AKS:长视频理解的自适应关键帧采样
多模态大型语言模型(MLLMs)通过将视觉输入作为额外标记注入大型语言模型(LLMs)的上下文,实现了开放世界的视觉理解。然而,当视觉输入从单张图像变为长视频时,上述模式会遇到困难,因为大量的视频标记已显著超出了多模态大型语言模型的最大容量。因此,现有的基于视频的多模态大型语言模型大多是通过从输入数据中采样一小部分标记来构建的,这可能导致关键信息丢失,从而产生错误的答案。本文提出了一种简单而有效的算法,名为自适应关键帧采样(AKS)。它插入了一个名为关键帧选择的即插即用模块,旨在以固定数量的视频标记最大化有用信息。我们将关键帧选择表述为一个优化问题,涉及(1)关键帧与提示之间的相关性,以及(2)关键帧对视频的覆盖范围,并提出了一种自适应算法来近似最佳解决方案。在两个长视频理解基准上的实验证实,AKS通过选择信息丰富的关键帧,提高了视频问答的准确性(超过了强大的基线模型)。我们的研究揭示了信息预过滤在基于视频的多模态大型语言模型中的重要性。我们的代码可在https://github.com/ncTimTang/AKS获取。
一、为什么需要AKS?
基于图像的多模态大语言模型(MLLMs)的典型框架包括将输入图像编码为一组视觉令牌,并将其作为大语言模型(LLMs)的上下文输入。当这一框架被移植到视频(尤其是长视频)时,由于多模态大语言模型的容量有限,出现了一个难题,即多模态大语言模型能够处理的最大视觉令牌数量远少于整个视频的令牌数量;换句话说,并非所有视频令牌都能被多模态大语言模型感知。并且其性能很大程度上依赖于所选关键帧的质量。然而关键帧选择算法的均匀采样策略容易丢失重要信息,从而导致视频理解的输出结果不正确。根据此,提出了AKS以实现视频理解的最佳实践。
二、AKS 算法核心设计:兼顾相关性与覆盖度
- 两大核心优化目标
- 相关性(即关键帧与问题的关联程度)
- 覆盖率(即关键帧对整个视频中有用的信息的覆盖程度)
- 方法的整体框架
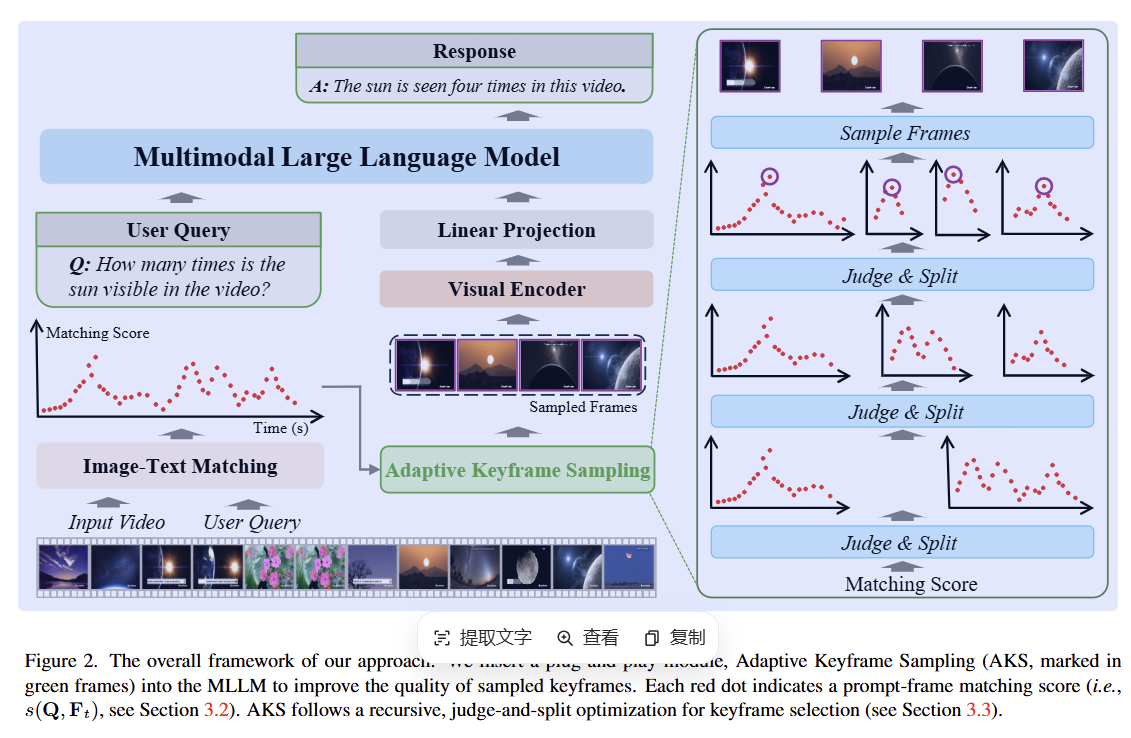
图2. 在多模态大语言模型中插入了一个即插即用模块——自适应关键帧采样(AKS,绿色框标记),以提高采样关键帧的质量。
每个红点表示一个提示-帧匹配分数(即 s(Q,Ft)s(Q, F_{t})s(Q,Ft))。AKS采用递归的“判断-分割”优化进行关键帧选择。
3. 关键帧的选择原则
关键帧选择函数,作用是从视频的所有帧中挑选出 M个关键帧。
- KSM(Q,F)=argmax∣I∣=MG′({Ft∣t∈I}).(1) KSM(Q, F) = \arg\max_{|\mathcal{I}|} = MG'(\{F_t | t \in \mathcal{I}\}). (1) KSM(Q,F)=arg∣I∣max=MG′({Ft∣t∈I}).(1)
