EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
背景问题
LLM 在自回归阶段,每输出一个 token 都要访问全部模型参数,导致推理昂贵且慢。已有的“speculative sampling”通过先用一个更小的draft model生成多步候选,然后再并行用target/base model验证来加速。这个方法的加速比效果受草稿质量限制(吐槽一下:如果接受长度=1,和没开有啥区别?如果接受长度=0~~还不如不用eagle3【手动狗头】)。
老 EAGLE 1/2 通过让草稿模型预测目标模型的“顶层特征”(用人话讲就是LM Head的输入,最后一个transformer encoder的输出)并复用目标模型的 LM head 来得得到预测 token的 distribution。但是这些方法存在两个主要局限:
- 把训练目标设为特征预测带来额外约束,限制草稿模型表达能力,使得随着训练数据扩大量收益有限;
- 仅复用目标模型的顶层特征,顶层特征主要对应下一个 token 的 distribution,难以有效支持多步(multi-step)草稿生成,也没法对丰富的语义信息进行利用。
这里讲一下人话哈:就是说,老 eagle 给他堆数据,不会增智(表现堆了几倍数据,accept length还是差不多)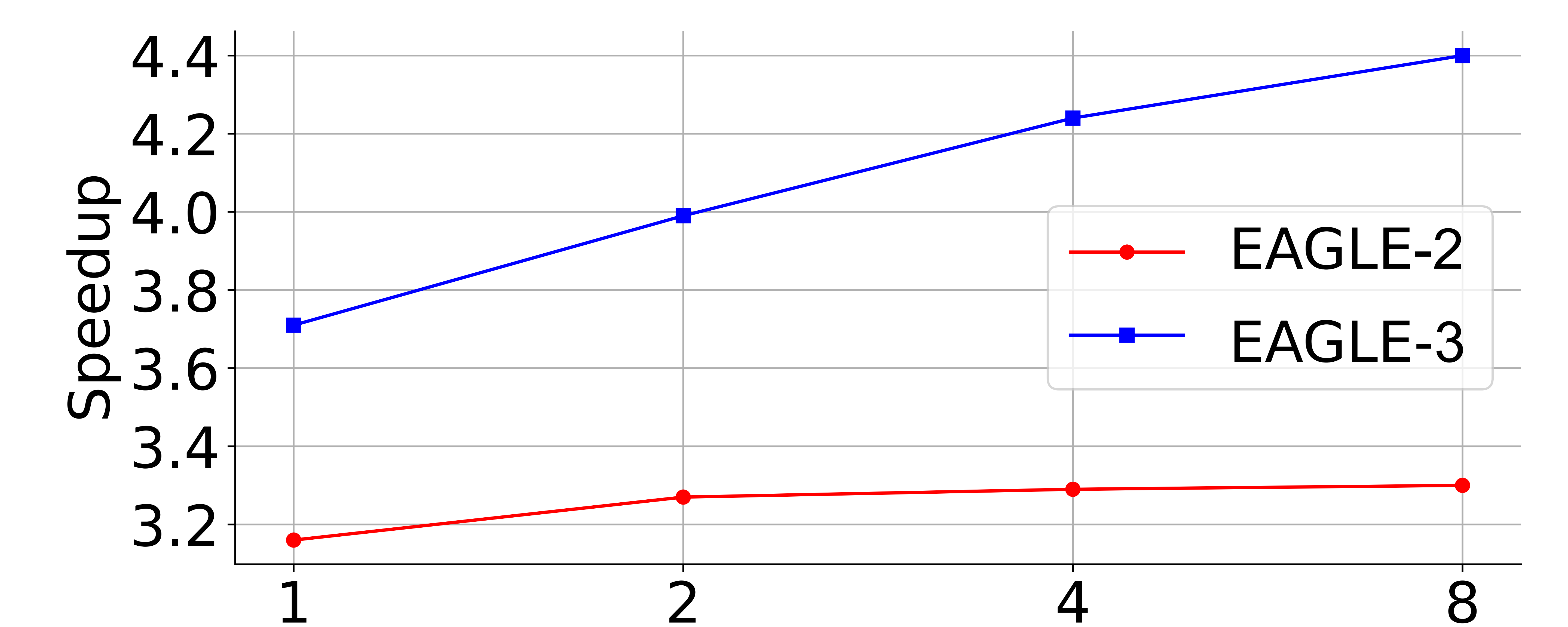
正经时间到~~~
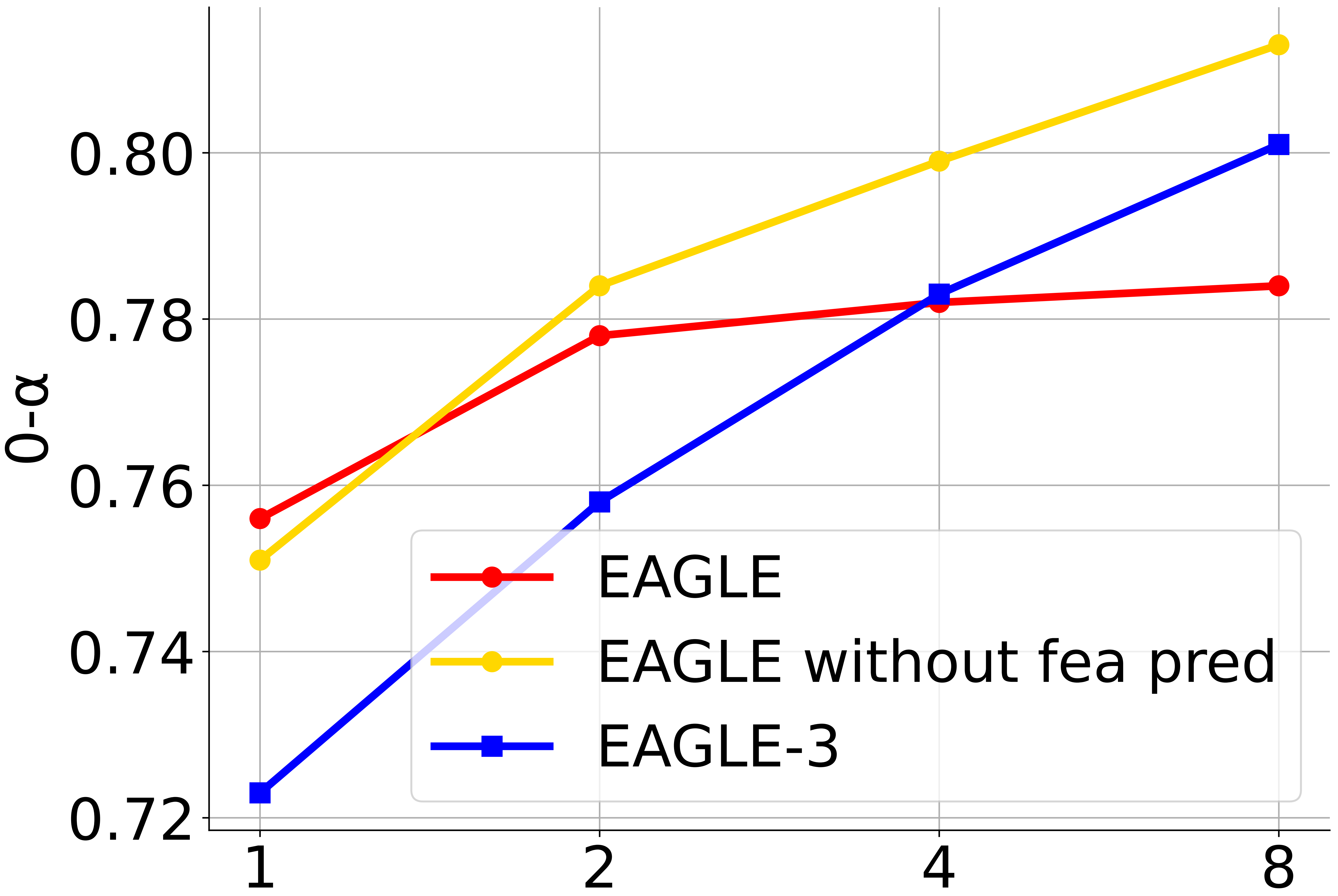
图在 MT-bench(一个多任务评估或人类偏好评估集合)上评估模型性能随训练数据规模变化的规律(scaling law)。这里把 LLaMA-Instruct 3.1 8B 当作“目标模型”(target model),通常意味着评估时用它的表现作为比较基准或对照模型,或是在这个基准上测量其他模型对齐人类偏好的能力。
