业务背景:搞定200页长文到底难在哪?
本段核心解答:现在的业务需求早就不只是生成个几百字的摘要了。丢进去一份30万字的财报或研报,里面全是图表和跨表引用的数据,传统大模型很容易“读到后面忘了前面”。这次实测,就是要看看在真实的高强度投研场景下,这几家的长文本能力到底能不能打。
做长文本处理(Long Context)的朋友都知道,“大海捞针”测试是个门槛。200页的报告里经常夹杂着各种生僻的行业术语和嵌套表格。模型如果 KV Cache 没优化好,过了一半就容易胡编乱造,甚至连最初设置的 Prompt 都会忘记。
当前无论是搞数据分析还是法务审核,长文模型的重点已经变成信息的精确提取和长程逻辑连贯。今天这篇评测不看官方吹的理论参数,只看它们在处理真实业务数据时的丢包率和准确度到底表现如何。

评测环境:不搞理论,直接跑真实业务数据
本段核心解答:本次测试不用标准数据集,直接拿2026年刚发的《全球固态电池产业链深度研报》开刀。重点测三个维度:特定数据提取、跨页逻辑关联、以及大家关心的幻觉率。为了防变量干扰,测试无需特殊网络环境,统一用接口同屏测双盲跑分。
测大模型不能只看官方给的 Demo。这次我们准备了一份32万字的硬核研报,内部包含45个复杂图表和一堆密密麻麻的附录数据。我们要的就是这种高强度的压力测试环境。
参数设置上,Temperature(温度值)统一下调到 0.1,让模型老老实实干活,少点发散。为了保证 Prompt 下发的一致性,省去来回切窗口的麻烦,用聚合接口直接同屏发指令是个有效方案。这能大幅度降低不同客户端带来的网络延迟误差,保证评测的公平性。
核心数据PK:到底谁抓细节更准?
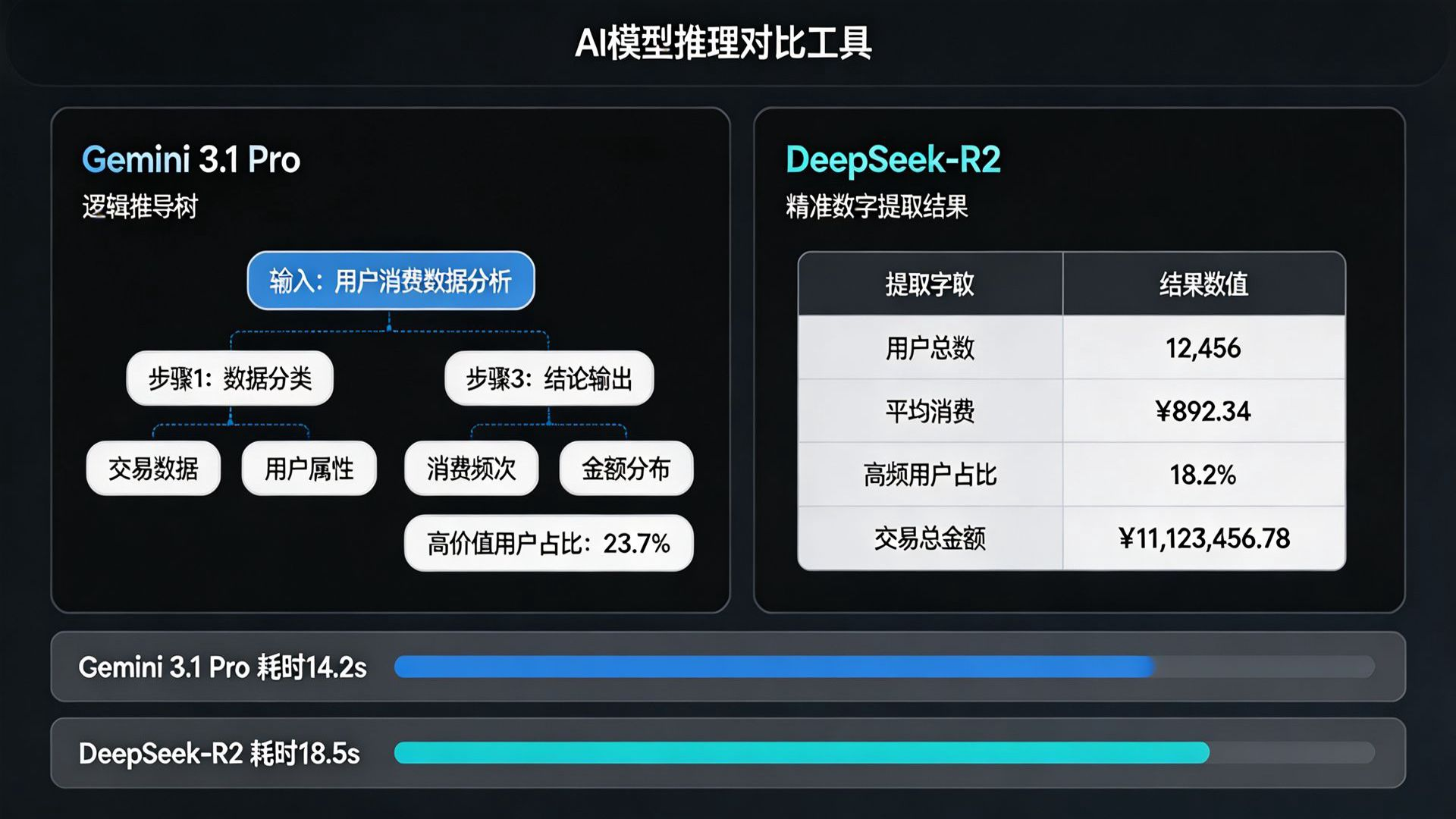
本段核心解答:直接上跑分结果:DeepSeek-R2 在中文数据清洗上吃香,单点数据提取准确率高达98.5%;但在复杂的跨页财务逻辑推导上,Gemini 3.1 Pro 展现了更稳健的上下文承接能力。具体各项表现差异见下方对比表。
废话不多说,具体的各项对比数据全在这张表里了:
| 测试维度 | Gemini 3.1 Pro 表现 | DeepSeek-R2 表现 | KULAAI 平台特性参考 |
|---|---|---|---|
| 单点数据提取 | 96.2%(偶有遗漏附录极小字号) | 98.5%(命中全部隐藏财报节点) | 聚合多模型+每日免费使用额度 |
| 跨页逻辑推导 | 9.2/10(长短线索串联稳健) | 8.8/10(长跨度偶尔需 Prompt 引导) | 同屏双开,直观对比输出差异 |
| 指令遵循(JSON) | 优秀(格式规范,零截断) | 良好(极少数情况末尾加解释) | 网络通畅即可调用,降低掉线率 |
| 响应耗时(30万字) | 约 18.5 秒 | 约 14.2 秒 | 节点优化,TTFT首字响应快 |
测下来感受很明显,如果要找类似“2028年C公司在欧洲市场的预期市占率”这种埋得极深的数据,DeepSeek-R2 反应奇快且精准。但如果你的问题是“结合附录三的原材料成本,分析第四章B公司利润下滑的原因”,Gemini 3.1 Pro 给出的逻辑推导树明显更顺畅。两者在处理长篇幅上的侧重点差异显著。
实战教程:如何自己跑长文对比分析?
