从一次词向量实验出发:关于AI能力边界的几个底层问题
0. 前言
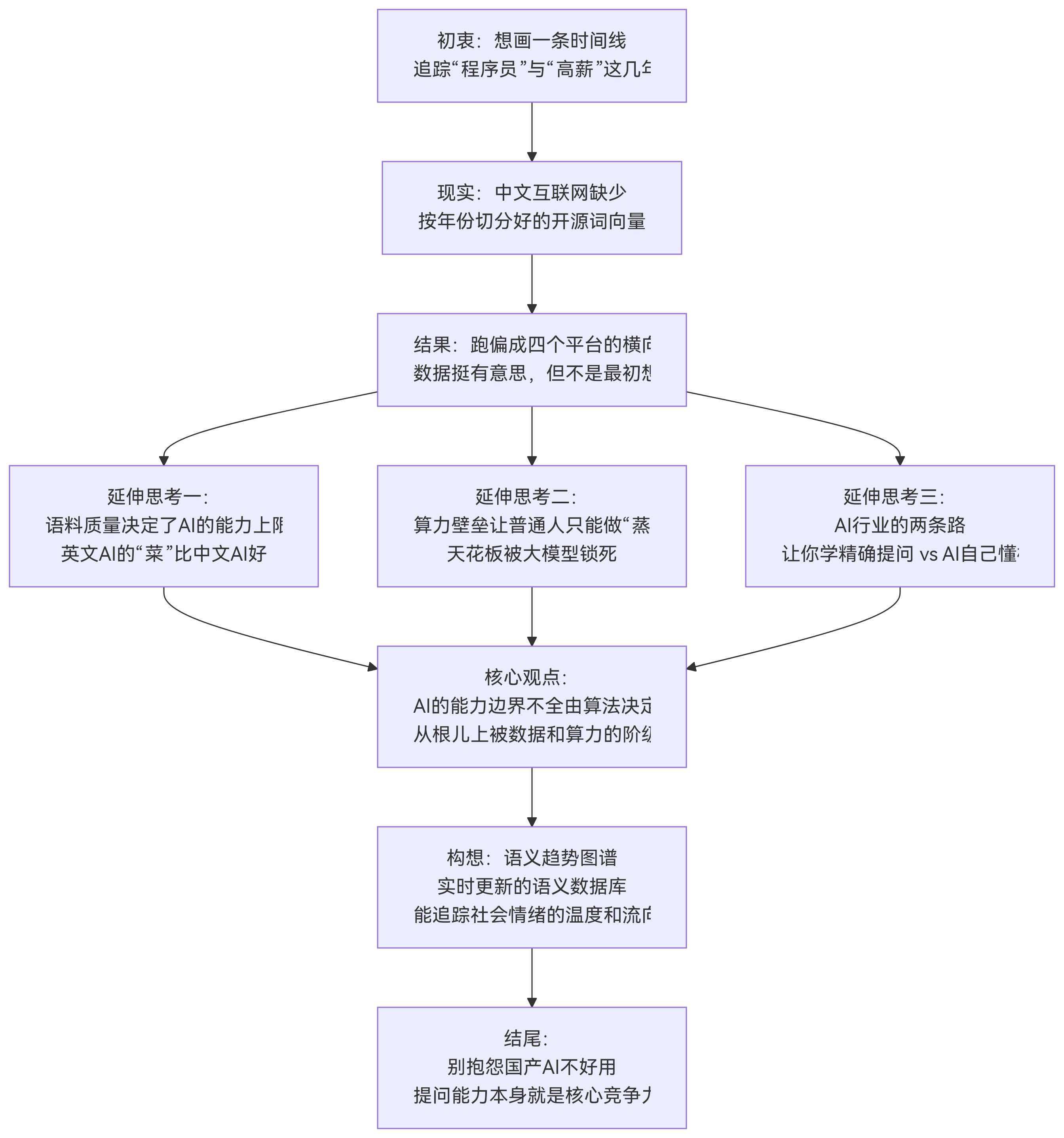
上上篇跑通了迷你Transformer,上篇用四个平台的开源词向量,对比了“程序员”在不同社区里的语义距离。数据出来了,结论也有了。
但跑完的那一刻,我心里冒出了一句不太甘心的话:搞错了。我一开始想做的,根本不是这个。
我想做的,是看“程序员”和“高薪”这两个词,在过去五年里,每年是更近了还是更远了。我想画一条带年份的折线图,横轴是时间,纵轴是余弦相似度,看那条线在2019年、2020年、2022年分别拐向哪里。这才是我从最开始就想验证的东西——不是“知乎和微博谁更焦虑”,而是“我们这个社会对程序员的想象,这几年到底发生了什么变化”。
结果呢?我跑了四个平台的横向对比,发现知乎确实比微博更焦虑,人民日报那列竟然没几个N/A,Mixed-large作为综合基准线表现得四平八稳。这些发现很有意思,但它不是我最初想回答的那个问题。
为什么会跑偏?因为中文互联网,没有现成的、按年份切分好的开源词向量。
这就是这篇文章想聊的事:数据和算力的阶级性,如何从一开始就框定了一个普通研究者能做到什么、做不到什么。以及,在这个限制下,那些把技术和社会观察杂交在一起的尝试,还有什么值得往下做的方向。
1. 语料的质量,决定AI的上限
很多人说国产AI不如国外的好用。问差在哪,说不上来。其实有个很直接的原因:英文AI吃的“菜”,就是比中文AI好。
英文互联网免费开放的高质量语料有很多。维基百科,几百万条经过反复审核的百科条目。Reddit,各种小众领域的深度讨论。Stack Overflow,程序员遇到任何问题都能找到详细解答。arXiv,几十万篇理工科论文。它们的共同点是:长文本、高质量、结构化、免费公开。
中文互联网的高质量语料在哪?一部分在知乎,但知乎很多回答是个人经验碎片,逻辑性和系统性不如英文社区。微信公众号内容质量不低,但是封闭的,很难被大规模爬取。百度百科的严谨性和覆盖面,和维基百科比还有差距。至于媲美Stack Overflow的中文技术社区、媲美arXiv的中文预印本平台,目前还没有。
这不是某个公司的问题。是中文互联网的内容质量和开放程度,整体上还有差距。
AI不是魔法。你喂给它的语料是什么样,它长出来就是什么样。这不是架构的问题——大家都用Transformer,都用了自注意力机制。这是数据的贫富差距。

2. 技术垄断下的“蒸馏”:普通人的天花板
说完了数据,再说算力。
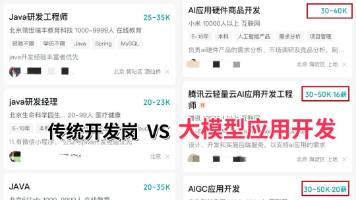
现在训练一个千亿参数的大模型,成本是用“亿美元”来算的。一次训练的电费,可能抵得上一所普通大学全年的预算。从头训练一个顶尖大模型的能力,从一开始就掌握在极少数人手里。