x 轴表示训练数据量的相对尺度,以 ShareGPT(一个常用的对话数据集)为基准。例如 x=1 表示与 ShareGPT 同样量的数据,x=2 表示两倍 ShareGPT 的数据量,依此类推。因而图上不同点对应用不同比例的数据(相对于 ShareGPT)训练或微调得到的模型表现。
总结一下:意思是 EAGLE-3 的架构改善了模型对更多数据的利用效率,使得扩大训练数据量带来了显著的性能收益。
论文要解决的核心问题
如何在保留“无损(lossless)加速”与并行化草拟—验证思路下,提高草稿模型的接受率与加速比,尤其使草稿模型能从更多训练数据中受益并支持更长多步草稿而不发生误差累积,进而显著升推理速度与吞吐量。
解决效果
新方法称为 EAGLE-3,实验表明其在多任务、多模型上都显著优于先前方法(包括 EAGLE 与 EAGLE-2),速度加速比可达约 3.0x–6.5x,相较 EAGLE-2 约提升 1.4x,且在扩大训练数据时出现了此前 EAGLE 未见的“推理加速随训练数据规模增长而提升”的尺度律(scaling law)。
这里展示的是在温度(temperature)设为 0 的情况下,不同方法的加速比(speedup ratio)。
标准的 speculative sampling(推测抽样)方法中,主模型(用于最终生成、这里是 Vicuna-13B)配套使用的草稿模型(draft model)是一个小模型 Vicuna-68M。也就是说先用小模型快速生成“草稿”再由大模型验证/完成,从而实现加速。
