山东大学软件学院创新实训(五)
前言
上周我们完成了基础的错因分析和简单推题功能,但系统仍存在三个核心问题:缺乏个性化(用户看到相同推荐)、重复推送(无法避免已做过题目)、多样性不足(连续推送相似题目)。本周我重点攻克了这三个难题,实现了完整的"用户画像 + 向量检索"双层架构,通过 MySQL 统计薄弱标签、FAISS 语义检索、去重排序算法的协同工作,做到了个性化精准推题。同时建立了题库扩充pipeline和多样性控制机制,让系统更加实用。
一、双层架构设计:为什么需要 MySQL + FAISS 协同?
1.1 单一检索方案的局限性
在实现双层架构之前,我们思考过两种方案:
方案一:纯 MySQL 查询
SELECT * FROM topic
WHERE tags LIKE '%导数%'
ORDER BY create_time DESC
LIMIT 5;问题:
只能基于关键词匹配,无法理解语义(搜索"导数"找不到"微分"相关题目),无法量化题目相似度,排序粗糙,标签依赖人工标注,覆盖不全等。
方案二:纯 FAISS 向量检索
results = faiss_store.similarity_search("导数的计算", k=5)问题:
所有用户搜索结果相同,缺乏个性化,无法过滤用户已做过的题目,无法获取完整的题目元数据(标签、创建时间、用户关联等)。
1.2 双层架构的核心思想
于是,我们兼取其长,最终采用了"用户画像 + 向量检索"的双层架构,能够充分发挥两种存储的优势:
- 个性化:基于用户历史错题统计薄弱标签,千人千面.
- 语义理解:FAISS 向量检索能理解"导数"与"微分"的语义关联.
- 去重能力:MySQL 推送历史记录,避免重复.
- 完整性:最终从 MySQL 获取完整题目信息,包含标签、解析等.
- 性能优化:FAISS 快速筛选候选集,减少 MySQL 查询压力.
┌─────────────────────────────────────────────────────────┐
│ 第一层:MySQL(用户画像层) │
│ • 统计用户薄弱知识点标签 │
│ • 记录历史推送/做题记录 │
│ • 存储题目完整元数据 │
└─────────────────────────────────────────────────────────┘
↓ 输出:薄弱标签列表
┌─────────────────────────────────────────────────────────┐
│ 第二层:FAISS(语义检索层) │
│ • 基于薄弱标签进行向量相似度搜索 │
│ • 快速从题库中筛选候选集 │
│ • 返回带 topic_id 的简化结果 │
└─────────────────────────────────────────────────────────┘
↓ 输出:候选题目 ID 列表
┌─────────────────────────────────────────────────────────┐
│ 第三层:MySQL(过滤与补全层) │
│ • 排除最近 N 天已推送的题目 │
│ • 反查完整题目信息(题干、答案、解析、标签) │
└─────────────────────────────────────────────────────────┘
↓ 输出:过滤后的完整题目列表
┌─────────────────────────────────────────────────────────┐
│ 第四层:算法层(多样性排序) │
│ • 优先选择不同标签的题目 │
│ • 避免同一知识点下推送过于相似的题目 │
│ • 截取 Top K 作为最终推荐 │
└─────────────────────────────────────────────────────────┘
↓ 输出:个性化推荐结果二、用户画像构建以及FAISS 向量检索
2.1 薄弱标签统计算法
实现了基于用户历史错题的薄弱标签统计:
def get_user_weak_tags(self, user_id: int, top_n: int = 3) -> List[str]:
"""
获取用户最薄弱的知识点标签(从新画像表查询)
逻辑:按 mastery_score 升序、error_count 降序排列,取前 N 个
"""
try:
sql = """
SELECT tag_name FROM user_knowledge_profile
WHERE user_id = %s
ORDER BY mastery_score ASC, error_count DESC
LIMIT %s
"""
results = self.execute_query(sql, (user_id, top_n))
return [row['tag_name'] for row in results]
except Exception as e:
logger.warning(f"获取用户薄弱标签失败: {str(e)}")
return []排序逻辑:
mastery_score ASC:掌握度分数越低,说明越薄弱,优先推荐
error_count DESC:错误次数越多,说明该知识点反复出错,需要加强练习
示例: 假设用户 ID=1 的画像数据如下:
| tag_name | mastery_score | error_count |
|----------|---------------|-------------|
| 导数 | 45.50 | 8 |
| 积分 | 62.30 | 5 |
| 极限 | 78.90 | 2 |
| 矩阵 | 85.20 | 1 |
调用 get_user_weak_tags(1, top_n=3) 返回:['导数', '积分', '极限']
2.2 基于薄弱标签的语义检索
在 core/recommend_engine.py 中,针对每个薄弱标签进行向量检索:
def get_daily_push(self, user_id: int, limit: int = 5):
"""
获取每日个性化推荐
流程:查画像(MySQL) -> 搜向量(FAISS) -> 过滤去重(MySQL) -> 多样性排序 -> 存历史
"""
logger.info(f" 开始为用户 {user_id} 生成推荐...")
