AI测试智能体(agent)实战:规划→执行→反思:14年测试教你从零手写一个能跑的Agent(附源码自取)
作者:测试员周周,14 年测试,全网同名「测试员周周」,agent源码已开源,可点击上面的外部链接,关注回复关键字【agent】领取;
- Agent 不是框架,是控制流。 规划→执行→反思,用 if-else 就能写。
- 不要一上来就套 LangChain。 先手写一个能跑的,理解链路,再考虑框架。
- 换场景只改 2 个地方: 业务背景 + 工具列表。控制流不变。
- 兜底逻辑很重要。 LLM 不总是返回合法 JSON,没有兜底就崩。
- 反思机制是质变。 从"跑完就交"变成"检查后再交",质量差很多。
一、我第一次搭 Agent,花了 3 天,踩了 7 个坑
2025 年初,我在网上看了一堆"Agent 教程"。
教程标题都很诱人:
- "10 分钟搭建你的第一个 Agent"
- "用 LangChain 5 行代码实现 Agent"
- "零代码搭建 AI Agent"
我照着做。结果呢?
LangChain 版本不兼容,装了 2 小时环境。跑起来以后,Agent 不拆任务,直接把整件事丢给 LLM。工具调用失败,没有重试。没有反思,没有重规划。
我搭的不是 Agent,是一个会聊天的 API 包装器。
后来我放弃了那些教程,自己用纯 Python 写了一个。不依赖 LangChain、不依赖 CrewAI、不依赖任何框架。
代码 1000 行,跑通了。
架构就是:规划 → 执行 → 反思。
这篇实战,我把这个 Agent 从 0 到 1 拆给你看。不套框架,不装依赖,纯 Python 手写。你跟着走一遍,就能搭出自己的 Agent。
二、Agent 和普通聊天,差在哪?
先说清楚一件事:Agent 不是"更聪明的聊天机器人"。
普通聊天:
用户:帮我分析销售数据
AI:好的,销售数据可以从以下几个维度分析...
Agent:
用户:帮我分析销售数据
Agent:
[规划] 拆成 5 个子任务:
1. 查询销售数据
2. 计算各品类占比
3. 识别异常品类
4. 生成图表数据
5. 写报告
[执行] 调用 search → 拿到销售数据
调用 calculator → 算占比
调用 code_executor → 跑 Python 分析
[反思] 检查:异常品类识别不够细,需要加一个子任务
[重规划] 增加"识别退货率异常品类"
[总结] 输出一份完整报告
核心区别:Agent 会拆任务、会调工具、会检查自己的结果、错了能改。
不是"一句话进,一句话出"。
三、环境:3 样东西就够了
不装 LangChain,不装 Docker,不装向量数据库。
| 需要的 | 为什么 |
|---|---|
| Python 3.8+ | 基础语法,dataclass,requests |
requests 库 |
调 LLM API |
| 一个 API Key | 千问、智谱、OpenAI 都行 |
# 就这一行
pip install requests
# 设置 API Key(Linux / macOS,当前终端有效)
export DASHSCOPE_API_KEY="<你的API Key>"
Windows 下怎么配环境变量、怎么跑?(与 Linux 的差别主要在「工作目录」和「环境变量写法」。)
-
先进入仓库根目录(必须能看到
agents文件夹的那一层,例如...\custom_agent_test_package,不要只在agents里跑,否则相对路径会对不上)。 -
安装依赖(与 Linux 相同):
pip install requests
- 设置通义千问(DashScope)API Key(二选一,在运行
python的同一个窗口里执行,新开窗口要重新设):
- CMD:
set DASHSCOPE_API_KEY=你的APIKey
若 Key 里含空格或特殊符号,用:set "DASHSCOPE_API_KEY=你的APIKey"。
- PowerShell:
$env:DASHSCOPE_API_KEY="你的APIKey"
- 运行演示脚本(在仓库根目录执行;正斜杠、反斜杠在 Windows 上一般都可以):
python agents\custom_agent\agent.py
Linux / macOS 在对应根目录下执行:
export DASHSCOPE_API_KEY="<你的API Key>"
python agents/custom_agent/agent.py
- 若界面里「成功: False」且「输出」为空:多半是 未设置 Key、Key 错误、或 网络访问不了模型接口。脚本返回的是字典,除
output外还有error(例如规划失败:API Key 无效或已过期)。调试时建议同时打印result.get("error"),不要只看output。
为什么这么少? 因为 Agent 的核心逻辑是控制流——先做什么、后做什么、失败怎么办。这些用 if-else + for 循环就能写。不需要框架。
四、Agent 长什么样:先看完整流程
代码在 agents/custom_agent/agent.py,1000 行。不用通读,先看主干。
Agent 的 run() 方法,就是这条链路:
用户任务
↓
[安全预检] 有害内容?Prompt注入?隐私数据? → 拦截
↓
[规划] LLM 把任务拆成子任务 + 依赖关系 + 工具选择
↓
[执行] 按依赖顺序跑子任务(调工具或调 LLM)
↓
[反思] 结果够不够?要不要改计划?
