Stable Mean Teacher for Semi-supervised Video Action Detection:用于半监督视频动作检测的稳定均值教师模型
Stable Mean Teacher for Semi-supervised Video Action Detection:用于半监督视频动作检测的稳定均值教师模型
一、研究背景与核心痛点
- 视频动作检测除了需要进行分类外,还要求实现时空定位,而有限的标签数量会导致模型容易做出不可靠的预测
- 现有的时空损失函数没有考虑时间连贯性,容易导致时间上的不一致
二、本文创新点
- 提出了稳定均值教师(Stable Mean Teacher)框架,这是一种简单的基于师生结构的端到端框架,它得益于经过改进且具有时间一致性的伪标签。
- 提出了一种新颖的错误恢复(EoR)模块,该模块从学生的错误中学习,并帮助教师在标记样本有限的情况下提供更好的监督信号。
- 提出了像素差异(DoP)约束,这是一种简单且新颖的、专注于时间一致性的约束,能够实现连贯的时间检测。
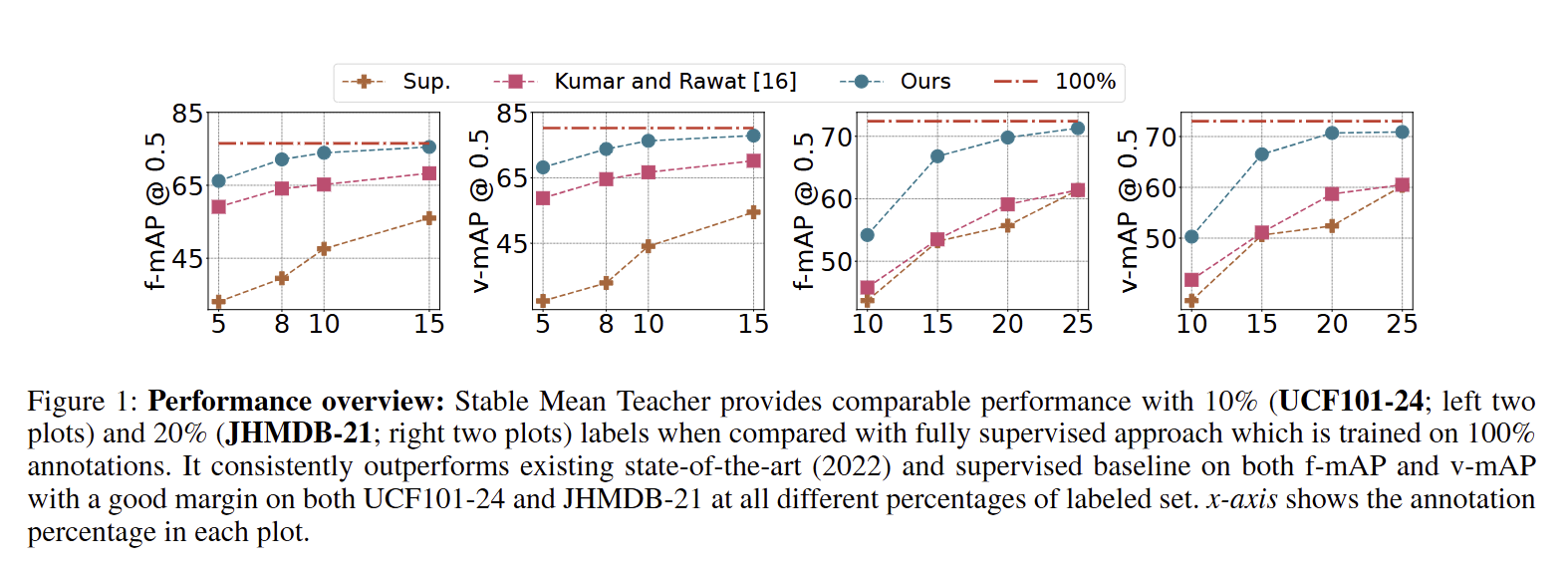
-
Sup.(棕色叉线):仅用当前比例标注数据训练的有监督基线模型
-
Kumar and Rawat [16](红色方块线):2022 年的半监督 SOTA 方法
-
Ours(蓝色圆点线):本文提出的Stable - Mean Teacher方法
-
100%(红色虚线):用 100% 标注数据训练的全监督模型(性能上限参考)
-
X轴:标注数据占比
-
Y 轴:评价指标(f-mAP@0.5:空间定位精度;v-mAP@0.5:时空联合精度)
-
结论:
- 少标签可以接近全监督的水平
- 蓝线明显更高,稳定超越对比方法
- 无论是侧重空间定位的f-mAP,还是侧重时空联合v-mAP,Ours 都保持领先,说明 EoR 和 DoP 模块同时提升了空间精度和时间连贯性。
三、具体方法
Stable Mean Teacher(SMT) 方法概述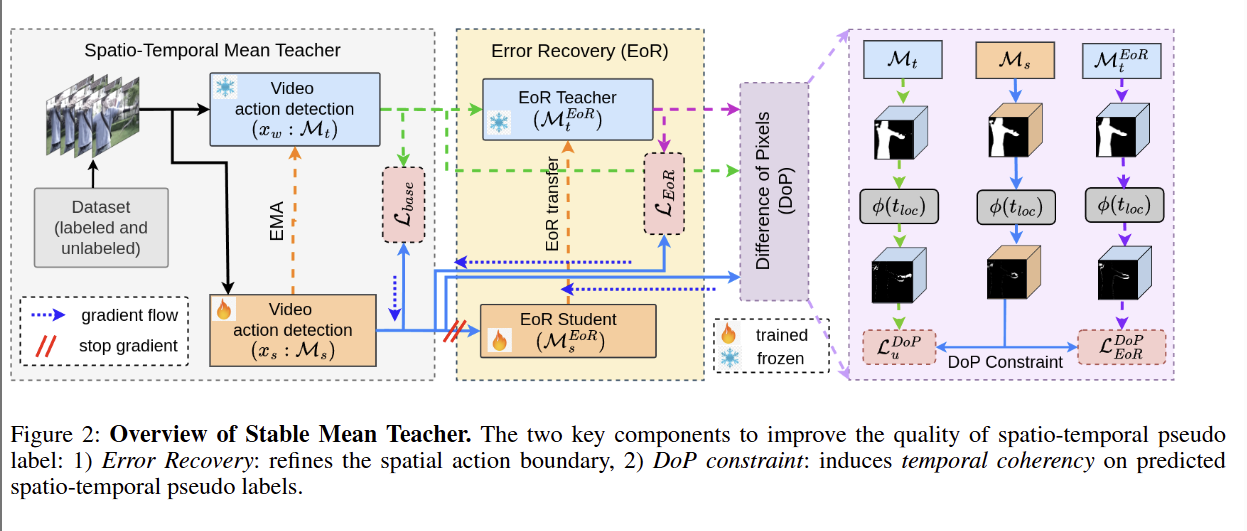
- 基础模型(左侧灰色)
处理的是半监督视频动作检测任务:
-
输入:
- 带标签样本 XLX_LXL:包含视频 x、动作类别标签 y、帧级时空标注 f
- 无标签样本 XUX_UXU:只有视频 x
-
输出:动作分类 + 时空定位的模型 M
-
教师模型 MtM_tMt,冻结状态:处理弱增强视频 xwx_wxw,生成伪标签
-