这张图说明了在确定性(temperature=0)条件下展示了若干方法的加速比,其中标准的 speculative sampling 是用小模型(Vicuna-68M)作为草稿模型来配合大模型(Vicuna-13B)。
ps: temperature=0 通常表示生成时去掉随机性(确定性采样),所以比较的是确定性条件下各方法的速度提升。
作者的解决方案
- 取消特征预测约束,改为直接训练草稿模型进行 token 预测,并在训练中通过“training-time test”模拟多步生成(把 Step1 的草稿生成也纳入训练),从而缓解训练-推理不一致与误差累积,使草稿模型能更充分利用更大规模训练数据。
- 不再只依赖顶层特征,而是通过多层特征融合(低/中/高层特征融合)为草稿模型提供更丰富语义信息,提升多步预测能力与接受率。
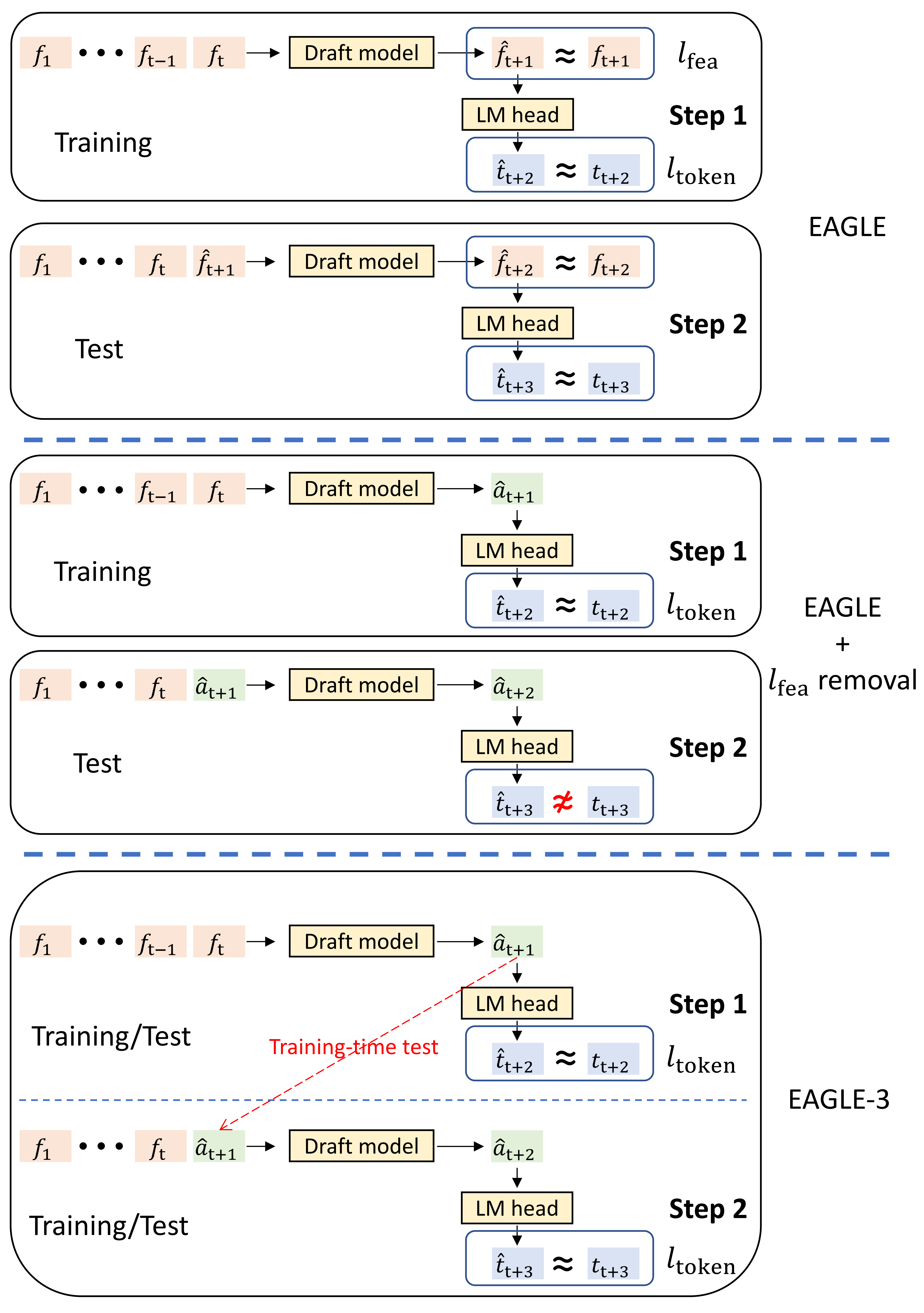
图的下半部分展示的是“training-time test”(训练时测试)方法的流程或行为;上半部分和中间部分分别展示其它“draft methods”(草案方法或候选方法)如何运作。也就是说,图把不同方法的流程并列比较,上面部分是已有方法/基线,中间可能是另一类方法或变体,底部是作者提出的训练时测试方法。
在图中,符号的含义是:
fff 表示“feature”,指base model的特征向量;
ttt 表示“token”,指预测出来的token(吐槽:这个应该不用教吧*-^);
aaa 表示“unconstrained vectors”,翻译过来就是不受约束的向量。
在图中带 ^\hat{}^(帽子)的变量,例如 t^\hat{t}t^、a^\hat{a}a^ 或 f^\hat{f}f^,表示模型的预测值(而不是原始/真实的输入或 ground-truth)。这是一个标准记法,用来区分预测与真实值或输入特征。