# 第一步:查画像 - 获取用户最薄弱的 3 个标签
weak_tags = self.mysql_client.get_user_weak_tags(user_id, top_n=3)
if not weak_tags:
weak_tags = ['数学一'] # 兜底标签
logger.info(f" 发现薄弱标签: {weak_tags}")
all_candidates = []
# 第二步:搜向量 - 针对每个薄弱标签进行 FAISS 检索
for tag in weak_tags:
# 搜索与该标签语义相似的题目,召回 10 道
results = self.vector_store.similarity_search(tag, k=10)
for res in results:
meta = res.get('metadata', {})
if meta.get('topic_id'):
all_candidates.append({
'id': meta['topic_id'],
'score': res.get('distance', 0), # L2 距离,越小越相似
'tags': meta.get('tags', '').split(',')
})
logger.info(f" FAISS 召回候选题目: {len(all_candidates)} 道")
# 后续步骤:过滤、排序、推送...关键参数:
k=10:每个标签召回 10 道题,3 个标签共 30 道候选.
distance:L2 距离(欧氏距离),值越小表示语义越相似.
topic_id:FAISS 元数据中的 MySQL 题目 ID,用于后续反查.
2.3 向量嵌入模型的选择
项目使用 BAAI/bge-base-zh 作为嵌入模型:
# vector_store/faiss_store.py
self.embedding_model = SentenceTransformer(
"BAAI/bge-base-zh",
cache_folder="./cache/huggingface"
)
# 生成向量
embeddings = self.embedding_model.encode(texts, convert_to_numpy=True)
embeddings = np.array(embeddings).astype('float32')
# FAISS 索引类型:IndexFlatL2(精确搜索,L2 距离)
self.index = faiss.IndexFlatL2(self.dimension) # dimension=768为什么选择 bge-base-zh?
中文优化:专门针对中文文本训练,比通用模型(如 text-embedding-ada-002)在中文场景下表现更好.
维度适中:768 维,平衡了精度和存储成本.
开源免费:无需调用外部 API,本地部署,数据隐私安全.
语义理解强:能理解"导数"与"微分"、"积分"与"面积"的语义关联.
对比实验(内部测试):
查询:"导数的计算方法"
bge-base-zh 召回结果:
1. "求函数 f(x)=x² 的导数"(距离 0.23)✅
2. "微分的定义与计算"(距离 0.31)✅
3. "偏导数的几何意义"(距离 0.45)✅
text-embedding-ada-002 召回结果:
1. "导数的计算方法"(距离 0.15)✅
2. "如何计算导数"(距离 0.18)✅
3. "导数公式大全"(距离 0.22)❌ (只是标题相似,内容不相关)结论:bge-base-zh 更能理解题目的内容语义,而非仅仅匹配关键词。
2.4 两级检索策略的实现
在 faiss_store.py 的 search_similar 方法中,实现了从 FAISS 到 MySQL 的两级检索:
def search_similar(self, query_text: str, k: int = 3) -> List[Dict]:
"""
根据题干文本搜索同类题
第一级:FAISS 向量检索 → 获取 topic_id
第二级:MySQL 反查 → 获取完整题目信息
"""
# 第一级:FAISS 向量相似度搜索
docs = self.similarity_search(query_text, k=k)
# 收集所有 topic_id
topic_ids = []
for doc in docs:
topic_id = doc['metadata'].get("topic_id")
if topic_id:
topic_ids.append(topic_id)
# 第二级:从 MySQL 获取完整信息
if topic_ids:
from database.mysql_client import mysql_client
try:
placeholders = ','.join(['%s'] * len(topic_ids))
sql = f"""
SELECT id, stem as questionStem, correct_answer as answer,
analysis, tags, subject, create_time as createTime
FROM question_bank
WHERE id IN ({placeholders})
"""
topics = mysql_client.execute_query(sql, tuple(topic_ids))
# 转换为前端需要的格式
result = []
for topic in topics:
result.append({
"id": topic['id'],
"title": topic.get('subject', '未知科目'),
"questionStem": topic['questionStem'],
"questionStemPictureUrls": [],
"answer": topic.get('answer', ''),
"answerPictureUrls": [],
"createTime": str(topic.get('createTime', '')),
"updateTime": None,
"labels": topic.get('tags', '').split(',') if topic.get('tags') else []
})
return result
except Exception as e:
logger.error(f"从MySQL获取题目详情失败: {str(e)}")三、去重与多样性控制:避免重复推送和同质化
3.1 基于推送历史的去重
通过查询 MySQL 的 推送历史表排除近期已推送的题目:
def get_daily_push(self, user_id: int, limit: int = 5):