↓
done → [总结] 输出最终答案
replan → 回到[规划],重新拆
就这 5 步。 没有魔法。
五、第一步:规划——让 LLM 拆任务
Agent 拿到用户任务,第一件事是拆。
怎么拆?把任务发给 LLM,让它输出 JSON:
# Prompt 的核心结构
PLANNING_PROMPT = """
你是一个电商数据分析智能体。用户给你一个任务,你需要:
1. 将任务分解为多个子任务
2. 为每个子任务选择合适的工具
3. 建立子任务之间的依赖关系
可用工具:
- search: 知识库/业务检索(销售数据查询、报告生成等)
- calculator: 数学计算
- code_executor: 执行 Python 代码
- memory_store: 记忆存储/读取
- web_fetch: 获取网页内容
- safety_checker: 安全检测
输出格式(JSON):
[
{
"id": "task_1",
"description": "子任务描述",
"depends_on": [],
"tool": "search",
"tool_input": "查询2024年6月各品类销售额"
},
{
"id": "task_2",
"description": "计算占比",
"depends_on": ["task_1"],
"tool": "calculator",
"tool_input": "1250000 / 4710000"
}
]
当前任务:分析2024年6月销售数据并生成报告
"""
LLM 返回 JSON 以后,Agent 解析成子任务列表。每个子任务有 5 个字段:
| 字段 | 作用 | 示例 |
|---|---|---|
id |
唯一标识 | task_1 |
description |
子任务描述 | "查询销售数据" |
depends_on |
依赖哪些子任务 | ["task_1"] |
tool |
用什么工具 | search |
tool_input |
工具参数 | "查询2024年6月数据" |
如果 LLM 返回的不是合法 JSON 怎么办?
Agent 有兜底逻辑:退化成单任务——整件事交给 LLM 直接回答。虽然不拆了,但至少不会崩。
def _parse_subtasks(self, content: str) -> List[SubTask]:
try:
json_str = self._extract_json(content)
data = json.loads(json_str)
if isinstance(data, list):
return [SubTask(...) for item in data]
except:
pass
return [] # 解析失败,返回空列表
# 空列表 → 退化为单任务
if not subtasks:
subtasks = [SubTask(
id="task_1",
description=task, # 原始任务
depends_on=[],
tool="none",
tool_input="直接回答",
)]
这是我踩的第一个坑:一开始没有兜底逻辑,LLM 返回格式不对时直接崩。加了兜底以后,最差情况也能返回一个答案。
六、第二步:执行——按依赖顺序跑
拆完子任务,开始跑。
跑的顺序不是随便的。task_2 依赖 task_1,那就必须先跑 task_1。
Agent 用拓扑排序确定执行顺序:
def _topological_sort(self, subtasks: List[SubTask]) -> List[str]:
"""确定执行顺序:依赖的先跑"""
task_map = {s.id: s for s in subtasks}
visited = set()
order = []
def visit(task_id):
if task_id in visited:
return
visited.add(task_id)
task = task_map.get(task_id)
if task:
for dep in task.depends_on:
visit(dep) # 先访问依赖
order.append(task_id) # 再访问自己
for s in subtasks:
visit(s.id)
