多元回归分析
一. 多元线性回归模型
-
(1) 模型的数学形式
多元回归模型用于分析多个自变量与因变量之间的关系。模型的基本数学形式为:
其中:是因变量,
是自变量,
是回归系数,
是随机误差项,满足
和
。
-
(2) 局限性
- 1. 因变量的正态假设不能满足实际应用要求。事实上,因变量可能是计数型变量、分类变量、或者是分布不对称的左偏或右偏变量等;
- 2. 因变量的方差常常随均值变化而变化,而非假设的常数,例如,对于指数分布,其方差是均值的平方;
- 3. 自变量之间可能通过乘法关系对因变量产生影响;因变量与自变量之间的关系可能是非线性关系,等等。
二. 广义线性模型
-
(1) 特点
- 扩展了多元回归模型,因变量不再局限于正态分布,而被扩展到指数族分布(包括二项分布、泊松分布、伽马分布等)。
- 通过链接函数将线性预测器与响应变量的期望值连接,提供更灵活的建模框架。
- 不要求方差为常数,方差可以是均值的函数;
- 参数的估计与因变量分布的具体形式无关,只需因变量的一、二阶矩即可。
- 适用于分类、计数和连续数据,广泛用于生物统计、社会科学等领域。
-
(2) 基本原理
-
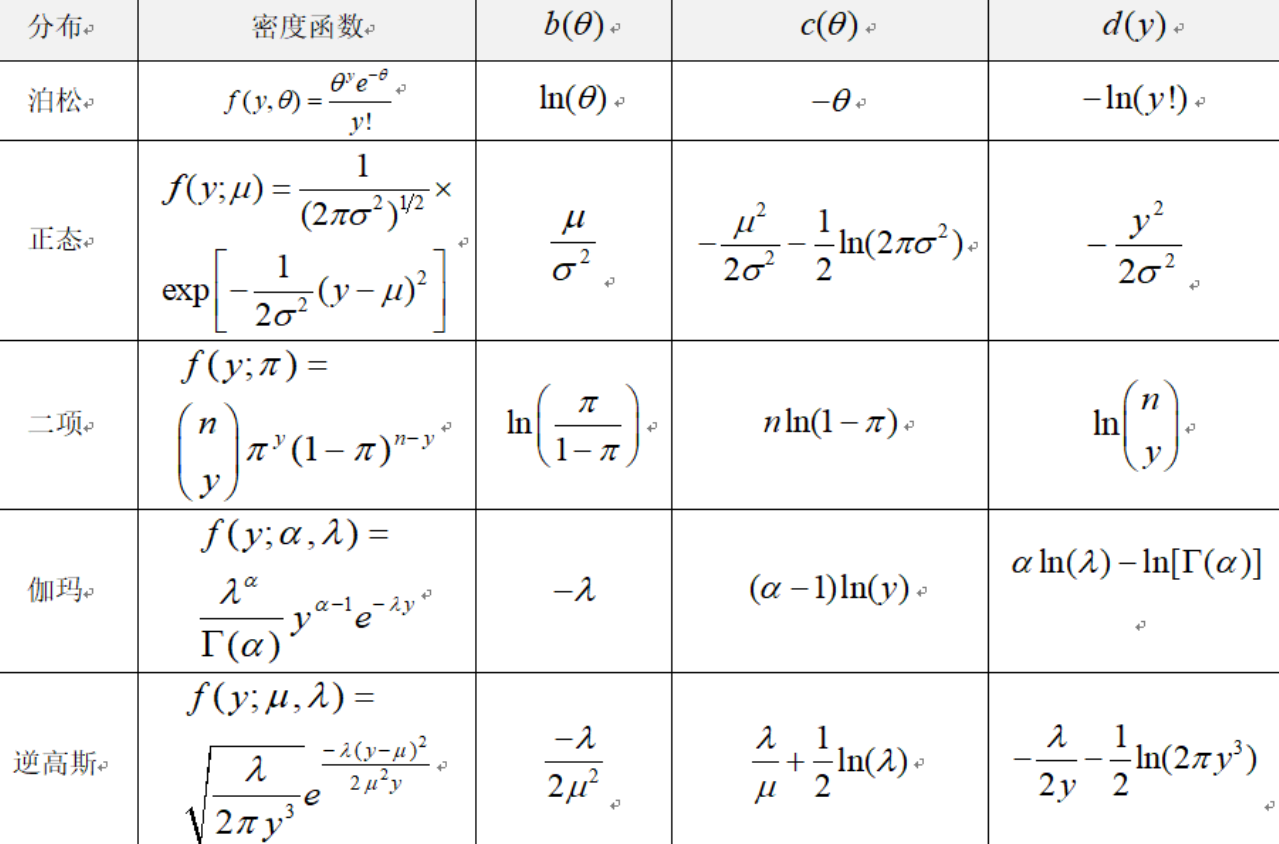
指数族分布
广义线性模型基于指数族分布,其概率密度函数为:例如,泊松分布的密度函数
上式可以改写为
其中
-
常见的指数型分布
-
-
定义
模型定义为:因变量的分布扩展到了指数族分布;因变量的拟合值是自变量线性组合的某一函数,即存在一个单调的连接函数g ,使得
其中:- E(y) 是响应变量的期望,
是链接函数(如Logit函数或Log函数),
是线性预测器。
通过连接函数使E(y)和x呈线性关系,从而可以用线性拟合的方法求解非线性模型
-
参数估计
使用最大似然估计法求解系数。似然函数为:
通过迭代加权最小二乘法求解估计方程: -
参数检验:多元回归方程建立之后需要进一步对回归估计系数进行显著性检验,判断回归方程的适用性和拟合效果。
- 系数的经济意义检验: 即检验回归估计系数的取值是否在一个合理的范围之
内,然后检验估计系数的符号是否正确,有没有违背实际经济意义的情况出现。 - 统计学检验: 通常包含三种检性即回归方程的拟合程度检验,回归方程的整