学生模型 MsM_sMs,训练状态:处理强增强视频 xsx_sxs,学习教师的伪标签和真实标签
-
参数更新:
教师参数通过学生参数的 EMA(指数移动平均)平滑更新:
θteacher=βθteacher+(1−β)θstudent \theta_{\text{teacher}} = \beta \theta_{\text{teacher}} + (1-\beta) \theta_{\text{student}} θteacher=βθteacher+(1−β)θstudent
β\betaβ 是衰减系数,保证教师参数稳定、平滑地向学生参数靠拢,避免震荡。
-
数据增强策略:
每个视频 xix_ixi 会生成两个视图:强增强 xsx_sxs(给学生,增加学习难度)和弱增强 xwx_wxw(给教师,保证伪标签质量)。 -
基础损失函数 LbaseL_{\text{base}}Lbase
- LbaseclsL_{\text{base}}^{\text{cls}}Lbasecls: 动作分类损失,约束学生模型的分类输出 sclss_{\text{cls}}scls 逼近真实标签 yty_tyt(带标签数据)或教师伪标签 tclst_{\text{cls}}tcls(无标签数据)
- LbaselocL_{\text{base}}^{\text{loc}}Lbaseloc: 时空定位损失,约束学生模型的定位图 slocs_{\text{loc}}sloc 逼近真实时空标注 ftf_{\mathbf{t}}ft(带标签数据)或教师定位图(无标签数据)
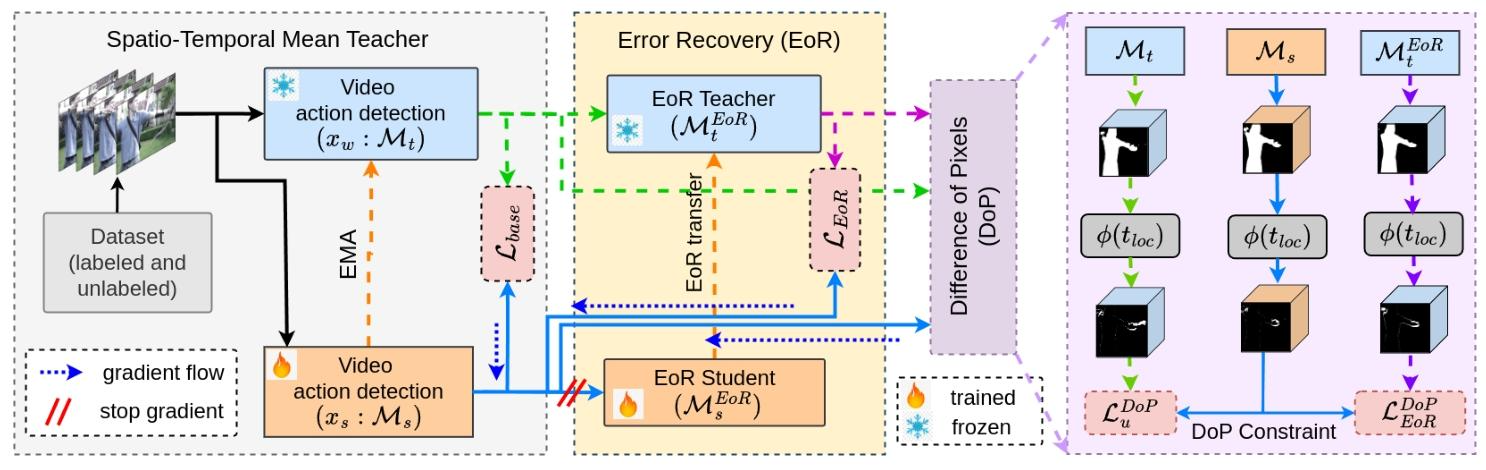
- 错误恢复(EOR)模块(黄色区域):优化空间动作边界
- 数据源:由于强增强(数据扰动),学生模型的预测结果会产生失真 / 偏差(即定位错误) EoR 模块仅专注于精修定位边界,无需担忧动作的具体类型,因此可以以类别无关的方式进行训练。
- EoR 模块首先在带标签样本上进行训练,任务是恢复学生模型在强数据增强下产生的时空定位错误。训练完成后,该模块被用于修复教师模型在弱数据增强下产生的定位错误,从而优化伪标签质量,供学生模型在无标签样本上学习。
- MtEoRM_t^{\text{EoR}}MtEoR 教师的模型参数通过指数移动平均EMA由学生的参数更新,衰减率与基础模型一致:
θtEoR=βθtEoR+(1−β)θsEoR \theta_t^{\text{EoR}} = \beta \theta_t^{\text{EoR}} + (1-\beta) \theta_s^{\text{EoR}} θtEoR=βθtEoR+(1−β)θsEoR
