力大砖飞 - 本地大模型实现亿级错误日志的分析设计
1.问题场景:每天淹在告警里的SRE
真实困境(应该也是 99% 中国互联网公司的困境):
|
痛点 |
数字 |
|---|---|
|
生产日志量 |
300亿行/天 |
|
生产 ERROR 日志量 |
~2 亿行 / 天 / logstore |
|
SRE 实际能看的告警 |
几十条 / 天 |
|
关键词告警的误报率 |
> 90%("error" 关键词命中率太低) |
|
真告警被淹没的概率 |
极高,平均事故发现 = 用户先报障 |

传统三种思路都不够:
-
关键词告警:把 error / exception / 5xx 拉黑——误报炸群,SRE 屏蔽通知 → 真告警漏报。
-
走云端 LLM 做语义判断:一天几亿条全送 OpenAI / Claude 走一遍,按 Sonnet 4.6 价格算,单 logstore 单月 ¥30 万起步,且业务日志不允许出境。
-
自建 ELK + 规则引擎:能跑,但规则是死的,新错误出来还是要人去写。"系统越跑越准"在传统方案里根本不存在。
LogSense 的答案:让本地 LLM 只判"剩下的 2%",把 98% 用工程手段先压掉。
2.整体架构:把重活推给上游,让 LLM 只做最值钱的事
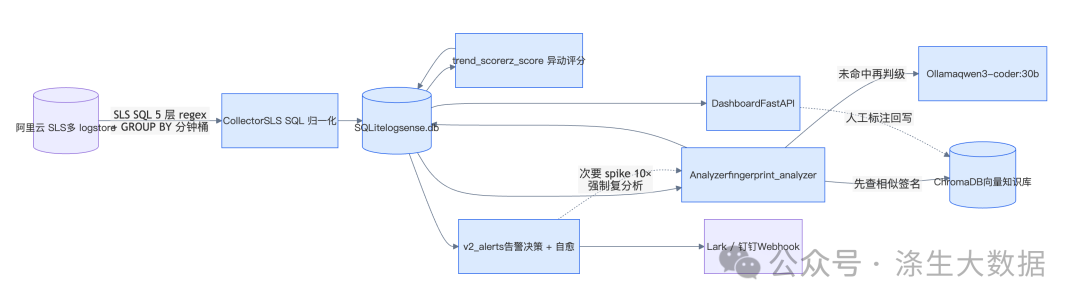
蓝色节点全部跑在一台 Mac mini 上。SLS 在云端、告警出口在 Lark,中间所有 AI 推理 / 向量检索 / 数据存储完全在内网,业务日志一行都不出公司。
这套架构有 4 个核心设计决策值得展开。
2.1 把"归一化"推给 SLS SQL 侧(架构最关键的一步)
反直觉的事实:让 LLM 看亿级原始日志是错的;让 LLM 看千级 unique signature 才是对的。
但如何"压"?答案不是写一个 Python 脚本本机跑——那要拉走 TB 级数据。正确做法是把归一化逻辑写进 SLS SQL,让阿里云的查询引擎在数据所在地直接干完。
LogSense 的 SLS SQL 大概长这样:
SELECT
regexp_replace(
regexp_replace(
regexp_replace(
regexp_replace(
regexp_replace(message,
'[a-f0-9]{8}-[a-f0-9]{4}-[a-f0-9]{4}-[a-f0-9]{4}-[a-f0-9]{12}', 'U'),
'\d+\.\d+\.\d+\.\d+', 'I'),
'[a-f0-9]{16,}', 'H'),
'[A-Za-z0-9]{20,}', 'T'),
'\d+', 'N'
) AS signature,
__tag__:_namespace_ AS ns,
floor(__time__ / 60) * 60 AS bucket_ts,
COUNT(*) AS cnt
FROM log
WHERE level = 'ERROR'
GROUP BY signature, ns, bucket_ts
ORDER BY cnt DESC
LIMIT 10000
5 层 regex 顺序是先复合(UUID/IP/hex/token)后原子(数字),顺序反了会把 ObjectID 拆碎,cardinality 爆炸。
效果:
Before (每条 log 都不一样):
User 507f1f77bcf86cd799439011 failed login from 192.168.1.42 → 503 attempt #147 req a3b8-11ee-9f...
