关于 ASR 实时推理与部署的深度调研报告-AI分析
以下是关于 ASR 实时推理与部署的深度调研报告,覆盖架构选型、工程优化、服务框架到延迟基准的全链路分析。
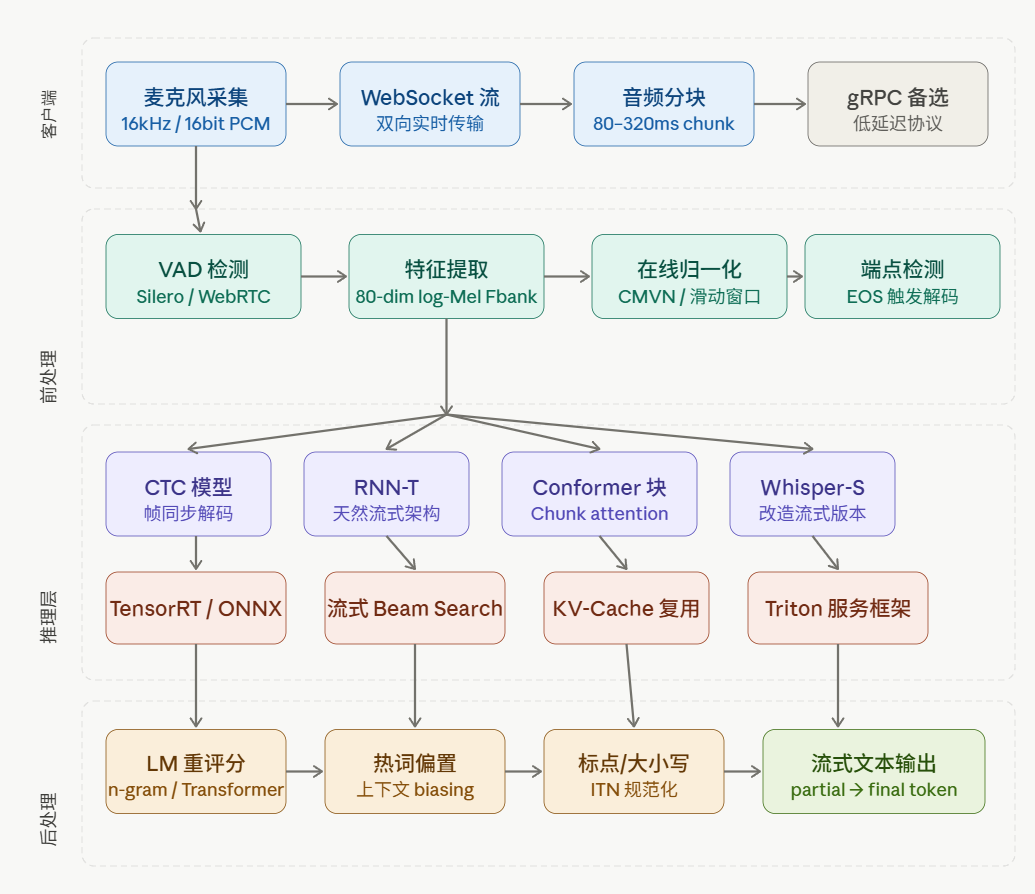
一、实时 ASR 的核心挑战
实时(Real-time)ASR 的本质问题是:在语音还未结束时就必须产出中间结果,这与离线 ASR"拿到全段音频再推理"的模式形成了根本矛盾。离线模型通常使用双向声学上下文训练,而流式系统必须在未来音频到达之前就输出 token,这种训练与推理的不匹配在低延迟场景下会导致精度显著下降。
三个核心指标始终需要平衡:WER(词错误率)、End-to-End 延迟、计算成本。团队往往只关注精度而忽视延迟目标,正确做法是早期定义可接受延迟上限,然后端对端测量延迟,并依此调优缓冲区大小和模型规模。
二、模型架构选型
流式 ASR 有三大主流端到端范式,各有优劣:
2.1 CTC(Connectionist Temporal Classification)
CTC 方式拥有简洁的 encoder-only 架构,训练效率高,天然适合分块流式推理,但其条件独立假设会影响建模能力。流式 CTC 的关键是让 encoder 以 causal 卷积 + 分块 attention 的方式运行,每处理完一个 chunk 即可输出帧级 logits,延迟与 chunk size 成正比。
2.2 RNN-T(Transducer)
RNN-T 和 AED 都克服了 CTC 的条件独立假设。对于 RNN-T,流式推理可通过对 encoder 做分块或使用因果神经网络 encoder 来实现。基于 Conformer-CTC 架构的模型可在 GPU 上实现低于 0.2 实时率(RTF < 0.2),适合流式对话和呼叫中心场景。
RNN-T 是当前工业界最主流的流式 ASR 架构,支持帧同步解码,理论延迟可控制在 chunk 大小(80–320ms)范围内。
2.3 AED + 分块注意力(Attention-based Encoder-Decoder)
AED 架构启用流式的主要方法是分块注意力:将输入音频划分为固定大小的 chunk,每块只关注当前及历史块。
2.4 两阶段混合解码(Two-Pass Streaming)
在两阶段流式 ASR(如 U2-Whisper)中,第一阶段 CTC 解码器用因果 attention mask 输出流式中间假设,第二阶段在检测到端点后使用全上下文 attention 对结果重排,兼顾低延迟与高精度。这是目前精度与延迟综合表现最好的方案之一。
2.5 统一架构(All-in-One ASR)
ICASSP 2025 提出的 All-in-One ASR 框架允许单一模型同时支持 CTC、AED 和 Transducer 三种范式,并兼容离线与流式模式,通过 multi-mode joiner 实现整合,显著降低部署维护成本。
三、关键工程技术
3.1 VAD 语音活动检测
VAD 是流式 ASR 的"开关",用于过滤静音、触发解码、确定端点。精心调优的 VAD 确保语音 Agent 在合适时机响应——不过早(打断用户)也不过晚(产生死寂),是实现实时体验的关键系统设计之一。
常用方案:Silero VAD(轻量神经网络)、WebRTC VAD(规则驱动,更低延迟)。
3.2 分块策略(Chunking)