在此,我们假设G′(⋅)G'(\cdot)G′(⋅)是G(⋅)G(\cdot)G(⋅)的互补函数,用于表示多模态大语言模型(MLLM)对其输出的置信度。式(1)在数学上难以求解,原因有二。首先,该优化涉及数量呈指数级增长的I候选值。其次,也是更重要的一点,函数G′(⋅)G'(\cdot)G′(⋅)难以估计,因为关键帧的选择缺乏监督——即便有训练集可用,且能够将G(⋅)G(\cdot)G(⋅)的输出与真实答案进行比较,也无法保证正确的答案就对应着一组完美的关键帧,反之亦然。
我们提出了一种启发式方法来近似公式(1)。直观地说,当满足以下条件时,一组关键帧是具有信息量的。(1)每个帧与提示之间的相关性较高,即视觉数据是有助于问答。(2)所选帧的覆盖范围足以全面回答问题。请注意,覆盖范围难以量化,第二条原则与防止选择冗余帧(e.g.,即视觉内容几乎相同的相邻帧)密切相关,因为(当∣I∣|I|∣I∣的大小固定时)它们可能会减少其他有用信息的数量,从而损害整个关键帧集的覆盖范围。
- 则可以得到:
KSM(Q,F)=argmax∣I∣=M∑t∈Is(Q,Ft)+λ⋅c(I).(2) KS_M(Q, F) = \arg\max_{|\mathcal{I}|=M} \sum_{t \in \mathcal{I}} s(Q, F_t) + \lambda \cdot c(\mathcal{I}). \quad (2) KSM(Q,F)=arg∣I∣=Mmaxt∈I∑s(Q,Ft)+λ⋅c(I).(2)
这是AKS里“选关键帧”的目标函数,用来定义怎么挑选出最好的M个关键帧。
KSM(Q,F)KS_M(\mathbf{Q}, \mathbf{F})KSM(Q,F)在提示词Q和所有视频帧的视觉令牌F中,选出 M 个关键帧的最优结果
argmax∣I∣=M\arg\max_{|\mathcal{I}|=M}argmax∣I∣=M从所有包含M个帧的集合I里,挑选出能让后面式子结果最大的那个集合
∑t∈Is(Q,Ft)\sum_{t \in \mathcal{I}} s(\mathbf{Q}, \mathbf{F}_t)∑t∈Is(Q,Ft) 每一帧和提示词Q的相关性得分之和,得分越高越能更好的契合问题
计算 s(Q,Ft)s(Q, F_{t})s(Q,Ft) 这涉及到一个视觉-语言(VL)模块,用于衡量 FtF_{t}Ft 是否包含回答Q的信息。尽管目标多模态大语言模型(MLLM)本身 G(⋅)G(\cdot)G(⋅) 可以发挥作用,但其高昂的计算成本会带来重大负担。在实践中,我们选择一个更廉价的VL模型(例如,CLIP [32] 或 BLIP ITM [16])来替代。
- 如何计算覆盖度?
