Python+AI
Python启航
课程导学
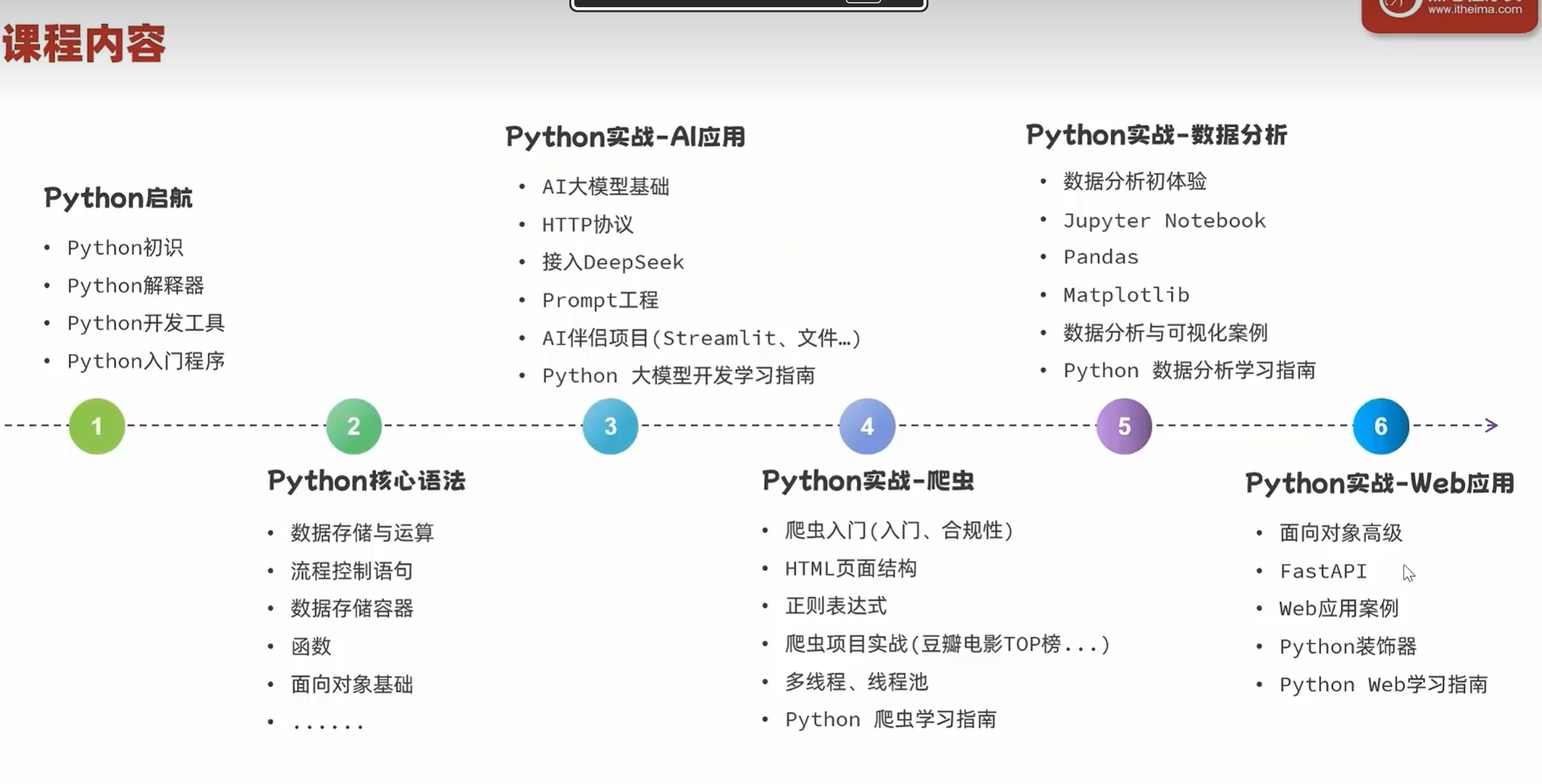
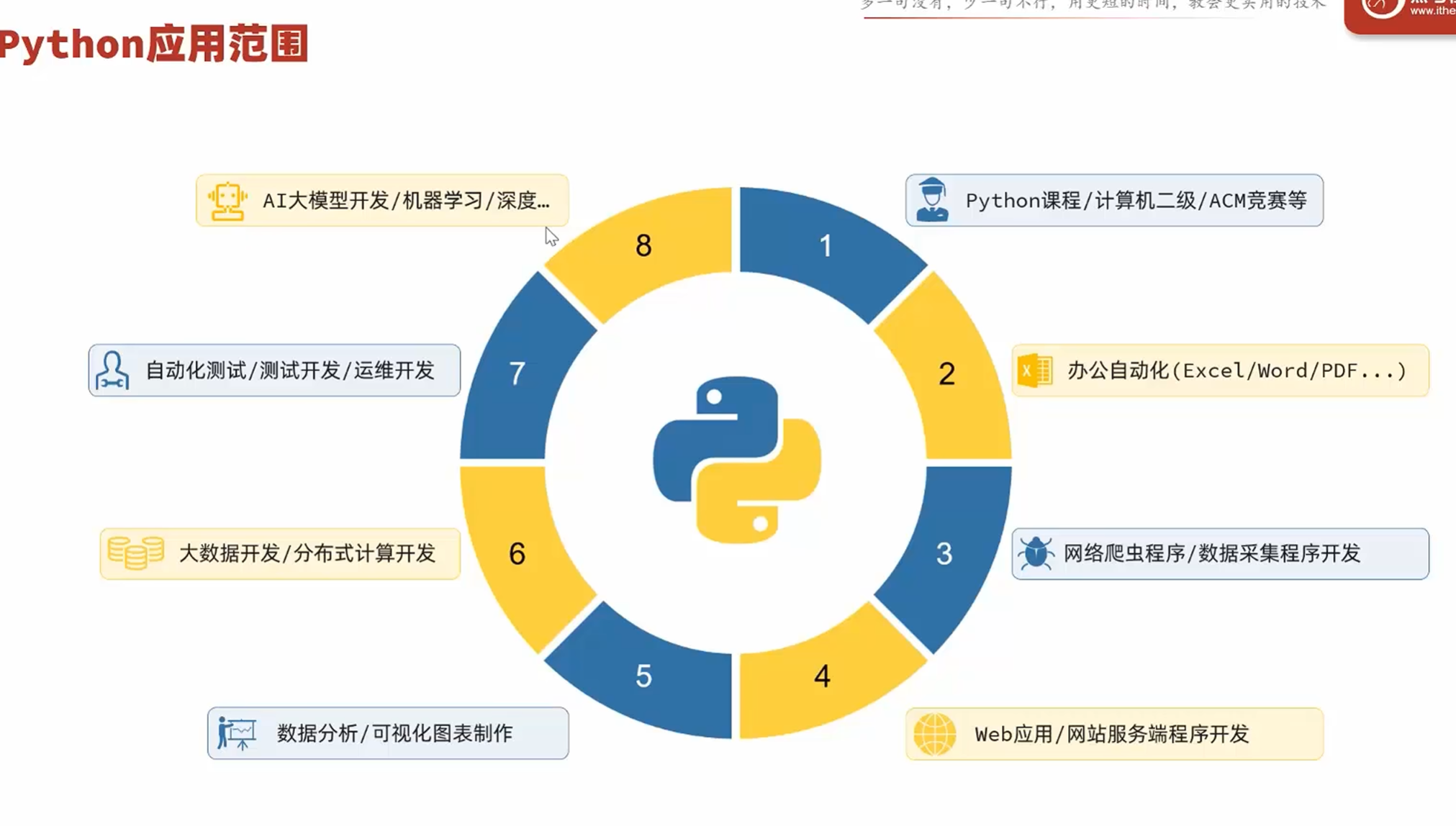
环境准备
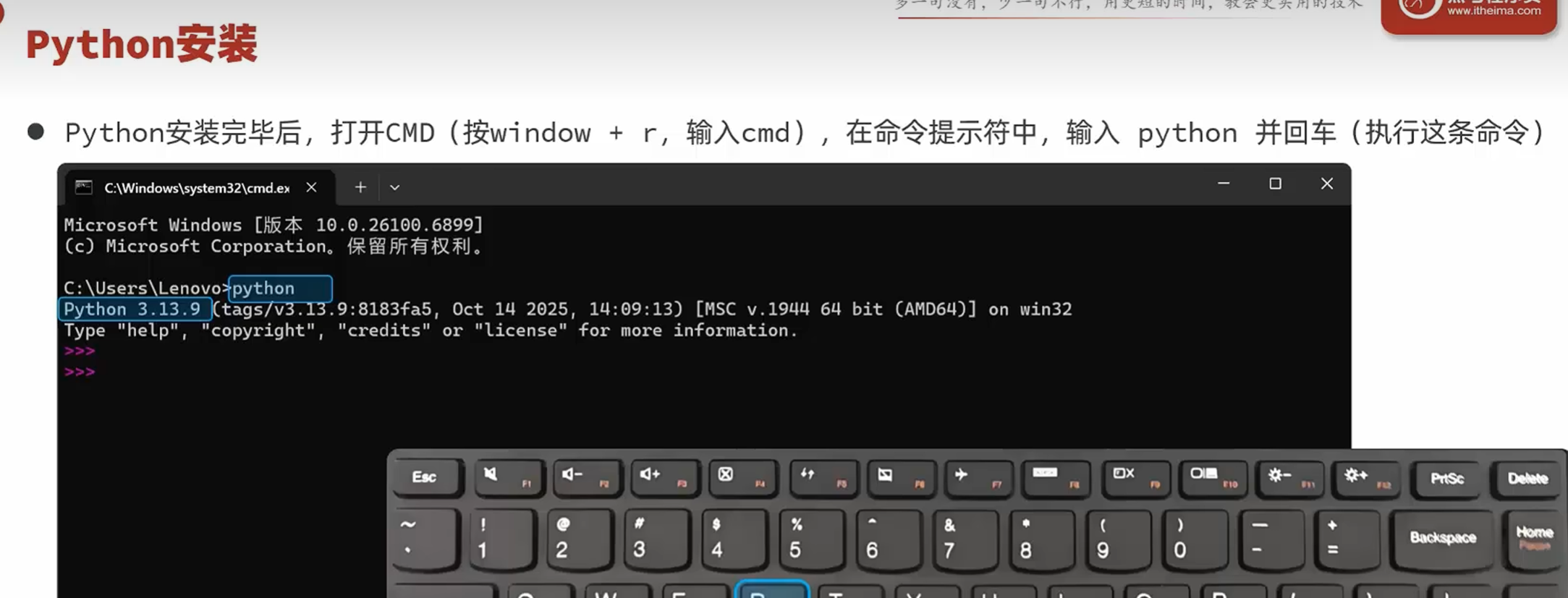
-Python安装
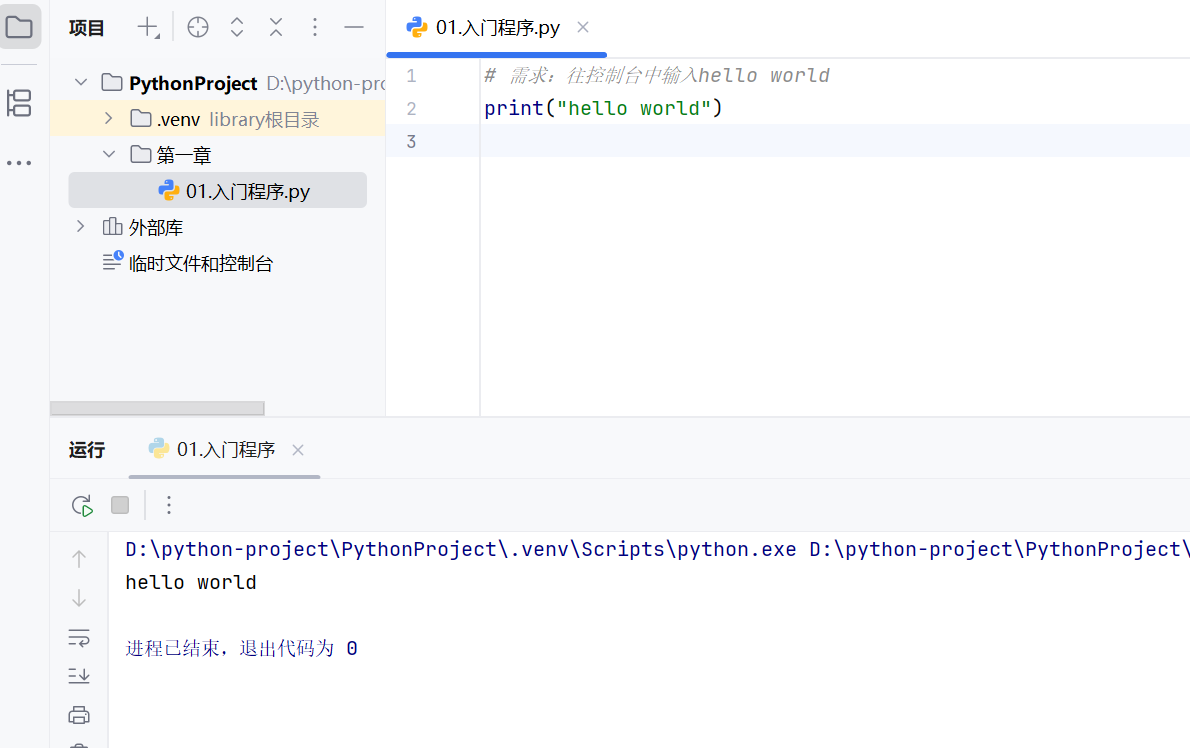
-Python程序初体验
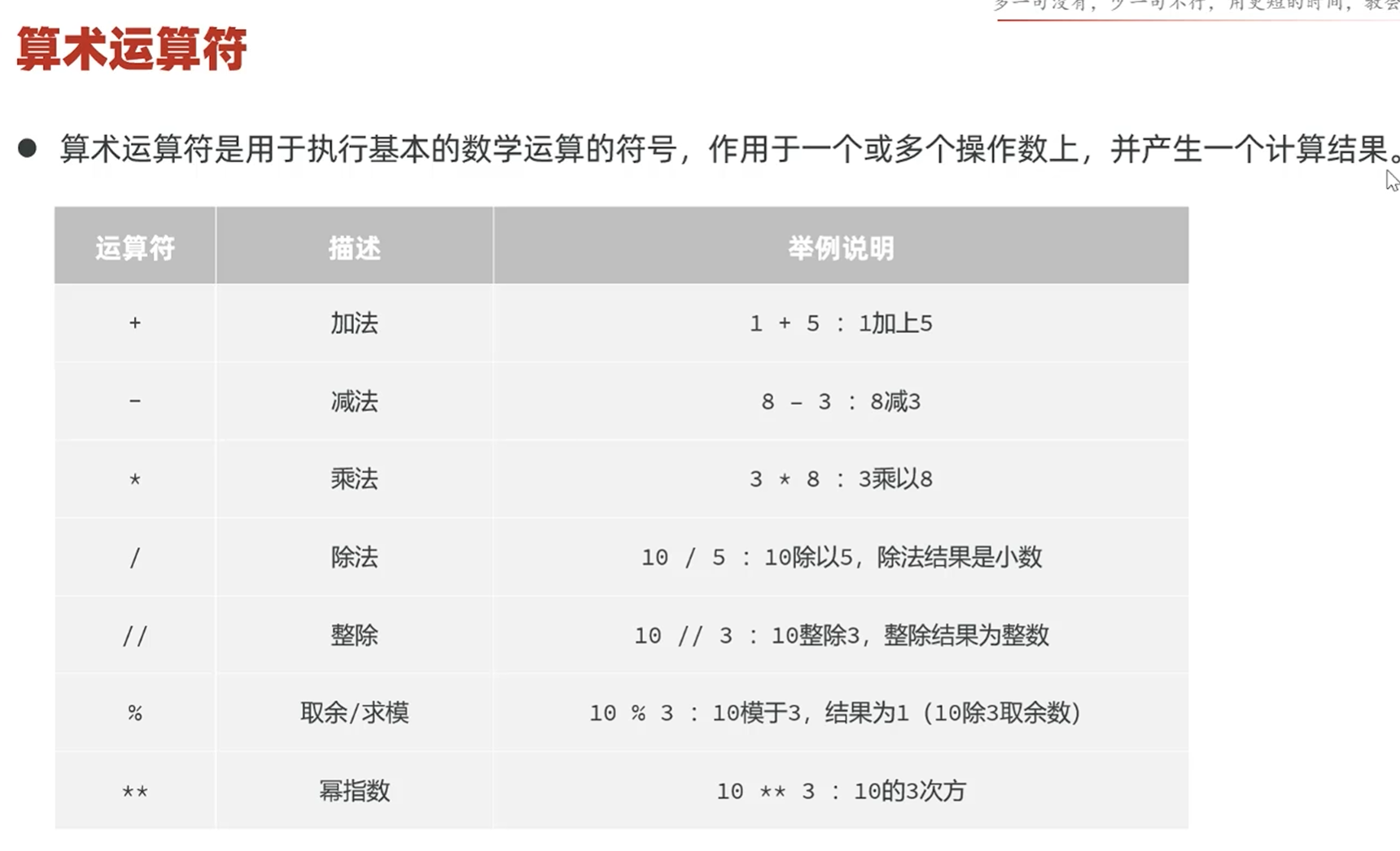
单行代码
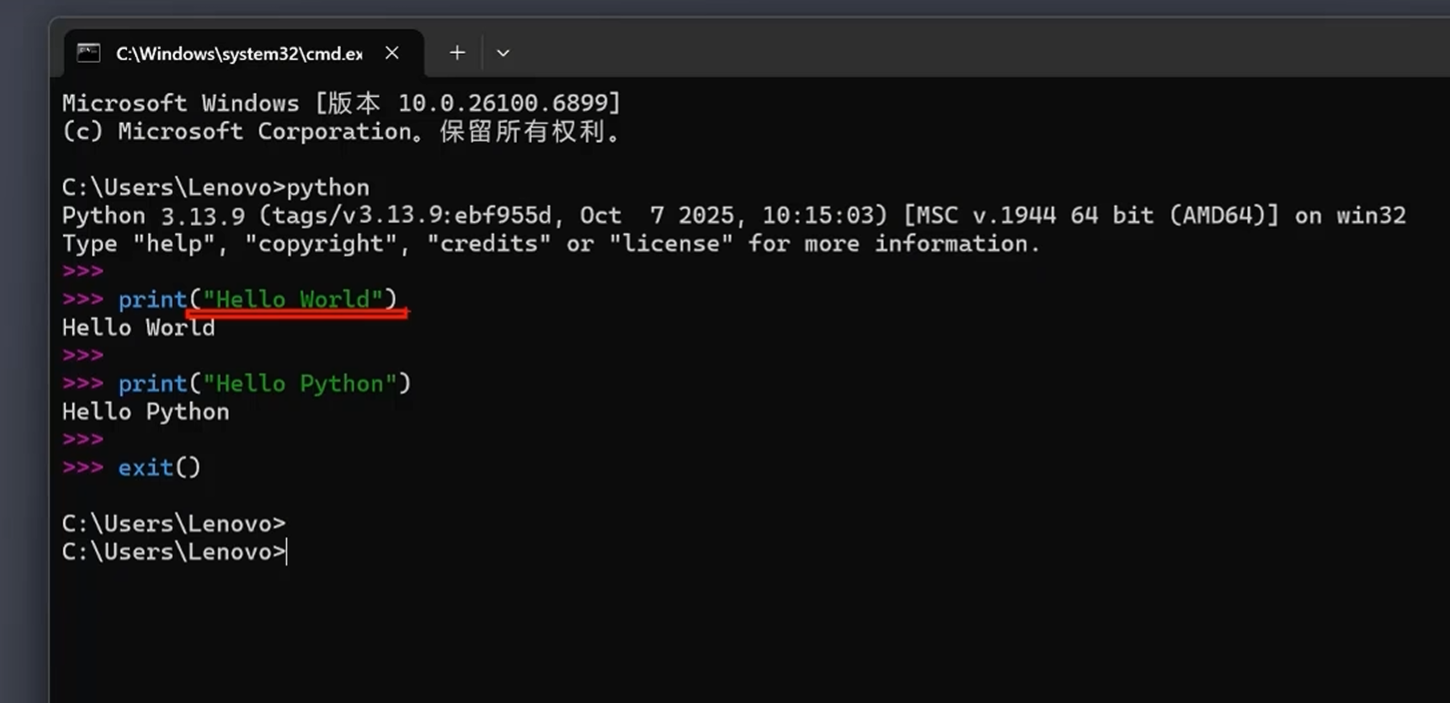
单行命令可以直接输入,如果要运行多行代码,可以写成文件,在cmd中直接运行
多行代码
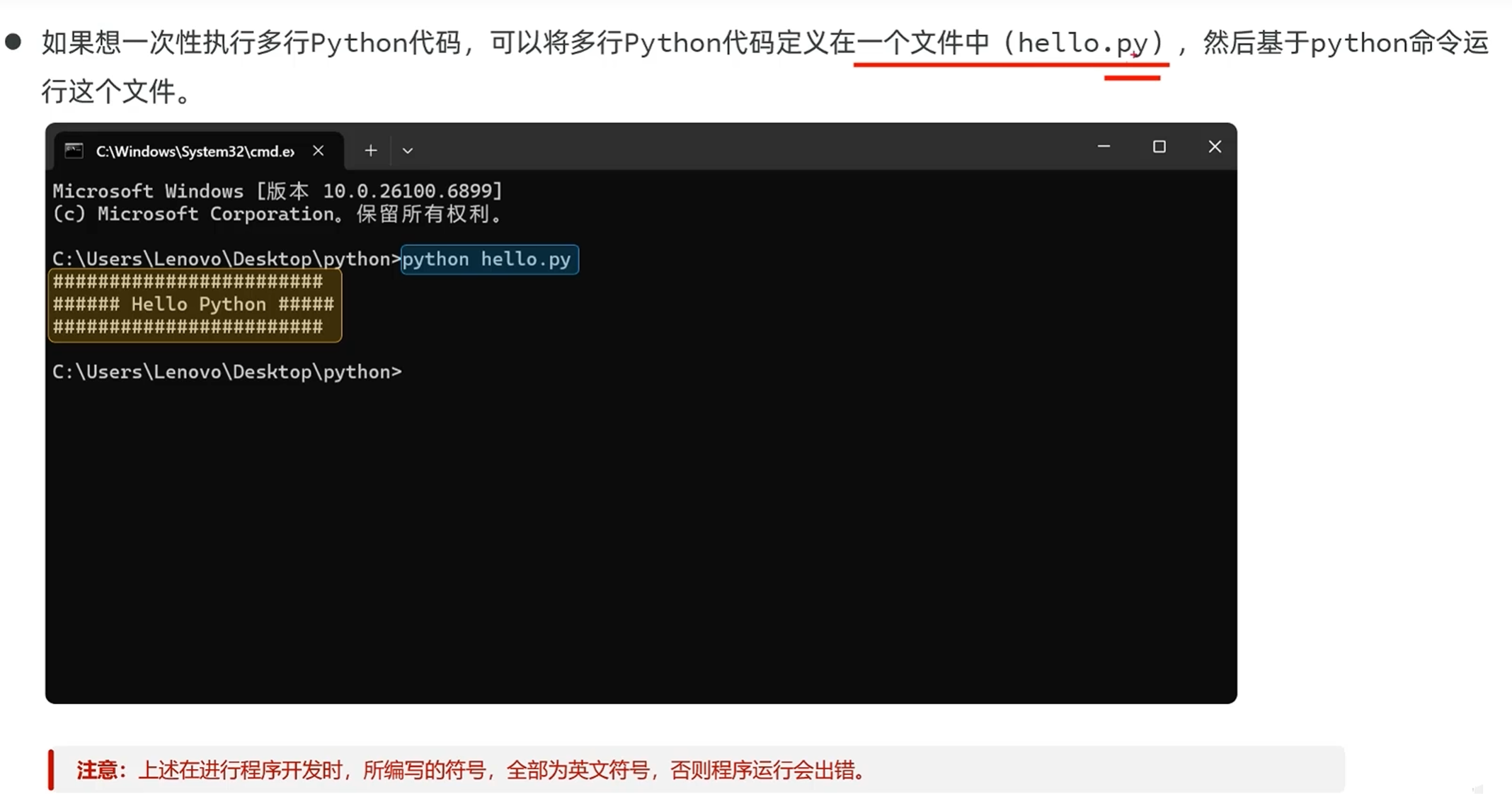
创建文本文档
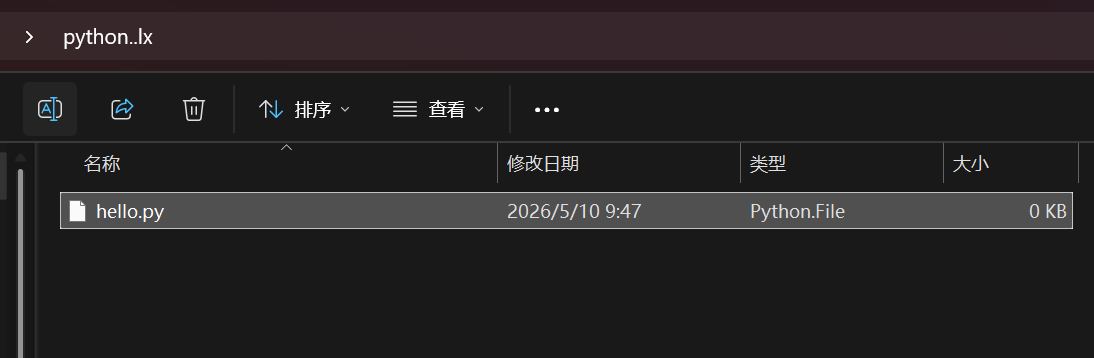
编写python代码
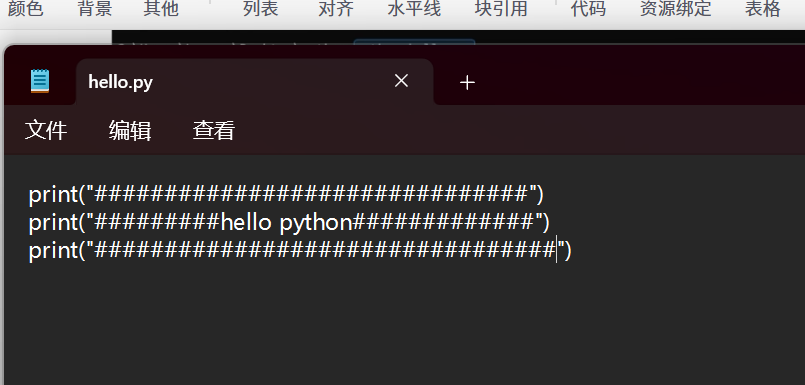
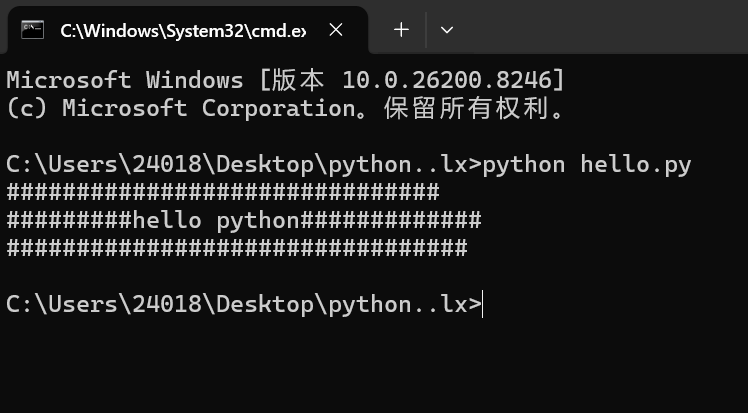
运行尝试

原因是cmd默认目录是c盘的Users的Lenovo下,该目录下没有hello.py
解决方案:
1.通过cd命令切换到
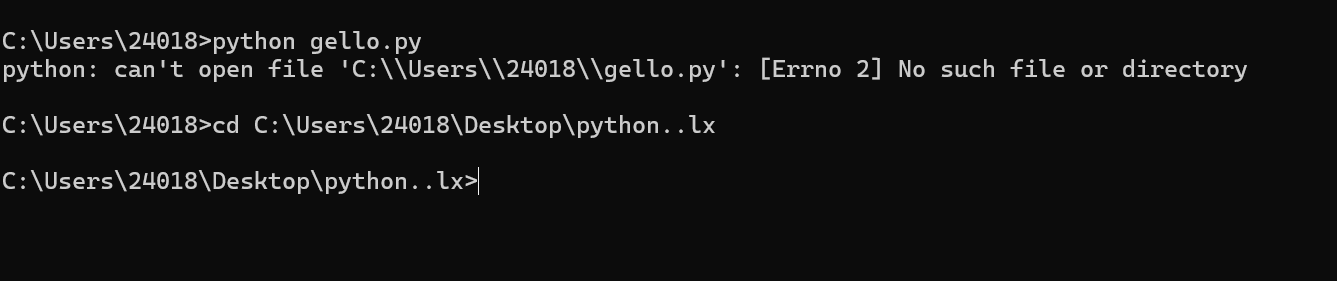
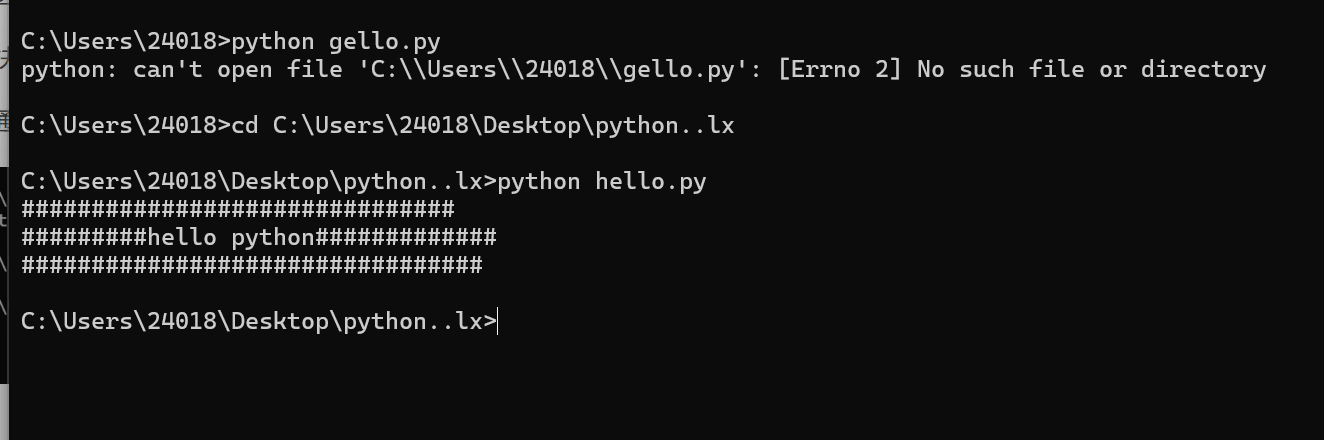
在对应目录下面执行命令
2.直接把地址栏的地址删掉,输入cmd

-常见问题解决方案
-Python开发工具PyCharm安装

-入门程序

换行会直接把两个语句分成·不同的
;只有在把两个语句写到同一行的时候才需要;作为分隔符
核心语法
-数据存储与运算


-字面量

直接书写的固定值


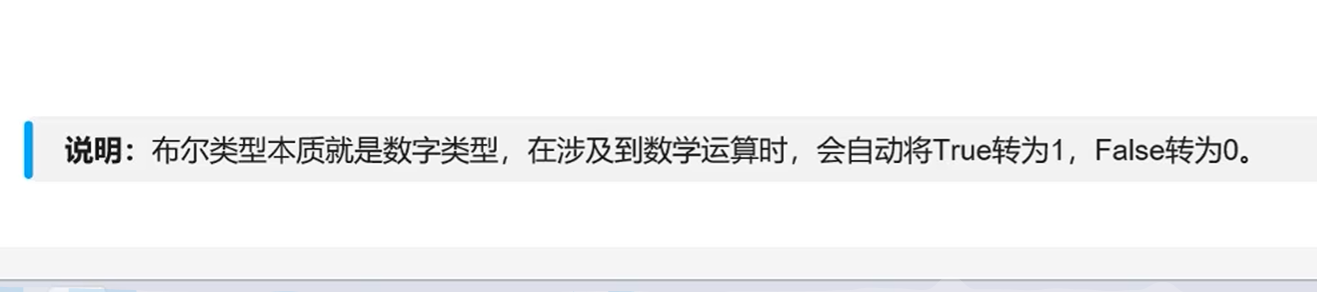
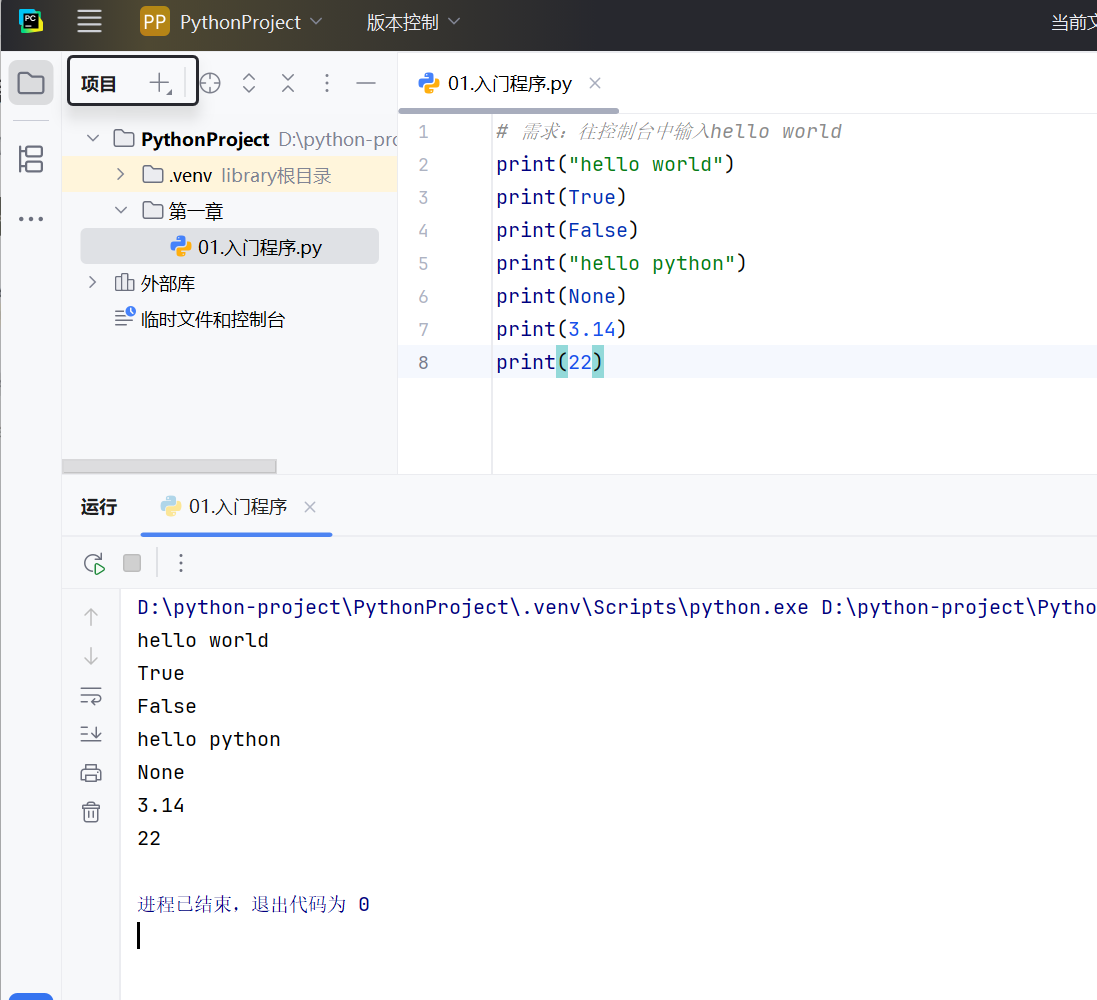
对于True,False这样的字面量需要大写
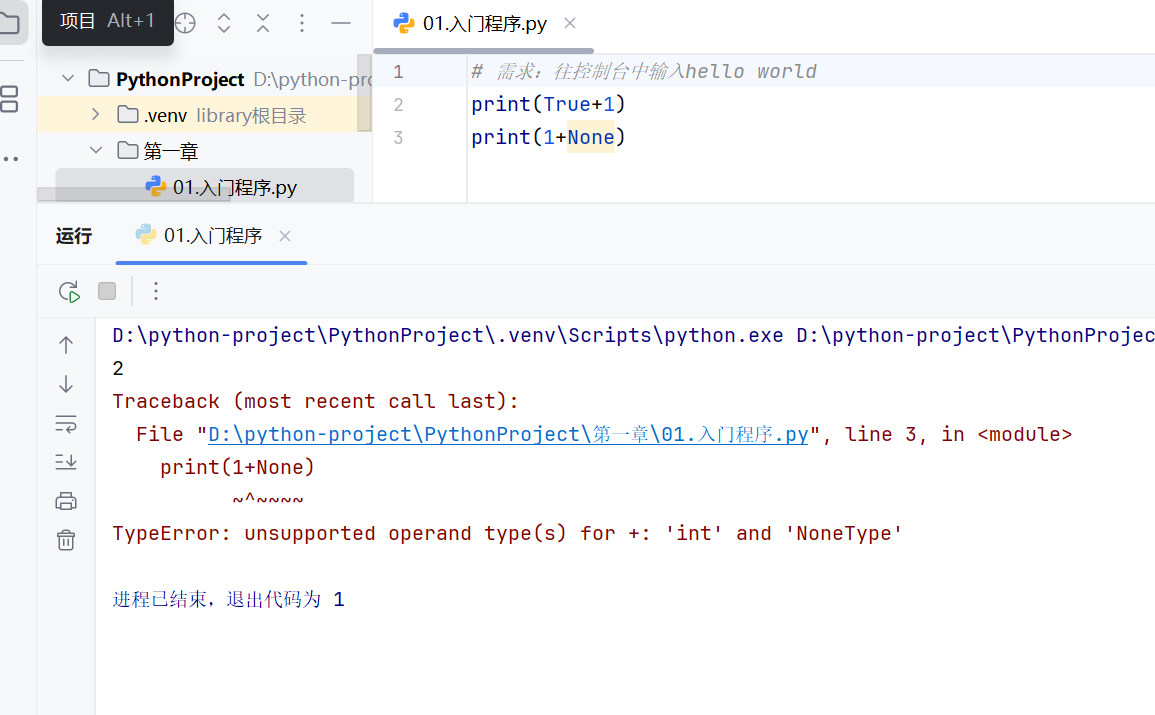
True本质是整型,可以用数字计算

-变量
变量的定义

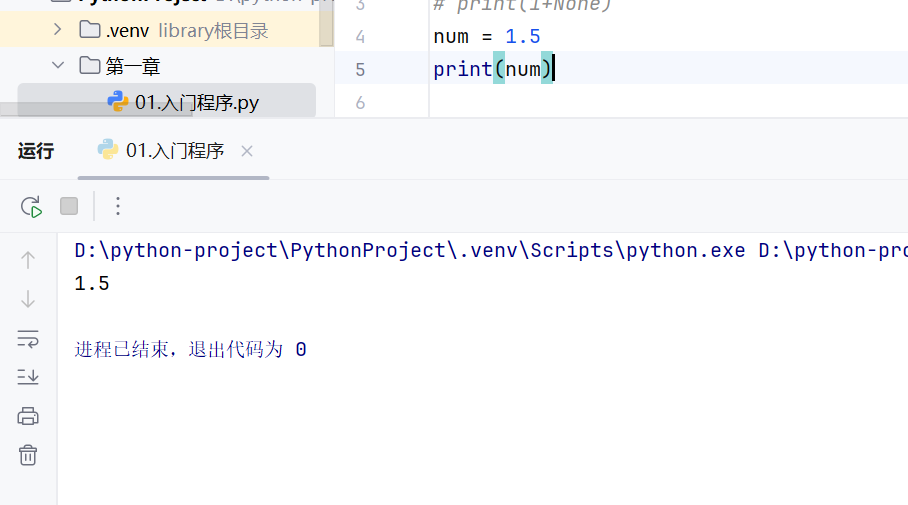
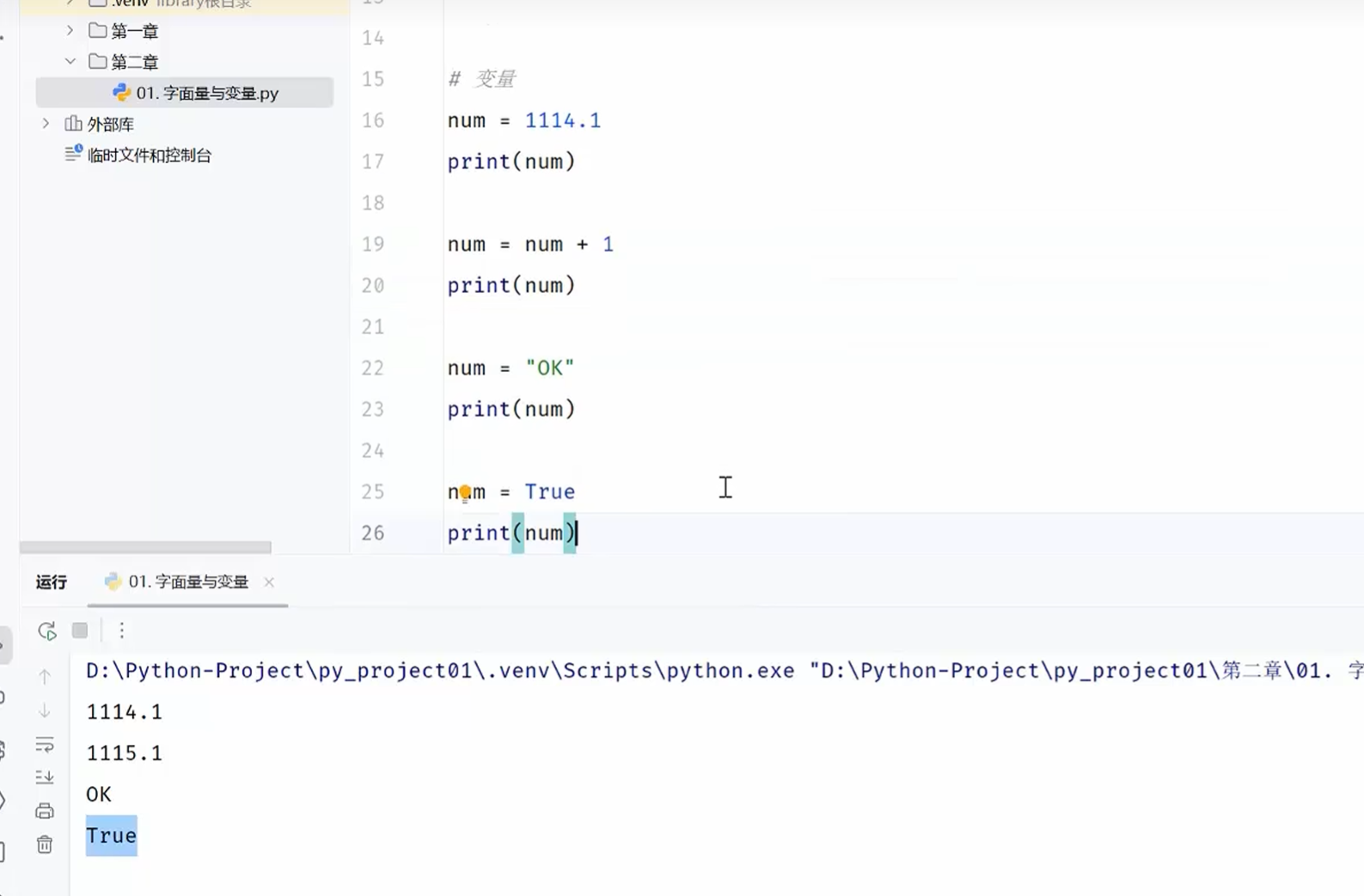
python是动态类型的语言,一个变量可以存储多种不同类型的数据,但是在开发中,我们推荐只存储一种类型的数据
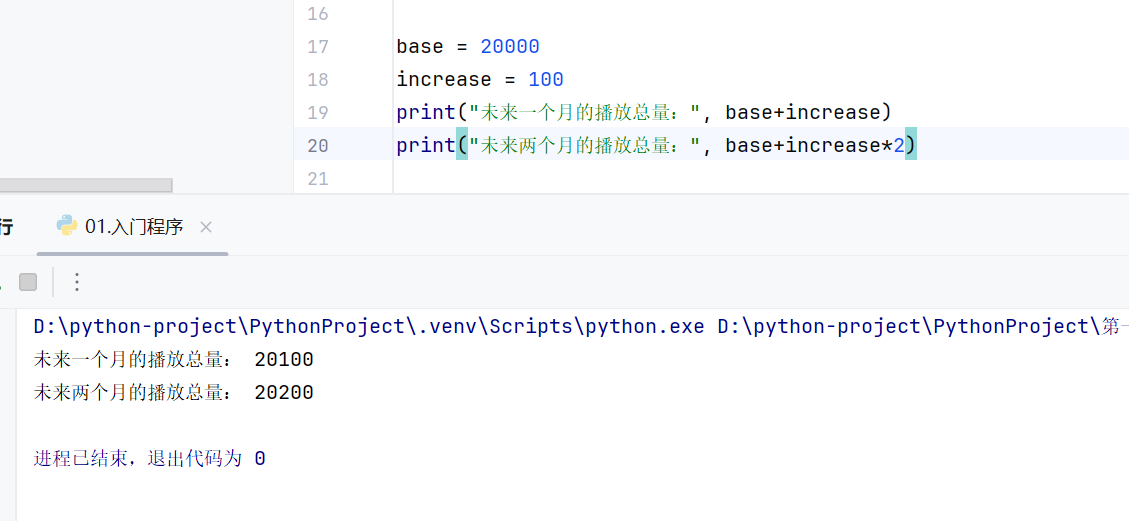
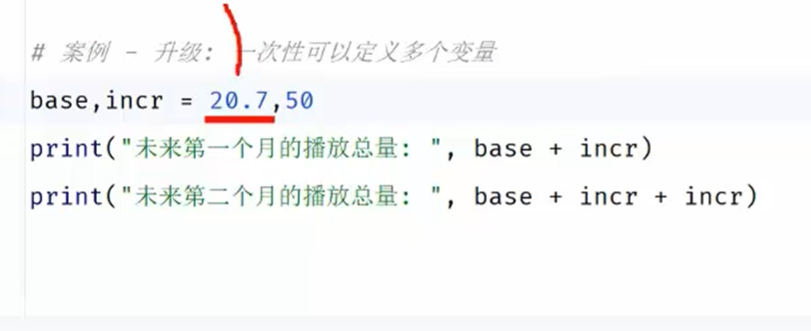
可以一次性定义多个变量
注意事项

-标识符


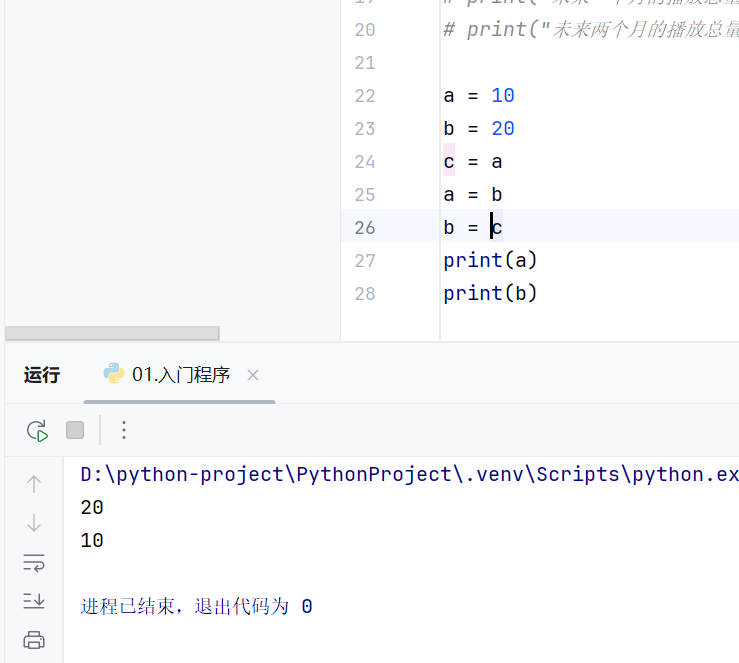
-变量案例(变量交换)
-数据类型

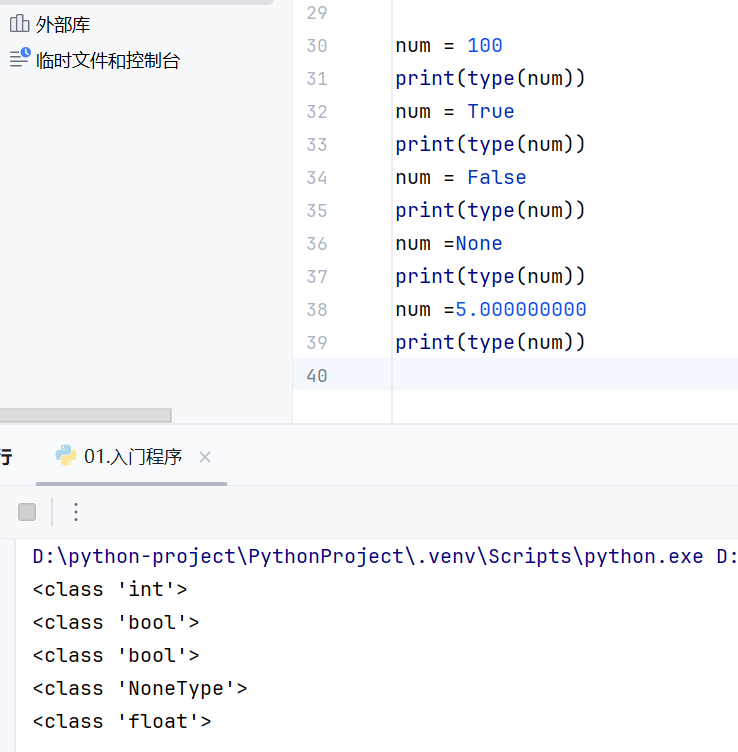
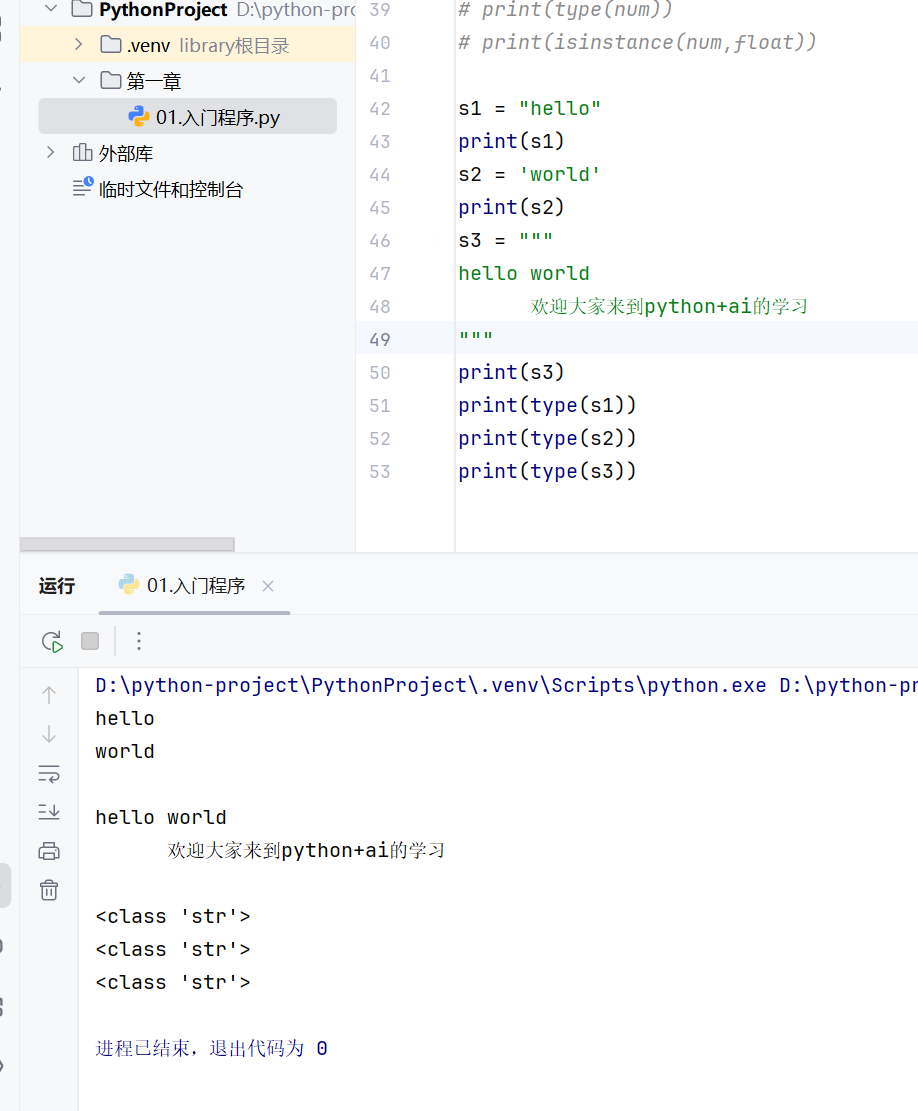
type()判断数据类型,返回数据类型
python中变量本身没有数据类型,type()中获取的数据类型是变量中存储的值的数据类型

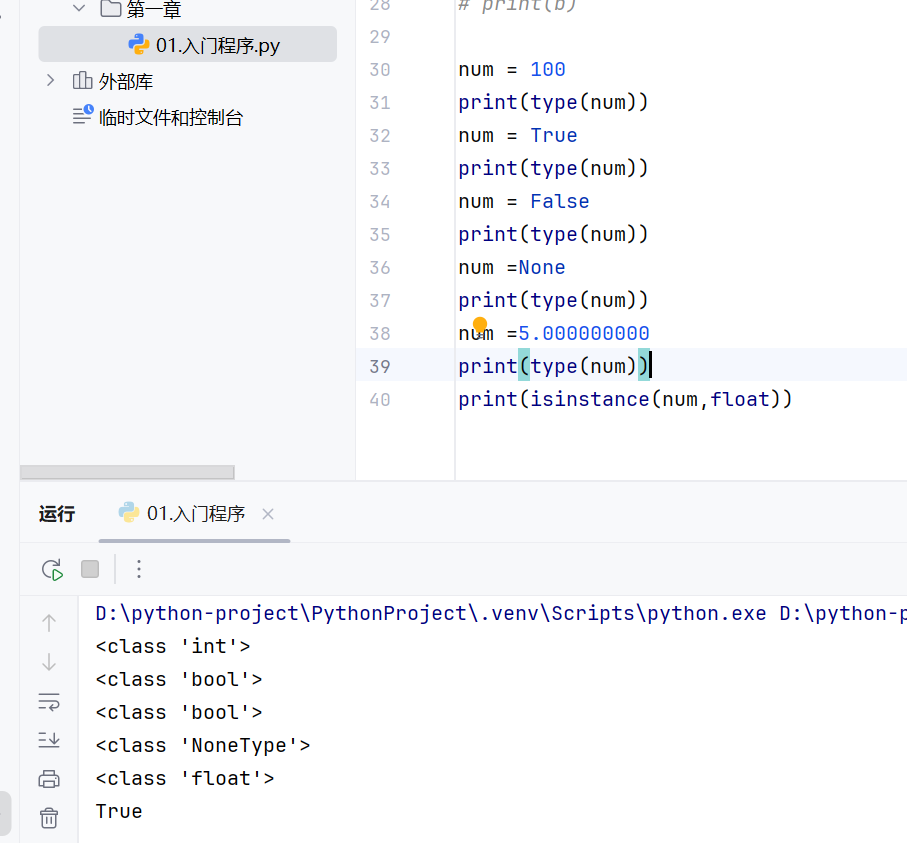
isinstanca() 检查数据是否是指定类型,返回bool值

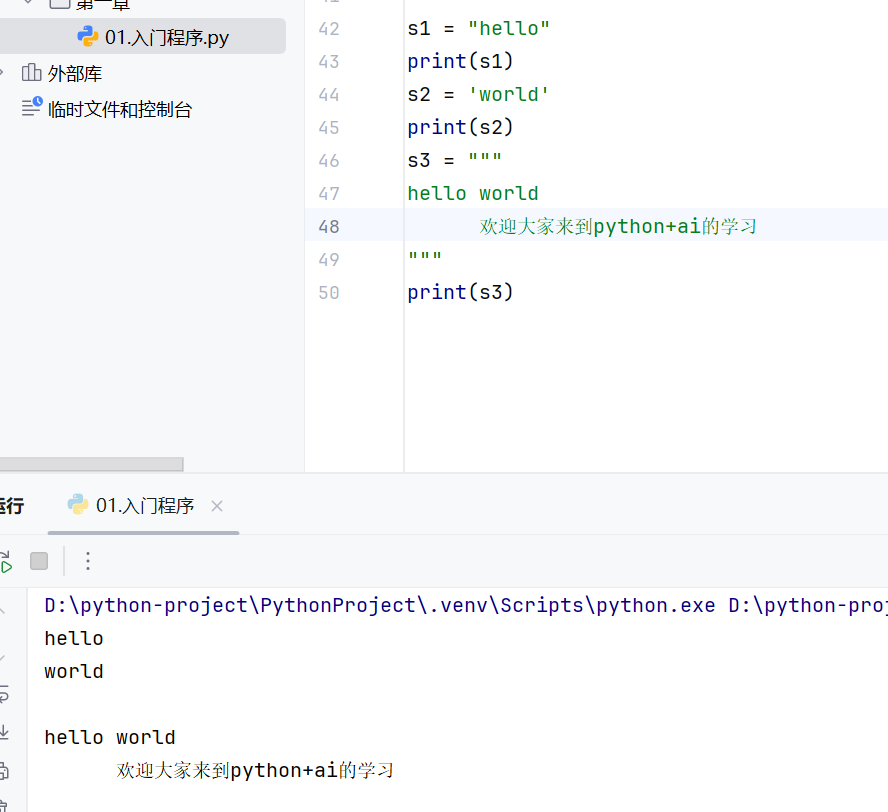
-字符串定义

双引号字符串
双引号和单引号定义的字符串不能换行
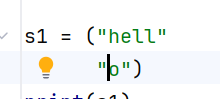
换行之后python会把两个字符串拼接起来
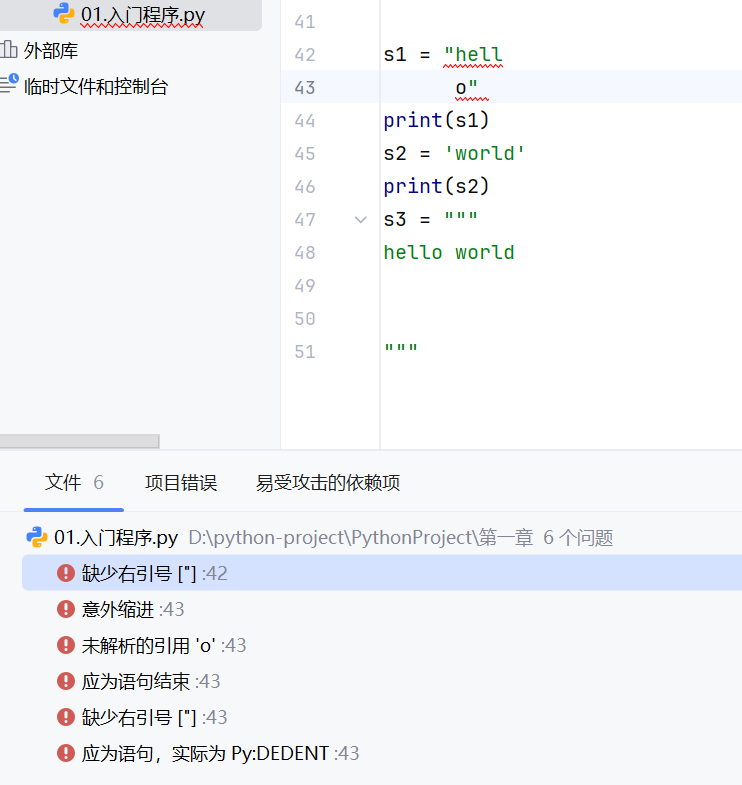
删掉的话会报错
单引号字符串
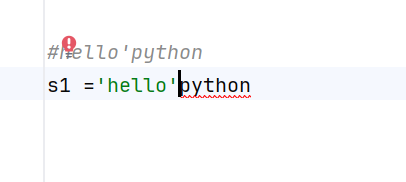
单引号字符串里面不能再出现单引号,因为会把单引号识别成结束符号