体显著性检验和回归估计系数的显著性检验。 常用的检验方法有:对数似然函数最大准则、残差平方和最小准则或基于残差的其它复合统计量,例如AIC, BIC等。
- 系数的经济意义检验: 即检验回归估计系数的取值是否在一个合理的范围之
-
三. 实现方法
-
(1) 步骤
实现广义线性模型的流程图可描述为以下步骤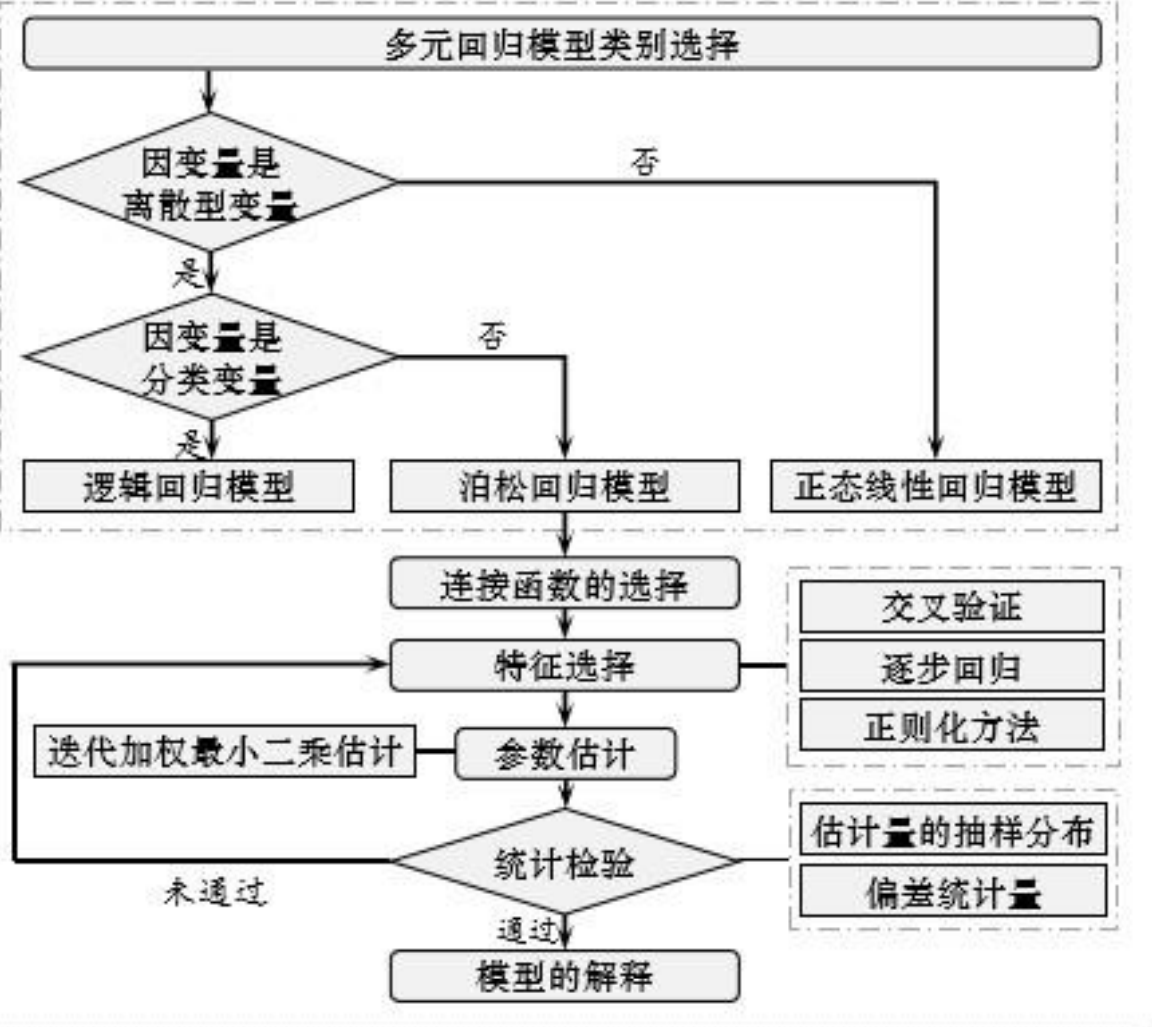
-
(2) Python软件实现 举个例子:25名糖尿病人的空腹血糖(y)、血清总胆固醇(x1)、甘油三酯(x2)、空腹胰岛素( x3)、糖化血红蛋白(x4):建立空腹血糖(y)与其它4个变量之间的多元线性回归模型,并求出经验回归方程
-
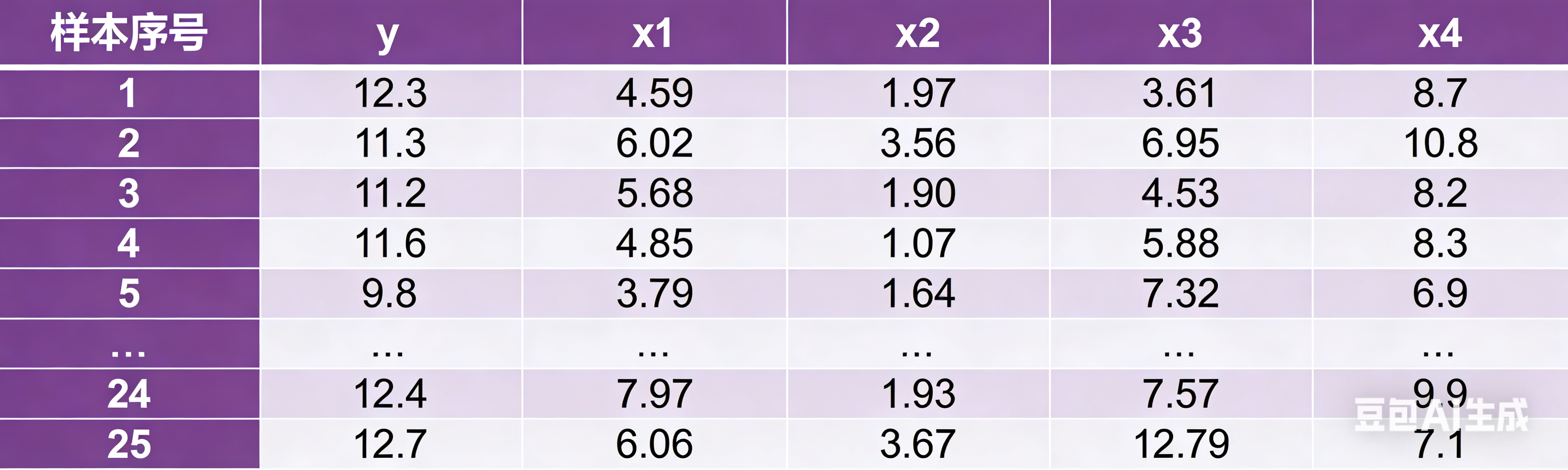
-
# Python代码2-1(GLM 线性回归模型) import numpy as np import pandas as pd import statsmodels.api as sm import statsmodels.stats.api as sms import matplotlib.pyplot as plt from statsmodels import graphics y=np.array([12.3,11.3,11.2,11.6,9.8,11.1,14.3,9.6,12.1,11.1,10.6,11.4,11.6,13.0,12.9,11.3,11.9,12.8,12.2,9.6,12.8,10.4,13.2,12.4,12.7]) x1=np.array([4.59,6.02,5.68,4.85,3.79,4.90,6.05,3.85,7.08,5.71,4.29,4.65,6.19,6.50,5.43, 