2026山东大学软件学院项目实训(七)——功能扩展
目录
团队信息
组号:69组
项目:AI零代码应用生成平台
负责人:樊伟彤
小组成员:者亚杰、蒋宇轩、张旭、李重昊
本期核心任务
为 AI 零代码应用生成平台拓展三大核心功能:
- 应用封面图自动生成
- 项目代码包下载
- AI 智能选型(自动匹配最优代码生成方案)
一、生成应用封面图
1.需求分析
应用封面是平台视觉体验的核心环节,需实现所见即所得的自动生成能力 —— 直接抓取应用实际运行页面作为封面,提升平台专业度与用户体验。
2.方案设计
实现流程
实现应用封面图生成功能,我们考虑到几个关键步骤:
-
首先要获取到应用的可访问 URL。由于我们的平台支持多种生成模式(原生 HTML、多文件项目、Vue 工程),其中原生模式和 Vue 工程模式生成可访问浏览 URL 的时机不一样。所以为了统一处理,而且确保应用已经可以正常访问,我们选择在应用部署完成后再生成封面图。
-
使用 Selenium 这样的自动化工具打开一个无头浏览器,访问应用页面并进行截图。
-
直接截图得到的图片通常比较大,不仅占用存储空间,加载速度也会比较慢。因此我们需要对图片进行压缩处理。虽然我们可以通过调整 Selenium 的窗口大小来控制截图尺寸,但这样可能会导致页面显示不全。更好的方案是先按正常尺寸截图,然后使用工具库对图片进行压缩。
-
为了确保图片的持久化存储和快速访问,将压缩后的图片上传到腾讯云 COS 对象存储中,并将访问 URL 保存到数据库的应用表中。
-
最后,清理本地临时文件

网页截图方案选型
在选择网页截图技术方案时,我们综合考虑多个因素。市面上有很多可选的技术,每种都有自己的优缺点:
| 评估维度 | Selenium | Playwright | HtmlUnit | Puppeteer+Node.js | 云服务 API |
|---|---|---|---|---|---|
| 依赖大小 | ~50MB | ~100MB | ~30MB | ~200MB | 0MB |
| 启动时间 | 3-5 秒 | 1-2 秒 | <1 秒 | 2-3 秒 | 网络延迟 |
| 内存占用 | 200-500MB | 100-300MB | 20-50MB | 150-400MB | 0MB |
| CPU 占用 | 中等 | 较低 | 很低 | 中等 | 无 |
| 截图质量 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| JS 执行 | 完整支持 | 完整支持 | 有限支持 | 完整支持 | 完整支持 |
| Vue/React 适配 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 跨浏览器 | Chrome/Firefox/Edge | Chrome/Firefox/Safari | 模拟浏览器仅 Chrome 系 | 多种选择 | 多种选择 |
| 配置复杂度 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 学习成本 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 社区活跃度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 服务商决定 |
| 文档完善度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 服务商决定 |
| 错误处理 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 并发支持 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 企业采用场景 | 广泛使用 | 快速增长 | 传统项目 | 广泛使用 | 成本敏感场景 |
| 总体推荐度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
考虑到我们是 Java 技术栈,以及对稳定性的要求,最终选择 Selenium
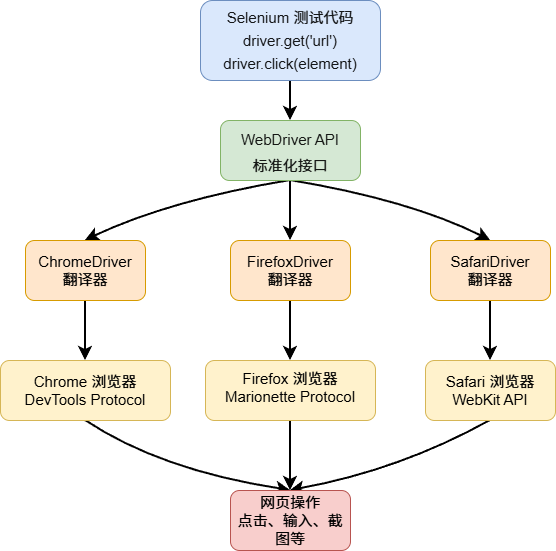
Selenium 核心原理
Selenium 是一个非常成熟的 Web 自动化框架,它的核心概念是 WebDriver(浏览器驱动)。
WebDriver 是一个可以控制浏览器行为的接口,能够让程序像人类一样操作浏览器:打开页面、点击按钮、输入文本、截取屏幕等。
可以说 WebDriver 是 Selenium 与浏览器之间的桥梁,因为不同浏览器(Chrome、Firefox、Safari 等)有不同的内部 API 和控制机制,驱动程序负责将 Selenium 的标准化命令翻译成各个浏览器能理解的具体指令,从而实现跨浏览器的统一自动化控制。
3.开发实现
依次开发实现下列功能:
-
本地生成截图
-
保存截图到对象存储
-
截图服务
-
触发截图生成
1)本地生成截图
首先,需要在项目中引入必要的依赖。
<!-- Selenium 网页截图依赖 -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.33.0</version>
</dependency>
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>6.1.0</version>
</dependency> 接下来,在utils包下创建专门用于网页截图的工具类,提供根据 URL 生成截图文件并返回路径的方法。
1)第一步是初始化驱动。需要注意避免重复初始化驱动程序:
-
在静态代码块里初始化驱动,确保整个应用生命周期内只初始化一次
-
默认使用已经初始化好的驱动实例
-
在项目停止前正确销毁驱动,释放资源
2)编写一些子方法
-
保存图片到文件
-
压缩图片
-
等待页面加载完成
/**
* 压缩图片
*/
private static void compressImage(String originalImagePath, String compressedImagePath) {
// 压缩图片质量(0.1 = 10% 质量)
final float COMPRESSION_QUALITY = 0.3f;
try {
ImgUtil.compress(
FileUtil.file(originalImagePath),
FileUtil.file(compressedImagePath),
COMPRESSION_QUALITY
);
} catch (Exception e) {
log.error("压缩图片失败: {} -> {}", originalImagePath, compressedImagePath, e);
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "压缩图片失败");
}
}3)最后编写完整的生成网页截图方法,访问网页、等待页面加载完成并截图、保存截图文件并压缩、最后返回压缩后的路径。
/**
* 生成网页截图
*
* @param webUrl 网页URL
* @return 压缩后的截图文件路径,失败返回null
*/
public static String saveWebPageScreenshot(String webUrl) {
if (StrUtil.isBlank(webUrl)) {
log.error("网页URL不能为空");
return null;
}
try {
// 创建临时目录
String rootPath = System.getProperty("user.dir") + File.separator + "tmp" + File.separator +
"screenshots"
+ File.separator + UUID.randomUUID().toString().substring(0, 8);
FileUtil.mkdir(rootPath);
// 图片后缀
final String IMAGE_SUFFIX = ".png";
// 原始截图文件路径
String imageSavePath = rootPath + File.separator + RandomUtil.randomNumbers(5) + IMAGE_SUFFIX;
// 访问网页
webDriver.get(webUrl);
// 等待页面加载完成
waitForPageLoad(webDriver);
// 截图
byte[] screenshotBytes = ((TakesScreenshot) webDriver).getScreenshotAs(OutputType.BYTES);
// 保存原始图片
saveImage(screenshotBytes, imageSavePath);
log.info("原始截图保存成功: {}", imageSavePath);
// 压缩图片
final String COMPRESSION_SUFFIX = "_compressed.jpg";
String compressedImagePath = rootPath + File.separator + RandomUtil.randomNumbers(5) +
COMPRESSION_SUFFIX;
compressImage(imageSavePath, compressedImagePath);
log.info("压缩图片保存成功: {}", compressedImagePath);
// 删除原始图片,只保留压缩图片
FileUtil.del(imageSavePath);
return compressedImagePath;
} catch (Exception e) {
log.error("网页截图失败: {}", webUrl, e);
return null;
}
}2)保存截图到对象存储
为了让生成的封面图能够持久化存储并快速访问,我们需要将图片上传到腾讯云 COS 对象存储。
创建可复用的 CosManager 类,专门负责和 COS 对象存储进行交互,提供文件上传功能, 不包含特殊的业务逻辑。
/**
* COS对象存储管理器
*
* @author yupi
*/
@Component
@Slf4j
public class CosManager {
@Resource
private CosClientConfig cosClientConfig;
@Resource
private COSClient cosClient;
/**
* 上传对象
*
* @param key 唯一键
* @param file 文件
* @return 上传结果
*/
public PutObjectResult putObject(String key, File file) {
PutObjectRequest putObjectRequest = new PutObjectRequest(cosClientConfig.getBucket(), key,
file);
return cosClient.putObject(putObjectRequest);
}
/**
* 上传文件到 COS 并返回访问 URL
*