要用转义字符\'表示的是'本身
1.使用·转义字符
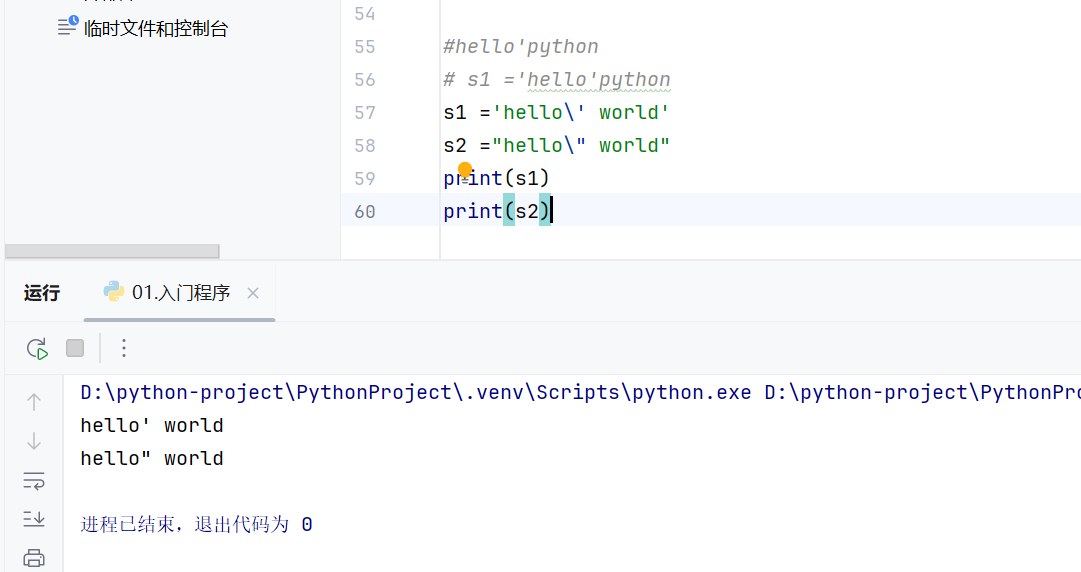
2.在单引号字符串中使用双引号
转义字符
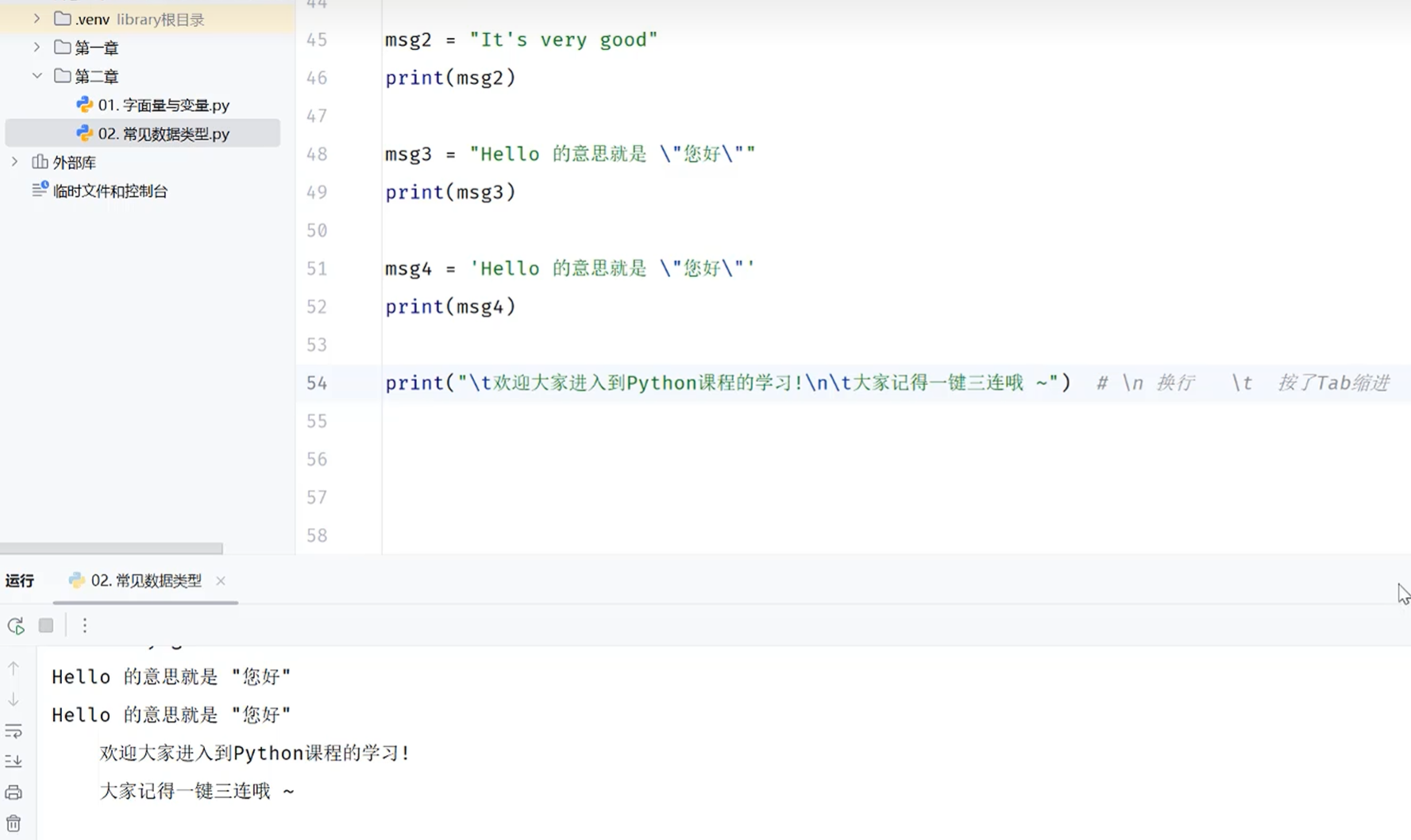
三引号—多行字符串
多行字符串在打印的时候会把三行字符串中的所有内容原封不动的全部打印出来
数据类型
小节

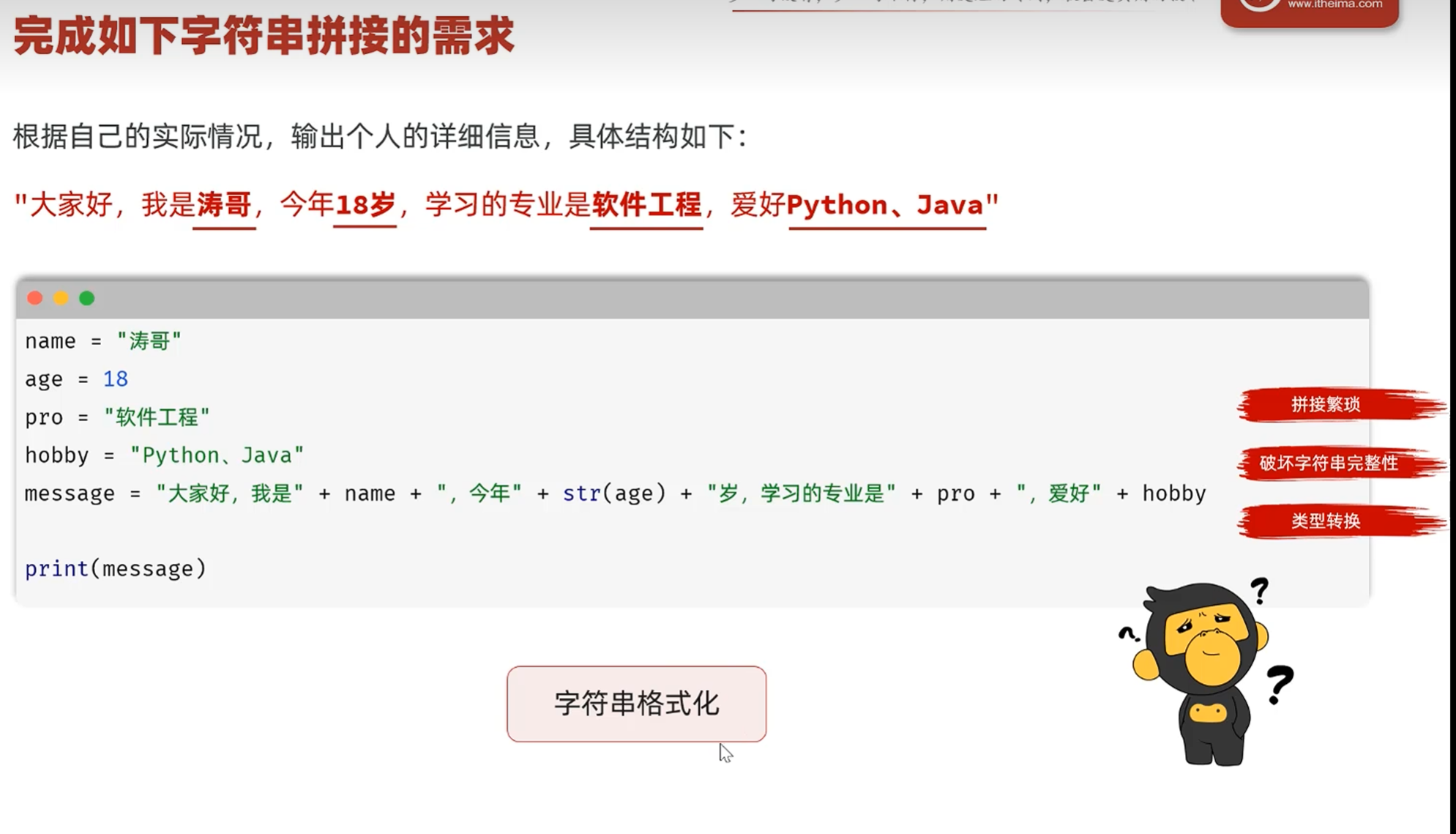
字符串拼接
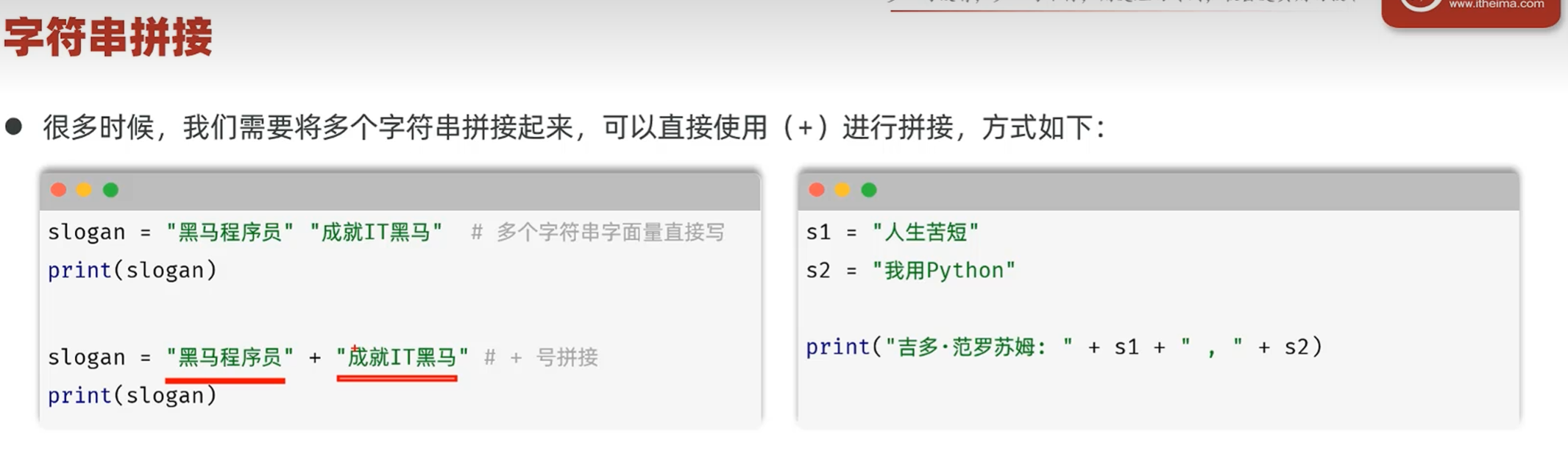
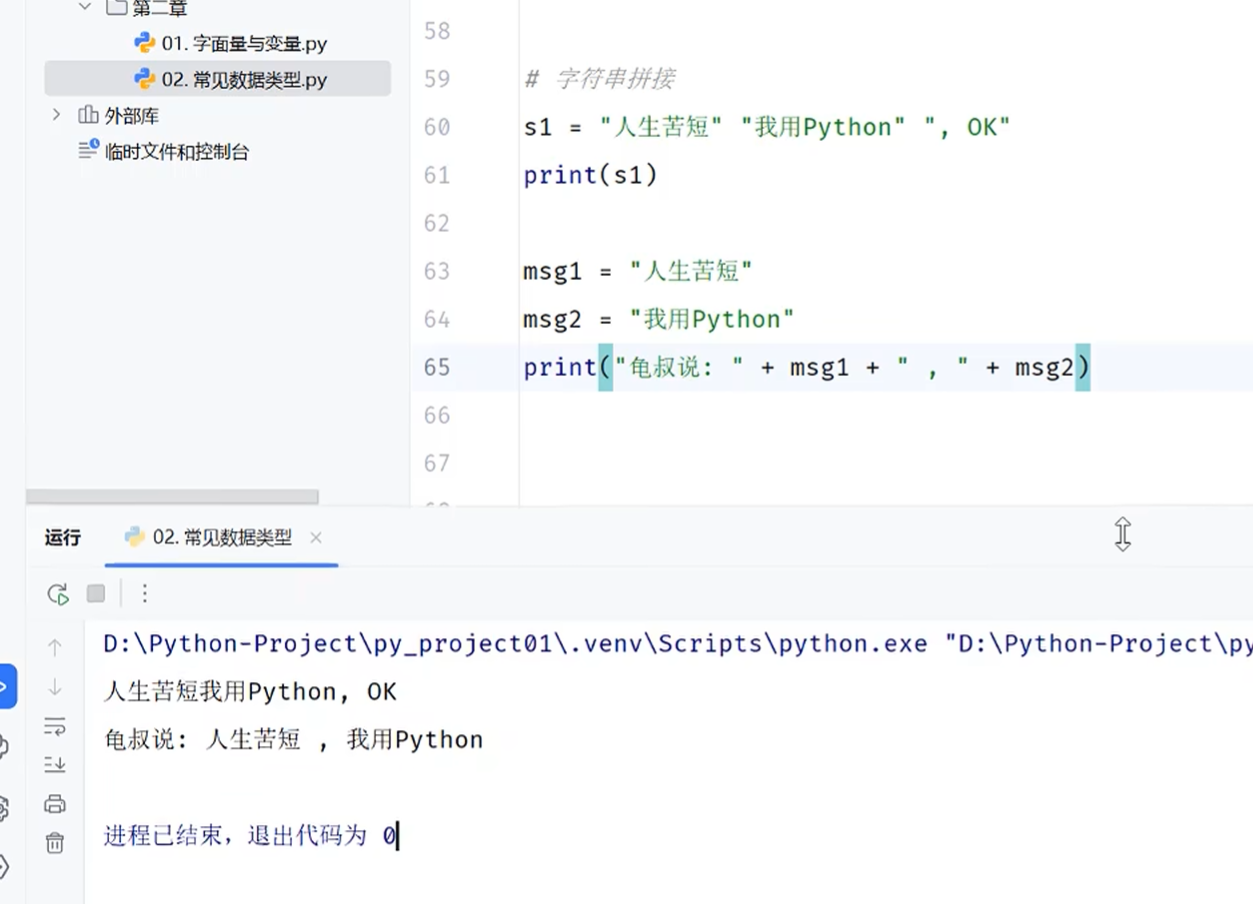

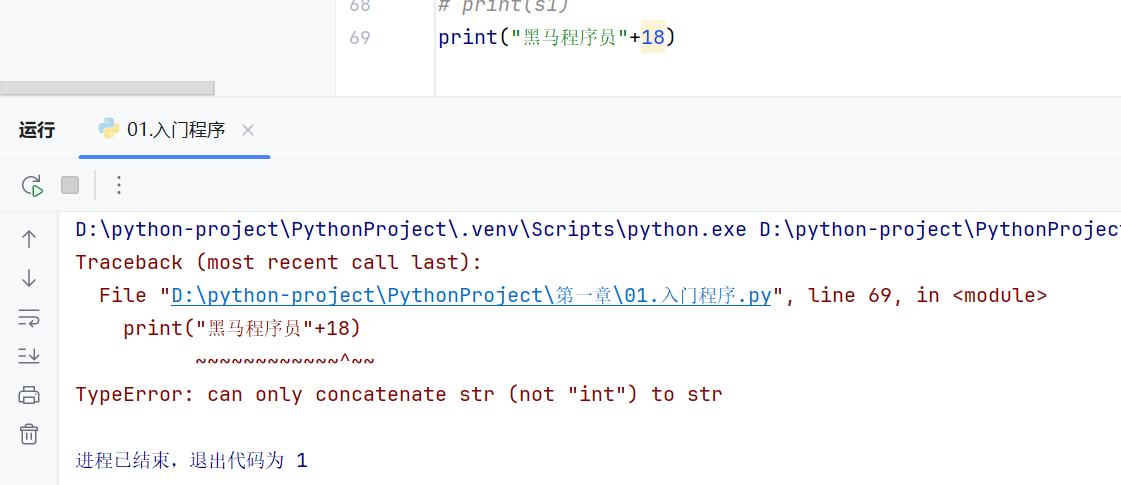
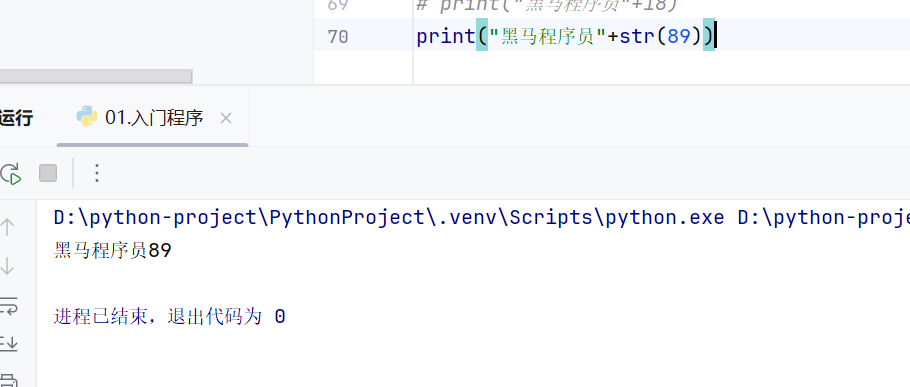
非字符串需要转换为字符串
-字符串的格式化
%占位符
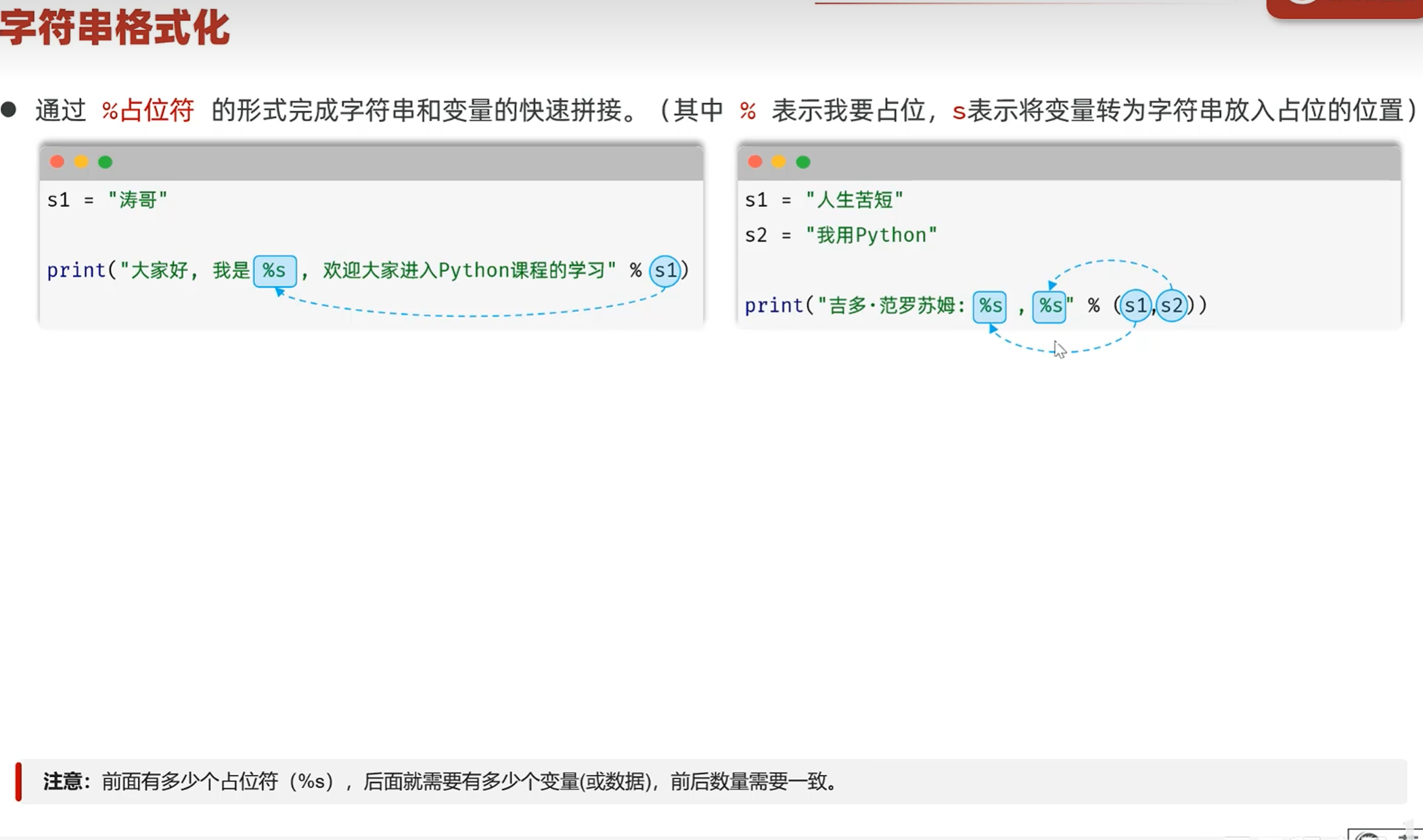
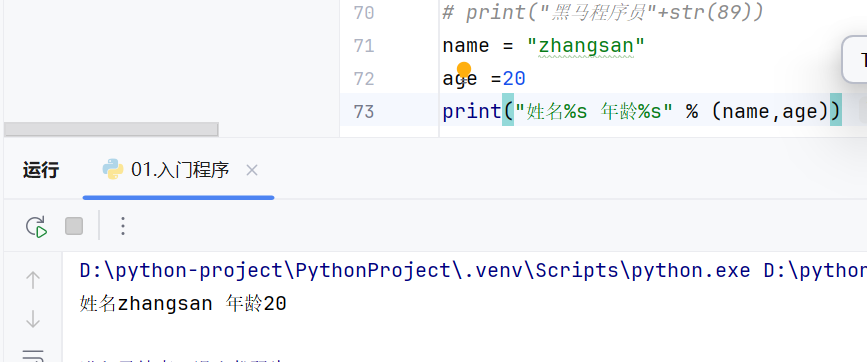
用占位符的方法,不用考虑参数是字符串还是其他类型(不用做类型转换)
f"...{}..."占位符
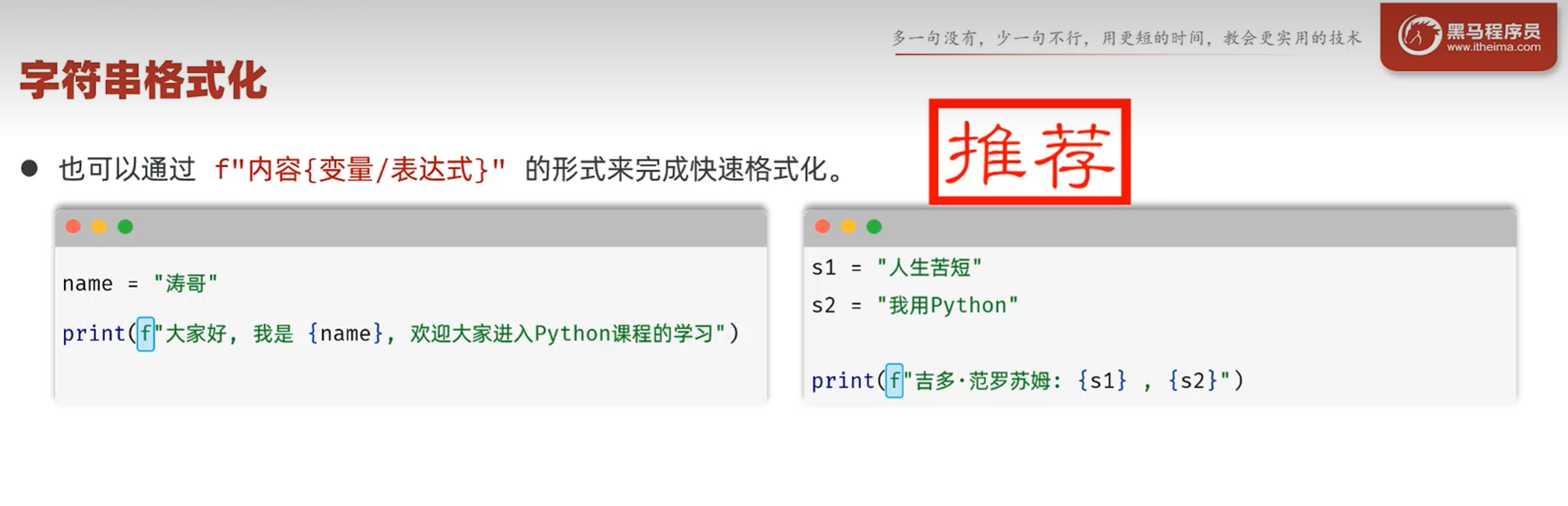
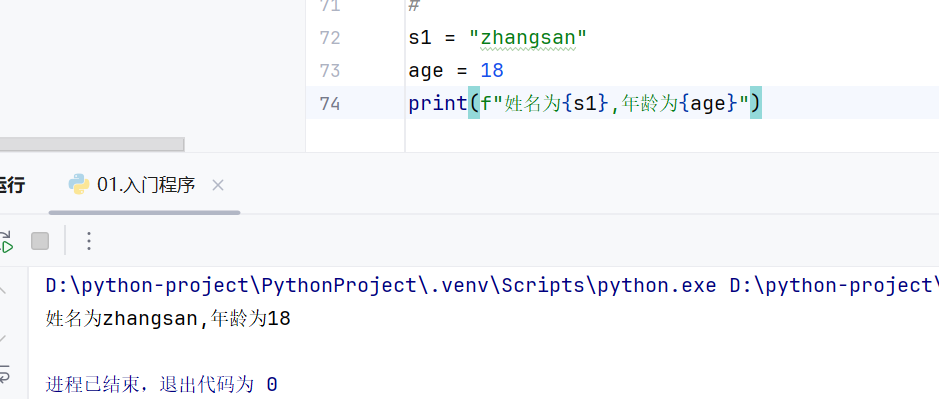
企业开发中的推荐方式,也不用类型转换
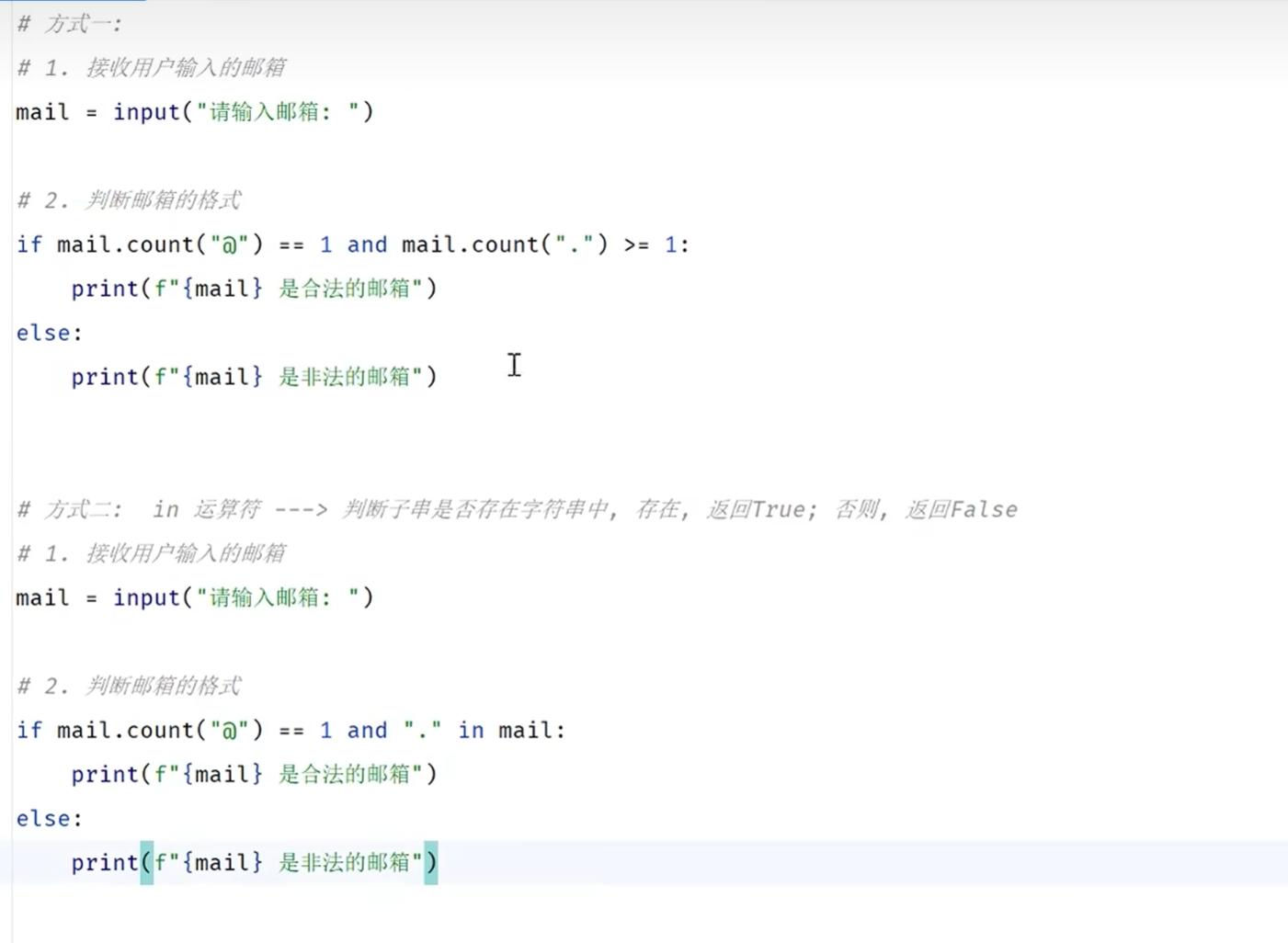
-输入与输出
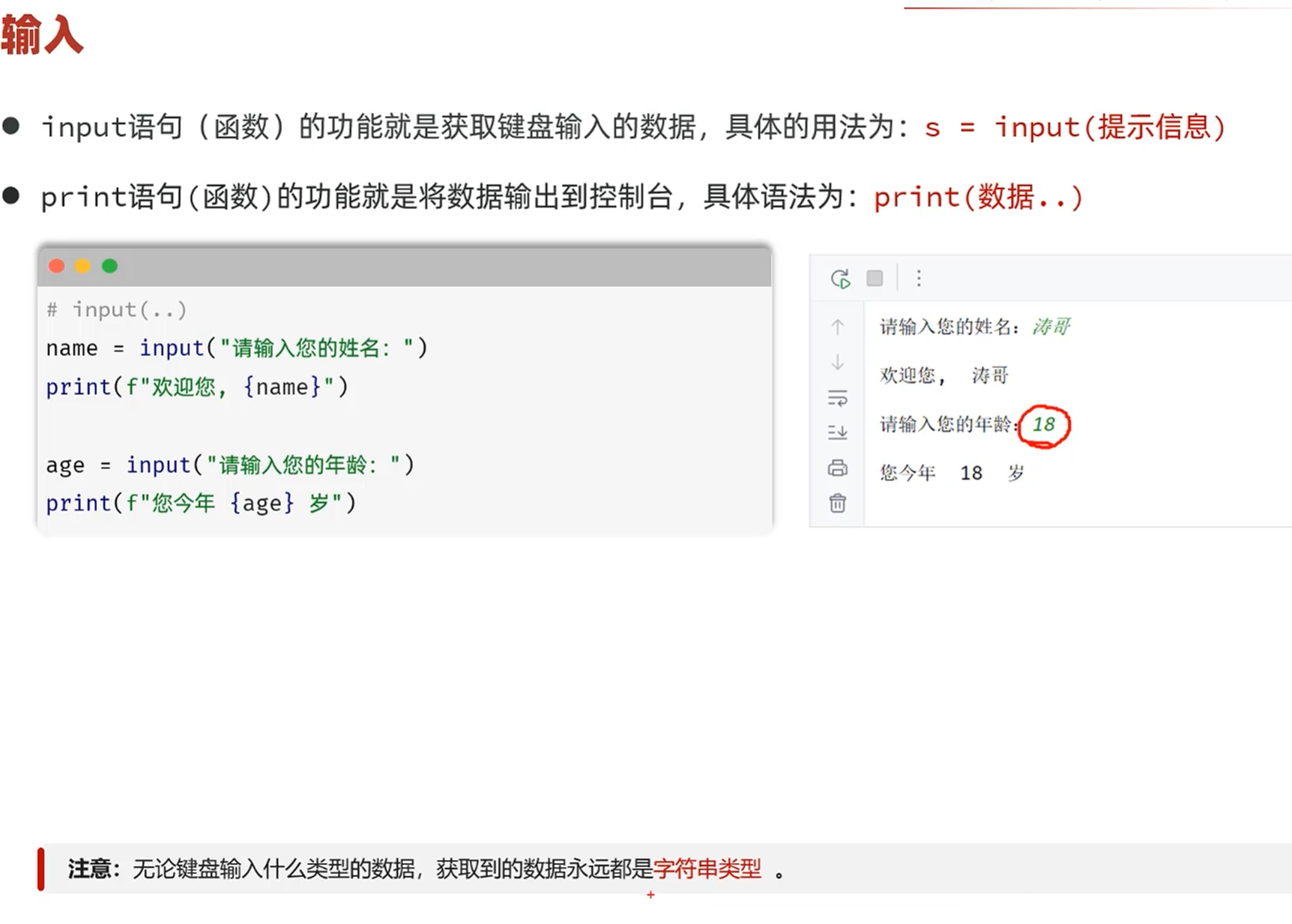
input()接收到的数据类型永远是字符串类型
练习案例
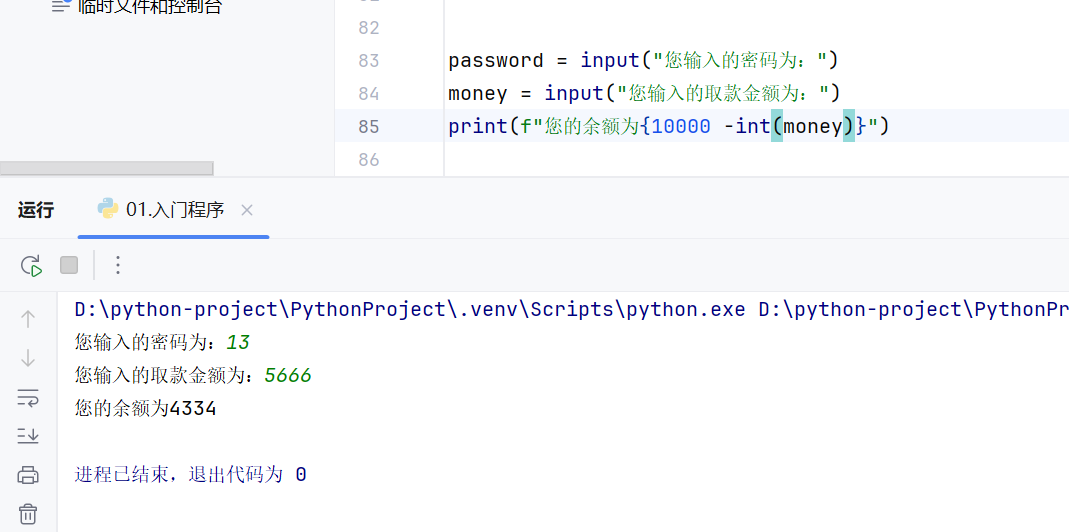

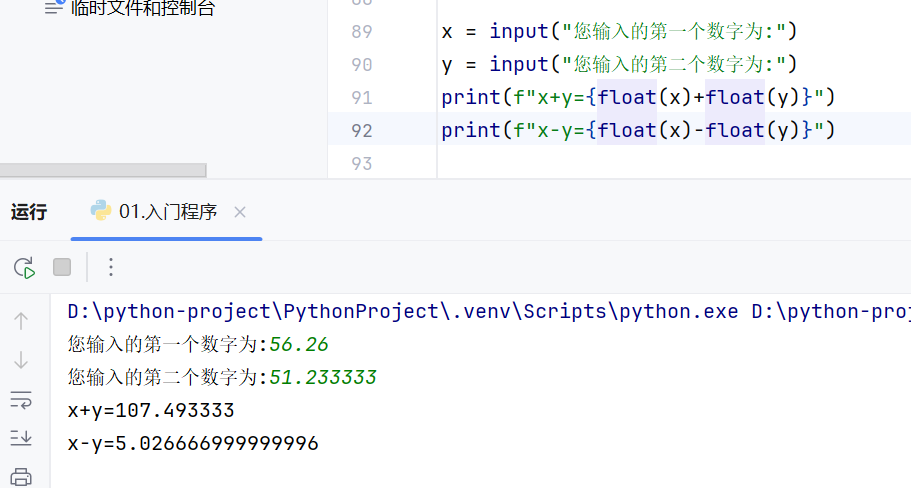
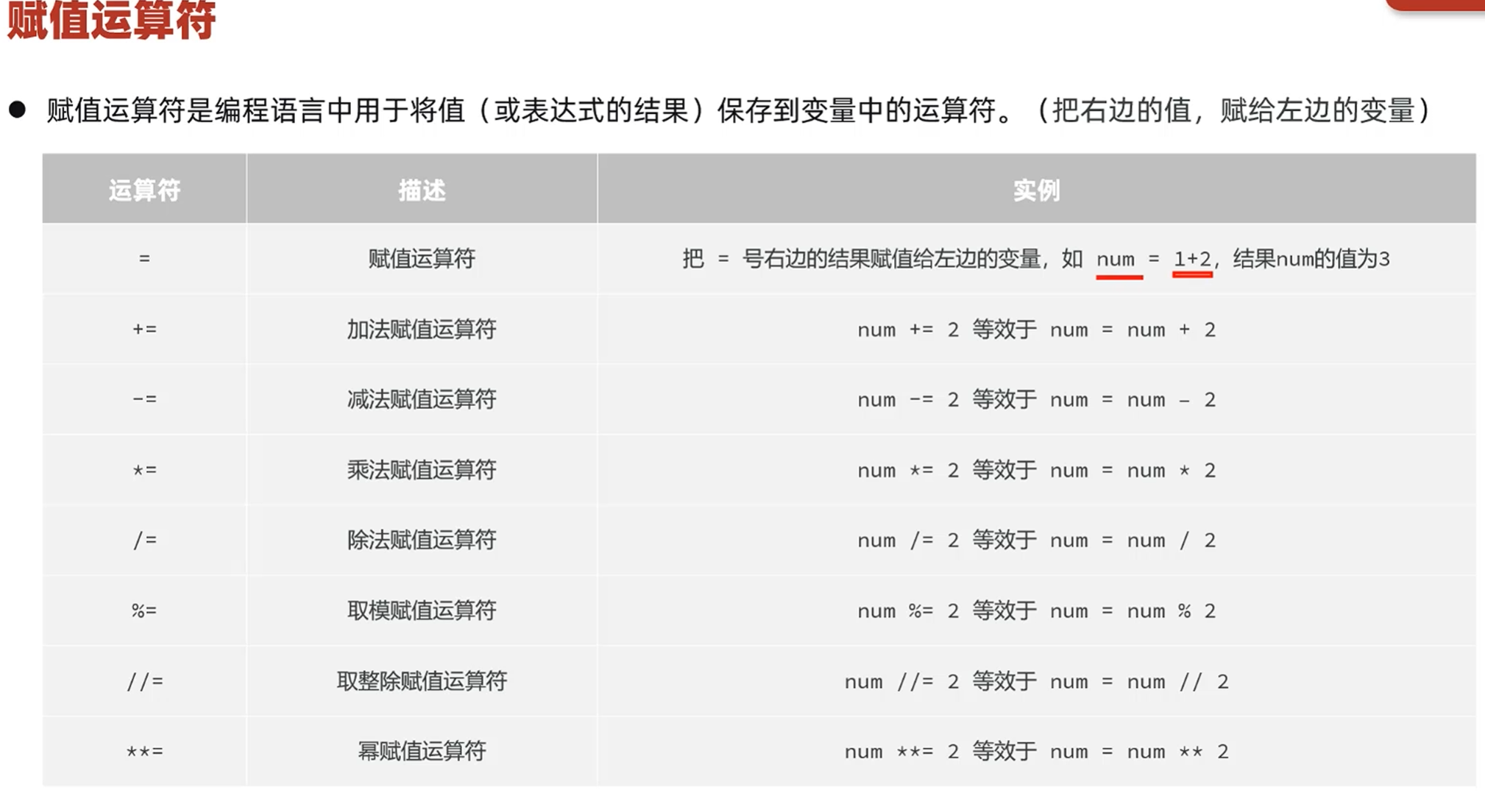
运算符

占位运算符
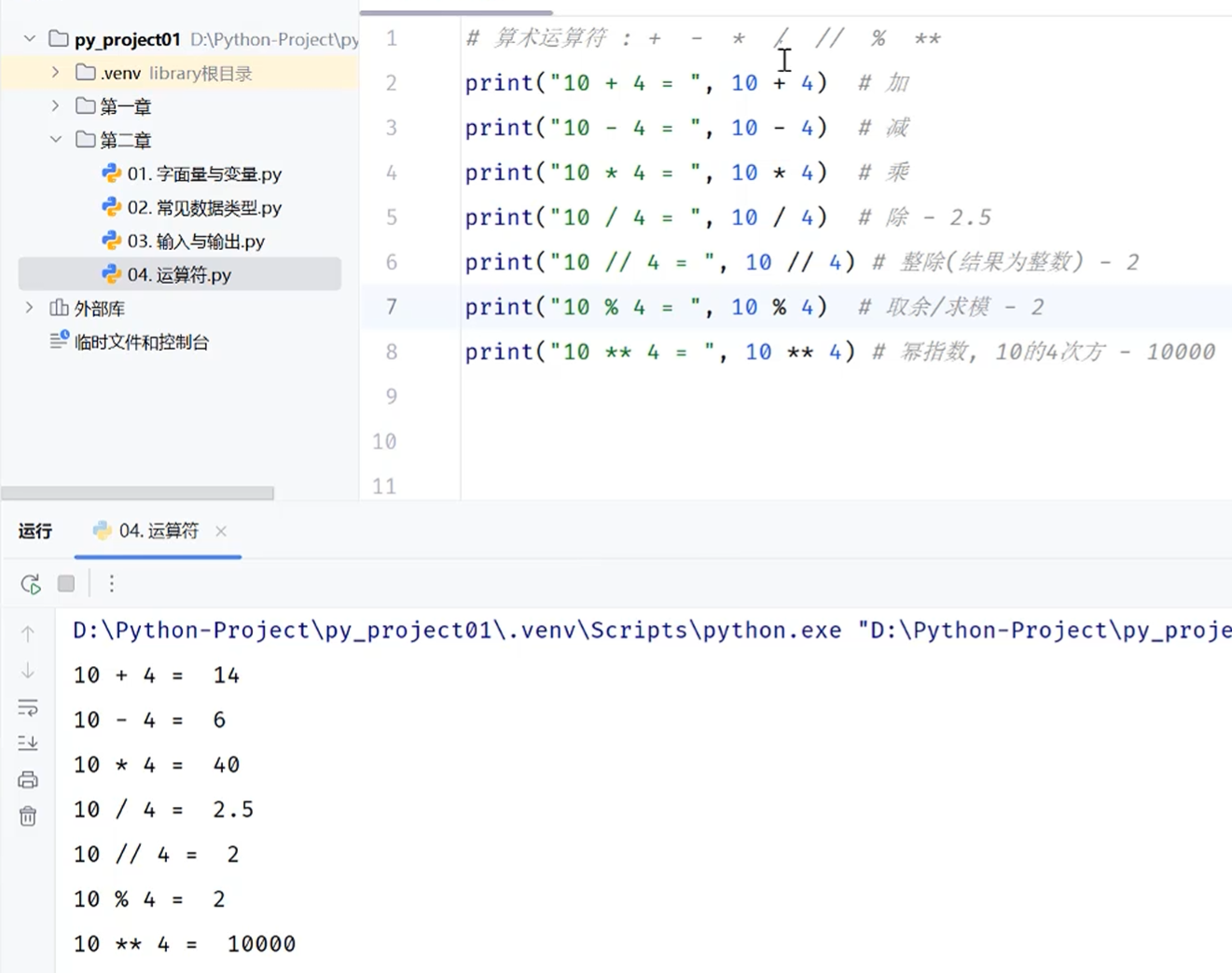
优先级问题

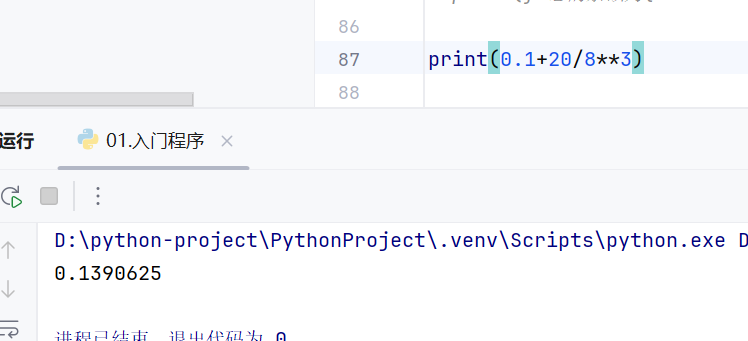
input()输入的内容都是字符串,要计算的话需要手动转换数据类型
精度损失
精度损失:二进制无法完全准确地表示某些小数,所以在进行浮点数字的运算的时候,会出现精度损失

赋值运算符
比较运算符

逻辑运算符

-流程控制语句
-if基础语法
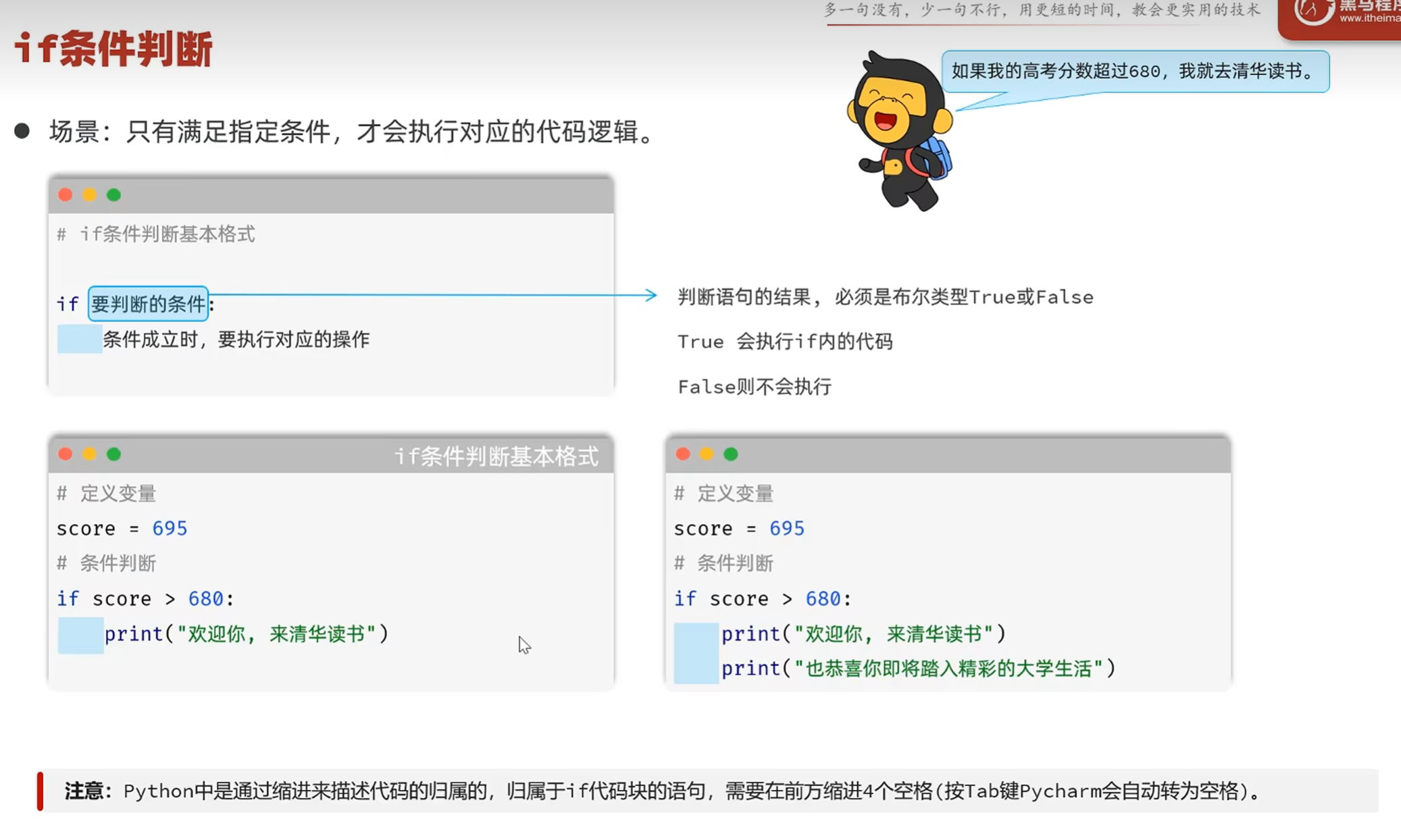
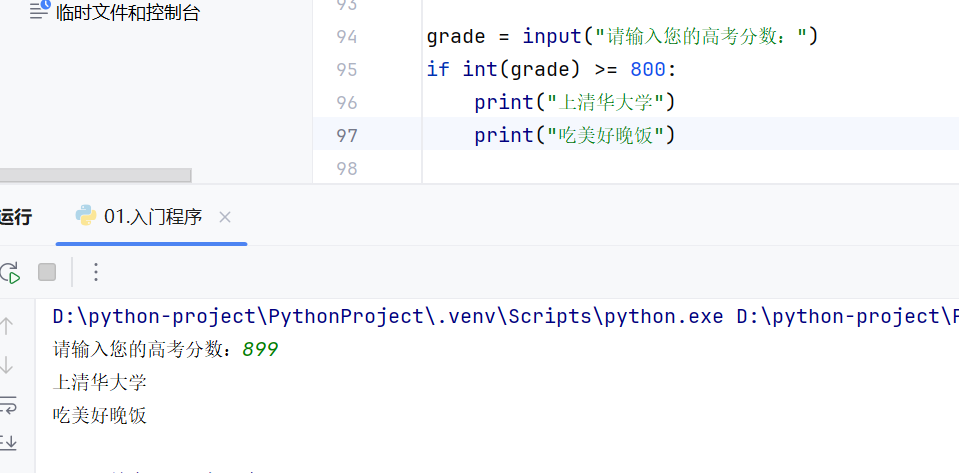

if条件判断-案例
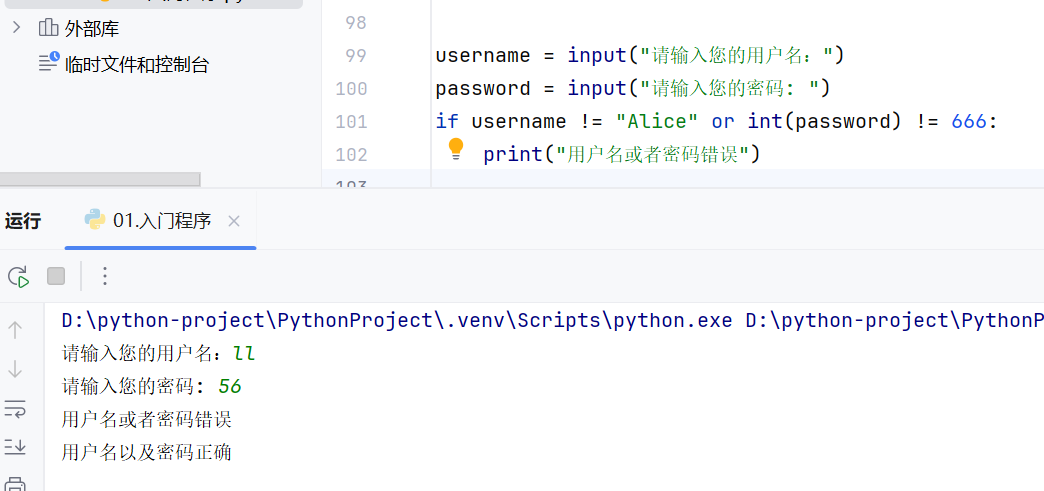
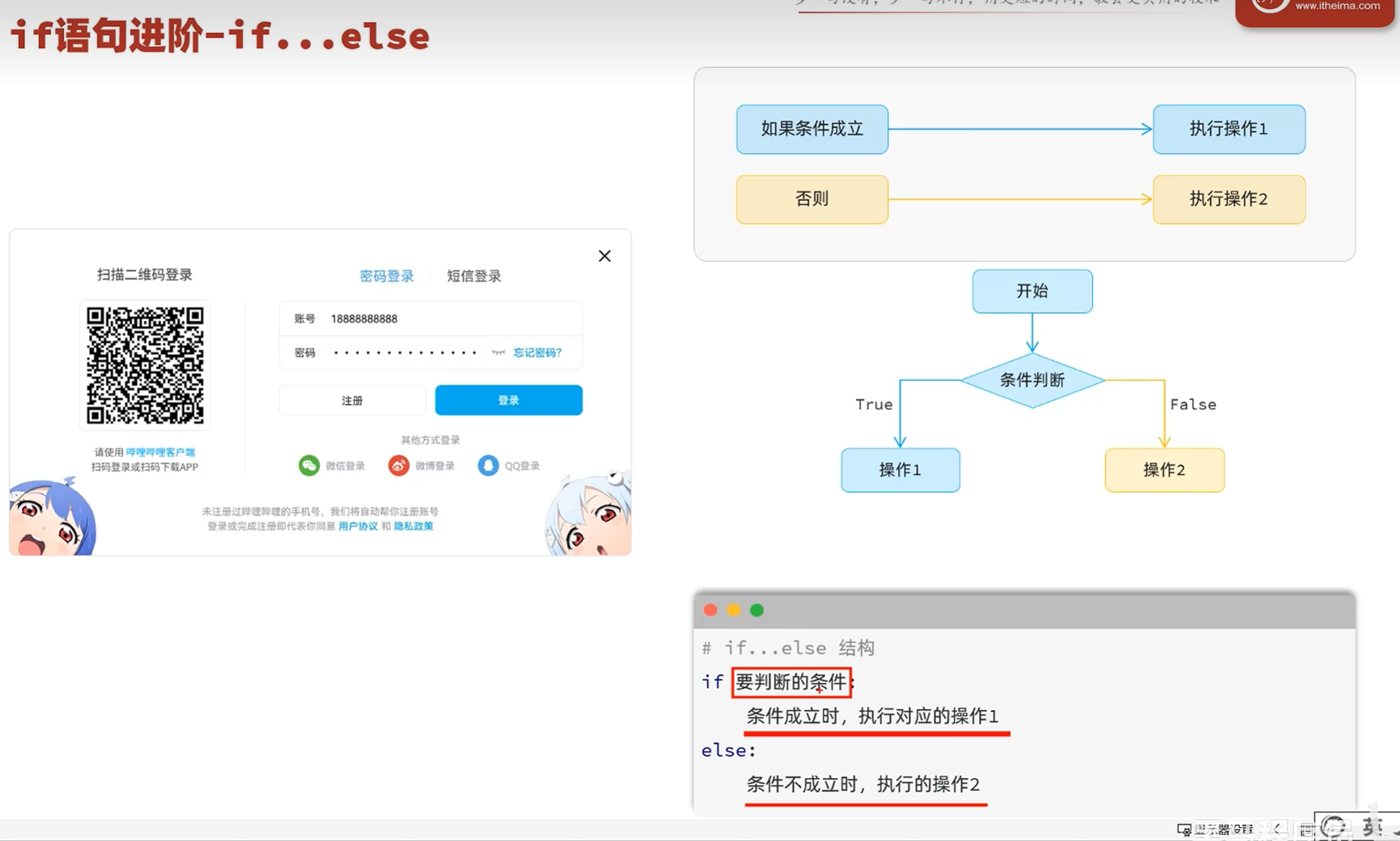
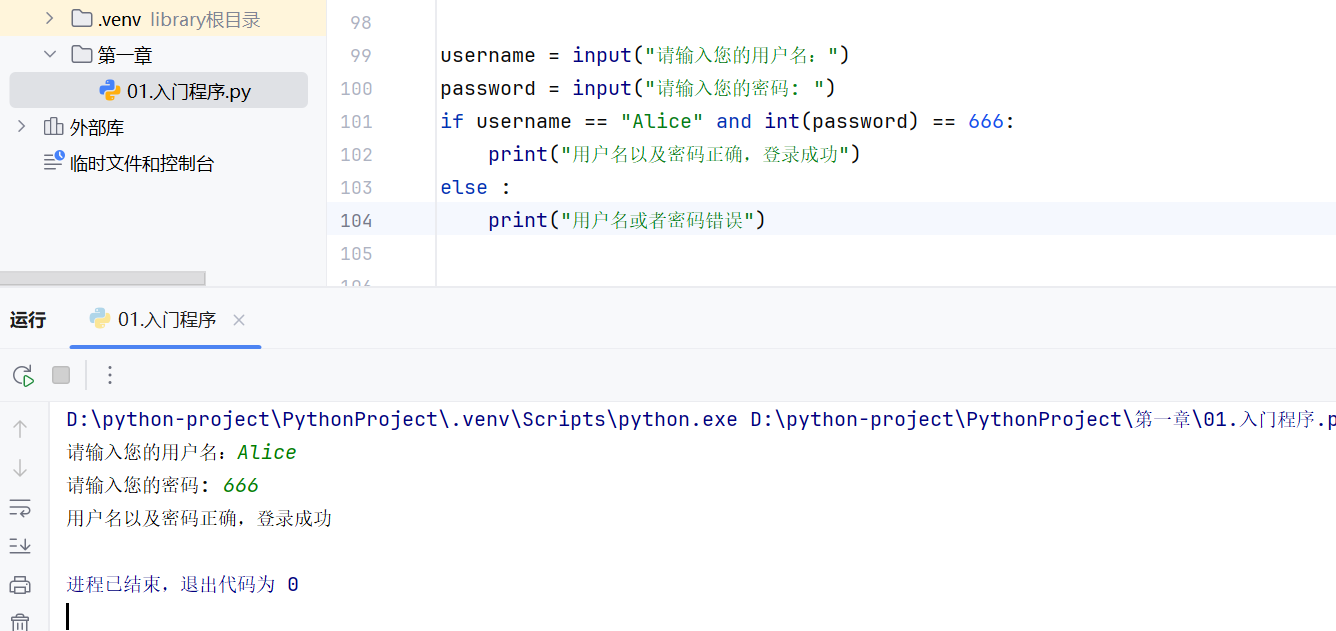
-if进阶(if...else)-案例