许多序列生成模型在生成当前时间步输出时,会参考上一个时间步已经生成的 token 序列(即自回归或基于历史 context)。论文中,作者说明了:图中没有画出“来自上一个时间步的 token 序列”,为了图示简洁省略了,但实际上所有这些方法在实际实现或训练/推理过程中都会用到之前时间步的 token 信息。
EAGLE-3 的真实输入并不是图中标为 fff 的那个向量。作者提醒读者注意:图为了通用或简化把输入标记为 fff,但 EAGLE-3 实际用的是别的输入形式或额外信息(比如:三尺度的特征),预知细节如何,请看下文【手动狗头】。
这里补充一下:
- “训练时测试”(training-time test)通常指在训练阶段模拟或使用测试时的解码/生成策略(例如用模型自己的预测作为下一个输入,或以某种推理方式训练模型),这有助于减少训练/测试时分布不一致(exposure bias)。
- “Draft methods” 可能指在生成任务中先生成一个连续向量草稿(a,unconstrained vectors),再将其映射或解码为离散 token(t)。不同方法在“是否限制草稿向量”、如何把草稿转成 token、以及草稿是否依赖特征 f 或历史 token 等方面存在差异。
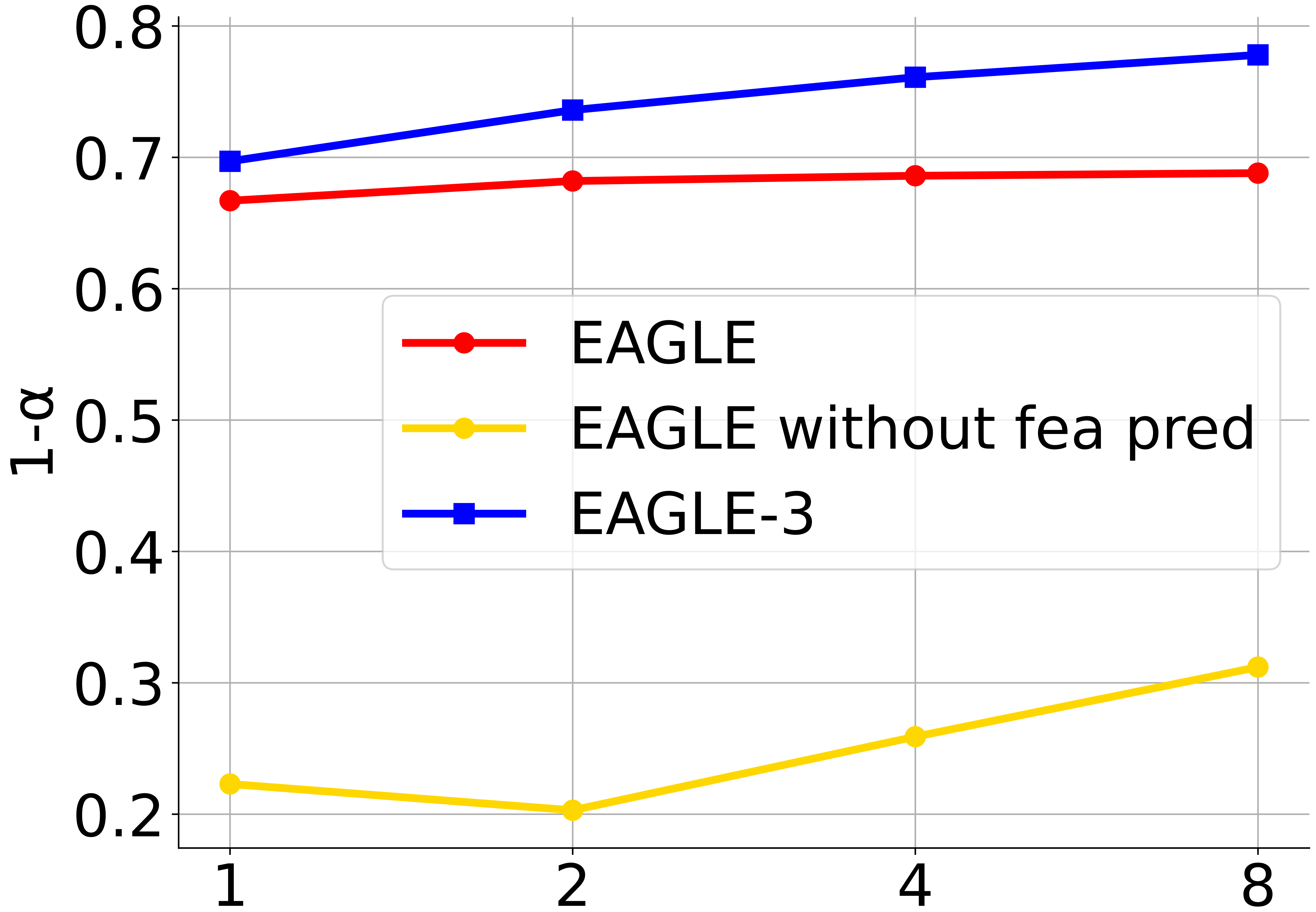
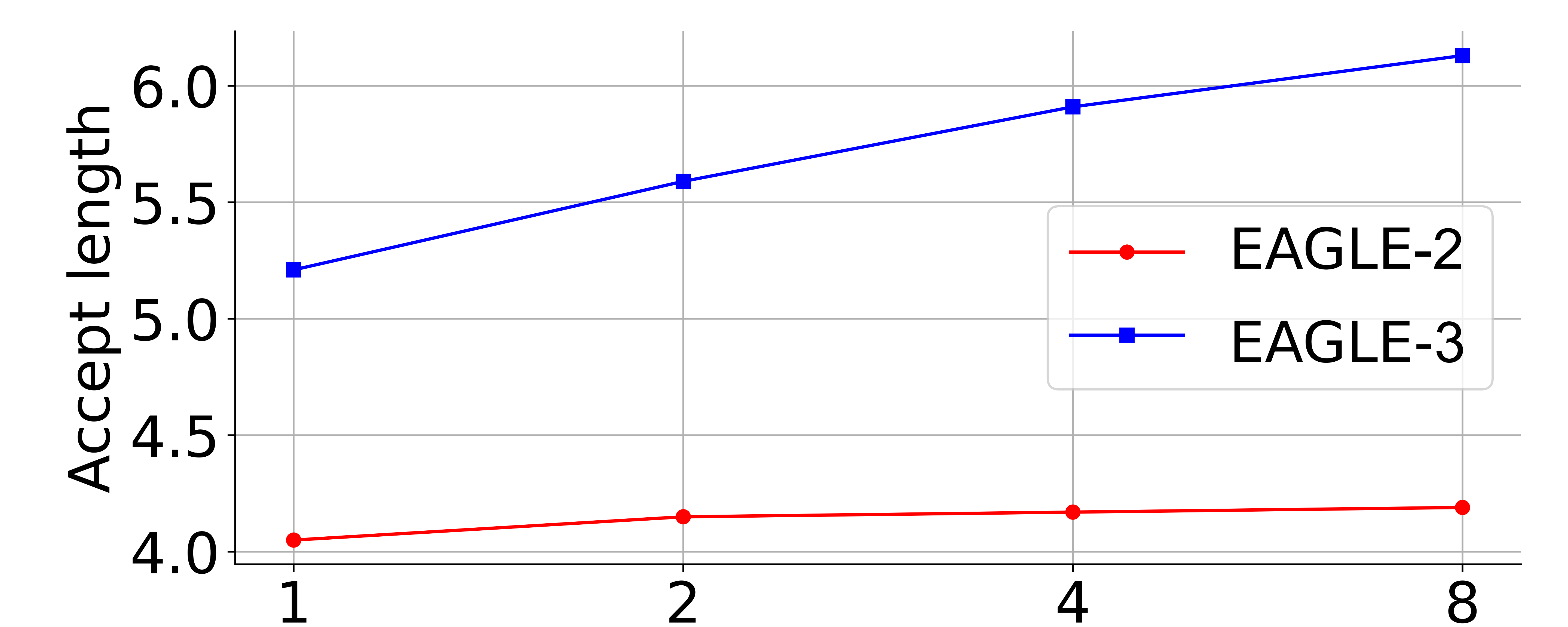
上图比较了不同方法在“接受率(acceptance rate)”上的表现,横轴为数据规模相对于 ShareGPT 的倍数(例如 0.1×、1×、10× 等),纵轴为接受率(越高表示模型越倾向接受人类提供的建议或更容易通过某个判定标准)。这说明随着训练/微调时使用数据量的改变,不同方法在接受率上的敏感性和趨势。