* @param key COS对象键(完整路径)
* @param file 要上传的文件
* @return 文件的访问URL,失败返回null
*/
public String uploadFile(String key, File file) {
// 上传文件
PutObjectResult result = putObject(key, file);
if (result != null) {
// 构建访问URL
String url = String.format("%s%s", cosClientConfig.getHost(), key);
log.info("文件上传COS成功: {} -> {}", file.getName(), url);
return url;
} else {
log.error("文件上传COS失败,返回结果为空");
return null;
}
}
}3)截图服务
考虑到后续项目要改造为微服务,最好将截图功能单独封装为一个通用服务,将本地生成截图和文件上传整合在一起。不包含 appId 等具体的业务参数,作用就是根据要截图的网址返回截图后的图片地址。
注意,本地截图文件在上传到对象存储后立即清理,避免占用服务器磁盘空间。同时,COS 对象键按日期分层存储,便于后续管理和维护。
4)触发截图生成
最后,需要在应用部署完成后触发截图生成。
// 10. 构建应用访问 URL
String appDeployUrl = String.format("%s/%s/", AppConstant.CODE_DEPLOY_HOST, deployKey);
// 11. 异步生成截图并更新应用封面
generateAppScreenshotAsync(appId, appDeployUrl);
return appDeployUrl;由于截图生成是一个相对耗时的操作,必须使用异步方式处理,避免阻塞用户的部署流程。
@Resource
private ScreenshotService screenshotService;
/**
* 异步生成应用截图并更新封面
*
* @param appId 应用ID
* @param appUrl 应用访问URL
*/
@Override
public void generateAppScreenshotAsync(Long appId, String appUrl) {
// 使用虚拟线程异步执行
Thread.startVirtualThread(() -> {
// 调用截图服务生成截图并上传
String screenshotUrl = screenshotService.generateAndUploadScreenshot(appUrl);
// 更新应用封面字段
App updateApp = new App();
updateApp.setId(appId);
updateApp.setCover(screenshotUrl);
boolean updated = this.updateById(updateApp);
ThrowUtils.throwIf(!updated, ErrorCode.OPERATION_ERROR, "更新应用封面字段失败");
});
}这里我们使用了 Java 21 的虚拟线程(Virtual Thread)特性。
这是由 JVM 管理的轻量级线程。它的创建成本极低(几乎无内存开销),且在执行 I/O 操作时会自动让出 CPU 给其他虚拟线程,从而在同样的系统资源下支持百万级并发而不是传统平台线程的几千级并发。而且它的使用和传统 Java 线程几乎没有区别,非常适合处理这种I/O 密集型的异步任务。
二、下载代码
1.需求分析
除了在线预览和使用生成的应用,用户可能需要下载代码到本地进行二次开发。这样一来,我们的平台不仅是一个在线工具,更是一个真正的开发起点。
2方案设计
实现代码下载功能需要考虑几个关键步骤:
-
基础校验:我们需要验证应用是否存在、用户是否有下载权限等。考虑到安全性,只有应用的创建者才能下载对应的代码。
-
找到应用的生成目录。这里要特别注意,我们要下载的是原始的生成目录,而不是部署目录。部署目录是打包构建之后的文件,而生成目录包含的是源代码。
-
定义文件过滤器,因为并不是所有文件都需要提供给用户下载。比如 node_modules 目录体积庞大且可以通过 npm install 重新安装,dist 和 build 目录是构建产物可以重新生成,.DS_Store、.env 等文件包含系统信息或敏感配置不应该下载。
-
最后将过滤后的文件打包成 ZIP 压缩包,通过 HTTP 响应直接返回给前端。需要设置正确的响应头,告诉浏览器这是一个需要下载的文件、并且传递下载的文件名称。
3.后端开发
和截图服务类似,我们将项目下载单独封装为一个service包下的通用服务 ProjectDownloadService,可以对指定路径下的文件进行打包下载。可以使用 Hutool 工具库的 ZipUtil 实现 ZIP 包压缩,支持指定文件过滤器,正好满足我们的需求。
1)文件过滤
不仅要过滤特定的文件和目录名称,还过滤了特定的文件扩展名。过滤逻辑会检查路径中的每一部分,确保不会遗漏无用文件
2)下载压缩包核心方法
@Override
public void downloadProjectAsZip(String projectPath, String downloadFileName, HttpServletResponse
response) {
// 基础校验
ThrowUtils.throwIf(StrUtil.isBlank(projectPath), ErrorCode.PARAMS_ERROR, "项目路径不能为空");