5.84,6.13,6.40,6.13,5.78,5.09,3.84,7.98,7.97,6.06]) x2=np.array([1.97,3.56,1.90,1.07,1.64,8.50,0.64,2.11,3.00,1.78,1.97,0.63,1.18,6.21,1.13,0.92,2.06,2.40,1.71,3.36,1.03,1.20,7.92,1.93,3.67]) x3=np.array([3.61,6.95,4.53,5.88,7.32,12.60,1.42,16.28,6.75,8.53,6.61,6.59,1.42,3.47,4.31,8.61,10.35,4.53,5.28,2.96,2.53,6.45,3.37,7.57,12.79]) x4=np.array([8.7,10.8,8.2,8.3,6.9,8.5,13.6,7.9,11.5,8.0,7.8,7.1,6.9,12.3,11.3,6.4,10.5, 10.3,9.9,8.0,8.9,9.6,9.8,9.9,7.1]) x0=np.ones(len(x1)) x=np.stack((x0,x1,x2,x3,x4),axis=1) glm_Gaussian = sm.GLM(y,x, family=sm.families.Gaussian()) res_Gaussian = glm_Gaussian.fit() print(res_Gaussian.summary()) print('AIC=',res_Gaussian.aic)结果报表:
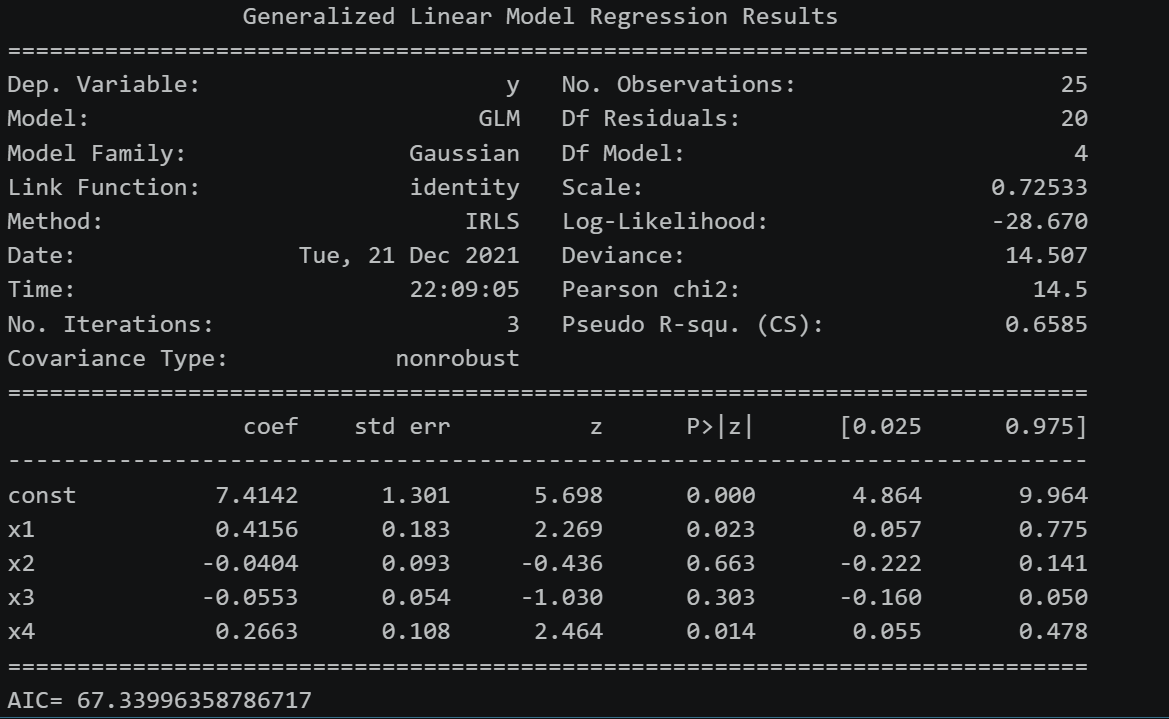 主要关注的几个指标
主要关注的几个指标 - AIC越小越好
- coef:系数项
- 显著性经验P值大于0.025说明显著性水平不通过(因变量与自变量之间不存在显著的线性关系)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.linear_model import LassoLarsIC #LASSO交叉验证模型
y=np.array([12.3,11.3,11.2,11.6,9.8,11.1,14.3,9.6,12.1,11.1,10.6,11.4,11.6,13.0,12.9,11.3,11.9,12.8,12.2,9.6,12.8,10.4,13.2,12.4,12.7])