测量覆盖率是一个开放问题,这与数据分布的均匀性有关。在数学中,里普利K函数[33]是一种常用的测量均匀性的方法。给定时间戳集III和任何搜索半径r<Tr<Tr<T,rrr的K函数,记为K^(r)\hat{K}(r)K^(r),与满足∣ti−tj∣<r| t_{i}-t_{j} |<r∣ti−tj∣<r的(ti,tj)(t_{i}, t_{j})(ti,tj)对的数量成比例。如果K^(r)\hat{K}(r)K^(r)近似与r2r^{2}r2成比例,则III的分布被认为是均匀的(即覆盖整个时间轴)。
通过递归划分时间区间,确保关键帧在时间轴上分布均匀,减少冗余。
4. 自适应关键帧采样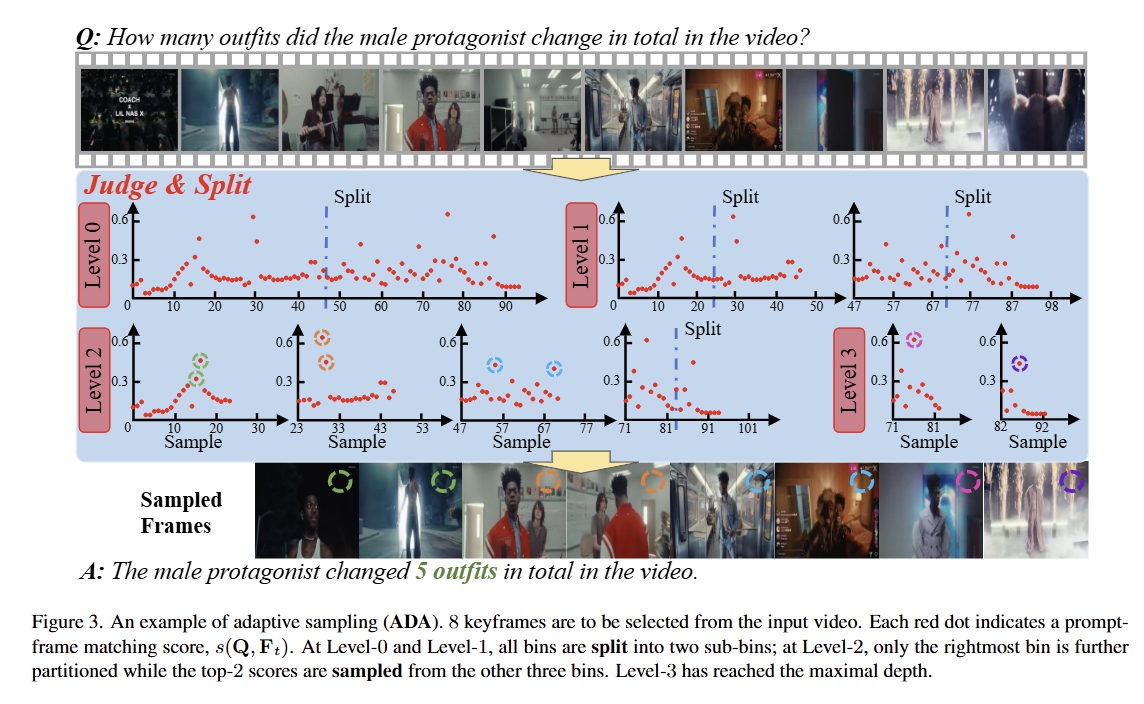
-
由于c(I)c(I)c(I)的定义复杂,很难为式(2)找到闭式解或精确的优化方法。本部分将讨论一种近似方法。与仅依赖s(Q,Ft)s(Q, F_{t})s(Q,Ft)分数的基线方法相比,我们将此类方法称为时间戳感知优化,因为它能够考虑时间戳,从而获得更好的关键帧选择结果。
-
两种极端情况的采样策略
- TOP(顶部采样)
- 对应λ=0\lambda=0λ=0(完全不管覆盖度),直接选相关性得分最高的前 MMM 帧;
- 缺点:关键帧会集中在某一小段时间里,模型容易漏掉其他时段的重要信息。
- BIN(区间采样)/UNI(均匀采样)
-
对应λ→+∞\lambda \to +\inftyλ→+∞(严格保证覆盖度),把视频分成多个区间,每个区间选得分最高的帧;
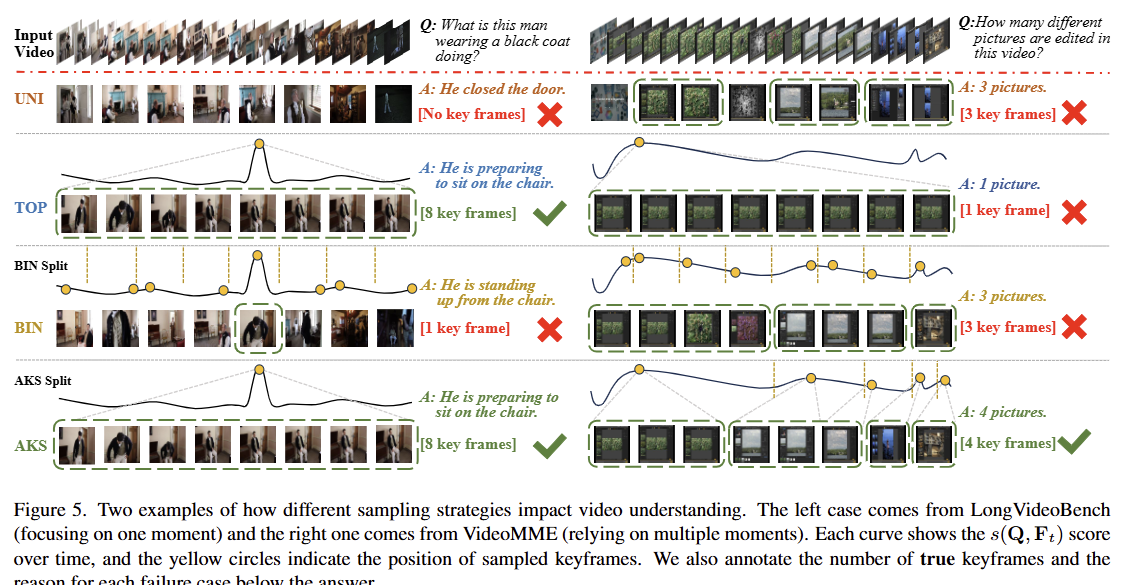
图五对比了不同采样策略对视频理解结果的影响,核心是展示 AKS 策略的优势。 UNI:均匀但不相关,容易漏关键信息; TOP:相关但集中,容易漏其他内容; BIN:覆盖但选帧少,信息不足; 而AKS 能同时兼顾 “相关性” 和 “覆盖度”,所以在两种场景下都能得到正确回答。