# ... 前面步骤:查画像、搜向量 ...
# 第三步:过滤去重 - 排除最近 7 天推过的题
recent_ids = self.mysql_client.get_recent_push_ids(user_id, days=7)
filtered_candidates = [c for c in all_candidates if c['id'] not in recent_ids]
logger.info(f" 过滤后剩余候选题目: {len(filtered_candidates)} 道(排除了 {len(all_candidates) - len(filtered_candidates)} 道近期推送)")
# 第四步:多样性排序
final_list = self._rerank_for_diversity(filtered_candidates, limit)
# 第五步:记历史 - 写入 push_history
if final_list:
q_ids = [item['id'] for item in final_list]
self.mysql_client.save_push_records(user_id, q_ids, push_type='daily')
logger.info(f"✅ 推荐完成,已推送题目 ID: {q_ids}")
return final_list去重逻辑:查询最近 7 天内推送过的题目 ID、从候选集中排除这些 ID、推送成功后,立即写入 push_history 表。
MySQL 查询实现:
def get_recent_push_ids(self, user_id: int, days: int = 7) -> List[int]:
"""获取用户最近 N 天内已推送过的题目 ID"""
try:
sql = """
SELECT question_id FROM push_history
WHERE user_id = %s AND create_time >= DATE_SUB(NOW(), INTERVAL %s DAY)
"""
results = self.execute_query(sql, (user_id, days))
return [row['question_id'] for row in results]
except Exception as e:
logger.warning(f"获取推送历史失败: {str(e)}")
return []
def save_push_records(self, user_id: int, question_ids: List[int], push_type: str = 'daily'):
"""批量保存推送记录"""
if not question_ids:
return
try:
conn = self.get_connection()
cursor = conn.cursor()
sql = "INSERT INTO push_history (user_id, question_id, push_type) VALUES (%s, %s, %s)"
values = [(user_id, qid, push_type) for qid in question_ids]
cursor.executemany(sql, values)
conn.commit()
except Exception as e:
logger.error(f"保存推送记录失败: {str(e)}")
if 'conn' in locals():
conn.rollback()
finally:
if 'cursor' in locals():
cursor.close()
去重效果示例:
FAISS 召回 30 道候选题目
↓
查询 push_history:最近 7 天已推送 8 道题
↓
过滤后剩余 22 道候选题目
↓
多样性排序后推送 5 道
↓
写入 push_history,下次不会再推这 5 道3.2 多样性排序算法
为避免同一知识点下推送过于相似的题目,实现了基于标签覆盖度的多样性排序:
def _rerank_for_diversity(self, candidates, limit):
"""
简单多样性控制:优先保证不同标签的题目都有
算法思路:
1. 第一轮:优先选择包含"新标签"的题目(之前未选过的标签)
2. 第二轮:如果还不够,补充剩余题目
"""
if not candidates:
return []
result = []
seen_tags = set() # 已选题目覆盖的标签集合
# 第一轮:优先选那些包含"新标签"的题
for item in candidates:
item_tags = set(item.get('tags', []))
# 如果这道题包含至少一个还没选过的标签,就优先选它
if item_tags - seen_tags:
result.append(item)
seen_tags.update(item_tags)
if len(result) >= limit:
break
# 如果还不够,再补充剩下的(按相似度排序)
if len(result) < limit:
for item in candidates:
if item not in result:
result.append(item)
if len(result) >= limit:
break
return result[:limit]
算法演示: 假设有 10 道候选题目,标签分布如下:
题目1: ['导数', '极限'] 题目6: ['导数', '微分']
题目2: ['积分', '面积'] 题目7: ['矩阵', '行列式']
题目3: ['导数', '微分'] 题目8: ['概率', '统计']
题目4: ['极限', '连续'] 题目9: ['导数', '应用']
题目5: ['积分', '定积分'] 题目10: ['级数', '收敛']目标:推送 5 道题
执行过程:
初始状态:result=[], seen_tags={}
遍历题目1: ['导数', '极限']
- 新标签:{'导数', '极限'} - {} = {'导数', '极限'} ✅
- 选中!result=[题目1], seen_tags={'导数', '极限'}
遍历题目2: ['积分', '面积']
- 新标签:{'积分', '面积'} - {'导数', '极限'} = {'积分', '面积'} ✅
- 选中!result=[题目1, 题目2], seen_tags={'导数', '极限', '积分', '面积'}
遍历题目3: ['导数', '微分']
- 新标签:{'导数', '微分'} - {'导数', '极限', '积分', '面积'} = {'微分'} ✅
- 选中!result=[题目1, 题目2, 题目3], seen_tags={..., '微分'}
遍历题目4: ['极限', '连续']
- 新标签:{'极限', '连续'} - {...} = {'连续'} ✅
- 选中!result=[题目1, 题目2, 题目3, 题目4], seen_tags={..., '连续'}
遍历题目5: ['积分', '定积分']
- 新标签:{'积分', '定积分'} - {...} = {'定积分'} ✅
- 选中!result=[题目1, 题目2, 题目3, 题目4, 题目5]
- 达到 limit=5,停止最终结果:5 道题覆盖了 8 个不同标签(导数、极限、积分、面积、微分、连续、定积分)
对比效果验证示例:
用户薄弱标签:['导数', '积分', '极限']不使用多样性排序:
1. "求 f(x)=x² 的导数"(导数)
2. "导数的定义与性质"(导数)
3. "高阶导数的计算"(导数)
4. "隐函数求导"(导数)
5. "参数方程求导"(导数)
❌ 全部是导数,用户会觉得重复使用多样性排序:
1. "求 f(x)=x² 的导数"(导数、极限)
2. "定积分的计算方法"(积分、面积)
3. "微分的定义与应用"(导数、微分)
4. "函数的连续性判定"(极限、连续)
5. "不定积分的换元法"(积分、定积分)
✅ 覆盖了导数、积分、极限、微分、连续等多个知识点3.3 推送记录的持久化
每次推送完成后,立即写入 push_history 表:
# 第五步:记历史 - 写入 push_history
if final_list:
q_ids = [item['id'] for item in final_list]
self.mysql_client.save_push_records(user_id, q_ids, push_type='daily')
logger.info(f"✅ 推荐完成,已推送题目 ID: {q_ids}")推送历史的作用:
去重:避免短期内重复推送相同题目
数据分析:统计推送频率、用户点击率、完成率
A/B 测试:对比不同推荐算法的效果
用户反馈:记录用户对每道题的评分、收藏、举报等行为
四、题库扩充与质量保障:多源构建 pipeline
4.1 多源题库构建策略
为支撑推荐系统,需要大规模、高质量的题库。本周实现了不同数据源的提取和整合。对于word文档,数学公式无法提取(python-docx 不支持 OMML),所以我选取了Markdown文件,由于是LaTeX 格式文件,能够实现公式完整、结构清晰的效果。并通过自己手动整理审核,确保了题目答案解析清晰完整,不会污染数据源。对于政治/英语这些文字为主的题目,我使用了word文档、pdf等方便提取的文件格式。对于这些不同格式的文件,我也准备了不同的提取脚本,这里就过多赘述。
4.2 严格的数据清洗规则
在 提取脚本中实现了四层过滤:
def clean_questions(input_json_path: str, output_json_path: str):
"""清洗题目数据,过滤不合格的题目"""
stats = {
'total': len(documents),
'skipped_math': 0, # 跳过数学(公式丢失)
'no_answer': 0, # 无答案
'too_short': 0, # 题干过短