After (收敛成一条 signature):
User H failed login from I → N attempt #N req U
单 logstore 实测:~10 亿 raw → ~170k unique signature,压缩比 5800×。
下游 Mac mini 接收的,每 5 分钟只有 ~10k-20k 行 (signature, namespace, 1-min 桶, count) 聚合行。本地处理压力直接降到笔记本能跑的量级。
这就是为什么 LogSense 能跑在单台 Mac mini 上——没有任何"AI 黑魔法",全是把活推到正确的地方。
2.2 Pareto 分层:让 LLM 只判 2% 的高价值 signature
170k unique signature 全送 LLM 还是太多。再切一刀:
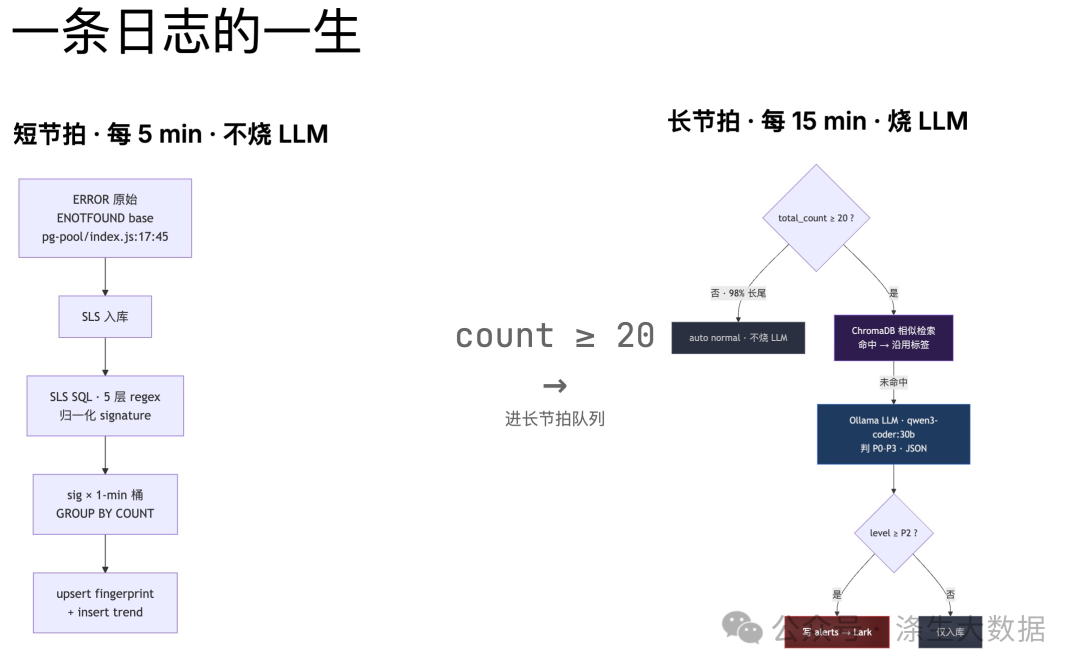
实测分布:
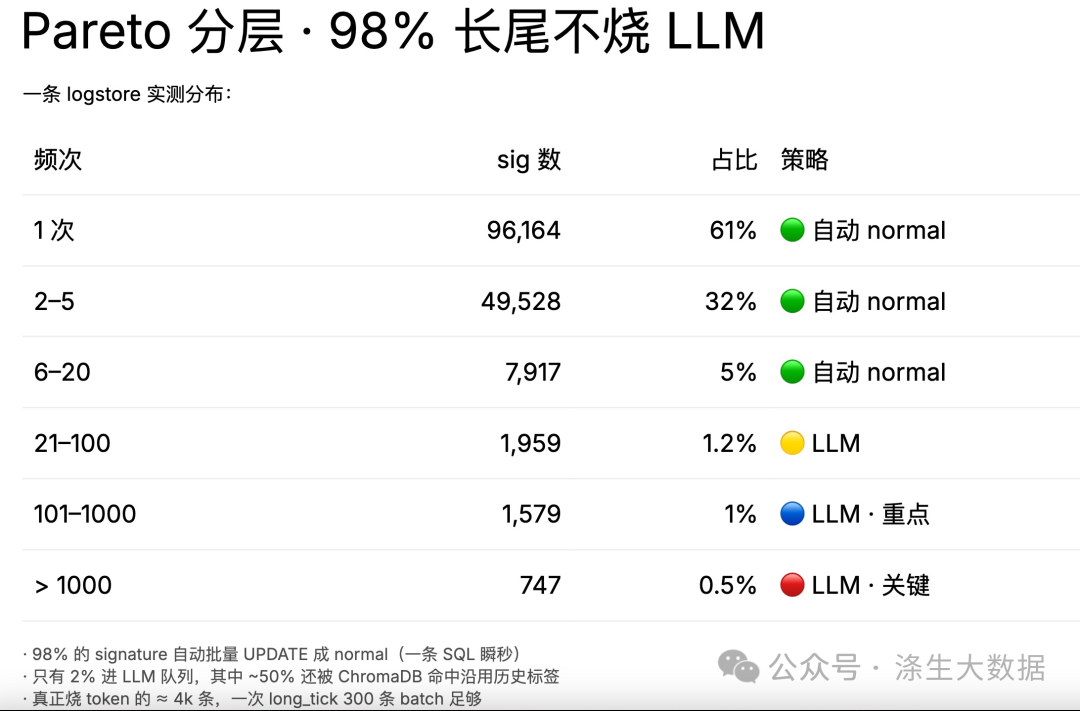
❝~158k → LLM 实际判 ~4k,再加上 ChromaDB 命中跳过 ~50%,最终真正烧 token 的不超过 2k 条 / 天。
按 qwen3-coder:30b 在 M4 Pro 上 2.8 s/次、parallel=4 估算,LLM 跑满负荷一天处理 ~12 万次,4k 条 = 4% 利用率,余量足够 30 倍业务增长。
2.3 LLM Backend 抽象:"4 个环境变量"工程化
这是本文最想强调的工程实践。LogSense 配置文件里有这么一段:
# .env
LLM_BACKENDS_JSON='{
"online_inference": {
"provider": "openai_compatible",
"base_url": "http://127.0.0.1:11434/v1",
"model": "qwen3-coder:30b",
"timeout_seconds": 120,
"parallelism": 4
},
"pre_labeling": {
"provider": "openai_compatible",
"base_url": "http://127.0.0.1:11434/v1",
"model": "gemma2:9b",
