普通人应该如何一步步搭建一个属于自己的 AI 量化交易系统
——从“凭感觉下单”,到“规则 + 数据 + 模型 + 风控”的完整实战路线
很多人一听到“AI 量化交易”,脑子里就自动浮现出几个词:自动赚钱、机器收割、24 小时不停印钞。但真正能跑起来的系统,从来不是一个神奇模型,而是一整条流水线:先有数据,再有规则,再有回测,再有风控,最后才轮到 AI 上场。
普通人最容易踩的坑,不是不会写代码,而是顺序错了:一上来就训练模型,一上来就想做高频,一上来就想满仓实盘。正确路线恰恰相反:先做最小闭环,再做 AI 增强;先做模拟盘,再碰真资金;先学会少亏,再谈怎么赚。
1. 先把认知摆正:AI 量化系统不是“自动暴富机”,而是“自动决策流水线”
量化交易,本质上就是把人的交易判断拆成可以重复执行的规则。比如:什么情况下进场,什么情况下减仓,亏多少必须停,赚到什么位置要不要锁利润。传统量化做的是“规则程序化”,AI 量化做的是“让模型参与判断”。
所以,真正的 AI 量化系统,一般至少包含六个部分:市场数据、数据清洗、特征工程、模型或策略、风险控制、下单执行。缺任何一块,这个系统都不完整。
一句话记住:模型负责“看机会”,风控负责“保命”,执行负责“别跑偏”。
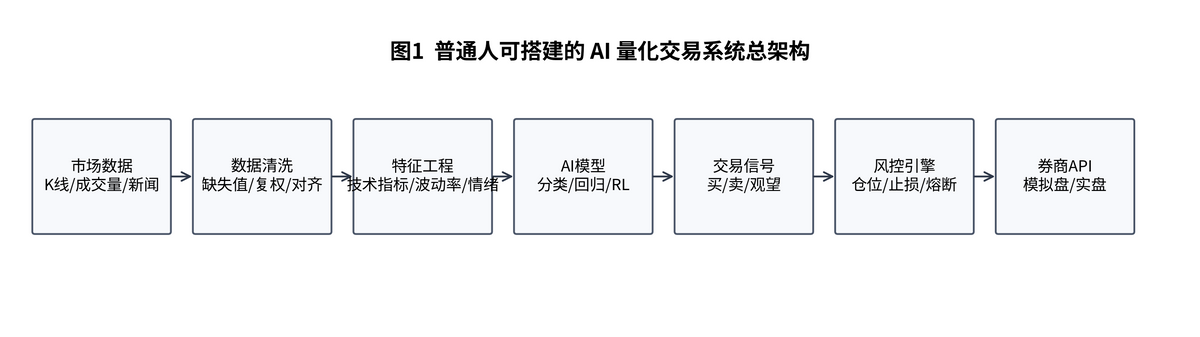
2. 第一步:别贪多,先选一个你能看懂、能拿到数据、能接 API 的市场
2.1 为什么第一套系统不要一上来就做全市场
普通人第一套系统,最怕的是复杂度失控。你同时做股票、期货、加密货币、外汇,看起来很厉害,实际上会把自己拖进数据格式、交易时段、手续费模型、滑点模型、风控规则完全不同的泥潭。
正确做法是:先选一个市场,再选一个简单频率,再选一个窄品种池。比如只做日线股票择时,或者只做少量高流动性加密货币。这样你才能尽快把闭环跑通。
2.2 选市场时,普通人最该看哪三件事
第一,看数据是否容易获取。第二,看有没有稳定的模拟盘或测试环境。第三,看交易接口是否成熟,文档是否清晰。只要这三件事过关,系统搭建难度就会大幅下降。
如果你连稳定数据都拿不到,或者根本没有模拟盘,那你不是在搭系统,而是在给自己埋雷。
3. 第二步:先把数据层搭起来,别急着训练模型
3.1 数据层到底要存什么
很多人以为数据层就是把 K 线下载下来。其实远远不够。一个最小可用的数据层,至少要有:时间、开高低收、成交量、复权处理方式、标的代码、交易日历,以及你后面要用的衍生特征。
如果还想让 AI 读新闻、财报、公告,那你还要把文本数据标准化,统一时间戳,和行情数据做对齐。否则模型看到的是“昨天的消息去预测前天的价格”,训练结果一定是假的。
3.2 普通人应该怎么搭自己的数据仓
最实用的办法,不是上来就建一个超级数据中台,而是先做“三层小仓库”:原始数据层、清洗数据层、特征数据层。原始层只负责留底;清洗层负责补缺失、去异常、统一格式;特征层只放模型真正要吃的数据。
你以后每次重训模型,只要能从原始层稳定重放到特征层,就说明这个系统是可复现的。可复现,比短期收益更重要。
4. 第三步:先写“规则策略”做回测,再把 AI 接进来
4.1 为什么不能一开始就直接上神经网络
因为你连最基础的交易逻辑都没证明能跑通,模型再复杂也只是在放大混乱。一个成熟系统的正确顺序应该是:先有基线策略,再让 AI 去增强它。