- 中间情况的自适应采样:ADA
当 0<λ<+∞0<\lambda<+\infty0<λ<+∞(同时兼顾相关性和覆盖度)
-
- 第一层级,我们确定如何将MMM个关键帧分配到两个容器中,即[0,T/2)[0, T / 2)[0,T/2)和(T/2,T)(T / 2, T)(T/2,T)。我们调用所有帧的相关分数s(Q,Ft)s(Q, F_{t})s(Q,Ft),计算所有帧的平均分数(记为salls_{\text{all}}sall)以及分数最高的MMM个帧的平均分数(记为stops_{\text{top}}stop)。如果只需选择一个关键帧,或者stop−salls_{\text{top}}-s_{\text{all}}stop−sall超过阈值sthrs_{\text{thr}}sthr,我们认为保证对得分最高的帧进行采样至关重要(即最大化公式(2)的第一项),因此该算法直接返回得分最高的MMM个帧作为关键帧。否则,我们将当前容器分割为两个子容器,并平均分配关键帧数量(即最大化公式(2)的第二项),然后在子容器中递归调用上述程序。我们将此策略命名为ADA,即“自适应采样”的缩写。请注意,超参数λ\lambdaλ并未进行显式调整,其作用由sthrs_{\text{thr}}sthr替代。
三、实验
- 与其他技术的比较
-
结果汇总于表1中。AKS相比三个基线模型带来了稳定的准确率提升,例如,在Qwen2VL上,LongVideoBench的提升为5.0%,VideoMME的提升为2.3%;即使在最强的基线模型LLaVA-Video上,这些数值分别为3.8%和0.9%。这些改进不仅使我们的方法超越了其他具有相似计算复杂度的竞争者(即输入不超过64帧,大语言模型不大于70亿参数),还使其能够达到更大模型所设定的更高水平(例如,借助AKS,LLaVA-Video-7B在LongVideoBench上的得分达到62.7%,比不使用AKS的LLaVA-Video-72B模型高出0.8%,比GPT-4V和Gemini1.5-Flash这两个使用256帧输入的专有模型分别高出1.4%和1.1%)。