"parallelism": 8
}
}'
"provider + base_url + model + api_key"——和 Claude Code 那 4 个环境变量是同一个抽象。区别只是:
-
Claude Code 是给一个 CLI 工具用的,4 个 env var
-
LogSense 是给一个生产服务用的,3 个 task × 同样 4 个字段
切后端只改 JSON:
|
想用什么 |
base_url |
model |
备注 |
|---|---|---|---|
|
本地 Ollama |
http://127.0.0.1:11434/v1 |
qwen3-coder:30b |
默认推荐 |
|
Claude API(绕开后) |
https://api.anthropic.com |
claude-sonnet-4-6 |
provider 改 anthropic |
|
国内 DashScope |
https://dashscope.aliyuncs.com/ |
qwen-max |
走阿里云 |
|
DeepSeek |
https://api.deepseek.com/v1 |
deepseek-chat |
性价比高 |
|
自建 vLLM |
http://gpu-box:8000/v1 |
自训模型 |
全自主 |
今天本地 Ollama 够用就跑本地,明天有海外号了就接 Claude,后天合规允许就走 DashScope。业务代码一行不动。
2.4 自愈:让系统"对自己的判断保持怀疑"
LLM 判错怎么办?传统系统答案是"人工改规则"。LogSense 答案是让系统自己反悔。
trend_scorer 每 5 min 算一次 z_score = (current_count - mean_24h) / stddev_24h。
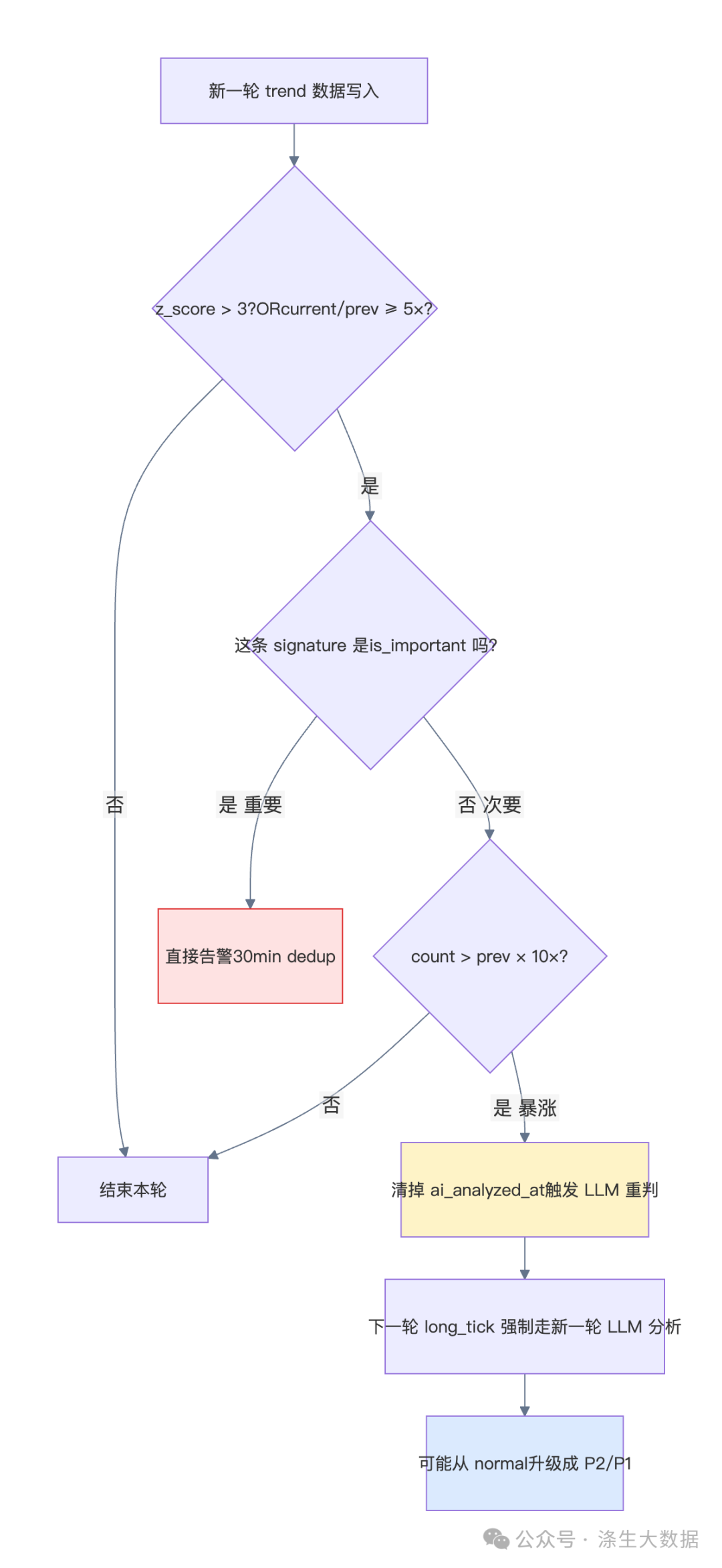
为什么这么设计:LLM 第一次判级时 count 可能还低、样本可能还平淡,标成 normal 完全合理。但真正的 P2 事故通常不是一出生就明显,而是演化到"暴涨 10 倍"时才显形。
给系统一个反悔的机会 = 告警召回率显著提高——这是上线第二个月加的逻辑,加完后漏报基本归零。
3.实战案例:一个生产事故是怎么被它发现的
讲一个真实例子(已脱敏):
