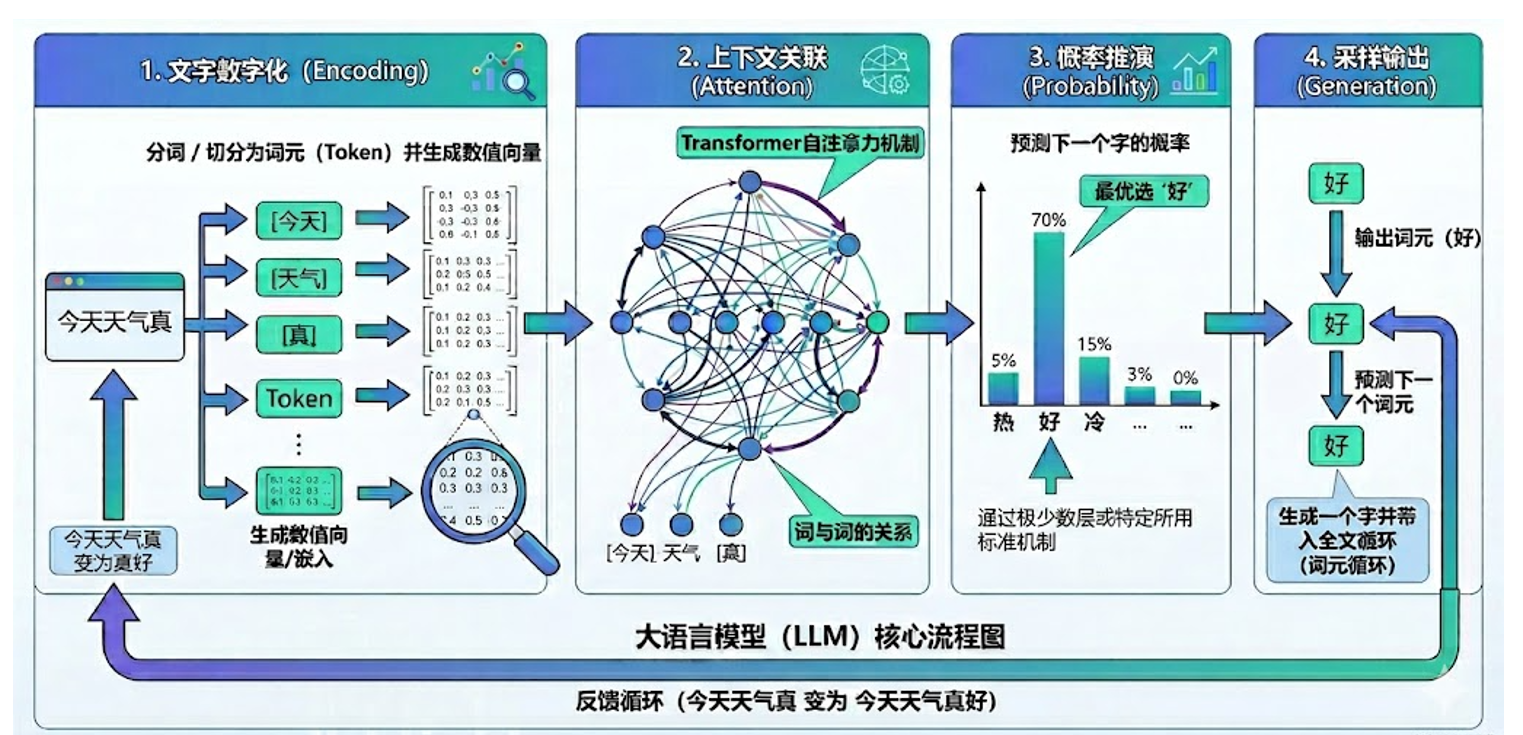
1.4 大模型完整工作流程
当你输入一句话后,AI到底经历了什么?一下这张流程图,将会讲明清楚ai所做的一切。
1.5 LLM关键特性
首先,AI是天生概率主义,必然存在幻觉。AI只会预判概率,不会辨别真假。遇到陌生知识,它会强行编造通顺答案,这就是AI幻觉,逻辑越通顺,不代表内容越真实。其次,AI上下文有限,存在记忆上限。每款模型都有固定上下文窗口,超出字数后,AI会遗忘前文内容,出现逻辑断裂。再者,AI训练数据有时间截止线。模型训练数据停留在固定时间,无联网能力时,无法获取截止时间后的新鲜资讯,这就是基础模型不懂实时新闻的原因。最后,也是最重要的是,AI没有自主意识,被动响应指令。它不会主动思考、不会拥有情绪、不会产生想法,你的提示词(Prompt)就是它的唯一行动指令,提示词质量直接决定回答质量。
二. Token
当迈过了LLM的坎,明白AI是逐字预判、依靠概率生成回答之后,人们一般都会卡在第二个核心疑问上:
AI的本质是神经网络,只会冰冷的数学矩阵运算,它看不懂汉字、英文,也识别不了标点。那我们输入的人类文字,究竟是怎么塞进模型里运算的?