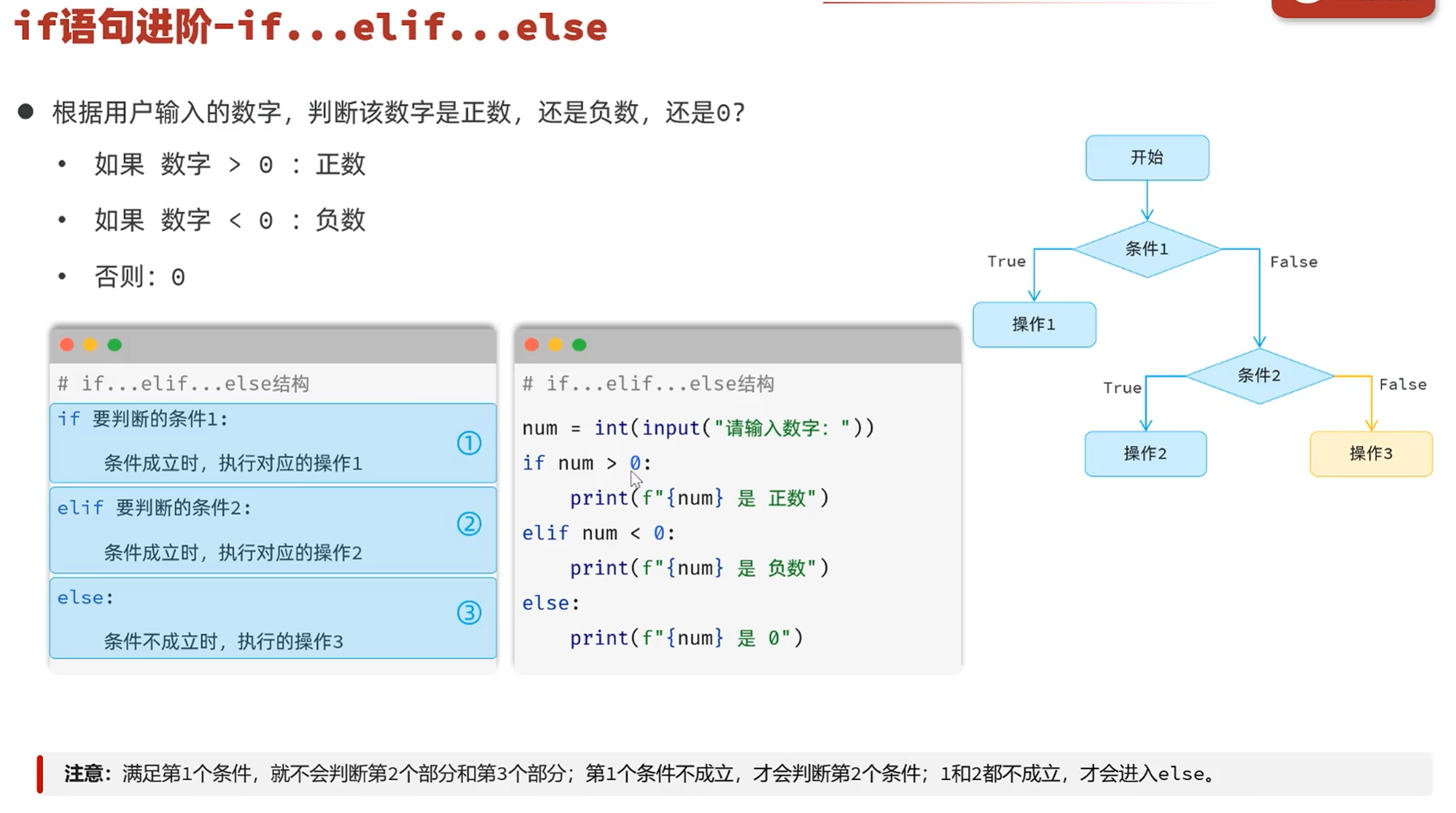
-if进阶(if...elif...else)-案例
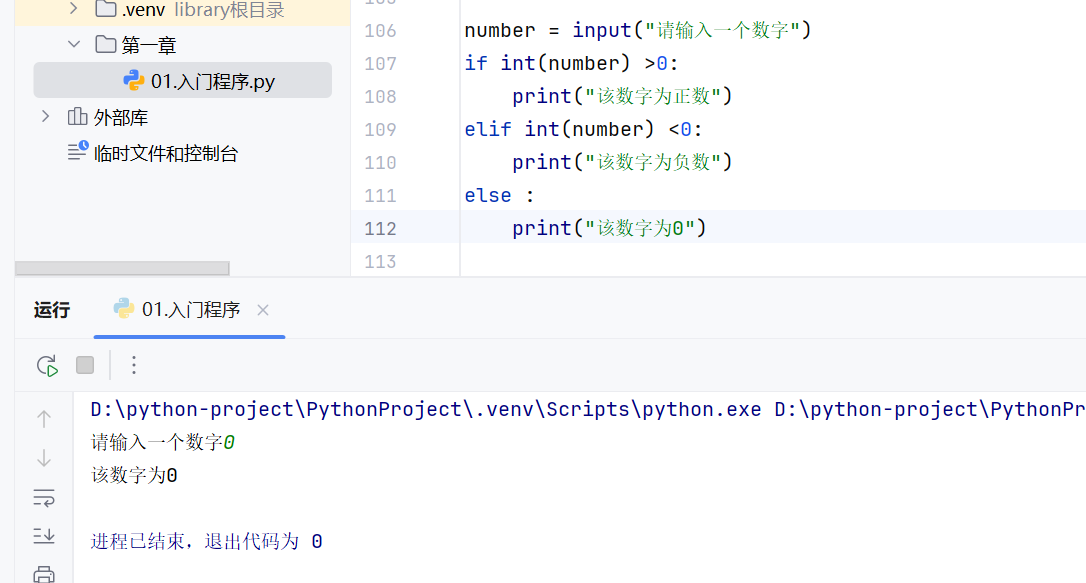
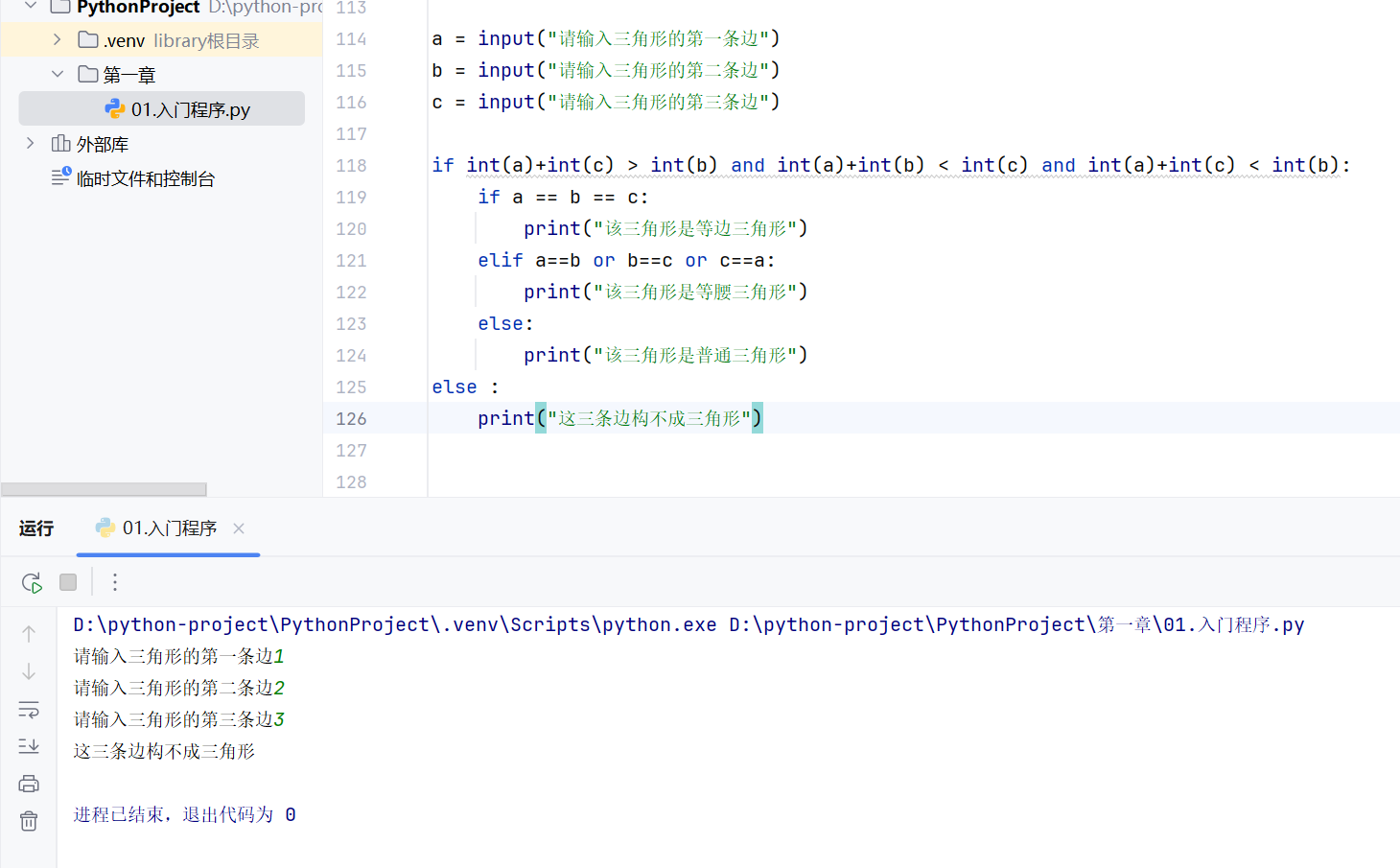
-if语句-综合案例

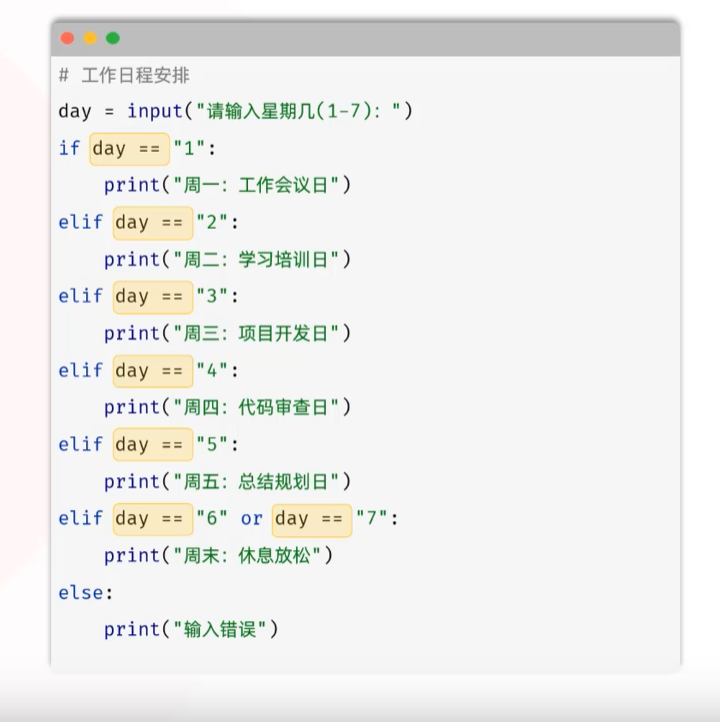
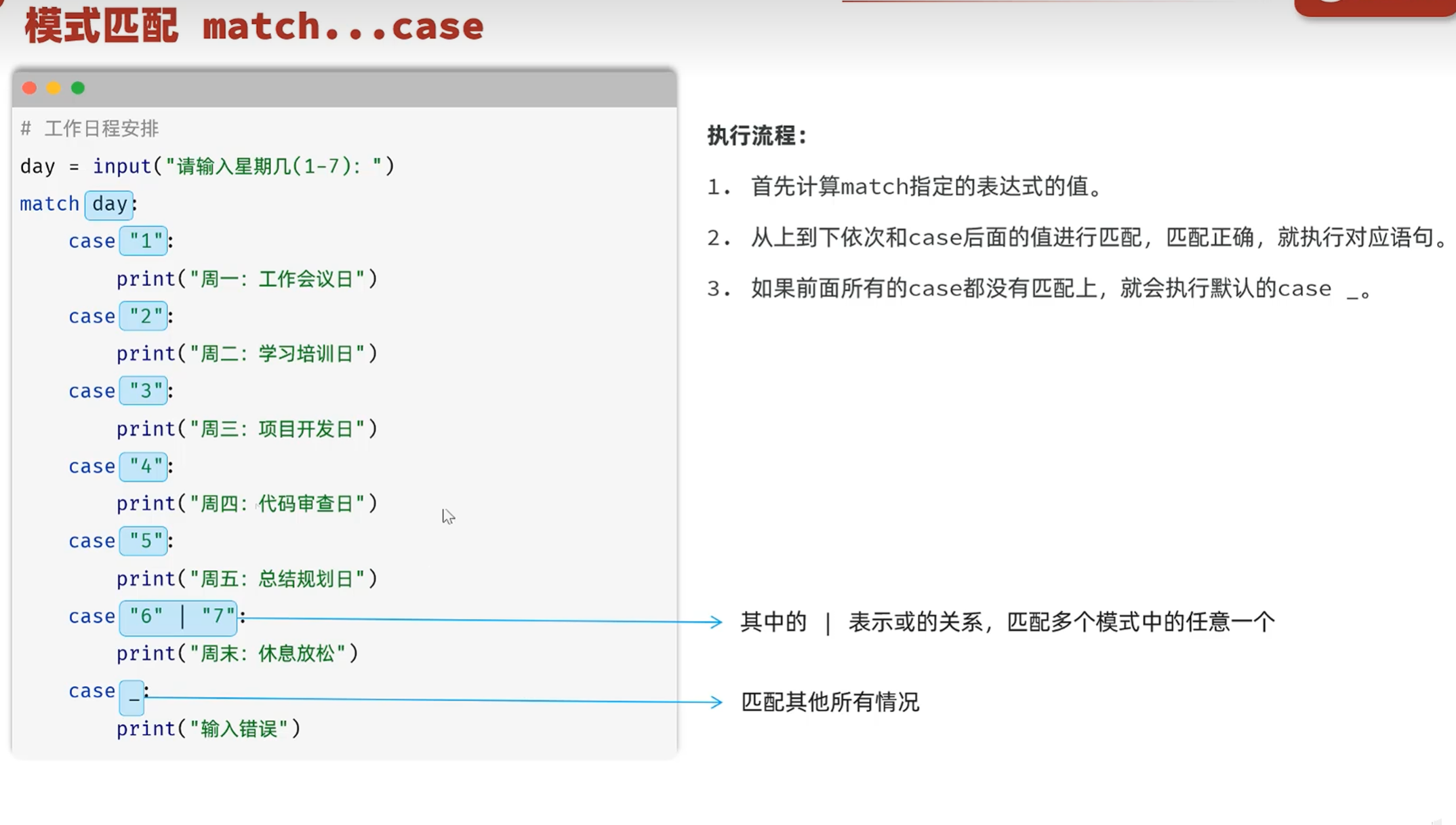
-match模式匹配
if条件判断语句的条件只能是结果为bool值的
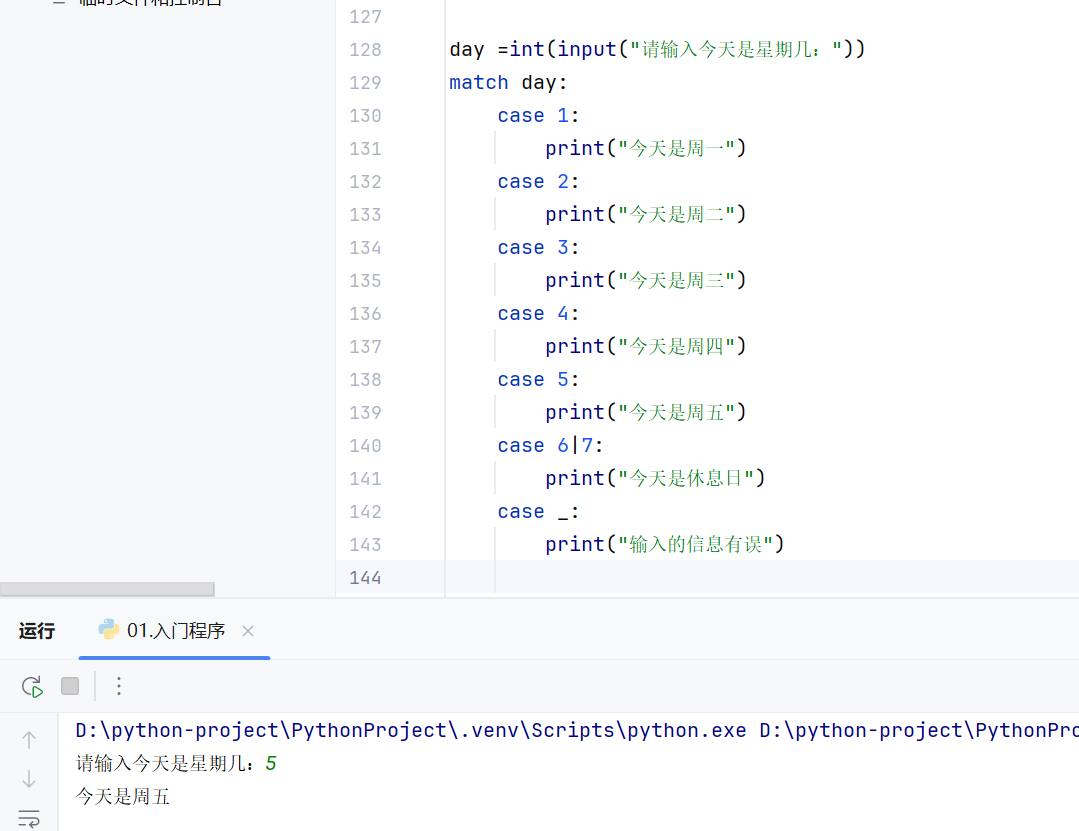
当case后面为整数时,判断输入的day,如果day为字符串类型的,就会输出"输入的信息有误"
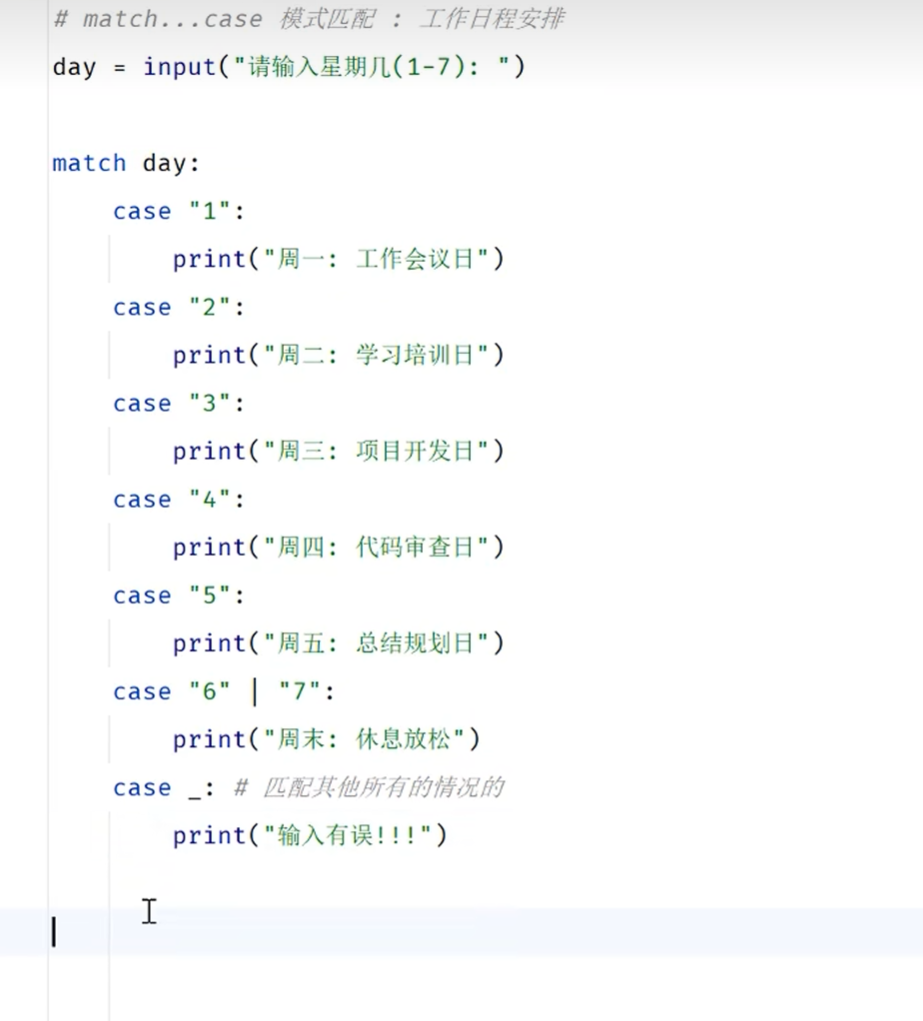
case后面的是字符串类型的时候,当day为字符串的时候就可以正常判断
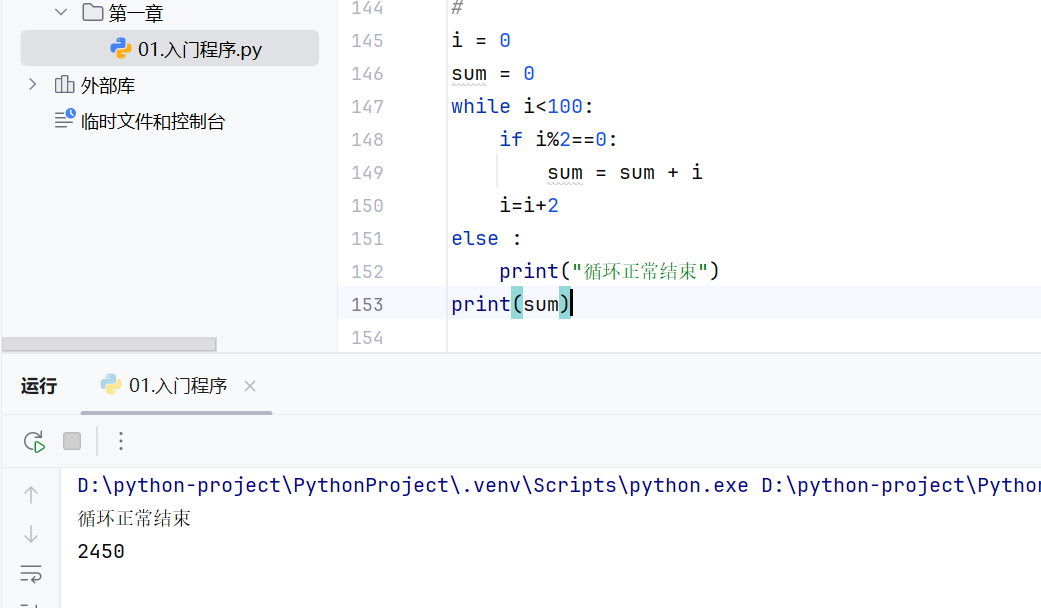
-while循环语法
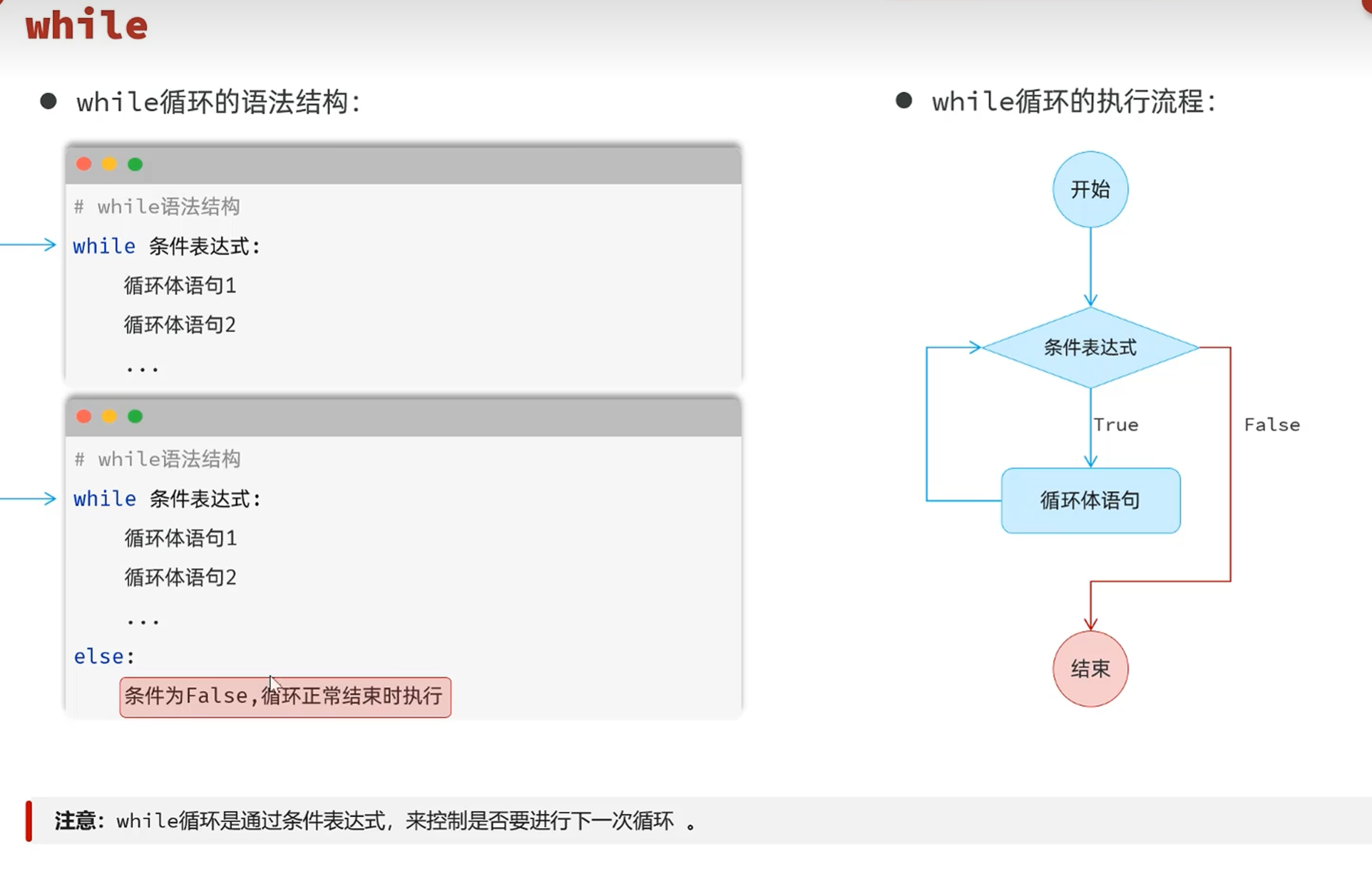

while循环还可以加上else:
用于循环正常结束时执行的操作
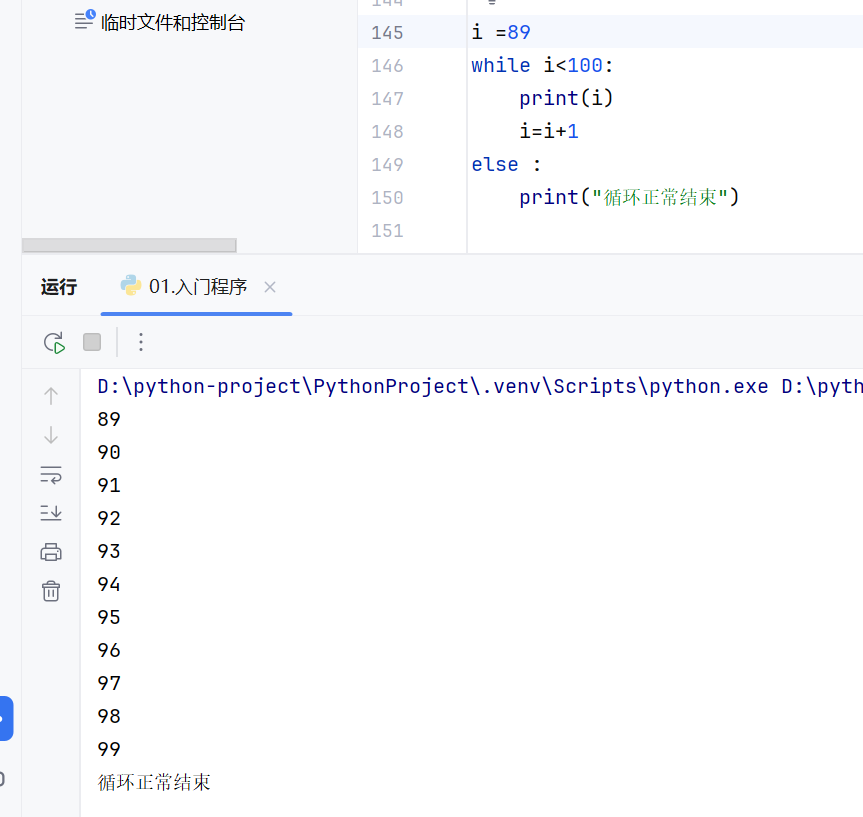
-while循环-案例
-for循环-语法
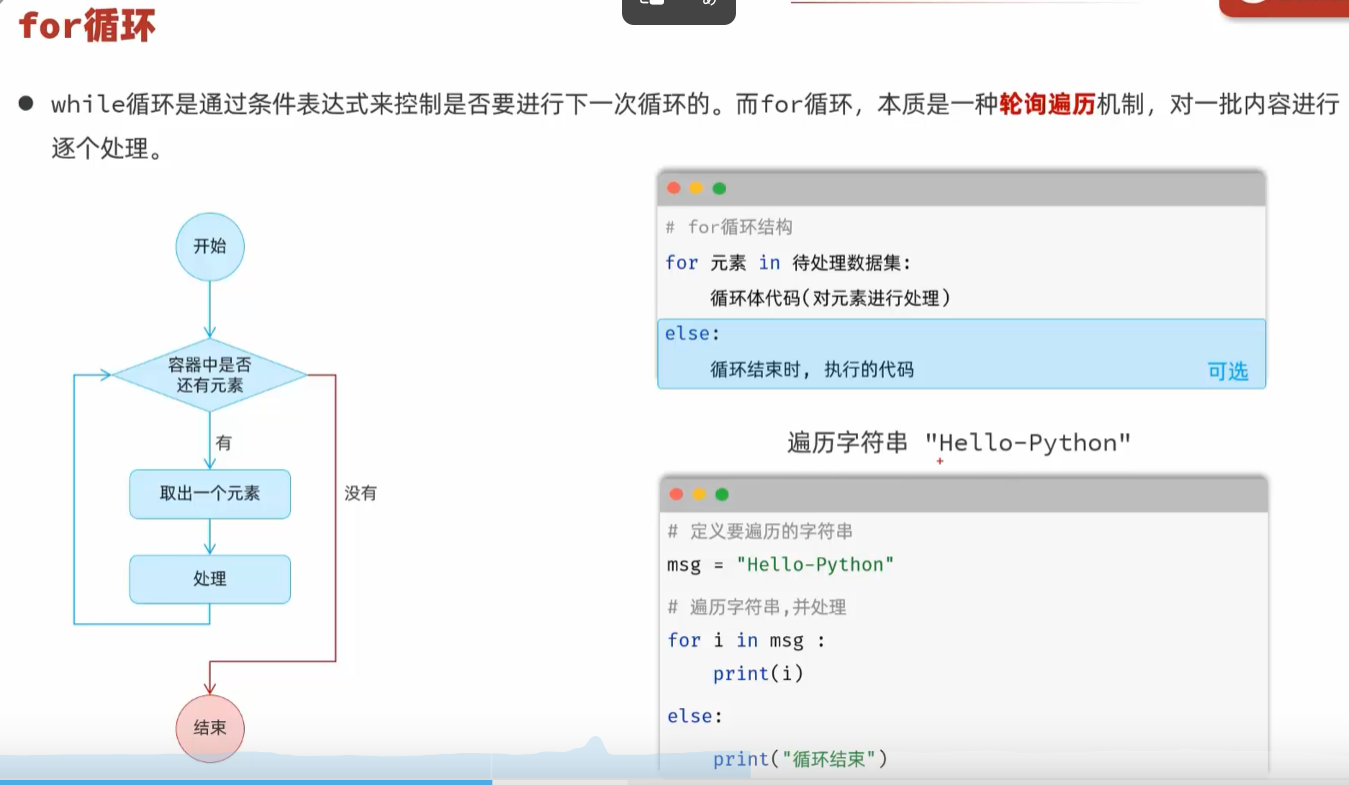
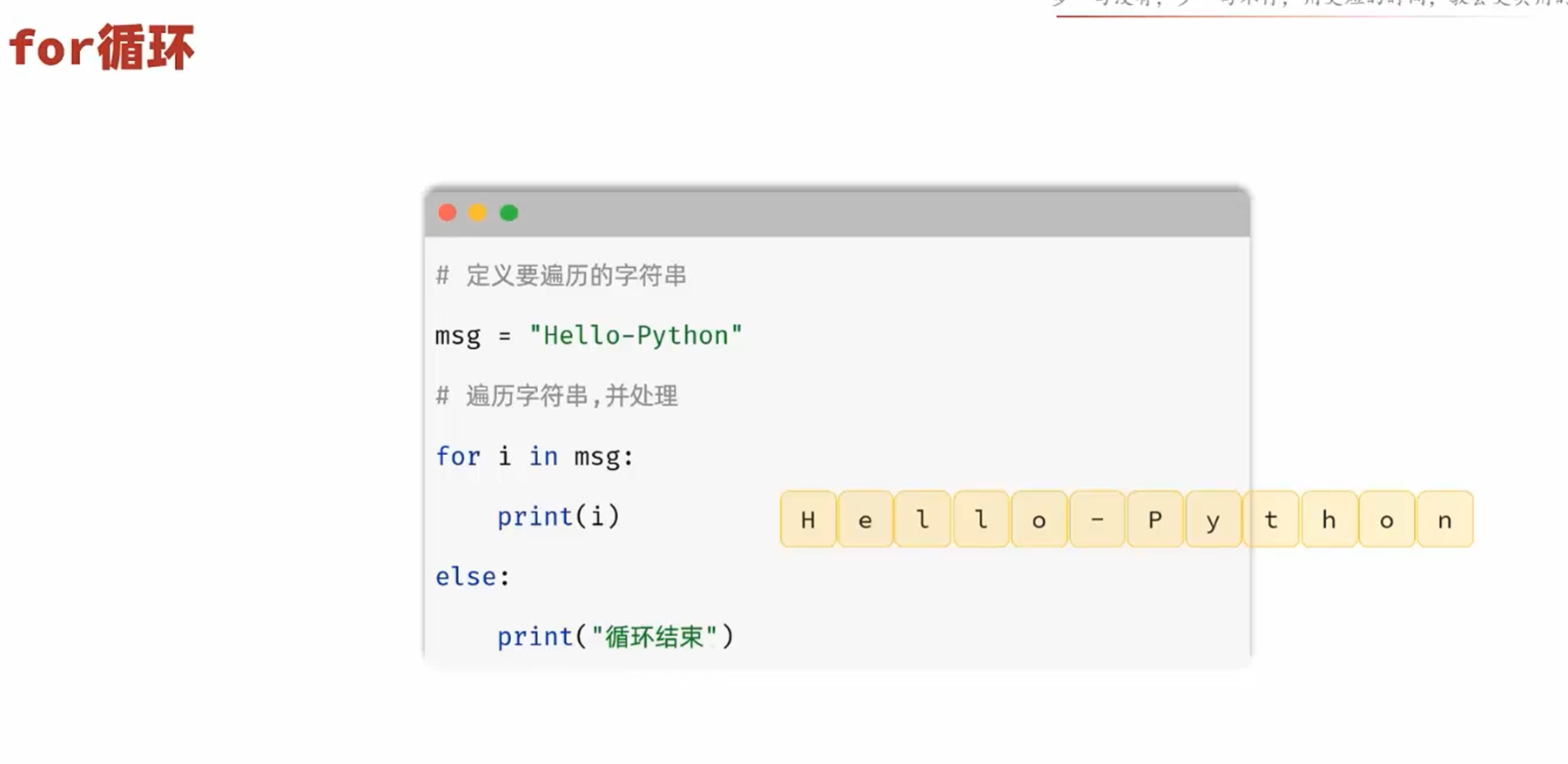
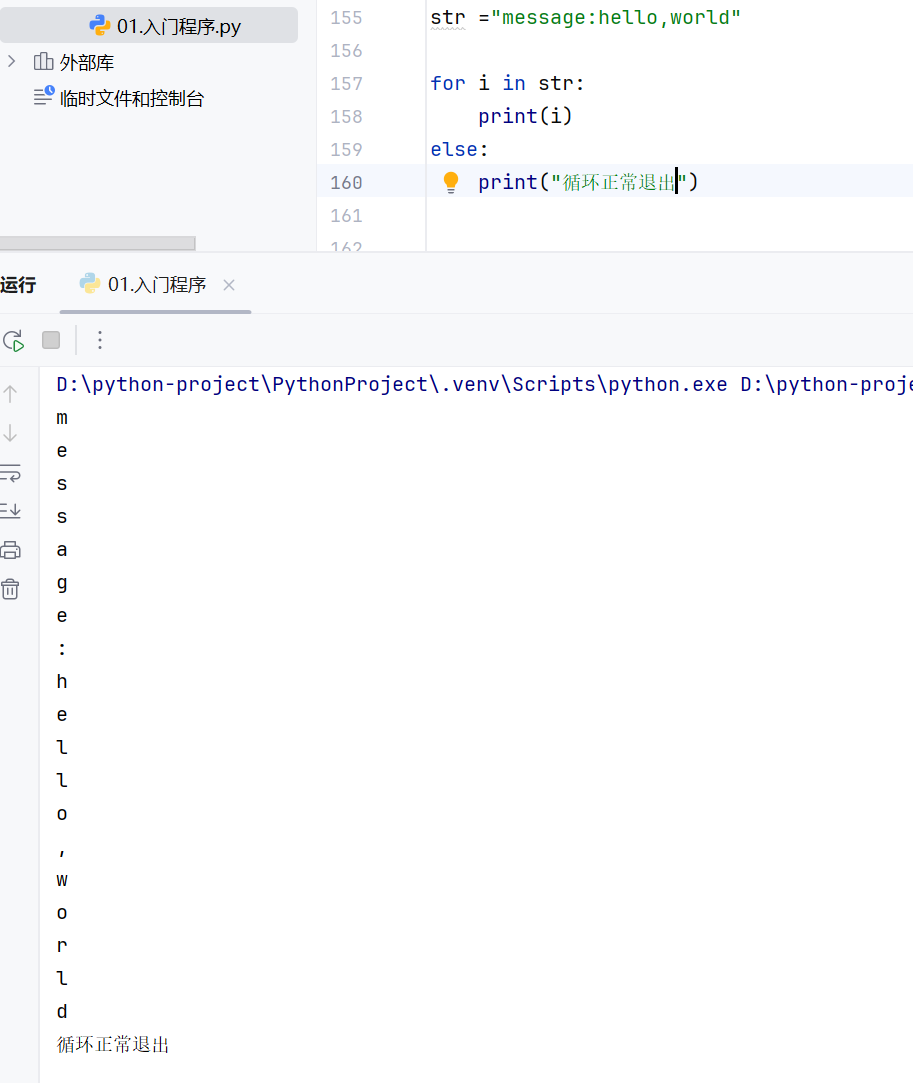
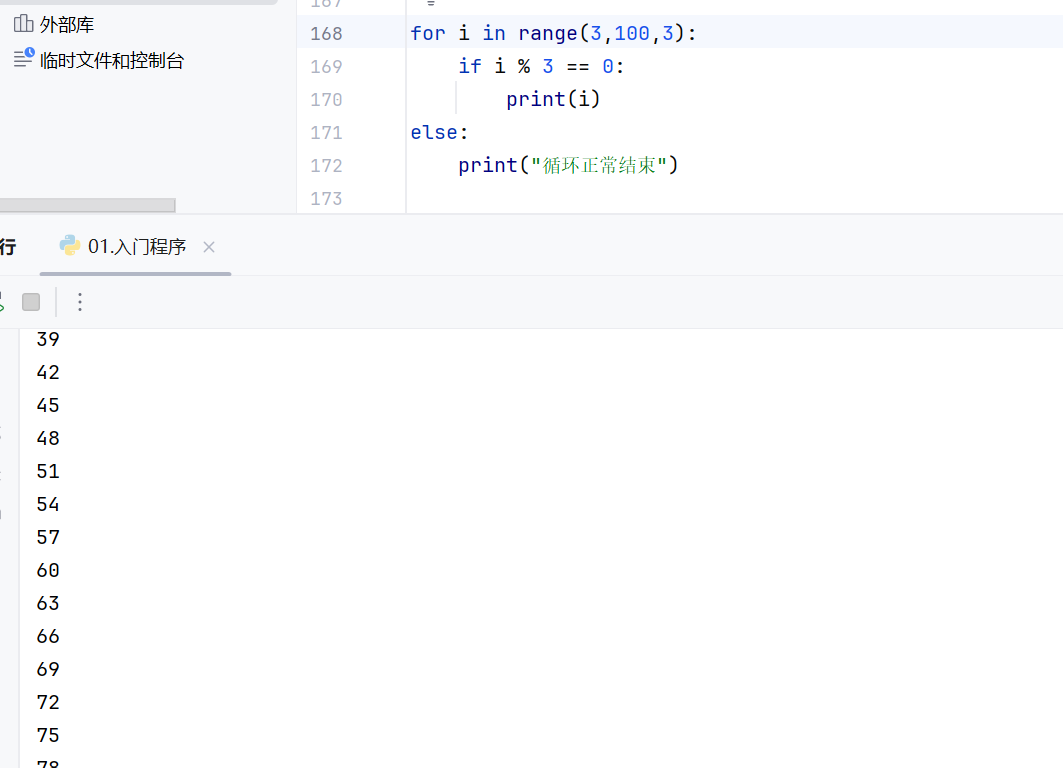
for循环-range语句

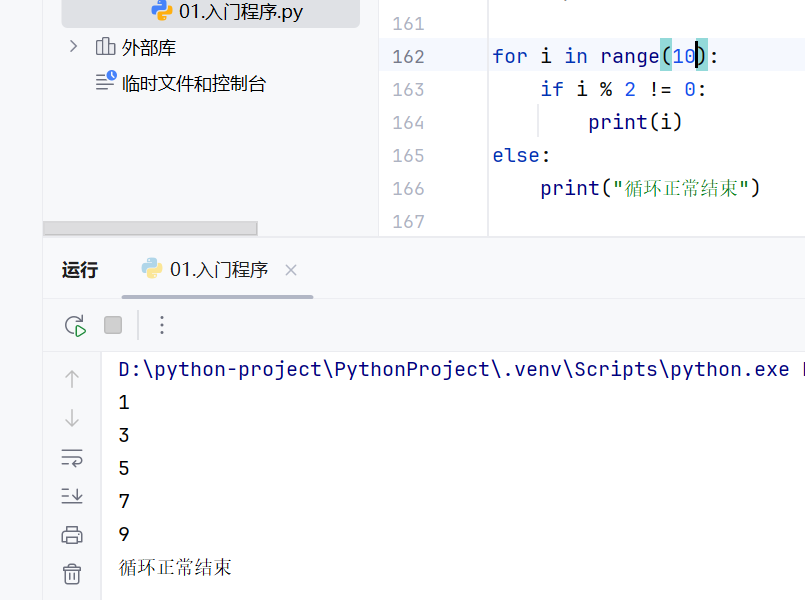
正确的使用range的步长还可以减少for循环的循环次数
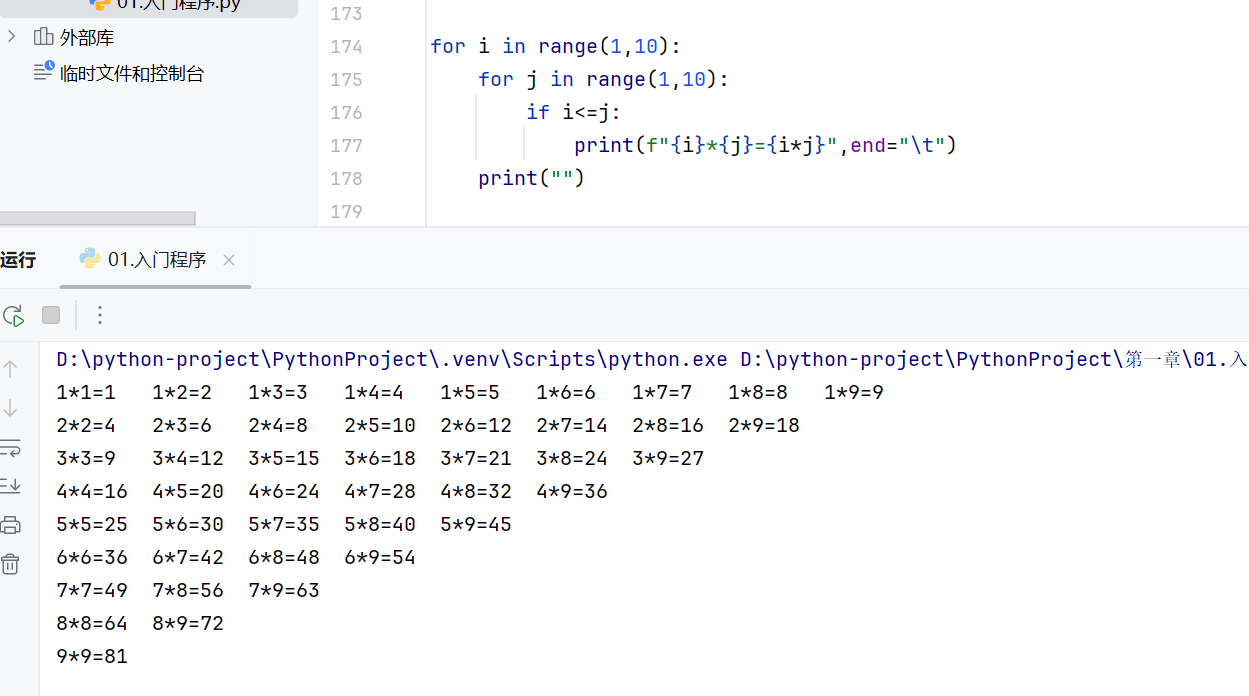
-嵌套循环
打印九九乘法表
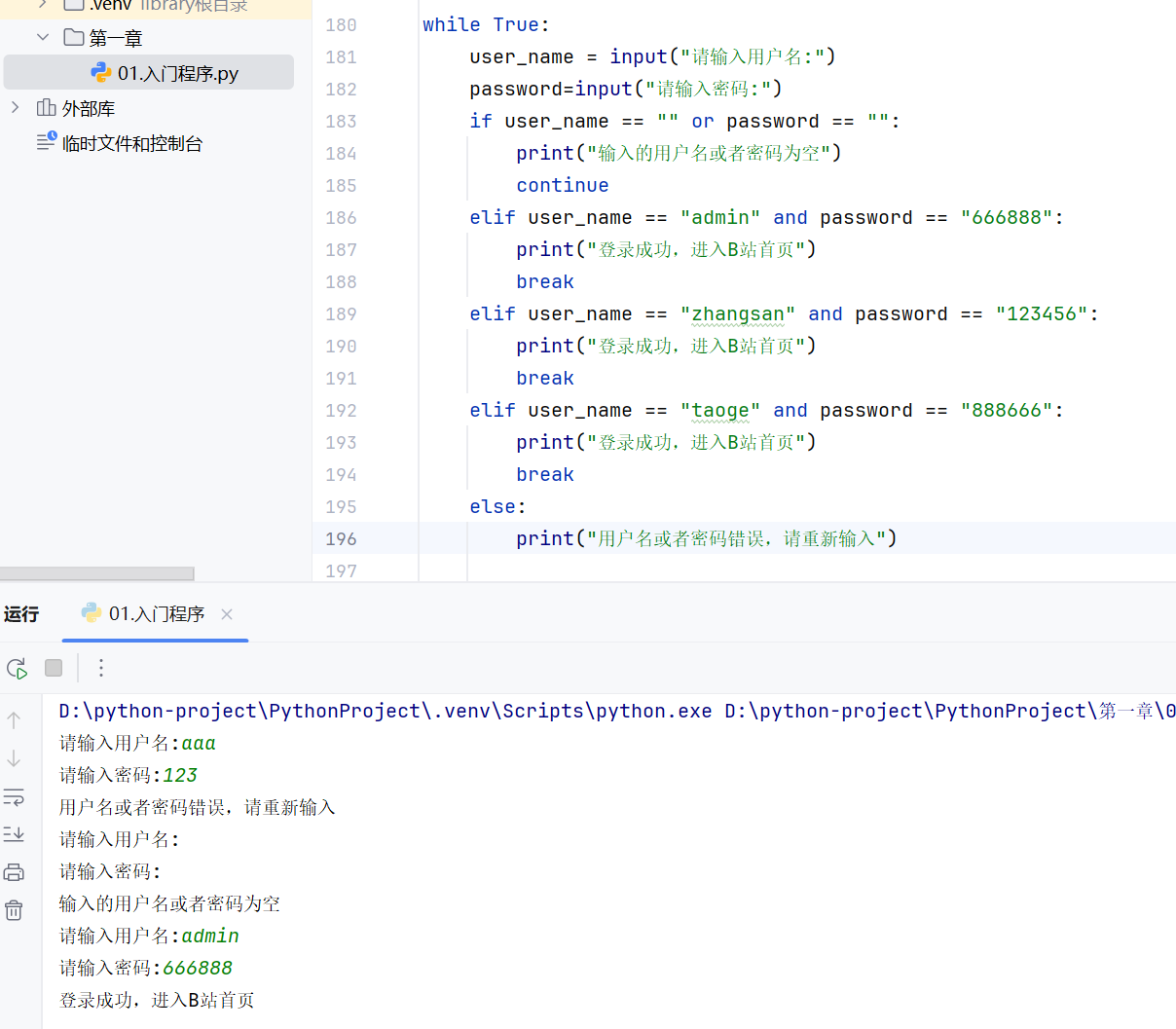
循环综合案例
continue和break