因为 β\betaβ 非常接近 1,所以教师参数只会缓慢、平滑地向学生参数靠拢,不会剧烈震荡,可以保证伪标签生成的稳定性。
- LEoRL_{\text{EoR}}LEoR:EoR损失计算方式为学生基础模型(MsM_sMs)的输出与 EoR 教师(MtEoRM_t^{\text{EoR}}MtEoR)生成的精修伪标签之间的均方误差(MSE):
LEoR=MSE(MtEoR(tloc),sloc) L_{\text{EoR}} = \text{MSE}\left( M_t^{\text{EoR}}(t_{\text{loc}}), s_{\text{loc}} \right) LEoR=MSE(MtEoR(tloc),sloc)
- DoP约束(紫色)
错误恢复(EoR)模块提升了伪标签的空间定位精度,但在视频场景中,模型预测还需要在时间维度上保持一致性。为确保帧间预测的时间连贯性,我们提出了一种全新的训练约束 ——像素差异(Difference of Pixels, DoP)约束。通过聚焦视频内部的像素运动,并利用损失函数优化帧间像素差异的准确性
第一行:原始视频帧
- 左侧:静态背景
- 右侧:动态背景
第二行(下排):真值的时间维度像素差异图
- 黑色背景:代表无变化的区域
- 白色轮廓:代表相邻帧之间发生变化的像素(即动作边界的位移)
LDoP=LuDoP+LEoRDoP=MSE(ϕ(tloc),ϕ(sloc))+MSE(ϕ(tlocEoR),ϕ(sloc)). \begin{aligned} \mathcal{L}_{\text{DoP}} &= \mathcal{L}_{\text{u}}^{\text{DoP}} + \mathcal{L}_{\text{EoR}}^{\text{DoP}} \\ &= \text{MSE}\left( \phi\left(t_{\text{loc}}\right), \phi\left(s_{\text{loc}}\right) \right) \\ &\quad + \text{MSE}\left( \phi\left(t_{\text{loc}}^{\text{EoR}}\right), \phi\left(s_{\text{loc}}\right) \right). \end{aligned} LDoP=LuDoP+LEoRDoP=MSE(ϕ(tloc),ϕ(sloc))+MSE(ϕ(tlocEoR),ϕ(sloc)).