想要解开这个疑问,就必须弄懂决定AI计费、记忆能力的核心根源——Token。
一下这个流程,是Token的核心流程:
人类文字 → 机器切分 → Token碎片 → Token ID编号 → 数字向量 → 送入模型 → 矩阵运算 → 解码还原文字
2.1 认知误区:Token = 汉字
Token的定义是这样的:它是大模型能够识别、处理的最小文本单元。Token不是单个汉字、也不是完整词语,它是机器按照规则切分出来的“文字最小碎片”。它的组成形式十分灵活,没有固定规则。在英文里,它可以是一个完整单词、单词后缀、词根;在中文里,它可以是一个汉字、两个连在一起的常用汉字;此外,在特殊符号中,标点、空格、emoji、换行,也要全部单独算作Token。
接下来,我们来举一个通俗的例子:我爱吃苹果。
站在人类视角,我们认字是独立拆分:我、爱、吃、苹、果
站在AI视角,机器会按高频用词习惯拆分:我爱、吃、苹果
这就是人和AI最核心的文字认知区别:人类以“字”为基础单位,AI以“Token碎片”为基础单位。
2.2 Tokenizer(AI专属翻译官)
既然AI天生看不懂人类文字,只能识别运算数字,就需要一个专属中间工具,搭建人和AI的沟通桥梁,这个关键工具就是 Tokenizer(分词器),它是一个AI的专属翻译官。
Tokenizer唯一工作职责极其简单,终生只负责两件事,构成AI输入输出的完整闭环:
-
编码(Encode):拆解人类文字、切割为Token碎片,最终映射为专属数字编号(Token ID)
-
解码(Decode):接收模型输出的数字编号,还原拼接为Token,最终转化为人类可读的文字
用一下一句话举例:今天天气很好,下图是它的工作流程:
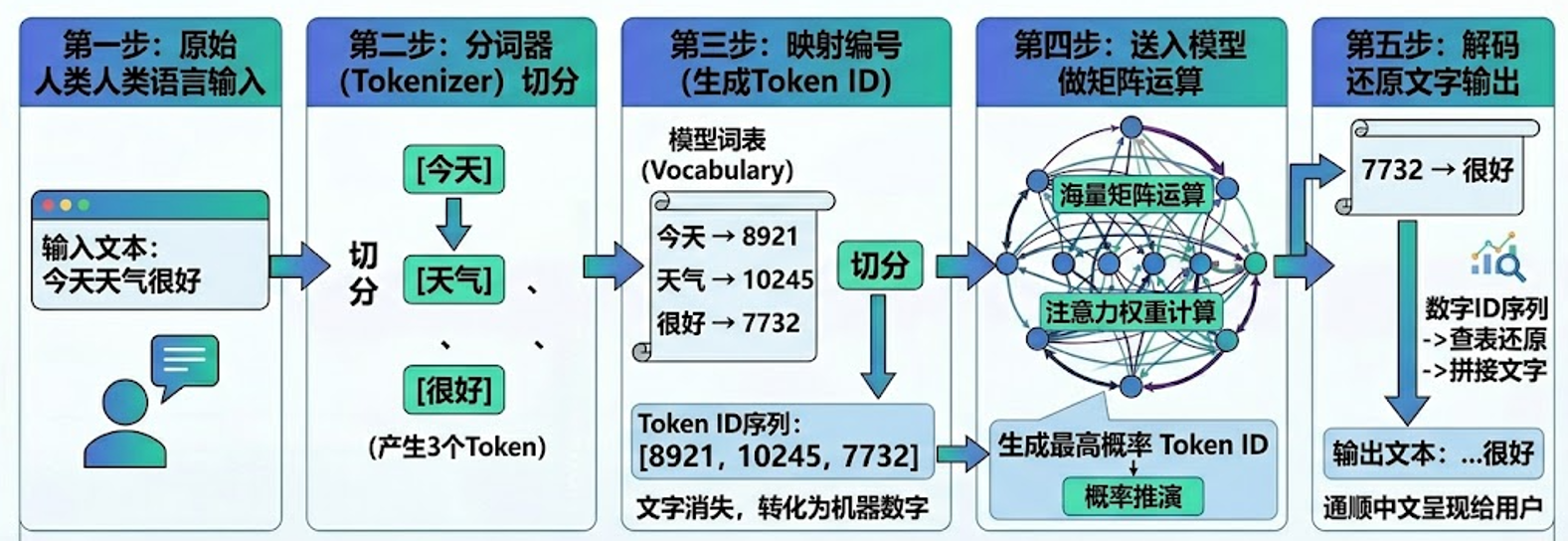
2.3 为什么中文的token更贵?
