05|Netty ByteBuf 源码分析:为什么不用 Java ByteBuffer
05|Netty ByteBuf 源码分析:为什么不用 Java ByteBuffer
前面几篇我们已经看过:
- ServerBootstrap 如何启动
- EventLoop 如何循环
- Pipeline 如何传播事件
这一篇看 Netty 另一个核心:
ByteBuf
我学 ByteBuf,不只是为了知道 Netty 为什么不用 ByteBuffer。
更重要的是,它提醒我:很多业务系统里的“性能问题”,最后都会落到数据如何被搬运、缓存、复用和释放。
在云边协同这类系统里,数据流动的形态很多:
- 视频流持续进出;
- MQTT payload 持续解析和转发;
- HTTP / Gateway 响应需要写回客户端;
- 大文件需要上传到对象存储;
- 日志、状态、任务结果也会不断在云边之间流动。
这些链路表面上不一定都直接使用 Netty ByteBuf。
但它们背后都绕不开同一类架构问题:
- 数据是不是被反复复制?
- 临时对象是不是太多?
- 缓冲区生命周期是否清楚?
- 慢链路是否导致内存堆积?
- 大对象、大 payload、大文件是否和普通请求混在一起处理?
所以这一篇看 ByteBuf,我真正想补的是“数据路径意识”:
高吞吐系统里,数据不是抽象地流动,它一定会占用内存、线程、队列和 IO 资源。
如果说 EventLoop 解决的是:
连接和事件如何调度。
Pipeline 解决的是:
IO 事件如何流向业务逻辑。
那么 ByteBuf 解决的是:
网络数据如何高效存储、读写、复用和释放。
很多人学 Netty 时容易只盯着线程模型,却忽略内存管理。
但对高并发网络框架来说,内存管理同样是性能核心。
因为网络系统会频繁做:
- 读 socket
- 写 socket
- 拆包
- 粘包
- 编解码
- 临时缓存
- 消息聚合
如果每次都创建新的 byte[] 或 ByteBuffer,很容易带来:
- 频繁内存分配
- GC 压力
- 内存压力和泄漏风险
- 吞吐抖动
- 延迟毛刺
Netty 自己设计 ByteBuf,就是为了把网络数据缓冲区这件事做得更适合高并发场景。
一、Java ByteBuffer 有什么问题?
Java NIO 原生提供的是:
java.nio.ByteBuffer
它可以分为:
HeapByteBufferDirectByteBuffer
堆内 ByteBuffer 存在 JVM 堆里。
直接内存 ByteBuffer 存在堆外,更适合和操作系统 IO 交互。
ByteBuffer 本身并不是不能用,但在网络编程里有几个明显不舒服的点。
第一,读写模式依赖 flip()。
典型流程是:
buffer.put(data);
buffer.flip();