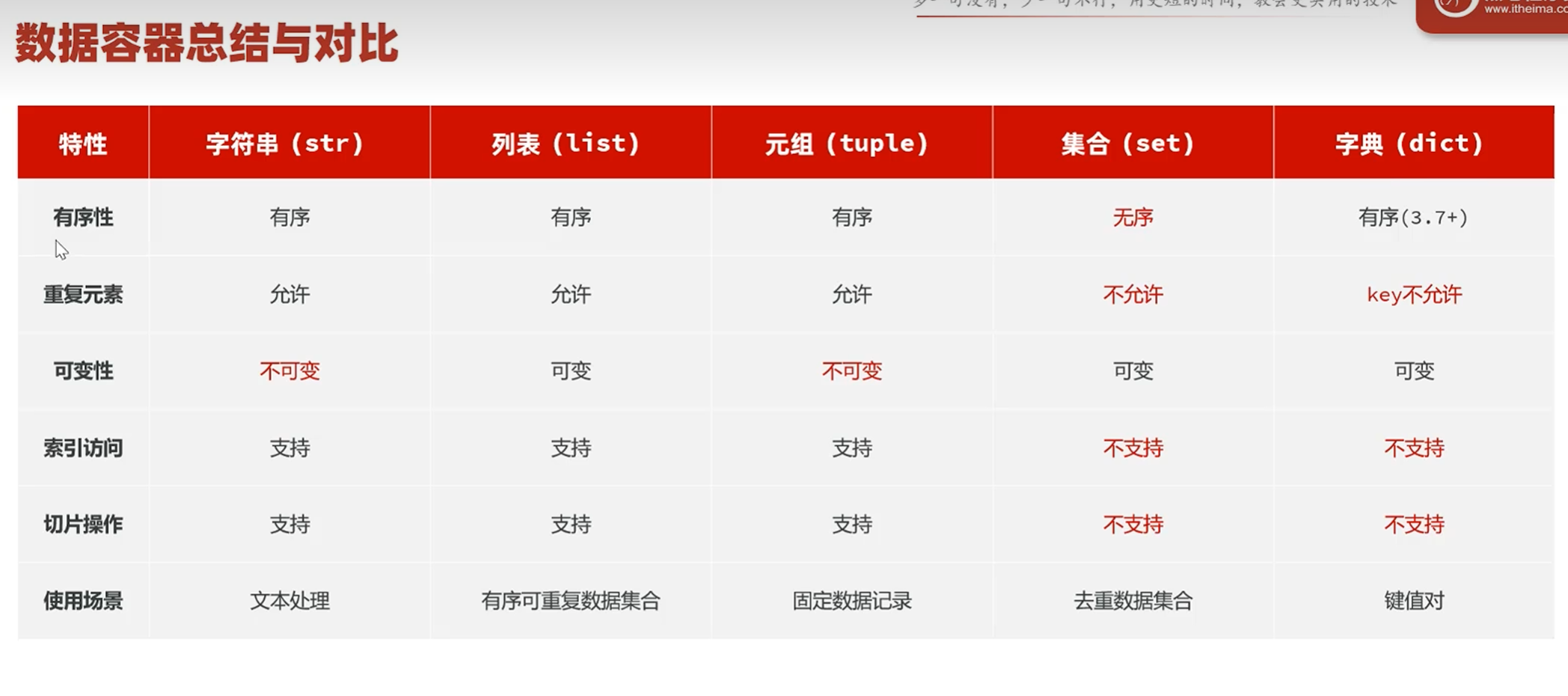
-数据容器
-列表list
-特点

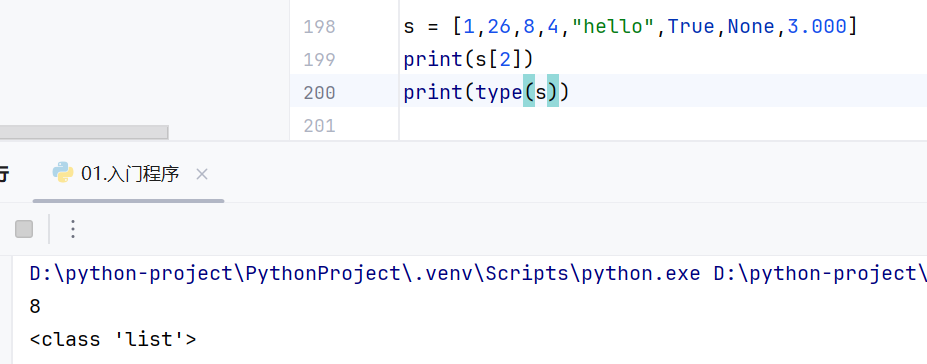
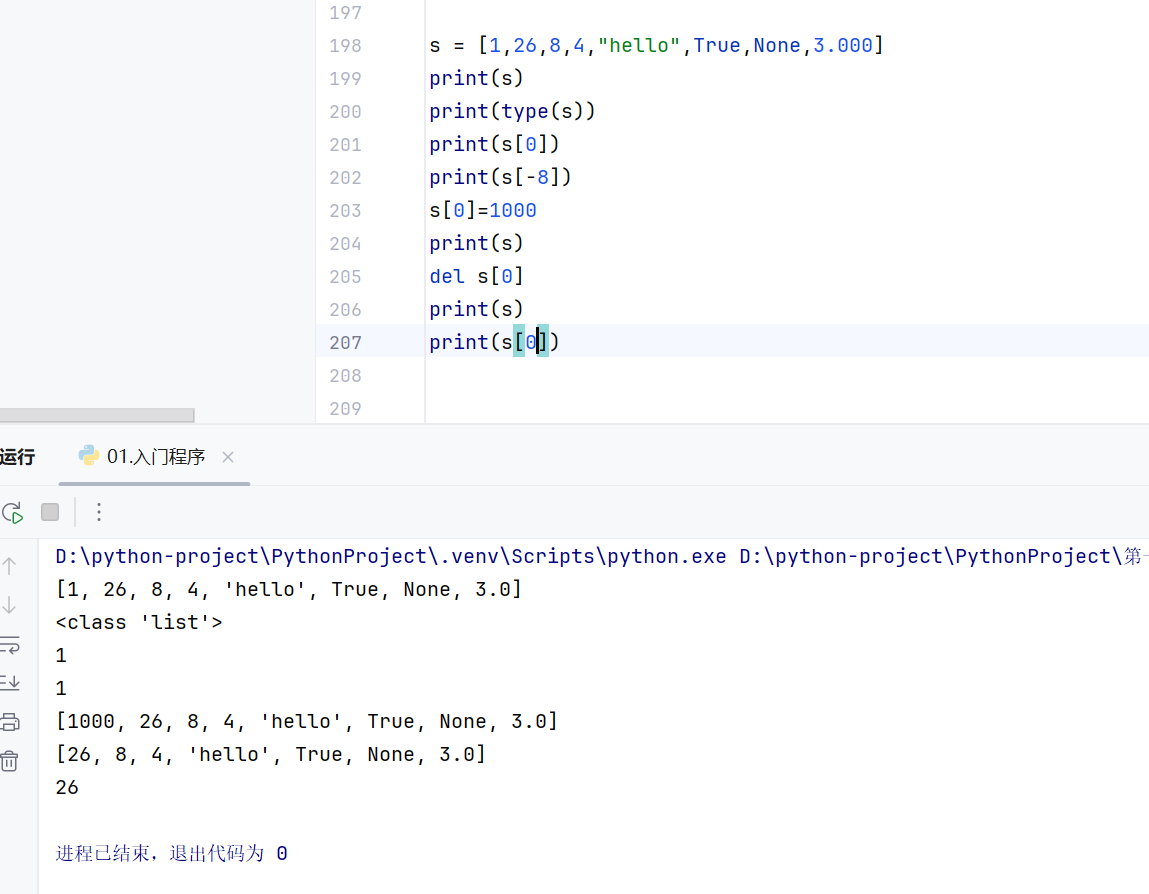
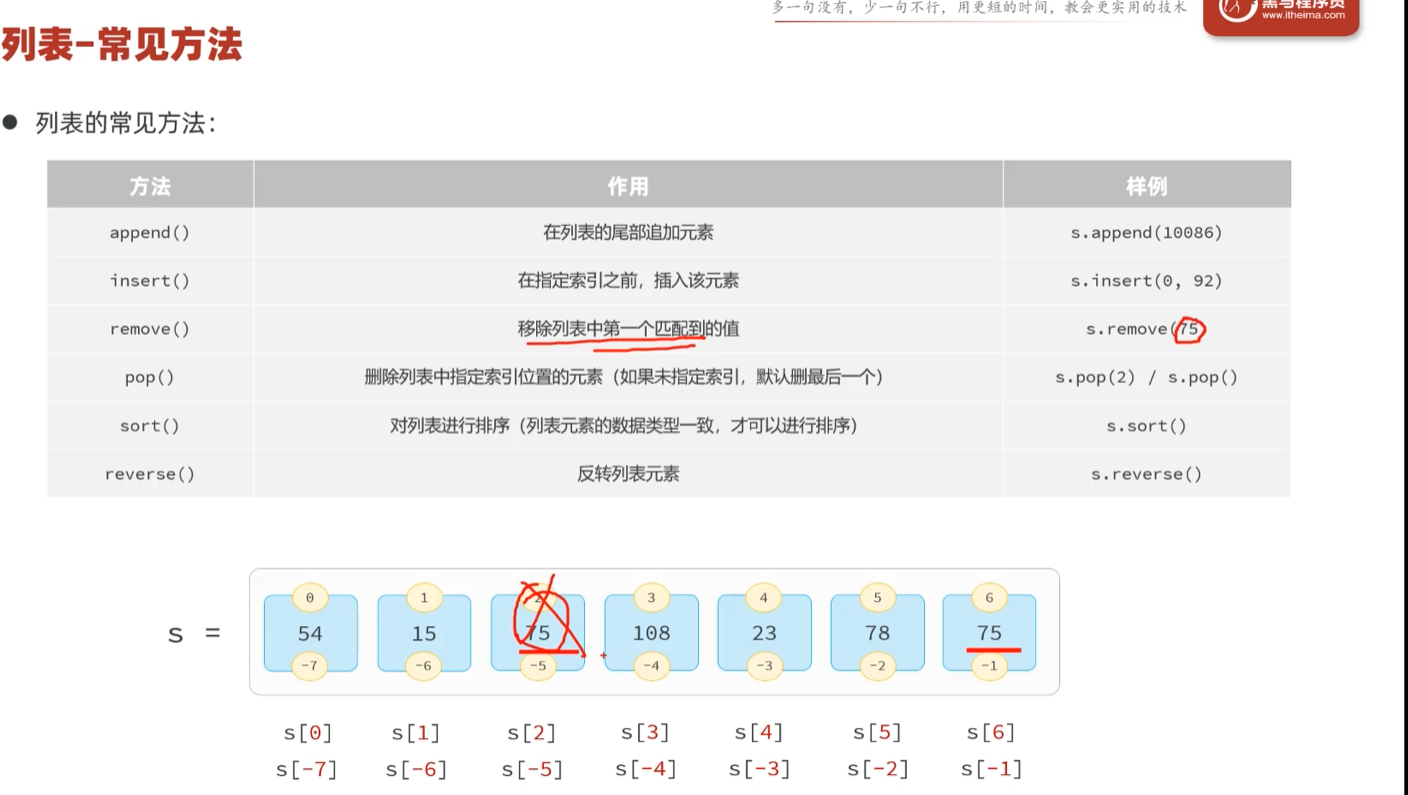
删改查
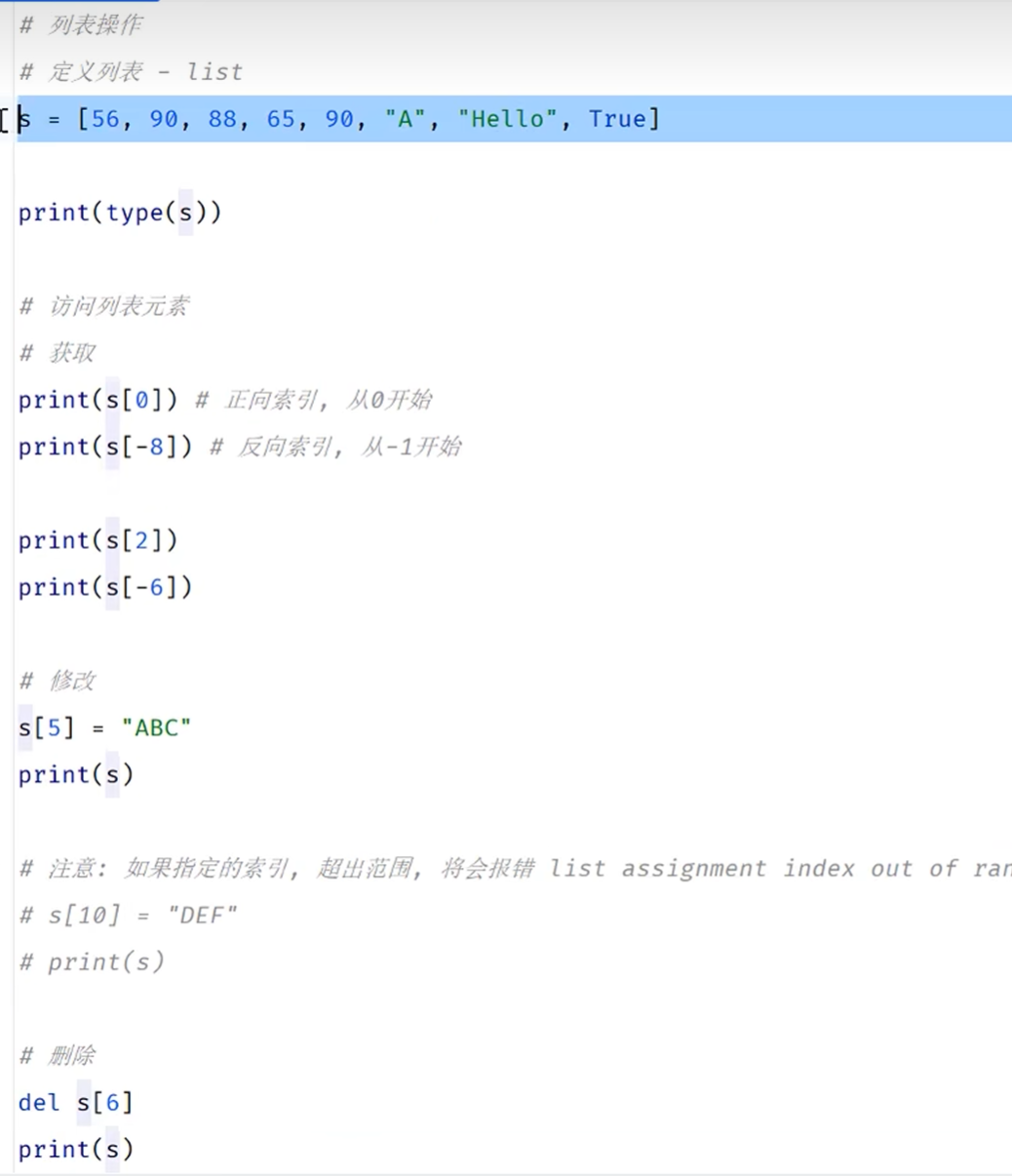
删除之后顺序不变,删除下标为0的元素之后,下标为1的元素变为下标为0的元素
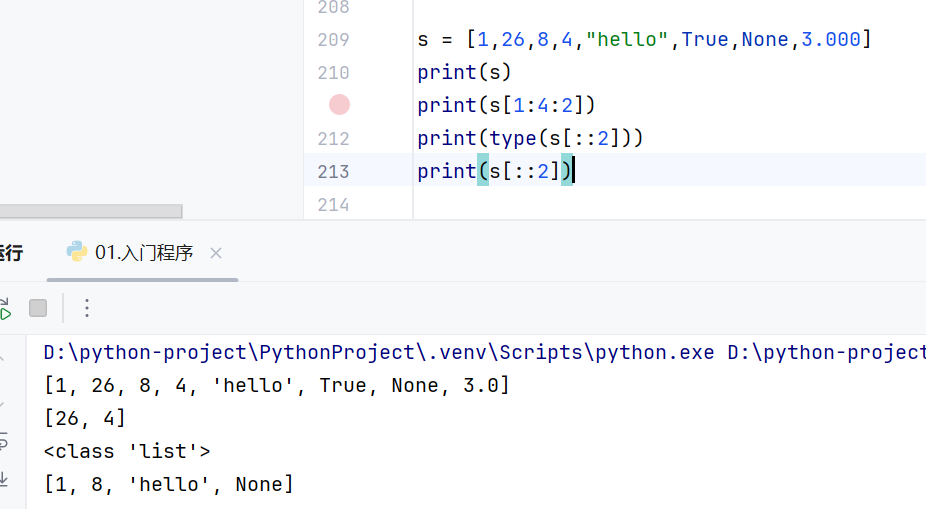
-切片
正向索引
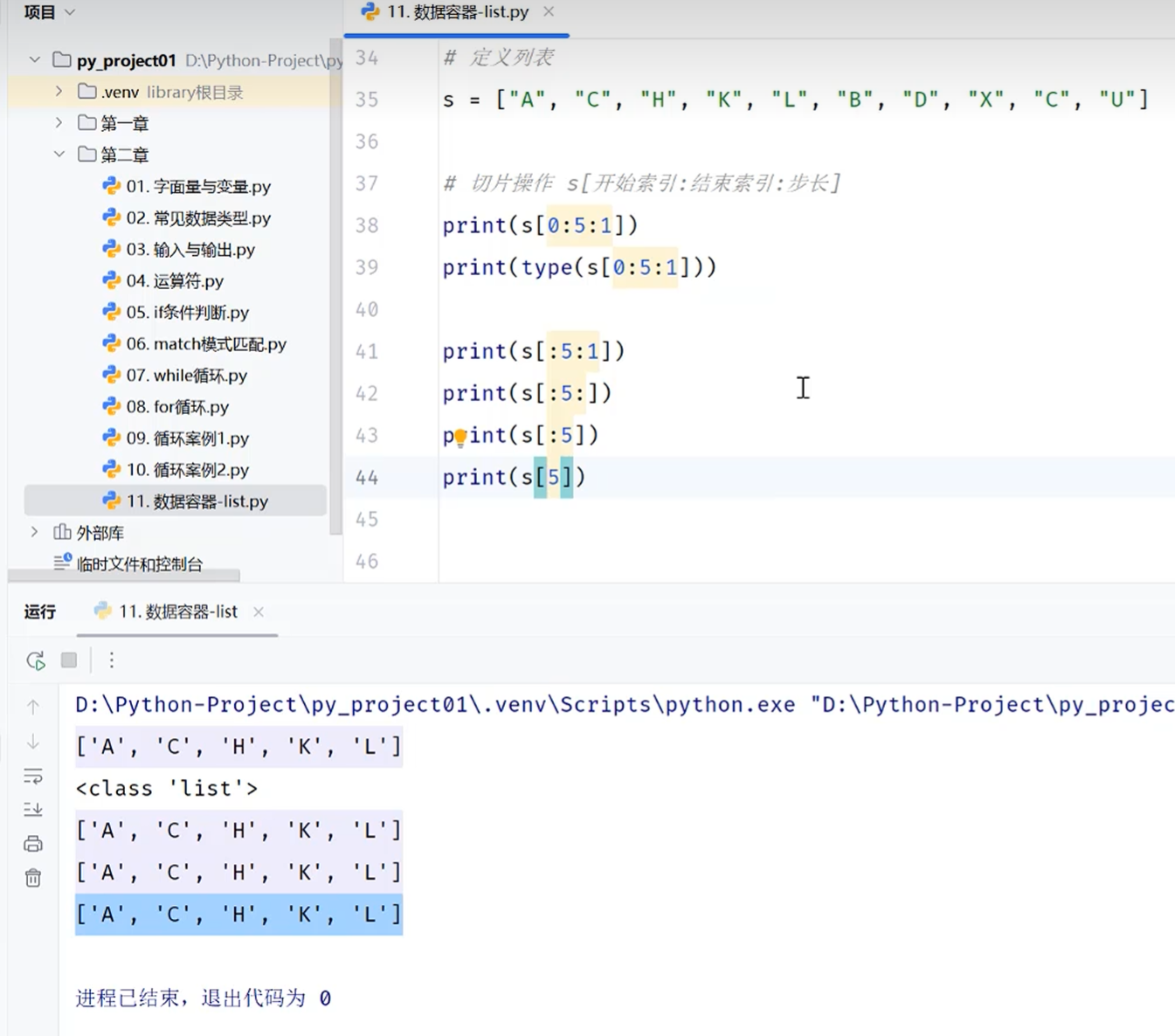
第二个省略号可以省略,但是第一个省略号不能省略
反向索引
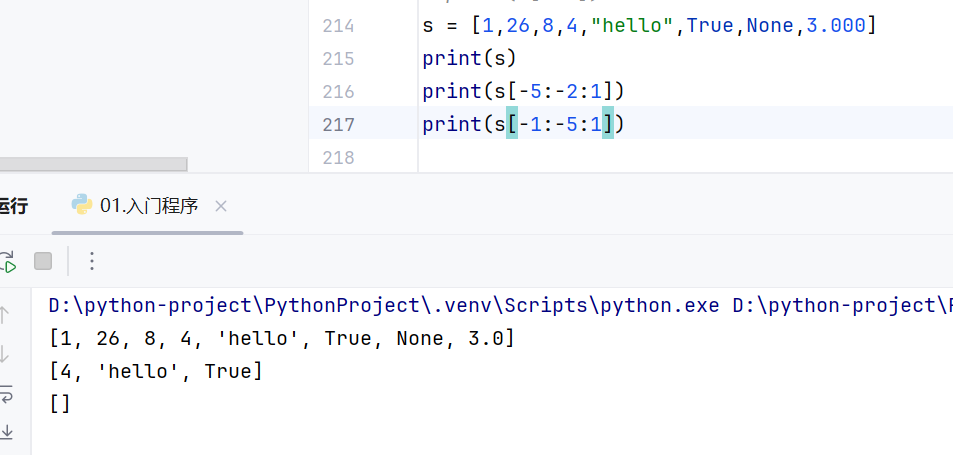
可以使用反向索引,但是不能反向切片,会返回空
常用方法

list-案例1

-list-案例2-解包
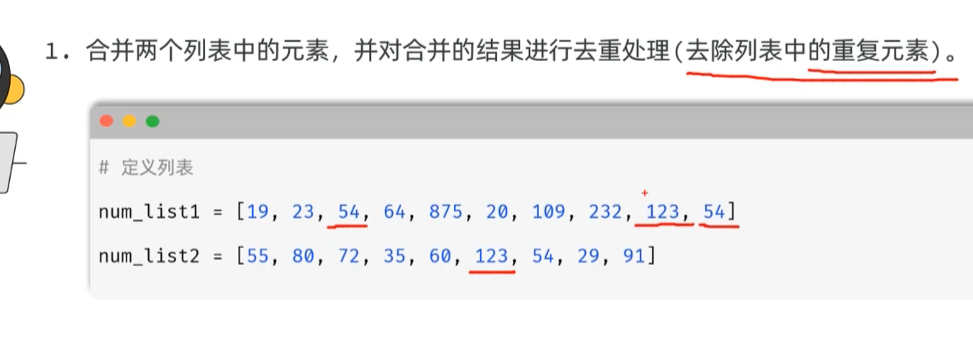
解包和组包
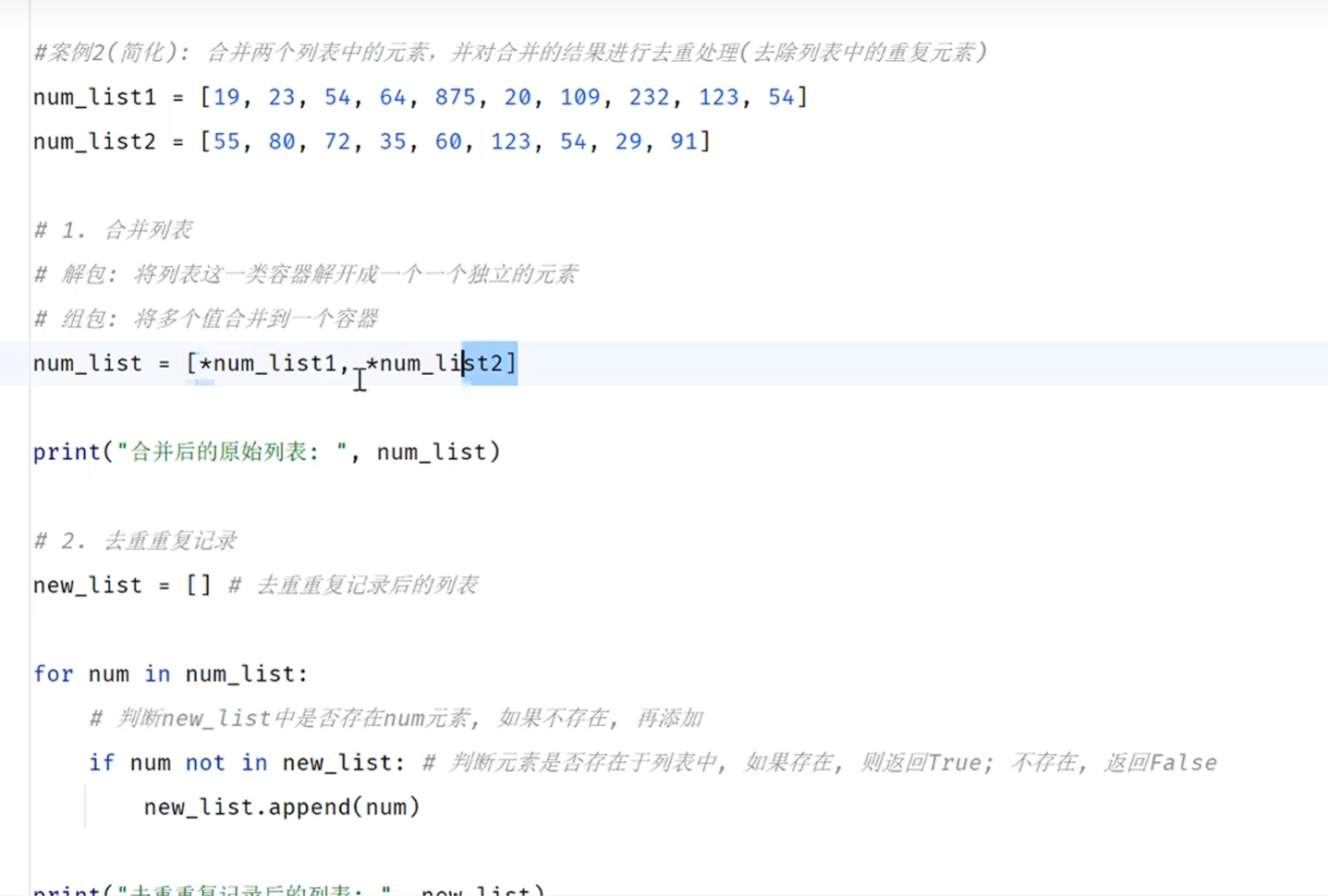
快速合并两个列表的元素
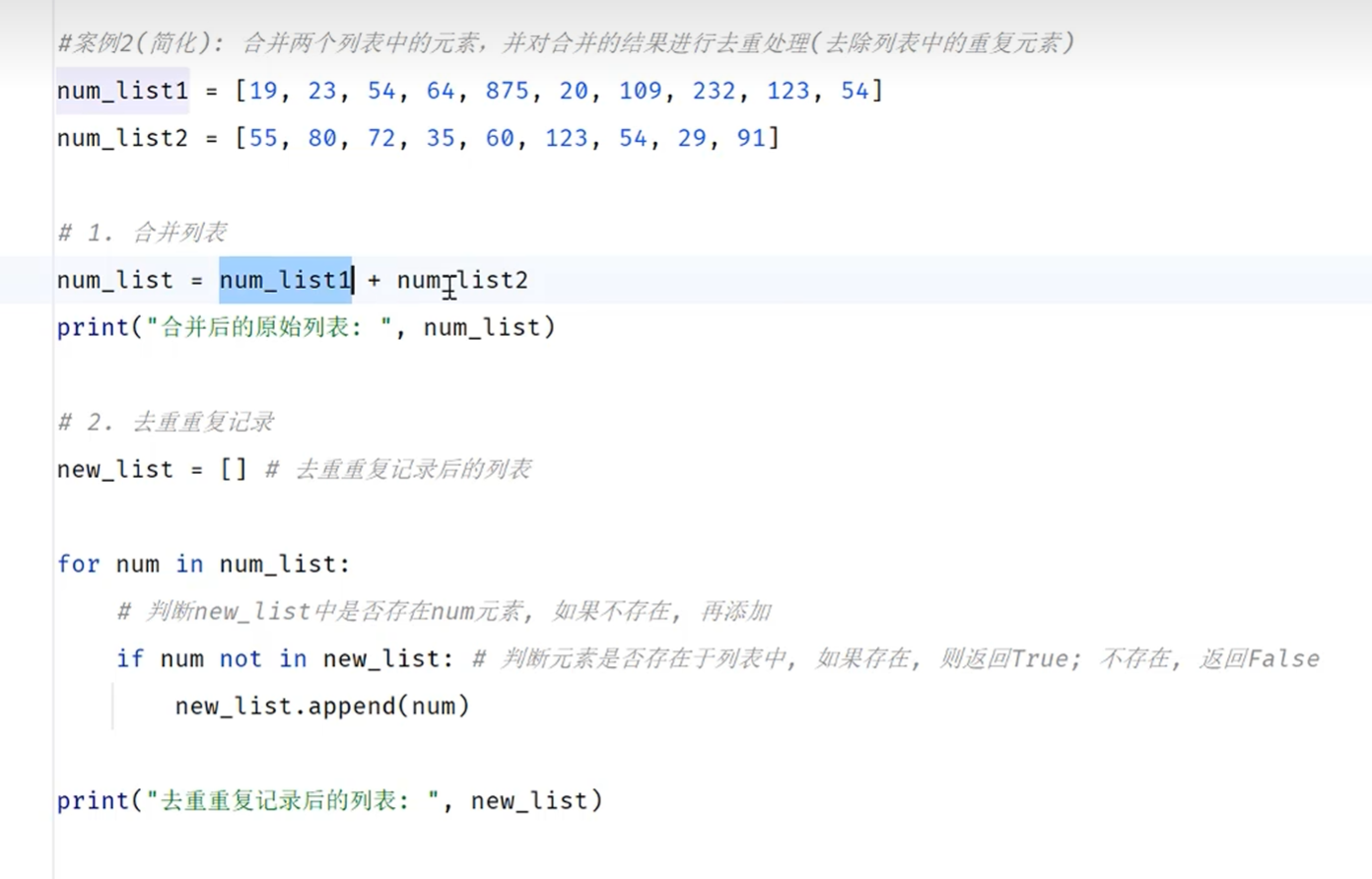
快速判断元素是否存在于列表之中

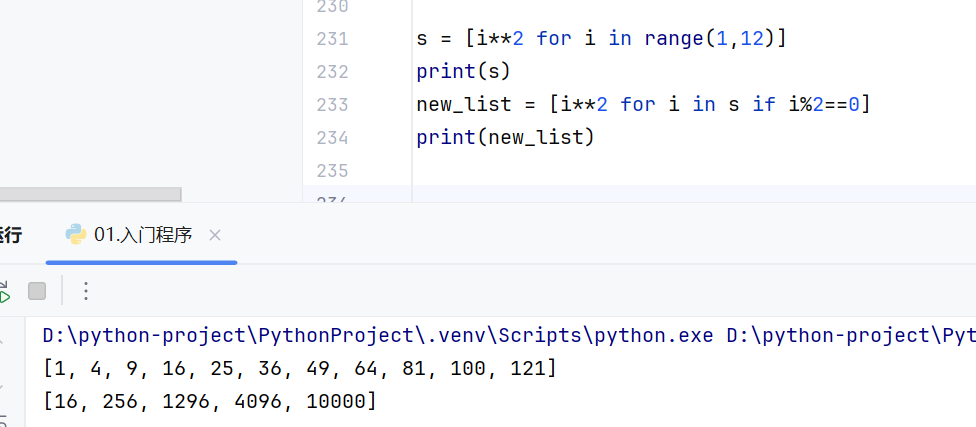
-list-案例3-推导式

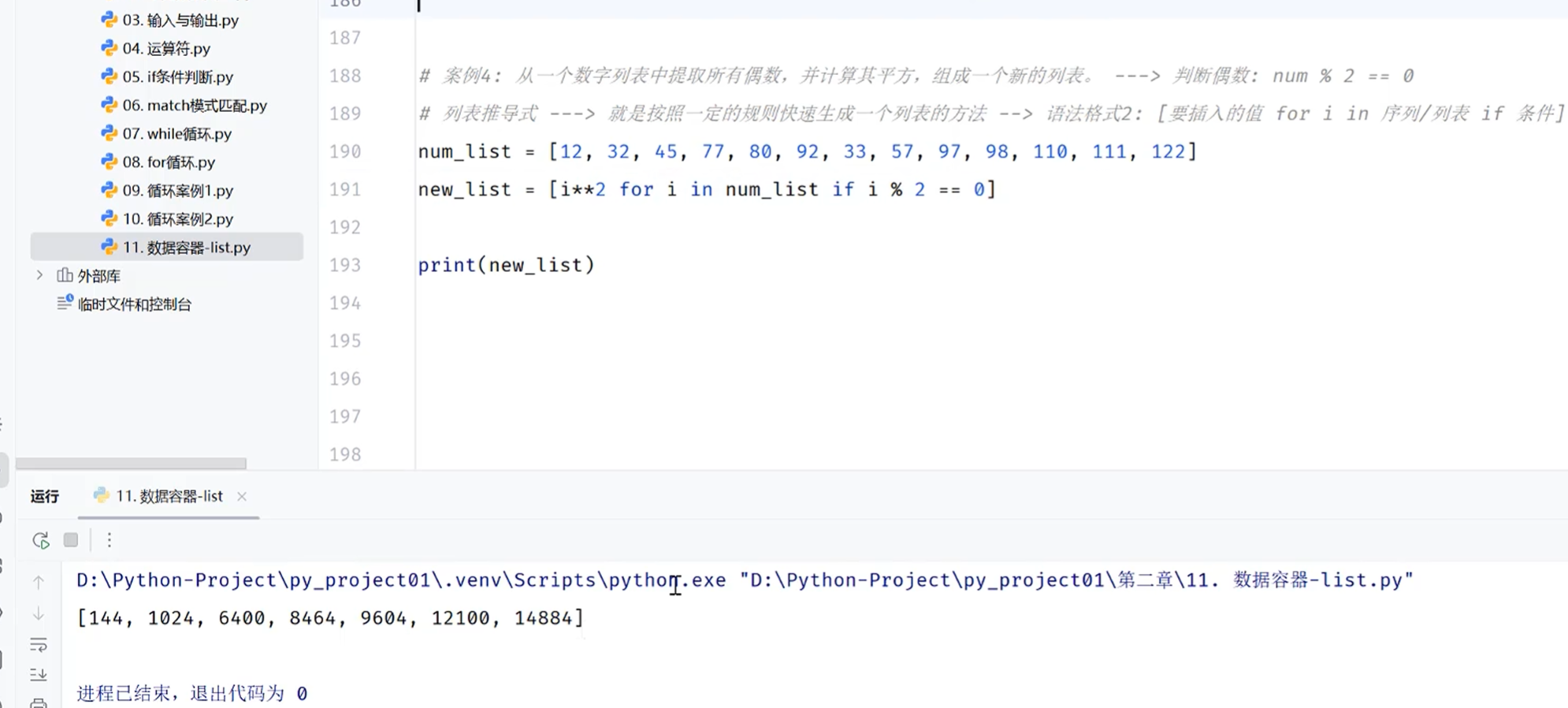
列表推导式包括三部分:要输入的值,范围,判断条件
字符串str
-基本操作

字符串也支持反向索引
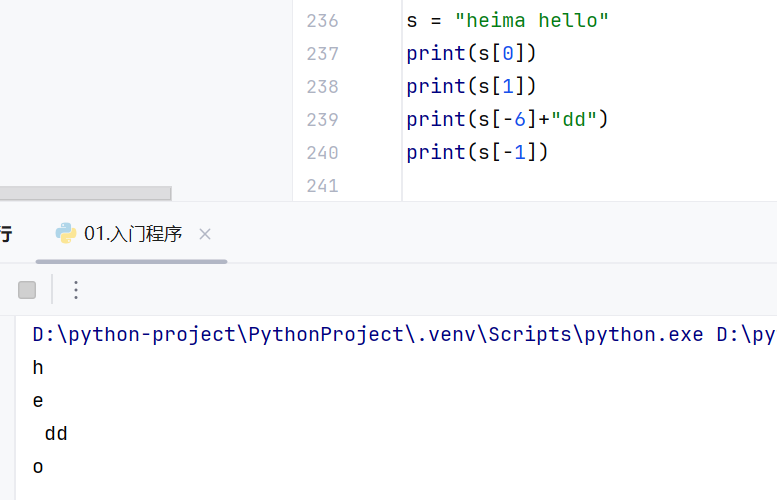
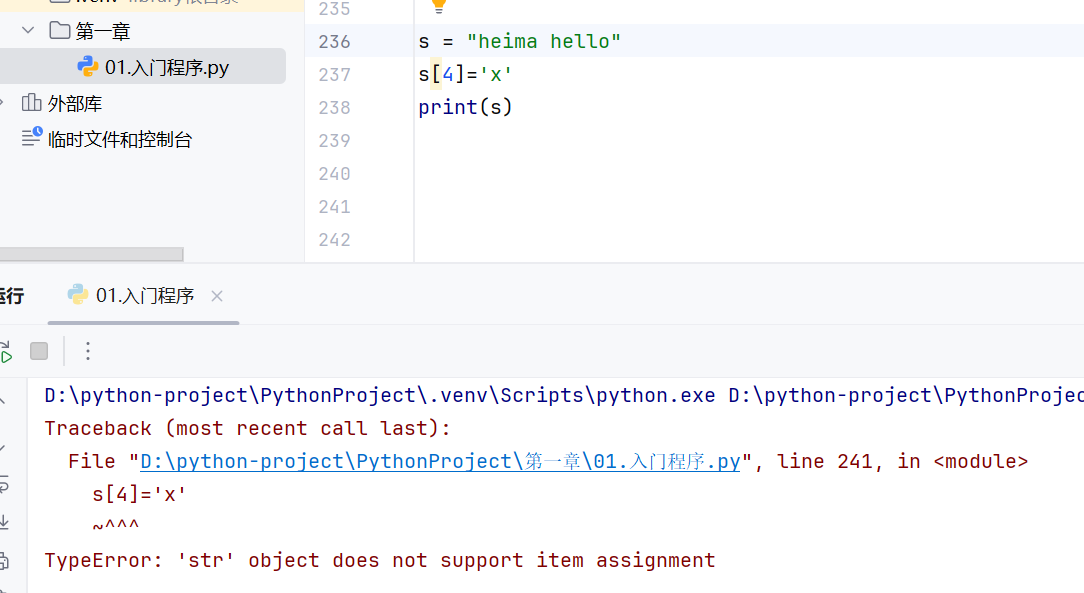
字符串无法修改
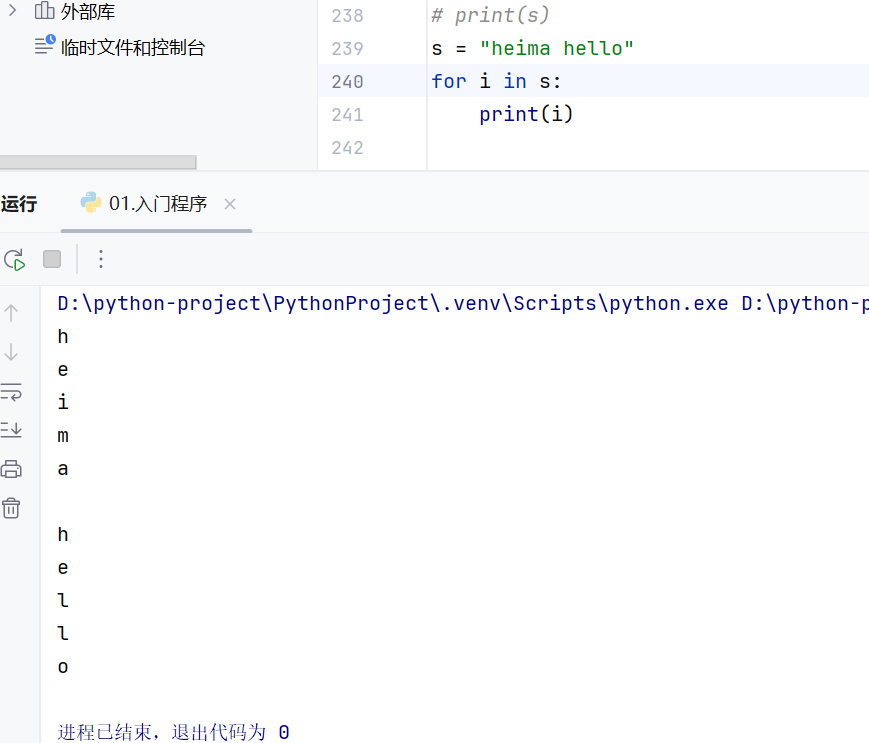
字符串有序性,可迭代性
可迭代指的是可以循环遍历
支持切片
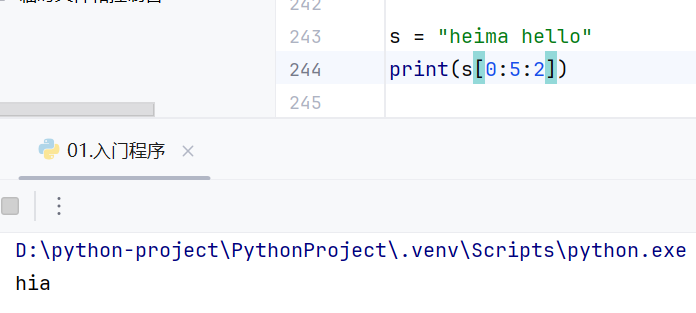
可以省略起始位置和步长,省略后默认起始位置为0,步长为1
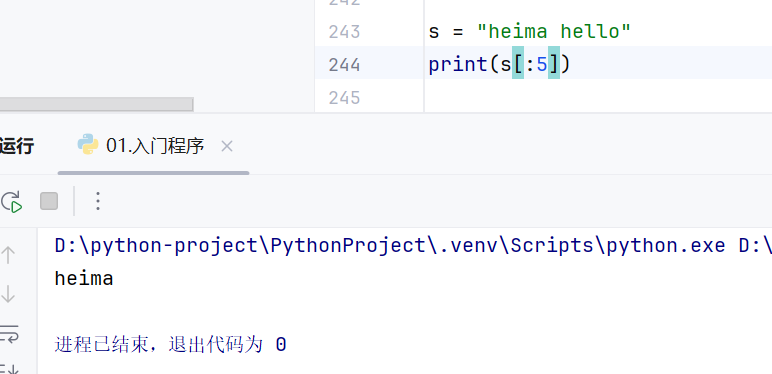
截取到字符串末尾直接写-1,如果省略,认为为-1
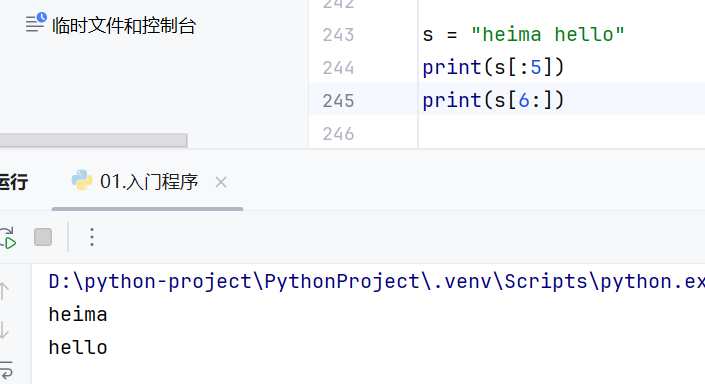
步长为正数,从前往后截取,步长为负数,从后往前截取
步长为负数的时候,起始位置和结束位置要调换
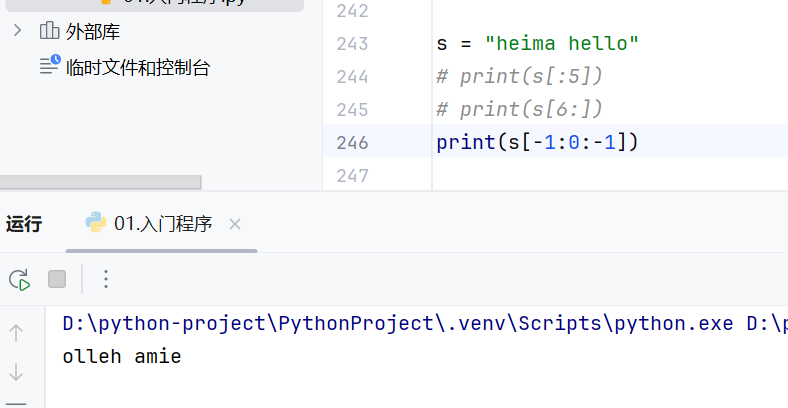
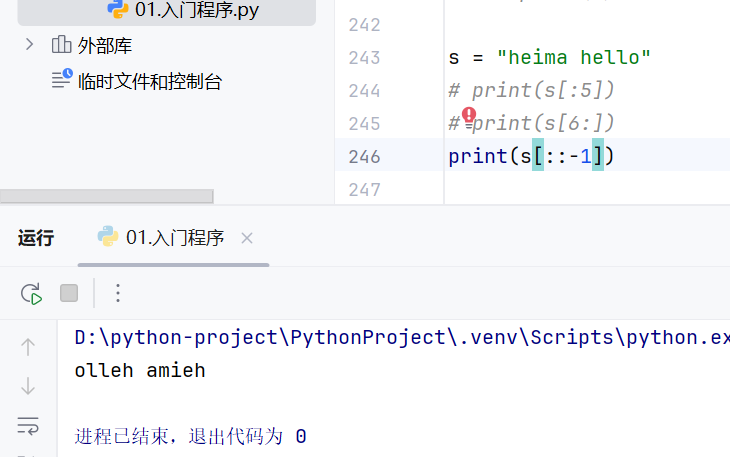

-常用方法

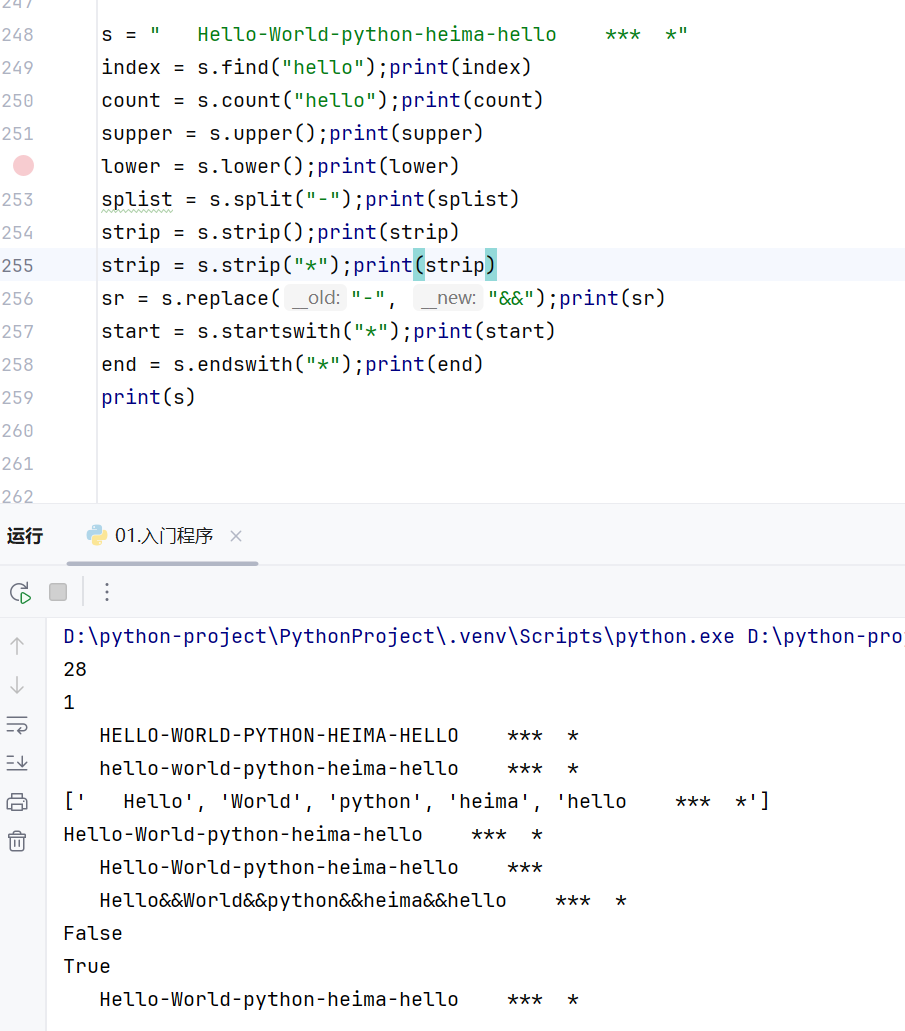
由于字符串的不可变性,原本的字符串没有改变,返回的都是新字符串
-案例
-元组tuple
-基本操作

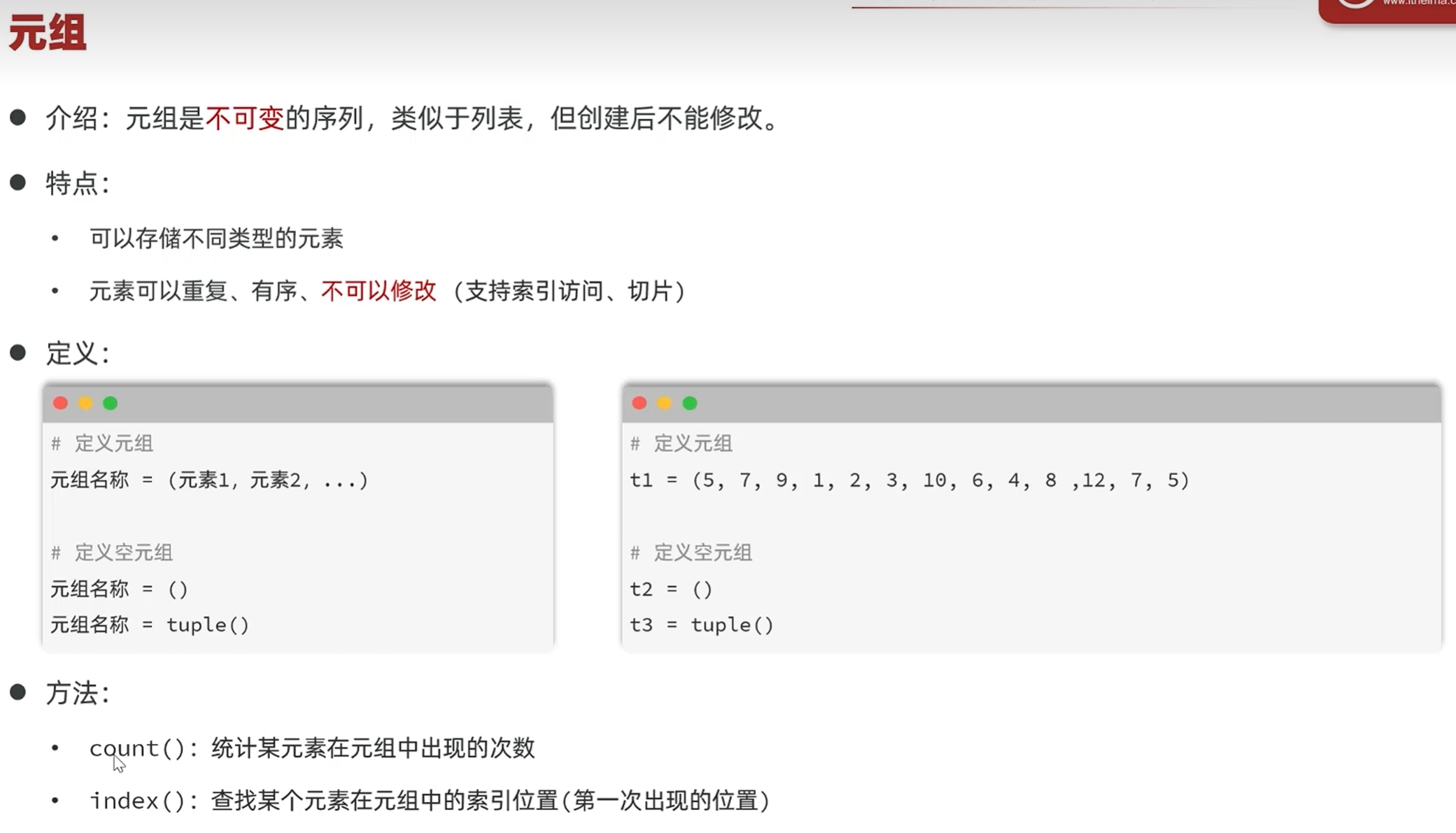
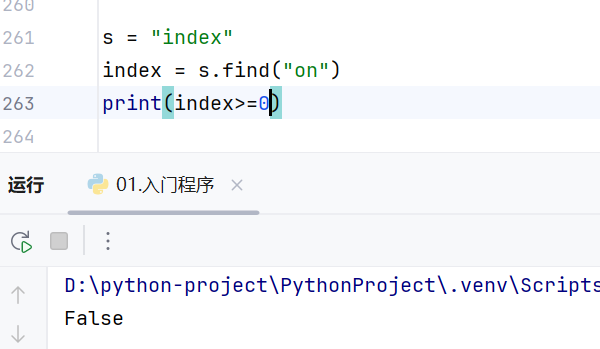
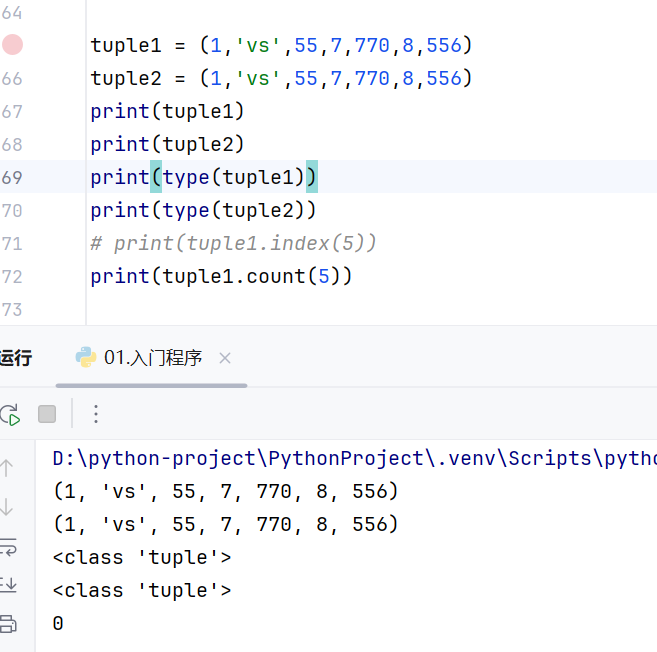
index()
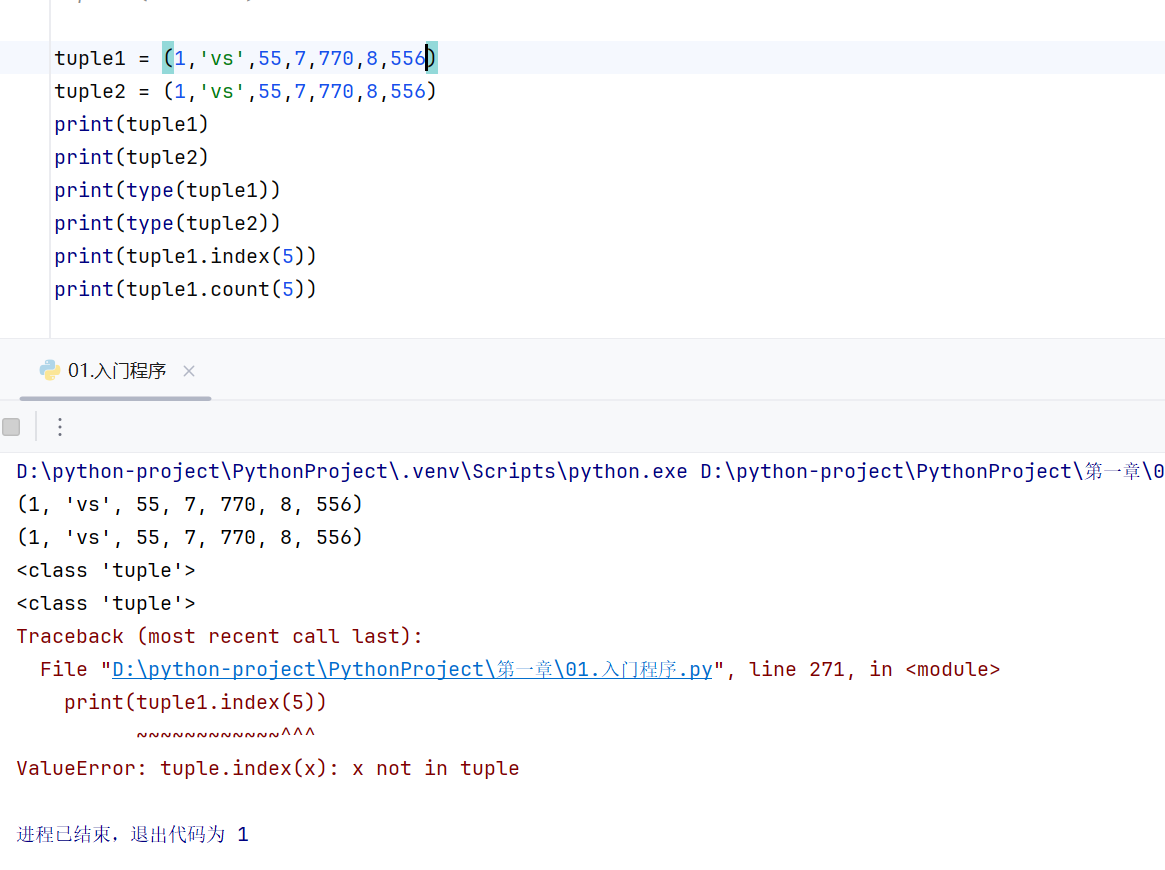
在搜索元组内不存在的元素的时候会报错
count()
索引访问

单元组定义要加,(逗号)

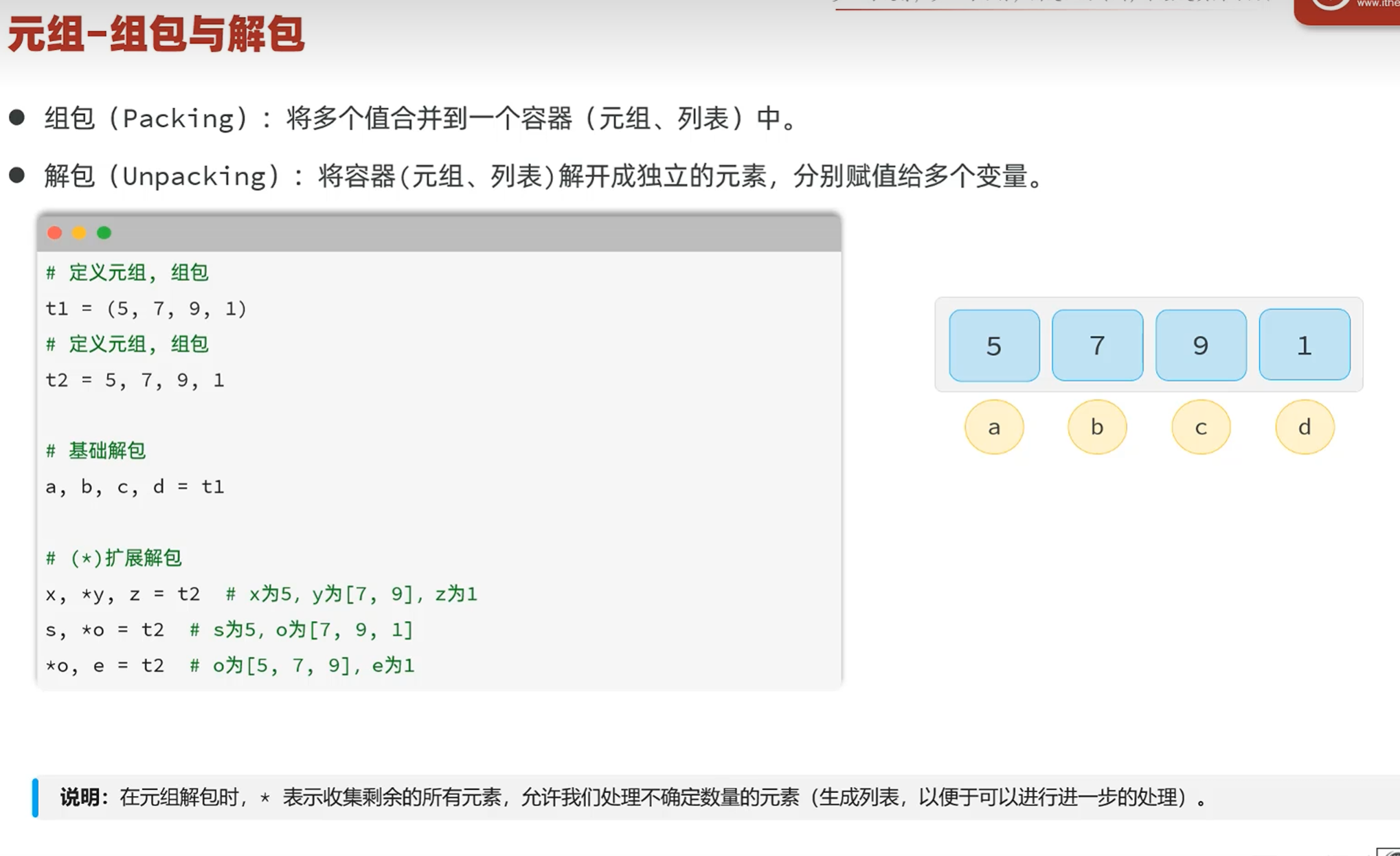
-组包与解包
*变量
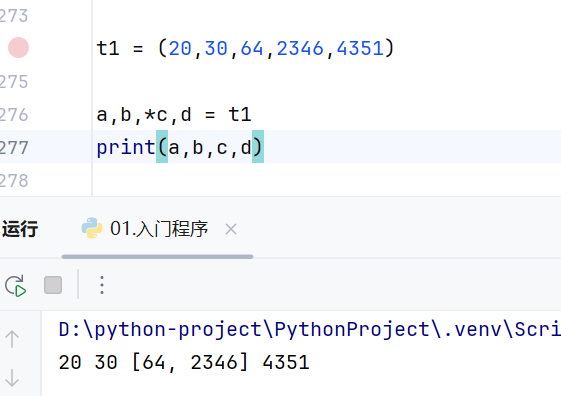
*m不能单独使用,必须位于列表或者元组中
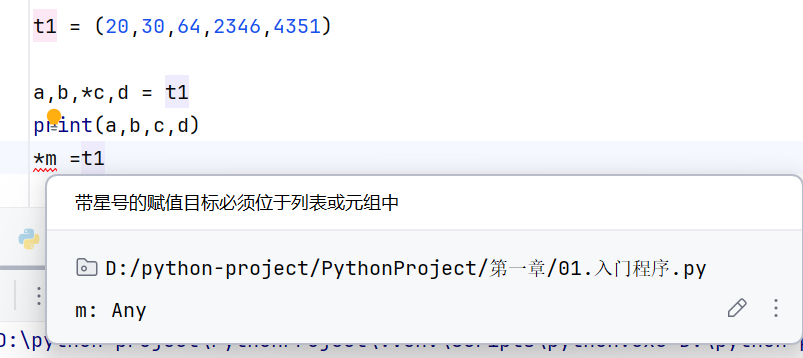
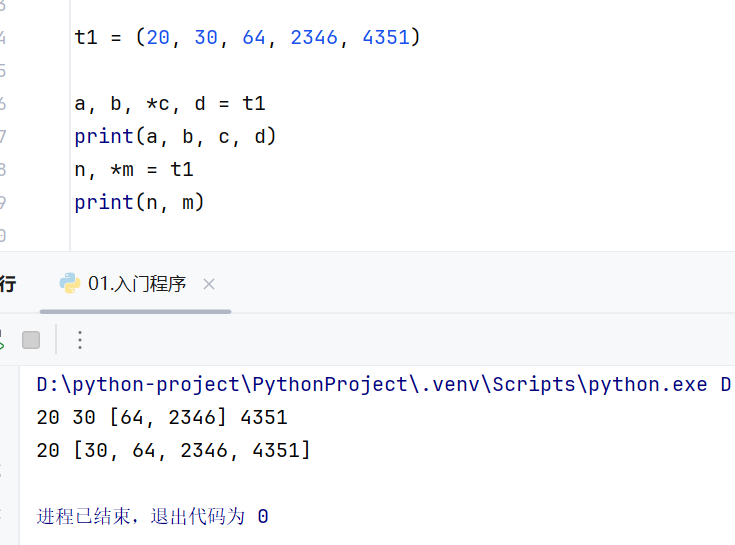
组包和解包的用法
交换变量