在日常的使用中,我们会发现,同样是用token,中文竟然比英文贵。其实,原因就在这里;英文语境下,平均4个字符≈1个Token,而在中文环境下,1-2个汉字≈1个Token。中文分词密度更低、拆分成本更高,同等字数下中文消耗的Token远多于英文,这也是国内用户使用海外大模型计费更贵的核心原因。
一个AI,哪怕模型参数再庞大、算力再强悍,没有Tokenizer做翻译拆解,它就只是一堆无法识别文字的无用矩阵。Tokenizer是AI的唯一文字入口,没有分词拆分,就没有AI的一切交互能力。
三. Context
AI为什么能记住你上一句话?为什么聊天久了它会突然忘事?为什么上传超长文档会错乱?这一切,全部由今天这个词决定——Context(上下文)。
3.1 什么是Context?
准确来讲,Context就是AI当下这一轮任务里,能看见、能记住、能读取的全部信息总和。
对了,不要只以为它只保存聊天记录,完整Context包含以下四类信息:
-
历史对话:你们之前所有聊天、提问、回答;
-
当前输入:你此刻发的这句话、这段文字;
-
工具列表:AI可调用的工具、功能、权限;
-
任务指令:你给AI的角色、要求、规则、限制。
只要进入Context,AI就能看见;一旦超出Context,AI彻底看不见、记不住。
3.2 另一个概念:Context Window(上下文窗口)
Context Window是指AI内存条的最大容量,单位是Token。每一个大模型,都有固定的内存上限。你所有的聊天、文档、指令、历史记录,全部都会转换成Token塞进窗口里。塞满之后,最先进去的内容直接被丢弃,AI永久遗忘。
同时,上下文窗口有一个公式:上下文窗口 = 输入Token + 输出Token 总和上限。