流式模型对到来的音频按小块(通常几十到几百毫秒)分段处理,每块到达即送入模型,后续块更新上下文并细化假设。chunk size 是延迟与精度的核心权衡参数:越小延迟越低,但上下文不足导致 WER 上升。
3.3 KV-Cache 与因果注意力
在 Transformer-based 流式模型中,每一步仅需计算当前 chunk 的新 key/value,历史 chunk 的 KV 被缓存复用,这避免了对全序列的重复计算,是降低延迟的核心工程优化。Voxtral Realtime 在 Transformer backbone 中采用 RMSNorm、SwiGLU 和 RoPE,并使用滑动窗口 self-attention,encoder 每 20ms 输出一个 embedding(50Hz),实现高效流式推理。
3.4 模型压缩
| 技术 | 原理 | 典型效果 |
|---|---|---|
| FP16 量化 | 半精度推理 | 能耗减半,精度损失极小 |
| INT8 量化 | 整数推理 | 内存减少 4×,延迟下降 |
| ONNX 导出 | 框架无关部署 | CPU 推理加速 1.3–2.9× |
| TensorRT | GPU 内核融合 | 延迟可降至 FP32 的 50% |
| 知识蒸馏 | 小模型逼近大模型 | 参数减少 10× 以上 |
基于 LoRA + INT8 的方案可将 Whisper-tiny 压缩至 60MB,在 Apple M1 CPU 上实现 RTF=0.20(5倍实时),在 NVIDIA A10 GPU 上达到 RTF=0.06,满足高并发云服务需求。
从 FP32 改为 FP16 可将音频转录的能耗减半,且性能降级极小;更大的模型并不保证更强的噪声鲁棒性,也不能预测能耗。
四、服务部署框架
4.1 NVIDIA Triton Inference Server
Triton 支持 TensorRT、PyTorch、ONNX、OpenVINO 等主流框架,可跨云端、数据中心、边缘和嵌入式设备部署,支持实时、批处理、Ensemble 和音视频流式推理,提供 HTTP/REST 和 gRPC 接口。
Triton 的动态批处理(Dynamic Batching)可将多个推理请求合并为一批,大幅提升吞吐量并降低延迟,特别适合实时应用。
4.2 流式传输协议选择
- WebSocket:双向全双工,适合浏览器端实时 ASR。WebSocket 流式传输可消除连接开销,是实现最低延迟 STT API 的关键基础设施。
- gRPC:基于 HTTP/2,延迟更低,适合服务间调用。
- 专有 TCP/UDP:极端低延迟场景。
4.3 边缘/端侧部署
WhisperKit 是专为 Apple 设备设计的优化推理系统,修改了 Whisper 的音频编码器使其原生支持流式推理,并在 Apple Neural Engine 上重实现以达到接近峰值的硬件利用率,同时保持足够的能效满足端侧部署需求。
在超过 50 种配置的系统基准测试中,NVIDIA Nemotron Speech Streaming 被确认为资源受限硬件上实时英文流式 ASR 的最佳候选,研究者在 ONNX Runtime 中重实现了完整推理流水线并评估了多种后训练量化策略。
五、延迟优化综合策略
以下是一个端到端延迟分解视图:
典型延迟来源(总目标 < 500ms):
| 阶段 | 延迟来源 | 优化手段 |
|---|---|---|