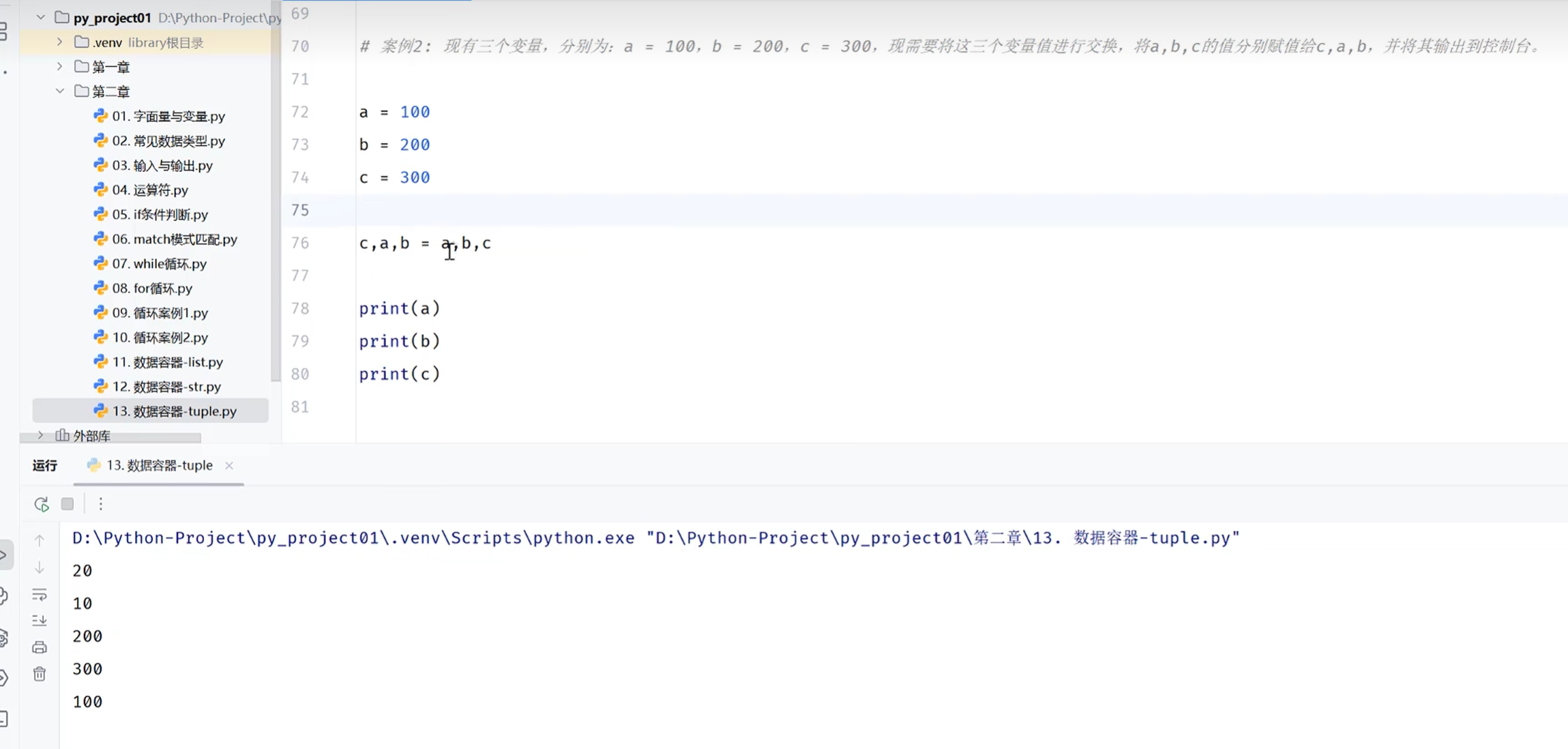
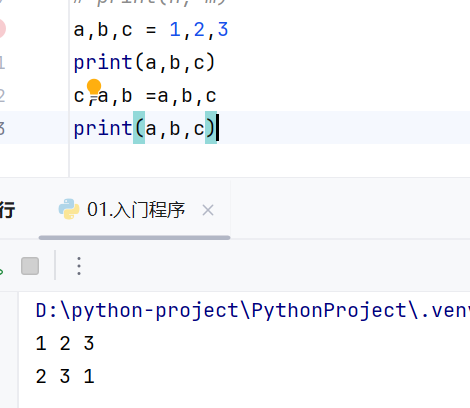
-案例

可以使用二维元组
集合set
-基本操作

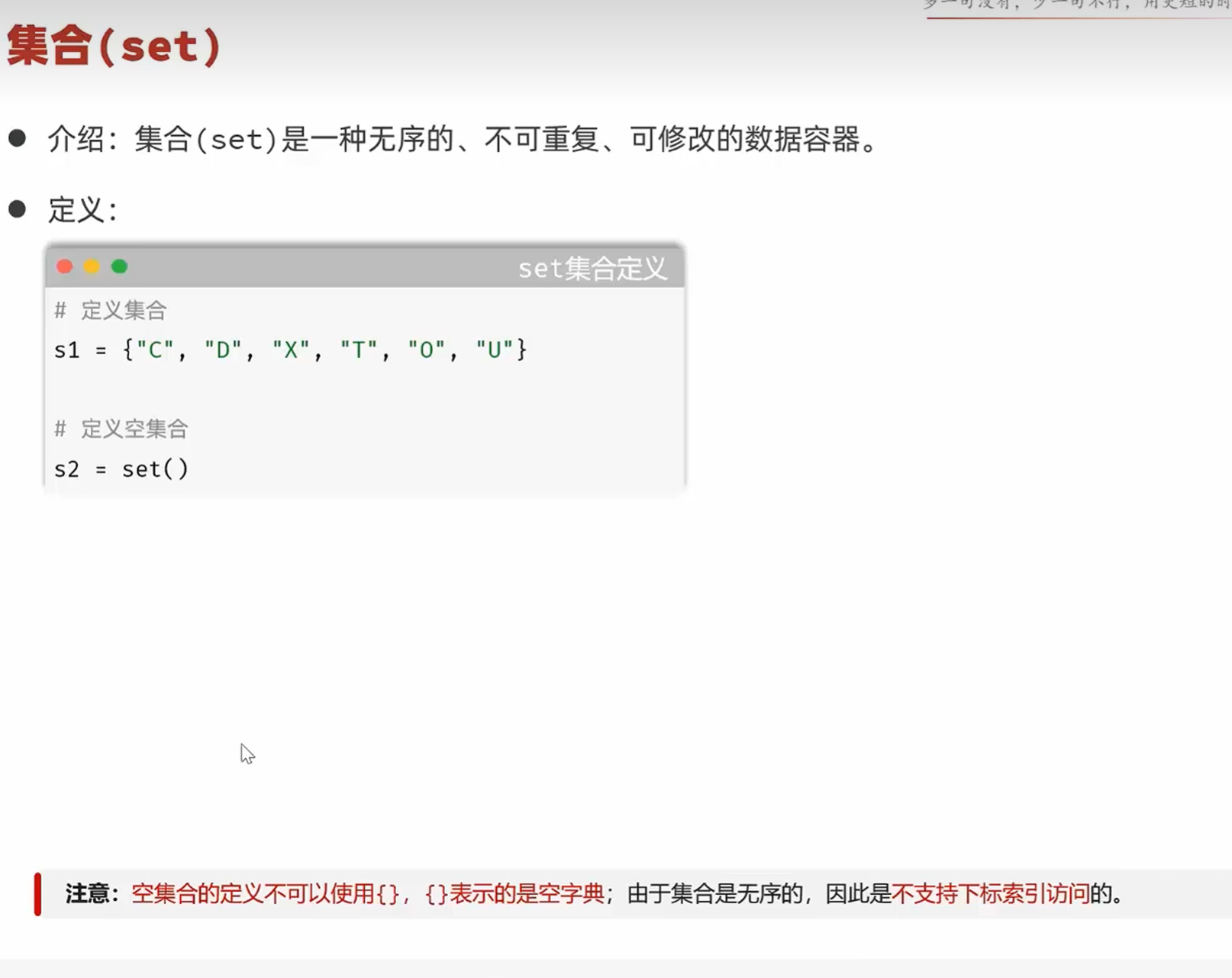
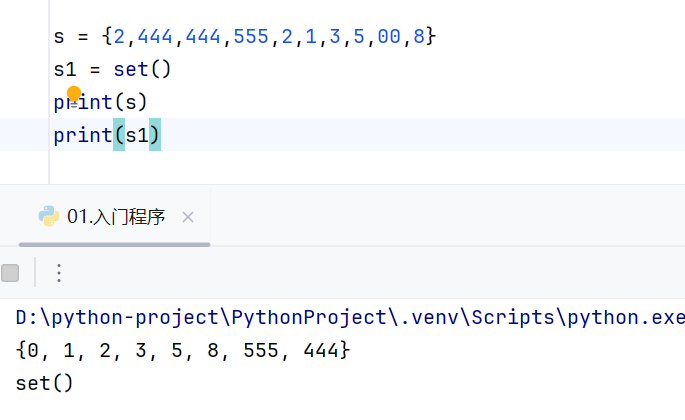
清空集合之后会变成set(),因为{}是空字典,set()才是空集合

-案例
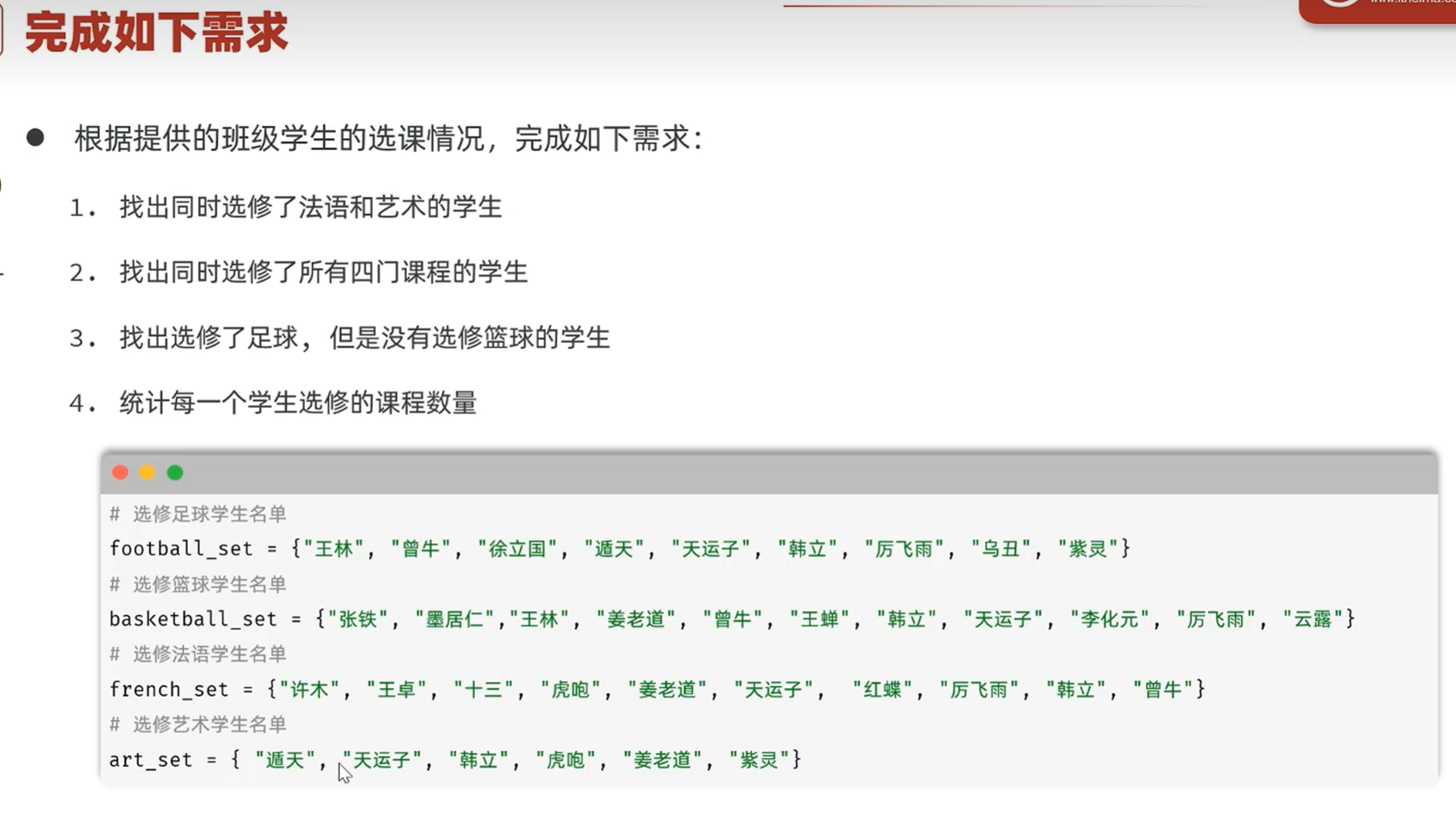
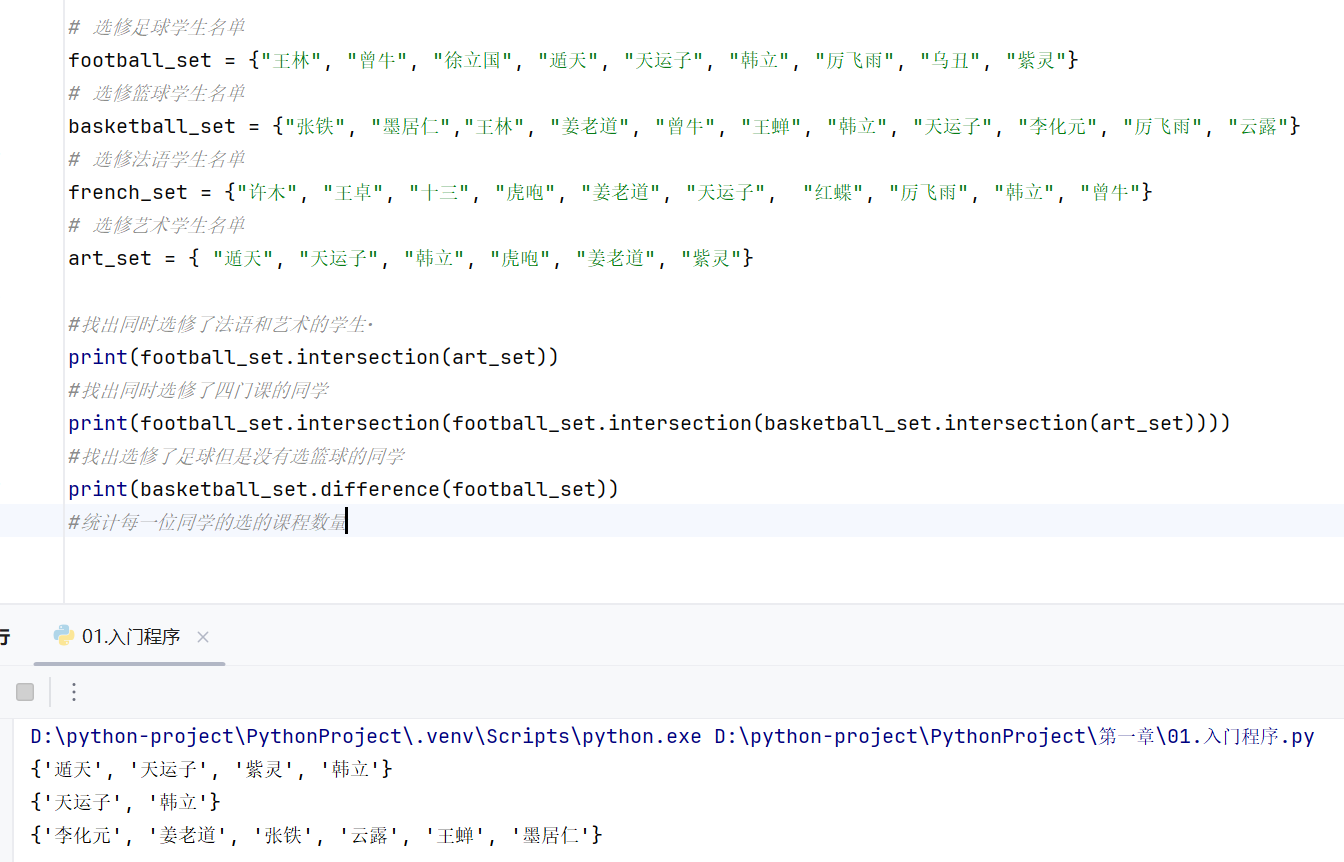
可以活用集合推导式

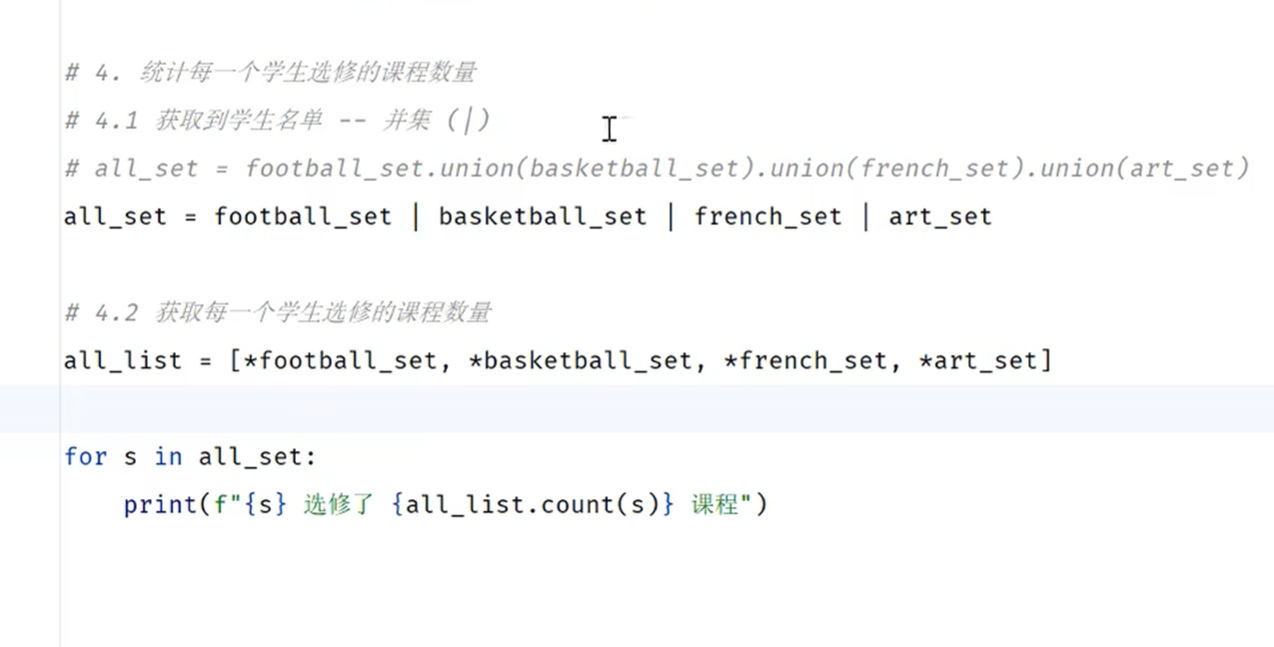
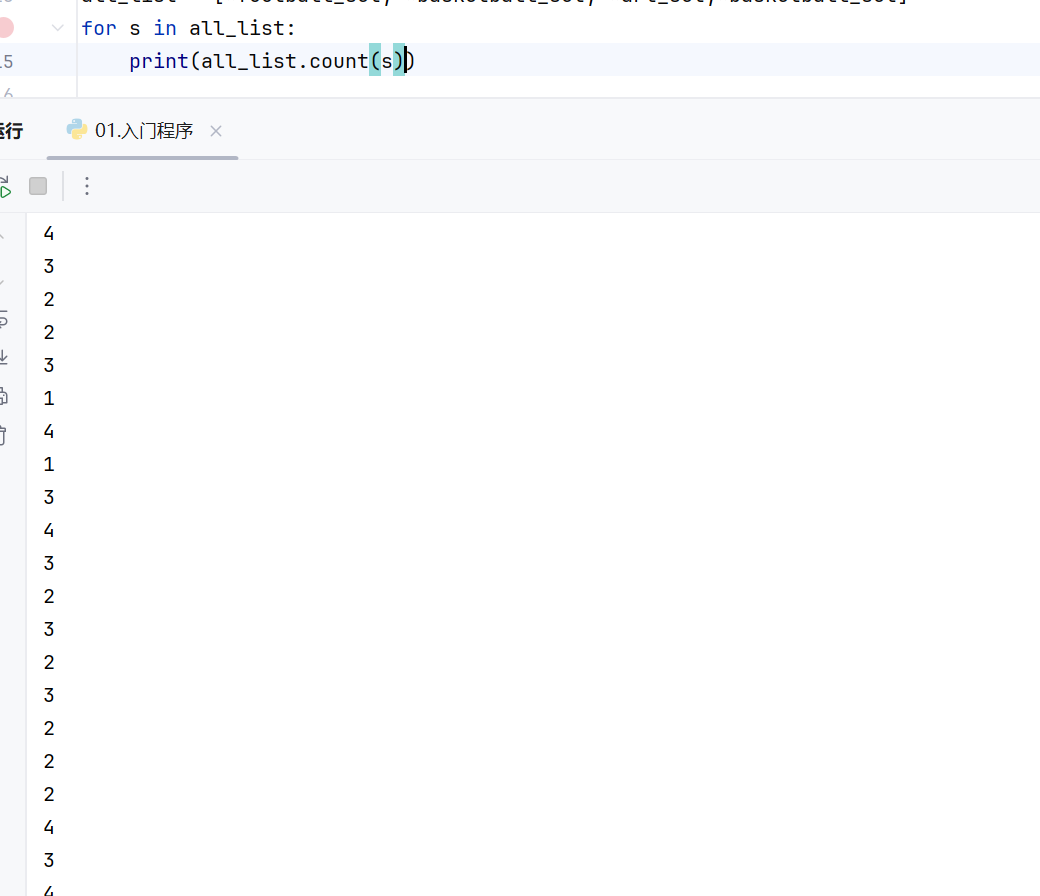
list的count()方法
-字典dict
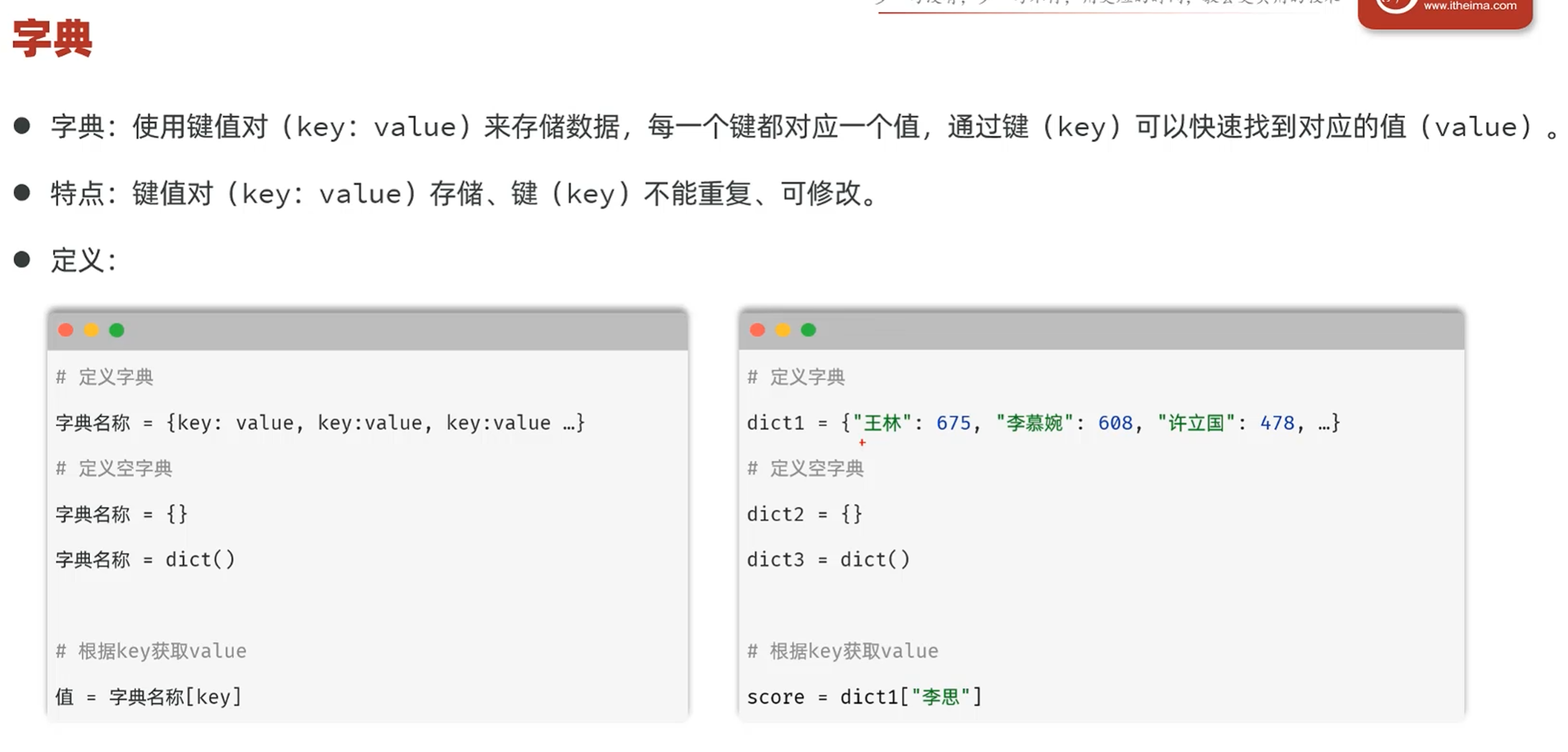
-介绍

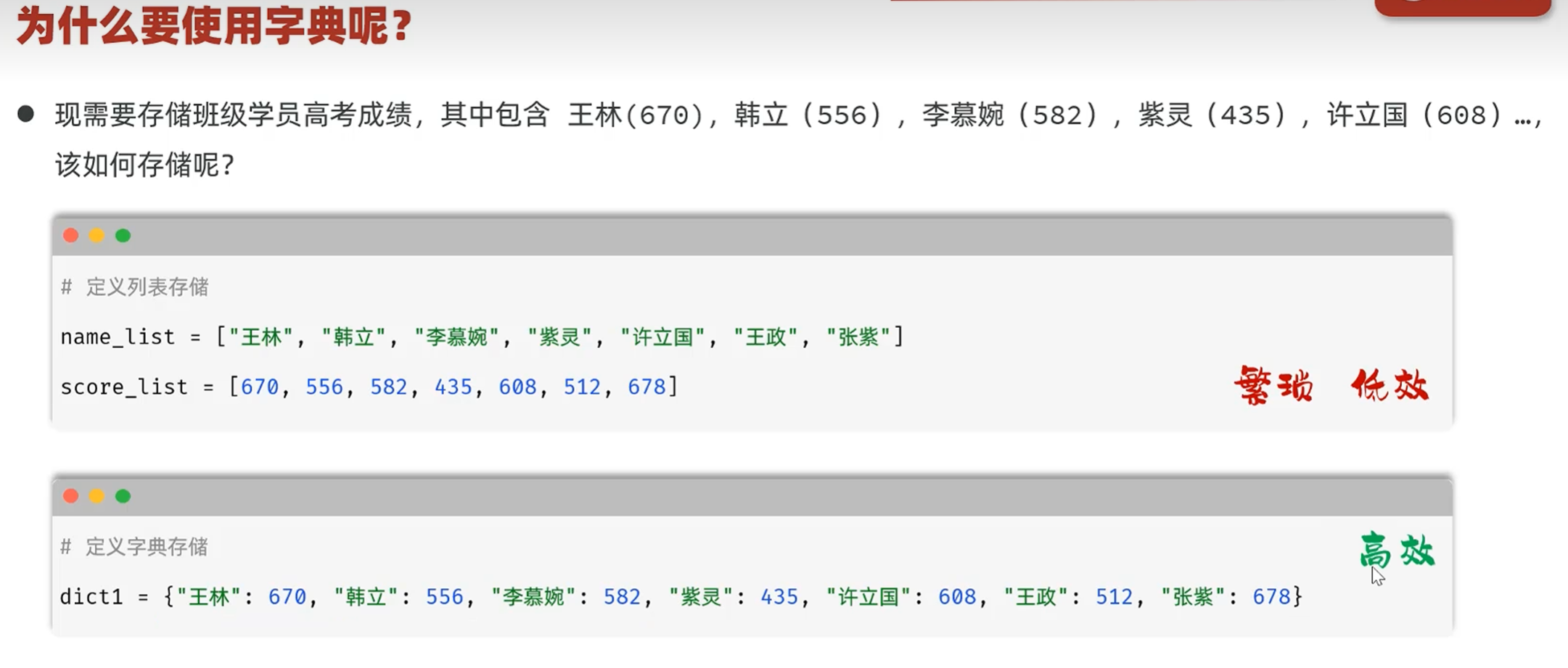
基本用法

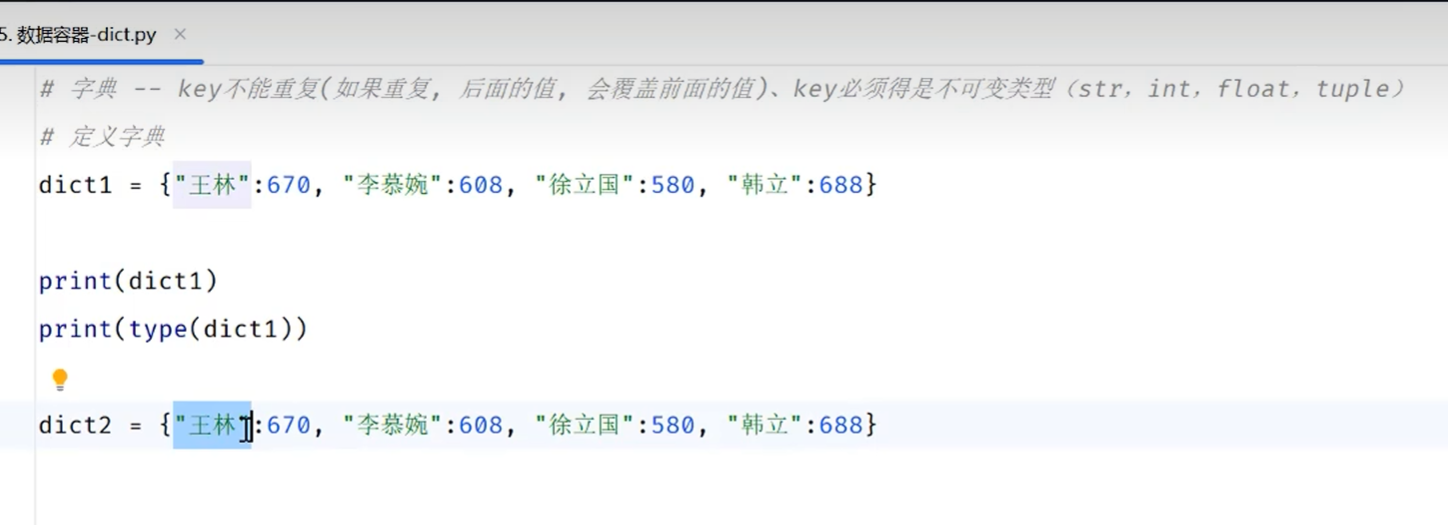
key不可重复而且得是不可变类型,key可以修改

-常用操作
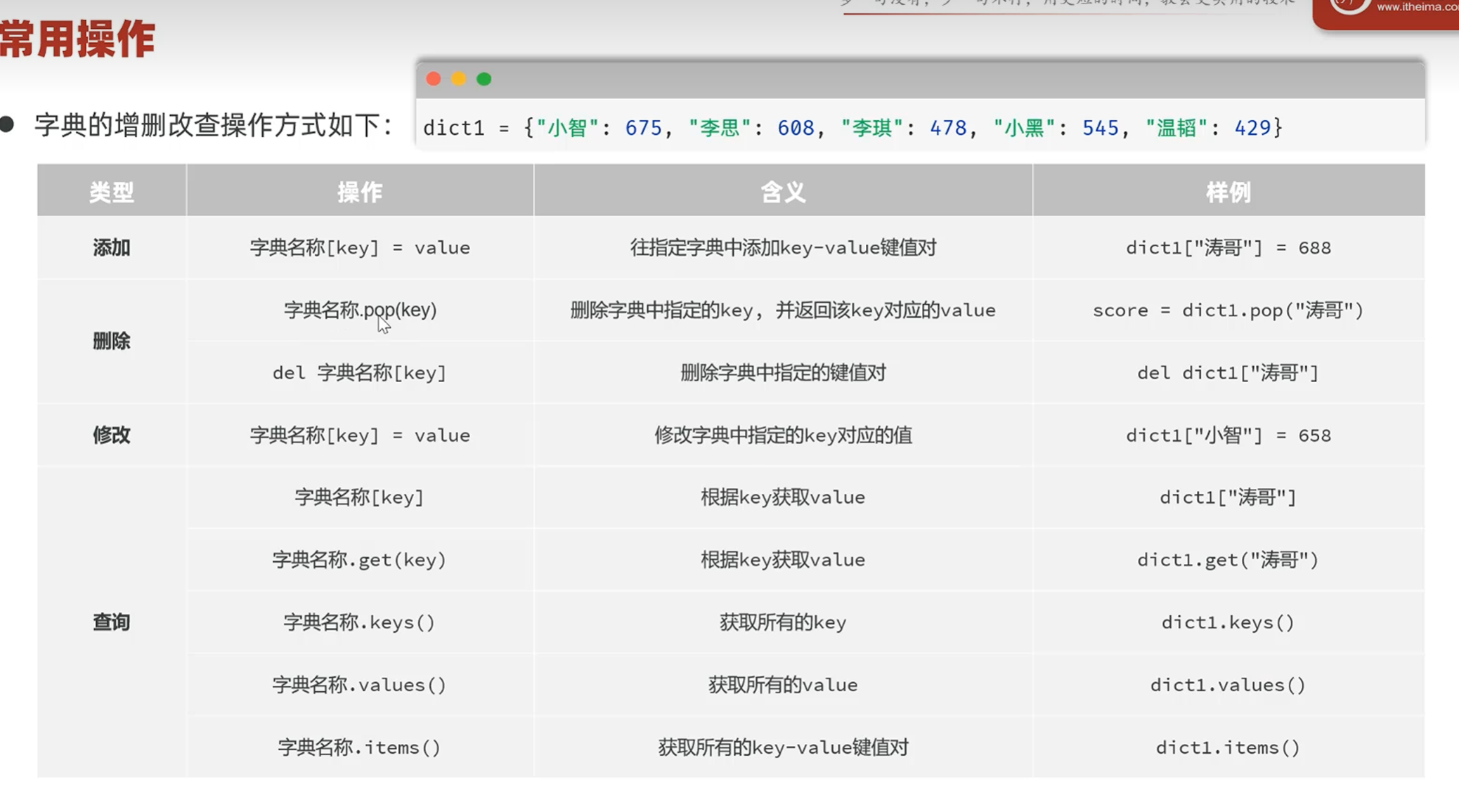
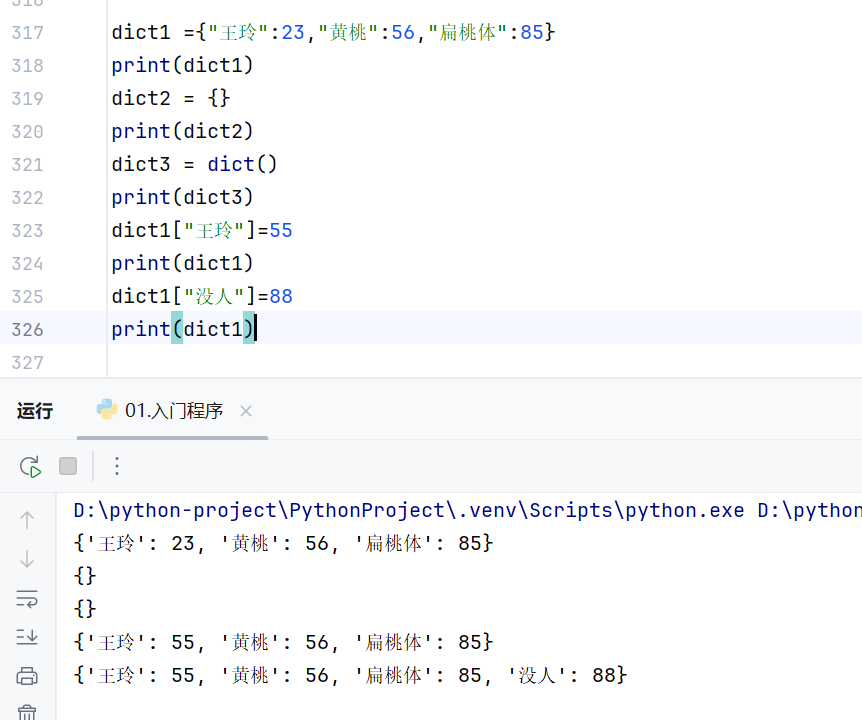
添加和修改:在key存在的时候为修改,在key不存在的时候为添加
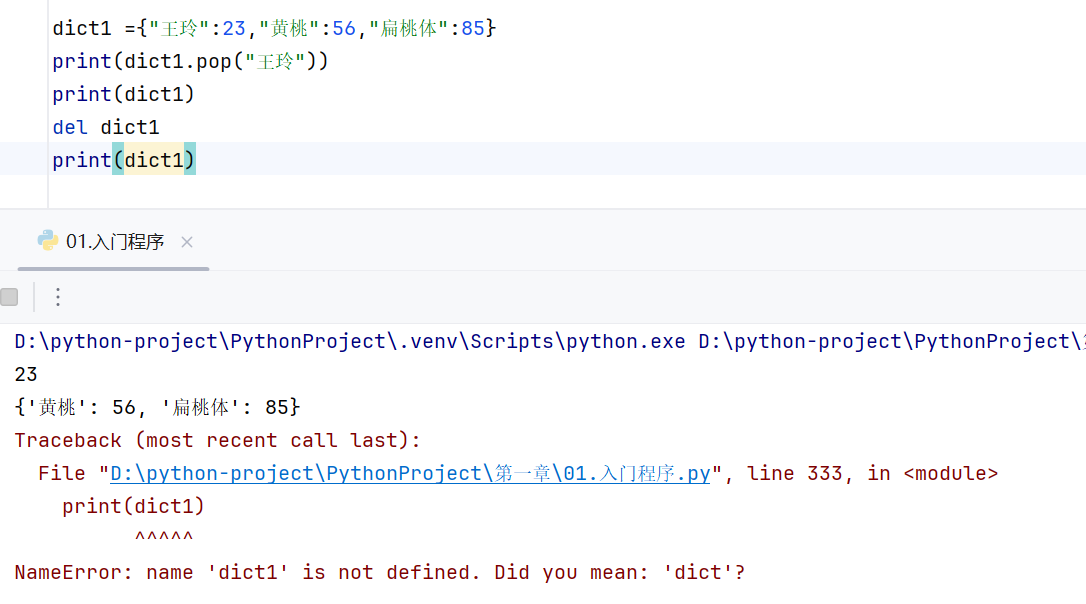
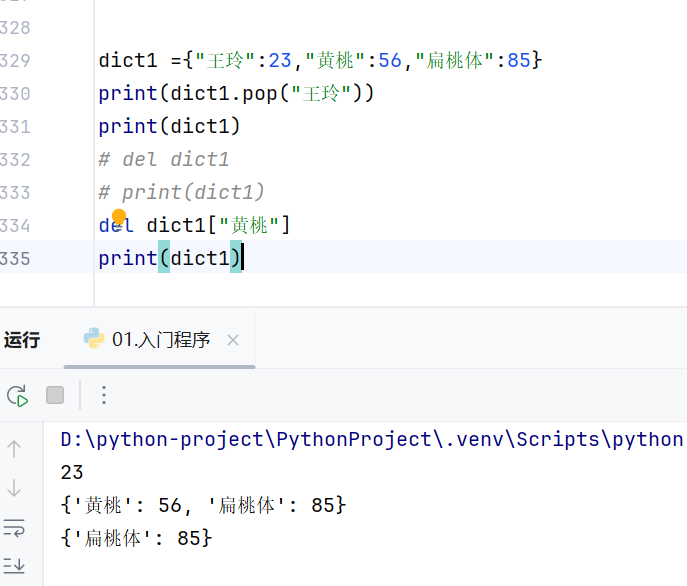
删除:pop方法可以根据key值把这个键值对删掉,
通过del+变量名命令删除变量本身
| 操作 | 作用 | 执行后变量状态 |
|---|---|---|
dict1.pop("key") |
删除指定键值对 | 变量仍存在,字典被修改 |
dict1.clear() |
清空所有键值对 | 变量仍存在,字典变为 {} |
del dict1["key"] |
删除指定键值对 | 变量仍存在,字典被修改 |
del dict1 |
删除变量本身 | 变量名从内存中移除,无法再访问 |
del+变量名[key]删除字典中键为key的键值对
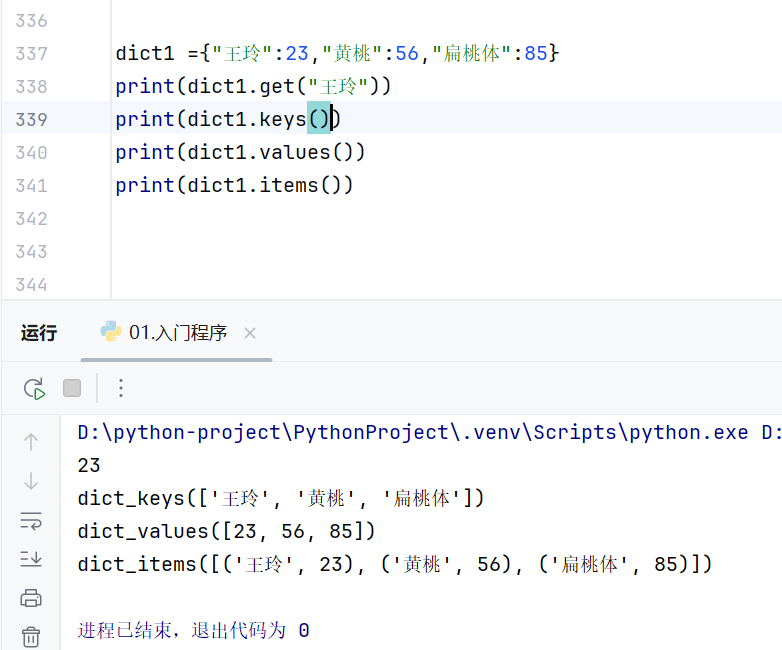
根据keys方法获取所有的键
根据values方法获取所有的值
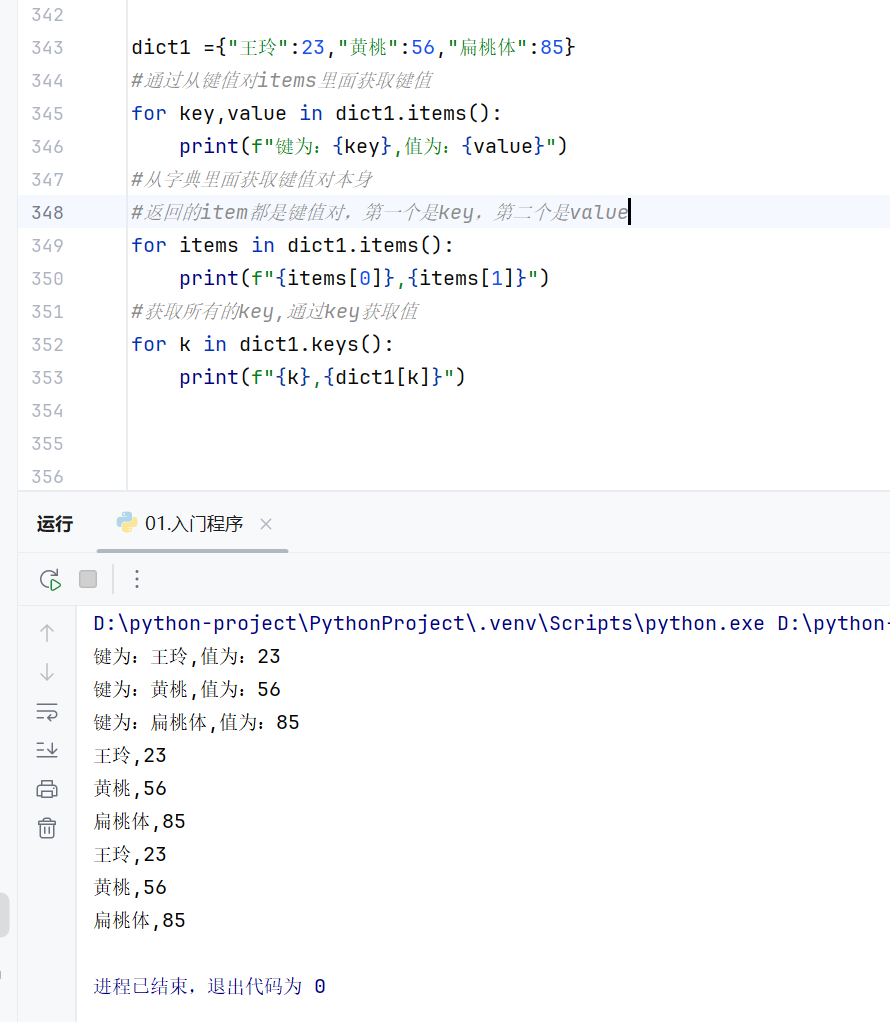
根据items方法获取所有的键值对
遍历

总结

-案例实现
-总结
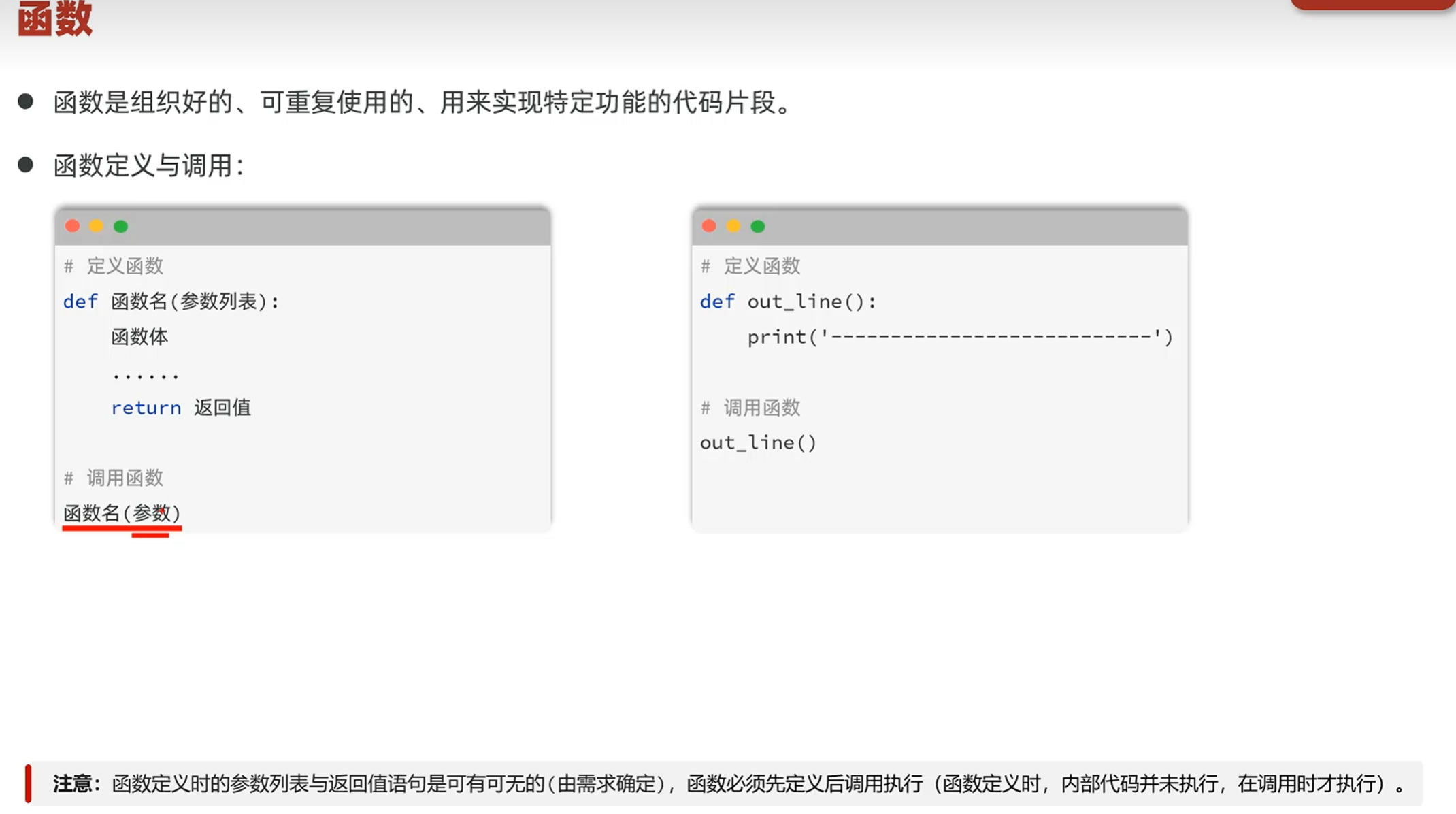
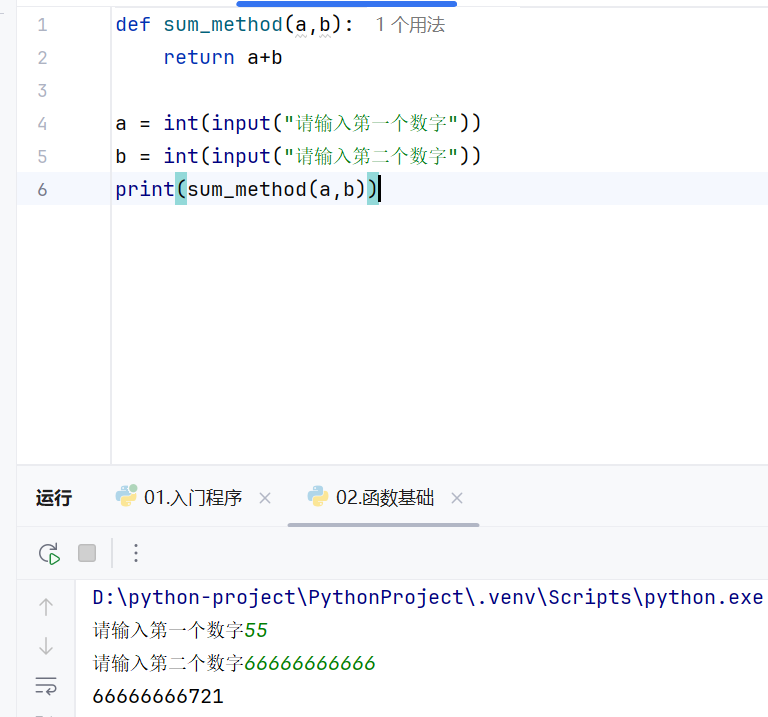
-函数基础
-介绍
-函数参数与返回值

-函数说明文档
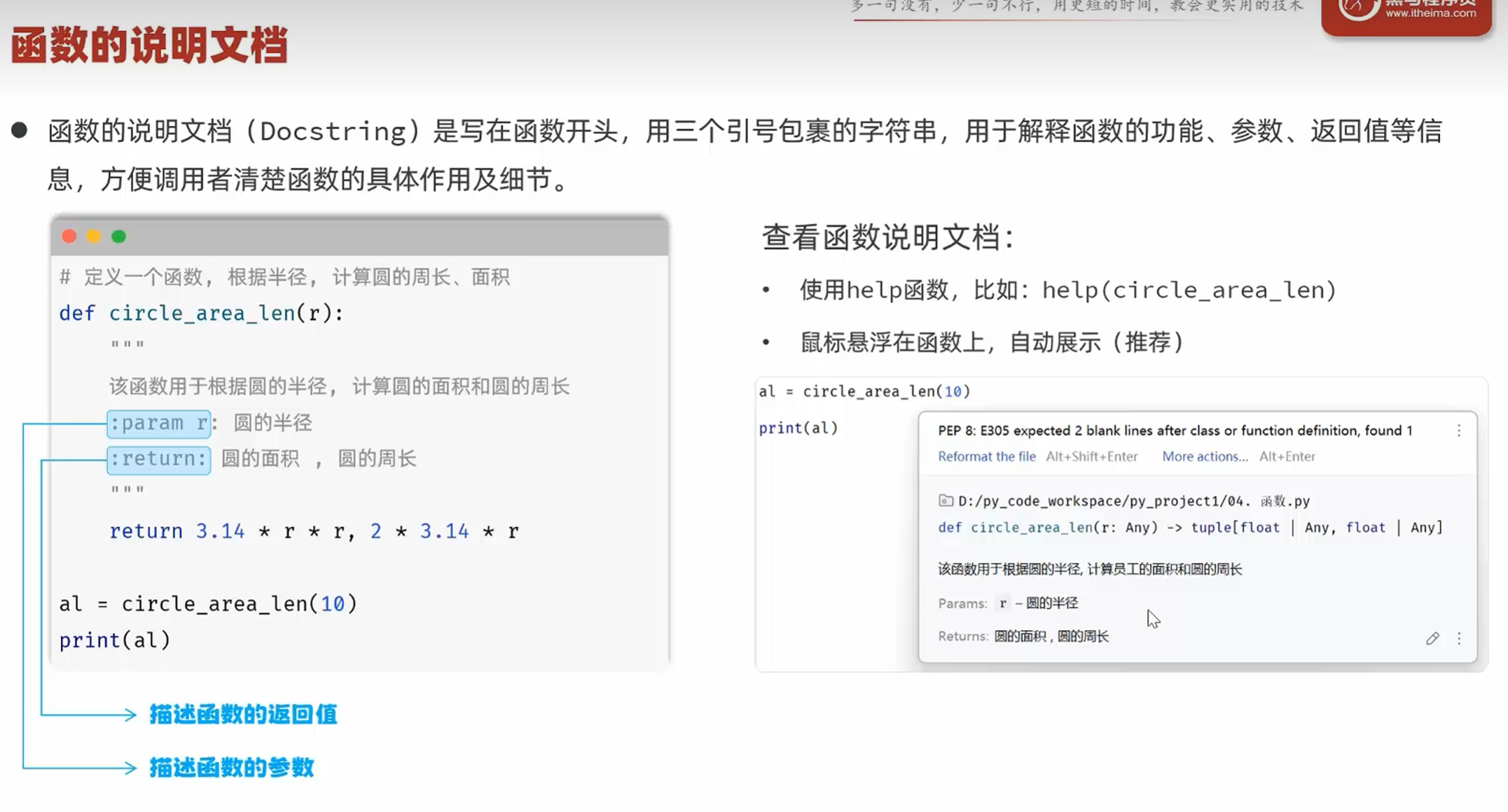
-函数嵌套调用
-案例
-函数进阶
-变量作用域
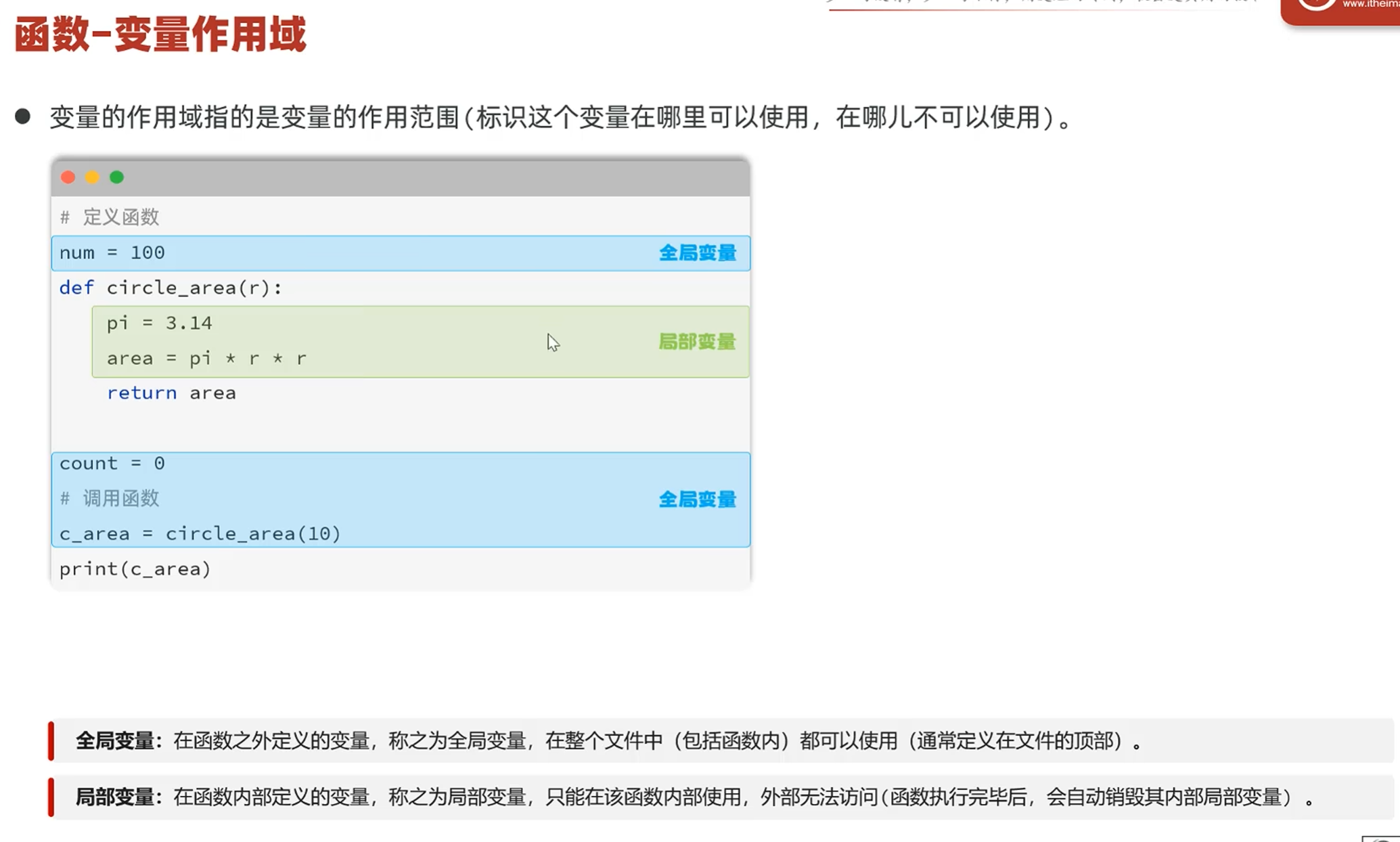
global全局变量
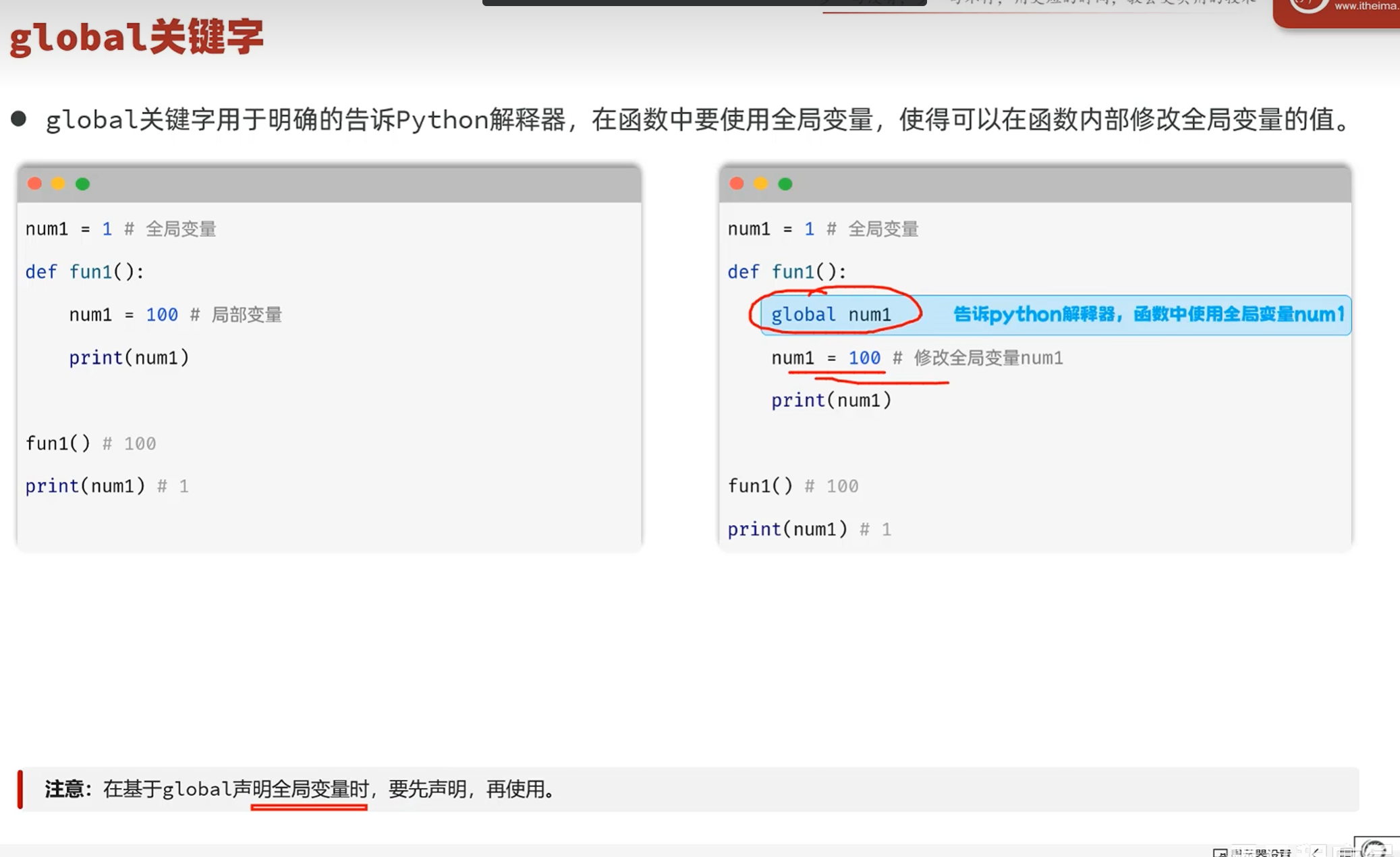

