具身智能中的传感器技术49——麦克风阵列4
**摘要:**麦克风阵列产业已进入"硬件红海,算法为王"阶段。硬件层由歌尔、瑞声等国产厂商主导,算法层则聚焦语音前端处理技术,科大讯飞、思必驰等提供核心方案。行业痛点在于嘈杂环境下的"鸡尾酒会问题",未来趋势将向视听融合(Audio-Visual Fusion)和边缘计算发展。具身智能领域复用成熟供应链,但面临机器人电机噪音等新挑战,AI大模型正重构传统信号处理方式,多模态交互板卡将成为关键发展方向。硬件国产化与算法智能化是产业两大特征。
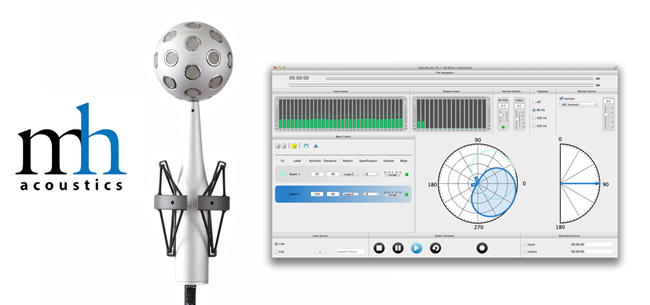
麦克风阵列产业目前处于**“硬件红海,算法为王”**的阶段。
随着智能音箱(Alexa/小爱同学)和新能源汽车(车载语音)的普及,麦克风阵列的供应链已经高度成熟且标准化。具身智能机器人基本是“坐享其成”,直接复用这些成熟方案。
一、 市场格局:软硬分离
1. 硬件层 (MEMS 麦克风芯片)
这是拼制造工艺和出货量的领域,中国厂商已占据半壁江山。
- 第一梯队 (全球霸主):
- 歌尔微电子 (Goertek Micro): 出货量全球第一。苹果、华为、小米的核心供应商。具身智能机器人 80% 用的都是歌尔的麦克风。
- 瑞声科技 (AAC): 全球前三。在微型化和封装技术上极强。
- 楼氏电子 (Knowles): 美国老牌巨头,依然把控着最高端的市场(如助听器级、极高 SNR 麦克风)。
- 第二梯队:
- 敏芯股份: 国内 MEMS 芯片设计强企。
- 共达电声。
2. 算法层 (语音前端处理 DSP)
这是具身智能真正的核心壁垒。光有麦克风没用,必须要有强大的降噪和定位算法。
- 通用语音巨头:
- 科大讯飞 (iFLYTEK): 依然是绕不过去的大山。提供从麦克风阵列板卡到云端识别的全套方案(麦克风阵列软核)。
- 思必驰 (AISpeech) / 云知声: 在车载和家居机器人领域份额很大,打法灵活,性价比高。
- 芯片级算法玩家:
- XMOS (英国): 他们的语音 DSP 芯片是行业标杆,算法固化在芯片里,性能极稳,很多高端机器人直接买芯片。
- Synaptics: 收购了 Conexant,在远场拾音领域积淀深厚。
3. 机器人垂直整合
头部机器人公司开始不满足于通用方案,开始自研:
- Tesla (Optimus): 依托其在车载语音上的积累,大概率会自研基于 Transformer 的端到端语音大模型,跳过传统的信号处理流程。
- 小米 (CyberOne): 复用小爱同学的声学技术栈。
二、 核心痛点与趋势
-
“鸡尾酒会问题”仍未完美解决:
- 在极度嘈杂的环境下(比如几个人同时说话,背景还有音乐),目前的阵列算法依然很难把目标人声完美分离出来。
- 趋势: 视听融合 (Audio-Visual Fusion)。
- 利用摄像头看到“谁嘴巴在动”,结合麦克风的声源定位,把视觉注意力机制引入听觉,大幅提升分离效果。
-
本地化 vs 云端:
- 以前语音识别都要上传云端。
- 趋势: 边缘计算。随着 Orin 这种高算力芯片上车,越来越多的降噪和唤醒算法直接在机器人本地跑,响应更快,隐私更好。
-
大模型重构:
