NeurIPS|2022|Knowledge Distillation from A Stronger Teacher:面向更强教师的知识蒸馏
目录导航
NeurIPS|2022|Knowledge Distillation from A Stronger Teacher:面向更强教师的知识蒸馏
摘要
本文提出了一种新的知识蒸馏方法 DIST,旨在解决在使用更强教师模型(更大模型或更强训练策略)时传统知识蒸馏(KD)性能下降的问题。引言中写到,作者通过实证发现,学生模型与更强教师模型之间的预测差异可能相当严重。因此,在 KL 散度中对预测进行精确匹配会干扰训练,导致现有方法表现不佳。
正文
DIST: 面向强教师的知识蒸馏方法
传统 KD 的核心痛点
传统知识蒸馏依赖 KL 散度强制匹配师生模型的输出分布,要求学生复刻教师的概率绝对值。但当教师模型采用更强的训练策略(如标签平滑、高级数据增强)时,师生模型的能力差距会显著拉大,这种 “硬匹配” 约束反而会干扰学生训练,导致蒸馏失效。
DIST 的核心改进:松弛匹配与两类关系蒸馏
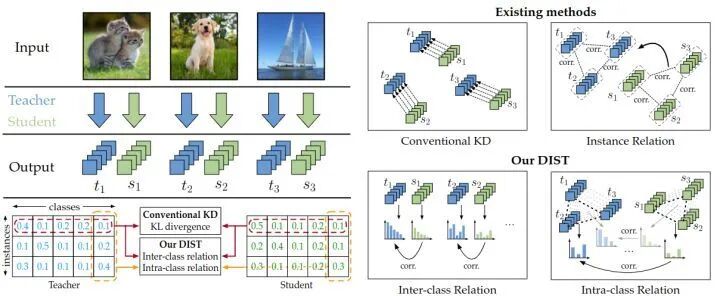
- DIST 放弃了对概率绝对值的强制对齐,转而保留师生模型预测的相对关系,迁移两类关键知识:
- 类间关系:每个样本的预测概率分布中,教师对不同类别的偏好排序(即 “教师更倾向于哪个类别” 的相对关系),无需复刻精确概率值。
- 类内关系:每个类别下,所有样本预测分数的相对排序,反映不同样本与该类别的相似度关系(例如,“猫” 样本在 “猫类” 的得分应高于 “狗” 和 “飞机” 样本)。
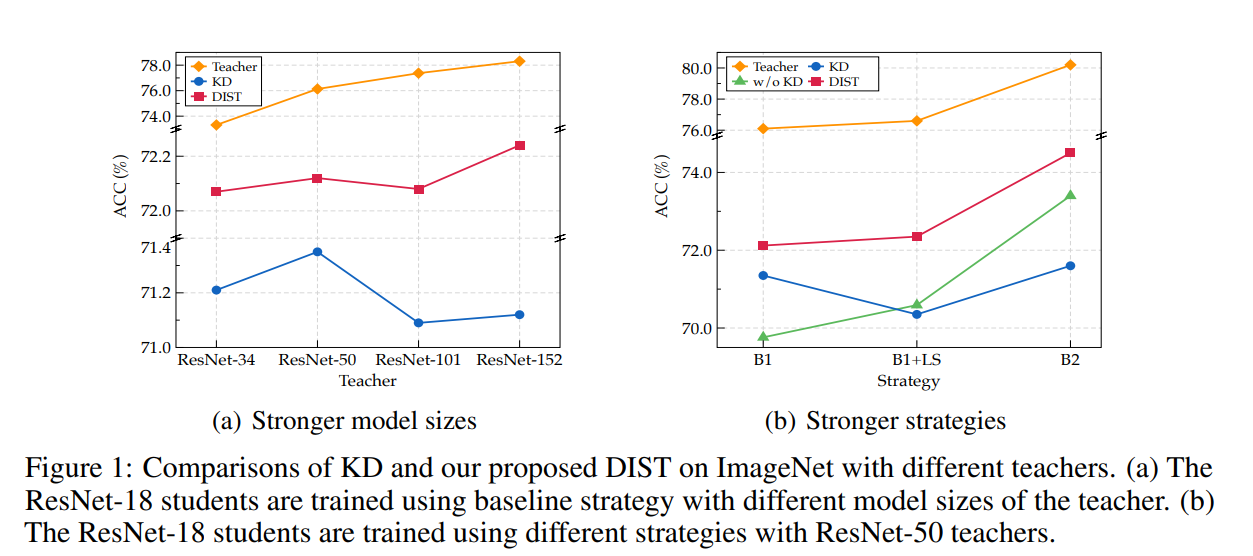
- 图 1 ImageNet 上不同教师模型与训练策略下,传统 KD 与 DIST 方法性能对比
(a) 不同规模教师模型对比:以 ResNet-18 为学生网络、采用基线训练策略,分别使用不同大小的教师模型(从弱到强),对比传统 KD 与 DIST 方法的学生性能。可以看到,随着教师模型性能变强,传统 KD 的学生性能反而持续下降,甚至低于无蒸馏的基线水平;而 DIST 方法始终稳定提升学生性能,不受教师强度影响。
(b) 不同训练策略对比:固定 ResNet-50 为教师、ResNet-18 为学生,切换不同训练策略(基线→强策略,含标签平滑、高级数据增强等)。结果显示,师生均采用强训练策略时,传统 KD 性能大幅下滑,完全失效;DIST 方法仍能高效吸收强教师知识,性能显著优于传统 KD 与基线。
核心发现
传统知识蒸馏存在 “强教师悖论”:教师模型越强、训练策略越先进,师生间能力差距越大,KL 散度强制匹配预测分布的约束越难满足,最终导致学生性能倒退、蒸馏失效;而 DIST 方法通过保留师生预测的相对关系(偏好排序),避开了精确匹配绝对值的难题,完美适配强教师场景。