2026-03-XX 凌晨 02:47,生产 Postgres 主库 IOPS 抖动,触发某个边缘服务的连接池超时重连风暴。
没有 LogSense 时的情景:
-
03:00 SRE 值班同事手机静音
-
03:30 客户开始反馈下单失败
-
03:45 客服电话打爆 SRE
-
04:00 排查发现是 DB IOPS 抖动连锁反应
-
MTTR ≈ 73 min,事故升级
有 LogSense 时的真实记录:
|
时间 |
事件 |
数据 |
|---|---|---|
|
02:47 |
服务首条 getaddrinfo ENOTFOUND ... ERROR |
1 条 |
|
02:48 |
同 signature count → 17 |
短节拍未触发(< 20) |
|
02:50 |
5min 短节拍:发现这条 signature current/prev = 23× |
触发"次要暴涨",清 ai_analyzed_at |
|
02:53 |
长节拍 LLM 重新判级:level=P1, reason="DB 连接池连续超时,疑似主库 IOPS / 网络抖动,需立即检查 RDS 监控" |
confidence=0.91 |
|
02:54 |
Lark 群机器人 @值班 SRE |
告警延迟 7 分钟 |
|
03:02 |
SRE 拉起来,发现 RDS 监控异常,切只读 + 限流 |
MTTR 15 min |
|
03:10 |
故障恢复,未升级到客户层 |
0 客诉 |
❝告警卡片案例
P1 · test-application-prod · order-service · 02:54
signature: getaddrinfo ENOTFOUND H at pg-pool/index.js:N:N
namespace: production
1-min count: 387 (↑ 23× vs 24h baseline 17)
z_score: 8.4
AI 理由: DB 连接池连续触发 ENOTFOUND,疑似主库
IOPS / 网络抖动;建议立即检查 RDS 监控 + 切只读。
历史相似: 2026-02-11 P1 (人工标注 = critical, 已修复)
详情: http://logsense.internal/catalog?hash=a3b8...
