RNN案例之:人名分类器
目录
一、需求分析
1、背景
-
关于人名分类问题:
以一个人名为输入, 使用模型帮助我们判断它最有可能是来自哪一个国家的人名, 这在某些国际化公司的业务中具有重要意义, 在用户注册过程中, 会根据用户填写的名字直接给他分配可能的国家或地区选项, 以及该国家或地区的国旗, 限制手机号码位数等等.
-
人名分类数据预览
-
数据存放路径:$(home)/data/name_classfication.txt
- 数据格式说明 每一行第一个单词为人名,第二个单词为国家名。中间用制表符tab分割
2、数据说明
- 数据格式说明 每一行第一个单词为人名,第二个单词为国家名。中间用制表符tab分割
Huffmann German
Hummel German
Hummel German
Hutmacher German
Ingersleben German
Jaeger German
Jager German
Deng Chinese
Ding Chinese
Dong Chinese
Dou Chinese
Duan Chinese
Eng Chinese
Fan Chinese
Fei Chinese
Abaimov Russian
Abakeliya Russian
Abakovsky Russian
Abakshin Russian
Abakumoff Russian
Abakumov Russian
Abakumtsev Russian
Abakushin Russian
Abalakin Russian
二、整体步骤
整个案例的实现可分为以下五个步骤
- ✅第一步导入必备的工具包
- ✅第二步对data文件中的数据进行处理,满足训练要求
- ✅第三步构建RNN模型(包括传统RNN, LSTM以及GRU)
- ✅第四步构建训练函数并进行训练
- ✅第五步构建预测函数并进行预测
三、代码实现
1、导入必备的包
# 导包
import torch # 张量计算相关
import torch.nn as nn # 神经网络模块, 各种模型的层, 组件...
import torch.nn.functional as F # 常用的函数库...
import torch.optim as optim # 优化器模块
from torch.utils.data import Dataset, DataLoader # 数据集对象, 数据加载器
import string # 字符串处理模块.
import time # 时间模块.
import matplotlib.pyplot as plt # 绘图模块.
from tqdm import tqdm # 进度条
# 解决绘图时, 中文乱码问题.
plt.rcParams['font.sans-serif'] = ['SimHei'] # Mac本换成: 'Arial Unicode MS'
plt.rcParams['axes.unicode_minus'] = False2、将数据处理为训练需要的张量
# todo 1. 定义遍历, 获取常用的字符数量.
# 1. 获取所有的常用字符 -> 包括 字母 + 符号
all_letters = string.ascii_letters + " .,;'" # 52个字母(大小写形式) + '空格 点 逗号 分号 单引号'
# 2. 获取常用的字符的数量
n_letters = len(all_letters)
# print('所有常用字符: ', all_letters) # abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'
# print('常用字符数量: ', n_letters) # 57
# todo 2. 定义遍历, 获取常用国家名 种类数 和 个数.
# 1. 国家名 种类数.
categories = ['Italian', 'English', 'Arabic', 'Spanish', 'Scottish', 'Irish', 'Chinese', 'Vietnamese', 'Japanese', 'French', 'Greek', 'Dutch', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Czech', 'German']
# 2. 国家名 个数.
category_num = len(categories)
print('国家名: ', categories)
print('国家名种类数: ', category_num) # 18个国家名
# todo 3. 定义函数, 实现: 读取源数据到内存.
def read_data(file_path):
"""
读取源数据到内存中, 并把 特征(人名) 和 标签(国家) 分别存储到两个列表中.
:param file_path: 源数据文件的路径
:return: my_list_x: 存储的人名(特征), my_list_y: 存储的国家名(标签)
"""
# 1. 创建两个列表, 分别存储: 人名(特征), 国家名(标签)
my_list_x, my_list_y = [], []
# 2. 关联文件, 并读取其内容(逐行读取)
with open(file_path, 'r', encoding='utf-8') as f:
# 3. 遍历, 获取到每一行的数据.
for line in f.readlines():
# 4. 过滤无效数据, 假设(整行的)长度 小于等于5, 就过滤掉. 整行长度 = 人名 + '\t' + 国家名
if len(line) <= 5:
continue
# 5. 走到这里, 说明该行数据是有效数据(即: 行长度 > 5), 处理后, 添加到对应的列表中.
x, y = line.strip().split('\t')
# 6. 添加到对应的列表中.
my_list_x.append(x)
my_list_y.append(y)
# 扩展: 查看下数据集的长度, 即: 判断数据是否正确.
print(f'my_list_x: {len(my_list_x)}') # 20074
print(f'my_list_y: {len(my_list_y)}') # 20074
# 7. 返回解析后的 样本 和 标签.
return my_list_x, my_list_y
# todo 4. 创建数据集对象, 即: 原始数据 -> 数据集对象TensorDataset -> 数据加载器DataLoader
class NameClassDataset(Dataset):
# 1. 初始化函数, 接收: 样本和标签数据, 初始化数据集基本属性.
def __init__(self, my_list_x, my_list_y):
self.my_list_x = my_list_x # 存储样本数据列表
self.my_list_y = my_list_y # 存储标签数据列表
self.sample_len = len(my_list_x) # 计算样本总数并存储, 20074
# 2. 定义函数, 用于获取样本总数. 外界用 len(NameClassDataset对象) 的时候, 自动触发.
def __len__(self):
return self.sample_len
# 3. 定义函数, 实现根据指定索引, 获取其对应的样本.
def __getitem__(self, index):
"""
根据指定的索引, 获取其对应的样本, 并进行 one-hot编码 和 张量转换.
:param index: 样本索引
:return: tensor_x: 人名(特征)的one-hot编码, tensor_y: 国家(标签)的张量表示
"""
# 1. 索引边界校验, 确保索引在合法范围. [0, self.sample_len - 1]
index = min(max(index, 0), self.sample_len - 1)
# 2. 按照索引获取原始样本 和 标签.
x = self.my_list_x[index] # 例如: Ding -> (4, 57)
y = self.my_list_y[index] # 例如: Chinese -> 18个国家中的某个索引, 例如: 6
# 3. 人名数据转换为 one-hot编码.
# 3.1 生成全0张量
tensor_x = torch.zeros(len(x), n_letters) # 例如: [4, 57]
# 3.2 遍历人名, 获取每个字母, 生成one-hot张量.
for li, letter in enumerate(x):
# 3.2.1 获取字母在 全局字母表中的索引位置, 例如: 字母'D' 在 "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'"中的位置
letter_index = all_letters.find(letter)
# 3.2.2 在对应位置设置为1 -> 即: one-hot编码
tensor_x[li][letter_index] = 1
# 4. 国家数据转换为 张量.
tensor_y = torch.tensor(categories.index(y), dtype=torch.long)
# 5. 返回结果
return tensor_x, tensor_y
# todo 5. 定义函数, 获取数据加载器对象 -> 思路: Tensor -> TensorDataset -> DataLoader
def get_dataloader():
# 1. 读取数据文件, 获取: 样本(人名)列表 和 标签(国家名)列表.
my_list_x, my_list_y = read_data('./data/name_classfication.txt')
# 2. 创建数据集对象
name_class_dataset = NameClassDataset(my_list_x, my_list_y)
# 3. 创建数据加载器对象, 用于批量加载和处理数据.
# 参1: 数据集对象(20074个人名 和 国家名), 参2: 批次大小, 参3: 是否打乱数据(训练集打乱, 测试集不打乱)
my_dataloader = DataLoader(name_class_dataset, batch_size=1, shuffle=True)
# 4. 测试数据加载器, 打印第一批数据(某一个样本的) 形状 和 内容
for x, y in my_dataloader:
print(f'x.shape: {x.shape}, x: {x}') # 人名的张量形状和内容.
print(f'y.shape: {y.shape}, y: {y}') # 国家张量形状和内容.
break # 仅打印第1批次数据, 用于查看, 避免全部输出.