ThrowUtils.throwIf(StrUtil.isBlank(downloadFileName), ErrorCode.PARAMS_ERROR, "下载文件名不能为
空");
File projectDir = new File(projectPath);
ThrowUtils.throwIf(!projectDir.exists(), ErrorCode.NOT_FOUND_ERROR, "项目目录不存在");
ThrowUtils.throwIf(!projectDir.isDirectory(), ErrorCode.PARAMS_ERROR, "指定路径不是目录");
log.info("开始打包下载项目: {} -> {}.zip", projectPath, downloadFileName);
// 设置 HTTP 响应头
response.setStatus(HttpServletResponse.SC_OK);
response.setContentType("application/zip");
response.addHeader("Content-Disposition",
String.format("attachment; filename=\"%s.zip\"", downloadFileName));
// 定义文件过滤器
FileFilter filter = file -> isPathAllowed(projectDir.toPath(), file.toPath());
try {
// 使用 Hutool 的 ZipUtil 直接将过滤后的目录压缩到响应输出流
ZipUtil.zip(response.getOutputStream(), StandardCharsets.UTF_8, false, filter, projectDir);
log.info("项目打包下载完成: {}", downloadFileName);
} catch (Exception e) {
log.error("项目打包下载异常", e);
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "项目打包下载失败");
}
}3)接口设计
接下来在AppController中编写接口,拼接好应用代码目录和下载文件名,然后调用下载服务。
下载文件名最好是英文的,否则前端可能不会获取到。
@Resource
private ProjectDownloadService projectDownloadService;
/**
* 下载应用代码
*
* @param appId 应用ID
* @param request 请求
* @param response 响应
*/
@GetMapping("/download/{appId}")
public void downloadAppCode(@PathVariable Long appId,
HttpServletRequest request,
HttpServletResponse response) {
// 1. 基础校验
ThrowUtils.throwIf(appId == null || appId <= 0, ErrorCode.PARAMS_ERROR, "应用ID无效");
// 2. 查询应用信息
App app = appService.getById(appId);
ThrowUtils.throwIf(app == null, ErrorCode.NOT_FOUND_ERROR, "应用不存在");
// 3. 权限校验:只有应用创建者可以下载代码
User loginUser = userService.getLoginUser(request);
if (!app.getUserId().equals(loginUser.getId())) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR, "无权限下载该应用代码");
}
// 4. 构建应用代码目录路径(生成目录,非部署目录)
String codeGenType = app.getCodeGenType();
String sourceDirName = codeGenType + "_" + appId;
String sourceDirPath = AppConstant.CODE_OUTPUT_ROOT_DIR + File.separator + sourceDirName;
// 5. 检查代码目录是否存在
File sourceDir = new File(sourceDirPath);
ThrowUtils.throwIf(!sourceDir.exists() || !sourceDir.isDirectory(),
ErrorCode.NOT_FOUND_ERROR, "应用代码不存在,请先生成代码");
// 6. 生成下载文件名(不建议添加中文内容)
String downloadFileName = String.valueOf(appId);
// 7. 调用通用下载服务
projectDownloadService.downloadProjectAsZip(sourceDirPath, downloadFileName, response);
}4.前端开发
修改前端页面,增加下载相关功能。
三、AI智能选择方案
1.需求分析
目前我们平台提供了 3 套不同的代码生成方案:原生 HTM L、原生多文件、Vue 工程。分别适合不同复杂度的项目需求,也使用了成本不同的大模型。
那么问题来了,当用户提出需求时,如何判断应该使用哪套方案呢?