3.3 2026主流大模型上下文窗口数据
GPT-5.5 (OpenAI):105万;
Claude Opus 4.7 (Anthropic):100万;
Gemini 3.1 Pro (Google):100万
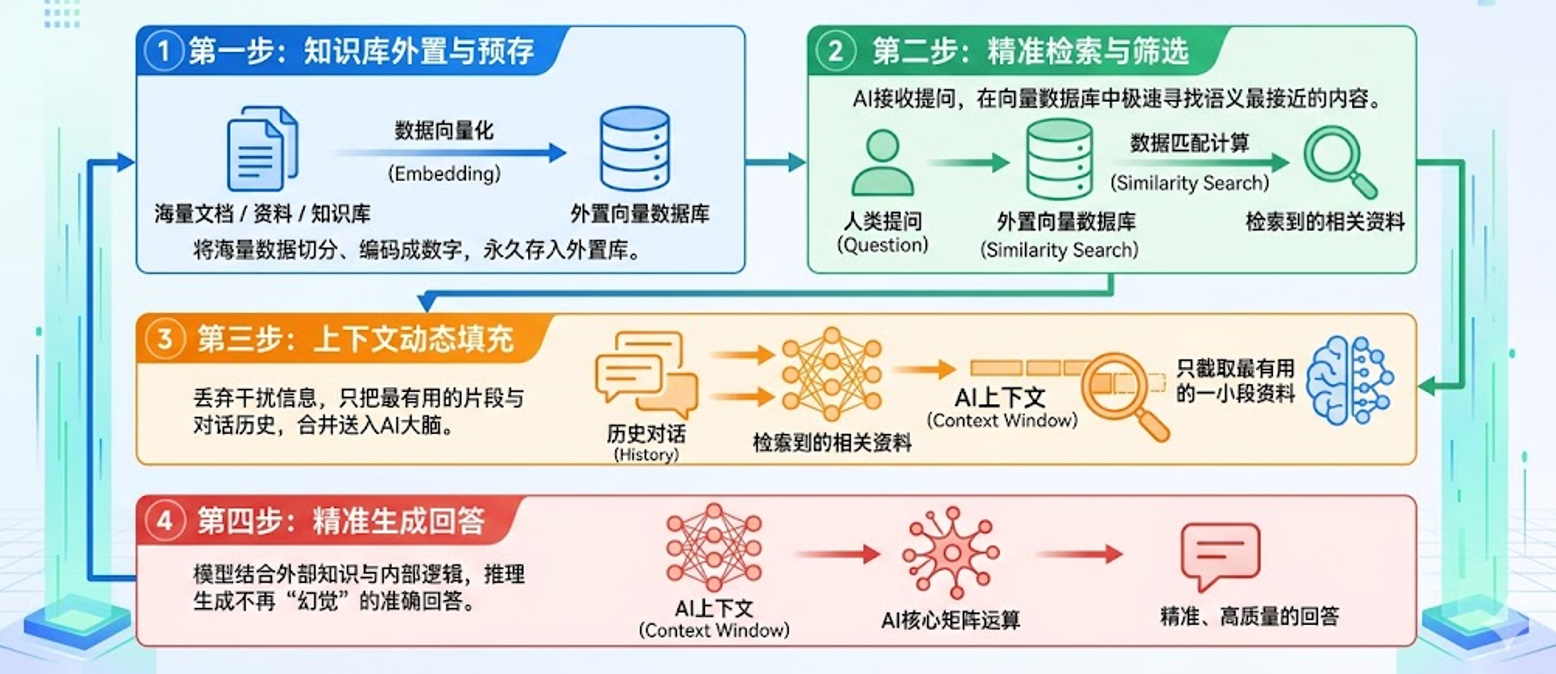
3.4 RAG 如何解决 Context 上限问题?
哪怕是GPT-5.5的105万Token窗口,依然存在物理上限,不可能无限装下数据。想要突破临时内存限制,就必须用到现在全网爆火的RAG(检索增强生成)。
RAG:外置知识库
Context是临时内存条,塞满就丢;RAG是外置储存盘,数据永久保存,不会占用上下文窗口额度。以下一张图可以直观的展现它的工作原理:
四. Prompt
一台只会算数字、只有短期内存的AI,凭什么听话?凭什么做出不同风格、不同质量的回答?答案只有一个:Prompt(提示词)
4.1 Prompt是什么?
Prompt是人类丢给大模型的一切指令文本,是人和AI唯一的沟通语言。写好Prompt不需要文采,只需要做到六个字:具体、清晰、明确。
4.2 Prompt的分类
第一种:System Prompt(系统提示词)。它是后台隐形指令,你看不到,但是优先级最高。
System Prompt相当于给AI定人设、定底线、定做事规则。在聊天开始前,就被写入Context,永久生效。官方出厂限制、自定义角色、禁止违规回答、回答语气、思维方式,全部由它管控。比如,你让AI做专业顾问、禁止编造信息、说话通俗易懂、严禁废话,这些底层约束,全部写在System Prompt里。它藏在后台,不会显示在聊天界面,却从头到尾霸占内存,约束AI所有行为。