x1=np.array([4.59,6.02,5.68,4.85,3.79,4.90,6.05,3.85,7.08,5.71,4.29,4.65,6.19,6.50,5.43, 5.84,6.13,6.40,6.13,5.78,5.09,3.84,7.98,7.97,6.06])
x2=np.array([1.97,3.56,1.90,1.07,1.64,8.50,0.64,2.11,3.00,1.78,1.97,0.63,1.18,6.21,1.13,0.92,2.06,2.40,1.71,3.36,1.03,1.20,7.92,1.93,3.67])
x3=np.array([3.61,6.95,4.53,5.88,7.32,12.60,1.42,16.28,6.75,8.53,6.61,6.59,1.42,3.47,4.31,8.61,10.35,4.53,5.28,2.96,2.53,6.45,3.37,7.57,12.79])
x4=np.array([8.7,10.8,8.2,8.3,6.9,8.5,13.6,7.9,11.5,8.0,7.8,7.1,6.9,12.3,11.3,6.4,10.5,
10.3,9.9,8.0,8.9,9.6,9.8,9.9,7.1])
x0=np.ones(len(x1))
x=np.stack((x0,x1,x2,x3,x4),axis=1)
#建立因变量和四个解释变量的正态线性回归模型
reg0=reg = linear_model.LinearRegression().fit(x, y) #调用线性回归模型
print('reg0.intercept_=',reg0.intercept_,'\nreg0.coef=', reg0.coef_) #输出截距及回归系数
print('reg0_predict=',reg0.predict(x))
print('reg0.score=',reg0.score(x,y)) #返回预测性能得分,不超过1,可能为负,越大越好
#求最优惩罚系数及相应模型的回归系数
model_aic = LassoLarsIC(criterion='aic').fit(x, y)
alpha_aic_ = model_aic.alpha_