ϕ\phiϕ 表示时间差分运算,定义为:
ϕ(x{f})=xloc{f+1}−xloc{f} \phi\left(x^{\{f\}}\right) = x_{\text{loc}}^{\{f+1\}} - x_{\text{loc}}^{\{f\}} ϕ(x{f})=xloc{f+1}−xloc{f}
xloc{f}x_{\text{loc}}^{\{f\}}xloc{f} 代表第 fff 帧的时空定位图。这一策略能在时空预测中强化更强的时间连贯性,进而提升网络生成的伪标签质量。
我们发现,无论是静态还是动态背景,都能有效突出动作边界的连续变化。证明 DoP 对复杂场景也具备鲁棒性。
四、实验
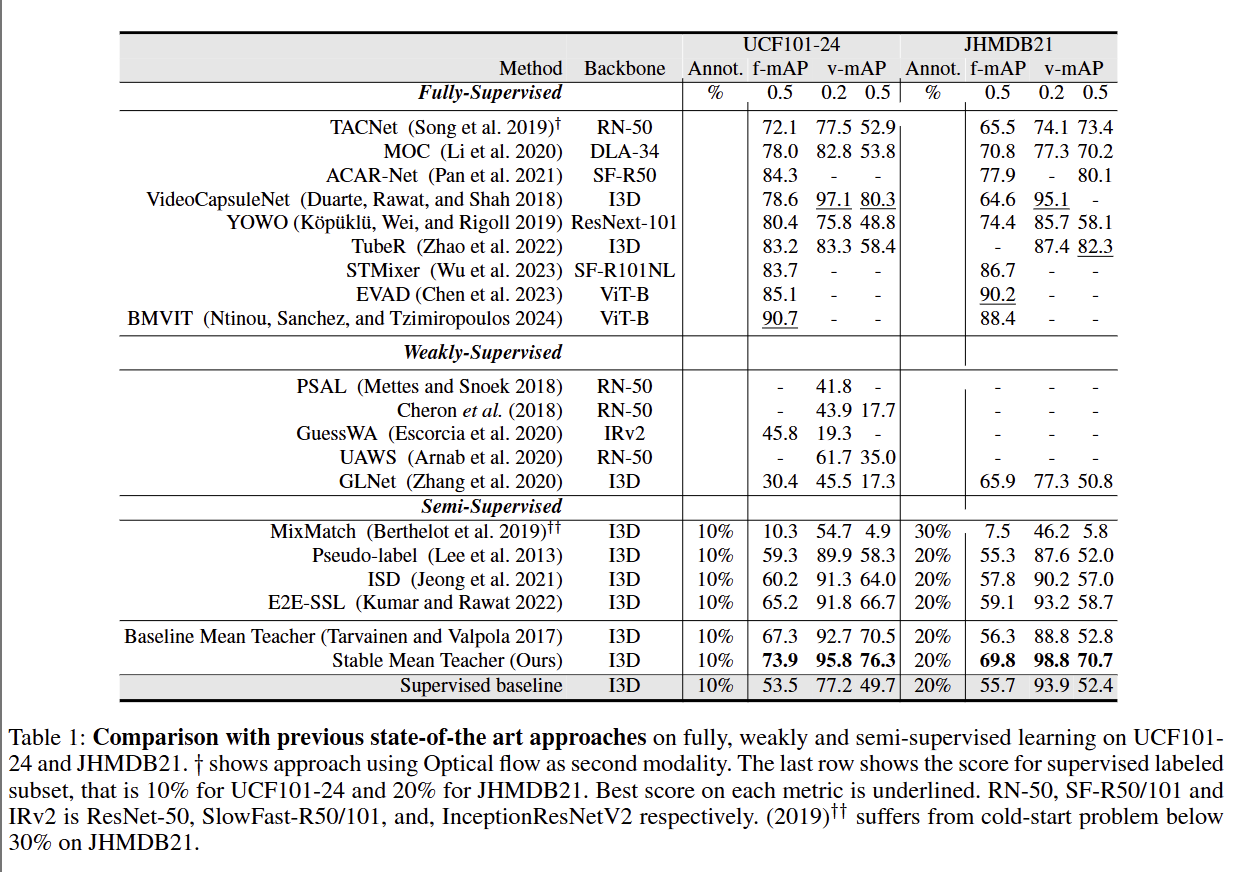
这张表是论文核心实验结果,对比了全监督、弱监督、半监督三类方法在两个经典视频动作检测数据集(UCF101-24、JHMDB21)上的性能
Method:方法名称(分为全监督 / 弱监督 / 半监督三组)
Backbone:模型骨干网络
Annot. %:使用的标注数据比例
f-mAP@0.5 / v-mAP@0.5:
f-mAP:帧级平均精度(侧重空间定位精度)
v-mAP:视频级平均精度(侧重时空联合精度)
后缀 0.5 表示 IoU 阈值为 0.5
下划线:代表该指标下的最优成绩
结论:Stable Mean Teacher 在仅用 10%~20% 标注数据的半监督场景下,性能全面超越现有 SOTA,且接近用 100% 标注训练的全监督模型
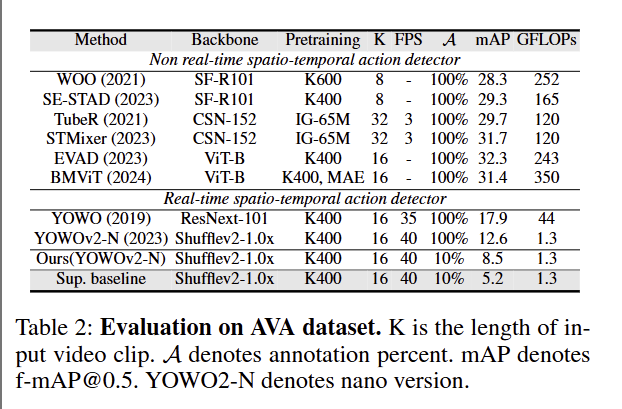