横轴以 ShareGPT 数据量为基准,值小于 1 表示使用比 ShareGPT 少的数据(下采样),大于 1 表示使用更多的数据(扩增或合并其他来源)。这样可以观察方法在数据稀缺与数据丰富两种情形下的鲁棒性。
每条曲线代表一种训练或微调方法(例如:基础模型、指令微调(Instruction Tuning)、对比学习、RLHF、偏好对齐方法,或论文中具体命名的几种变体)。图中点/线的高度显示对应数据规模下的接受率,通常会标明置信区间(误差条)来反映统计不确定性。
看图的方法:
- 若某方法曲线整体高于其他方法,表示在各数据规模下普遍能获得更高接受率,说明该方法在该任务或评测标准下更有效。
- 若某方法在低数据量(左侧)就表现好,说明该方法对数据效率高,适合数据受限场景。
- 若某方法随着数据增加性能持续上升,说明该方法能有效利用额外数据进行改进。相反,若曲线平坦或下降,说明方法对更多数据不敏感或出现过拟合/偏差问题。
- 不同方法在交叉点处互相超越,说明在不同的数据规模区间,每种方法的优劣顺序会变化,这提示实际部署时需根据可用数据量选择方案。
作者可能总结道某种新方法在小样本和大样本均优于基线,或指出传统方法在数据足够时仍能追平新方法,或强调在数据受限时采用 X 方法更合适。也可能指出不同来源的数据(比如 ShareGPT vs. WebQA)对接受率影响不同。
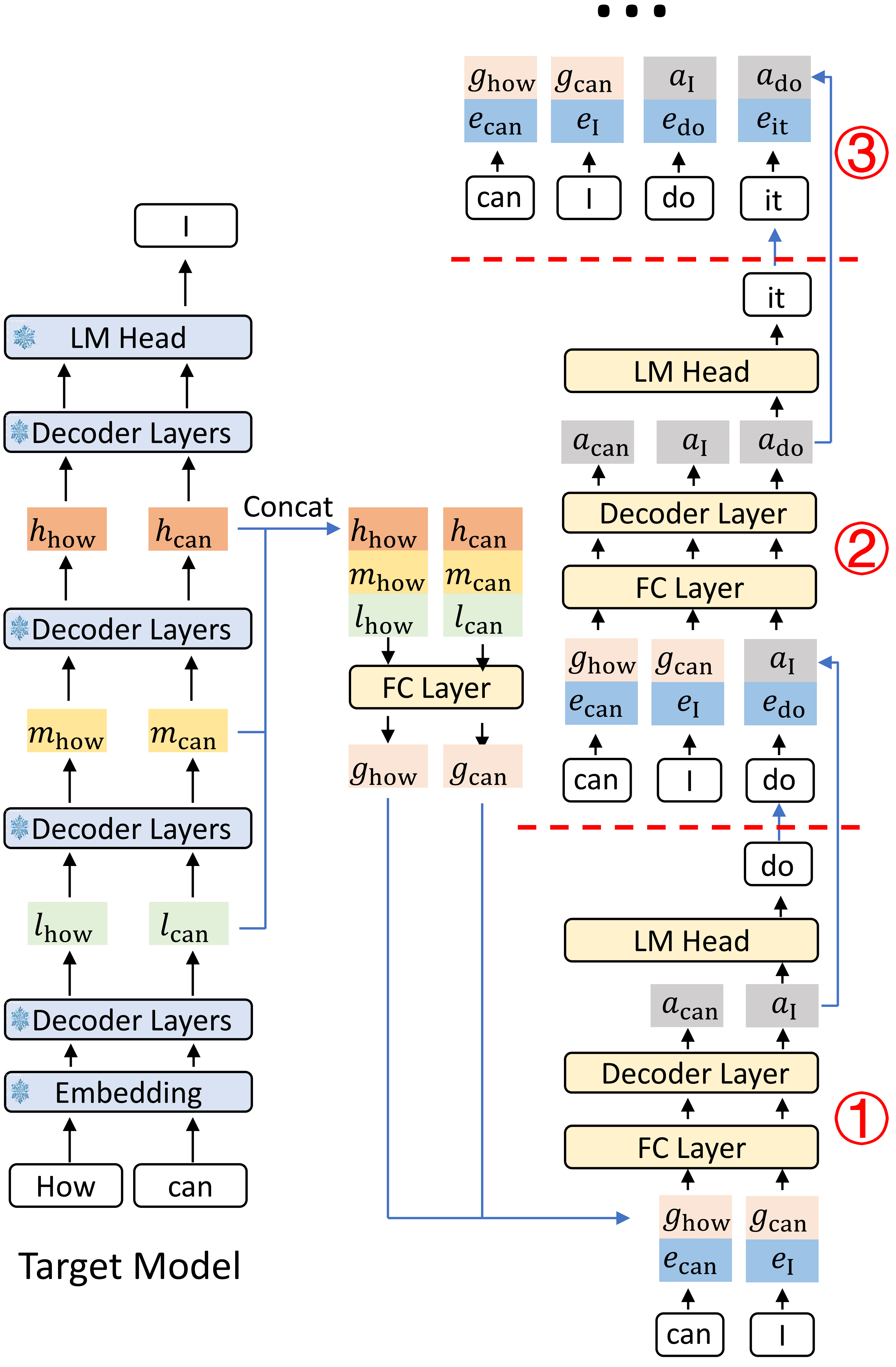
上图描述的是 EAGLE-3 在推理(inference)阶段如何逐步从输入生成最终输出的流程。模型采用分层特征和多步“草案—修正”式的生成策略:先产生粗糙草案,再逐层精修,最终得到高质量结果。