# 5. 优化1: 可以把上述的数据加载器给返回, 后续直接调用.
# return my_dataloader运行结果如下:
3、搭建模型,并且进行训练
🧩 RNN测试
# todo 6. 搭建神经网络模型.
# todo 6.1 搭建RNN网络
class My_RNN(nn.Module):
# 1. 初始化函数: 输入特征维度, 隐藏层维度, 输出维度, 层数.
def __init__(self, input_size, hidden_size, output_size, n_layers=1):
# 1.1 初始化父类成员.
super().__init__()
# 1.2 输出特征维度(对应字母表大小, 即: 57个字符)
self.input_size = input_size
# 1.3 隐藏层维度, 决定模型的表示能力.
self.hidden_size = hidden_size
# 1.4 输出维度(对应国家名数量, 即: 18个国家名)
self.output_size = output_size
# 1.5 层数, 默认为1.
self.n_layers = n_layers
# 1.6 定义RNN层, 接收输入特征 和 输出隐藏状态.
self.rnn = nn.RNN(self.input_size, self.hidden_size, self.n_layers)
# 1.7 定义全连接层, 将RNN的隐藏状态转换成输出.
self.linear = nn.Linear(self.hidden_size, self.output_size)
# 1.8 定义激活函数, 将输出类别 -> 类别的概率分布.
# 大白话解释: 多分类交叉熵损失函数CrossEntropyLoss(新版写法) = NLLLoss损失函数 + LogSoftmax(dim=-1) 旧版写法
self.softmax = nn.LogSoftmax(dim=-1) # 优化2: 如果用CrossEntropyLoss损失函数, 这行代码可以省略不写.
# 2. 前向传播函数.
# 参1: input输入张量, 形状为: [seq_len, input_size] -> [seq_len, batch_size, input_size]
# 参2: hidden(隐藏状态), 形状为: [n_layers, batch_size, hidden_size]
def forward(self, input, hidden):
# 2.1 调整输入张量, 添加: batch_size
input = input.unsqueeze(1)
# 2.2 通过RNN计算.
# output: 所有时间步的隐藏状态 hidden: 最后1个时间步的隐藏状态
output, hn = self.rnn(input, hidden)
# 2.3 提取最后1个时间步的隐藏状态.
tmp_output = output[-1] # 形状为: [batch_size, hidden_size]
# 2.4 通过全连接层, 获取输出.
tmp_output = self.linear(tmp_output)
# 2.5 数据通过激活函数, 映射到概率分布, 并返回.
return self.softmax(tmp_output), hn
# 3. 初始化隐藏状态, 创建全0的初始化隐藏状态.
def init_hidden(self):
# 参1: 隐藏层层数, 参2: 批次大小, 参3: 隐藏层维度.
return torch.zeros(self.n_layers, 1, self.hidden_size)
# todo 6.2 搭建LSTM网络
class My_LSTM(nn.Module):
# 1. 初始化函数: 输入特征维度, 隐藏层维度, 输出维度, 层数.
def __init__(self, input_size, hidden_size, output_size, n_layers=1):
# 1.1 初始化父类成员.
super().__init__()
# 1.2 输出特征维度(对应字母表大小, 即: 57个字符)
self.input_size = input_size
# 1.3 隐藏层维度, 决定模型的表示能力.
self.hidden_size = hidden_size
# 1.4 输出维度(对应国家名数量, 即: 18个国家名)
self.output_size = output_size
# 1.5 层数, 默认为1.
self.n_layers = n_layers
# 1.6 定义LSTM层, 接收输入特征 和 输出隐藏状态.
self.rnn = nn.LSTM(self.input_size, self.hidden_size, self.n_layers)
# 1.7 定义全连接层, 将RNN的隐藏状态转换成输出.
self.linear = nn.Linear(self.hidden_size, self.output_size)
# 1.8 定义激活函数, 将输出类别 -> 类别的概率分布.
# 大白话解释: 多分类交叉熵损失函数CrossEntropyLoss(新版写法) = NLLLoss损失函数 + LogSoftmax(dim=-1) 旧版写法
self.softmax = nn.LogSoftmax(dim=-1) # 优化2: 如果用CrossEntropyLoss损失函数, 这行代码可以省略不写.
# 2. 前向传播函数.
# 参1: input输入张量, 形状为: [seq_len, input_size] -> [seq_len, batch_size, input_size]
# 参2: hidden(隐藏状态), 形状为: [n_layers, batch_size, hidden_size]
def forward(self, input, hidden, c):
# 2.1 调整输入张量, 添加: batch_size
input = input.unsqueeze(1)
# 2.2 通过LSTM计算.
# output: 所有时间步的隐藏状态 hidden: 最后1个时间步的隐藏状态
output, (hn, cn) = self.rnn(input, (hidden, c))
# 2.3 提取最后1个时间步的隐藏状态.
tmp_output = output[-1] # 形状为: [batch_size, hidden_size]
# 2.4 通过全连接层, 获取输出.
tmp_output = self.linear(tmp_output)
# 2.5 数据通过激活函数, 映射到概率分布, 并返回.
# 返回值1: 预测的类别概率分布, 形状: [batch_size, output_size]
# 返回值2: (最后一个时间步的)隐藏状态张量, 形状: [n_layers, batch_size, hidden_size]
# 返回值3: (最后一个时间步的)细胞状态张量, 形状: [n_layers, batch_size, hidden_size]
return self.softmax(tmp_output), hn, cn
# 3. 初始化隐藏状态, 创建全0的初始化隐藏状态.
def init_hidden(self):
# 参1: 隐藏层层数, 参2: 批次大小, 参3: 隐藏层维度.
hidden = c = torch.zeros(self.n_layers, 1, self.hidden_size)
return hidden, c
# todo 6.3 搭建GRU网络
class My_GRU(nn.Module):
# 1. 初始化函数: 输入特征维度, 隐藏层维度, 输出维度, 层数.
def __init__(self, input_size, hidden_size, output_size, n_layers=1):
# 1.1 初始化父类成员.
super().__init__()
# 1.2 输出特征维度(对应字母表大小, 即: 57个字符)
self.input_size = input_size
# 1.3 隐藏层维度, 决定模型的表示能力.
self.hidden_size = hidden_size
# 1.4 输出维度(对应国家名数量, 即: 18个国家名)
self.output_size = output_size
# 1.5 层数, 默认为1.
self.n_layers = n_layers
# 1.6 定义GRU层, 接收输入特征 和 输出隐藏状态.
self.rnn = nn.GRU(self.input_size, self.hidden_size, self.n_layers)
# 1.7 定义全连接层, 将RNN的隐藏状态转换成输出.
self.linear = nn.Linear(self.hidden_size, self.output_size)
# 1.8 定义激活函数, 将输出类别 -> 类别的概率分布.
# 大白话解释: 多分类交叉熵损失函数CrossEntropyLoss(新版写法) = NLLLoss损失函数 + LogSoftmax(dim=-1) 旧版写法
self.softmax = nn.LogSoftmax(dim=-1) # 优化2: 如果用CrossEntropyLoss损失函数, 这行代码可以省略不写.