比如,你先做一个最简单的基线:趋势向上时允许开仓,趋势向下时禁止抄底;成交量异常放大时降低仓位;连续亏损几次后自动休息。等这个基线能稳定回测,你再让 AI 做信号打分、择时过滤、仓位微调,这样才是“模型为系统服务”,而不是“系统被模型绑架”。
4.2 回测时最容易出现的三个幻觉
第一,未来函数。你不小心让今天的策略看到了明天的数据。第二,忽略手续费和滑点。纸面盈利很好看,一上实盘马上变形。第三,参数试太多,只把最漂亮的一组留下来。表面上像“优化”,本质上往往是“挑中了一次幸运”。
回测不是为了证明你有多厉害,而是为了提前发现这套规则哪里会死。
5. 第四步:AI 到底该插在哪一层,才最适合普通人
5.1 最稳的做法:让 AI 先做“增强器”,不要做“独裁者”
AI 最适合做的,不是直接拍板“满仓买入”,而是做四种增强:第一,做信号过滤,把低质量信号拦掉;第二,做市场状态识别,判断当前是趋势市、震荡市还是极端波动市;第三,做多因子融合,把多个指标压成一个更稳定的综合评分;第四,做文本信息提炼,比如把新闻情绪和公告风险转成结构化特征。
换句话说,普通人最容易成功的路线,不是“让 AI 替你交易”,而是“让 AI 帮你少犯错”。
5.2 三种最适合新手上手的 AI 任务
第一种,分类任务:预测下一交易日更可能上涨、下跌还是震荡。第二种,回归任务:预测未来一段时间的收益强弱。第三种,排序任务:在一篮子标的里,排出相对更值得关注的前几名。
这三种任务的共同点是:目标清晰,训练逻辑相对直观,容易和基线策略结合。相比之下,一上来就做强化学习、自动做市、超高频撮合,对普通人来说跨度太大,失败概率很高。

6. 第五步:系统真正的灵魂不是模型精度,而是风控引擎
6.1 为什么很多“神策略”死在实盘第一周
因为回测看到的是“过去的数据世界”,实盘面对的是“现在的对手盘世界”。一旦市场突然切换风格,延迟变大,成交变差,流动性下滑,再好的信号也可能被执行层拖死。
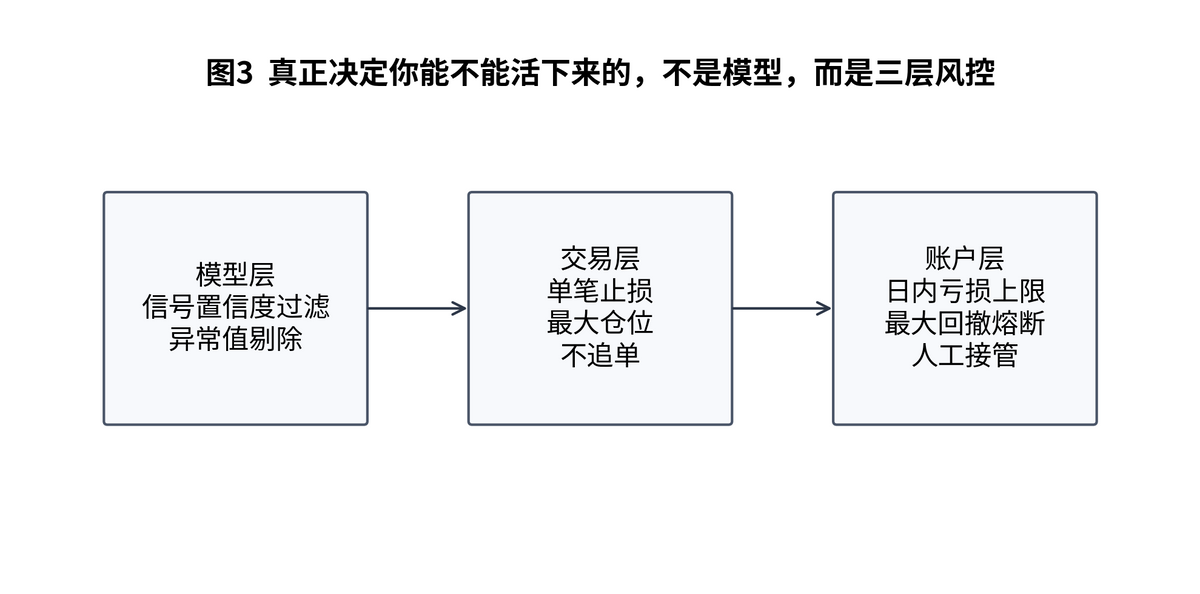
所以,成熟系统一定要做三层风控:模型层、交易层、账户层。模型层控制信号质量,交易层控制单笔风险,账户层控制整套系统的生死线。
6.2 三层风控具体怎么落
模型层可以设置置信度阈值、异常值拦截、数据质量检测;交易层可以设置单笔最大亏损、单标的最大仓位、连续亏损暂停;账户层可以设置日亏损上限、周回撤阈值、总资金熔断,以及人工接管开关。
请记住:真正让账户活得久的,从来不是“预测有多准”,而是“错的时候亏得有多慢”。
7. 第六步:从回测到模拟盘,再到小资金实盘,中间至少隔着三道门
7.1 第一门:历史回测
历史回测解决的是“过去是否讲得通”。这里你要重点看:收益是否稳定、最大回撤是否能接受、换手是否过高、不同年份和不同市场状态下是否都能活。
7.2 第二门:走样测试和滚动验证
真正靠谱的系统,不能只在一个时间段里好看。你要把数据切成训练期、验证期、测试期,按时间滚动往前推。只有不断在未知区间里还能维持稳定,系统才有资格进入下一阶段。
7.3 第三门:模拟盘
模拟盘解决的是“系统上线后会不会跑歪”。这时你要盯的不是模型准确率,而是订单是否正常发出、成交回报是否正确、日志是否完整、断线重连是否可靠、风控闸门是否真的会生效。
很多人回测能赚钱,模拟盘就露馅:一下单就报错,价格一跳就追不上,仓位一算就超限。说明问题根本不在模型,而在工程。
8. 第七步:普通人的最小可行技术栈,应该怎么选
8.1 最小可行版本,不求豪华,但求闭环