| 音频采集 | 缓冲区大小 | 20ms chunk,异步 I/O |
| 网络传输 | RTT | WebSocket 长连接,就近部署 |
| VAD | 静音检测 | Silero VAD,阈值调优 |
| 特征提取 | STFT/Fbank | GPU 加速,CUDA kernel |
| 模型推理 | 前向传播 | TensorRT INT8,KV-Cache |
| 解码 | Beam Search | Greedy 或 small-beam |
| 后处理 | LM 重评分 | 轻量 n-gram 或跳过 |
通过 VAD 指导分块、推理流水线并行(VAD → Whisper → 后处理阶段重叠)、动态批处理与内存池化,可在单张 H100 上实现 1300× 实时速度,延迟低于 100ms。
关于 Whisper 流式改造
Whisper-Streaming 通过局部一致性策略(local agreement policy)和自适应延迟实现了流式转录,在欧洲议会语音测试集上达到 3.3 秒平均延迟。但原生 Whisper 基于 30 秒固定窗口设计,对流式场景需要深度改造。
Moonshine 是 Whisper 的重构版本,移除了对 30 秒缓冲区的依赖,显著提升流式效率,但在长文本转录上存在精度损失,且已发布的模型规模未超过 tiny 和 base 级别。
WhisperFlow 通过系统级优化将每词延迟降低 1.6×–4.7×,最低可达 0.5 秒,在入门级 MacBook Air 上保持约 1 秒的每词延迟,整机功耗仅 7 瓦。
六、实践路线推荐
根据不同场景,推荐如下选型路线:
场景 A:云端实时字幕 / 会议转录 最佳架构 → Conformer/Emformer + CTC,TensorRT FP16,Triton 部署,gRPC 传输,服务端 VAD。
场景 B:语音助手 / 对话 Agent(< 300ms 延迟) 最佳架构 → RNN-T + 两阶段解码,INT8 量化,动态批处理,WebSocket 传输,Silero VAD。
场景 C:端侧/离线设备(手机/嵌入式) 最佳架构 → 蒸馏小模型 + ONNX Runtime INT8,CoreML(Apple)或 NNAPI(Android),WhisperKit 方案可参考。
场景 D:高准确率优先(可接受 500ms+ 延迟) 最佳架构 → Whisper Large v3 Turbo 两阶段,Beam Search + LM 重评分,批处理推理。
七、关键结论
- 架构决定延迟下限:RNN-T 和 CTC 是天然流式架构,Whisper 类 AED 需要改造后才能实现真正的流式;
- VAD 和 Chunking 是工程核心:chunk size、VAD 阈值是延迟与精度的主要调节旋钮;
- 量化是部署必选项:TensorRT INT8 / FP16 可将延迟降低 2–4×,生产环境应默认开启;
- 两阶段解码是精度与延迟的最佳平衡:第一阶段快速 CTC 输出中间结果,第二阶段 attention 重评分提升最终精度;
- WebSocket + Triton 是云端流式部署的黄金组合,gRPC 适合微服务间调用场景。
如需深入某个具体方向(如 RNN-T 解码实现、Triton 部署配置、Whisper 流式改造代码),可以进一步展开。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)