# 2. 前向传播函数.
# 参1: input输入张量, 形状为: [seq_len, input_size] -> [seq_len, batch_size, input_size]
# 参2: hidden(隐藏状态), 形状为: [n_layers, batch_size, hidden_size]
def forward(self, input, hidden):
# 2.1 调整输入张量, 添加: batch_size
input = input.unsqueeze(1)
# 2.2 通过RNN计算.
# output: 所有时间步的隐藏状态 hidden: 最后1个时间步的隐藏状态
output, hn = self.rnn(input, hidden)
# 2.3 提取最后1个时间步的隐藏状态.
tmp_output = output[-1] # 形状为: [batch_size, hidden_size]
# 2.4 通过全连接层, 获取输出.
tmp_output = self.linear(tmp_output)
# 2.5 数据通过激活函数, 映射到概率分布, 并返回.
return self.softmax(tmp_output), hn
# 3. 初始化隐藏状态, 创建全0的初始化隐藏状态.
def init_hidden(self):
# 参1: 隐藏层层数, 参2: 批次大小, 参3: 隐藏层维度.
return torch.zeros(self.n_layers, 1, self.hidden_size)
# todo 7. 测试神经网络模型 (了解)
# todo 7.1 测试RNN网络模型
def dm_test_myrnn():
# 1. 实例化RNN对象
my_rnn = My_RNN(57, 128, 18)
# print(f'my_rnn: {my_rnn}') # my_rnn: My_RNN( (rnn): RNN(57, 128) (linear): Linear(in_features=128, out_features=18, bias=True) (softmax): LogSoftmax(dim=-1) )
# 2. 准备测试数据, 创建1个随机张量, 模拟输入, 形状为: [seq_len人名长度, input_size词向量维度]
input = torch.randn(6, 57) # liru: ouyang 欧阳
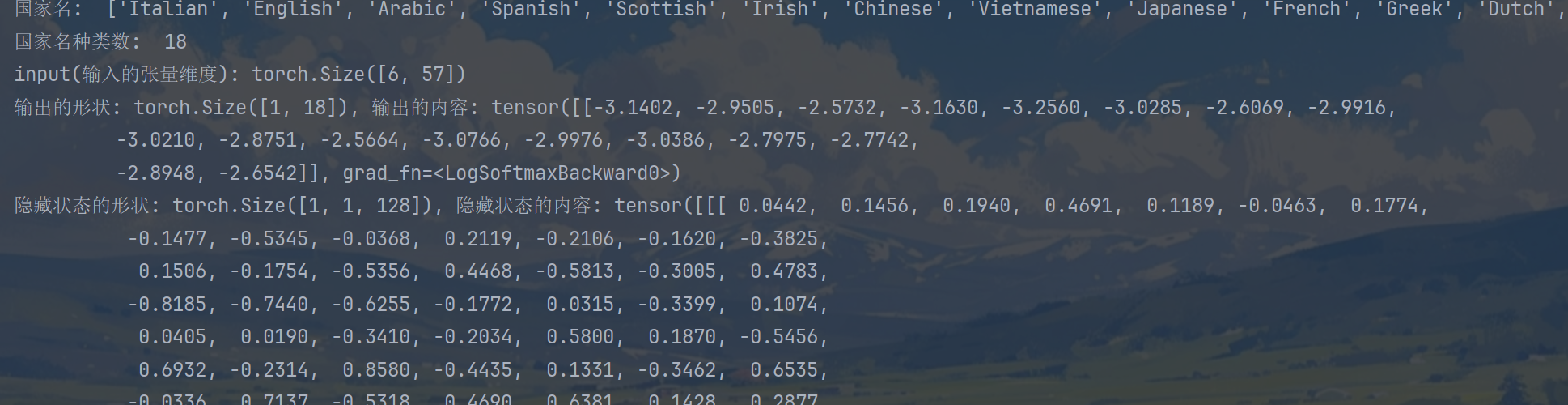
print(f'input(输入的张量维度): {input.shape}') # torch.Size([6, 57])
# 3. 初始化隐藏状态
# h0 = torch.zeros(1, 1, 128)
h0 = my_rnn.init_hidden() # 效果同上.
# 4. 测试一次性输入完整的一个样本(序列数据)
output, hn = my_rnn(input, h0)
# 5. 打印结果.
print(f'输出的形状: {output.shape}, 输出的内容: {output}') # [1, 18]
print(f'隐藏状态的形状: {hn.shape}, 隐藏状态的内容: {hn}') # [1, 1, 128]
# todo 7.2 测试RNN, LSTM, GRU网络模型
def dm_test_rnn_lstm_gru():
# 1. 定义遍历, 记录: 输入维度(词向量维度: 57), 隐藏层维度(128), 输出维度(18, 国家数量)
input_size, n_hidden, output_size = n_letters, 128, category_num
# input_size, n_hidden, output_size = 57, 128, 18 # 效果同上.
# 2. 加载数据
my_list_x, my_list_y = read_data('./data/name_classfication.txt')
# 3. 创建数据集对象
name_class_dataset = NameClassDataset(my_list_x, my_list_y)
# 4. 创建数据加载器.
my_dataloader = DataLoader(name_class_dataset, batch_size=1, shuffle=True)
# 5. 模型初始化.
my_rnn = My_RNN(input_size, n_hidden, output_size)
my_lstm = My_LSTM(input_size, n_hidden, output_size)
my_gru = My_GRU(input_size, n_hidden, output_size)
# 6. 模型结构可视化.
print(f'RNN模型结构: {my_rnn}')
print(f'LSTM模型结构: {my_lstm}')
print(f'GRU模型结构: {my_gru}')
# 7. 测试上述的3个模型
# 7.1 测试RNN模型
for i, (x, y) in enumerate(my_dataloader):
print(f'i: {i}') # 编号, 第i条数据
print(f'x: {x}, x.shape: {x.shape}') # 输入数据的词向量形式, 例如: x.shape: torch.Size([1, 10, 57])
print(f'y: {y}, y.shape: {y.shape}') # 输出数据(国家的编号), 例如: y: tensor([15]), y.shape: torch.Size([1])
# 7.2 初始化隐藏状态.
hidden = my_rnn.init_hidden() # 形状: [1, 1, 128]
# 7.3 前向传播.
output, hidden = my_rnn(x[0], hidden) # x[0] 等价于: [10, 57]
print(f'RNN输出形状: {output.shape}, 预测结果: {output}')
# 扩展: 只训练1个样本, 不然太多了, 这里看看即可.
if i == 0:
break
# 7.2 测试LSTM模型
for i, (x, y) in enumerate(my_dataloader):
# print(f'i: {i}') # 编号, 第i条数据
# print(f'x: {x}, x.shape: {x.shape}') # 输入数据的词向量形式, 例如: x.shape: torch.Size([1, 10, 57])
# print(f'y: {y}, y.shape: {y.shape}') # 输出数据(国家的编号), 例如: y: tensor([15]), y.shape: torch.Size([1])
# 7.2 初始化隐藏状态.
hidden, c = my_lstm.init_hidden() # 形状: [1, 1, 128]
# 7.3 前向传播.
output, hidden, c = my_lstm(x[0], hidden, c) # x[0] 等价于: [10, 57]
print(f'LSTM输出形状: {output.shape}, 预测结果: {output}')
# 扩展: 只训练1个样本, 不然太多了, 这里看看即可.
if i == 0:
break
# 7.3 测试GRU模型
for i, (x, y) in enumerate(my_dataloader):
# print(f'i: {i}') # 编号, 第i条数据
# print(f'x: {x}, x.shape: {x.shape}') # 输入数据的词向量形式, 例如: x.shape: torch.Size([1, 10, 57])
# print(f'y: {y}, y.shape: {y.shape}') # 输出数据(国家的编号), 例如: y: tensor([15]), y.shape: torch.Size([1])
# 7.2 初始化隐藏状态.
hidden = my_gru.init_hidden() # 形状: [1, 1, 128]
# 7.3 前向传播.
output, hidden = my_gru(x[0], hidden) # x[0] 等价于: [10, 57]
print(f'GRU输出形状: {output.shape}, 预测结果: {output}')
# 扩展: 只训练1个样本, 不然太多了, 这里看看即可.
if i == 0:
break
# todo 8. 模型训练.
# 定义变量, 记录: 学习率, 训练的轮数.
my_lr, epochs = 1e-3, 1
# todo 8.1 RNN模型训练.
def train_rnn():
# 1. 数据准备动作.
# 1.1 读取数据
my_list_x, my_list_y = read_data('./name_classfication.txt')
# 1.2 构建数据集对象.
name_class_dataset = NameClassDataset(my_list_x, my_list_y)
# 2. 模型与优化器初始化.
# 2.1 定义模型参数,
# 参1: 输入维度(字符表大小), 参2: 隐藏层维度, 参3: 输出维度(国家数量)
input_size, n_hidden, output_size = n_letters, 128, category_num # 等价于: 57, 128, 18
# 2.2 创建模型对象.
my_rnn = My_RNN(input_size, n_hidden, output_size)
# 2.3 定义损失函数和优化器.
criterion = nn.NLLLoss() # 如果你用了CrossEntropyLoss(), 则它 = NLLLoss() + LogSoftmax()
optimizer = optim.Adam(my_rnn.parameters(), lr=my_lr)
# 3. 训练过程 -> 参数初始化
start_time = time.time() # 模型开始训练时间.
total_iter_num = 0 # 已训练的样本数.
total_loss = 0.0 # 已训练的损失和
total_loss_list = [] # 每100个样本求一次平均损失, 形成: 损失列表.
total_acc_num = 0 # 已训练的样本, 预测准确总数
total_acc_list = [] # 每100个样本求一次平均准确率, 形成: 准确率列表.