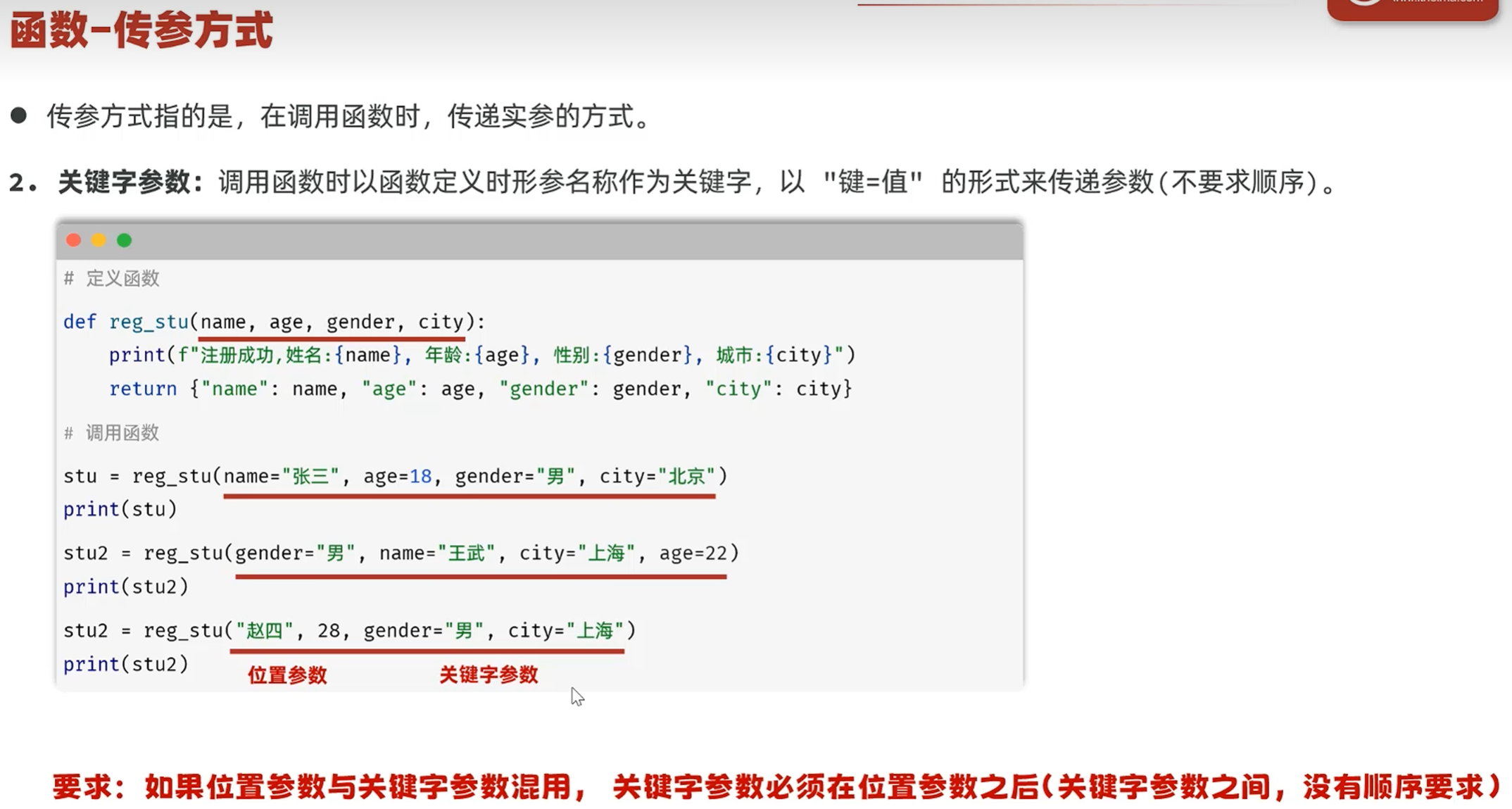
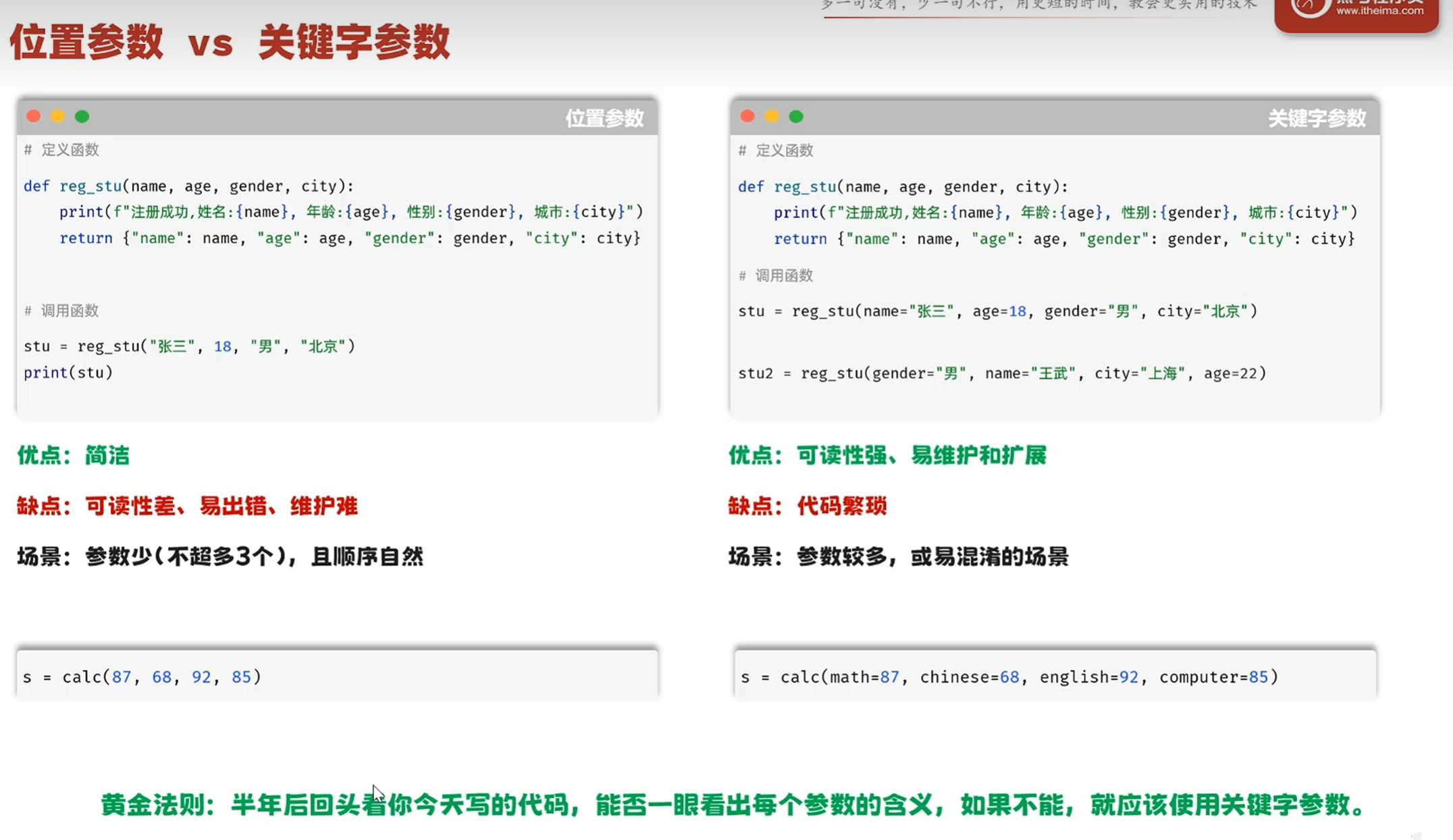
-传参方式
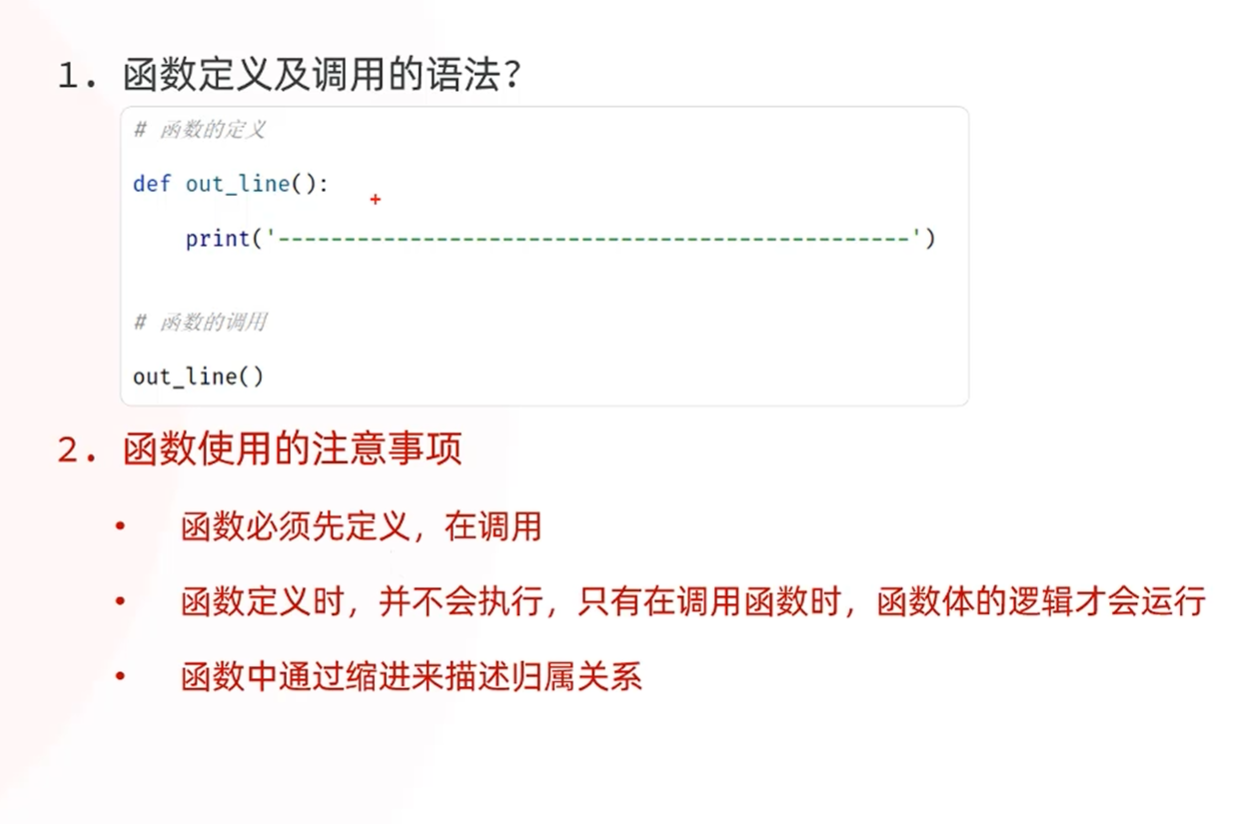
根据位置传递参数

形参的名称作为关键字
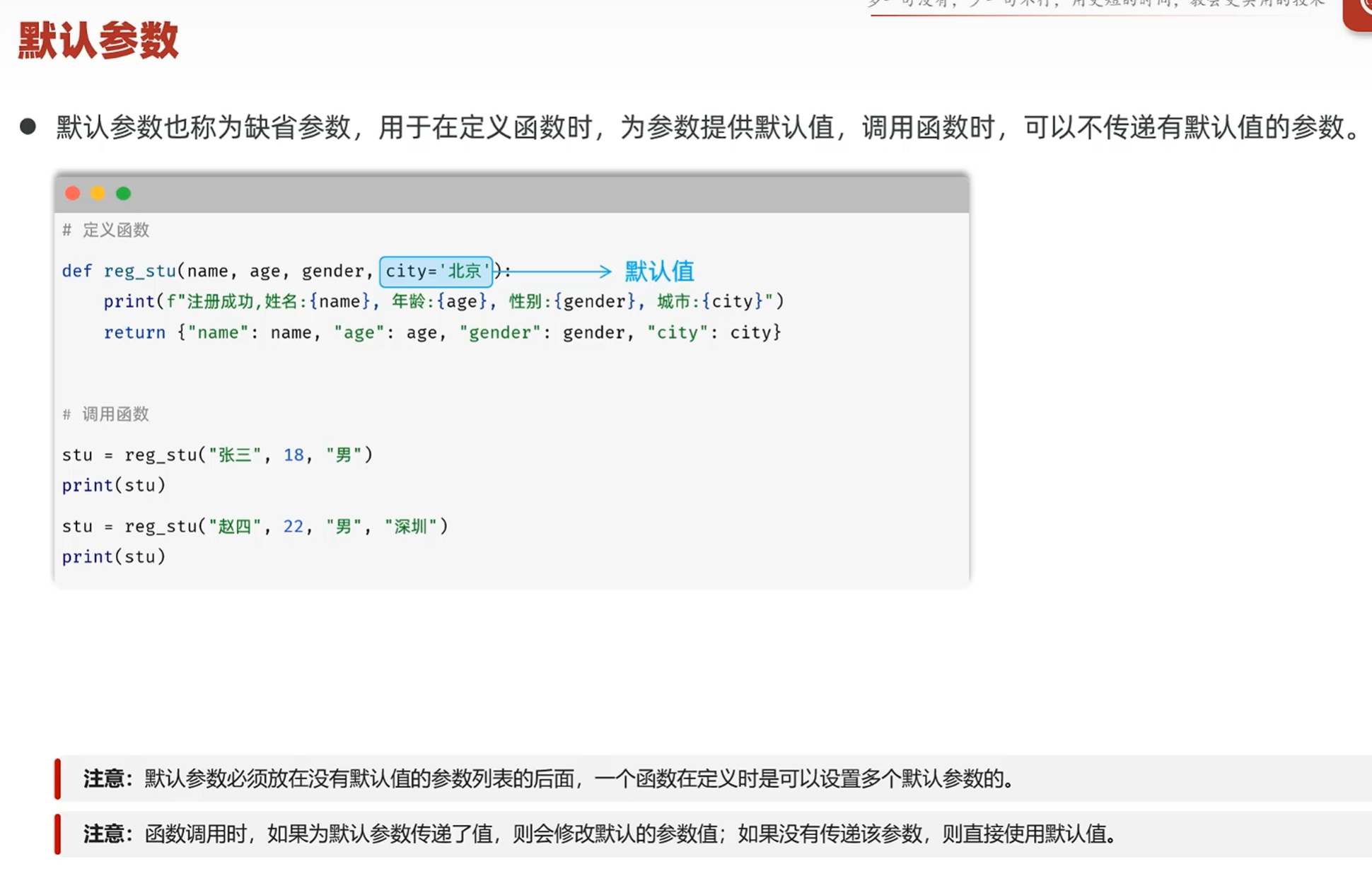
-默认参数
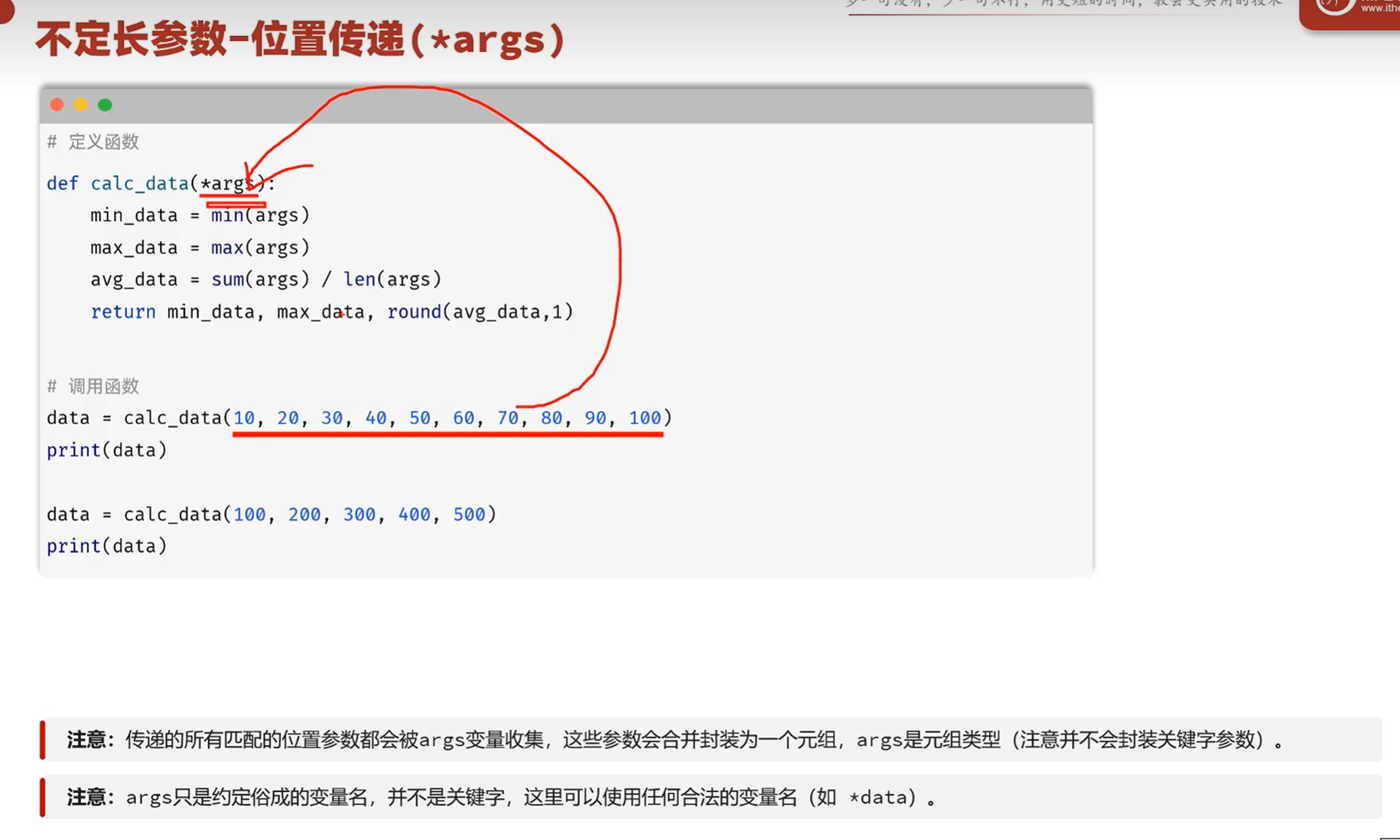
-不定长参数
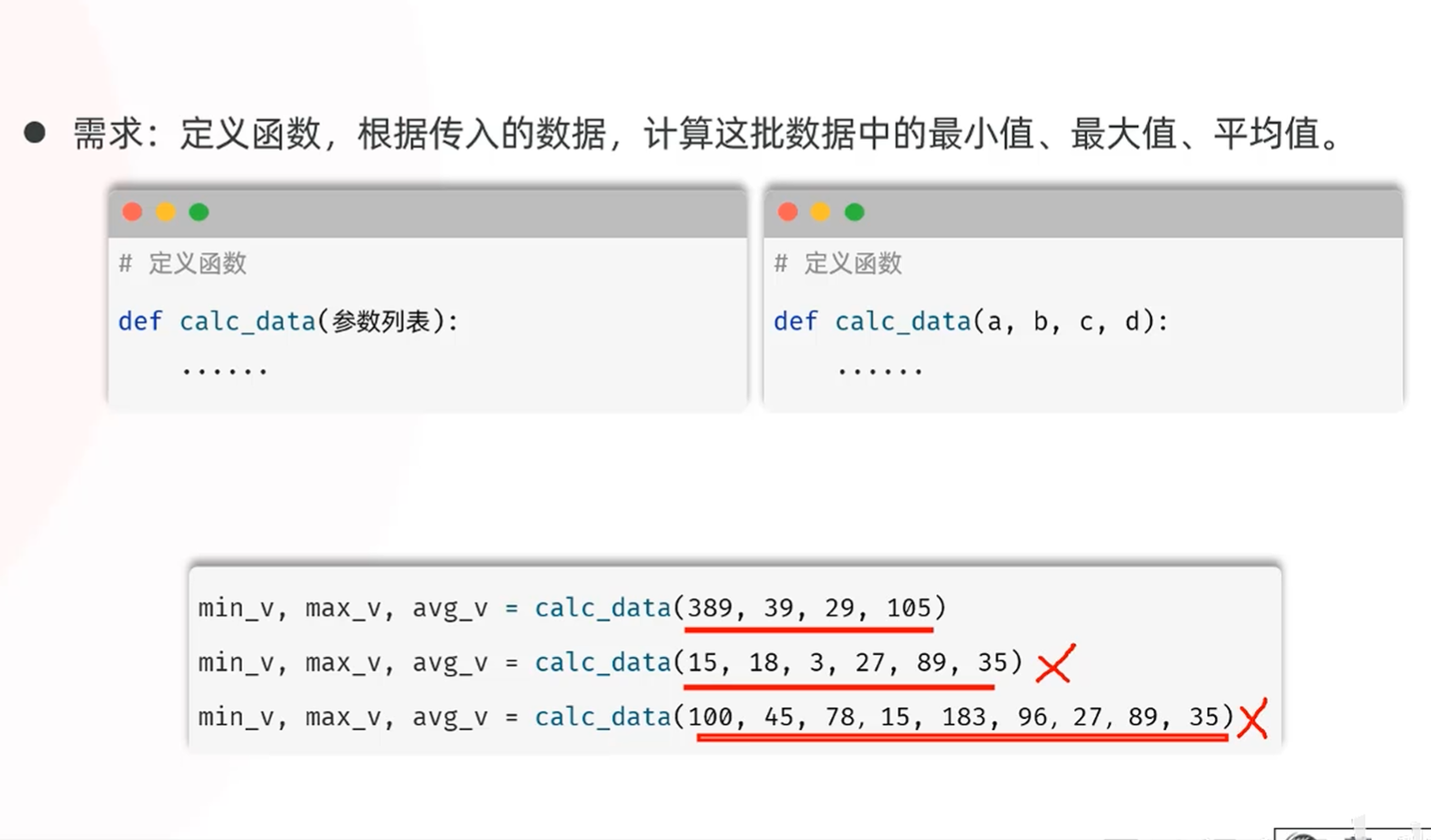
适用于传入的参数的数量不一定的时候
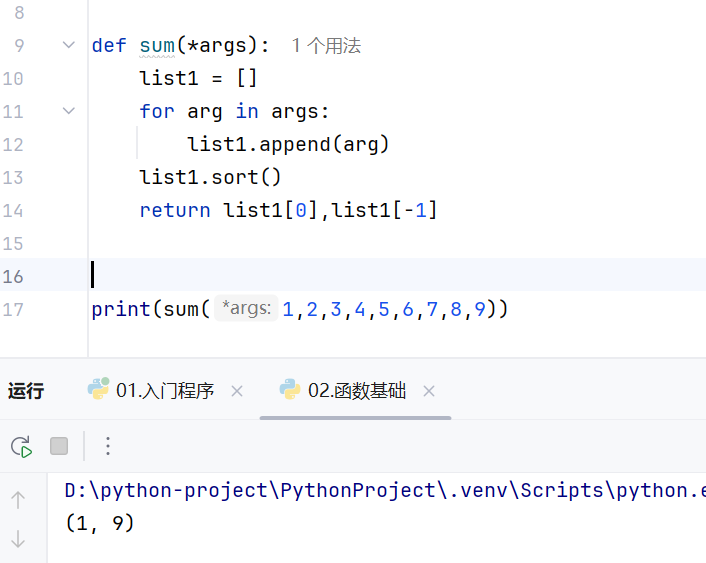
*args参数 接受所有的位置参数,并封装为元组
**kwargs参数 接收所有的关键字参数,并封装为字典类型
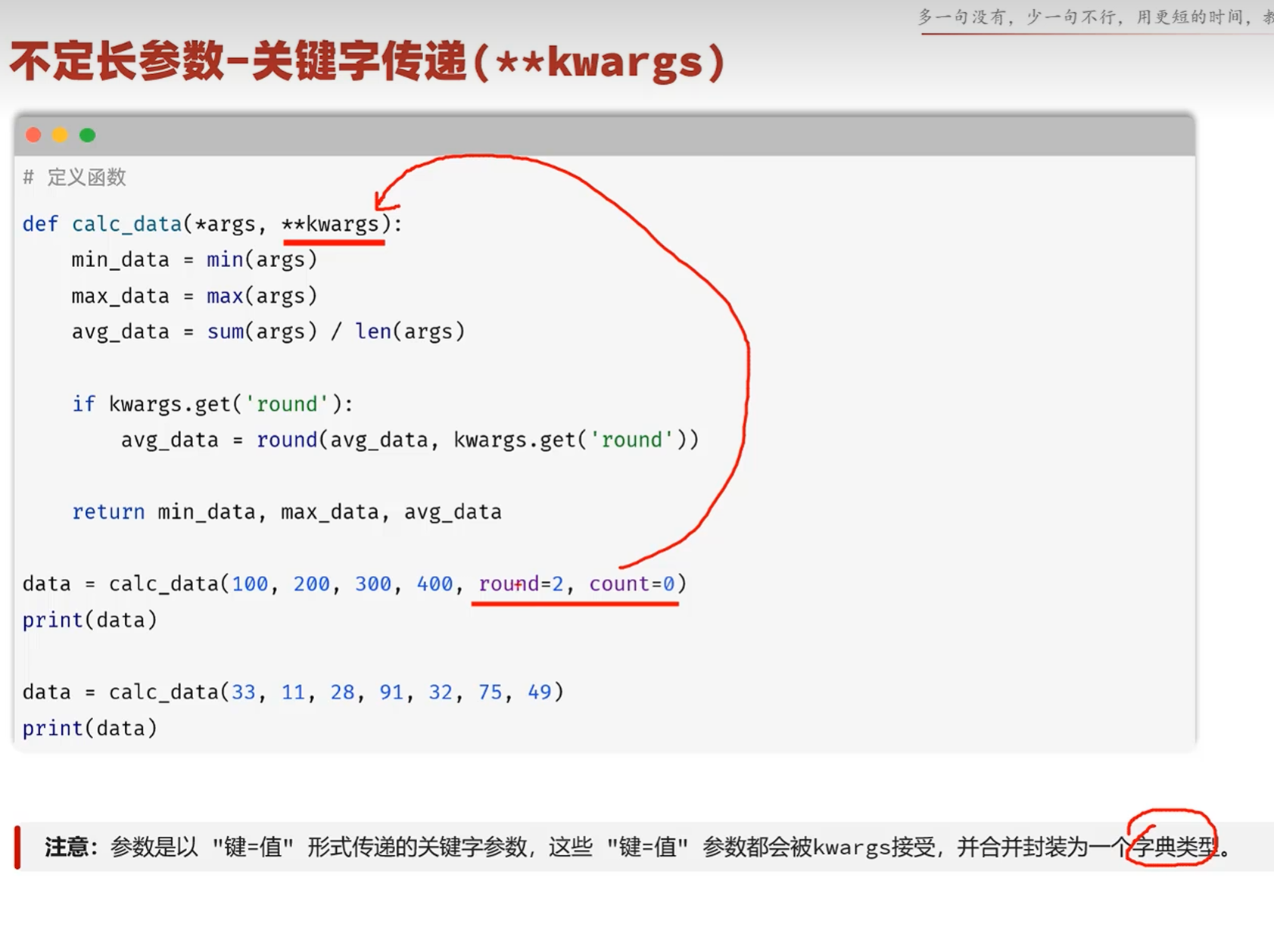
**kwargs参数适用于处理数量不确定的选项(函数的配置参数,用来定制函数的行为)
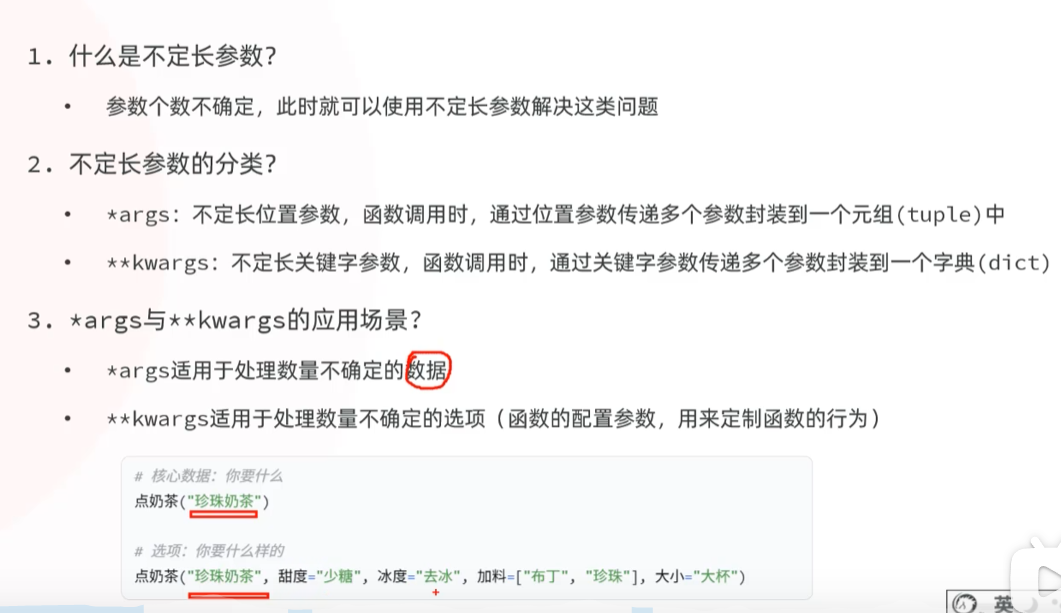
-参数类型(函数作为参数)
-匿名函数(lambda表达式)
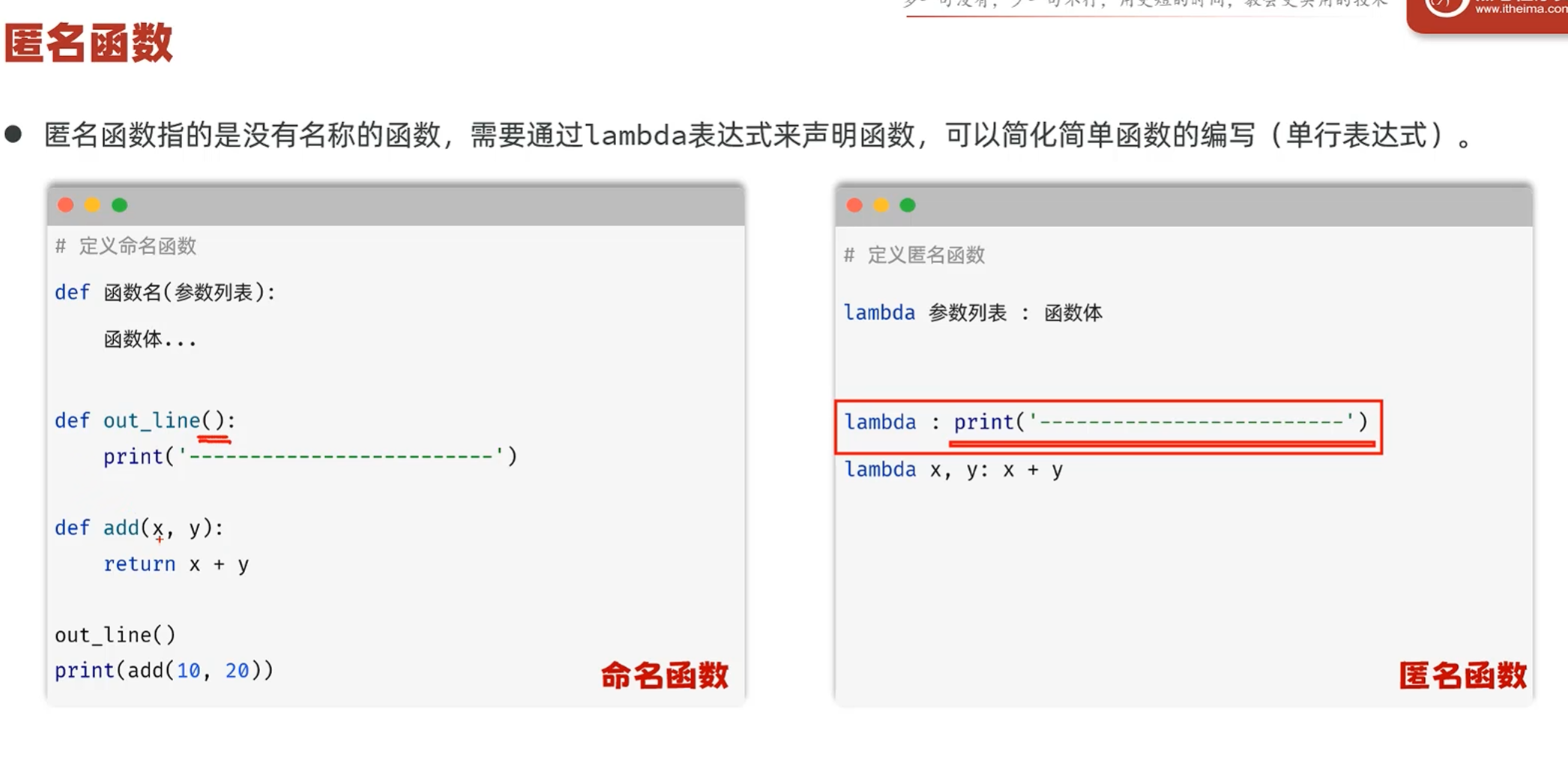
匿名函数:没有函数名的函数,只有参数列表和函数体

匿名函数主要用于高阶函数的参数部分
由于匿名函数没有名字,需要调用的话只能拿一个变量来接收
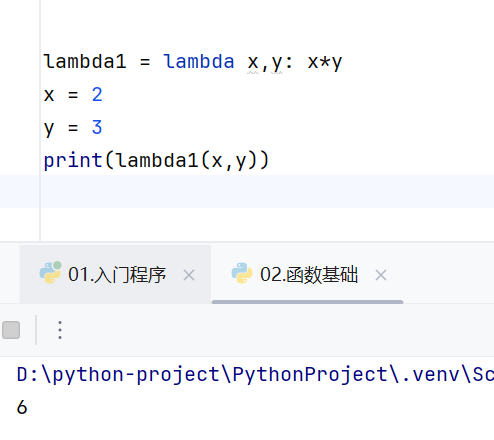
要调用函数的之后直接变量名()就可以调用了
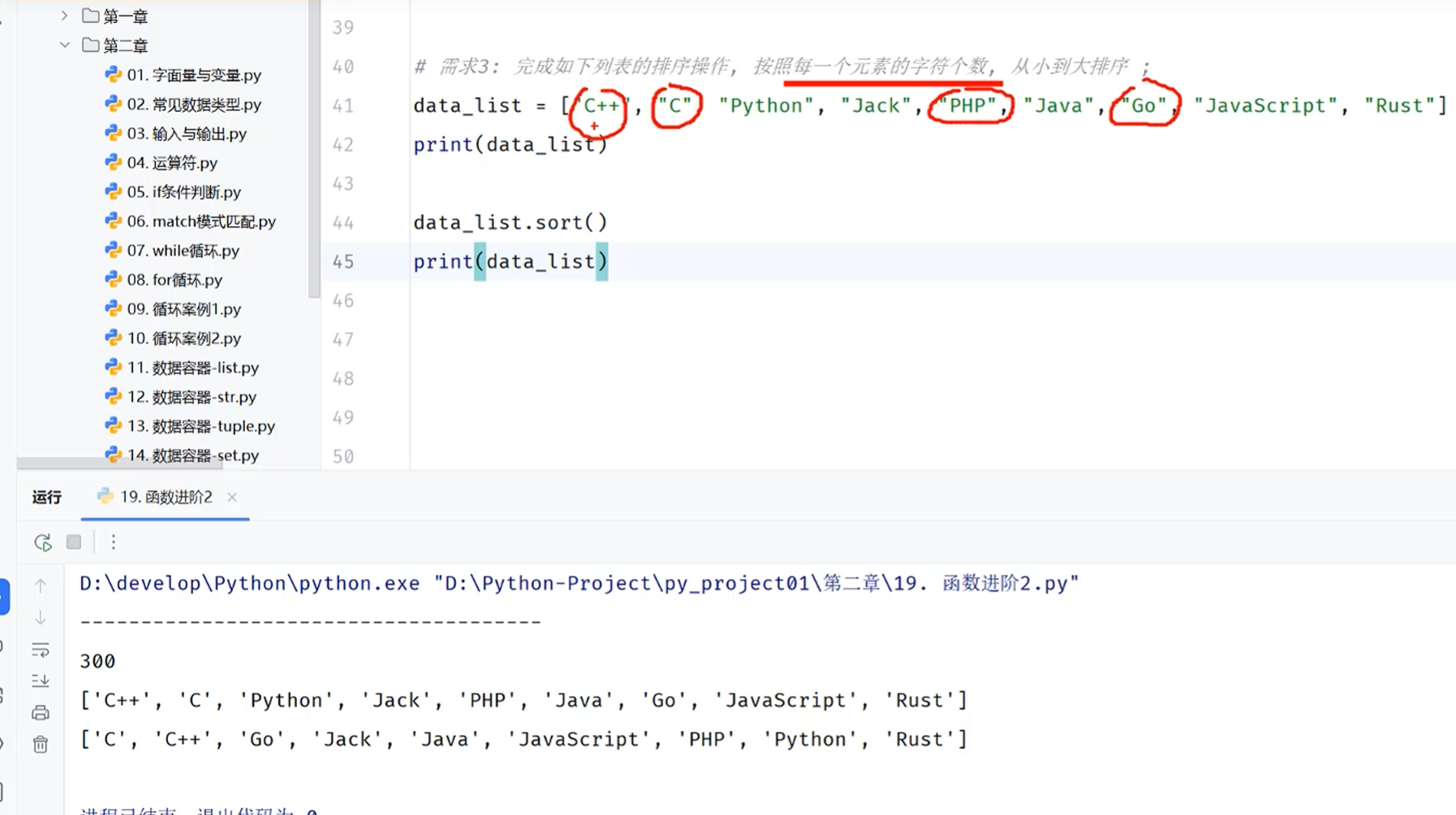
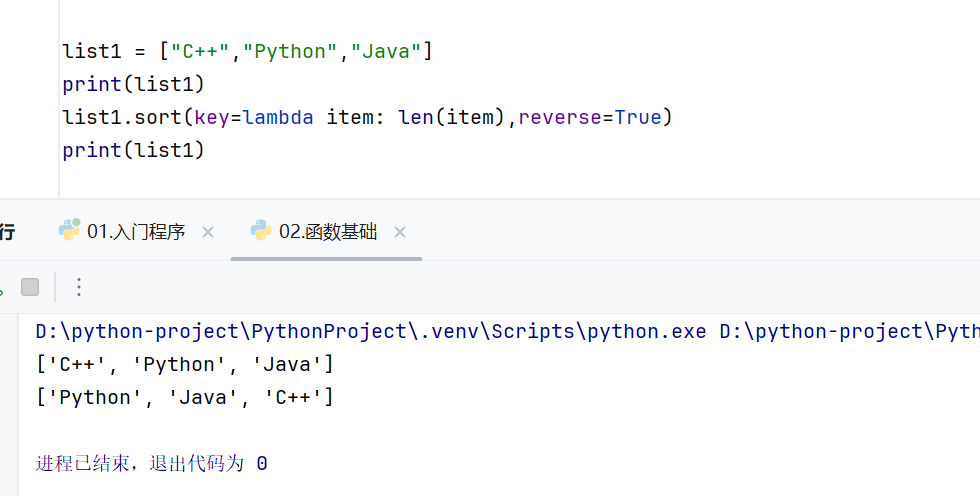
列表的排序规则和我们的要求不符
列表的排序规则是:按照字母大小A>B>C(也就是按照字母顺序)
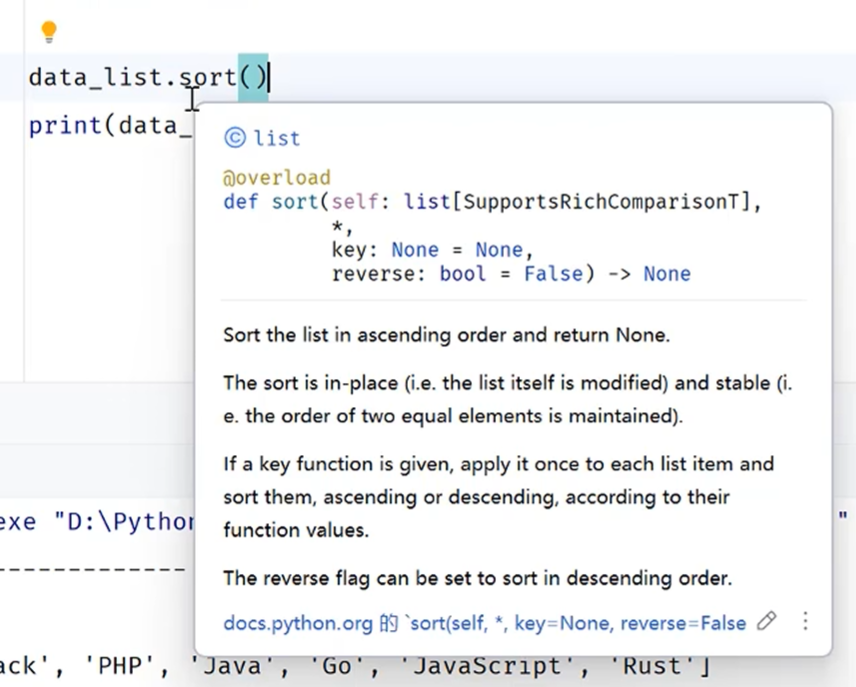
列表的排序方法中给我们提供了自定义的排序方法
可以根据我们自己的需求来指定排序方式

在key里面可以修改函数的排序方式
在reverse里面可以指定是要从小到大排序,还是从大到小排序
默认情况下:key=None reverse=false
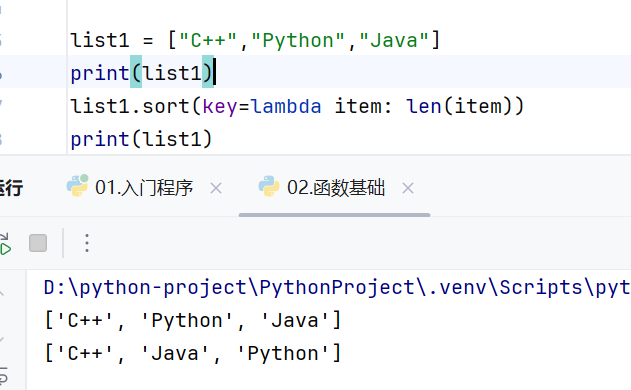
倒序输出为

-案例1(递归)
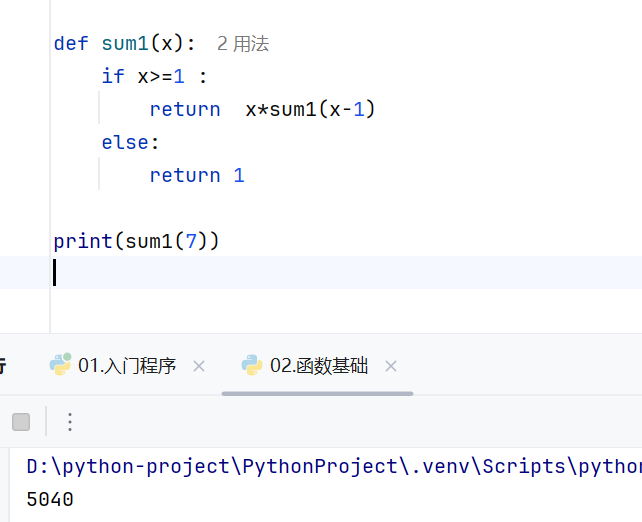
-案例2
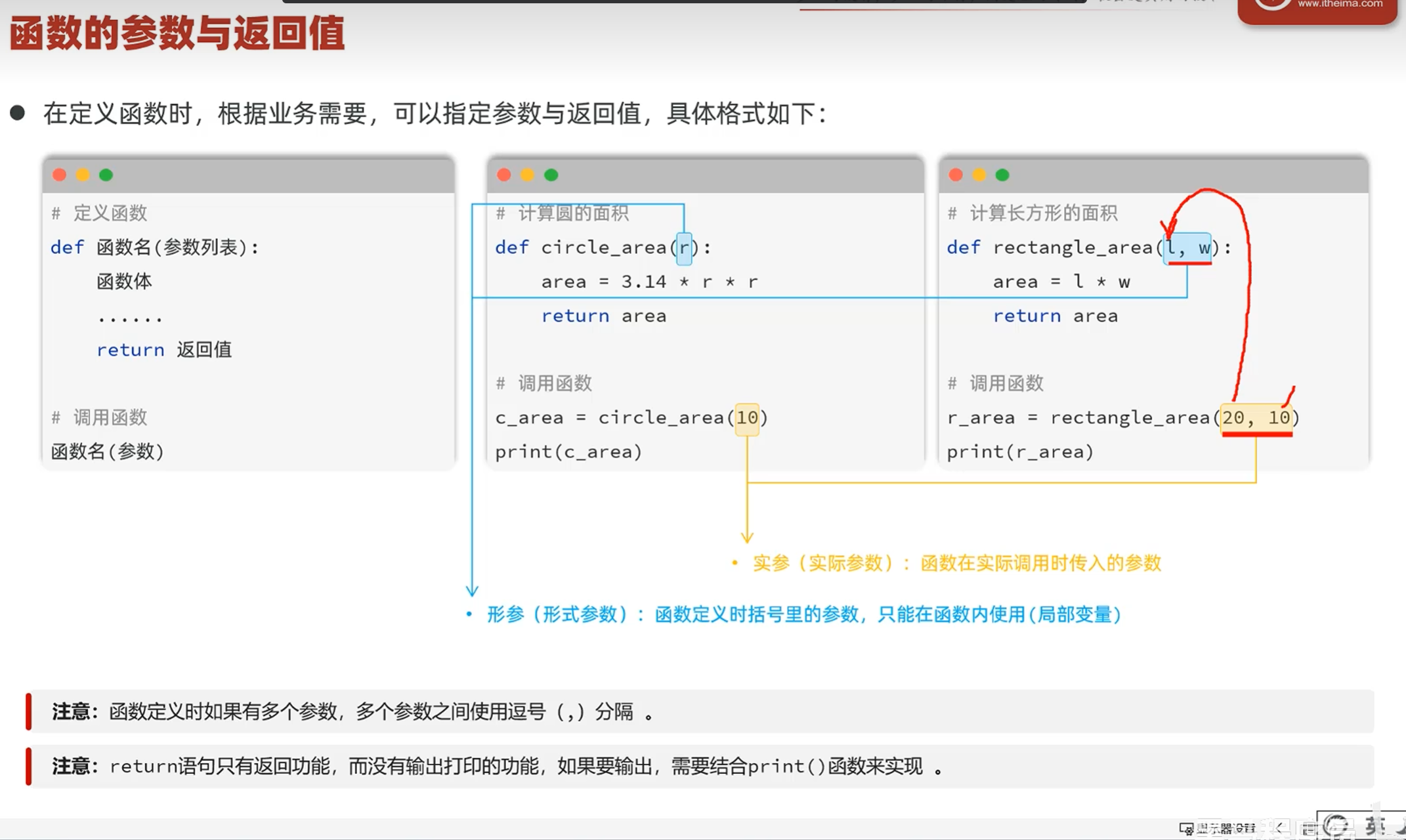
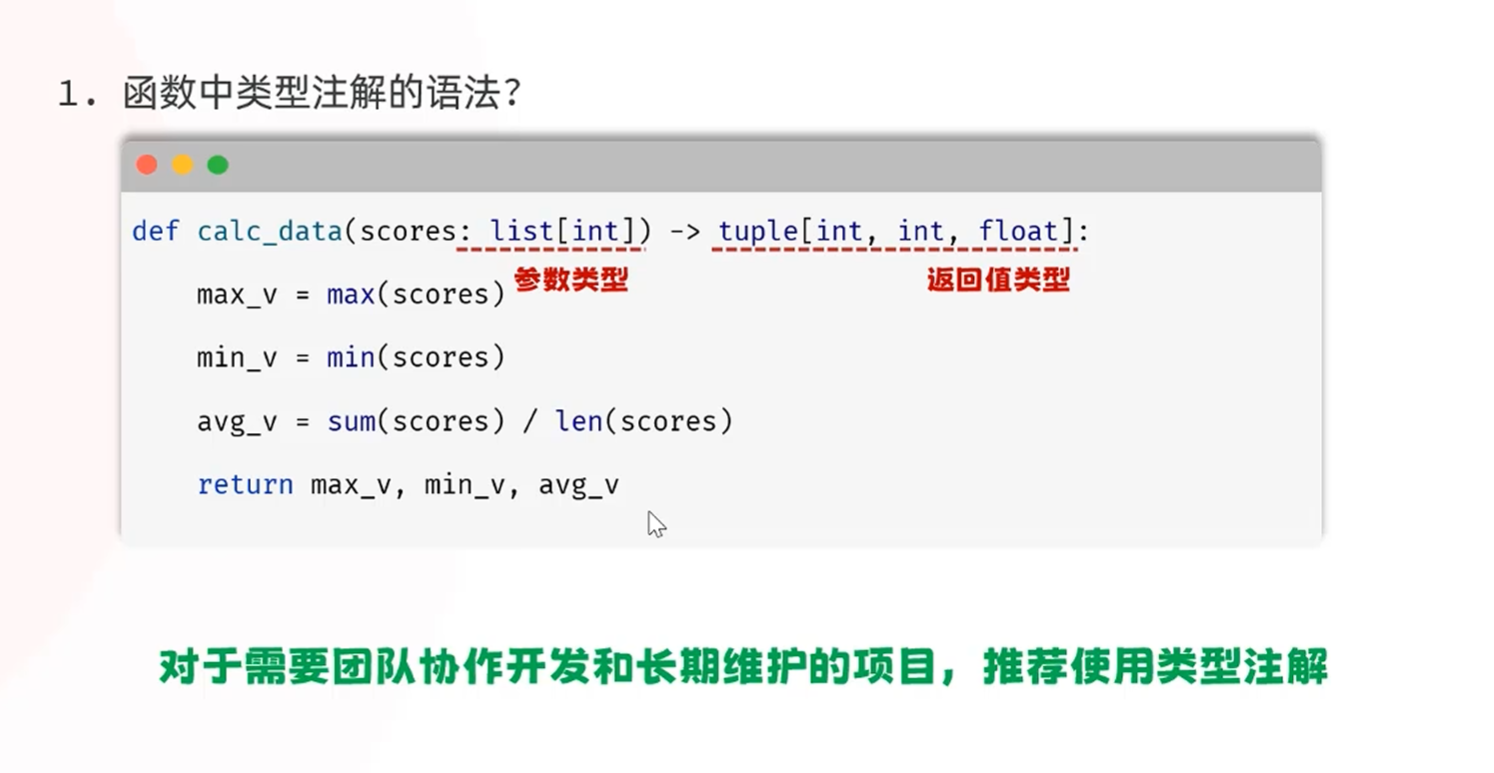
-类型注解
-介绍
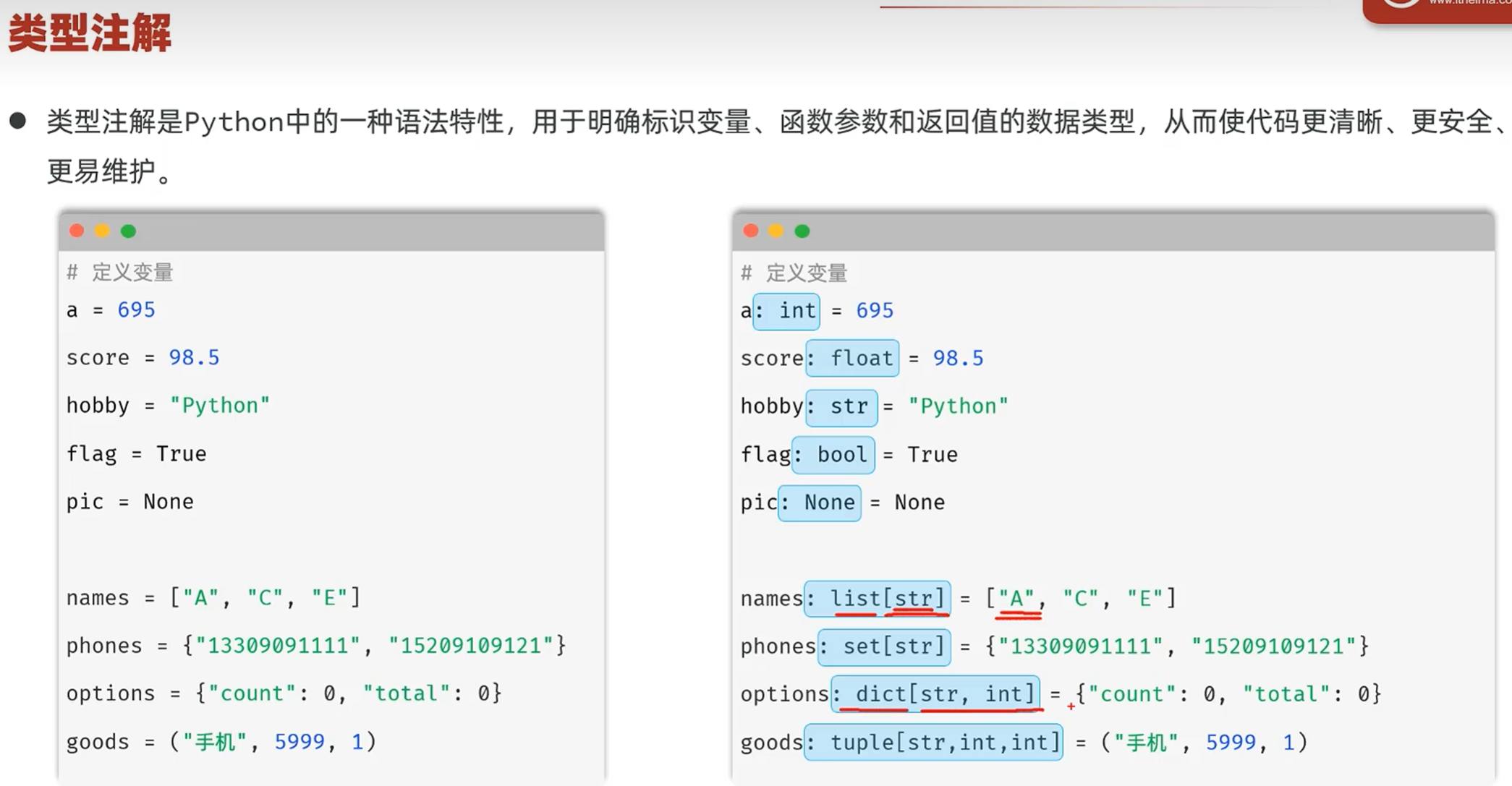
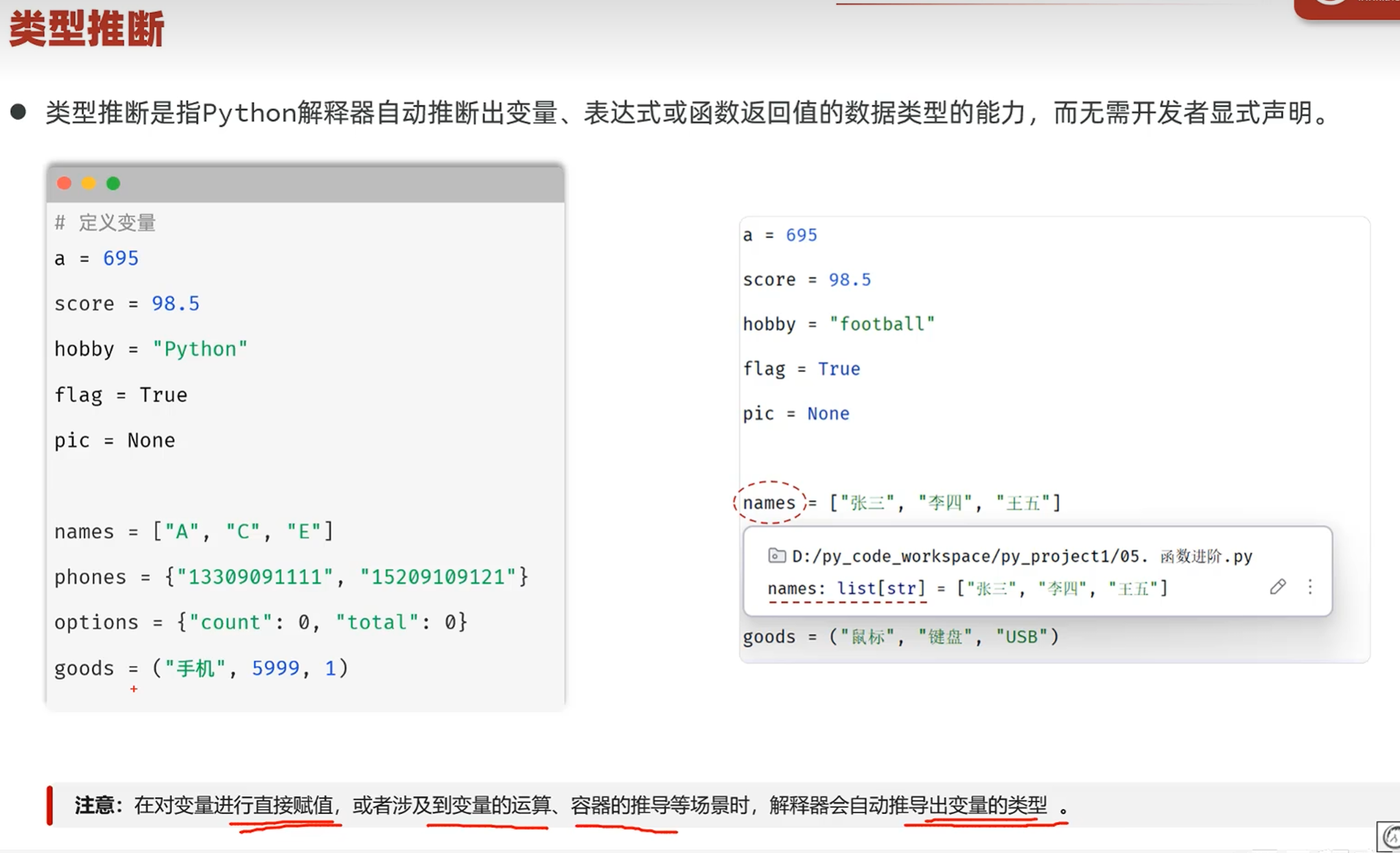