三个步骤对应三个草案阶段,每一步都使用不同层级的特征和嵌入信息来引导生成或修正。
逐步解释(对应图中三个步骤)
- 第一步:基于低级特征(l)和初始嵌入(e)生成低精度草案
输入:初始嵌入 e(可以来自输入数据或前序编码器),以及目标模型的低级特征 l。
作用:利用最底层的特征信息产生第一个粗略草案(草案0或草案1),该草案包含基础结构或粗粒度内容,但细节和全局一致性尚不完整。
意图:快速给出一个可行的起点,计算代价较低,便于后续迭代改进。 - 第二步:结合中级特征(m)对草案进行中层修正
输入:第一步生成的草案与中级特征 m(以及对应的嵌入 e)。
作用:中级特征提供比低级更多的语义/结构信息(例如中等尺度的形状、句法或局部语义关系),用于对草案进行改进,修正错误并填充更多细节,产生更精细的第二阶段草案。
意图:在保持第一步结构的基础上,提升质量与连贯性。 - 第三步:使用高级特征(h)做最终精修
输入:第二步草案、最高层特征 h 以及嵌入 e。
作用:高级特征包含全局、语义或抽象层次的信息(例如全局语义一致性、长程依赖、风格等),用于对草案做最终微调,解决长期依赖问题、提升整体一致性与细节质量,输出最终结果。
意图:通过最高层语义引导,达成最终高质量输出。
关于图中 e(嵌入)的作用
e 很可能在每一步都被用作条件信息或上下文向量,向每个草案阶段传递输入的固定语义信息(例如文本提示、图像编码或先验)。
嵌入可与各层特征联合用于注意力机制或条件生成,使每一步生成既参考多层特征又保持与原始输入一致。
设计动机与优点:
- 分层草案策略可以逐步聚焦不同尺度的信息:先处理低级结构,再逐步融入中高层语义,从而提升效率与质量。
- 每一步只需处理相应层级的复杂度,计算更可控;同时多阶段修正有助于纠正早期错误,增强最终输出的鲁棒性。