# 4. 具体的训练过程, 按轮数遍历数据集.
for epoch in range(epochs): # epoch: 第几轮
print(f'\n开始第{epoch + 1}/{epochs} 轮训练...')
# 4.1 创建数据集加载器对象, 随机打乱数据集.
train_dataloader = DataLoader(name_class_dataset, batch_size=1, shuffle=True)
# 4.2 样本迭代训练, 即: 本轮具体的每批次训练
for i, (x, y) in enumerate(tqdm(train_dataloader)): # 优化点3: 这里加入进度条.
# 4.3 前向传播, 计算结果.
output, hidden = my_rnn(x[0], my_rnn.init_hidden())
# 4.4 计算损失.
my_loss = criterion(output, y)
# 4.5 三剑客 -> 梯度清零, 反向传播, 优化器更新参数.
optimizer.zero_grad()
my_loss.backward()
optimizer.step()
# 4.6 统计训练结果(指标统计)
total_iter_num += 1 # 训训练的样本数 + 1
total_loss += my_loss.item() # 累计损失值
# 4.7 计算当前样本预测准确率
pred_tag = torch.argmax(output).item()
total_acc_num += (1 if pred_tag == y else 0) # 统计: 预测正确的样本数
# 4.8 统计: 每100个样本求一次平均损失, 准确率 形成: 损失列表, 准确率列表.
if total_iter_num % 100 == 0:
# 走这里, 说明100步了, 计算: 平均损失.
avg_loss = total_loss / total_iter_num # 总损失 / 总样本数
# 把上述的平均损失, 添加到: 损失列表.
total_loss_list.append(avg_loss)
# 计算准确率, 即: 预测正确的 / 总样本数, 并添加到: 准确率列表.
avg_acc = total_acc_num / total_iter_num
total_acc_list.append(avg_acc)
# 4.9 每2000步(个样本), 打印训练日志.
if total_iter_num % 2000 == 0:
# 计算平均损失.
avg_loss = total_loss / total_iter_num
# 计算模型训练耗时
end_time = int(time.time() - start_time)
# 输出训练日志.
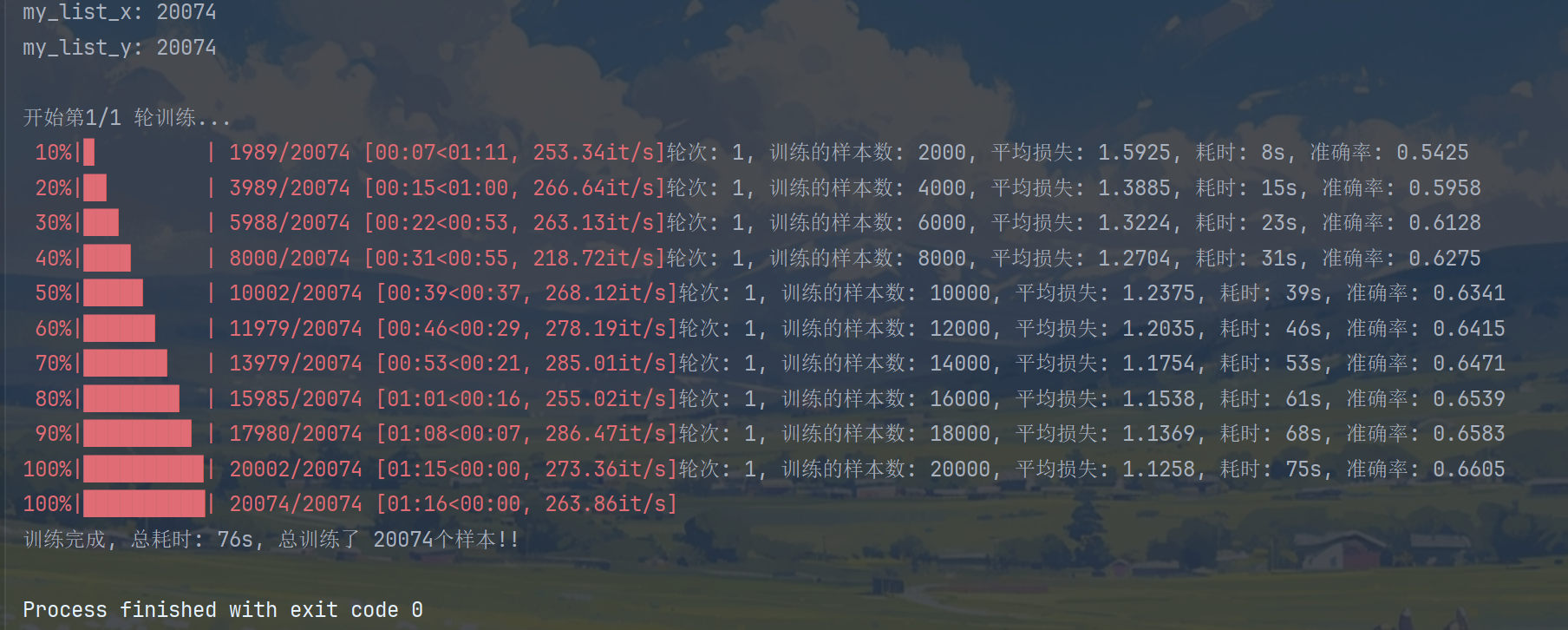
print(f'轮次: {epoch + 1}, 训练的样本数: {total_iter_num}, 平均损失: {avg_loss:.4f}, 耗时: {end_time}s, 准确率: {avg_acc:.4f}')
# 4.10 走到这里, 说明一轮训练完毕 -> 保存模型.
torch.save(my_rnn.state_dict(), f'./model/my_rnn_wh02_{epoch + 1}.bin')
# 5. 走到这里, 训练结束, 返回统计结果.
total_time = int(time.time() - start_time)
print(f'训练完成, 总耗时: {total_time}s, 总训练了 {total_iter_num}个样本!!')