print('最优惩罚系数为:',alpha_aic_)
reg3 = linear_model.Lasso(alpha =alpha_aic_).fit(x, y) #调用LASSO回归模型
print('reg3.intercept_=',reg3.intercept_,'\nreg3.coef_=',reg3.coef_)
print('alpha_aic_=',model_aic.criterion_) #输出AIC
print('reg3.score=',reg3.score(x,y))
#图示最优惩罚系数的确定
EPSILON=1e-4
def plot_ic_criterion(model, name, color):
criterion_ = model.criterion_
plt.semilogx(model.alphas_ + EPSILON, criterion_, '--', color=color,linewidth=1, label='%s criterion' % name)
plt.axvline(model.alpha_+ EPSILON, color=color, linewidth=1,label='alpha: %s estimate' % name)
plt.xlabel(r'$\alpha$')
plt.ylabel('criterion')
plt.figure()
plot_ic_criterion(model_aic, 'AIC', 'b')
plt.legend()
plt.title('Information-criterion for model selection')
plt.show()
结果
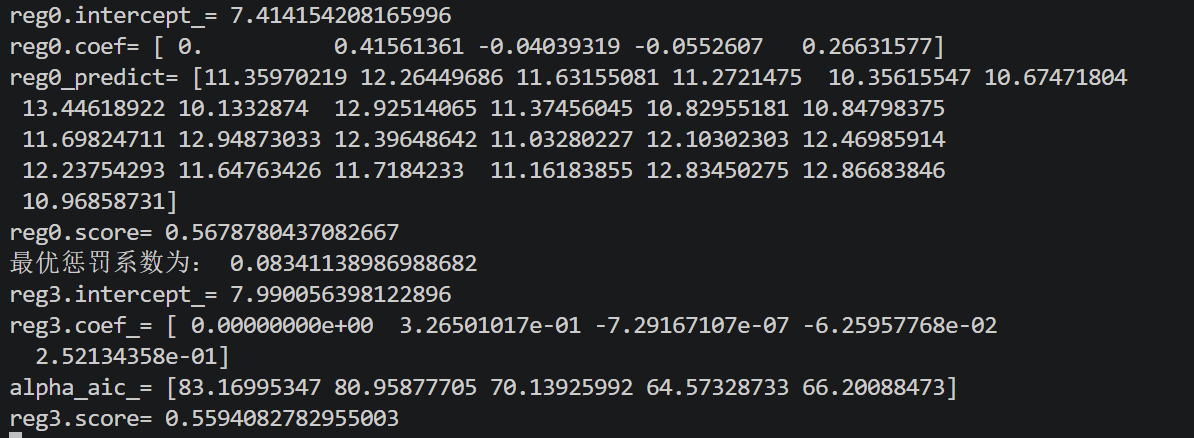
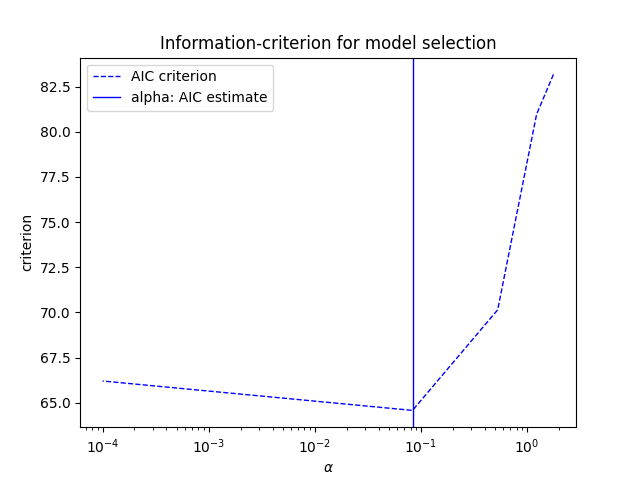
岭回归模型:带 L2 正则的线性回归,主要用来解决普通最小二乘(OLS)在多重共线性、特征多样本少、过拟合时不稳定、泛化差的问题。
python实现:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