channel.write(buffer);
buffer.clear();
这要求开发者非常清楚当前 buffer 是写模式还是读模式。
稍不注意就容易写错。
第二,只有一个 position。
ByteBuffer 通过:
positionlimitcapacity
表达读写状态。
但网络数据处理里,经常需要同时维护:
- 读到哪里了
- 写到哪里了
一个 position 会让状态管理不够直观。
第三,扩容不方便。
如果 buffer 不够大,需要自己创建新 buffer,再拷贝旧数据。
第四,池化和引用释放不是统一模型。
高并发网络系统需要频繁申请和释放缓冲区。
如果没有清晰的池化和生命周期模型,性能和稳定性都会受影响。
所以 Netty 没有直接把 ByteBuffer 暴露成核心数据结构,而是设计了:
ByteBuf
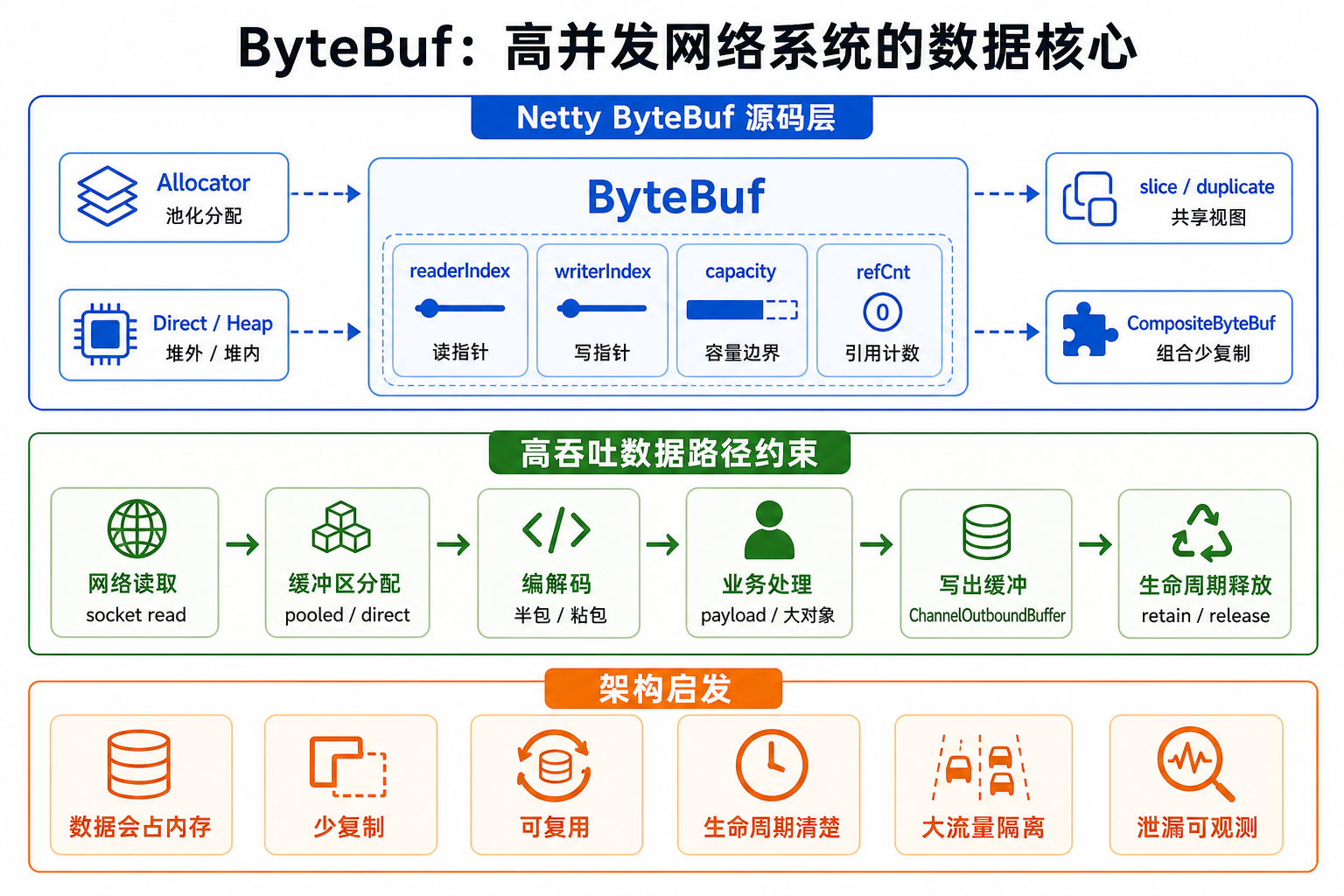
二、ByteBuf 的核心设计:readerIndex 和 writerIndex
ByteBuf 最核心的改进是把读写指针分开:
readerIndexwriterIndexcapacity
可以理解成:
0 -------- readerIndex -------- writerIndex -------- capacity- | 已读区域 | 可读区域 | 可写区域 |
其中:
readerIndex:
下一次读从哪里开始。writerIndex:
下一次写从哪里开始。capacity:
当前缓冲区容量。
可读字节数:
readableBytes = writerIndex - readerIndex
可写字节数:
writableBytes = capacity - writerIndex
这样就不需要像 ByteBuffer 那样反复 flip()。
写数据时,移动 writerIndex。
读数据时,移动 readerIndex。
比如:
ByteBuf buf = allocator.buffer();
buf.writeBytes(data);
while (buf.isReadable()) {
byte b = buf.readByte();
}
这个模型对网络协议解析非常自然。
因为解码器经常需要:
- 看看当前可读数据够不够一个完整包
- 够了就读
- 不够就等下一次数据到来
ByteBuf 的双指针模型正好适合这个场景。
三、ByteBuf 的常见类型
Netty 的 ByteBuf 有很多实现。
可以从几个维度理解。
第一个维度:堆内还是堆外。
HeapByteBuf:
数据在 JVM 堆内,底层通常是 byte[]。DirectByteBuf:
数据在堆外直接内存,更适合 socket IO。
为什么网络 IO 更偏向 DirectByteBuf?