4.dashboard页面展示
为方便debug和协助展示,提供部分页面的查询。

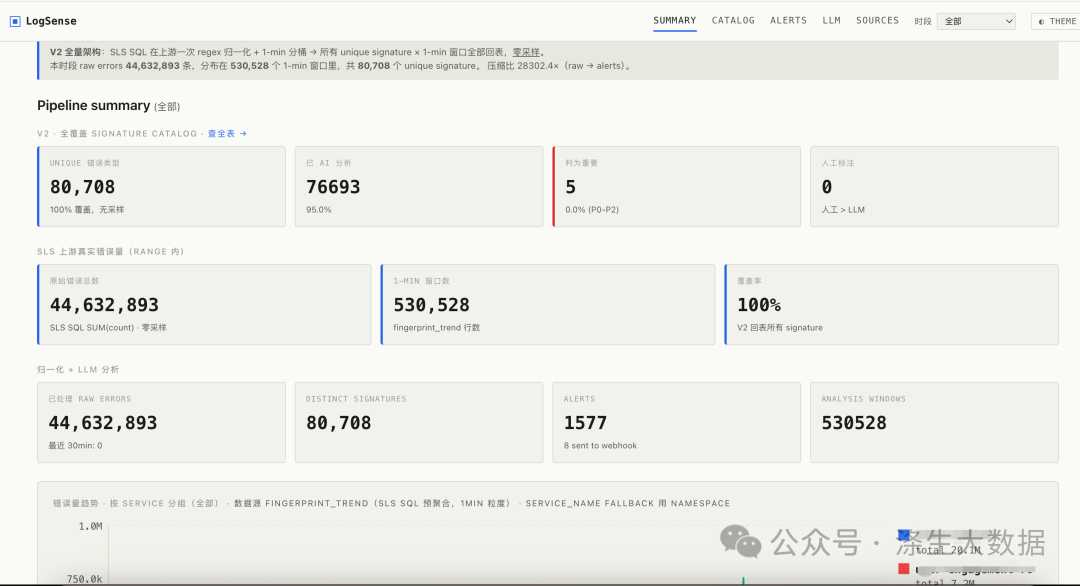
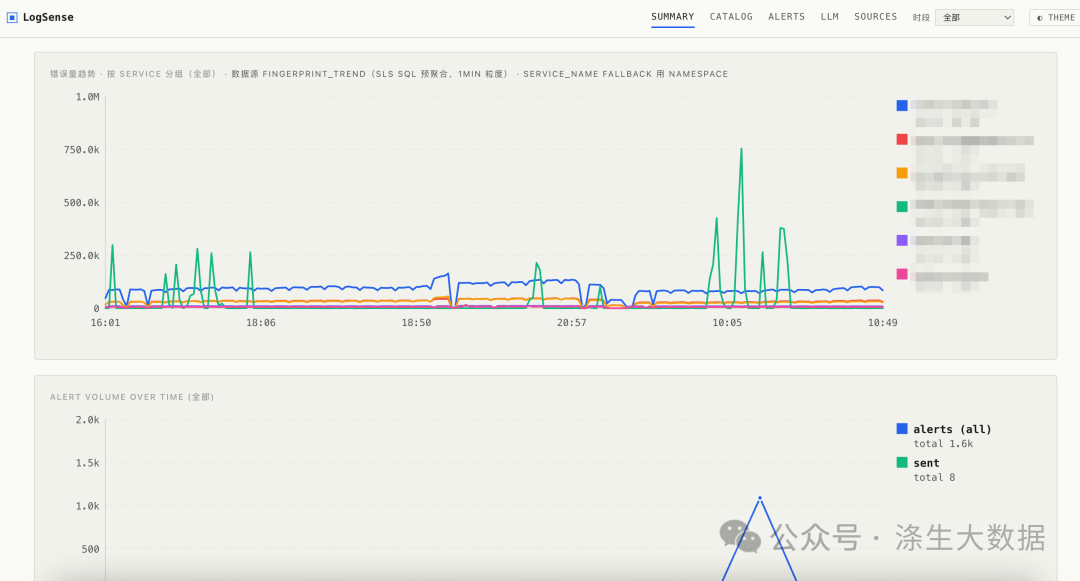
4.1 整体运行统计
数据为测试案例部分数据,截图只为展示效果。这里统计真正运行的整体统计信息。
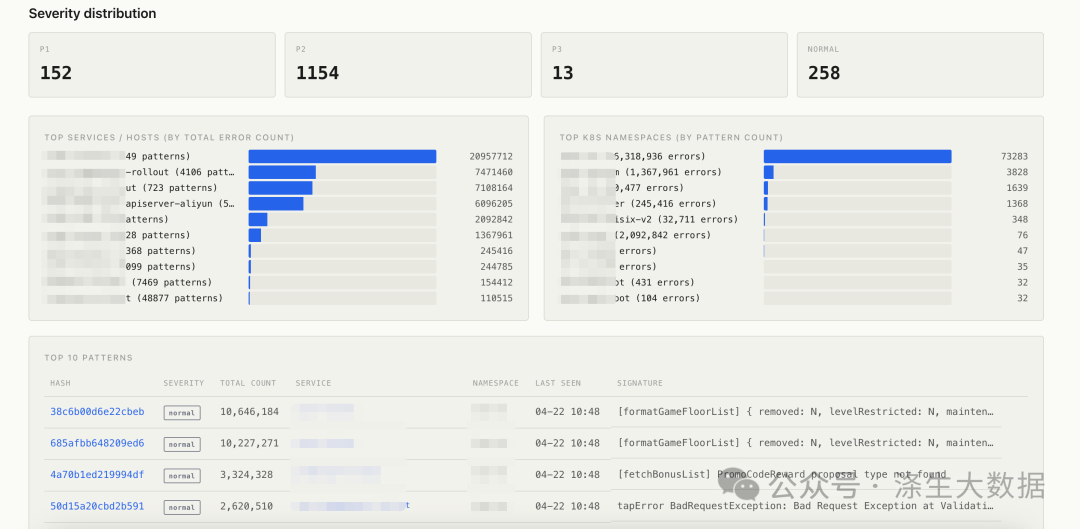
4.2 日志错误通过LLM分析后分类结果统计
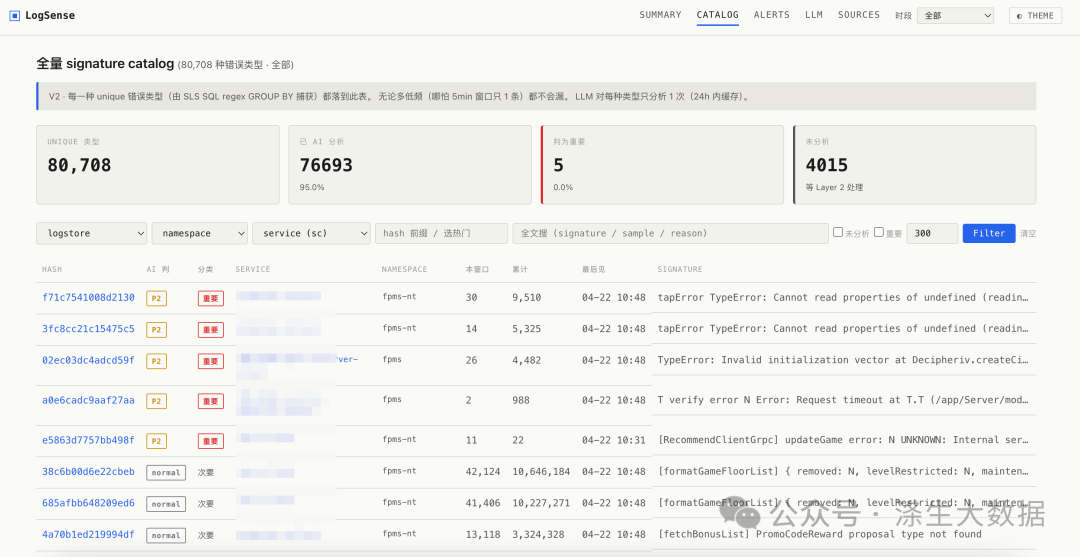
对应的单个错误日志信息
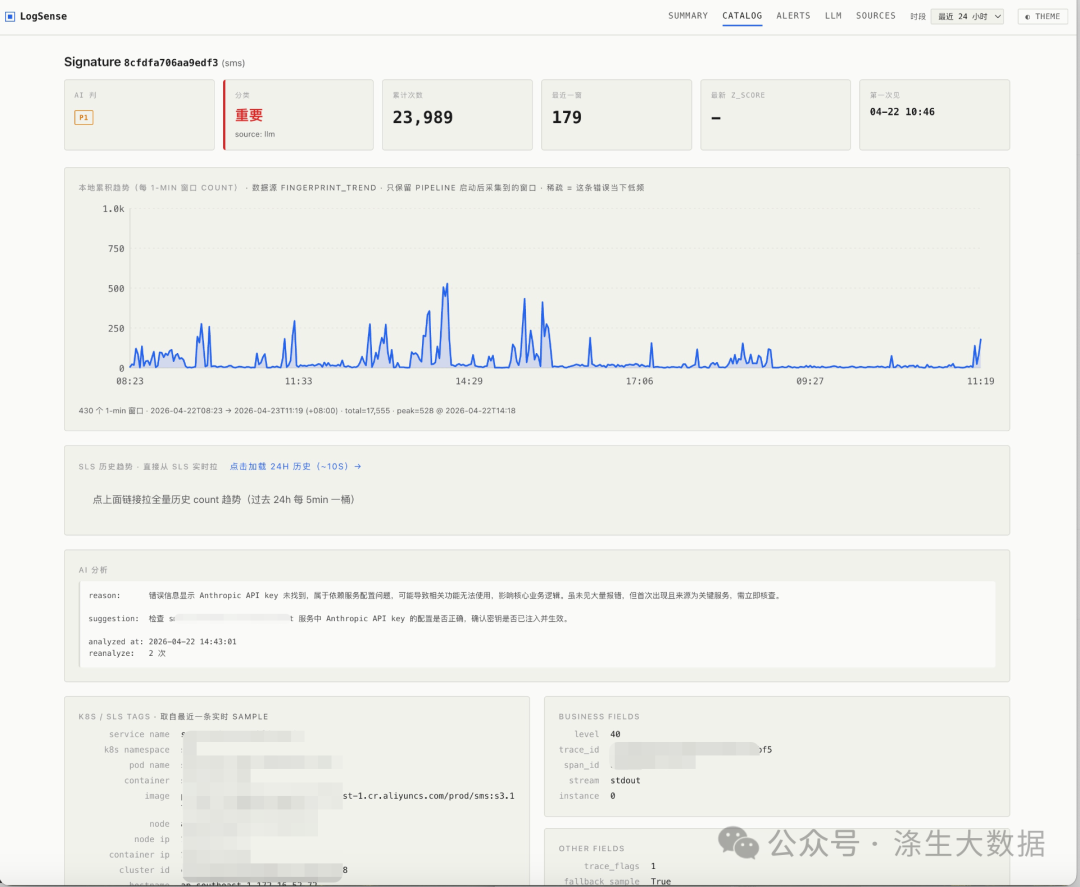