-函数的类型注解
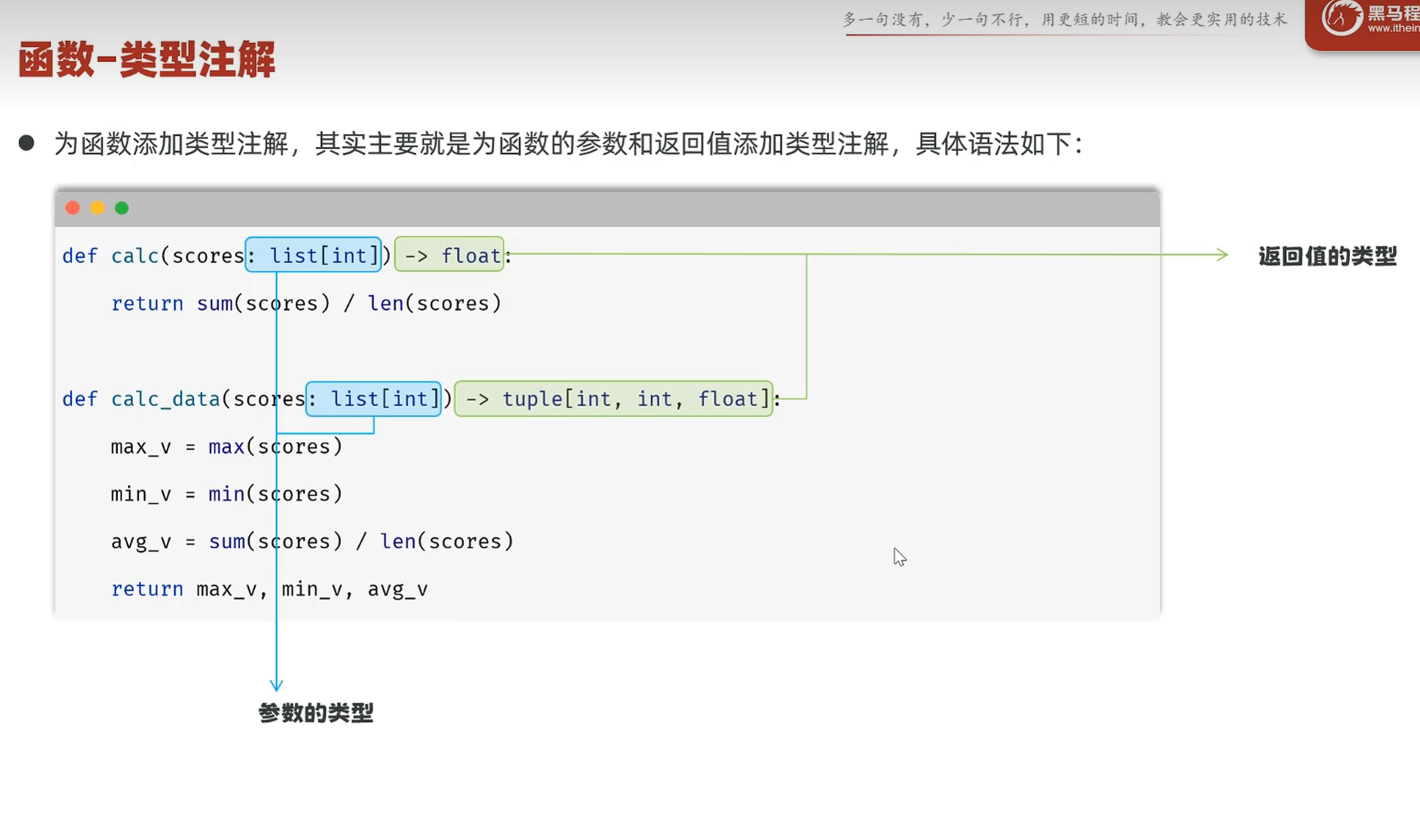
类型注解在变量赋值的时候可以根据赋的值来推断参数的类型(在变量修改或添加的时候自动推断)
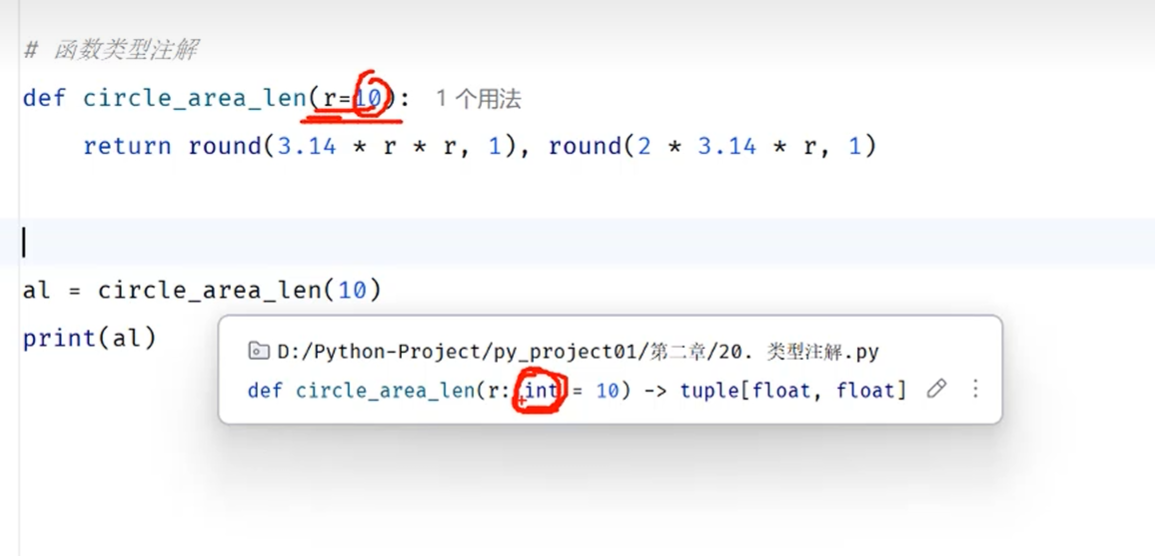
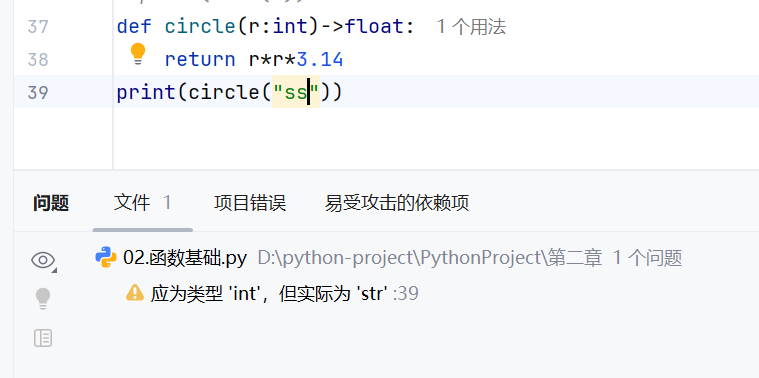
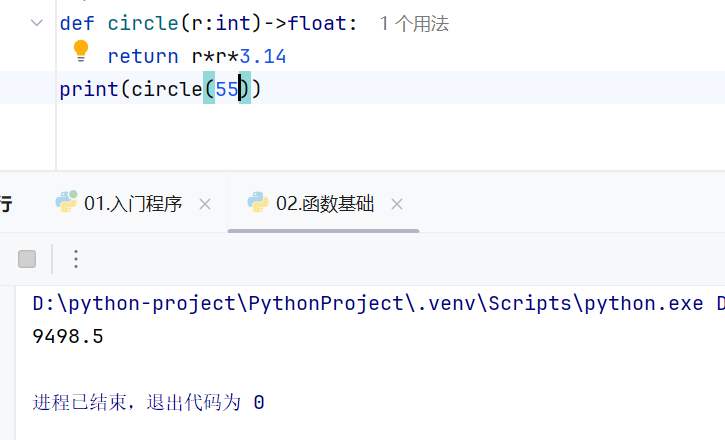
函数:1.在函数参数部分指定函数参数的返回类型
2.给函数参数赋绝对值时可以进行类型推断
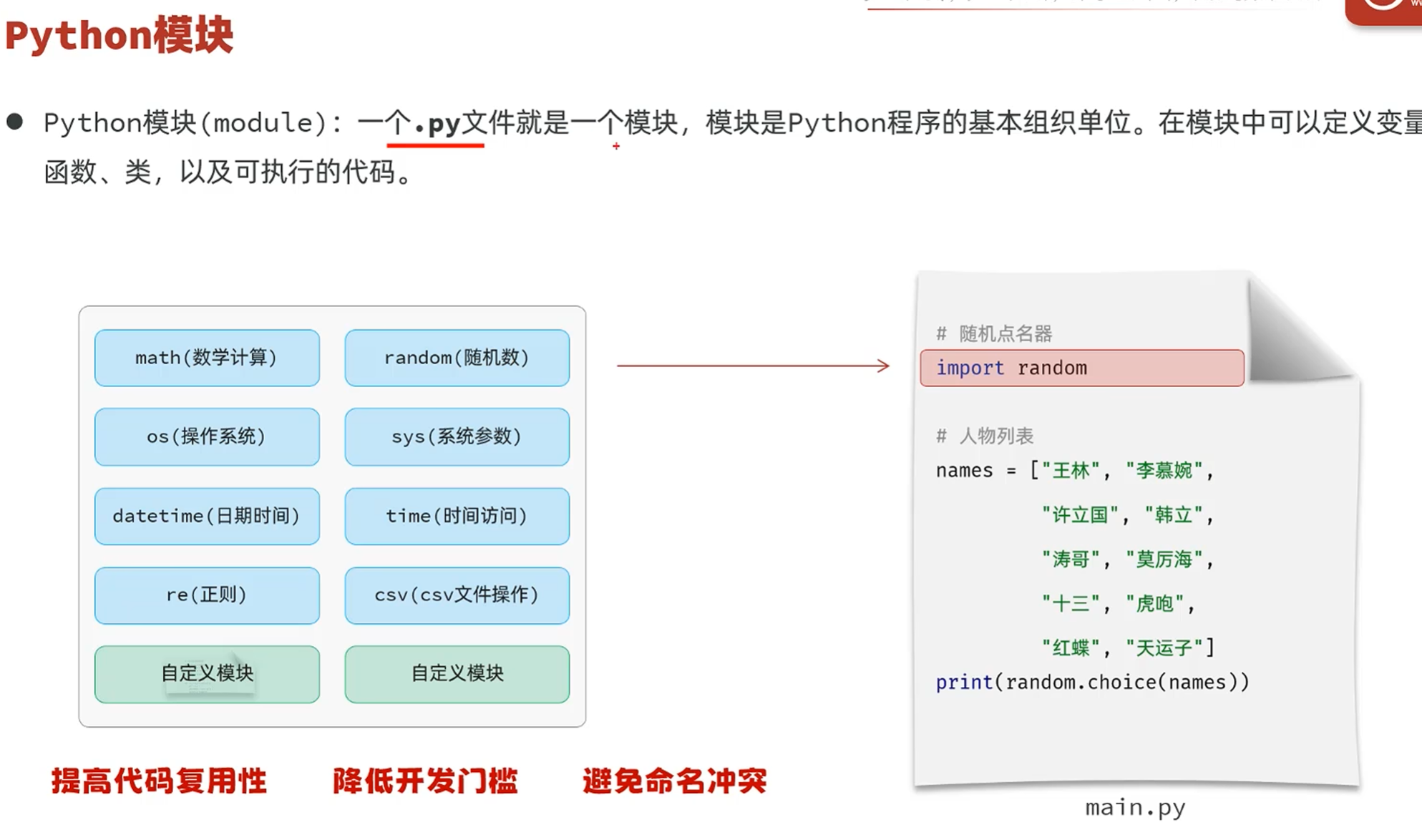
-模块
-介绍

一个.py文件就是一个模块
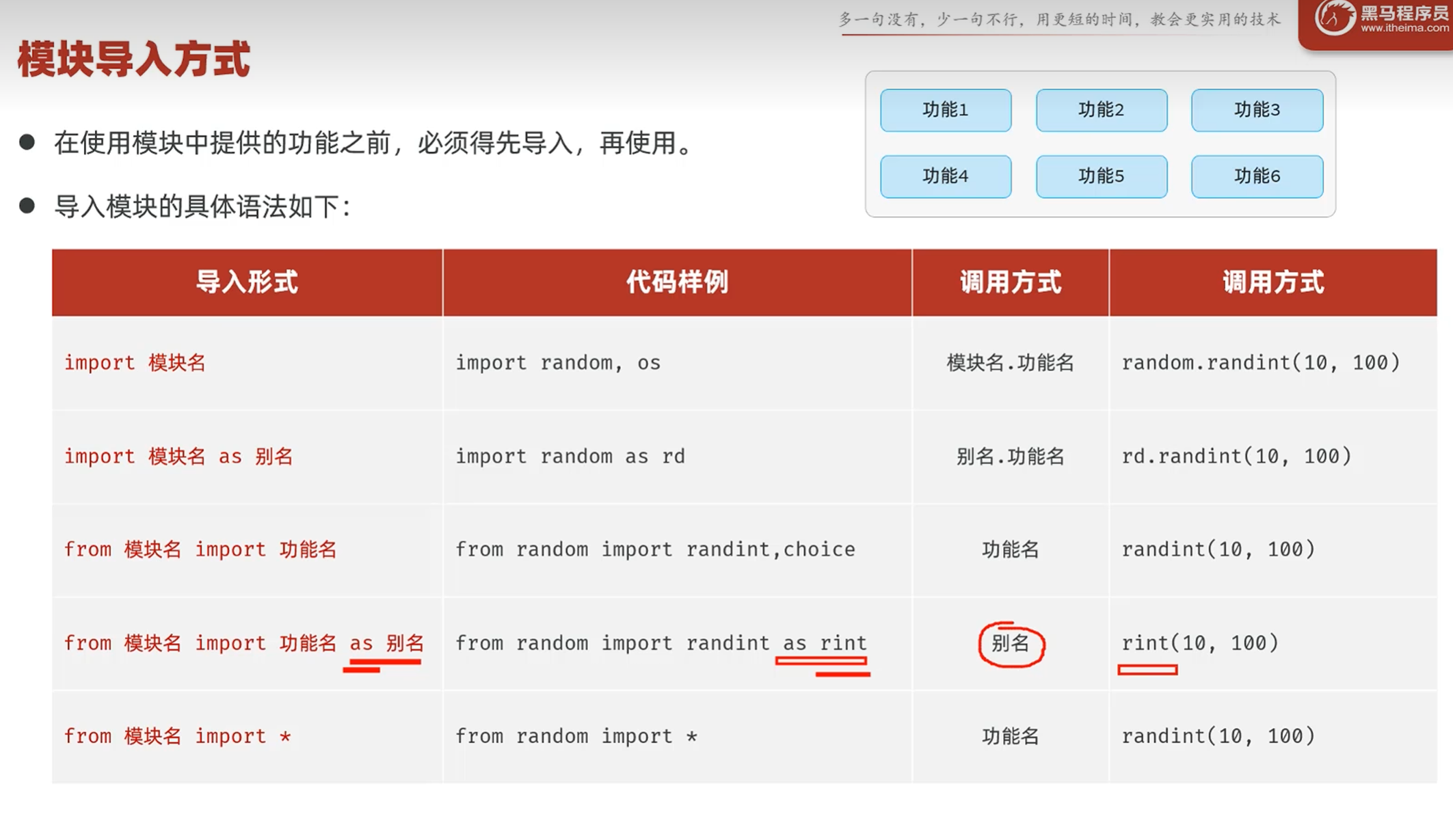
-导入模块
把模块比作一个盒子,功能是里面的工具,只导入盒子还要拿出来
只导入模块的时候,如果要调用里面的功能,还需要用模块名.功能名的方式来调用
导入模块内的功能的时候,可以直接调用功能
导完包之后,如果不用,会显示灰色
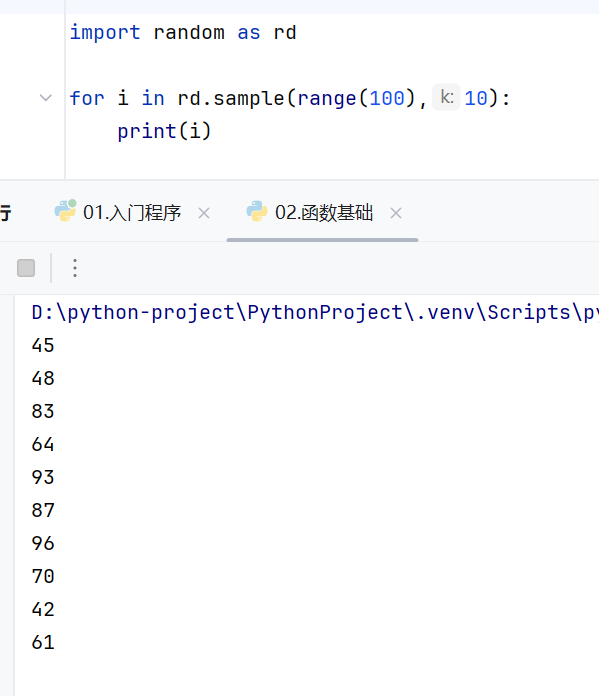
导包可以用包名调用方法,也可以用给包名起的别名来调用
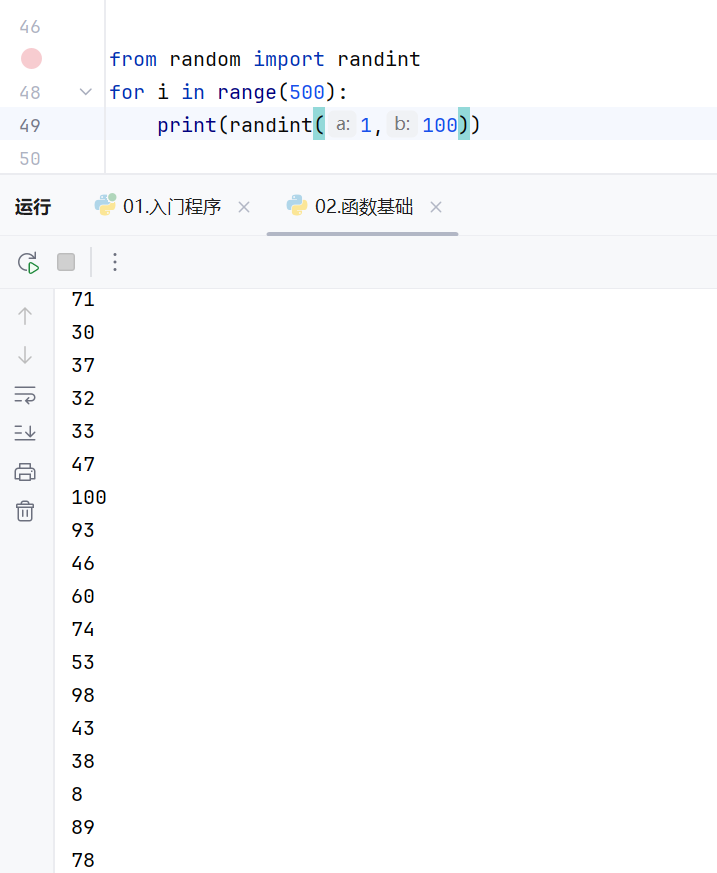
导入包内的方法之后,可以直接调用方法

-自定义模块
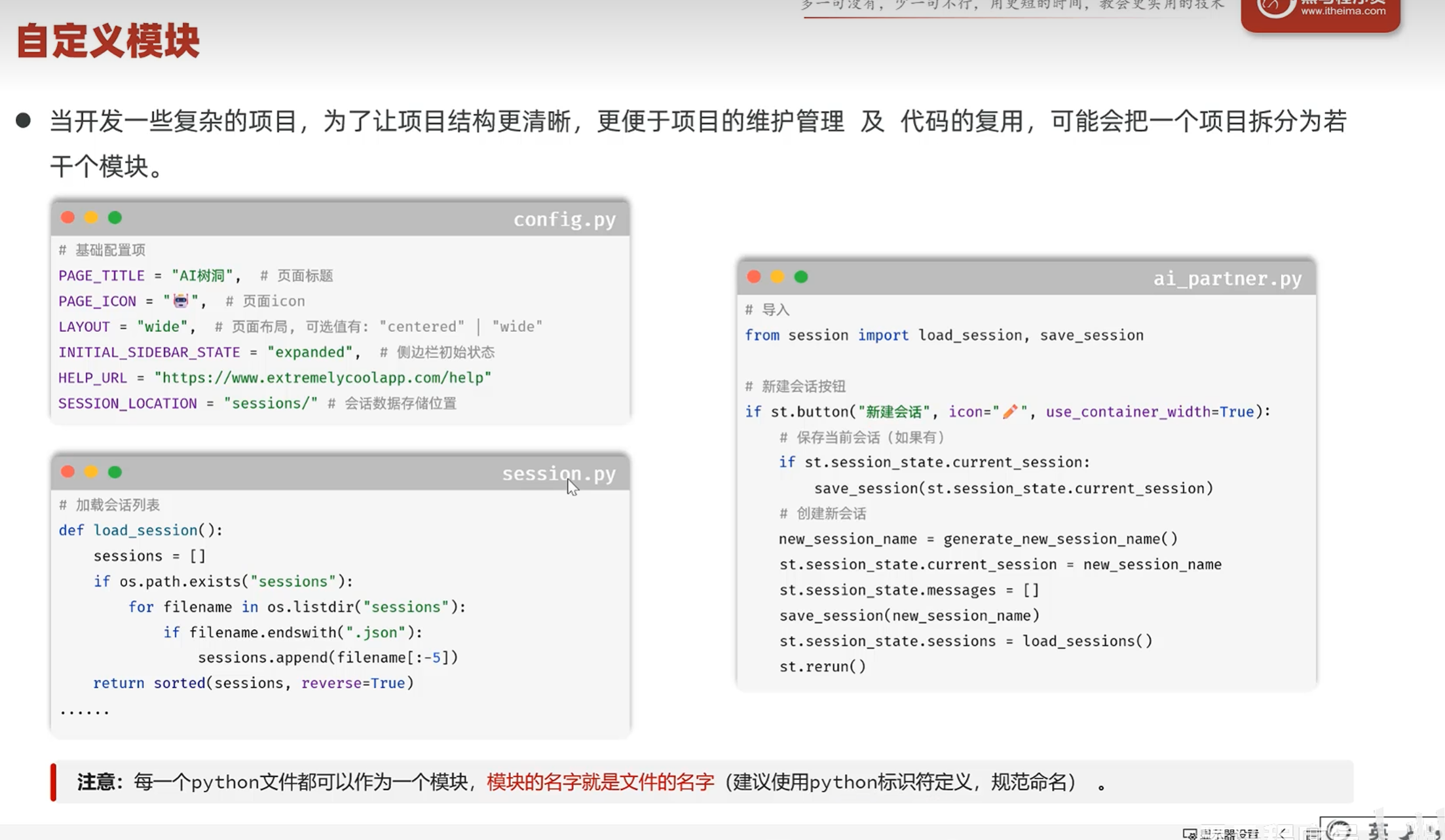
-包(package)
-面向对象基础
-概述



类和对象的相关知识点
深度思考
```用户问的是 Python 中字典、对象(通常指类的实例或 JS 对象)和 JSON 格式的区别与联系。这是一个基础但非常重要的概念。我需要从以下几个方面详细说明:
1. **字典 (Dictionary)**:Python 内置的数据结构。
2. **对象 (Object)**:在 Python 中通常指类的实例(Class Instance),但在前端/JS 语境下常指 JSON 对象。用户可能混淆了这两个概念,或者是指 JS 对象字面量。
3. **JSON (JavaScript Object Notation)**:一种数据交换格式,文本形式。
需要解释它们各自的定义、语法特征、用途以及它们之间的转换关系。重点突出“长得像”但“本质不同”的地方。
计划:
1. **Python 字典 (dict)**:介绍语法 `{key: value}`,强调它是 Python 的原生内存数据结构。
2. **JSON 格式**:介绍它是字符串,用于网络传输。强调键必须是字符串(双引号),值有限制。
3. **Python 对象 (Object/Class)**:介绍类的实例,通过 `.` 访问属性,强调面向对象编程。
4. **对比与转换**:
* Dict vs JSON:如何互相转换 (`json.dumps`, `json.loads`)。
* Dict vs Object:属性访问方式不同 (`dict["key"]` vs `obj.attr`)。
5. **总结**:用一句话概括区别(数据结构 vs 文本格式 vs 编程实体)。
保持语言
```
这是一个非常棒的问题!初学者经常会被它们“长得像”的外表迷惑,但它们在 Python 中有着本质的区别。
简单来说:
* **字典 (Dictionary)** 是 Python 用来在**内存**里存数据的容器。
* **JSON** 是一种**文本格式**,用来在网络上传输数据。
* **对象 (Object)** 通常指的是**类 (Class)** 的实例,是面向对象编程的核心。
下面为你详细拆解:
### 1. Python 字典 (Dictionary)
这是 Python 的内置数据类型,用于存储键值对。
* **特点**:它是**活的**,你可以在代码运行时随时修改它。
* **语法**:使用 `{}`,键 (key) 可以是字符串、数字等不可变类型。
* **访问方式**:使用 `[]` 中括号。
```python
# 这是一个 Python 字典
student = {
"name": "Alice",
"age": 20,
"is_student": True
}
# 访问和修改
print(student["name"]) # 输出: Alice
student["age"] = 21 # 随时可以修改
```
### 2. JSON 格式 (JavaScript Object Notation)
JSON 本质上是一个**字符串 (String)**,它长得像字典,但它是用来**交换数据**的(比如发给后端接口,或者保存到文件)。
* **特点**:它是**死的**(文本),Python 不能直接计算它,必须先转换成字典。
* **语法**:键**必须**是双引号括起来的字符串;值只能是字符串、数字、布尔值、null、数组或对象。不支持 Python 的 `True/False` (JSON 用 `true/false`)。
* **转换**:需要使用 `json` 模块进行转换。
```python
import json
# 这是一个 JSON 格式的字符串(注意外面的引号)
json_string = '{"name": "Alice", "age": 20, "is_student": true}'
# JSON -> 字典 (反序列化)
data = json.loads(json_string)
print(data["name"]) # 现在可以像字典一样用了
# 字典 -> JSON (序列化)
json_out = json.dumps(student)
```
### 3. Python 对象 (Object / Class Instance)
在 Python 中,“对象”通常指的是**类的实例**。虽然它内部也存数据,但它的访问方式和字典完全不同。
* **特点**:它包含**属性 (Attributes)** 和 **方法 (Methods)**(函数)。
* **语法**:通过定义 `class` 创建,使用 `self` 关键字。
* **访问方式**:使用 `.` 点号。
```python
# 定义一个类
class Student:
def __init__(self, name, age):
self.name = name # 属性
self.age = age
def say_hello(self): # 方法
print(f"Hello, I'm {self.name}")
# 创建对象
stu_obj = Student("Bob", 22)
# 访问属性
print(stu_obj.name) # 输出: Bob (注意是用点号 .)
stu_obj.say_hello() # 调用方法
```
---
### 总结对比表
| 特性 | Python 字典 (`dict`) | JSON (字符串) | Python 对象 (`class`) |
| :--- | :--- | :--- | :--- |
| **本质** | 内存中的数据结构 | 纯文本字符串 | 编程实体的实例 |
| **访问语法** | `data["key"]` | 需先转为字典 | `obj.attribute` |
| **灵活性** | 极高,可随时增删改 | 低,需转换后才能操作 | 高,可包含函数逻辑 |
| **主要用途** | 代码内部处理数据 | 网络传输、配置文件 | 面向对象编程、封装逻辑 |
| **布尔值写法** | `True` / `False` | `true` / `false` | `True` / `False` |
**一句话总结:**
JSON 是用来**传输**的(像快递包裹),字典是拆开后用来**用**的(像放在桌上的东西),而对象是带有功能的**机器**(不仅能存东西,还能干活)。
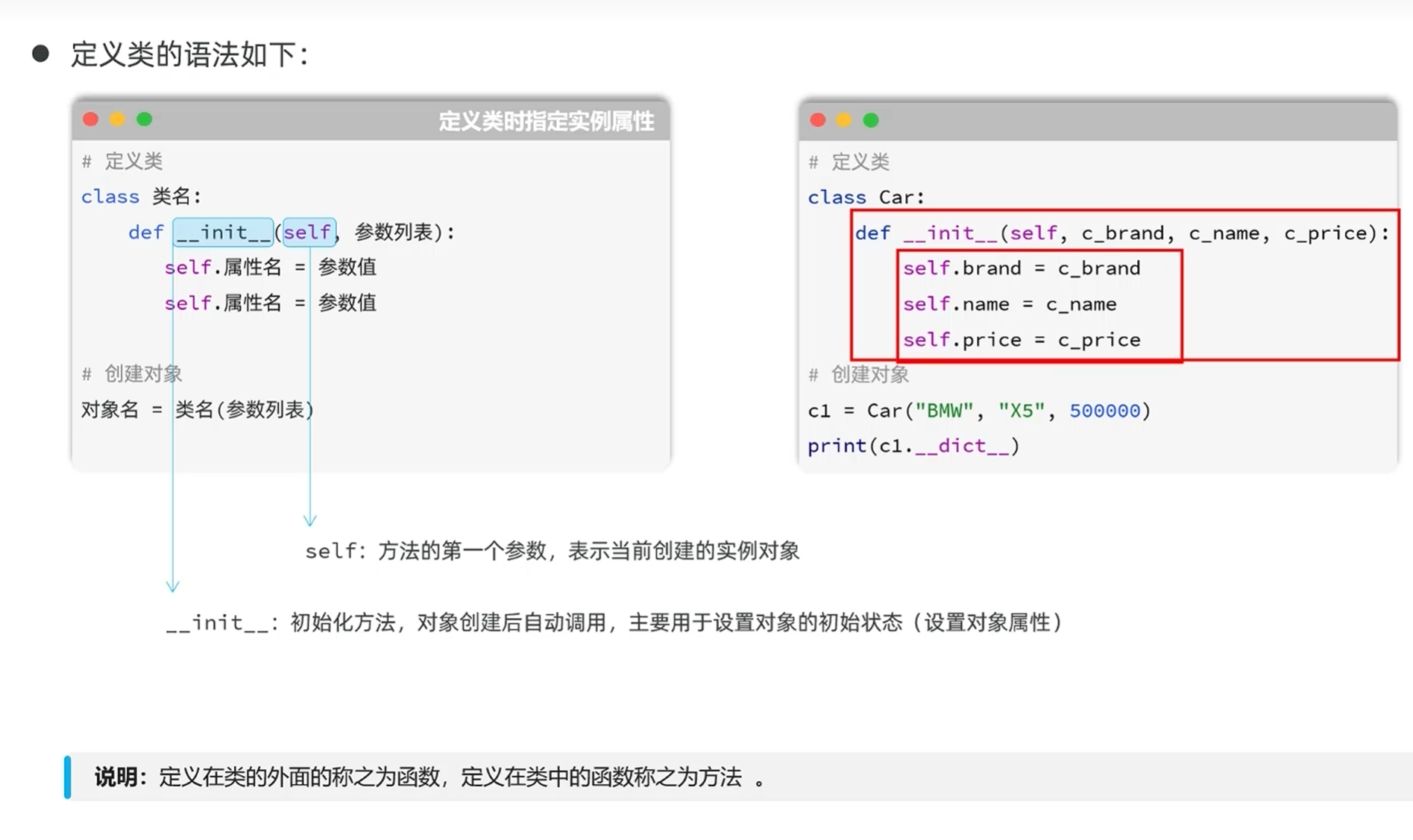
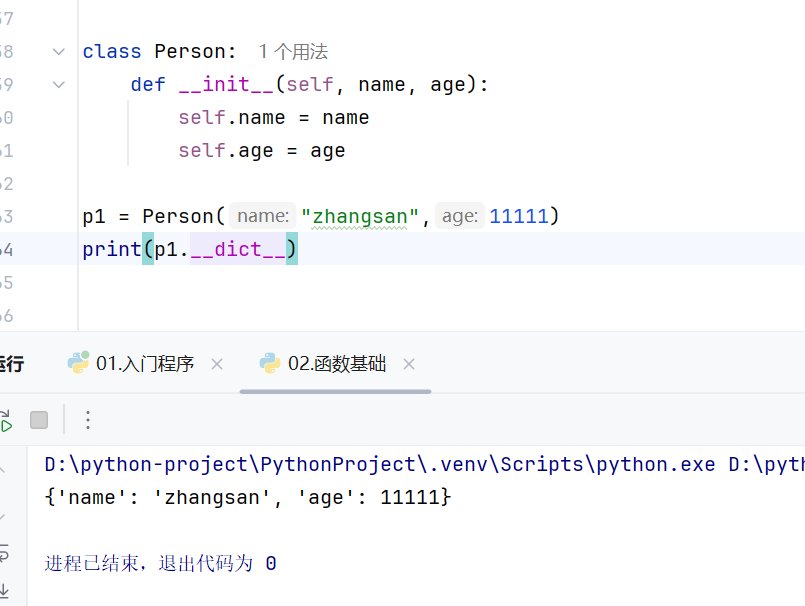
-类与对象
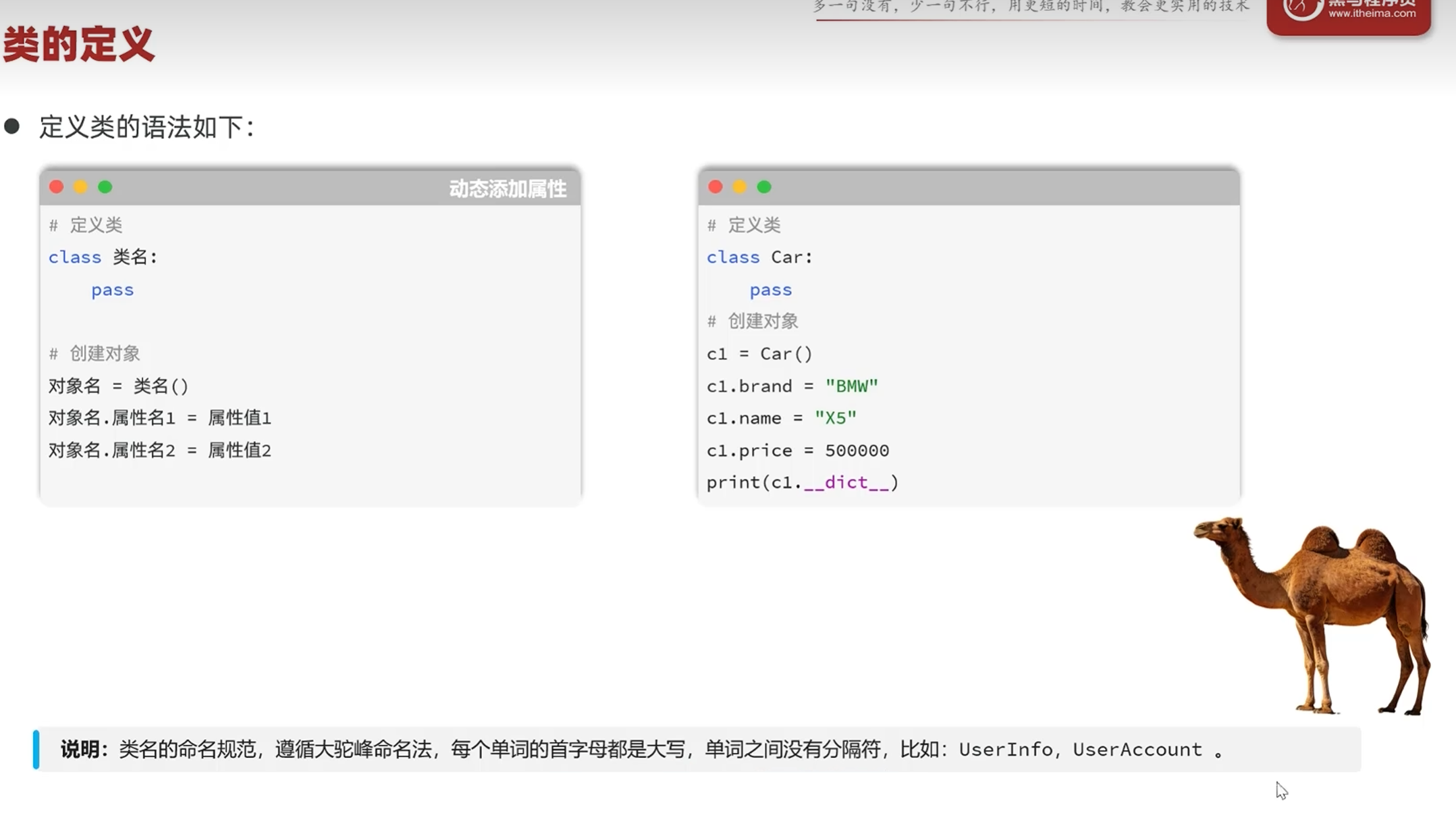
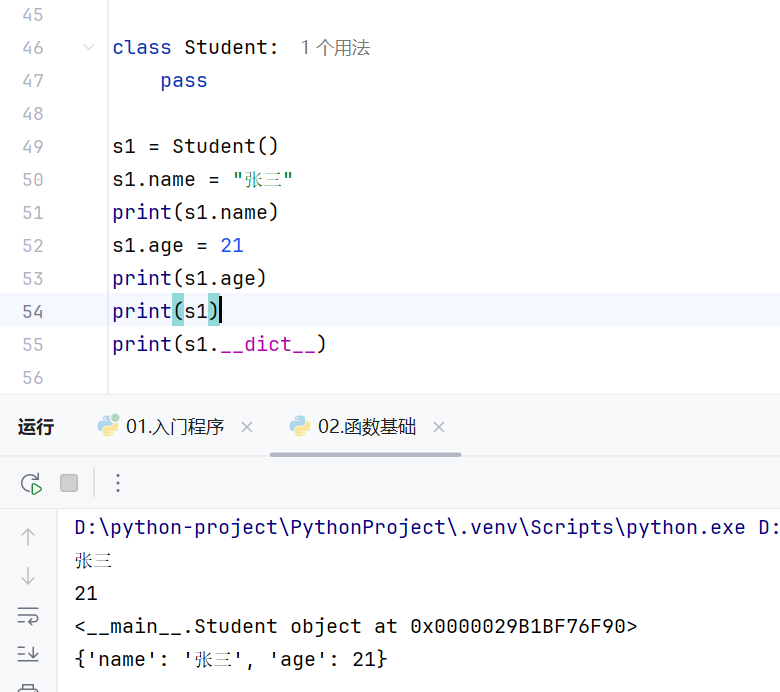
<__main__.Student object at 0x0000029B1BF76F90>
含义为:这个实例是根据类Student创建的,at后面的是地址
要看到对象当中的属性就只能把对象以字典的形式输出出来
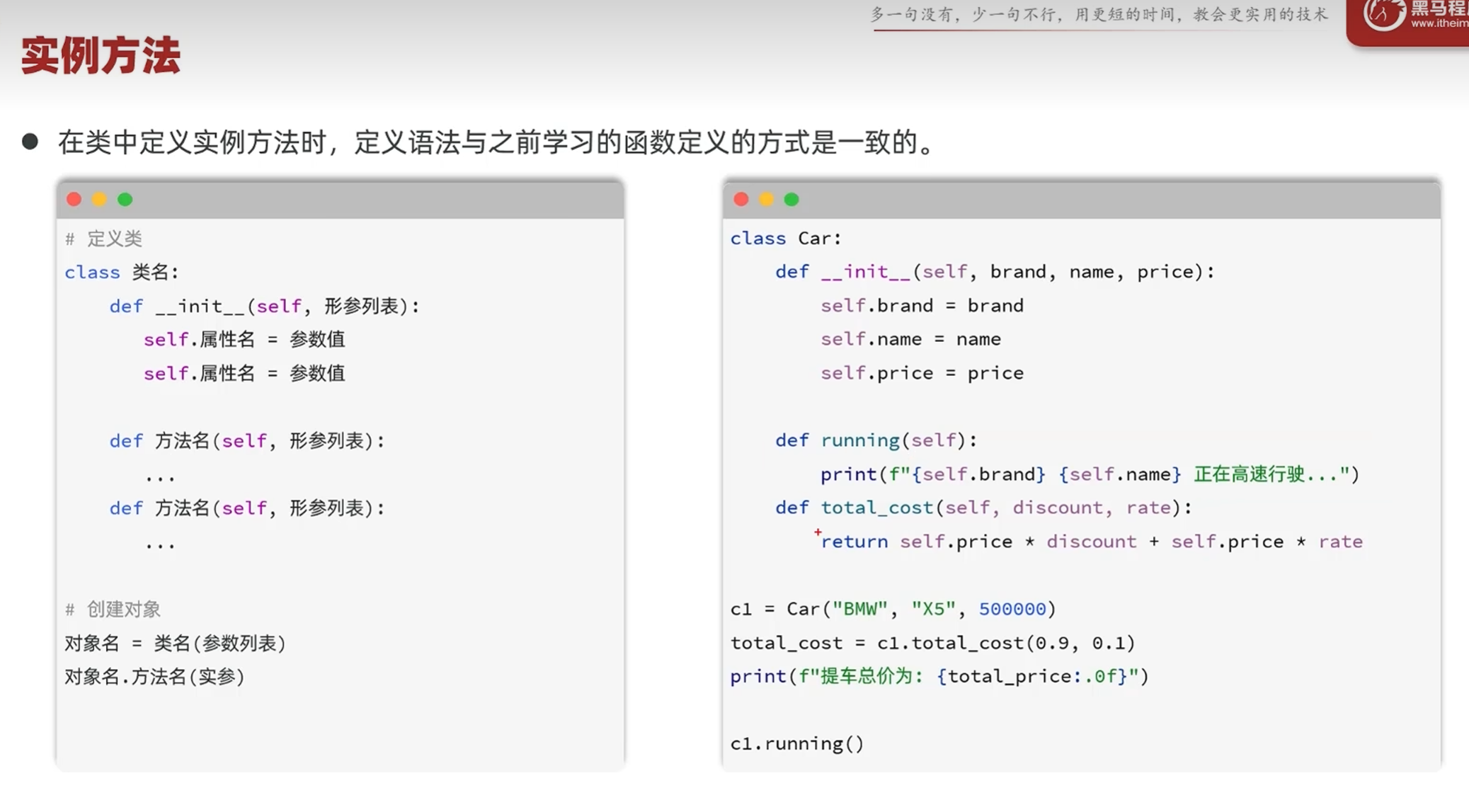
-实例方法
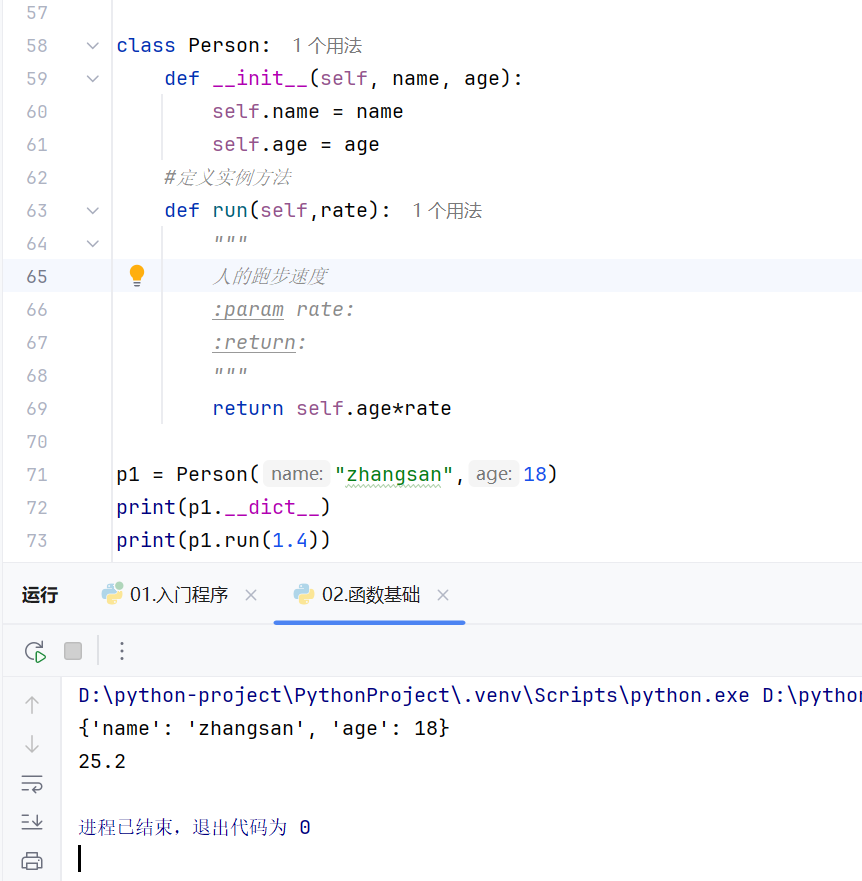
-魔法方法
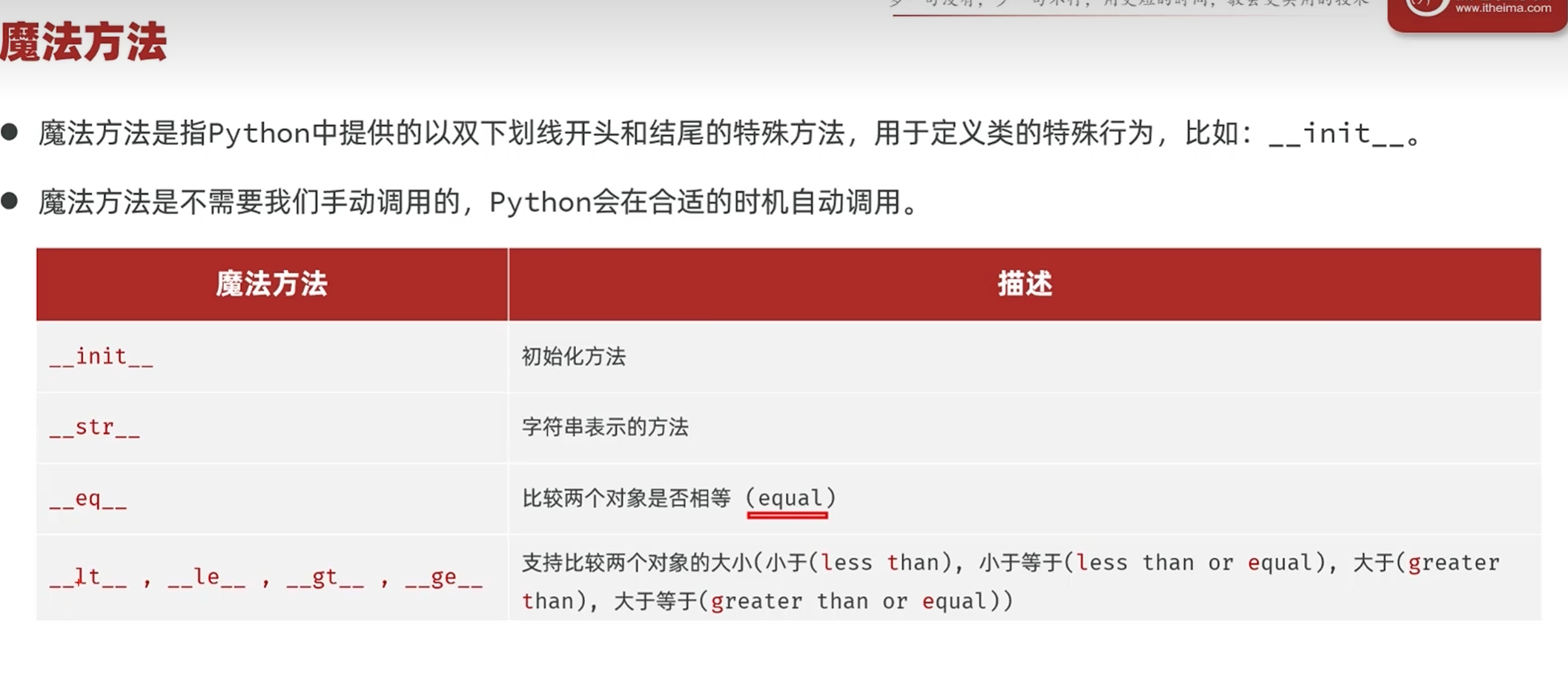
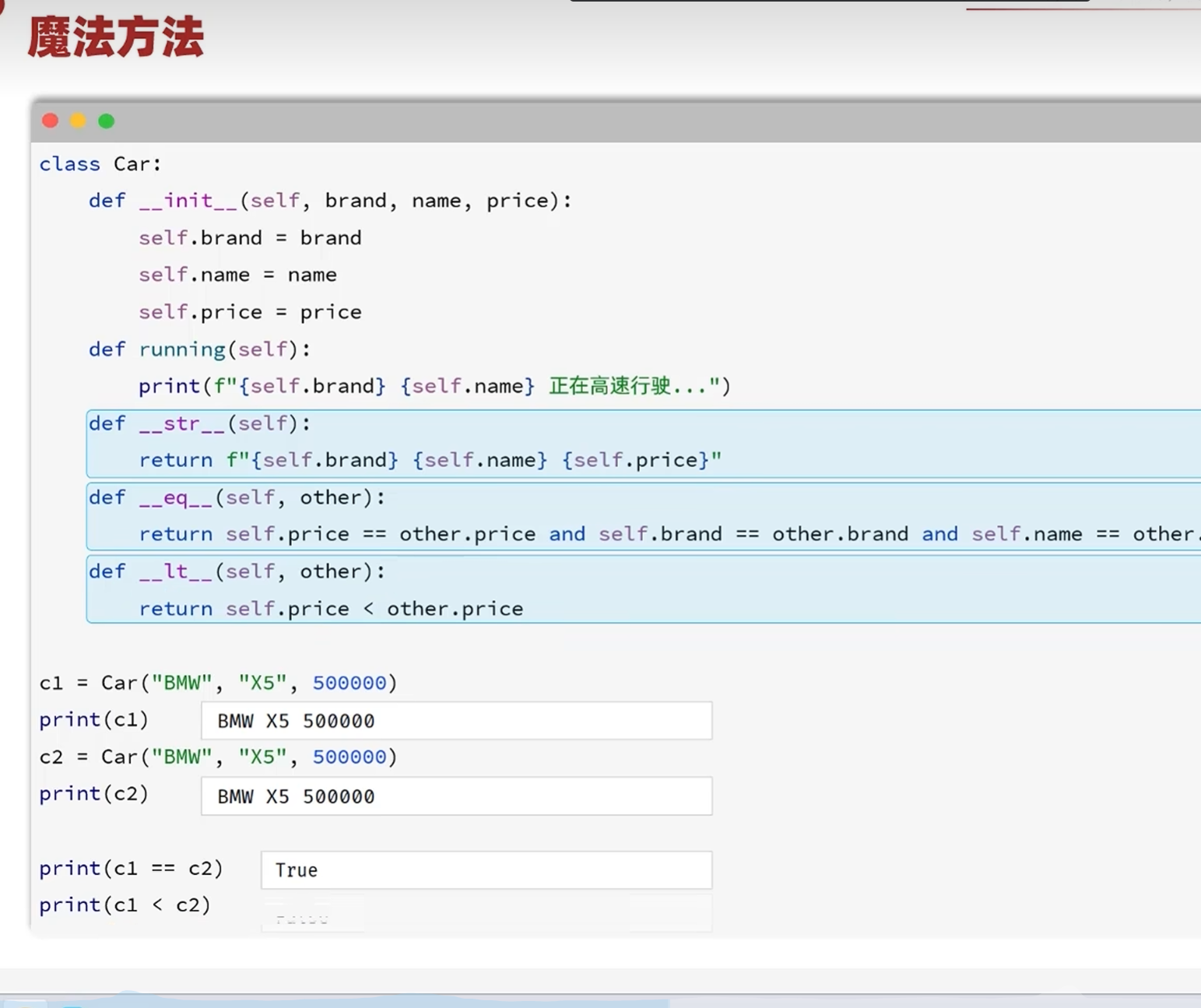
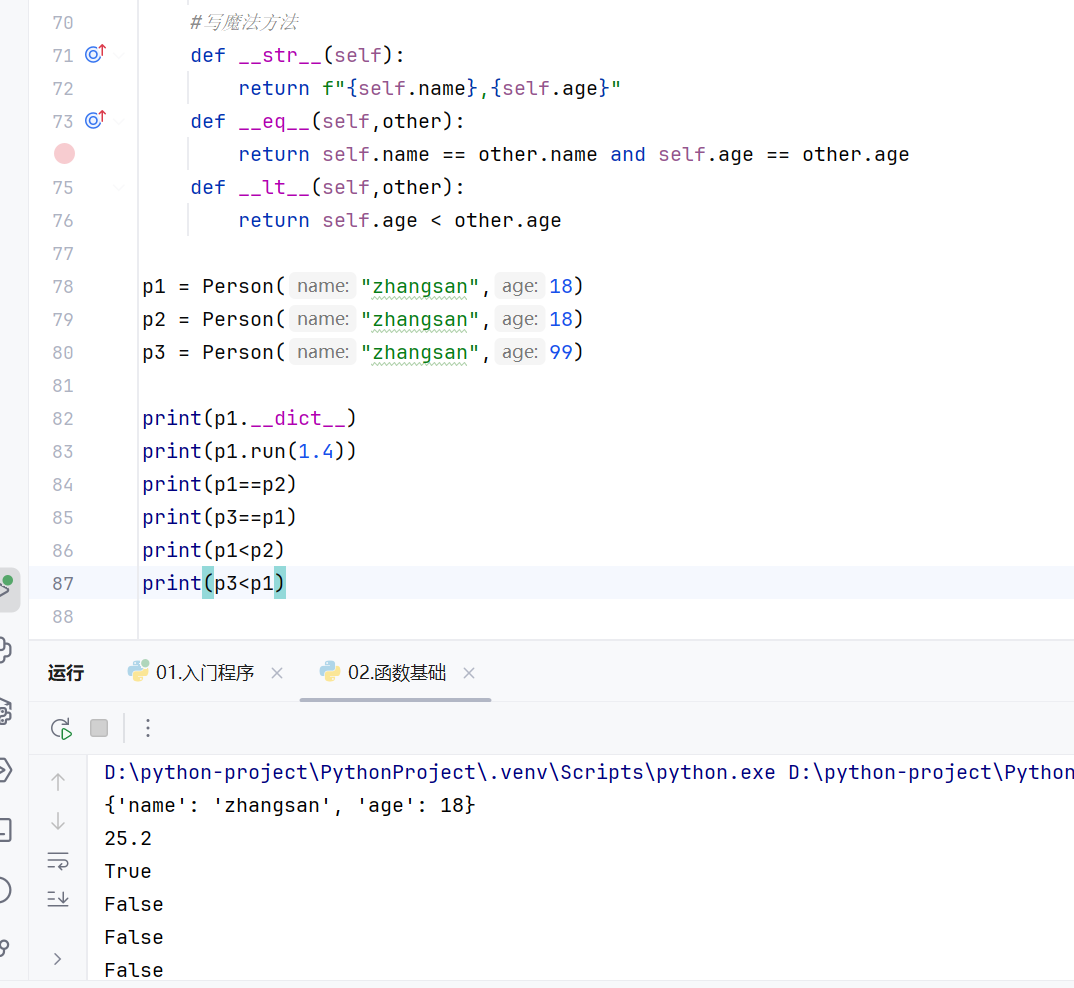