让用户自己选择的话,会增加用户的使用门槛。更好的方案是让 AI 来自动判断,这就是所谓的智能路由。
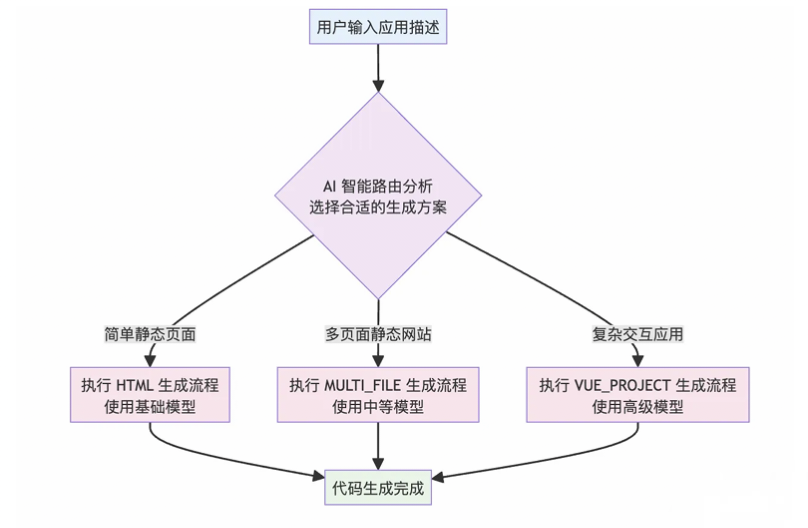
2.方案设计
在实际生产环境中,智能路由本身应该选择成本更低、输出更快的大模型,因为路由决策是一个相对简单的分类任务,不需要太强的模型。
我们可以利用 LangChain4j 的结构化输出功能来实现智能路由。结构化输出支持枚举类型,这正好符合我们的需求。
编写一段用于 AI 路由的提示词,需要给出清晰的判断规则。
你是一个专业的代码生成方案路由器,需要根据用户需求返回最合适的代码生成类型。
可选的代码生成类型:
1. HTML - 适合简单的静态页面,单个 HTML 文件,包含内联 CSS 和 JS
2. MULTI_FILE - 适合简单的多文件静态页面,分离 HTML、CSS、JS 代码
3. VUE_PROJECT - 适合复杂的现代化前端项目
判断规则:- 如果用户需求简单,只需要一个展示页面,选择 HTML- 如果用户需要多个页面但不涉及复杂交互,选择 MULTI_FILE- 如果用户需求复杂,涉及多页面、复杂交互、数据管理等,选择 VUE_PROJECT3.后端开发
1)在 ai 包下新建 AI 智能路由服务,也是一个 AI Service
/**
* AI代码生成类型智能路由服务
* 使用结构化输出直接返回枚举类型
*
* @author yupi
*/
public interface AiCodeGenTypeRoutingService {
/**
* 根据用户需求智能选择代码生成类型
*
* @param userPrompt 用户输入的需求描述
* @return 推荐的代码生成类型
*/
@SystemMessage(fromResource = "prompt/codegen-routing-system-prompt.txt")
CodeGenTypeEnum routeCodeGenType(String userPrompt);
}2)创建 AI 智能路由服务工厂
/**
* AI代码生成类型路由服务工厂
*
* @author yupi
*/
@Slf4j
@Configuration
public class AiCodeGenTypeRoutingServiceFactory {
@Resource
private ChatModel chatModel;
/**
* 创建AI代码生成类型路由服务实例
*/
@Bean
public AiCodeGenTypeRoutingService aiCodeGenTypeRoutingService() {
return AiServices.builder(AiCodeGenTypeRoutingService.class)
.chatModel(chatModel)
.build();
}
}3)编写service方法
@Resource
private AiCodeGenTypeRoutingService aiCodeGenTypeRoutingService;
@Override
public Long createApp(AppAddRequest appAddRequest, User loginUser) {
// 参数校验
String initPrompt = appAddRequest.getInitPrompt();
ThrowUtils.throwIf(StrUtil.isBlank(initPrompt), ErrorCode.PARAMS_ERROR, "初始化 prompt 不能为空");
// 构造入库对象