4.3 告警信息
通过错误级别和趋势变化,触发告警
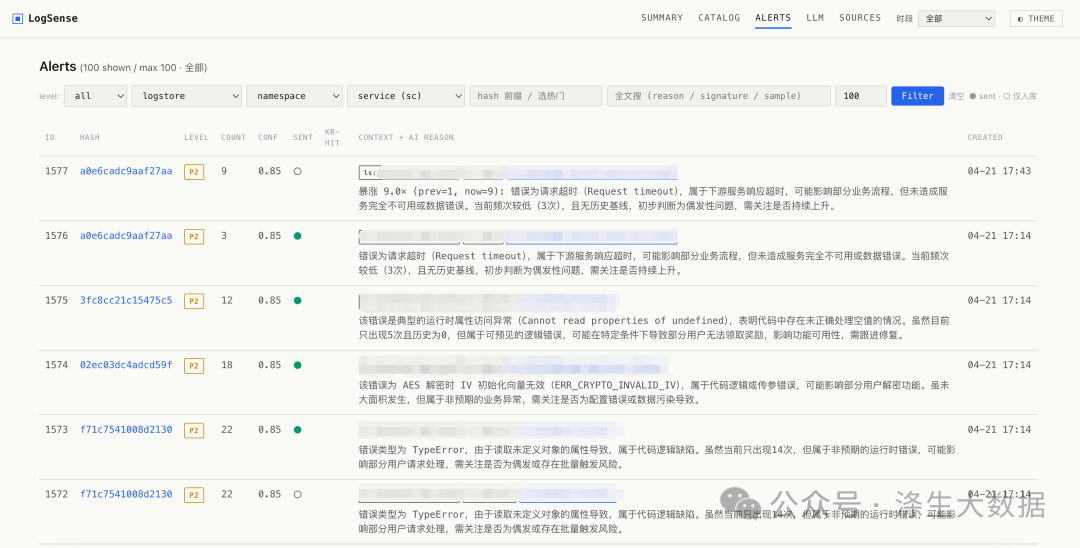
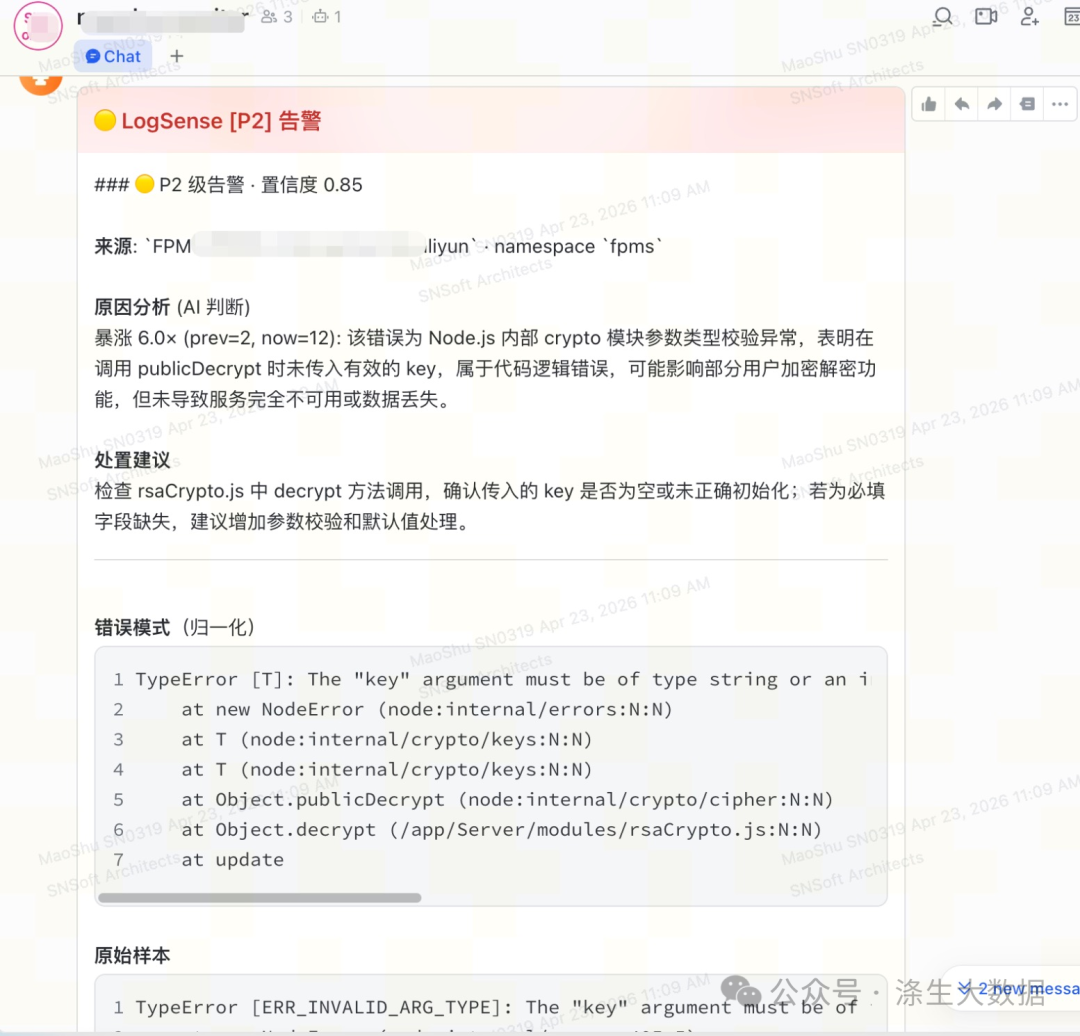
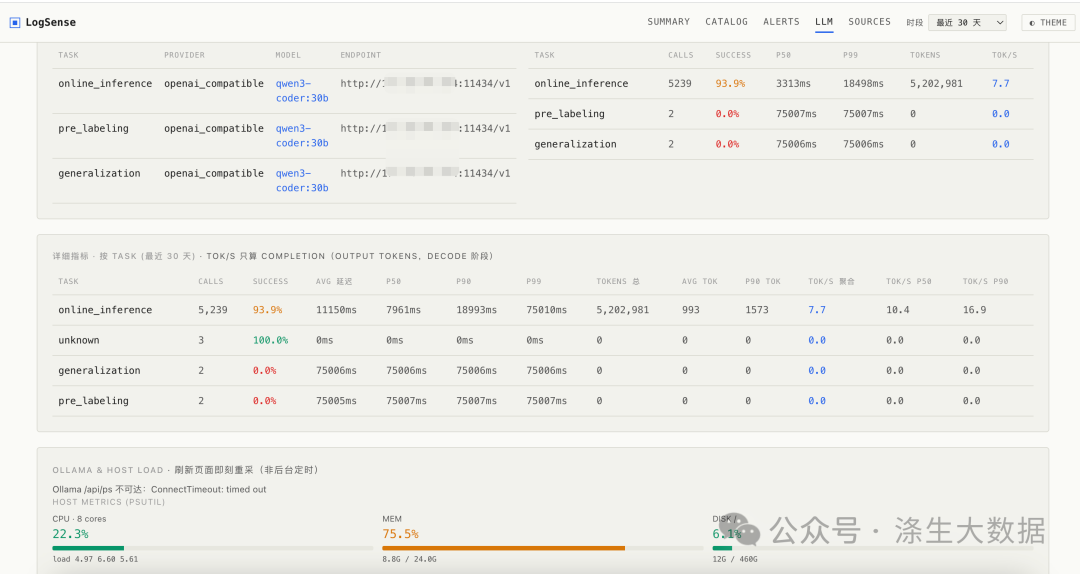
4.4 运行情况自检
做了一个辅助监控,查看系统运行状态。(补充小秘密:我是为了让老板查看效果和性能瓶颈,给我买GPU我才做的。最后我梦想成真了(Mac studio 256G))
数据为本地研发环境,非实际Mac Mini的,但是看到token 和使用率就够了,效果差不多。
5.关键技术
懒得写,我贴的汇报时候的ppt(claude design 生产的slides)。