- 利用嵌入作为贯穿的条件信息,保证各阶段生成与输入语义对齐。
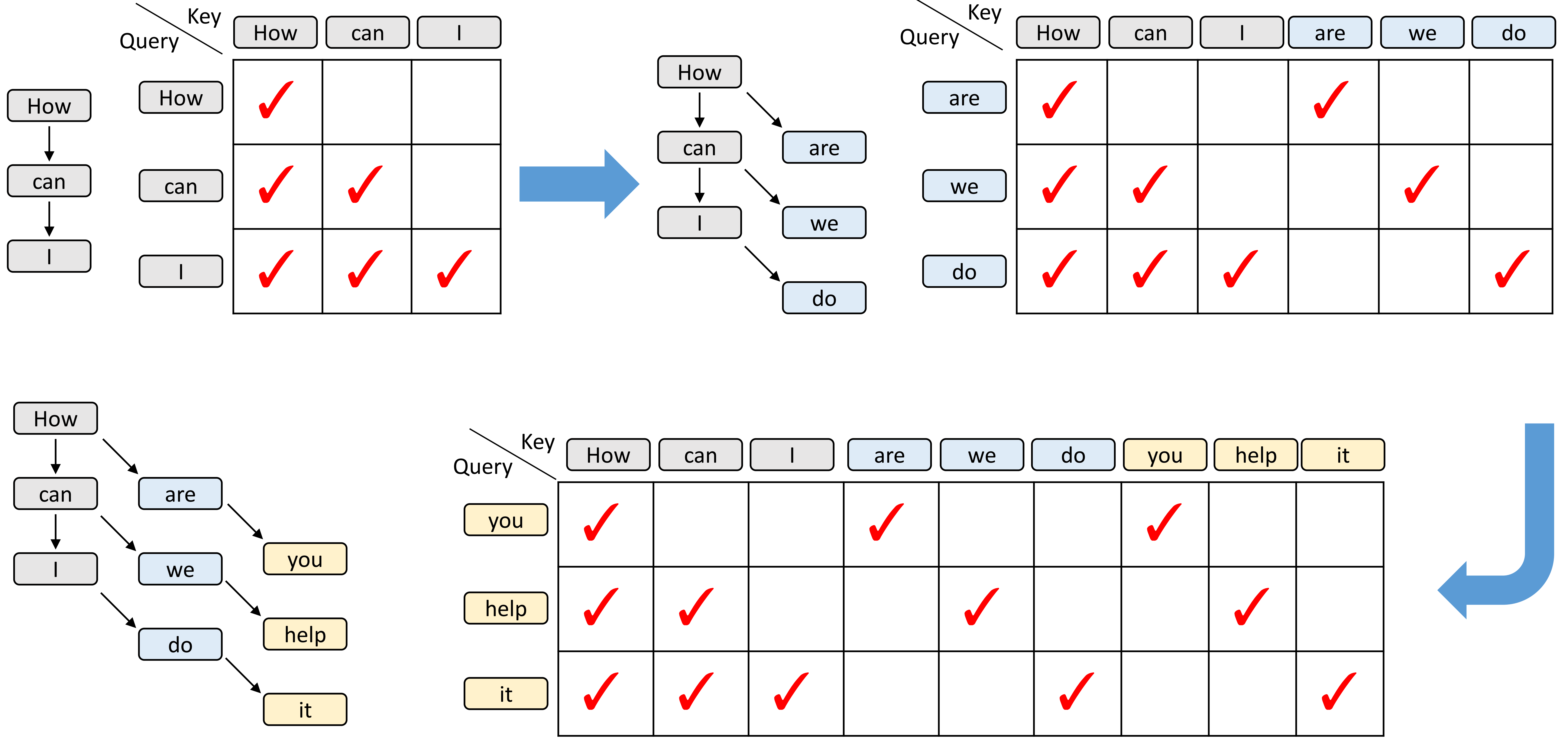
上图展示了训练时对模型生成过程的模拟(用 causal attention masks 控制信息流动)的三个连续步骤:第一步是“原生训练步”(native training step),接着是两步由草稿模型(draft model)生成的预测所模拟的训练步骤:
- 箭头表示注意力/上下文依赖关系(哪个 token 可以看到或利用哪个 token 的信息)。
- 灰色 token:训练数据(ground-truth 或历史上下文),模型在训练时可以直接访问这些真实标签。
- 蓝色 token:草稿模型的第一轮预测(round-1 prediction),作为后续训练步骤的输入/条件之一,但这些是模型生成的伪数据而非真实标签。
- 黄色 token:草稿模型的第二轮预测(round-2 prediction),进一步模拟更深一步的生成。
具体步骤解释:
- 原生训练步:模型在给定训练数据(灰色 token)的条件下进行标准的训练或计算损失。注意力掩码允许当前位置看到其左侧(因果顺序)真实训练 token,但不会看到未来的真实标签(保持因果性)。相当于普通的自回归训练:模型学习在真实上下文下预测下一个真实 token。
- 第一轮模拟训练步:这里引入草稿模型的第一轮预测(蓝色 token)作为“已生成”的上下文,模拟模型在推理/生成时的输入。注意力掩码在这一步被修改,使得后续 token 可以看到先前生成的蓝色 token(作为上下文),同时仍只能看到被允许看到的真实训练 token(灰色)。这样做的目的是训练或评估主模型在面对草稿模型提供的伪标签时,如何利用这些预测来继续生成或进行修正。箭头从蓝色 token 指向后续 token,表明后续 token 可以基于这些预测来计算注意力。