y=np.array([12.3,11.3,11.2,11.6,9.8,11.1,14.3,9.6,12.1,11.1,10.6,11.4,11.6,13.0,12.9,11.3,11.9,12.8,12.2,9.6,12.8,10.4,13.2,12.4,12.7])
x1=np.array([4.59,6.02,5.68,4.85,3.79,4.90,6.05,3.85,7.08,5.71,4.29,4.65,6.19,6.50,5.43, 5.84,6.13,6.40,6.13,5.78,5.09,3.84,7.98,7.97,6.06])
x2=np.array([1.97,3.56,1.90,1.07,1.64,8.50,0.64,2.11,3.00,1.78,1.97,0.63,1.18,6.21,1.13,0.92,2.06,2.40,1.71,3.36,1.03,1.20,7.92,1.93,3.67])
x3=np.array([3.61,6.95,4.53,5.88,7.32,12.60,1.42,16.28,6.75,8.53,6.61,6.59,1.42,3.47,4.31,8.61,10.35,4.53,5.28,2.96,2.53,6.45,3.37,7.57,12.79])
x4=np.array([8.7,10.8,8.2,8.3,6.9,8.5,13.6,7.9,11.5,8.0,7.8,7.1,6.9,12.3,11.3,6.4,10.5,
10.3,9.9,8.0,8.9,9.6,9.8,9.9,7.1])
x0=np.ones(len(x1))
x=np.stack((x0,x1,x2,x3,x4),axis=1)
#交叉验证法求最优惩罚系数
n_alphas = 2000
reg = linear_model.RidgeCV(alphas=np.logspace(-5, 20, n_alphas)).fit(x,y) #np.logspace对数等比数列,从10^(-5),到10^20,共2000个数据
print('reg.alpha_=',reg.alpha_) #输出最优惩罚系数