如果你现在从零开始,最小可行栈完全可以很朴素:Python 负责策略与训练,pandas/numpy 处理数据,Backtrader 之类的回测框架做回测,scikit-learn 或 XGBoost 做基础模型,数据库用 SQLite 或 PostgreSQL 先跑起来,日志和监控先用最简单的文件日志加告警。
等你把最小闭环打通之后,再考虑把数据平台、特征平台、模型注册、分布式训练这些“高级基础设施”一点点补齐。别一开始就追求机构级架构,普通人最大的优势是轻、快、能迭代。
8.2 什么时候该用 Qlib,什么时候该看 FinRL
如果你更想走“数据处理—特征工程—模型训练—回测分析”的经典机器学习路线,Qlib 这类面向 AI 量化研究的平台会更顺手。它更像一个研究流水线。
如果你想研究“让智能体在环境里自己学动作”的路线,再去看 FinRL 这类金融强化学习框架更合适。但请注意,对普通人来说,强化学习不该是起点,更适合作为你把基线系统做稳之后的进阶实验。
9. 一套普通人真能落地的 90 天路线图
9.1 第 1—2 周:只做市场与数据
选一个市场,确定标的池,下载历史行情,整理交易日历,把原始数据、清洗数据、特征数据分开存。这个阶段不碰模型。
9.2 第 3—4 周:做基线策略与回测
先写一个简单但可解释的规则策略,加入手续费、滑点、仓位上限、止损规则,把回测框架跑通。这个阶段的目标不是暴利,而是能稳定重跑。
9.3 第 5—8 周:接入 AI 做增强
把 AI 的任务限定为一个非常具体的小问题,比如“过滤低质量买点”或“给信号打分”。只改一个环节,你才知道收益提升到底来自哪里。
9.4 第 9—10 周:做滚动验证与压力测试
把模型丢到不同年份、不同波动环境里试,看看在极端行情下会不会连续犯错。必要时降低复杂度,而不是盲目加层数。
9.5 第 11—12 周:模拟盘 + 小资金试运行
先跑模拟盘,再做超小资金试单。这个阶段最重要的不是赚多少,而是日志是否完整、异常是否能报警、熔断是否真能触发、人工接管是否顺畅。
10. 普通人最容易踩的 10 个坑
1. 以为 AI 量化的核心是预测涨跌,其实核心往往是风险收益比。
2. 一上来就做分钟级甚至高频,结果被数据质量和延迟打爆。
3. 回测只看收益,不看最大回撤和换手。
4. 忽略手续费、滑点、停牌、涨跌停、成交不足。
5. 试了太多参数,只保留最好看的一组。
6. 把文本新闻随便丢给大模型,却没有做时间对齐和去噪。
7. 没有模拟盘阶段,直接上真资金。
8. 没有账户级熔断,亏损扩大后还让系统继续跑。
9. 看到模型准确率高,就误以为交易一定能赚钱。
10. 把量化系统当成一次性项目,而不是持续迭代的工程产品。
11. 结尾:普通人想搭 AI 量化系统,最正确的姿势不是“追神话”,而是“搭闭环”
你真正要做的,不是找到一个能预测市场的万能模型,而是搭出一套小而完整、能反复验证、能稳定执行、出错时能刹车的系统。
普通人搭 AI 量化,最值钱的能力不是数学有多深,也不是 GPU 有多强,而是你能不能把“市场—数据—策略—模型—风控—执行—复盘”这一整条链路串起来。
先做一套会走的系统,再做一套会跑的系统;先做一套不容易死的系统,再谈它能不能赚大钱。这个顺序一旦对了,你就已经超过大多数只会喊口号的人了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)