# 6. 优化4: 你可以把下述返回的三个值(损失列表, 训练总耗时, 准确率列表), 存储到文件中.
# 因为一会儿我们会 可视化3个模型的训练结果, 如果没有存储的话, 会把 训练动作从新跑一次.
# 7. 返回结果: 损失列表, 训练总耗时, 准确率列表.
return total_loss_list, total_time, total_acc_list
if __name__ == '__main__':
dm_test_myrnn()
train_rnn()运行结果如下:
🧩LSTM测试:
# todo 8.2 LSTM模型训练.
def train_lstm():
# 1. 数据准备动作.
# 1.1 读取数据
my_list_x, my_list_y = read_data('./data/name_classfication.txt')
# 1.2 构建数据集对象.
name_class_dataset = NameClassDataset(my_list_x, my_list_y)
# 2. 模型与优化器初始化.
# 2.1 定义模型参数,
# 参1: 输入维度(字符表大小), 参2: 隐藏层维度, 参3: 输出维度(国家数量)
input_size, n_hidden, output_size = n_letters, 128, category_num # 等价于: 57, 128, 18
# 2.2 创建模型对象.
my_rnn = My_LSTM(input_size, n_hidden, output_size)
# 2.3 定义损失函数和优化器.
criterion = nn.NLLLoss() # 如果你用了CrossEntropyLoss(), 则它 = NLLLoss() + LogSoftmax()
optimizer = optim.Adam(my_rnn.parameters(), lr=my_lr)
# 3. 训练过程 -> 参数初始化
start_time = time.time() # 模型开始训练时间.
total_iter_num = 0 # 已训练的样本数.
total_loss = 0.0 # 已训练的损失和
total_loss_list = [] # 每100个样本求一次平均损失, 形成: 损失列表.
total_acc_num = 0 # 已训练的样本, 预测准确总数
total_acc_list = [] # 每100个样本求一次平均准确率, 形成: 准确率列表.
# 4. 具体的训练过程, 按轮数遍历数据集.
for epoch in range(epochs): # epoch: 第几轮
print(f'\n开始第{epoch + 1}/{epochs} 轮训练...')
# 4.1 创建数据集加载器对象, 随机打乱数据集.
train_dataloader = DataLoader(name_class_dataset, batch_size=1, shuffle=True)
# 4.2 样本迭代训练, 即: 本轮具体的每批次训练
for i, (x, y) in enumerate(tqdm(train_dataloader)): # 优化点3: 这里加入进度条.
# 4.3 前向传播, 计算结果.
hidden, c = my_rnn.init_hidden()
output, hidden, c = my_rnn(x[0], hidden, c)
# 4.4 计算损失.
my_loss = criterion(output, y)
# 4.5 三剑客 -> 梯度清零, 反向传播, 优化器更新参数.
optimizer.zero_grad()
my_loss.backward()
optimizer.step()
# 4.6 统计训练结果(指标统计)
total_iter_num += 1 # 训训练的样本数 + 1
total_loss += my_loss.item() # 累计损失值
# 4.7 计算当前样本预测准确率
pred_tag = torch.argmax(output).item()
total_acc_num += (1 if pred_tag == y else 0) # 统计: 预测正确的样本数
# 4.8 统计: 每100个样本求一次平均损失, 准确率 形成: 损失列表, 准确率列表.
if total_iter_num % 100 == 0:
# 走这里, 说明100步了, 计算: 平均损失.
avg_loss = total_loss / total_iter_num # 总损失 / 总样本数
# 把上述的平均损失, 添加到: 损失列表.
total_loss_list.append(avg_loss)
# 计算准确率, 即: 预测正确的 / 总样本数, 并添加到: 准确率列表.
avg_acc = total_acc_num / total_iter_num
total_acc_list.append(avg_acc)
# 4.9 每2000步(个样本), 打印训练日志.
if total_iter_num % 2000 == 0:
# 计算平均损失.
avg_loss = total_loss / total_iter_num
# 计算模型训练耗时
end_time = int(time.time() - start_time)
# 输出训练日志.
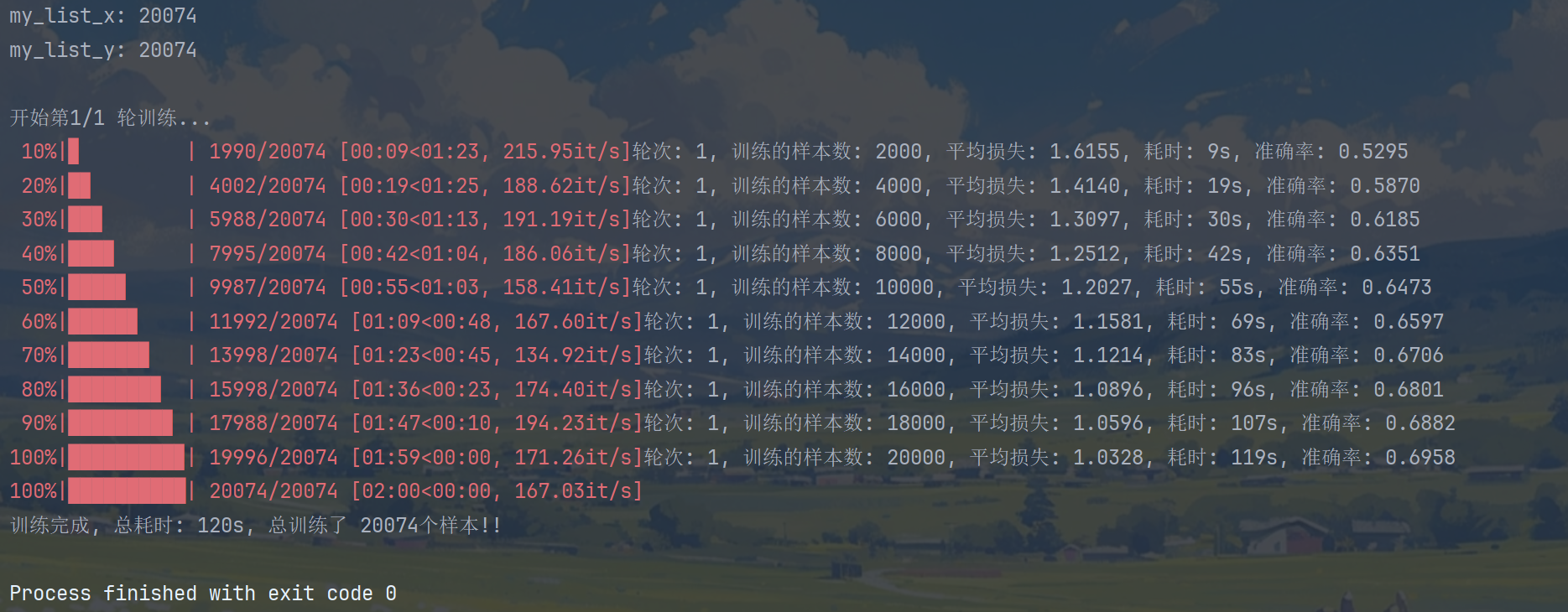
print(f'轮次: {epoch + 1}, 训练的样本数: {total_iter_num}, 平均损失: {avg_loss:.4f}, 耗时: {end_time}s, 准确率: {avg_acc:.4f}')
# 4.10 走到这里, 说明一轮训练完毕 -> 保存模型.
torch.save(my_rnn.state_dict(), f'./model/my_lstm_wh02_{epoch + 1}.bin')
# 5. 走到这里, 训练结束, 返回统计结果.
total_time = int(time.time() - start_time)
print(f'训练完成, 总耗时: {total_time}s, 总训练了 {total_iter_num}个样本!!')
# 6. 优化4: 你可以把下述返回的三个值(损失列表, 训练总耗时, 准确率列表), 存储到文件中.
# 因为一会儿我们会 可视化3个模型的训练结果, 如果没有存储的话, 会把 训练动作从新跑一次.
# 7. 返回结果: 损失列表, 训练总耗时, 准确率列表.
return total_loss_list, total_time, total_acc_list运行结果如下:
🧩GRU测试:
# todo 8.3 GRU模型训练.
def train_gru():
# 1. 数据准备动作.
# 1.1 读取数据
my_list_x, my_list_y = read_data('./data/name_classfication.txt')
# 1.2 构建数据集对象.
name_class_dataset = NameClassDataset(my_list_x, my_list_y)
# 2. 模型与优化器初始化.
# 2.1 定义模型参数,
# 参1: 输入维度(字符表大小), 参2: 隐藏层维度, 参3: 输出维度(国家数量)
input_size, n_hidden, output_size = n_letters, 128, category_num # 等价于: 57, 128, 18
# 2.2 创建模型对象.
my_rnn = My_GRU(input_size, n_hidden, output_size)
# 2.3 定义损失函数和优化器.
criterion = nn.NLLLoss() # 如果你用了CrossEntropyLoss(), 则它 = NLLLoss() + LogSoftmax()
optimizer = optim.Adam(my_rnn.parameters(), lr=my_lr)
# 3. 训练过程 -> 参数初始化
start_time = time.time() # 模型开始训练时间.
total_iter_num = 0 # 已训练的样本数.
total_loss = 0.0 # 已训练的损失和
total_loss_list = [] # 每100个样本求一次平均损失, 形成: 损失列表.
total_acc_num = 0 # 已训练的样本, 预测准确总数
total_acc_list = [] # 每100个样本求一次平均准确率, 形成: 准确率列表.