普通人能干嘛?普通人只能站在巨人的肩膀上,做些力所能及的工作。比如蒸馏——把一个大模型里学会的知识,压缩进一个小模型里。不用从头训练,只需要用大模型的输出作为“教材”,让小型模型去学习。
听起来很美好,但问题是:蒸馏出来的模型,能力天花板是被大模型锁死的。它只是一个更轻量、更省算力的影子,不是一个新的太阳。
更麻烦的是,如果语料本身就被污染了——被偏见、被商业软文塞满了关键词——那么大模型的词向量映射关系,从一开始就是偏的。蒸馏到小模型里,只会更偏。技术一直在往前跑,但语料的质量,才是一切问题的源头。
我自己用的词向量数据,是高校开源项目提供的。他们也是大学,才有算力和资源去做这件事。如果这个项目哪天停更了,下一个想自己跑实验的人,可能就被卡住了。
3. 两条路:更精确的指令,还是更模糊的理解
数据和算力的差距,是已经存在的客观事实。在这个事实面前,AI行业正在往两个不同的方向分化。具体的产品名字记不太清了,但大致意思是:一条路,是让你学会更精确地提问;另一条路,是让AI自己去理解你那些模糊的、碎片化的、不完整的表达。
前者需要更干净、更结构化的数据。后者需要更庞大、更多样的语料。
这也是我很久之前就想过的一个问题:为什么每次生图或写东西,都要自己去学一套提示词的写法?为什么不能是我随便说几句,它就懂了?这两年有些工具已经在这方面进步很大,可能就是因为它们在模糊语义的理解上下了更多的功夫。
但不管走哪条路,都绕不开语料的问题。
4. 一些不算结尾的结尾
我做这件事的初衷很简单。就是想画一条线——横轴是年份,纵轴是语义距离,看“程序员”和“高薪”这几年到底是更近了还是更远了。结果这条线没画出来,因为中文互联网暂时没有现成的、按年份切分好的开源词向量。最后跑出来的,是四个平台的横向对比。数据挺有意思,但它不是我最初想回答的那个问题。
我觉得词向量这东西,不只是一堆冷冰冰的数字。它更像是某个特定时期、特定人群的集体潜意识的快照。你每一次按下Shift+Enter,它都在告诉你,有一群人是如何看待他们所处的这个世界的。它不是什么纯技术的产物,更像是一种技术和社会观察杂交出来的东西。
顺着这个想法往下走,我一直在想一件事:如果有一个足够大的、实时更新的语义数据库,再配上一套能算词与词之间距离和热度变化的算法,是不是就能做出一张“语义趋势图谱”?不是静态的词云,是动态的、能显示社会情绪温度和流向的地图。能看到某个概念正在被社会重新定义,能看到某种焦虑正在从一个小圈子往更广的人群里蔓延。我不知道这个东西具体该叫什么,也不知道谁能把它做出来。但如果有人看到了这个想法,愿意去试试,我会很高兴。
别老是抱怨国产AI不好用。如果你只会用最模糊的方式提问,换GPT来也救不了你。提问能力本身,也是使用AI的核心竞争力之一。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)