第二种:User Prompt(用户提示词)。就是你手动输入的每一句话。
你日常的提问、要求、文案生成、修改指令,全部属于User Prompt。它是动态的、实时的,每发送一次,就追加进Context上下文。我们普通人平时打字输入的内容,全部都是User Prompt。
五.tool
原生大模型是封闭的,它看不见外界、连实时信息都获取不到。它的训练数据有截止时间,无法联网、无法查询、无法实操、无法获取外部数据。想要打破限制,让AI拥有外部能力,就必须依靠——Tool(工具)。
5.1 Tool:一个可被调用的固定函数
很多人把工具想的很复杂,其实Tool本质就是提前写好的函数。它没有思维、没有判断、不会自主运行,本身没有任何智能,唯一作用就是给大模型提供它本身不具备的外部能力。比如天气查询、实时搜索、代码运行、文件解析、计算表格,全部都是最简单的工具函数。原生LLM只能靠旧数据推理,搭配Tool之后,AI才能触碰真实外界。
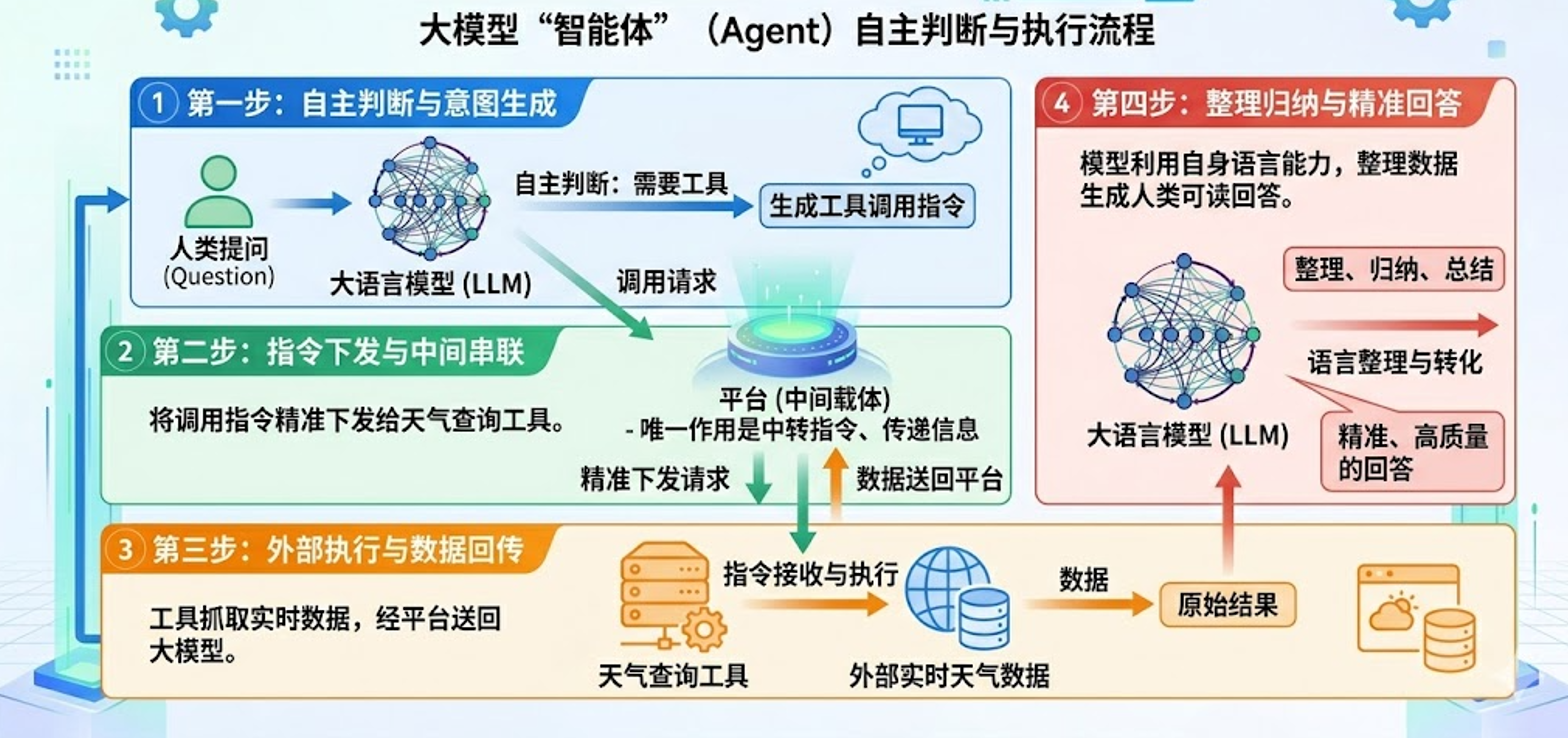
5.2 完整工具调用
一个完整的调用过程是这样的:用户提问→大模型选工具→平台中转→工具执行→数据回传→模型总结输出
用最简单的天气查询案例,一次性讲透完整流转流程,全程只有四个参与角色:用户、大模型、工具、平台。我将用以下的流程图来完整的概述整个过程:
六. MCP
每一家大模型平台,工具接入大模型的标准全部不一样。OpenAI一套格式、Anthropic一套格式、Google又是另一套格式。你写一个天气工具、文档工具,想要换一个模型使用,就要重新改写代码、适配新规范,重复劳动、极度繁琐。工具无法通用、接口互不兼容,这就是AI行业碎片化乱象。