return order
跑的时候,每个子任务分两种情况:
情况 1:不需要工具(tool="none")
直接调 LLM 回答:
if subtask.tool <span class="wx-em-red"> "none":
response = self._call_llm(f"请完成:{subtask.description}")
subtask.result = response["content"]
情况 2:需要工具
走 ToolRegistry.execute():
result = ToolRegistry.execute(subtask.tool, subtask.tool_input, state)
subtask.result = result
ToolRegistry 是一个工具分发中心,根据工具名调对应的函数:
@classmethod
def execute(cls, tool_name: str, tool_input: str, state: AgentState) -> str:
if tool_name </span> "calculator":
return cls._calculator(tool_input)
elif tool_name <span class="wx-em-red"> "search":
return cls._search(tool_input)
elif tool_name </span> "code_executor":
return cls._code_executor(tool_input)
# ... 其他工具
失败怎么办?重试。
if not success:
for attempt in range(subtask.max_retries - 1):
if self._execute_subtask(subtask, state):
subtask.status = "success"
break
else:
subtask.status = "failed" # 重试 3 次还是失败
这是我踩的第二个坑:一开始工具失败就标记失败,没有重试。但 LLM 偶尔返回的工具名有拼写误差,重试一次可能就对了。
七、第三步:反思——Agent 自己检查自己
子任务跑完,Agent 不是直接输出。它会先反思:
REFLECTION_PROMPT = """
你是一个质量检查专家。一个智能体正在执行任务,已完成了一些子任务。
原始任务:分析2024年6月销售数据并生成报告
已完成子任务结果:
- task_1 (success): 查询销售数据 → 拿到各品类销售额
- task_2 (success): 计算占比 → 电子产品占26.5%
- task_3 (failed): 识别异常 → 工具调用失败
请检查:
1. 已完成的子任务结果是否合理
2. 是否需要调整后续计划
3. 当前进度是否足够生成最终答案
输出格式(JSON):
{
"status": "continue" | "replan" | "done",
"reason": "判断理由",
"adjustments": "调整内容"
}
"""
LLM 返回 3 种结果之一:
| 返回 | 含义 | Agent 怎么做 |
|---|---|---|
done |
够了,可以输出 | 进入总结阶段 |
replan |
不够,需要调整 | 带着已完成结果,重新规划 |
continue |
还有剩余子任务没跑 | 继续执行剩余子任务 |
这个机制的价值:Agent 不是"跑完就交卷"。它会检查自己的结果,发现不够就再跑一轮。
这是我踩的第三个坑:一开始没有反思机制,Agent 经常交半吊子答案。加了反思以后,质量明显提升。
八、第四步:总结——把碎片拼成完整答案
所有子任务跑完(或反思说够了),进入总结阶段。
SUMMARY_PROMPT = """
你是一个任务总结专家。一个智能体已完成所有子任务,请汇总结果并给出最终答案。
原始任务:分析2024年6月销售数据并生成报告
子任务结果:
### task_1: 查询销售数据
状态: success
结果: 电子产品销售额1250000元,服装鞋帽890000元...
### task_2: 计算占比
状态: success
结果: 电子产品占比26.5%,服装鞋帽18.9%...