- Method:所测试的模型 / 方法(“w/ AKS” 代表在原模型基础上加入了自适应关键帧采样模块);
Frames:模型输入的关键帧数量;
LLM:模型所基于的大语言模型参数量(如 7B 代表 70 亿参数);
LVB val:在 LongVideoBench 验证集上的得分;
V-MME:在 VideoMME 测试集上的得分(分数越高,视频理解效果越好)。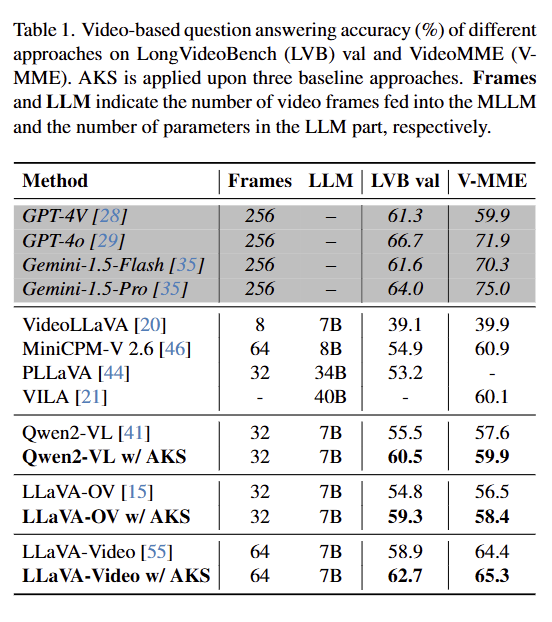

在图4中,我们展示了AKS(基于LLaVAVideo-7B)及其他方法具有代表性的视频理解结果。可以看到,所选关键帧与问题密切相关;这使得具有有限上下文容量的多模态大语言模型(MLLM)能够全面了解与问题相关的内容,从而得出正确答案。顺便说一句,我们发现VideoMME包含许多需要对视频内容进行高层次理解的问题,在这些问题中,均匀采样是一种安全的选择;尽管如此,AKS仍然能找到更多信息丰富的帧并提高准确率,尽管其增益小于在LongVideoBench上的增益。
2. 关键帧选择诊断
本部分旨在分析AKS的工作原理,并对其设计选择进行消融实验。我们基于最强的基线模型LLaVA-Video构建测试。
多模态大语言模型(MLLMs)受益于更好的关键帧。为了展示关键帧选择如何影响视频理解,我们测试了3.3节中描述的不同策略。表2列出了结果。
- UNI(基线策略):LongVideoBench val 得 58.9,VideoMME 得 64.4
- TOP:LongVideoBench val 得 62.4,VideoMME 得 63.7
- BIN:LongVideoBench val 得 60.2,VideoMME 得 65.2