知识蒸馏中的匹配问题
公式
令 Z s Z^{s} Zs ∈ \in ∈ R B × C R^{B \times C} RB×C和 Z t Z^{t} Zt ∈ \in ∈ R B × C R^{B \times C} RB×C分别代表教师和学生模型的输出, 式中, B为 Batch Size, C为通道数。原始的 KD Loss 可以写成:
L KD : = τ 2 B ∑ i = 1 B KL ( Y i , : ( t ) , Y i , : ( s ) ) = τ 2 B ∑ i = 1 B ∑ j = 1 C Y i , j ( t ) log ( Y i , j ( t ) Y i , j ( s ) ) , (1) \mathcal{L}_{\text{KD}} := \frac{\tau^2}{B} \sum_{i=1}^{B} \text{KL}\left(\mathbf{Y}_{i,:}^{(t)}, \mathbf{Y}_{i,:}^{(s)}\right) = \frac{\tau^2}{B} \sum_{i=1}^{B} \sum_{j=1}^{C} Y_{i,j}^{(t)} \log\left( \frac{Y_{i,j}^{(t)}}{Y_{i,j}^{(s)}} \right), \tag{1} LKD:=Bτ2i=1∑BKL(Yi,:(t),Yi,:(s))=Bτ2i=1∑Bj=1∑CYi,j(t)log(Yi,j(s)Yi,j(t)),(1)
Y i , : ( s ) = softmax ( Z i , : ( s ) / τ ) , Y i , : ( t ) = softmax ( Z i , : ( t ) / τ ) , (2) \mathbf{Y}_{i,:}^{(s)} = \text{softmax}\left( \mathbf{Z}_{i,:}^{(s)} / \tau \right), \quad \mathbf{Y}_{i,:}^{(t)} = \text{softmax}\left( \mathbf{Z}_{i,:}^{(t)} / \tau \right), \tag{2} Yi,:(s)=softmax(Zi,:(s)/τ),Yi,:(t)=softmax(Zi,:(t)/τ),(2)
L tr = α L cls + β L KD , (3) \mathcal{L}_{\text{tr}} = \alpha \mathcal{L}_{\text{cls}} + \beta \mathcal{L}_{\text{KD}}, \tag{3} Ltr=αLcls+βLKD,(3)