# 4. 具体的训练过程, 按轮数遍历数据集.
for epoch in range(epochs): # epoch: 第几轮
print(f'\n开始第{epoch + 1}/{epochs} 轮训练...')
# 4.1 创建数据集加载器对象, 随机打乱数据集.
train_dataloader = DataLoader(name_class_dataset, batch_size=1, shuffle=True)
# 4.2 样本迭代训练, 即: 本轮具体的每批次训练
for i, (x, y) in enumerate(tqdm(train_dataloader)): # 优化点3: 这里加入进度条.
# 4.3 前向传播, 计算结果.
output, hidden = my_rnn(x[0], my_rnn.init_hidden())
# 4.4 计算损失.
my_loss = criterion(output, y)
# 4.5 三剑客 -> 梯度清零, 反向传播, 优化器更新参数.
optimizer.zero_grad()
my_loss.backward()
optimizer.step()
# 4.6 统计训练结果(指标统计)
total_iter_num += 1 # 训训练的样本数 + 1
total_loss += my_loss.item() # 累计损失值
# 4.7 计算当前样本预测准确率
pred_tag = torch.argmax(output).item()
total_acc_num += (1 if pred_tag == y else 0) # 统计: 预测正确的样本数
# 4.8 统计: 每100个样本求一次平均损失, 准确率 形成: 损失列表, 准确率列表.
if total_iter_num % 100 == 0:
# 走这里, 说明100步了, 计算: 平均损失.
avg_loss = total_loss / total_iter_num # 总损失 / 总样本数
# 把上述的平均损失, 添加到: 损失列表.
total_loss_list.append(avg_loss)
# 计算准确率, 即: 预测正确的 / 总样本数, 并添加到: 准确率列表.
avg_acc = total_acc_num / total_iter_num
total_acc_list.append(avg_acc)
# 4.9 每2000步(个样本), 打印训练日志.
if total_iter_num % 2000 == 0:
# 计算平均损失.
avg_loss = total_loss / total_iter_num
# 计算模型训练耗时
end_time = int(time.time() - start_time)
# 输出训练日志.
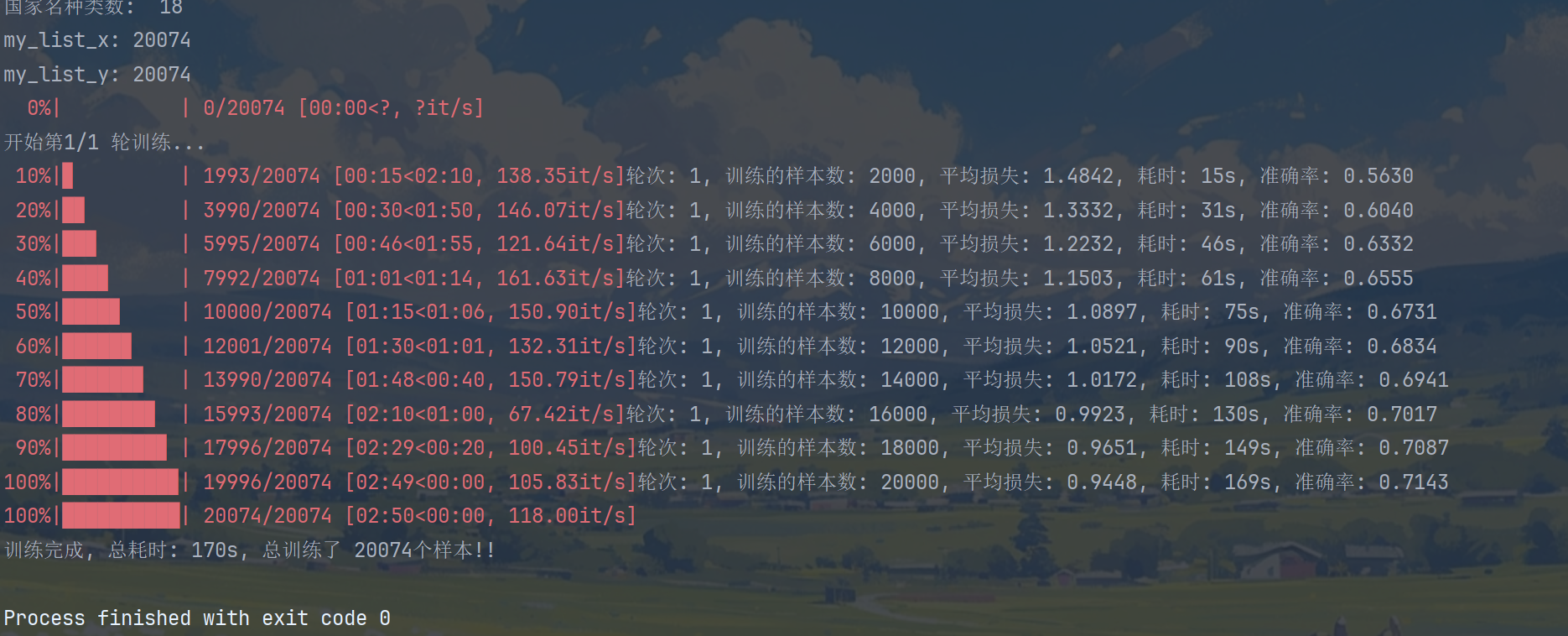
print(f'轮次: {epoch + 1}, 训练的样本数: {total_iter_num}, 平均损失: {avg_loss:.4f}, 耗时: {end_time}s, 准确率: {avg_acc:.4f}')
# 4.10 走到这里, 说明一轮训练完毕 -> 保存模型.
torch.save(my_rnn.state_dict(), f'./model/my_gru_wh02_{epoch + 1}.bin')
# 5. 走到这里, 训练结束, 返回统计结果.
total_time = int(time.time() - start_time)
print(f'训练完成, 总耗时: {total_time}s, 总训练了 {total_iter_num}个样本!!')
# 6. 优化4: 你可以把下述返回的三个值(损失列表, 训练总耗时, 准确率列表), 存储到文件中.
# 因为一会儿我们会 可视化3个模型的训练结果, 如果没有存储的话, 会把 训练动作从新跑一次.
# 7. 返回结果: 损失列表, 训练总耗时, 准确率列表.
return total_loss_list, total_time, total_acc_list运行结果如下:
可以用可视化图表对比一些这几个训练结果:
# todo 9. 模型训练绘图 -> 这个函数的可视化代码你可以不写, 但是模型训练等代码要写出来, 出3张图.
def dm_test_train_rnn_lstm_gru():