这张表在大规模AVA 数据集上,对比了非实时 / 实时时空动作检测器的性能与计算效率,重点验证本文方法(Ours)在轻量化、低标注、实时场景下的优势。
1. 含义
Method:方法名称
Backbone:骨干网络(轻量型 Shufflenev2-1.0x 用于实时模型)
Pretraining:预训练数据集
K:输入视频片段长度
FPS:推理帧率(越高越实时)
A:标注数据比例
mAP:帧级平均精度(f-mAP@0.5,核心性能指标)
GFLOPs:计算量(越低越高效)
2. 方法:(1)非实时检测器(Non real-time)这类模型用大骨干(SF-R101、CSN-152、ViT-B)和100% 标注数据,追求最高精度,但是计算量巨大无法实时运行
(2)实时检测器(Real-time)这类模型用轻量骨干,追求高 FPS + 低计算量,适合落地场景
3. 结论
这张表验证了本文方法在大规模、轻量化、低标注场景下的实用性:用 10% 标注数据实现了远超有监督基线的性能,同时保持 40 FPS 实时推理和极轻计算量,完美平衡了标注成本、精度与效率
五、消融实验
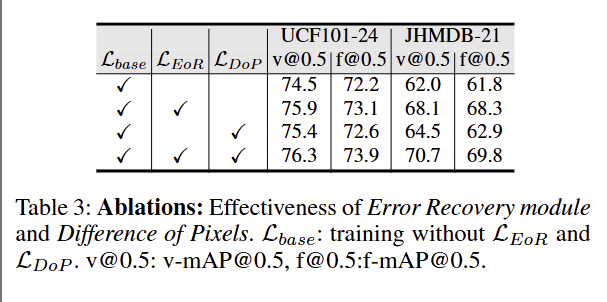
验证模型中两个核心模块(EoR 误差恢复模块、DoP 像素差约束)的独立作用和联合作用
仅用LbaseL_{\text{base}}Lbase时性能最差,证明 EoR 和 DoP 是性能提升的关键;
单独添加 EoR 或 DoP 均能提升性能,联合添加时性能达到最优,说明两个模块互补、协同生效;
DoP 对 v-mAP 的提升更显著,印证其 “增强时间一致性” 的核心作用。
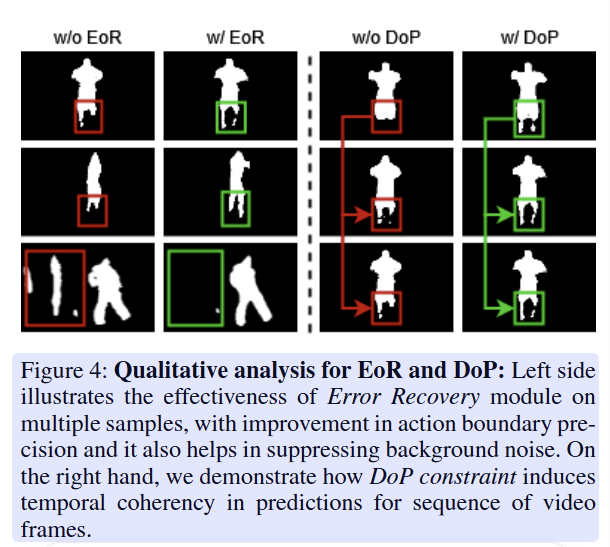