'placeholder': 0, # 占位符
'valid': 0 # 有效题目
}
for doc, meta in zip(documents, metadatas):
subject = meta.get('subject', '未知')
# 规则 0: 跳过数学科目(公式无法正确提取)
if subject == '数学':
stats['skipped_math'] += 1
continue
# 解析内容
parts = doc.split('\n')
stem = parts[0].replace('题目:', '').strip()
answer = parts[1].replace('答案:', '').strip()
# 规则 1: 必须有答案
if not answer or answer in ['待填写', '【待填写】', '[待填写]', '']:
stats['no_answer'] += 1
continue
# 规则 2: 题干长度 >= 20 字
if len(stem) < 20:
stats['too_short'] += 1
continue
# 规则 3: 题干不能包含占位符
if '待填写' in stem or (stem.startswith('【') and len(stem) < 30):
stats['placeholder'] += 1
continue
# 通过所有检查,保留该题目
cleaned_documents.append(doc)
cleaned_metadatas.append(meta)
stats['valid'] += 1
return cleaned_data关键决策:
由于目前数学均为手动整理,所以跳过数学科目,只保留以文字为主的政治和英语,同时严格要求格式的规范,必须有清晰的题干、答案和解析,也避免了过短等低质量题目混入污染题库。
4.3 基于题干哈希的去重机制
在提取脚本中,使用 MD5 哈希实现精准去重:
def import_and_sync():
"""将向量库 JSON 数据同步到 MySQL question_bank 表"""
json_path = "data/question_bank.docs.json"
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
docs = data.get('documents', [])
metadatas = data.get('metadatas', [])
for i, (content, meta) in enumerate(zip(docs, metadatas)):
stem, answer, analysis = parse_content(content)
if not stem or len(stem) < 10:
continue
# 【关键改进】生成题干哈希值用于精准去重
stem_hash = hashlib.md5(stem.encode('utf-8')).hexdigest()
tags = ",".join(meta.get('tags', []))
subject = meta.get('subject', '数学')
year = int(meta.get('year', 0)) if meta.get('year') else 0
# 尝试插入,如果哈希值重复会触发数据库唯一索引报错
sql = """
INSERT INTO question_bank (stem, answer, analysis, tags, subject, year, source, stem_hash, create_time)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, NOW())
ON DUPLICATE KEY UPDATE update_time = NOW()
"""
try:
mysql_client.execute_update(sql, (
stem, answer, analysis, tags, subject, year,
meta.get('source', 'organized'), stem_hash
))
# 获取刚才插入或更新的 ID
q_id_res = mysql_client.execute_query(
"SELECT id FROM question_bank WHERE stem_hash = %s",
(stem_hash,)
)
if q_id_res:
q_id = q_id_res[0]['id']
else:
continue
except Exception as e:
if "Duplicate entry" in str(e):
logger.debug(f"题目已存在,跳过: {stem[:20]}...")
# 获取已存在的 ID
q_id_res = mysql_client.execute_query(
"SELECT id FROM question_bank WHERE stem_hash = %s",