为了解决这个问题,全网现在爆火的MCP 应运而生。
6.1 MCP是什么?
MCP(Model Context Protocol,模型上下文协议),AI行业统一通用接口标准。
它由Claude母公司Anthropic在2024年11月开源推出,它可以理解为AI界的USB-C通用接口。以前安卓、苹果、充电口各不相同,现在统一Type-C;以前GPT、Claude、谷歌工具接口各不相同,现在统一MCP。
MCP唯一目的就是把工具接入规则标准化,一套工具,所有大模型通用。
6.2 MCP诞生的原因
在MCP没出现之前,所有平台各自为战,规则封闭。OpenAI有自己的函数调用格式,参数写法、传输逻辑独有;Anthropic Claude格式完全不同;Google Gemini又是另一套交互规范。开发者想要把同一个工具上架到不同AI平台,必须反复改写、反复适配、反复调试,成本极高。工具无法迁移、无法互通、复用率极低。
MCP就是为了打破这种壁垒而生:它制定一套公开、统一、通用的通信协议,不管是什么模型、什么平台,只要遵守MCP规范,工具直接一键接入、直接使用,不用二次改写。
6.3 MCP在干什么?
没有MCP的时候,工具必须适配平台,平台格式卡住工具,换模型就要重做工具。当有了MCP后,工具按照MCP标准编写,MCP充当中间翻译层,统一对接所有大模型平台。不管是GPT、Claude还是Gemini,全部识别同一套工具语言,不需要额外改造。它不生产工具、不产生智能、不修改模型,只做一件事:统一规则、打通壁垒、兼容所有平台。
七. Agent与Agent Skills
Agent 和 Agent Skills 是什么,他们到底差在哪里?总结下来,Agent是会自主干活的人,Agent Skills是提前写好、存在硬盘里的工作手册。一个是活体智能体,一个是固化文档。
7.1 Agent:拥有自主执行能力的智能个体
普通大模型永远被动,人发一句、它回一句,不会主动行动。而Agent(智能体) 最大的区别就是拥有自主性。它可以接收用户一个笼统任务,依靠自身LLM大脑自主规划步骤,主动判断需要哪些工具,并且能够多次、反复调用工具。不会因为一次调用失败就停止,也不会因为信息不足就胡乱回答,它会持续调取资源、反复校验,直到完整达成用户任务才结束流程。
市面上目前比较热门且强大的三款Agent,Claude Code、Codex、Gemini CLI。Claude Code偏向大型工程项目自主开发,Codex主打轻量化代码编写调试,Gemini CLI专注服务器终端自动化运维,三者全部具备无人工干预、循环调用、自主纠错的能力。
7.2 Agent Skills:存在硬盘里的固化技能文档
很多人误以为Skills是AI自己学会的能力,这是严重误区。Agent Skills 不是天赋,是提前写好的 Markdown 说明文档。它不会动、不会思考、不会执行,只能安静储存在本地硬盘。整体分为两层结构:一层是原数据层,存放原始参考资料、素材、基础数据;另一层是指令层,写死执行规范、流程要求、做事逻辑。
你可以把它理解为给Agent准备好的工作SOP手册。Agent本身智商有限,提前给它存入结构化文档,它在需要的时候读取硬盘、加载技能、按照固定流程执行任务。没有Skills文档,Agent只能靠原生大脑思考;加载Skills文档,它就能熟练执行定制化复杂工作。
7.3 智能体 + 固化技能 = 完整AI
Agent是执行主体,负责自主规划、反复调用工具、完成闭环任务;Agent Skills是外置静态文档,保存在硬盘,给Agent提供固定流程、规范、原始数据。
单纯的Agent聪明但是没有流程,容易逻辑乱跑;单纯的Skills文档只是一堆死文字,无法自己运行。当Agent读取硬盘载入Skills文档,动态自主能力 + 静态固化流程结合,才是现在行业主流的高级智能体架构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)