- ADA:LongVideoBench val 得 62.7,VideoMME 得 65.3(两个基准均为最优)
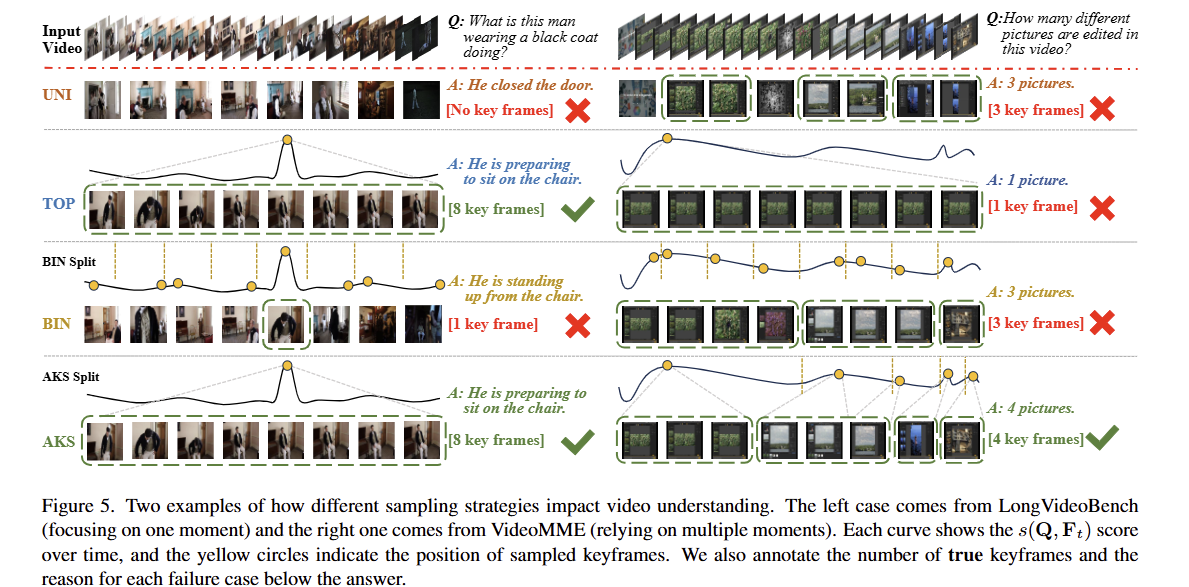
图5展示了两个例子来解释LongVideoBench和VideoMME中问题的风格差异,以及这种差异如何导致模型的答案。
ADA采样吸收了TOP和BIN策略的优点,并能自适应地将关键帧分配到所需位置(见图3中的示例)——这就是它在两个基准测试中都能取得最佳结果的原因。图6展示了AKS 关键帧选择策略的灵活性。对同一个输入视频,AKS 会根据不同的问题选择不同的关键帧集。这提高了冻结的多模态大语言模型(MLLM)适应不同场景的灵活性。
- Method:所测试的模型 / 方法(“w/ AKS” 代表在原模型基础上加入了自适应关键帧采样模块);
四、消融实验
-
为了降低AKS带来的额外计算成本,我们采样更少的关键帧候选(即每2/4/8/10秒一帧,并将结果与标准的1帧/秒方法进行比较。结果汇总于表3中。
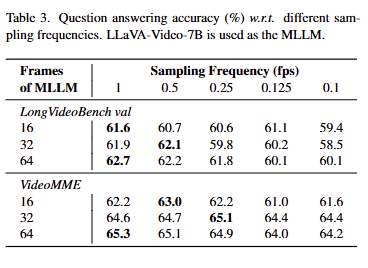
在LongVideoBench上,即使帧率为0.1 fps,所有结果也都高于基线(即16、32、64帧时分别为57.4%、57.9%、58.9%)。
VideoMME呈现出类似的趋势,0.25 fps似乎是一个能超过基线的稳妥选择。值得探索更高效的预过滤算法,以在准确性和效率之间实现更好的平衡。 -
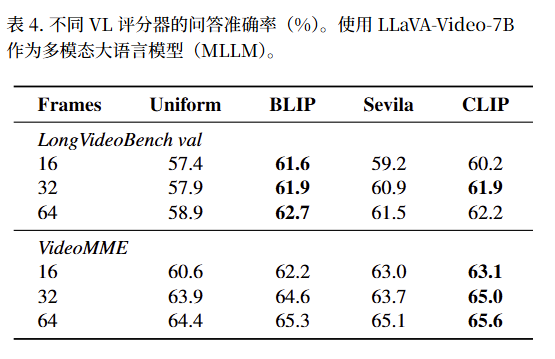
用于计算 s(Q,Ft)s(Q, F_{t})s(Q,Ft) 分数的VL模型。我们分析了使用不同VL模型计算提示-帧相关性的影响。我们研究了三种选择,即BLIP[16](本文中的默认选择)、Sevila(在[47]中使用)和CLIP[32]。结果汇总于表4。
- 行:两个测试集(LongVideoBench val、VideoMME)