- 第二轮模拟训练步:基于第一轮生成的蓝色 token,草稿模型继续生成第二轮预测(黄色 token),这模拟更长的生成链或多轮迭代生成的情形。在这一步,注意力掩码允许新产生的黄色 token 被后续位置看到(箭头从黄色 token 指出),同时它们也可以看到灰色与蓝色 token(根据掩码规则)。通过逐步增加由草稿模型产生的伪数据,并控制哪些位置可以注意到哪些预测,训练可以更好地模拟实际生成时模型所处的条件分布,从而提高鲁棒性或支持多轮修正策略。
设计意图与作用:
- 通过在训练时模拟推理/生成时的上下文(即让模型看到草稿预测而非仅真实标签),可以减小训练/推理分布差异(exposure bias),提升模型在实际生成过程中的表现。
- 因果注意力掩码被精细设计以保证信息只沿因果时间方向流动,并明确哪些预测可作为后续输入,防止“偷看未来真实标签”。
- 颜色区分(灰/蓝/黄)强调不同来源的信息(真实 vs. 第1轮生成 vs. 第2轮生成)以及它们在训练中被如何利用。
简短总结:图示描述了用因果注意力掩码在训练时模拟多步生成的过程:先用真实数据做一步标准训练,然后依次引入草稿模型产生的一轮与二轮预测(蓝、黄),并调整注意力掩码以控制信息流,从而训练模型在面对其自身或草稿模型生成的伪标签时仍能正确生成或修正输出。
结论
总体来说,论文针对 EAGLE 系列在特征预测与顶层特征复用上的局限,提出了 training-time test 与多层特征融合两项改进,使草稿模型更灵活、更能从大规模数据中获益,从而显著提升无损推理加速效果与稳定性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)