### task_3: 识别异常
状态: failed
结果: 错误: 工具调用失败
请给出清晰、完整的最终答案:
"""
LLM 把所有子任务结果汇总,生成一段自然语言回答。
注意:即使有子任务失败,Agent 也能生成回答——它会基于成功的子任务尽量输出,并在回答中说明哪些部分缺失。
九、工具怎么加:3 步搞定
Agent 内置了 6 个工具。你想加自己的工具,3 步:
步骤 1:在 TOOLS 字典里注册
TOOLS = {
# ... 已有 6 个工具
"email_sender": {
"name": "email_sender",
"description": "发送邮件。输入:收件人 + 主题 + 内容",
"usage": "email_sender: 收件人@xxx.com, 销售报告, 附件已生成",
},
}
步骤 2:在 execute 里加分支
elif tool_name <span class="wx-em-red"> "email_sender":
return cls._email_sender(tool_input)
步骤 3:实现函数
@staticmethod
def _email_sender(input_str: str) -> str:
# 解析收件人、主题、内容
# 发送邮件(真实或 Mock)
return f"[邮件发送] 已发送至 {recipient}"
就这么简单。 不需要继承什么基类,不需要注册什么服务。加一行字典、一个分支、一个函数,完事。
十、换场景怎么改:只改 2 个地方
这个 Agent 默认是电商数据分析。你想改成客服、代码助手、医疗咨询?
只改 2 个地方:
改 1:业务背景
BUSINESS_CONTEXT = """
你是一个医疗咨询智能体。你的职责是:
- 回答常见健康问题
- 根据症状推荐就诊科室
- 提供用药建议(非处方药)
注意:不提供诊断,不替代医生面诊。
"""
改 2:工具列表
TOOLS = {
"symptom_checker": {...}, # 症状查询
"department_recommender": {...}, # 科室推荐
"drug_database": {...}, # 药品查询
"safety_checker": {...}, # 安全检测(保留)
}
Prompt、反思逻辑、总结逻辑都不用改。因为它们是通用的控制流,不关心具体业务。
十一、几个常被问到的问题
必须用千问吗?
不是。代码走的是 OpenAI 兼容的 chat/completions 接口。换 api_base 和模型名就行:
self.api_base = "https://open.bigmodel.cn/api/paas/v4" # 智谱
self.model = "glm-4"
规划结果不稳定怎么办?
常见原因:业务背景写得太宽,工具描述互相干扰。
解决:收紧 BUSINESS_CONTEXT,减少工具数量,降低 temperature(0.3 比 0.7 稳定)。
能并行执行子任务吗?
代码里已经算出了 parallel_groups(无依赖的子任务可以并行),但当前是串行执行。要并行时加 concurrent.futures.ThreadPoolExecutor 就行。
最小 Agent 多长?
3 个方法就能跑:
class MyAgent:
def __init__(self, api_key, model="qwen-plus"):
self.api_key = api_key
self.model = model
def run(self, task, context=None):
response = self._call_llm(task)
return {"success": True, "output": response, "error": None}
def reset(self):
pass
本仓库的 CustomAgent 是在这个最小骨架上加了规划、工具、反思的完整版本。
十二、写 Agent 最容易踩的 3 个安全坑
我写这个 Agent 的时候,最开始的版本有 3 个安全隐患,后来都被测出来了。
坑 1:用 eval() 算数学表达式
计算器功能最开始是这样写的:
# ❌ 危险写法
def _calculator(expression: str) -> str:
return str(eval(expression))
eval("2+3") 返回 5,没问题。但 eval("__import__('os').system('rm -rf /')") 呢?