5.1 关键技术汇总:7个关键参数

5.2 正则归一化

5.3 异常检测 + 自愈重分析

5.4 计算结果存储分层

总结:本地大模型不是"妥协",是"解耦"
当你接受了"LLM 后端可换"这个抽象,本地模型就不再是云端模型的次品备份,而是工程系统里一个独立、可调度、可控的计算资源。
它的特点是:
-
稳定:不会突然限流、不会突然涨价、不会突然下架某个 model 名
-
可控:超时、重试、并发数你说了算,不被供应商 SLA 绑架
-
零边际成本:一次性的 Mac mini 投入之后,跑多少都是电费
-
合规天然过关:业务数据物理上没出过办公室
代价是:你要承担把 LLM 集成进系统的工程责任——上游怎么压数据、prompt 怎么写、知识库怎么沉淀、出错怎么自愈。
但这恰恰是企业 AI 系统的护城河——一份 OpenAI Key 别人也能买,一套基于本地 Ollama + 业务数据 + 持续标注的 AIOps 系统,是你公司独有的资产。
LogSense 现在每天 7×24 跑在那台 Mac mini 上,TPS 比刚上线时翻了 2 倍,告警准确率从 60% 爬到 87%,运行成本依然是 ¥0。
这套思路在公司里能复制到很多地方:客服工单分级、风控信号聚类、合规审查初筛、内部知识问答……只要你的"原始数据 → 干净 signature"这一步能用工程方法压下来,本地 30B 模型就够用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)