reg4 = linear_model.Ridge(alpha=reg.alpha_).fit(x,y) #拟合模型
print('reg4.intercept_=',reg4.intercept_,'\nreg4.coef_=',reg4.coef_ ) #输出截距及回归系数
print('reg4.score=',reg4.score(x,y))
#绘制岭迹图
alphas = np.logspace(-3,6, n_alphas )
coefs0 = []
for a in alphas:
ridge = linear_model.Ridge(alpha=a, fit_intercept=False)
ridge.fit(x, y)
coefs0.append(ridge.coef_)
coefs=np.array(coefs0)
ax = plt.gca()
ax.plot(alphas, coefs[:,1],color='red' )
ax.plot(alphas, coefs[:,2],color='green' )
ax.plot(alphas, coefs[:,3],color='black' )
ax.plot(alphas, coefs[:,4],color='blue' )
ax.set_xscale('log')
plt.ylabel('weights')
plt.title('Ridge coefficients as a function of the regularization')
plt.axis('tight')
plt.show()岭迹图结果:
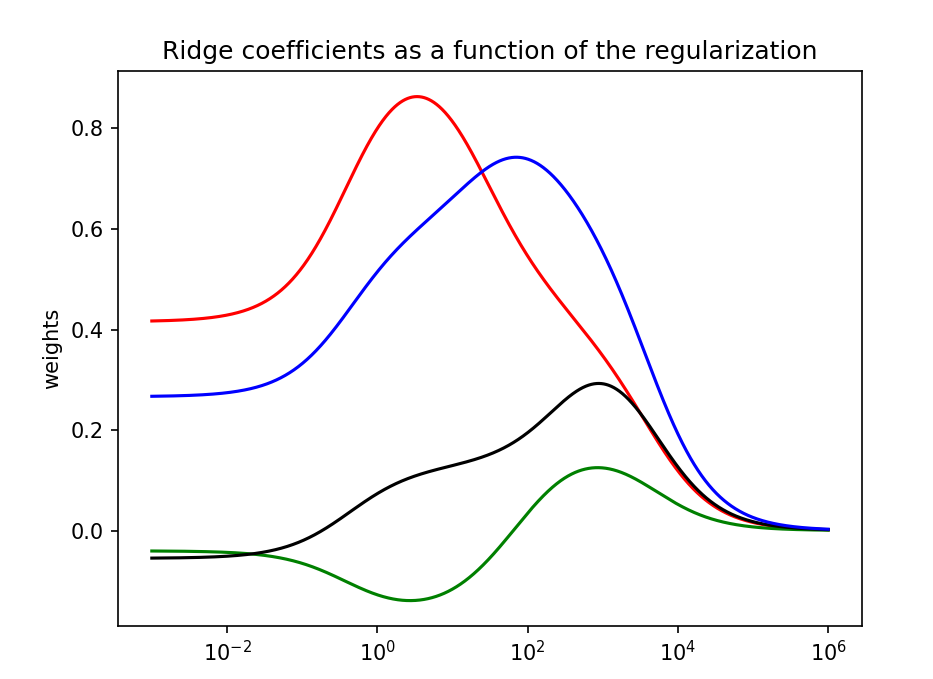
岭回归选择变量的原则:
(1)随着k的增加,回归系数不稳定,震动趋于零的自变量可以剔除。(这里绿线波动趋近于0)
(2)究竟去掉几个,去掉哪几个,这并无一般原则可循,这需根据去掉某个变量后重新进行
岭回归分析的效果来确定。
根据图中结果可以剔除变量X2,然后再重新进行岭回归

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)