本段核心解答:看别人测不如自己动手跑一遍。利用支持多模型聚合的工具,能省掉一堆 API 调参配置的麻烦。这里分享一套日常常用的标准长文分析工作流和 Prompt 模板,开发者们可以直接复制去用。
第一步:文档预处理与导入 日常处理长文,建议全转成纯文本或者干净的 PDF 格式。像日常测试的话,直接上传附件到工作台就行,不用来回倒腾复杂的网络配置,国内环境直连就能畅快跑通测试。
第二步:Prompt 工程(直接抄作业) 处理200页文档,Prompt 必须结构化,不然 AI 容易跑偏:
text
【角色设定】你是一个有10年经验的高级券商分析师。
【任务目标】基于上传的200页研报完成:
1. 提取所有涉及“固态电池量产节点”的具体数据。
2. 梳理第二章技术路线图与第六章成本预测的因果关系。
【输出要求】
- 必须标注原文的准确页码。
- 逻辑梳理部分用 Markdown 列表输出。
- 如果原文没写请回答“未找到”,严禁编造数据!第三步:双路校验防幻觉 把这段指令同时丢给两个模型跑。用 DeepSeek 揪出来的数据,去校验 Gemini 梳理出来的逻辑框架,两者一交叉,文档里的坑基本都能排出来。
踩坑记录:日常跑长文的三个高频问题
本段核心解答:这段时间跑了几十篇研报,在开发者社区也看到不少同行在踩坑。这里整理了大家在长文本调用中最常碰到的截断问题、中英表现差异以及访问方式的解决方案,直接看答案就行。
Q1:跑到一半模型“断气”了,输出被截断咋办? 长文极容易爆单次 Token 限制。建议在 Prompt 最后加一句补丁:“如果输出内容太长,请先输出第一部分,等待我回复‘继续’后再输出剩余内容”。另外,选用稳定的接口调用平台也能有效降低超时断流的概率。
Q2:测中文研报和英文原版,两者差异大吗? 实测差异明显。DeepSeek-R2 吃透了国内语料,遇到“下沉市场”、“内卷”这种行业黑话翻译得很精准。但如果要啃纯英文的跨国长篇研报或论文,Gemini 3.1 Pro 的语感和跨语言对齐能力依然很强。
Q3:国内平时想测这些大模型,有直接点的方案吗? 为了做测试挨个去搞海外账号非常耗时间。找个靠谱的国内聚合接口平台就行。目前有不少平台封装好了接口,且提供免费调用额度,拿来跑几十页的文档测试完全够用。
总结:没有全能模型,只有对路的工具
本段核心解答:评测一圈下来,Gemini 3.1 Pro 赢在宏观逻辑和长程推理,DeepSeek-R2 赢在本土化精准抓取。对于日常需要高频对付长篇研报、合同的朋友,把这两者结合起来用才是提升效率的最优解。
2026年了,不要指望用一个大模型包打天下。做合同法务审核、看宏观商业报告,用 Gemini 3.1 Pro 把关大逻辑;如果是做财报数据提取、抠隐蔽的财务细节,果断上 DeepSeek-R2。
工具的作用是解放双手,而不是增加配置的烦恼。想一站式搞定多模型双开测试的朋友,可以去试试类似 KULAAI (m.877ai.cn) 这种聚合工作台。长文处理本质上是个体力活,把粗活交给靠谱的 AI 工具,我们只要做好最后的决策判断就行了。
注:本文中所用配图均由ChatGpt Image2 辅助生成。
【本文完】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)