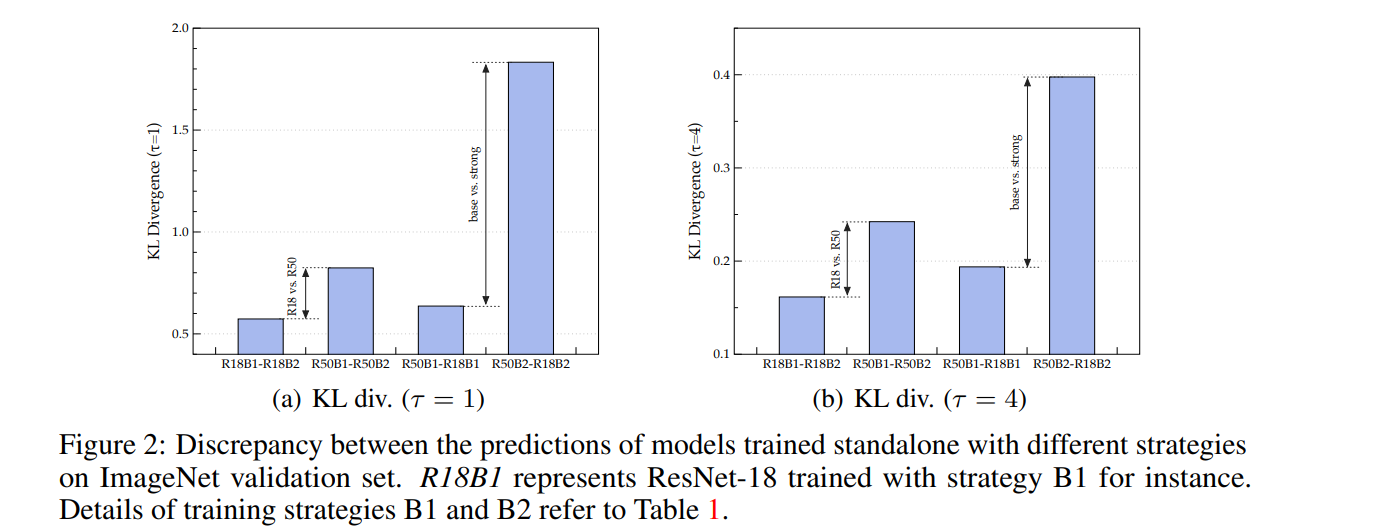

- 得出结论: 使用 B2 进行训练比使用 B1 获得更高的准确率,例如在 ResNet-18 上,B2的准确率为 73.4%,B1 为 69.8%。
DIST中的类间匹配
- 预测分数代表了一个模型对于所有类别的置信度,
d ( m 1 a + n 1 , m 2 b + n 2 ) = d ( a , b ) , (4) d(m_1 a + n_1, m_2 b + n_2) = d(a, b), \tag{4} d(m1a+n1,m2b+n2)=d(a,b),(4)
-
式子中, m 1 , m 2 , n 1 , n 2 m1,m2,n1,n2 m1,m2,n1,n2是常数,且有m1 × \times ×m2>0.那要使得式4完全成立,d(.,.)可以选择皮尔逊相关系数 d p ( u , v ) : = 1 − ρ p ( u , v ) . (5) d_p(u, v) := 1 - \rho_p(u, v). \tag{5} dp(u,v):=1−ρp(u,v).(5)
ρ p ( u , v ) : = Cov ( u , v ) Std ( u ) Std ( v ) = ∑ i = 1 C ( u i − u ˉ ) ( v i − v ˉ ) ∑ i = 1 C ( u i − u ˉ ) 2 ∑ i = 1 C ( v i − v ˉ ) 2 . (6) \rho_p(u, v) := \frac{\operatorname{Cov}(u, v)}{\operatorname{Std}(u)\operatorname{Std}(v)} = \frac{\sum_{i=1}^{C} (u_i - \bar{u})(v_i - \bar{v})}{\sqrt{\sum_{i=1}^{C} (u_i - \bar{u})^2 \sum_{i=1}^{C} (v_i - \bar{v})^2}}. \tag{6} ρp(u,v):=Std(u)Std(v)Cov(u,v)=∑i=1C(ui−uˉ)2∑i=1C(vi−vˉ)2∑i=1C(ui−uˉ)(vi−vˉ).(6) -
C o v ( u , v ) Cov(u,v) Cov(u,v)为标准差
-
式6相当于是把 correlation 视为 relation,它舍弃了传统的 KL 散度的精确匹配的模式,而是采用一种较为松弛的模式,希望保持住每个实例教师和学生模型输出向量的线性相关关系。作者称这样的匹配为类间匹配 (inter-class relation),写成公式就是:
L inter : = 1 B ∑ i = 1 B d p ( Y i , : ( s ) , Y i , : ( t ) ) . (7) \mathcal{L}_{\text{inter}} := \frac{1}{B} \sum_{i=1}^{B} d_p\left(\mathbf{Y}_{i,:}^{(s)}, \mathbf{Y}_{i,:}^{(t)}\right). \tag{7} Linter:=B1i=1∑Bdp(Yi,:(s),Yi,:(t)).(7)
DIST中的类内匹配
- 作者在类间关系基础上新增类内关系蒸馏,将同一类别下不同样本预测分数的相对排序规律从教师迁移给学生,让学生学习样本与类别间的相似度关联。
L intra : = 1 C ∑ j = 1 C d p ( Y : , j ( s ) , Y : , j ( t ) ) . (9) \mathcal{L}_{\text{intra}} := \frac{1}{C} \sum_{j=1}^{C} d_p\left(\mathbf{Y}_{:,j}^{(s)}, \mathbf{Y}_{:,j}^{(t)}\right). \tag{9} Lintra:=C1j=1∑Cdp(Y:,j(s),Y:,j(t)).(9)
L tr = α L cls + β L inter + γ L intra , (10) \mathcal{L}_{\text{tr}} = \alpha \mathcal{L}_{\text{cls}} + \beta \mathcal{L}_{\text{inter}} + \gamma \mathcal{L}_{\text{intra}}, \tag{10} Ltr=αLcls+βLinter+γLintra,(10)
实验结果
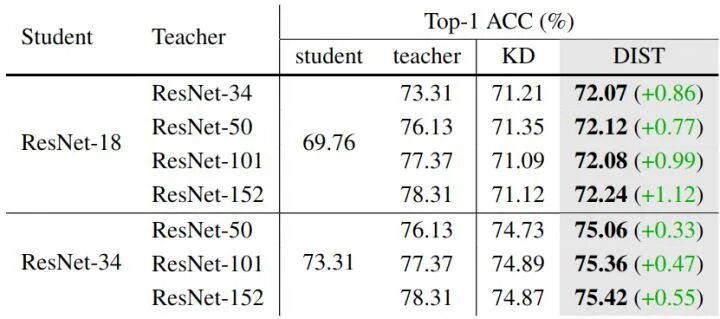
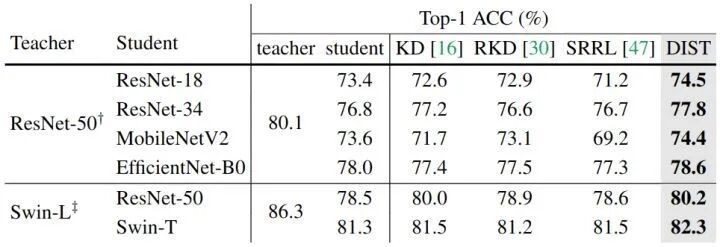
- ImageNet-1K 实验表明,面对规模更大的教师模型,DIST 能随教师能力增强持续提升 ResNet-18 学生性能,有效解决了传统 KD 在师生差距过大时性能下降的问题
总结
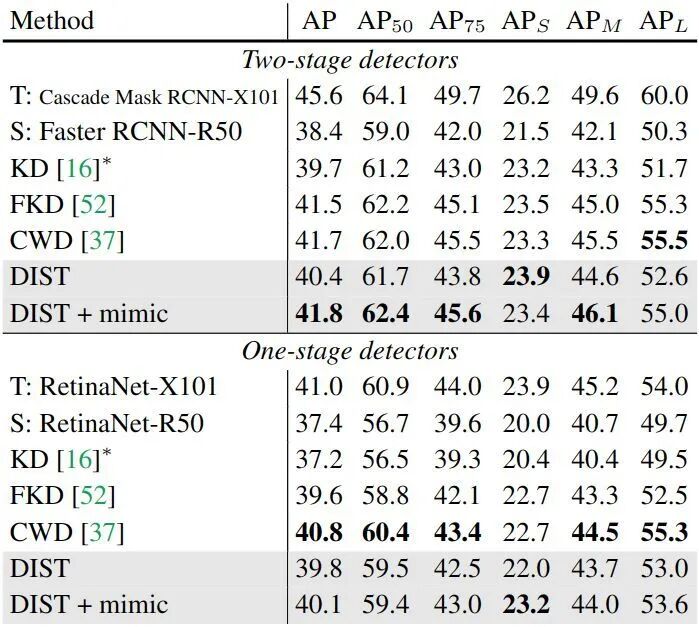
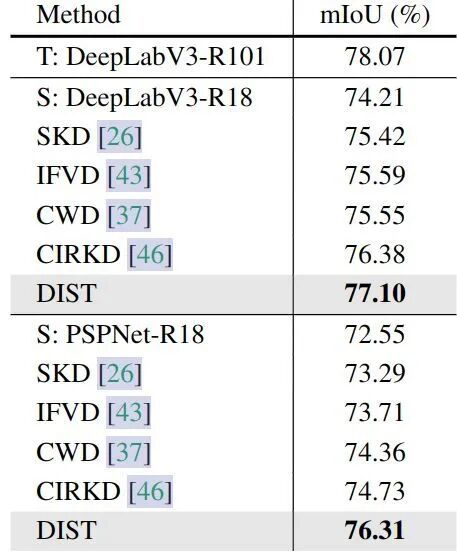
本文观察到,教师模型规模更大、训练策略更强时,传统知识蒸馏效果不佳,原因是 KL 散度的精确匹配要求过高。为此,作者提出兼顾类内、类间关系的松弛蒸馏方法 DIST,在图像识别、目标检测、语义分割任务中均表现优异

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)