- 传统的信号处理(AEC/BF)正在被 AI 降噪 取代。基于深度学习的降噪模型(如 RNNoise 的进阶版)能把非稳态噪音(如键盘声、关门声)滤得干干净净。
总结: 麦克风硬件已经白菜价,未来的竞争在于**“多模态交互”**——谁能把“听觉”和“视觉”结合得最好,谁的机器人就最聪明。
在具身智能(Humanoid Robot)这个细分赛道,麦克风阵列的产业现状呈现出**“复用成熟链条,探索AI重构”**的特点。
具身智能并没有重新发明麦克风,而是直接继承了智能音箱和智能座舱的遗产,但在算法层面正在进行一场**“视听融合”**的革命。
一、 硬件供应链:高度成熟,国产主导
机器人厂商在选购麦克风时,基本不需要定制,直接采购现成的 MEMS 麦克风。
-
芯片巨头 (MEMS Die):
- 楼氏 (Knowles) / 英飞凌 (Infineon): 依然占据高端(高 SNR > 70dB)市场。如果机器人需要在极嘈杂环境下工作,通常选它们。
- 歌尔微 (Goertek) / 瑞声 (AAC): 统治了中高端市场。性价比之王。绝大多数服务机器人和国产人形机器人(如优必选、追觅、小米)用的都是这两家的方案。
-
模组方案商 (PCBA):
- 机器人本体厂商很少自己画麦克风阵列的电路板(涉及到复杂的声学腔体设计),通常找方案商买板子。
- 科大讯飞: 提供 4麦/6麦 标准阵列板,算法硬化在芯片里,插上就能用,省心但贵。
- 声加科技 (SoundPlus): 在 TWS 耳机降噪领域很强,现在也切入机器人市场,算法非常能打。
- 蛙声科技: 专注于会议全向麦,技术迁移到机器人上很顺畅。
二、 算法生态:从 DSP 向 AI 大模型迁移
这才是具身智能麦克风阵列真正的战场。
-
传统 DSP 派 (信号处理):
- 代表: XMOS, Synaptics, 科大讯飞。
- 现状: 依然是主流。利用波束成形 (BF) 和回声消除 (AEC) 等数学公式处理声音。
- 痛点: 对非平稳噪声(如突然的摔杯子声、不规则的风噪)处理能力有限;且多轮对话打断体验一般。
-
AI 大模型派 (端到端):
- 代表: Tesla Optimus, Google RT-2。
- 趋势: Audio-Visual LLM。
- 不再单独处理声音。而是把声音波形直接作为 Token 喂给大模型。
- 视听融合: 机器人看着你的脸(视觉),结合听到的声音(听觉),利用唇语辅助和注意力机制,解决“鸡尾酒会效应”。这是传统 DSP 做不到的。
三、 具身智能的特殊需求与机会
虽然供应链成熟,但人形机器人带来了一些新挑战,也带来了新机会:
-
极致的自我消噪 (Ego-Noise Reduction):
- 痛点: 人形机器人全身几十个电机,走路时吱吱响,还有散热风扇的呼呼声。这比智能音箱(静止的)和汽车(隔音好)的声学环境恶劣得多。
- 机会: 谁能针对机器人电机噪音开发出专用的主动抑噪算法,谁就能赢。
-
多模态交互板卡:
- 趋势: 以前是买一块麦克风板子。未来是买一块**“视听一体板”**——上面集成了麦克风、摄像头接口和一颗 AI 算力芯片,直接输出“谁在说什么”的高层语义。
总结: 具身智能的耳朵,硬件是中国制造的天下,但灵魂(算法)正在等待 AI 大模型的重塑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)