对 EoR(Error Recovery,误差恢复模块) 和 DoP(Difference of Pixels,像素差约束) 两个核心模块的定性可视化分析,用来直观展示它们在视频动作分割任务中的效果,和之前的消融实验(Table 3)形成了 “定量 + 定性” 的互补验证。
- 左侧:EoR 模块的效果(w/o EoR vs w/ EoR
- 动作边界精度提升:红色框(w/o EoR)里的人体轮廓边缘模糊、残缺,绿色框(w/ EoR)里的轮廓更完整、边缘更贴合真实人体动作。
- 抑制背景噪声:最下面一行示例中,w/o EoR 时出现了大量无关的白色噪点(红色框),w/ EoR 后这些噪声被有效清除,只保留了清晰的人体区域。
- DoP 约束的效果(w/o DoP vs w/ DoP)
- 时间连贯性增强:w/o DoP 时,同一肢体部位在连续帧中的检测位置漂移、断裂(红色框 + 箭头),预测结果不稳定;w/ DoP 后,肢体位置在帧间保持一致、连续(绿色框 + 箭头),动作序列更平滑。
- 结论:
- EoR 提升了单帧的空间精度与抗噪能力;
- DoP 提升了多帧的时间连贯性;
- 两者结合后,模型在空间精度和时间一致性上都得到了优化,最终带来了 v-mAP 和 f-mAP 的全面提升。
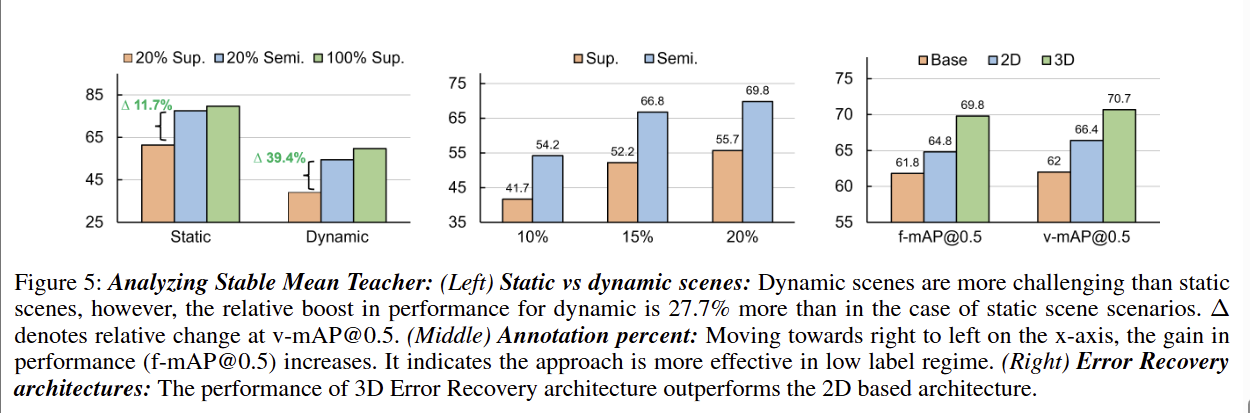
Stable Mean Teacher 模型的多维度性能分析图,从场景类型、标注率、EoR 架构三个角度,进一步验证了模型的优势和设计合理性
- 图一:静态场景 vs 动态场景
- 橙色:20% 全监督(20% Sup.)