# 1. 训练3种模型, 并获取性能指标.
# 参1: 损失列表, 参2: 训练总耗时, 参3: 准确率列表.
total_loss_list_rnn, total_time_rnn, total_acc_list_rnn = train_rnn()
total_loss_list_lstm, total_time_lstm, total_acc_list_lstm = train_lstm()
total_loss_list_gru, total_time_gru, total_acc_list_gru = train_gru()
# 2. 绘制 损失对比曲线(评估: 模型收敛速度)
# 2.1 创建画布. 0: 图1
plt.figure(0, figsize=(10, 5))
# 2.2 绘制各模型损失曲线.
plt.plot(total_loss_list_rnn, label='RNN')
plt.plot(total_loss_list_lstm, label='LSTM')
plt.plot(total_loss_list_gru, label='GRU')
# 2.3 设置图表属性
plt.title('模型损失对比曲线')
plt.xlabel('训练步数(每100步)')
plt.ylabel('平均损失值')
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend(loc='upper left')
plt.savefig('./img/RNN_LSTM_GRU_loss_time.png')
plt.show()
# 3. 绘制 训练耗时对比柱状图(评估: 模型计算效率)
# 3.1 创建画布, 1: 图2
plt.figure(1, figsize=(10, 5))
# 3.2 准备x轴 和 y轴标签内容.
x_data = ['RNN', 'LSTM', 'GRU']
y_data = [total_time_rnn, total_time_lstm, total_time_gru]
# 3.3 绘制柱状图
plt.bar(range(len(x_data)), y_data, tick_label=x_data)
# 3.4 设置图表属性
plt.title('模型耗时对比柱状图')
plt.savefig('./img/RNN_LSTM_GRU_time.png')
plt.show()
# 4. 绘制 训练准确率对比曲线(评估: 模型效果)
# 4.1 创建画布. 2: 图3
plt.figure(2, figsize=(10, 5))
# 4.2 绘制各模型准确率曲线.
plt.plot(total_acc_list_rnn, label='RNN', color='red')
plt.plot(total_acc_list_lstm, label='LSTM', color='green')
plt.plot(total_acc_list_gru, label='GRU', color='orange')
# 4.3 绘制图表属性.
plt.title('模型准确率对比曲线')
plt.legend(loc='upper left')
plt.savefig('./img/RNN_LSTM_GRU_acc.png')
plt.show()模型训练结果分析
1 损失对比曲线分析
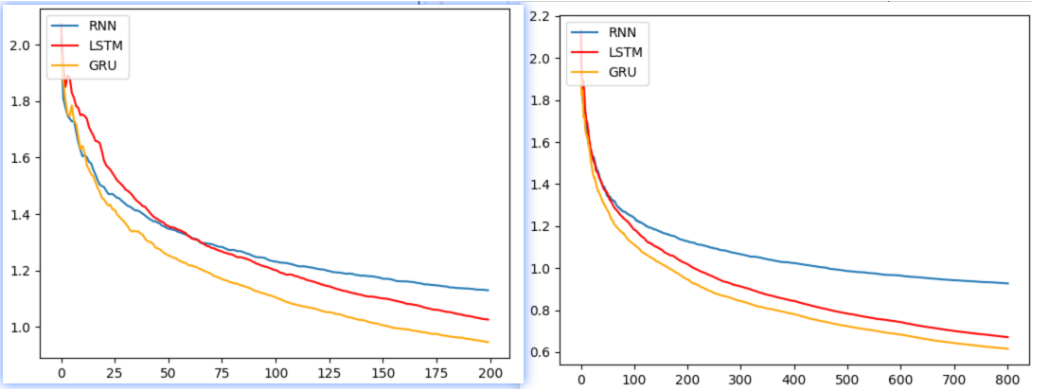
- 左图:1个轮次损失对比曲线,右图4个轮次损失对比曲线
- 模型训练的损失降低快慢代表模型收敛程度。由图可知, 传统RNN的模型第一个轮次开始收敛情况最好,然后是GRU, 最后是LSTM, 这是因为RNN模型简单参数少,见效快。随着训练数据的增加,GRU效果最好、LSTM效果次之、RNN效果排最后。
- 所以在以后的模型选用时, 要通过对任务的分析以及实验对比, 选择最适合的模型。
2 训练耗时分析
训练耗时对比图:
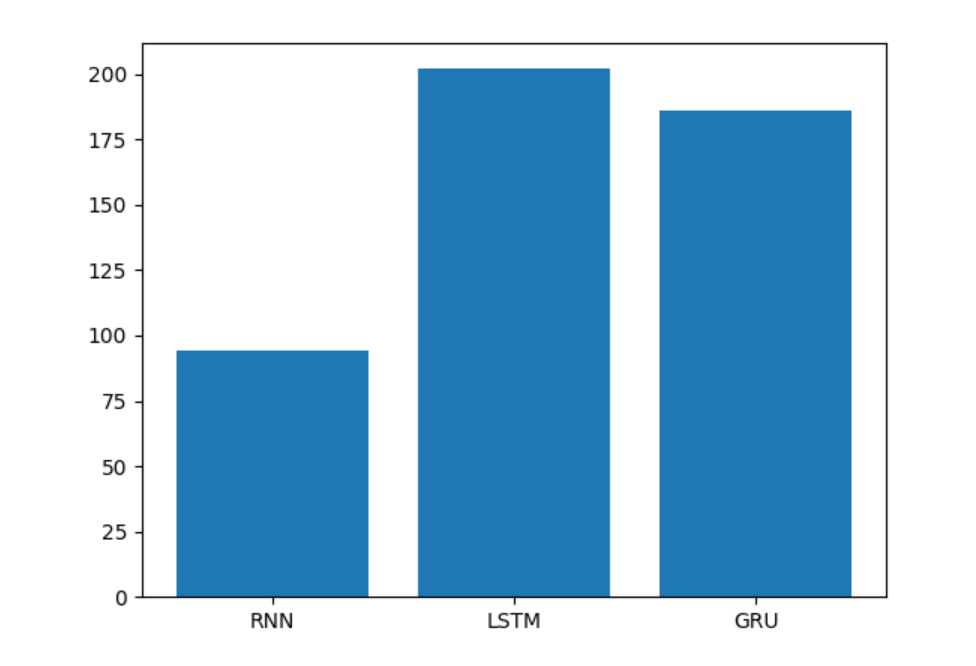
- 模型训练的耗时长短代表模型的计算复杂度,由图可知, 也正如我们之前的理论分析,传统RNN复杂度最低, 耗时几乎只是后两者的一半, 然后是GRU,最后是复杂度最高的LSTM。
3、 训练准确率分析
训练准确率对比图:
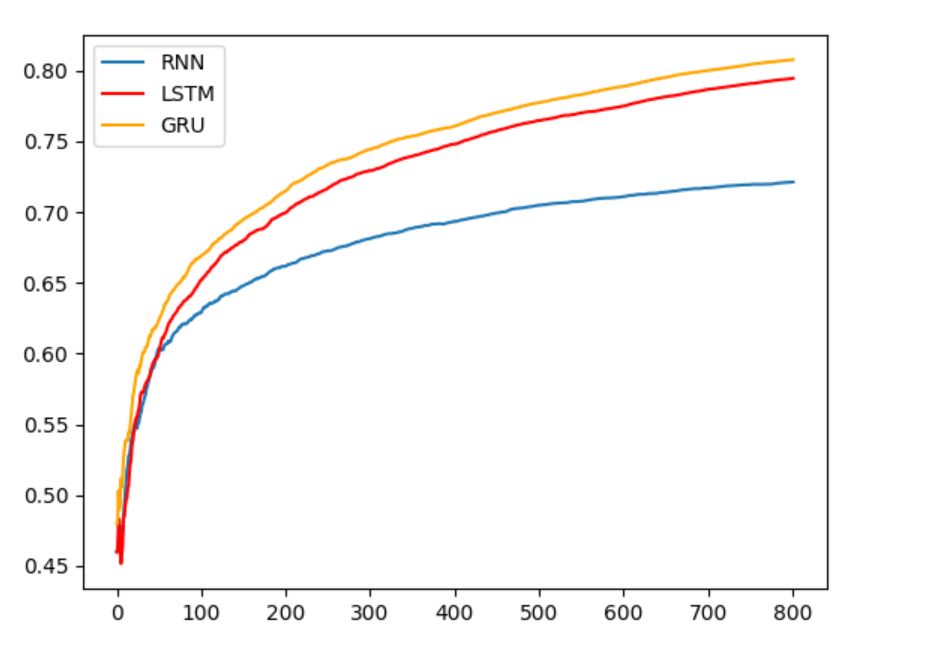
- 由图可知, GRU效果最好、LSTM效果次之、RNN效果排最后。
结论:
模型选用一般应通过实验对比,并非越复杂或越先进的模型表现越好,而是需要结合自己的特定任务,从对数据的分析和实验结果中获得最佳答案。
四、模型预测
RNN预测:
# todo 10. 模型预测.
# todo 10.1 RNN模型预测
# todo 10.1.1. 定义遍历, 记录模型的参数的路径.
my_rnn_path = './model/my_rnn_wh02_1.bin'
my_lstm_path = './model/my_lstm_wh02_1.bin'
my_gru_path = './model/my_gru_wh02_1.bin'
# todo 10.1.2 定义函数, 将要预测的人名 转成 one-hot编码, 例如: 'zhang' -> [5, 57]
def lineToTensor(line):
# 1. 初始化张量, [文本长度, 字符表长度]
tensor_x = torch.zeros(len(line), n_letters)
# 2. 遍历文本, 获取到每个字符及其索引.
for i, letter in enumerate(line):
# 3. 查看字符在全局字母表中的位置(索引)
letter_index = all_letters.find(letter)
# 4. 在张量的对应位置改为1, 完成: one-hot编码
tensor_x[i][letter_index] = 1
# 5. 返回结果.
return tensor_x # 即: 'zhang' -> [5, 57]
# todo 10.1.3 定义函数, 实现: RNN预测.
def dm_predict_rnn(x):
# 1. 定义遍历, 记录模型相关参数.
n_letters, n_hidden, n_categories = 57, 128, 18
# 2. 把输入的文字转成 one-hot编码.
x_tensor = lineToTensor(x)
# 3. 创建模型对象.
my_rnn = My_RNN(n_letters, n_hidden, n_categories)
# 4. 加载模型参数.
my_rnn.load_state_dict(torch.load(my_rnn_path))
# 5. 进行预测, 不计算梯度. -> 节省内存和计算机资源.
with torch.no_grad():
# 5.1 模型预测
output, hidden = my_rnn(x_tensor, my_rnn.init_hidden())
# 5.2 从预测结果中, 获取前3个最大的元素.
# 参1(k): 取前3个最大的元素.
# 参2(dim): 获取概率最大的元素所在的维度.
# 参3(largest): 获取概率最大的元素.
topv, topi = output.topk(3, 1, True)
# 5.3 打印待预测文本.
print(f'rnn(待预测文本): {x}')
# 5.4 解析预测结果.
for i in range(3):
value = topv[0][i].item() # 概率值 -> Python的标量
category_idx = topi[0][i].item() # 类别索引
category = categories[category_idx] # 类别名称.
print(f'value: {value}, category: {category}')
运行结果:

LSTM预测:
# 构建LSTM 预测函数
def my_predict_lstm(x):
n_letters = 57
n_hidden = 128
n_categories = 18
# 输入文本, 张量化one-hot
x_tensor = lineToTensor(x)
# 实例化模型 加载已训练模型参数
my_lstm = LSTM(n_letters, n_hidden, n_categories)
my_lstm.load_state_dict(torch.load(my_path_lstm))
with torch.no_grad():
# 模型预测
hidden, c = my_lstm.inithidden()
output, hidden, c = my_lstm(x_tensor, hidden, c)
# 从预测结果中取出前3名
# 3表示取前3名, 1表示要排序的维度, True表示是否返回最大或是最下的元素
topv, topi = output.topk(3, 1, True)
print('rnn =>', x)
for i in range(3):
value = topv[0][i]
category_idx = topi[0][i]
category = categorys[category_idx]
print('\t value:%d category:%s' % (value, category))
print('\t value:%d category:%s' % (value, category))
GRU预测:
# 构建GRU 预测函数
def my_predict_gru(x):
n_letters = 57
n_hidden = 128
n_categories = 18
# 输入文本, 张量化one-hot
x_tensor = lineToTensor(x)
# 实例化模型 加载已训练模型参数
my_gru = GRU(n_letters, n_hidden, n_categories)
my_gru.load_state_dict(torch.load(my_path_gru))
with torch.no_grad():
# 模型预测
output, hidden = my_gru(x_tensor, my_gru.inithidden())
# 从预测结果中取出前3名
# 3表示取前3名, 1表示要排序的维度, True表示是否返回最大或是最下的元素
topv, topi = output.topk(3, 1, True)
print('rnn =>', x)
for i in range(3):
value = topv[0][i]
category_idx = topi[0][i]
category = categorys[category_idx]
print('\t value:%d category:%s' % (value, category))
最后构建函数测试三个模型预测:
def dm_test_predic_rnn_lstm_gru():
# 把三个函数的入口地址 组成列表,统一输入数据进行测试
for func in [my_predict_rnn, my_predict_lstm, my_predict_gru]:
func('zhang')
运行结果如下:
rnn => zhang
value:0 category:Russian
value:0 category:Chinese
value:-4 category:German
rnn => zhang
value:0 category:Chinese
value:-1 category:Russian
value:-1 category:German
rnn => zhang
value:0 category:Russian
value:0 category:Chinese
value:-2 category:Korean
五、总结
-
学习了关于人名分类问题: 以一个人名为输入, 使用模型帮助我们判断它最有可能是来自哪一个国家的人名, 这在某些国际化公司的业务中具有重要意义, 在用户注册过程中, 会根据用户填写的名字直接给他分配可能的国家或地区选项, 以及该国家或地区的国旗, 限制手机号码位数等等.
-
人名分类器的实现可分为以下五个步骤:
- 第一步: 导入必备的工具包
- 第二步: 对data文件中的数据进行处理,满足训练要求
- 第三步: 构建RNN模型(包括传统RNN, LSTM以及GRU)
- 第四步: 构建训练函数并进行训练
- 第五步: 构建评估函数并进行预测
-
第一步: 导入必备的工具包
- python版本, pytorch版本
- 第二步: 对data文件中的数据进行处理,满足训练要求
- 读原始数据到内存,构建出模型需要的数据x,标签y,然后把数据转成数据源,最后再封装成数据迭代器
- 从编程实现来看,文本数值化,数值张量化是通过one-hot编码一步完成的
- 第三步: 构建RNN模型
- 构建传统的RNN模型的类class RNN.
- 构建LSTM模型的类class LSTM.
- 构建GRU模型的类class GRU.
- 第四步: 构建训练函数并进行训练
- 实例化数据迭代器对象
- 实例化模型对象、损失函数对象、优化器对象
- 定义模型训练的参数
- 训练模型
- 外层for循环 控制轮数
- 内层for循环 控制迭代次数,给模型喂数据,计算损失 ,梯度清零 ,反向传播 , 梯度更新,打印日志
- 模型保存
- 损失对比曲线分析:
- 传统RNN的模型第一个轮次开始收敛情况最好,然后是GRU, 最后是LSTM, 这是因为RNN模型简单参数少,见效快。
- 随着训练数据的增加,GRU效果最好、LSTM效果次之、RNN效果排最后
- 训练耗时对比图分析:
- 模型训练的耗时长短代表模型的计算复杂度,由图可知,也正如我们之前的理论分析,传统RNN复杂度最低,耗时几乎只是后两者的一半,然后是GRU,最后是复杂度最高的LSTM
- 结论:
- 模型选用一般应通过实验对比, 并非越复杂或越先进的模型表现越好, 而是需要结合自己的特定任务,从对数据的分析和实验结果中获得最佳答案
- 第五步: 构建预测函数并进行预测
- 构建传统RNN预测函数
- 构建LSTM预测函数
- 构建GRU预测函数
- 构建预测函数调用函数

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)