因为操作系统进行 socket 读写时,最终要和本地内存交互。
如果使用堆内 byte[],JVM 和本地 IO 之间可能还需要额外拷贝。
而直接内存更接近底层 IO 需要的内存形态。
第二个维度:池化还是非池化。
PooledByteBuf:
从内存池中分配,释放后可以复用。UnpooledByteBuf:
每次单独分配,不复用。
高并发场景下,池化非常重要。
因为网络服务会频繁创建临时缓冲区。
如果每次都向系统申请内存,成本很高,也容易造成 GC 或堆外内存压力。
第三个维度:组合缓冲区。
CompositeByteBuf
它可以把多个 ByteBuf 组合成一个逻辑上的 ByteBuf。
这对减少数据复制很有帮助。
比如 HTTP 响应可以由:
- 响应头 ByteBuf
- 响应体 ByteBuf
组合起来发送,而不一定要复制成一个大 buffer。
四、ByteBufAllocator:谁负责分配 ByteBuf?
ByteBuf 通常不是直接 new 出来的。
Netty 使用:
ByteBufAllocator
常见入口是:
ByteBufAllocator allocator = ctx.alloc();
ByteBuf buf = allocator.buffer();
ctx.alloc() 会拿到当前 Channel 关联的 allocator。
常见实现有:
PooledByteBufAllocatorUnpooledByteBufAllocator
默认情况下,Netty 常用池化分配器:
PooledByteBufAllocator
池化的目标是:
- 减少频繁内存申请和释放
- 复用内存块
- 降低 GC 压力
- 提高吞吐稳定性
这和数据库连接池、线程池的思想类似。
不是每次都创建新资源,而是从池里拿,用完归还。
五、PooledByteBufAllocator 大概怎么池化?
Netty 的池化内存管理比较复杂,完整展开可以单独写一篇。
这里先抓主线。
PooledByteBufAllocator 内部有几个核心概念:
ArenaChunkPageSubpageThreadLocalCache
可以粗略理解为:
Arena:
一组内存池管理区域。Chunk:
一大块连续内存。Page:
Chunk 被切分后的页。Subpage:
Page 继续切分,用于小对象分配。ThreadLocalCache:
每个线程的本地缓存,减少竞争。
为什么要这么复杂?