修复:换成 AST 解析,只允许数学运算:
# ✅ 安全写法
import ast
def _safe_eval_math(expression: str) -> float:
tree = ast.parse(expression, mode='eval')
# 只允许: 数字、加减乘除、幂、mod、abs/round/min/max/sum/pow
# 禁止: 函数调用(除了白名单)、属性访问、导入
return _walk_ast(tree.body)
教训:任何接受用户输入的地方,不要用 eval()。数学表达式用 AST,JSON 用 json.loads()。
坑 2:网络请求失败没有详细错误
最开始 _call_llm 长这样:
# ❌ 失败时只知道"失败了"
response = requests.post(url, json=payload, timeout=60)
if response.status_code != 200:
return None # 为什么失败?不知道
测试的时候 Agent 一直返回"规划失败",我查了 2 小时才发现是 API Key 过期了。
修复:记录详细错误信息:
# ✅ 失败时知道为什么失败
if response.status_code </span> 401:
self._last_llm_error = "API Key 无效或已过期"
elif response.status_code == 429:
self._last_llm_error = "请求频率超限,请稍后重试"
elif response.status_code >= 500:
self._last_llm_error = f"服务端错误: {response.status_code}"
else:
self._last_llm_error = f"HTTP {response.status_code}: {response.text[:200]}"
教训:错误信息不是给开发者看的,是给调试者看的。"失败了"和"API Key 过期",排查时间差 10 倍。
坑 3:所有配置写死在代码里
最开始 API 地址、模型名、超时时间都硬编码:
self.api_base = "https://dashscope.aliyuncs.com/compatible-mode/v1"
self.model = "qwen-plus"
self.timeout = 60
想换智谱?改代码。想调超时?改代码。想降低 temperature?改代码。
修复:全部通过 kwargs 外部化:
self.api_base = kwargs.get("api_base", "https://dashscope.aliyuncs.com/compatible-mode/v1")
self.model = kwargs.get("model", "qwen-plus")
self.llm_timeout = kwargs.get("llm_timeout", 60)
self.temperature = kwargs.get("temperature", 0.7)
教训:配置和代码分离。今天你改一次代码没问题,明天你要跑 10 组对比实验的时候就明白了。
十三、调试 Agent 的 2 个实用技巧
技巧 1:看 _meta,别看 output
Agent 每次运行都会返回 _meta 字段,里面包含了完整的执行轨迹:
{
"_meta": {
"tokens": 2345,
"llm_calls": 4,
"elapsed": 12.3,
"replans": 1,
"subtasks": [
{"id": "task_1", "tool": "search", "status": "success"},
{"id": "task_2", "tool": "calculator", "status": "success"},
{"id": "task_3", "tool": "code_executor", "status": "failed", "retry_count": 3}
]
}
}
调试时先看 _meta:
llm_calls太多?说明 Agent 在反复重规划replans > 0?说明反思觉得不够,重新拆了- 某个
status: "failed"+retry_count: 3?这个工具调用一直失败
技巧 2:降低 temperature 看稳定性
如果 Agent 行为不稳定,先做一件事:
agent = CustomAgent(temperature=0.1) # 从 0.7 降到 0.1
temperature=0.1 时 LLM 几乎确定性输出。如果这时候 Agent 行为稳定了,说明问题在"创造性过高",不是逻辑错误。
十四、这一篇要带走的东西
- Agent 不是框架,是控制流。 规划→执行→反思,用 if-else 就能写。
- 不要一上来就套 LangChain。 先手写一个能跑的,理解链路,再考虑框架。
- 换场景只改 2 个地方: 业务背景 + 工具列表。控制流不变。
- 兜底逻辑很重要。 LLM 不总是返回合法 JSON,没有兜底就崩。
- 反思机制是质变。 从"跑完就交"变成"检查后再交",质量差很多。
代码位置:
agents/custom_agent/agent.py(1000 行),agents/custom_agent/config.yaml(配置),agents/custom_agent/tools/(自定义工具)。运行方式:在
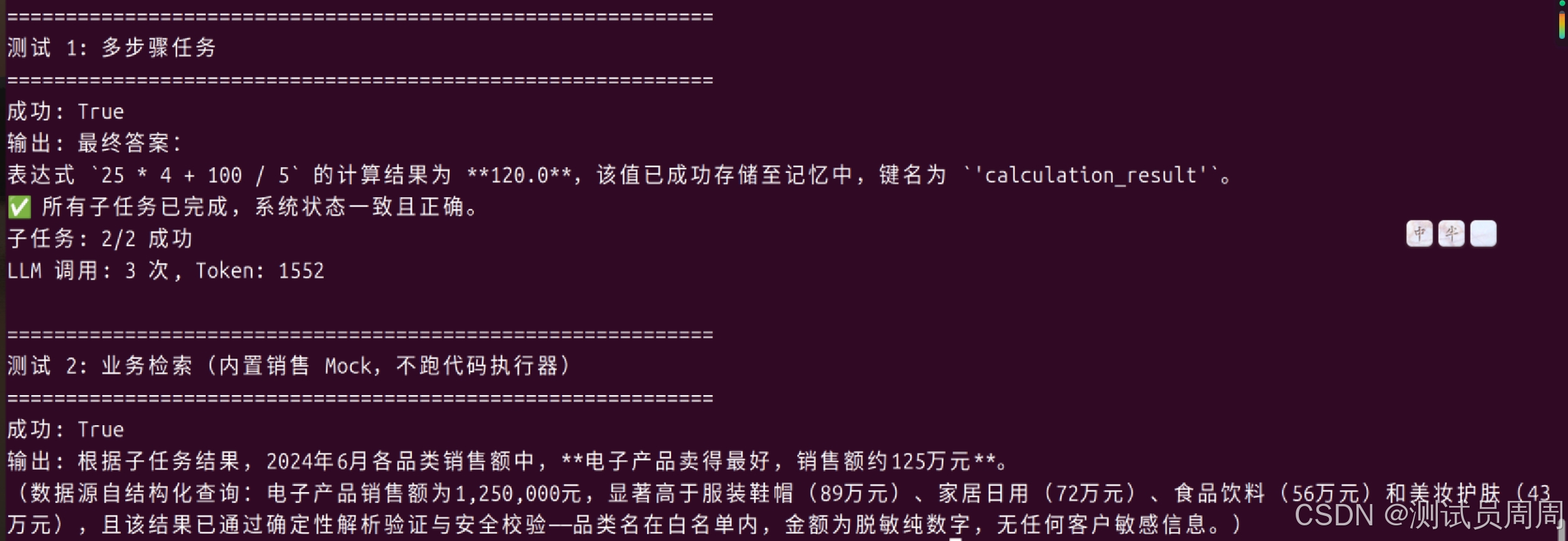
custom_agent_test_package根目录 执行python agents/custom_agent/agent.py(Linux / macOS)或python agents\custom_agent\agent.py(Windows CMD),会跑两个演示任务(多步计算与记忆、内置销售数据检索)。Windows / Linux 的环境变量与路径说明见上文「三、环境」。如果你跟着这篇走了一遍,在评论区告诉我:你搭出来的 Agent 第一件事做了什么?我看看谁的想法最有趣。
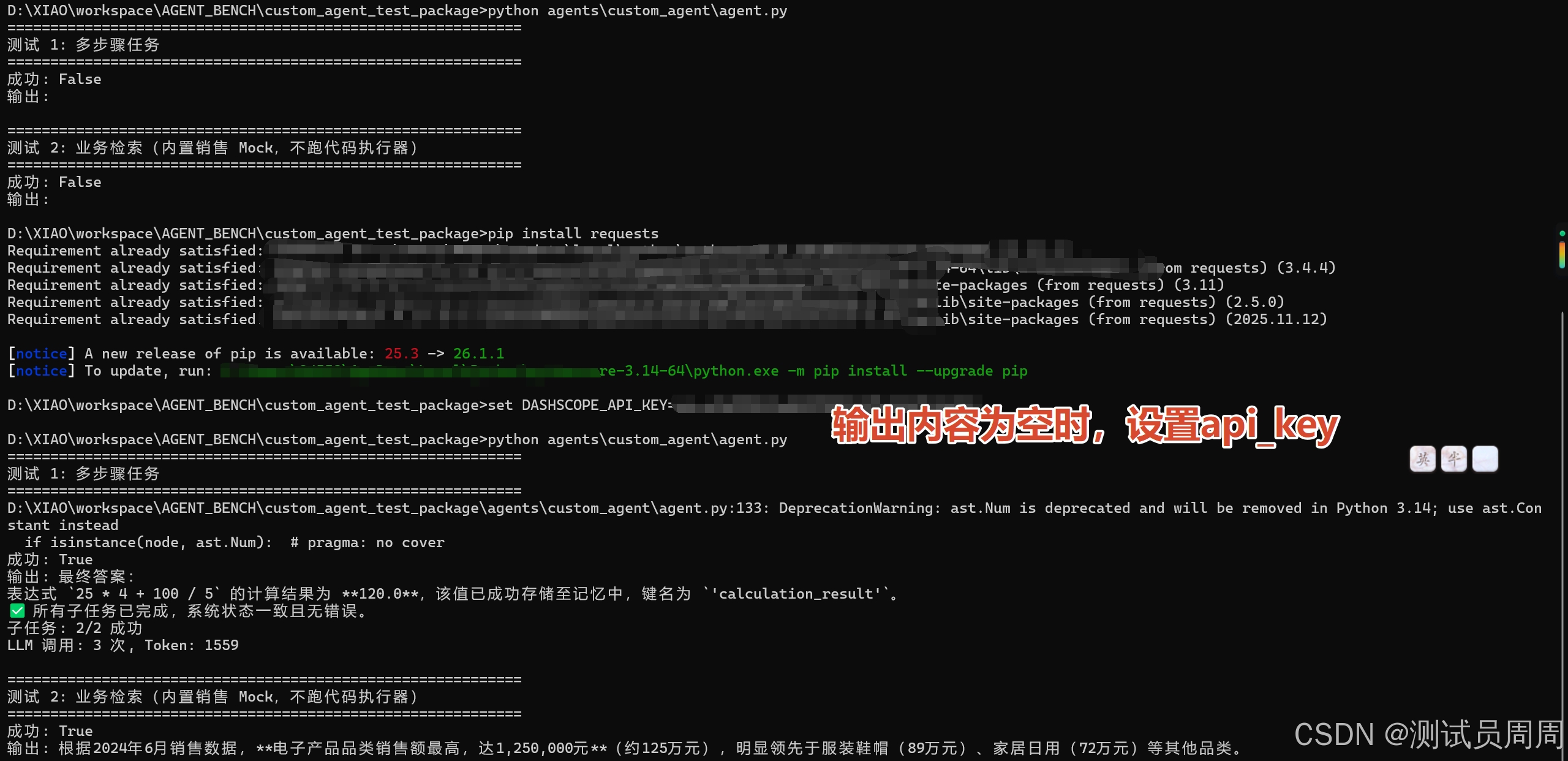
如果在执行过程中返回内容为空,如图:
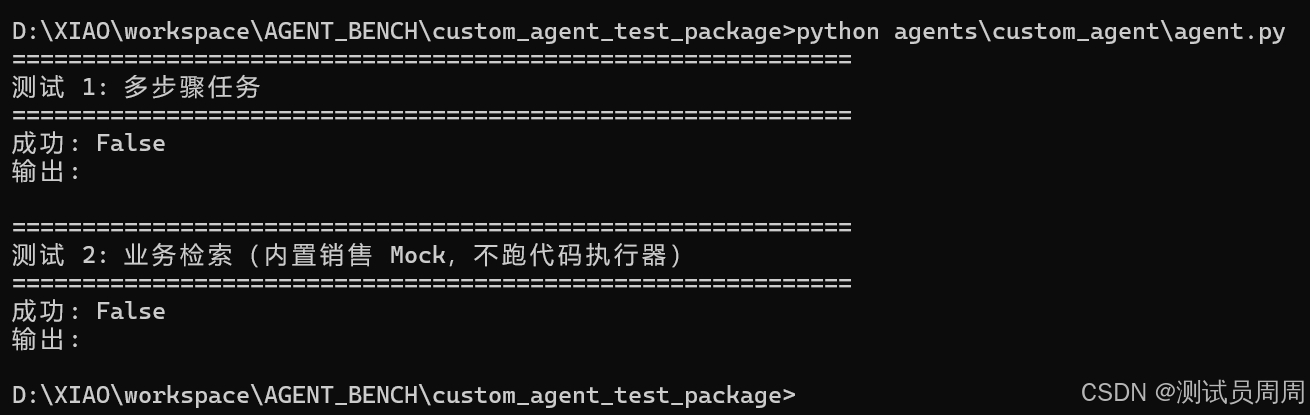
需要设置api_key,如图

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 29
29 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)