App app = new App();
BeanUtil.copyProperties(appAddRequest, app);
app.setUserId(loginUser.getId());
// 应用名称暂时为 initPrompt 前 12 位
app.setAppName(initPrompt.substring(0, Math.min(initPrompt.length(), 12)));
// 使用 AI 智能选择代码生成类型
CodeGenTypeEnum selectedCodeGenType = aiCodeGenTypeRoutingService.routeCodeGenType(initPrompt);
app.setCodeGenType(selectedCodeGenType.getValue());
// 插入数据库
boolean result = this.save(app);
ThrowUtils.throwIf(!result, ErrorCode.OPERATION_ERROR);
log.info("应用创建成功,ID: {}, 类型: {}", app.getId(), selectedCodeGenType.getValue());
return app.getId();
}4)优化 AppController 的代码
@PostMapping("/add")
public BaseResponse<Long> addApp(@RequestBody AppAddRequest appAddRequest, HttpServletRequest request)
{
ThrowUtils.throwIf(appAddRequest == null, ErrorCode.PARAMS_ERROR);
// 获取当前登录用户
User loginUser = userService.getLoginUser(request);
Long appId = appService.createApp(appAddRequest, loginUser);
return ResultUtils.success(appId);
}4.前端开发
为了让用户了解系统选择的生成类型,我们需要在前端展示这个信息。
可以在应用详情页的标题右侧和应用详情弹窗内增加生成类型的标签展示。
开发总结
本次我们对 AI 零代码应用生成平台进行了一些功能扩展,整体收获如下:
1.技术落地:掌握基于 Selenium 的网页自动化截图与图片压缩方案,实现腾讯云 COS 对象存储对接;完成项目代码过滤、ZIP 打包与下载服务开发;基于 LangChain4j 结构化输出实现 AI 智能路由,自动匹配最优代码生成方案,落地 Java 21 虚拟线程异步处理能力。
2. 工程化能力:完善平台功能生态,打通应用展示、代码导出、智能选型全流程;统一多模式应用的封面生成、下载逻辑,优化文件过滤、异步任务、并发控制等工程实践,提升系统易用性与稳定性。
3. 问题解决:成功解决截图时机不统一、图片体积过大、下载文件冗余、用户选型门槛高、前后端展示信息缺失等实际问题,积累自动化工具、文件处理、AI 路由的实战经验。
后续计划
- 可视化编辑功能:为生成的应用提供在线可视化编辑能力,支持对话编辑、实时预览,降低用户修改成本,提升平台易用性。
- 系统性能优化:针对接口响应、文件处理、异步任务、大模型调用等环节进行优化,提升平台并发能力、加载速度与运行稳定性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

{kind=link}
{kind=link}
{kind=link}
所有评论(0)