因为网络场景的内存申请很频繁,而且大小不一。
有时需要小 buffer:
- 几十字节
- 几百字节
有时需要大 buffer:
- 几 KB
- 几十 KB
如果每次都向操作系统申请和释放,会很慢。
Netty 通过池化和分级管理,尽量做到:
- 小内存快速分配
- 大内存减少碎片
- 线程本地缓存减少锁竞争
- 释放后尽可能复用
这也是 Netty 高性能的底层原因之一。
六、引用计数:retain 和 release
ByteBuf 另一个非常重要的设计是:
引用计数
ByteBuf 实现了:
ReferenceCounted
核心方法包括:
int refCnt();
ByteBuf retain();
boolean release();
初始情况下,一个 ByteBuf 的引用计数通常是:
refCnt = 1
当你需要延长它的生命周期,可以调用:
buf.retain();
引用计数加 1。
当使用完毕,需要调用:
buf.release();
引用计数减 1。
当引用计数变成 0,底层内存可以被释放或归还给内存池。
这带来一个非常重要的问题:
谁负责 release?
如果 release 少了,会内存泄漏。
如果 release 多了,会出现访问已释放内存的问题。
七、为什么会发生 ByteBuf 泄漏?
ByteBuf 泄漏通常发生在:
拿到了 ByteBuf,但没有释放。
比如在 Handler 中拦截消息:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf buf = (ByteBuf) msg;
// 处理后没有继续传递,也没有 release
}
如果你不继续传递:
ctx.fireChannelRead(msg);
也不释放:
ReferenceCountUtil.release(msg);
那么这个 ByteBuf 就可能泄漏。
常见规则是:
- 如果你消费了 ByteBuf,就要负责释放。
- 如果你继续向后传递,就不要在这里释放。
例如:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
try {
ByteBuf buf = (ByteBuf) msg;
// 消费数据
} finally {
ReferenceCountUtil.release(msg);
}
}
如果要继续传递:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ctx.fireChannelRead(msg);
}
就不要在当前 Handler 中 release。
八、Netty 如何检测内存泄漏?
Netty 提供了资源泄漏检测机制:
ResourceLeakDetector
可以通过系统参数调整检测级别:
io.netty.leakDetection.level
常见级别有:
DISABLEDSIMPLEADVANCEDPARANOID
默认通常是 SIMPLE。
开发或排查问题时,可以调高到:
ADVANCEDPARANOID
但级别越高,开销越大。
所以生产环境一般不建议长期使用最高级别。
如果看到类似:
LEAK: ByteBuf.release() was not called
基本就说明有 ByteBuf 没有正确释放。
九、slice、duplicate 和 copy 的区别
ByteBuf 中几个方法也很容易混淆:
slice()
duplicate()
copy()
slice():
- 切出一段视图。
- 共享底层内存。
- 有独立 readerIndex / writerIndex。
- 通常不额外增加引用计数。
duplicate():
- 复制一个视图。
- 共享底层内存。
- 有独立读写指针。
- 通常不额外增加引用计数。
copy():
- 真正复制数据。
- 新 ByteBuf 有自己的底层内存。
所以:
- slice / duplicate 不复制数据。
- copy 会复制数据。
这很重要。
如果你希望减少拷贝,可以用 slice 或 duplicate。
但也要注意生命周期。
因为它们共享底层内存,原始 ByteBuf 被释放后,视图也不能继续安全使用。
如果你要把切片后的 ByteBuf 继续传递到后续 Handler 或跨线程使用,通常要考虑:
retainedSlice()
retainedDuplicate()
它们会在创建派生视图时增加引用计数,更适合明确延长生命周期的场景。
如果你需要一份独立数据,就用 copy。
十、CompositeByteBuf:组合而不是复制
CompositeByteBuf 可以把多个 ByteBuf 组合成一个逻辑 ByteBuf。
比如:
headerBufbodyBuf
可以组合成:
compositeBuf = headerBuf + bodyBuf
逻辑上像一个连续 buffer。
但底层不一定真的复制成一块连续内存。
这对减少数据复制很有帮助。
例如协议响应中:
- 响应头
- 响应体
如果每次都拼接成一个大数组,就会有额外拷贝。
CompositeByteBuf 让 Netty 可以用组合的方式表达连续数据。
这也是 Netty 零拷贝思想的一种体现。
注意这里说的是 Netty 层面的零拷贝:
减少应用层内存复制。
它和 Linux sendfile 那种 file -> socket 的系统级零拷贝不是同一个层次,但思想类似。
十一、ByteBuf 和编解码的关系
ByteBuf 是编解码器的基础。
例如 ByteToMessageDecoder 的输入就是 ByteBuf。
解码器会检查:
in.readableBytes()
判断当前数据是否足够解析一个完整消息。
如果不够,就先返回,等待下一次数据到来。
如果够,就读取字段:
int length = in.readInt();
byte[] body = new byte[length];
in.readBytes(body);
这个过程依赖 ByteBuf 的:
readerIndexwriterIndexmarkReaderIndexresetReaderIndexreadableBytes
所以 ByteBuf 不是孤立存在的。
它和半包粘包、协议解析、Pipeline 编解码紧密相关。
十二、使用 ByteBuf 的基本原则
实践中可以记住几条规则。
第一,明确所有权。
- 谁消费 ByteBuf,谁负责 release。
- 继续传递就不要 release。
第二,避免无意义 copy。
能 slice / duplicate / composite,就不要随便 copy。
但减少 copy 的前提是生命周期清楚;如果生命周期不清楚,盲目共享底层内存反而容易导致释放错误。
第三,跨线程使用要谨慎。
如果 ByteBuf 要传到其他线程处理,要明确生命周期,必要时:
retain()
处理完再:
release()
第四,不要在业务代码里长期持有 ByteBuf。
ByteBuf 是网络缓冲区,不适合随便缓存到业务对象里长期保存。
如果确实要长期保存内容,最好复制成业务自己的数据结构。
第五,排查问题时打开泄漏检测。
-Dio.netty.leakDetection.level=ADVANCED
十三、对我的架构判断有什么用?
学完 ByteBuf 后,我以后看高吞吐链路时,不会只问:
- 功能有没有跑通?
- 传输协议选了什么?
- 接口响应快不快?
而会继续追问:
- 数据在链路中被复制了几次?
- 每一段缓冲区由谁分配、谁释放?
- 是否存在大 payload 或大文件把普通请求链路拖慢?
- 是否有池化、复用或分层传输策略?
- 如果某一侧变慢,数据会堆在哪里?
- 监控里能不能看到内存、队列、写出、上传和带宽的压力?
放到媒体、消息和文件链路里,这个视角可以转化为一组成本判断:
- 视频流不要只看协议转换,还要看持续数据搬运和缓冲压力;
- MQTT 消息不要只看 topic,还要看 payload 解析、转发和对象创建成本;
- 大文件上传不要和实时控制链路混在一起评估,要单独看带宽、分片、重试和内存占用;
- Gateway 响应不要只看路由成功,还要看慢客户端和写出缓冲是否会拖住系统。
这就是 ByteBuf 对我的价值。
它不是一个单纯的 Netty 数据结构,而是在提醒我:
架构设计不能只设计消息语义,也要设计数据在内存和 IO 路径中的真实成本。
十四、结论
Netty 之所以不用 Java 原生 ByteBuffer,是因为高并发网络场景需要更强的缓冲区模型。
ByteBuf 的核心价值包括:
- readerIndex / writerIndex 分离
- 更自然的网络读写模型
- 支持堆内和堆外内存
- 支持池化分配
- 支持引用计数
- 支持 slice / duplicate / composite 减少复制
- 更适合协议编解码
如果说 EventLoop 是 Netty 的调度核心,Pipeline 是 Netty 的扩展核心,那么 ByteBuf 就是 Netty 的数据核心。
它解决的是:
高并发网络系统中,数据如何高效地读、写、复用和释放。
理解 ByteBuf 后,再看半包粘包、编解码器、writeAndFlush、零拷贝和内存泄漏,就会清楚很多。
下一篇我们继续看:
Netty writeAndFlush 之后到底发生了什么?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)