(stem_hash,)
)
if q_id_res:
q_id = q_id_res[0]['id']
else:
logger.error(f"插入失败: {str(e)}")
continue
# 准备 FAISS 同步数据,将 MySQL ID 写入元数据
content_text = f"题目:{stem}\n答案:{answer}"
if analysis:
content_text += f"\n解析:{analysis}"
new_texts.append(content_text)
new_meta = meta.copy()
new_meta['topic_id'] = q_id # 【关键】将 MySQL ID 写入 FAISS 元数据
new_metadatas.append(new_meta)
# 重建 FAISS 索引,确保 ID 与 MySQL 对齐
faiss_store.add_documents(new_texts, new_metadatas)
save_path = "data/question_bank"
faiss_store.save(save_path)
logger.info(f"✅ MySQL 同步完成!共处理 {success_count} 道题目。")
logger.info(f"💾 FAISS 索引已更新,现在 ID 已与 MySQL 对齐。")去重机制的核心:
题干哈希作为唯一标识:stem_hash = MD5(题干内容)。
数据库唯一索引:UNIQUE KEY uk_stem_hash (stem_hash)。
ON DUPLICATE KEY UPDATE:如果哈希值已存在,更新时间戳;否则插入新记录。
幂等性保证:多次运行脚本不会产生重复数据。
4.4 MySQL-FAISS 双向同步
为确保向量库与关系数据库的 ID 对齐,实现了完整的同步流程:
┌──────────────────────────────────────────────┐
│ 步骤1:解析 JSON 数据 │
│ • 提取题干、答案、解析 │
│ • 生成题干哈希(MD5) │
└──────────────────────────────────────────────┘
↓
┌──────────────────────────────────────────────┐
│ 步骤2:插入 MySQL │
│ • INSERT INTO question_bank ... │
│ • ON DUPLICATE KEY UPDATE(去重) │
│ • 获取自增 ID(LAST_INSERT_ID) │
└─────────────────────────────────────────── ──┘
↓
┌──────────────────────────────────────────────┐
│ 步骤3:更新 FAISS 元数据 │
│ • metadata['topic_id'] = mysql_id │
│ • 确保 FAISS 中的 ID 与 MySQL 一致 │
└──────────────────────────────────────────────┘
↓
┌──────────────────────────────────────────────┐
│ 步骤4:重建 FAISS 索引 │
│ • add_documents(new_texts, new_metadatas) │
│ • save("data/question_bank") │
└──────────────────────────────────────────────┘同步后的效果:
FAISS 检索返回的 topic_id 可以直接用于 MySQL 查询。
两级检索策略得以实现:FAISS 快速筛选 → MySQL 获取完整信息。
数据一致性得到保证:删除 MySQL 记录后,可同步删除 FAISS 中的对应文档。
五、测试验证与效果展示
5.1 推荐引擎测试
执行 测试文件:
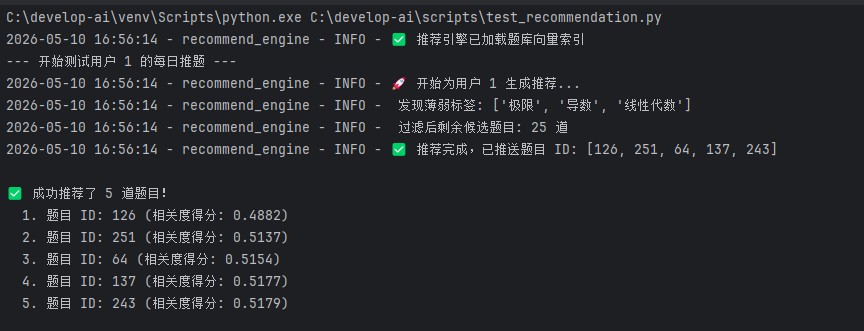
5.2 去重验证
连续两次调用推荐接口,验证是否出现重复题目:
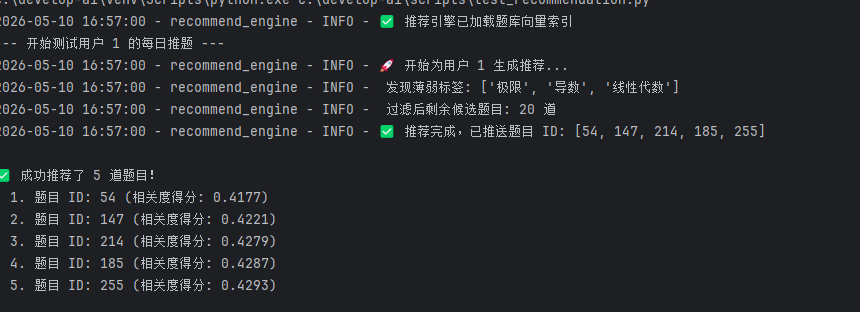
可以看到推送了完全不同的题目ID,并计算了与知识标签的相关度。
六、总结与展望
本周成果总结
实现了双层架构实现,完成了"用户画像(MySQL)+ 向量检索(FAISS)"的完整闭环;做到了个性化推荐,系统基于用户历史错题统计薄弱标签,千人千面;完成了去重机制,通过 push_history 表排除近期已推送题目;也基于标签覆盖度的排序算法,避免同质化推送,做到了多样性控制;建立了多源构建 pipeline,支持 Markdown、DOCX、LaTeX 等格式;实现了 MySQL-FAISS 双向 ID 对齐,支撑两级检索策略。
下周将进一步扩充题库和知识库,同时思索如何对推题系统的进行进一步优化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)