蓝色:20% 半监督(20% Semi.,即我们的模型)
绿色:100% 全监督(100% Sup.) - 结论:
动态场景更具挑战性
半监督模型在动态场景增益更大
半监督接近全监督性能
- 图二:不同标注率下的性能
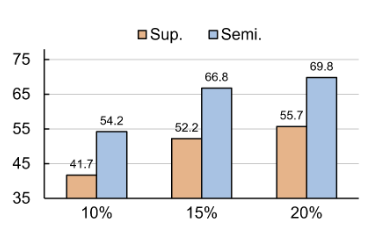
橙色:全监督
蓝色:半监督
结论
- 标注率越低,半监督优势越明显
- 低标注场景更有效:随着标注率从 20% 降到 10%,半监督的性能增益反而增大,说明模型在少样本 / 低标注场景下更具价值。
- 图三:EoR 架构对比
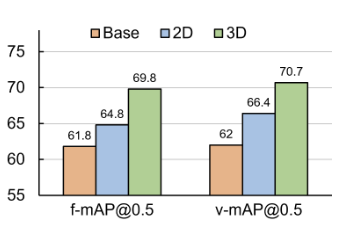
- 橙色:Base(无 EoR 模块)
- 蓝色:2D EoR(基于 2D 卷积的误差恢复模块)
- 绿色:3D EoR(基于 3D 卷积的误差恢复模块)
结论 - EoR 模块能显著提升性能
- 3D EoR 架构更优
- 3D 卷积更适合视频任务
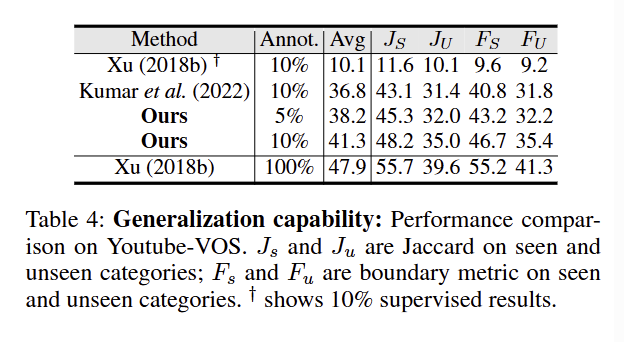
Youtube-VOS 数据集上的泛化能力对比,用来验证模型(Ours)在低标注率下的泛化表现
Annot.:标注数据占比(5% / 10% / 100%)
Avg:综合平均性能
JS/ JU:分别是 ** 见过类别(seen)和未见过类别(unseen)** 的 Jaccard 指数(交并比,衡量分割区域精度)
FS / FU:分别是见过类别和未见过类别的边界 F-measure
- 发现低标注率下平均性能已经高于Kumar方法,指标也更高
- 发现在未见过类别上的表现也由于Kumar方法
结论
证明了 Stable Mean Teacher 模型在低标注场景下的泛化优势: - 用更少的标注(5%/10%)达到甚至超过了现有半监督 SOTA 用更多标注(10%)的性能;
- 在 seen 和 unseen 类别上都表现稳定,验证了模型的鲁棒泛化能力
六、总结
我们提出了Stable Mean Teacher,这是一种用于半监督动作检测的新型师生方法。Stable Mean Teacher依赖于一种新颖的错误恢复模块,该模块从学生的错误中学习,并将这些知识传递给教师,以便为学生生成更好的伪标签。它还受益于像素差异,这是一种简单的约束,可在时空预测中增强时间连贯性。我们通过大量实验在三个动作检测数据集上证明了Stable Mean Teacher的有效性。此外,我们还展示了其在VOS任务上的性能,验证了其对视频中其他密集预测任务的泛化能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)