- 列:不同的 “VL 评分器”
- 所有评分器(BLIP/Sevila/CLIP)的准确率,都明显高于基线Uniform(比如 LongVideoBench val 的 64 帧下,Uniform 是 58.9,BLIP 是 62.7)。
- 在LongVideoBench val(任务侧重 “对象动作”):BLIP 效果最好(比如 64 帧下准确率 62.7,高于 Sevila 的 61.5、CLIP 的 62.2);
- 在VideoMME(任务侧重 “全局场景 / 多内容感知”):CLIP 效果最好(比如 64 帧下准确率 65.6,高于 BLIP 的 65.3、Sevila 的 65.1)。
- ADA超参数LLL和sthrs_{\text{thr}}sthr。最后,我们研究了LLL和sthrs_{\text{thr}}sthr的影响。结果总结在表5中。可以看出,与VideoMME相比,LongVideoBench更偏好较小的LLL和sthrs_{\text{thr}}sthr值。这是因为LongVideoBench上的关键信息更为集中(即许多问题与单个时刻相关),而VideoMME上的关键信息则更为多样(问答需要多时刻数据)。AKS具有灵活切换不同“模式”的能力,并在两个数据集上都取得了更好的结果。

五、结论
本文聚焦于提升多模态大语言模型(MLLMs)的长视频理解能力。主要难点在于多模态大语言模型的容量有限,这促使我们向模型输入包含丰富信息的视觉令牌。为此,我们提出了自适应关键帧采样(AKS)算法,该算法
(1)利用视觉-语言模型来估计相关性,
(2)应用自适应优化算法以提高所选关键帧的覆盖率。
定量和定性研究验证了其有效性。在不同的基线和基准上进行AKS。我们的研究表明,预过滤阶段为视频理解带来了显著益处,并倡导在这一方向上开展进一步研究。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)