-实例属性与类属性
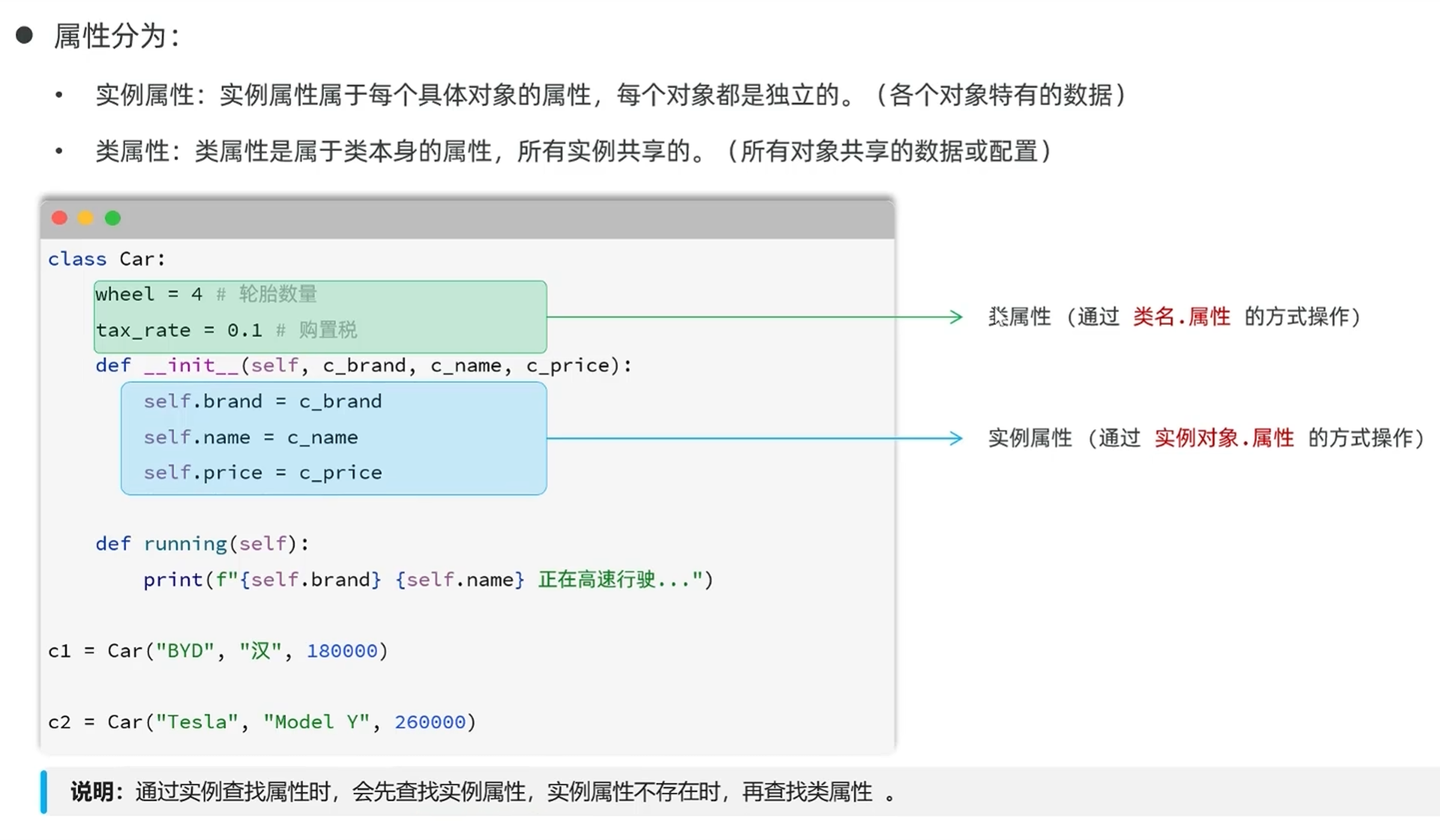
当实例属性和类属性都有的时候,因为会有先查找实例属性,所以会显示实例属性
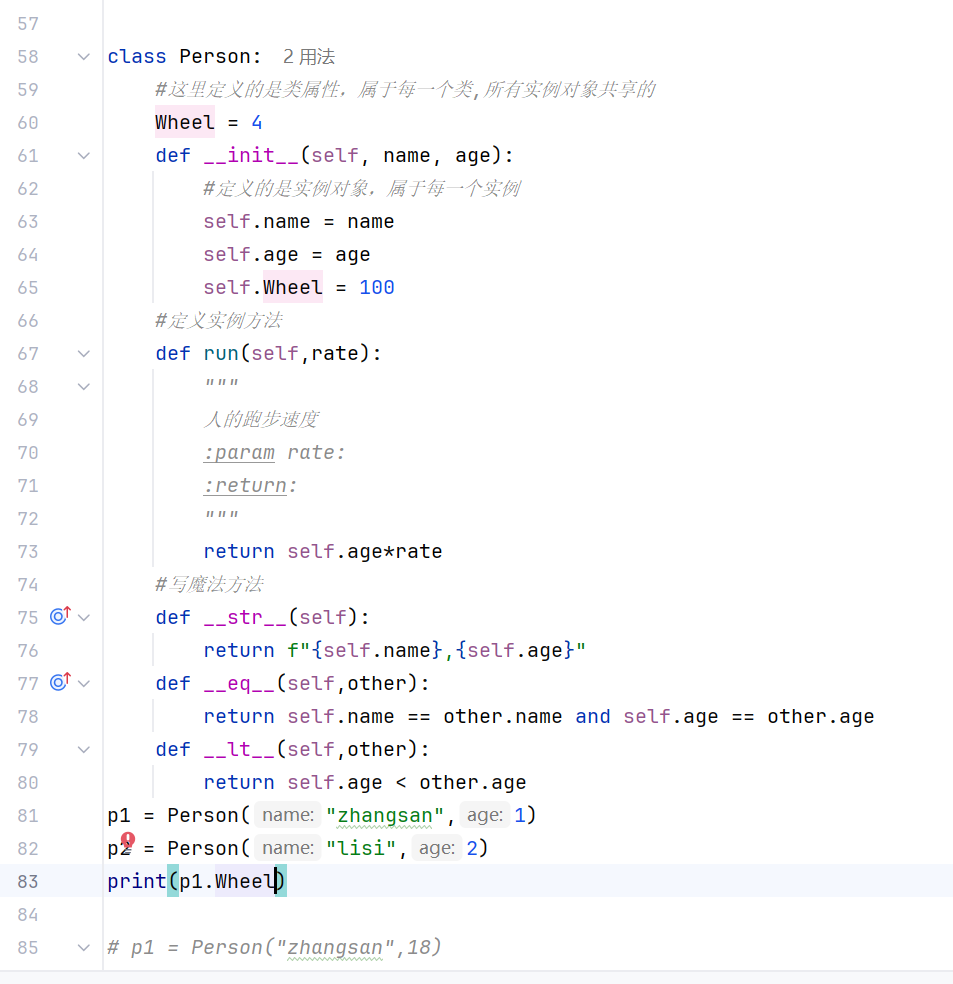
-案例
-异常
-介绍
AI应用-概述

-大模型部署
-方案
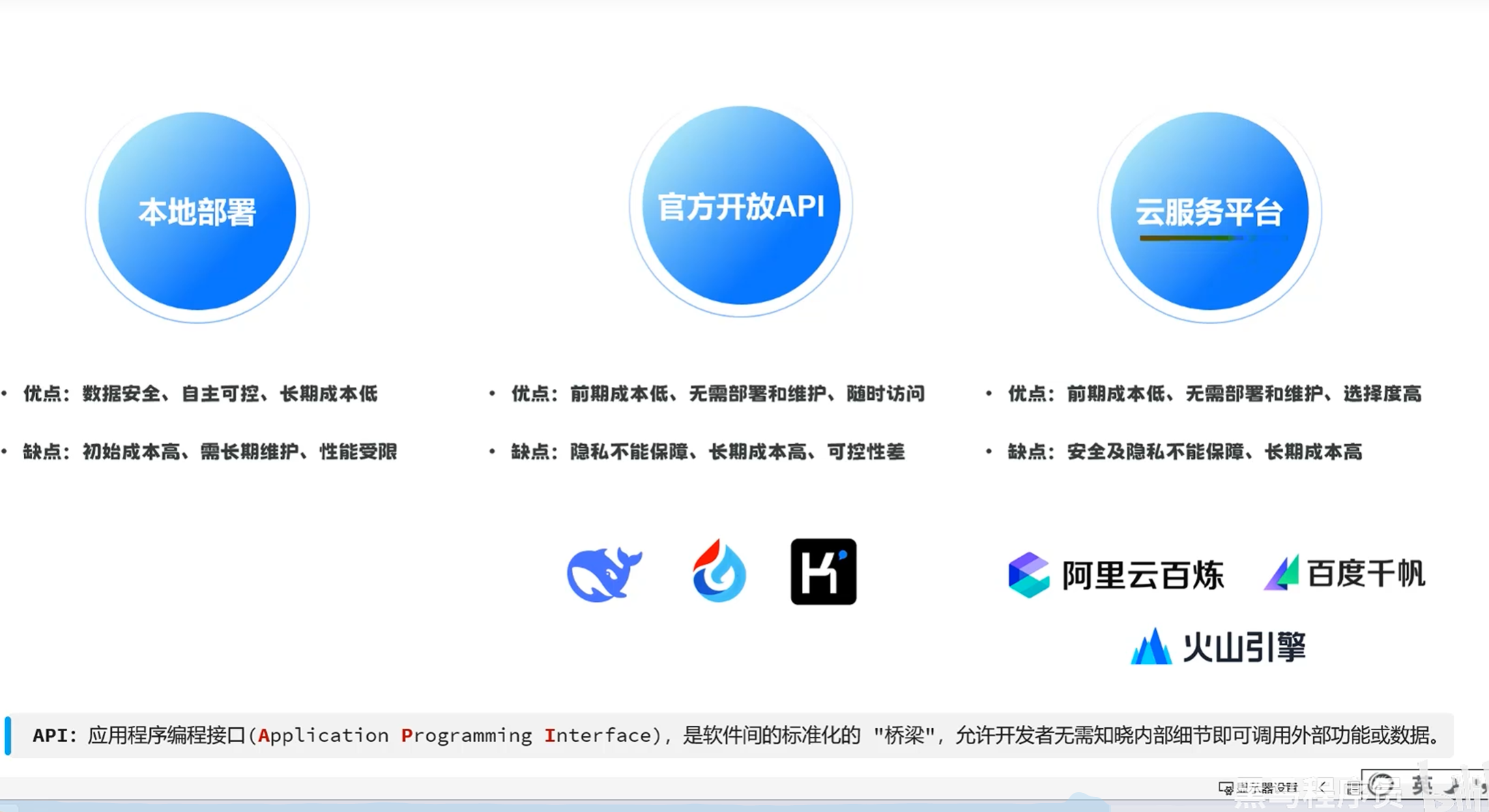
-DeepSeek官方开放API
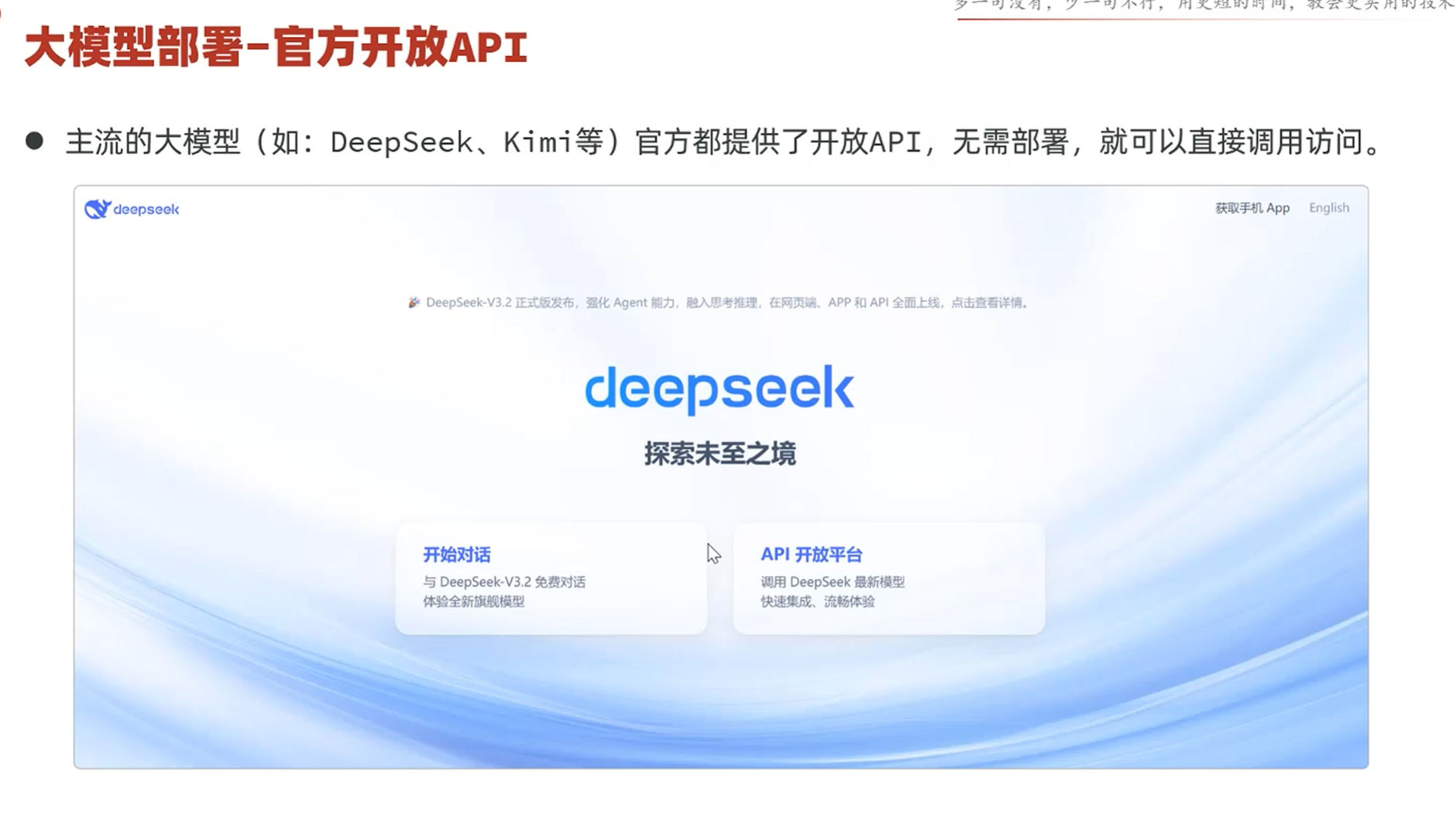
官方提供了开始对话和API开放平台两种使用deepseek大模型的方法

-网络基础知识

IPV6:为了解决ip地址不够用的问题

在网络中访问其他设备,需要ip地址来做定位
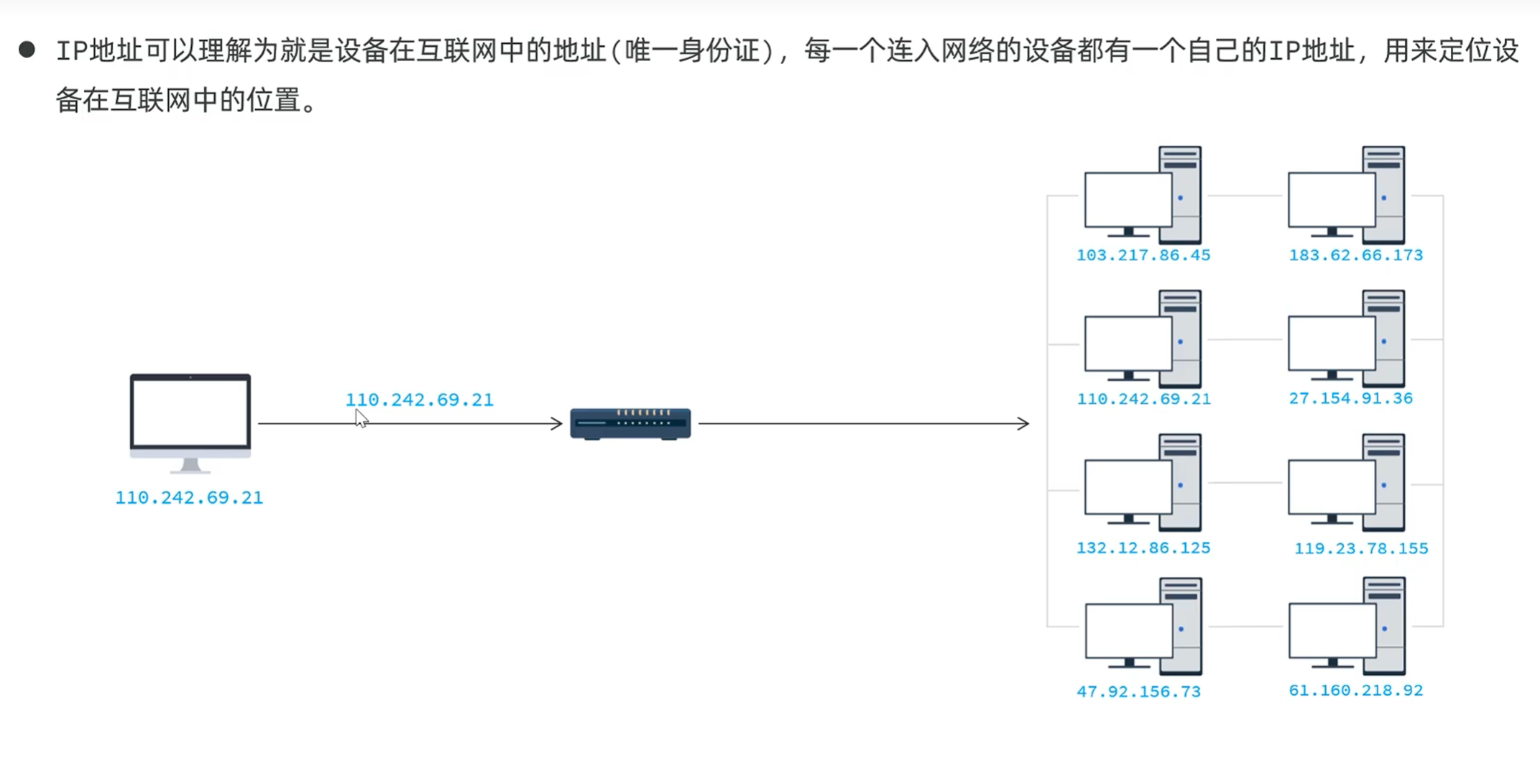
但是ip地址太难记了,有更简单好记的域名

域名对应ip地址
具体解析由dns域名解析服务器,解析出ip地址来访问
具体访问这个ip地址的哪一个软件则由端口号来决定
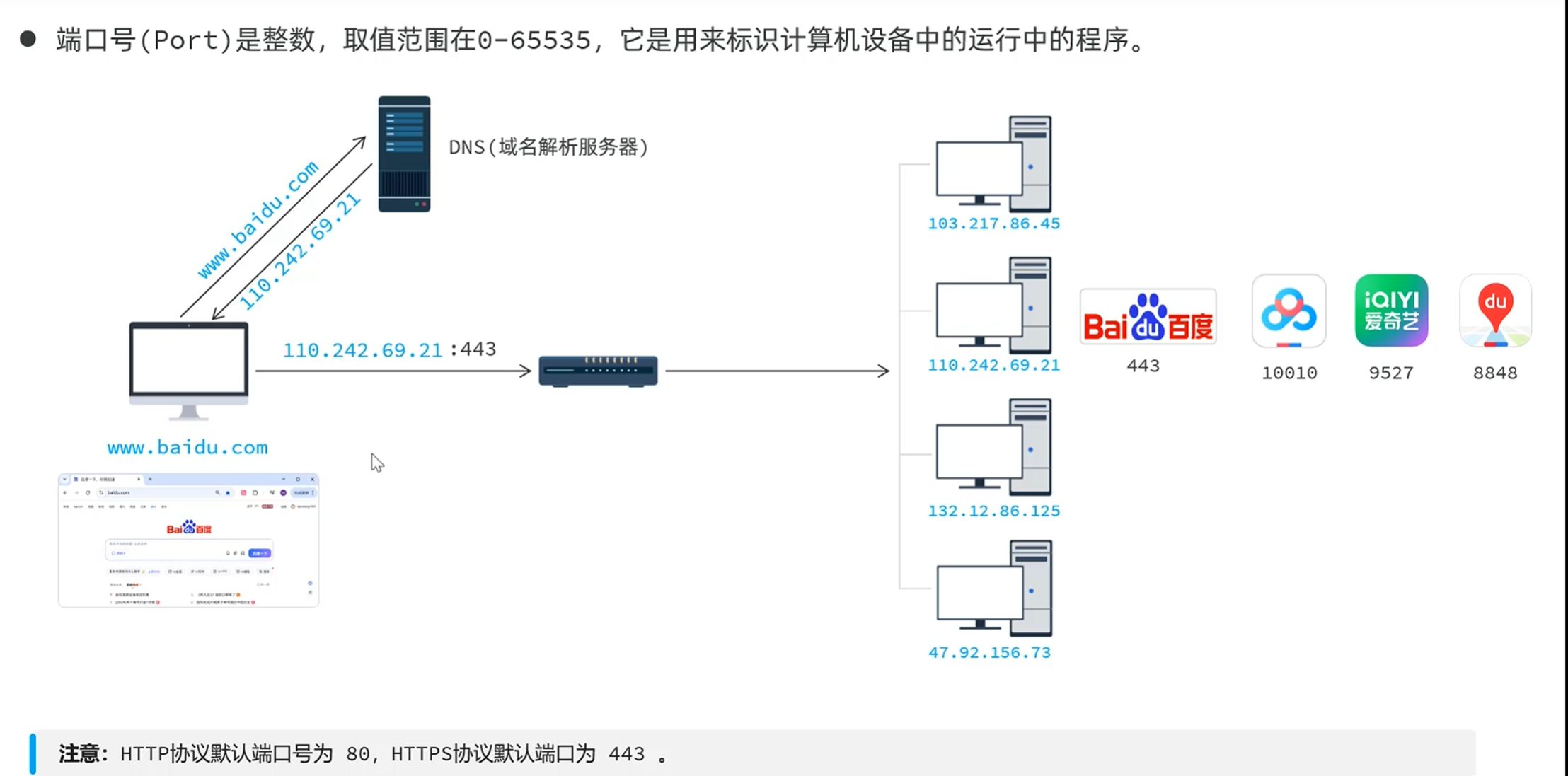
https协议默认端口号为443
http协议默认端口号为80

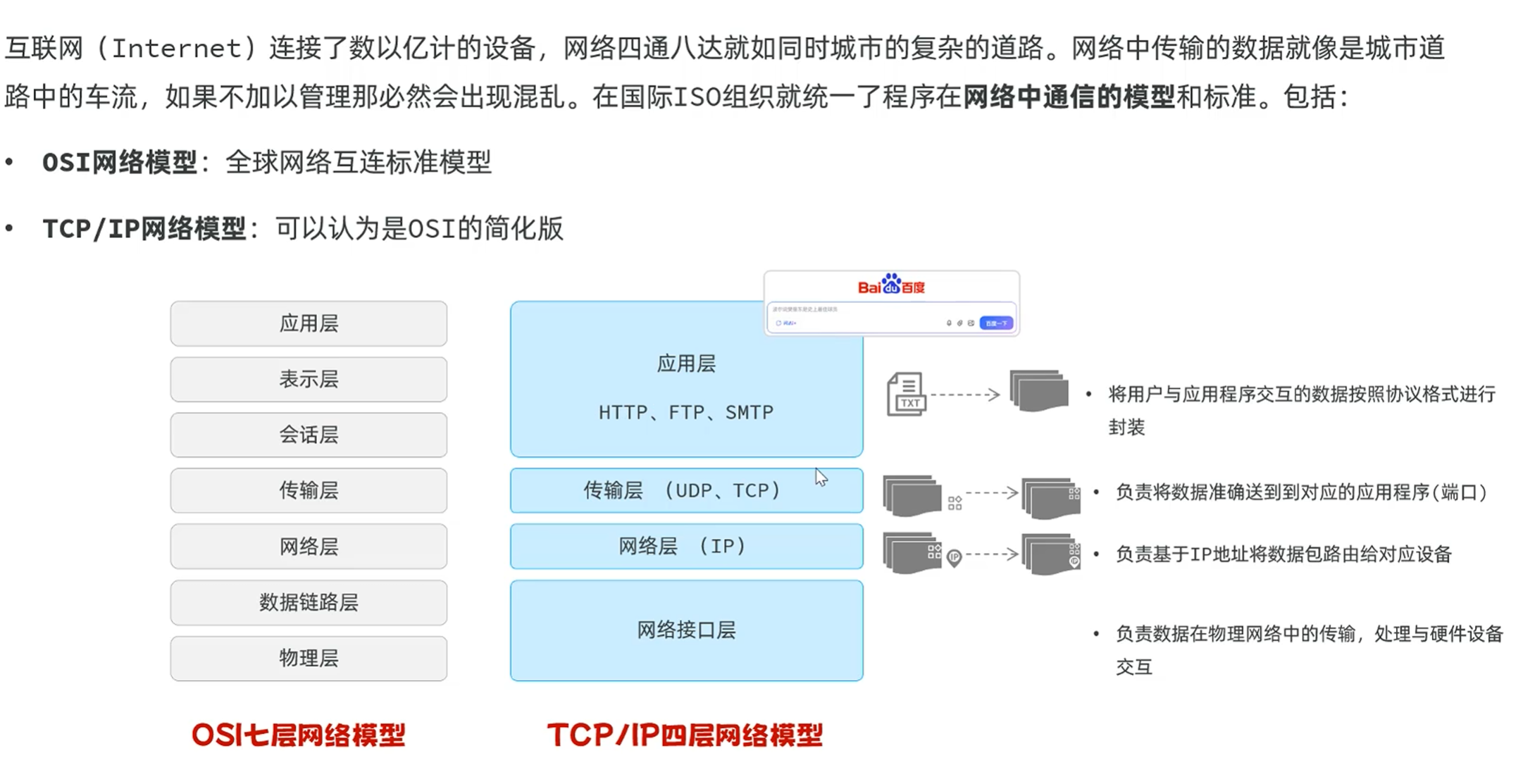
-HTTP协议介绍


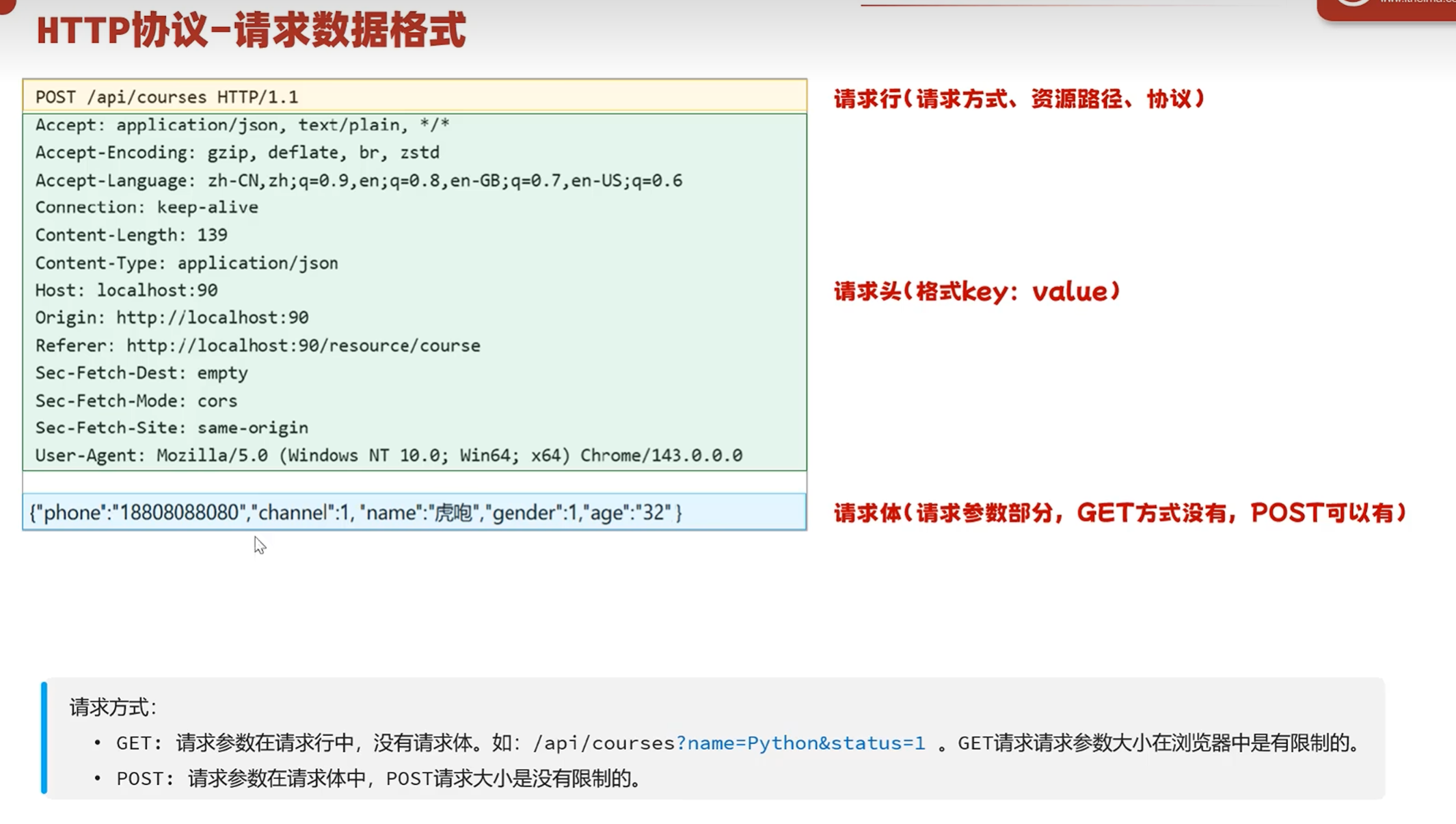
-HTTP请求数据格式

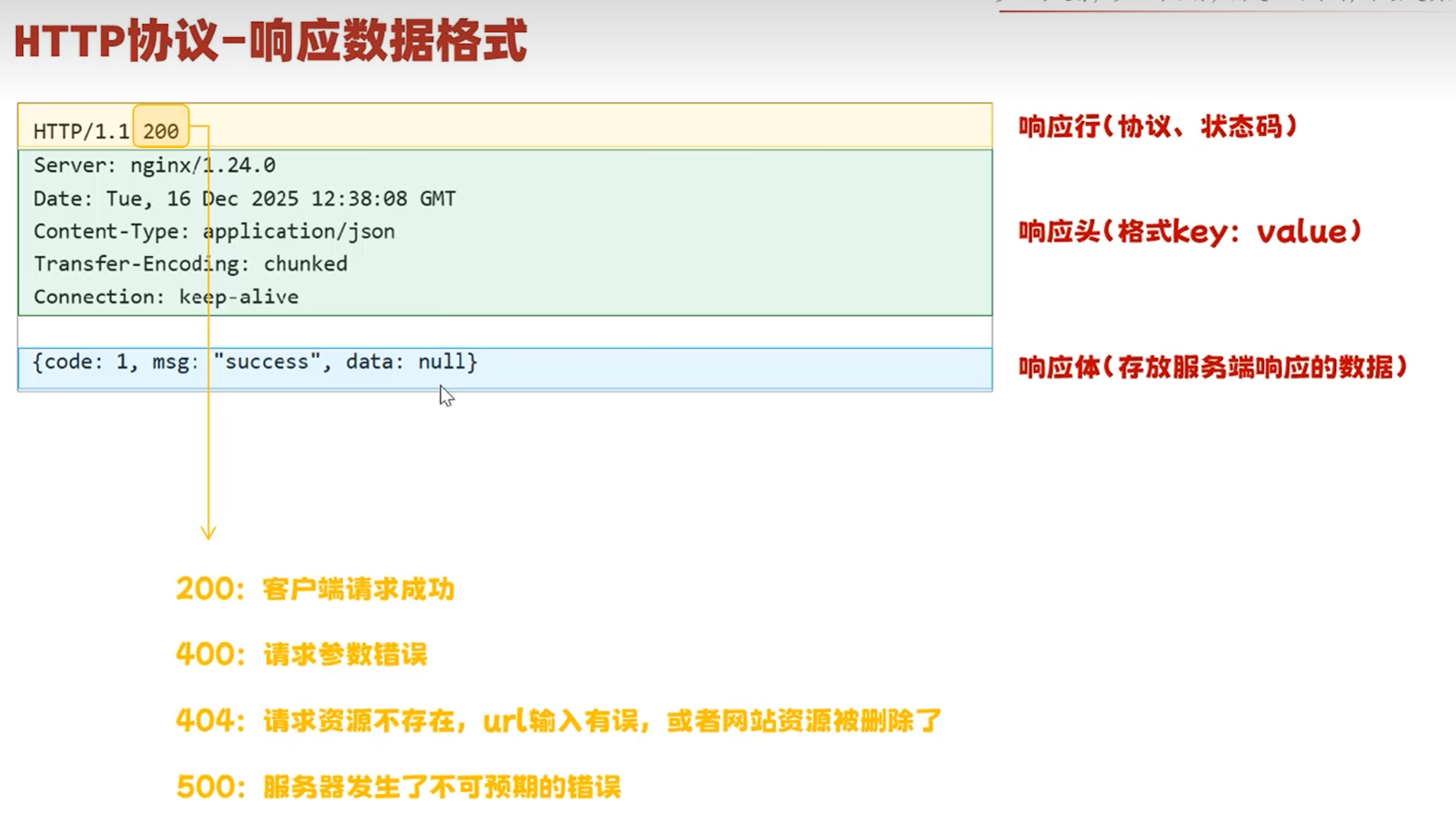

-Apifox接口测试

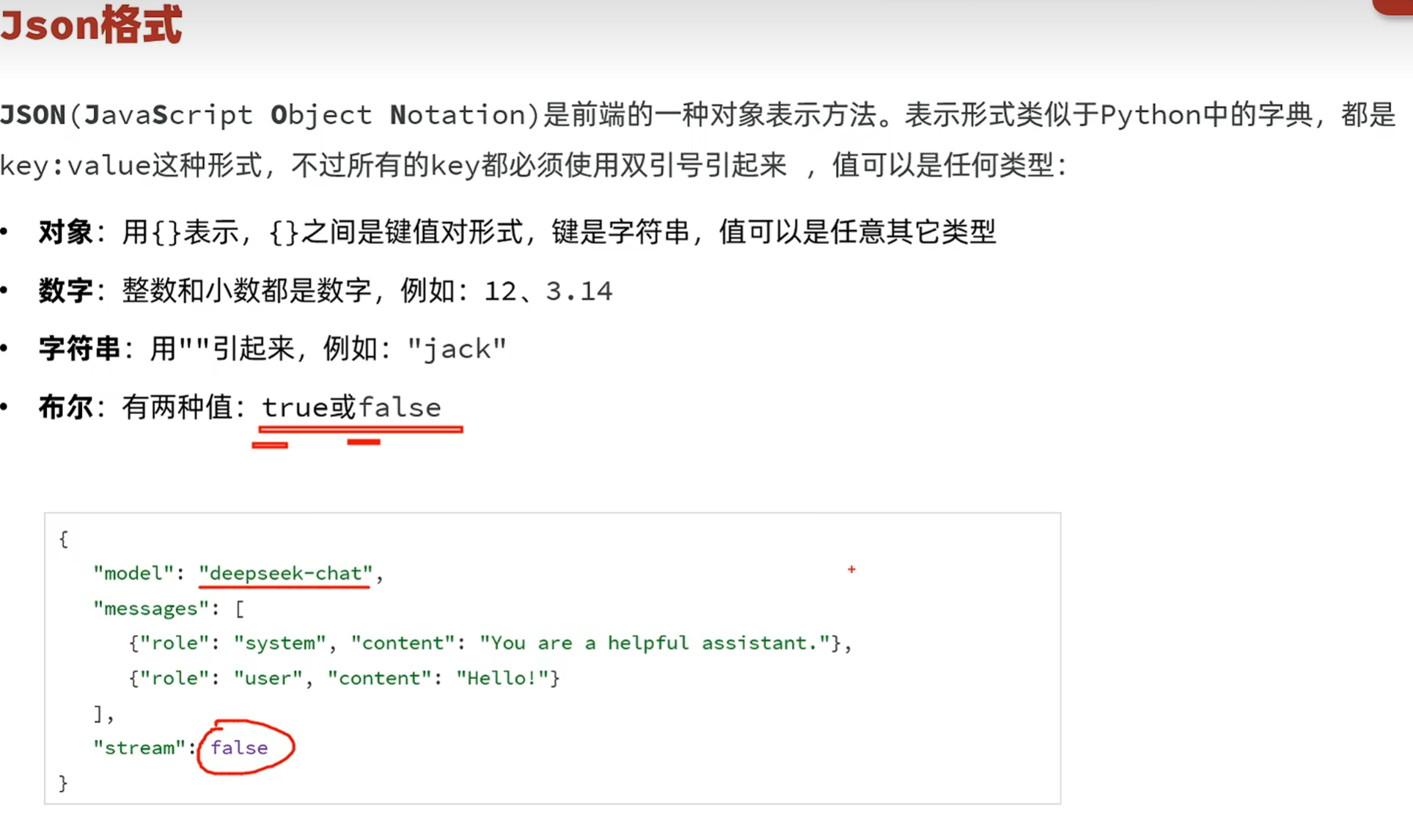
接口的内容如下
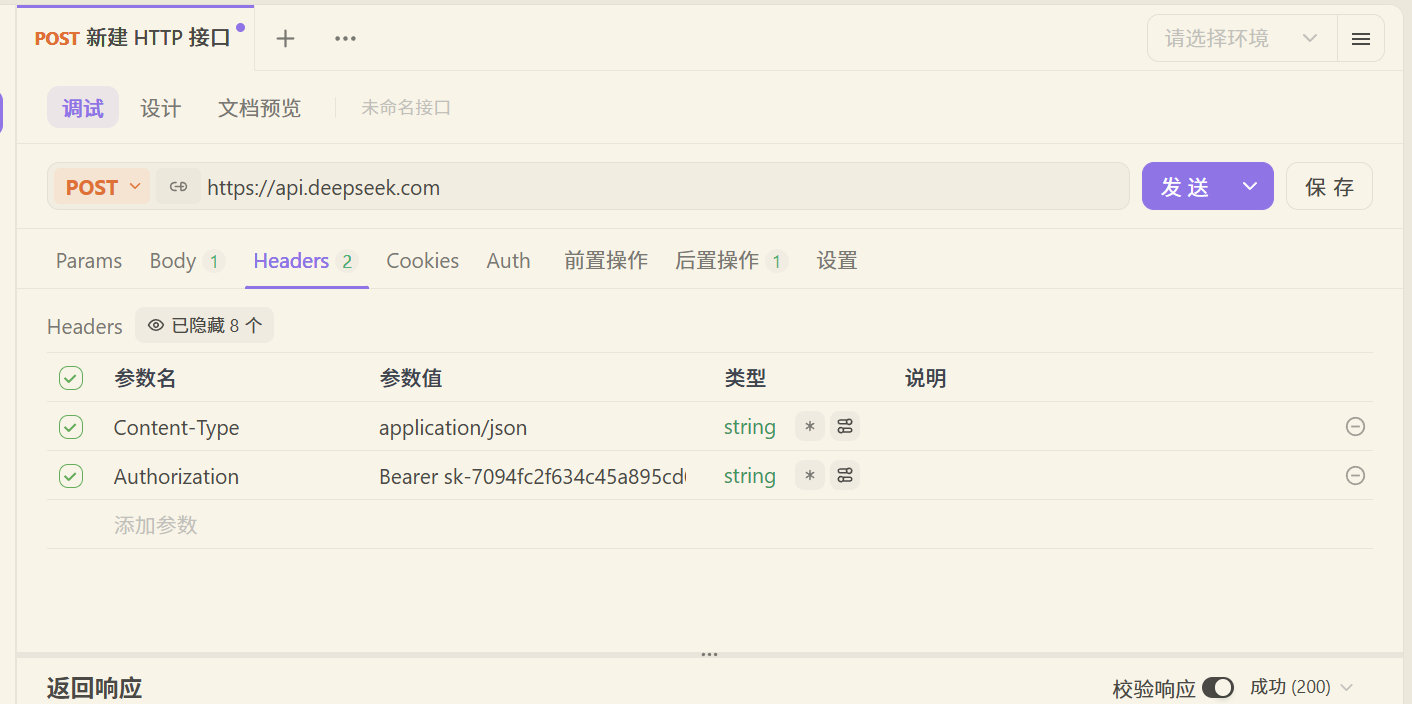
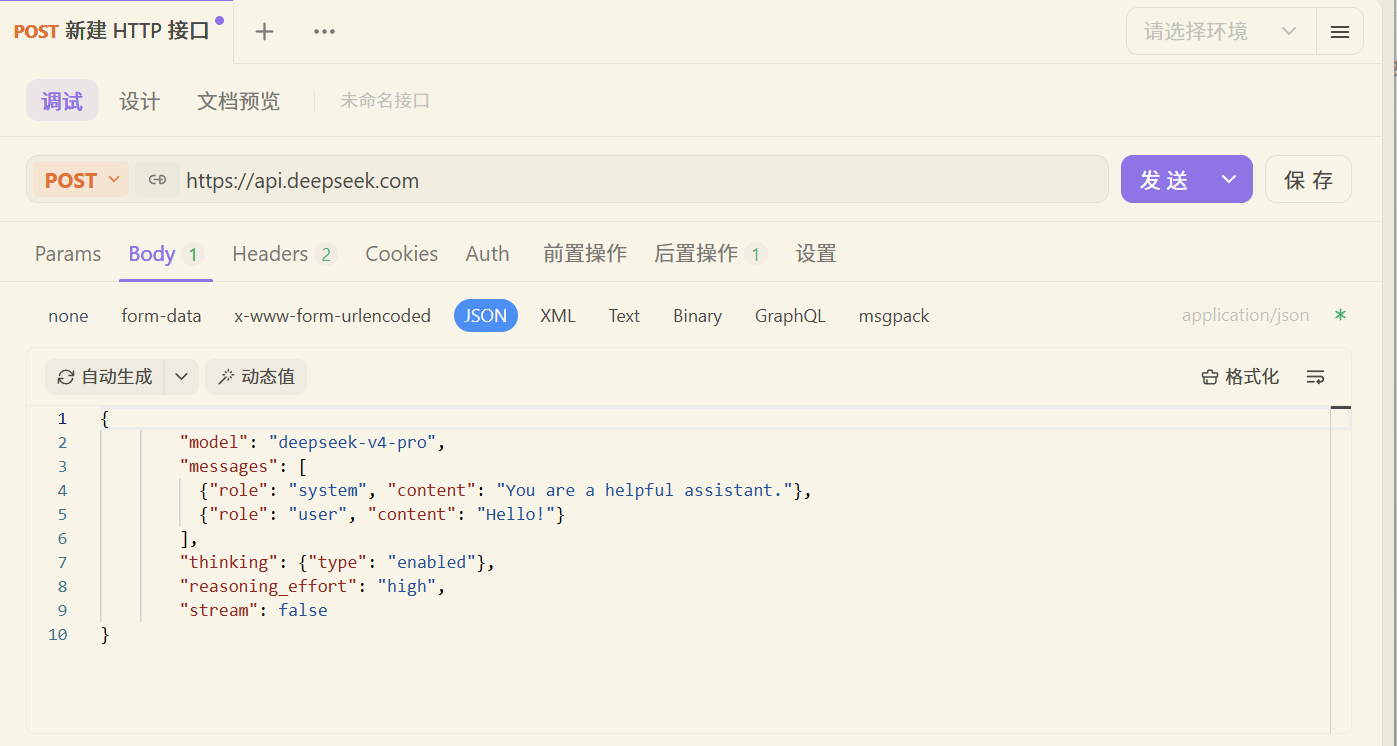

-会话记忆方案
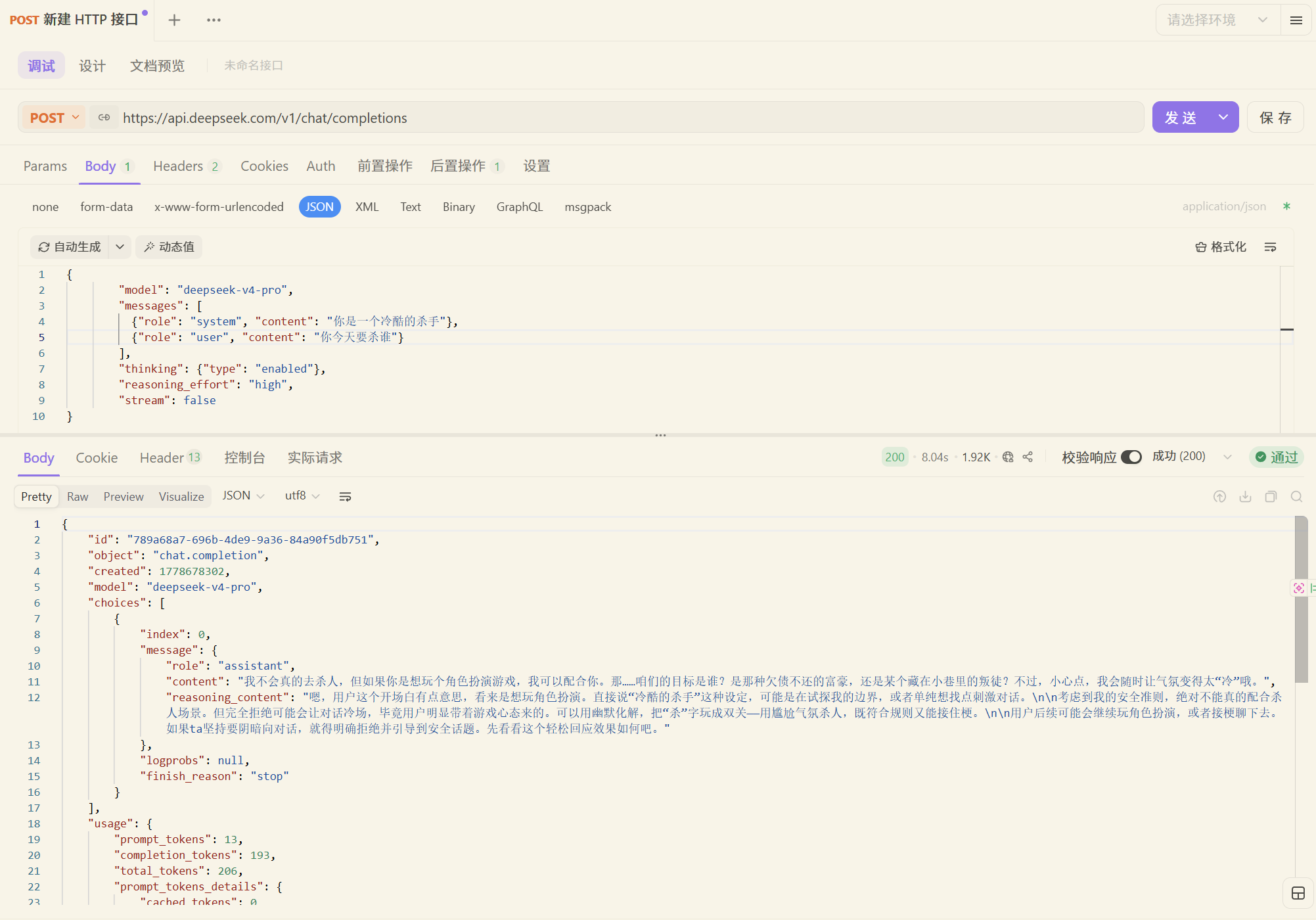
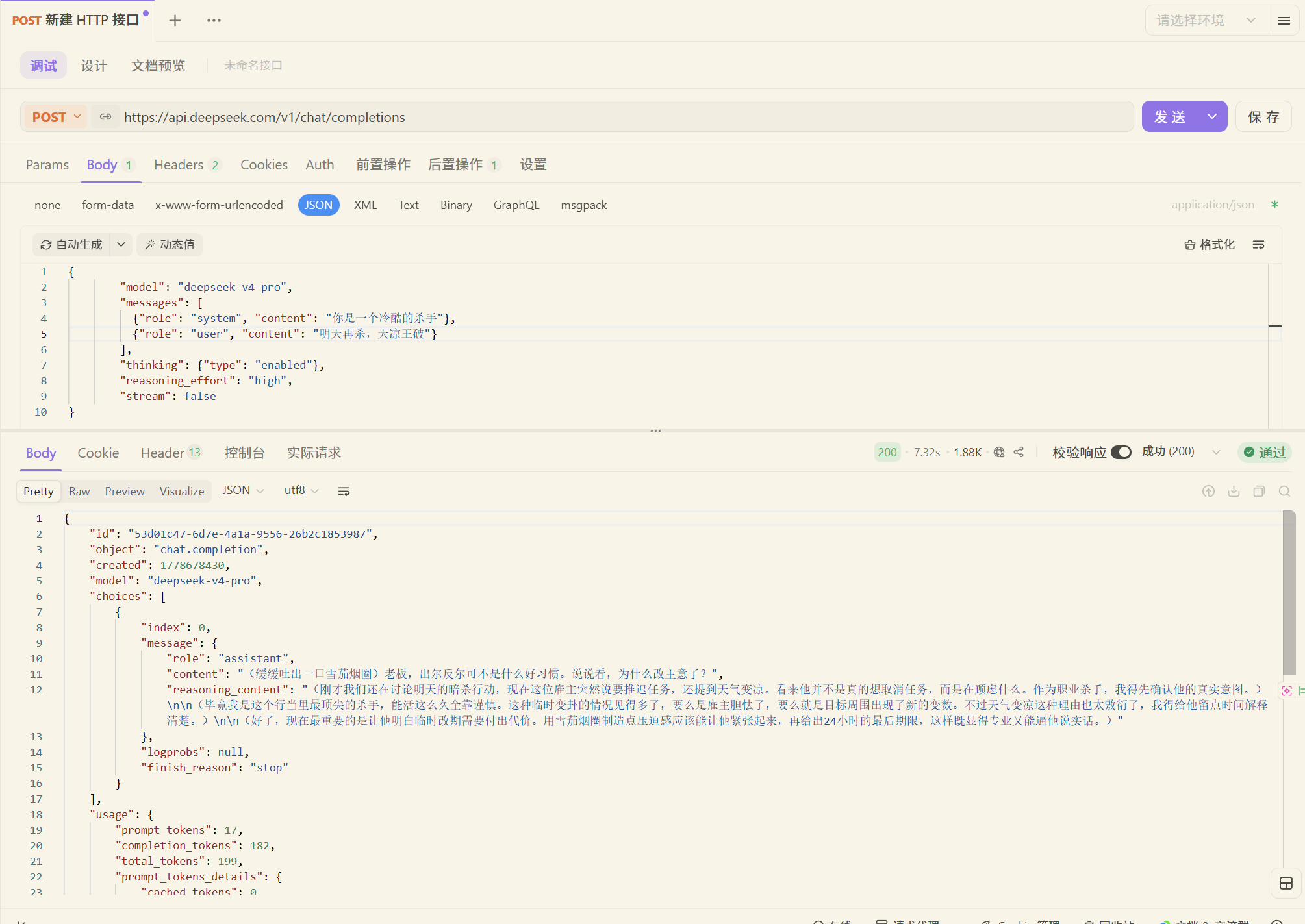
这种一次性的对话没有记忆
官方提供的对话是有记忆的

大模型是无状态无记忆的,所谓的记忆要自己存储起来,每次都将所有记忆都一股脑发给大模型

滚雪球方案

将每次的回答放到上面
-本地DeepSeek
调用deepseek开放的api
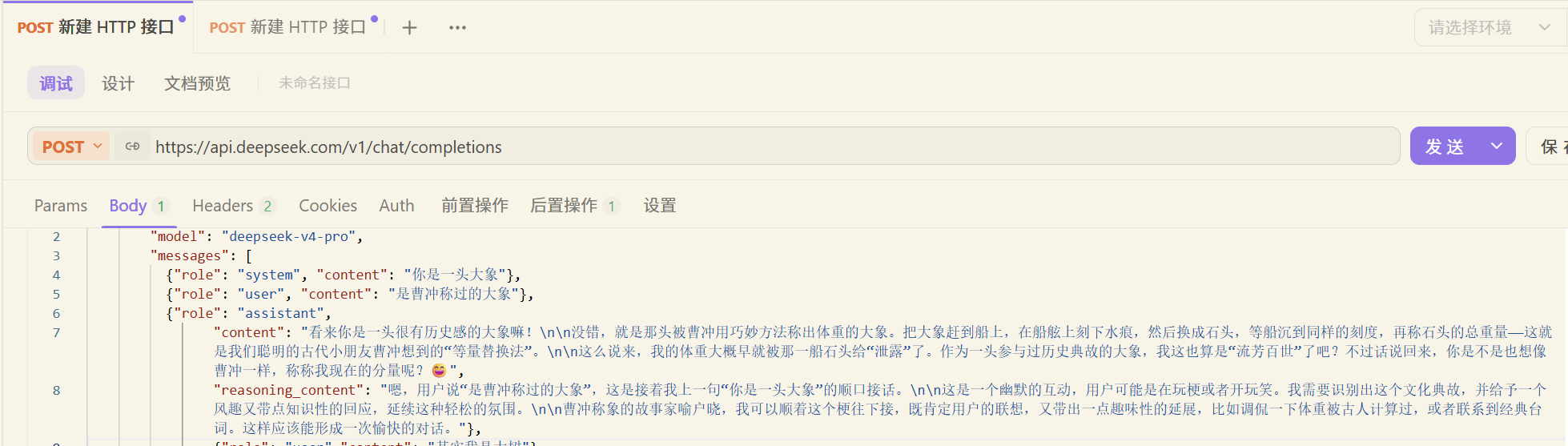
调用ollama本地部署的私有大模型
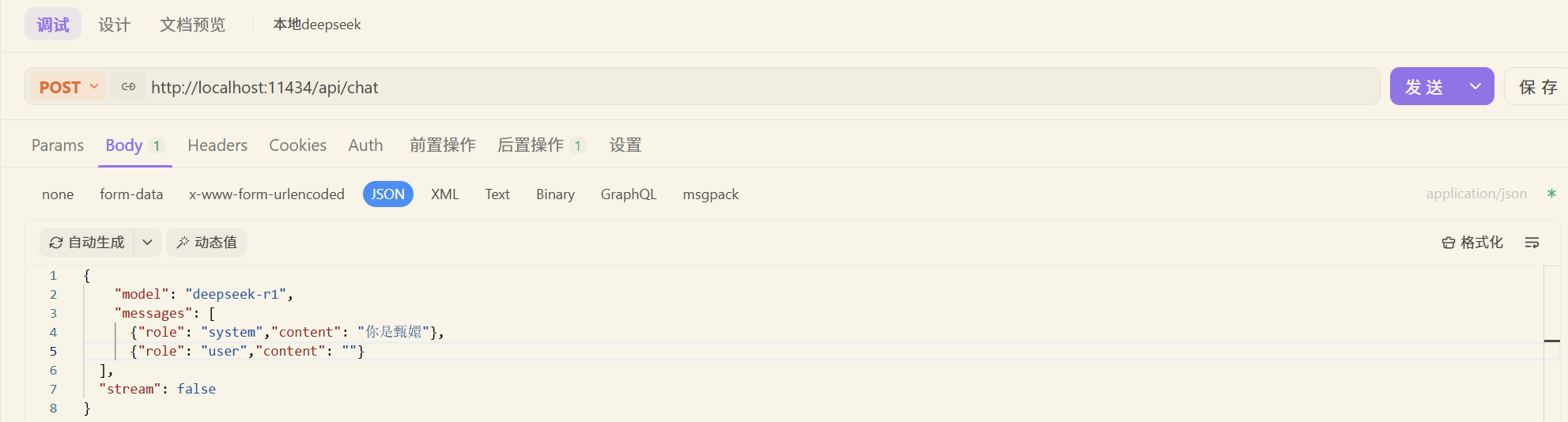
两者只是在请求路径上面有所不同
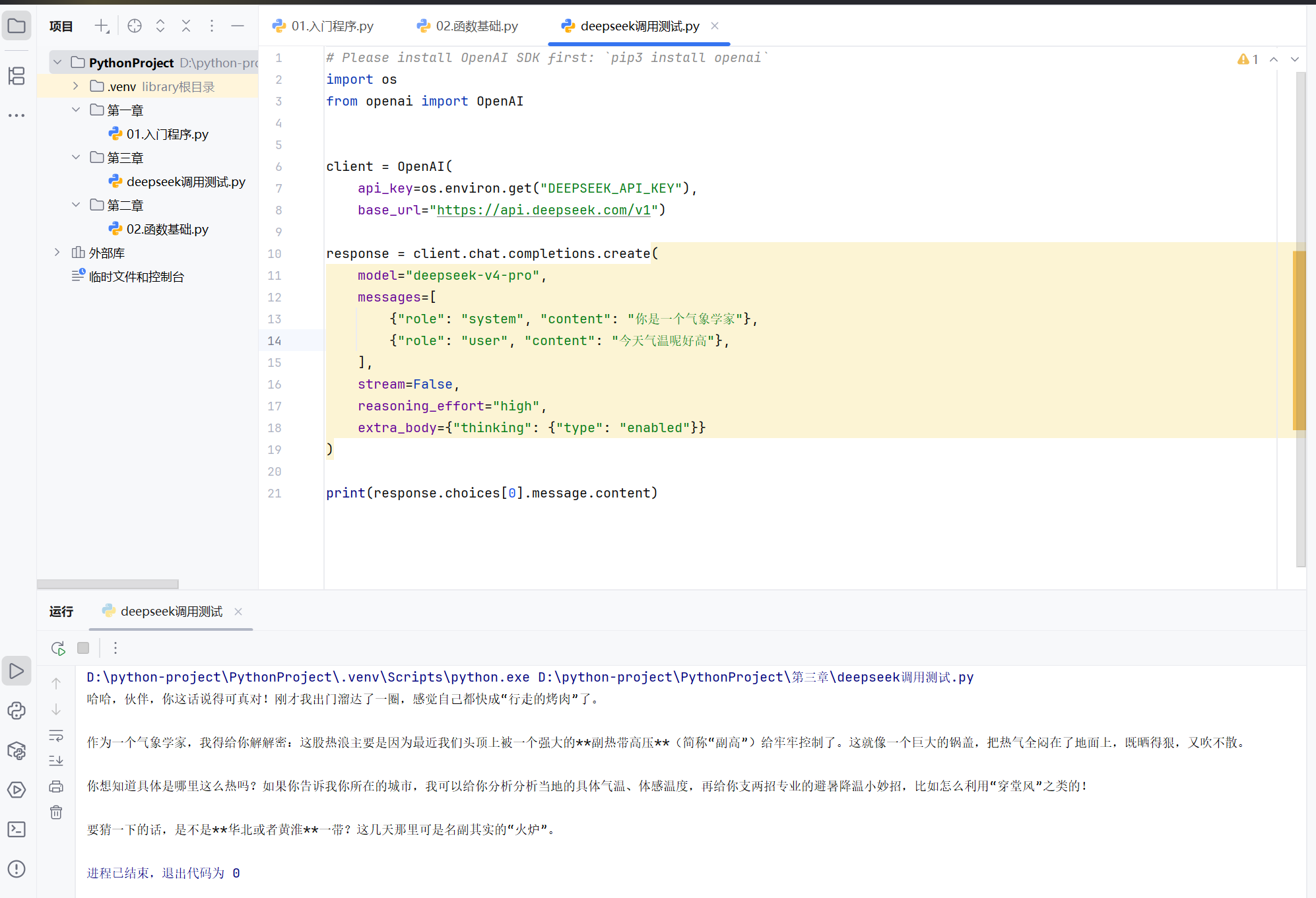
-代码调用大模型
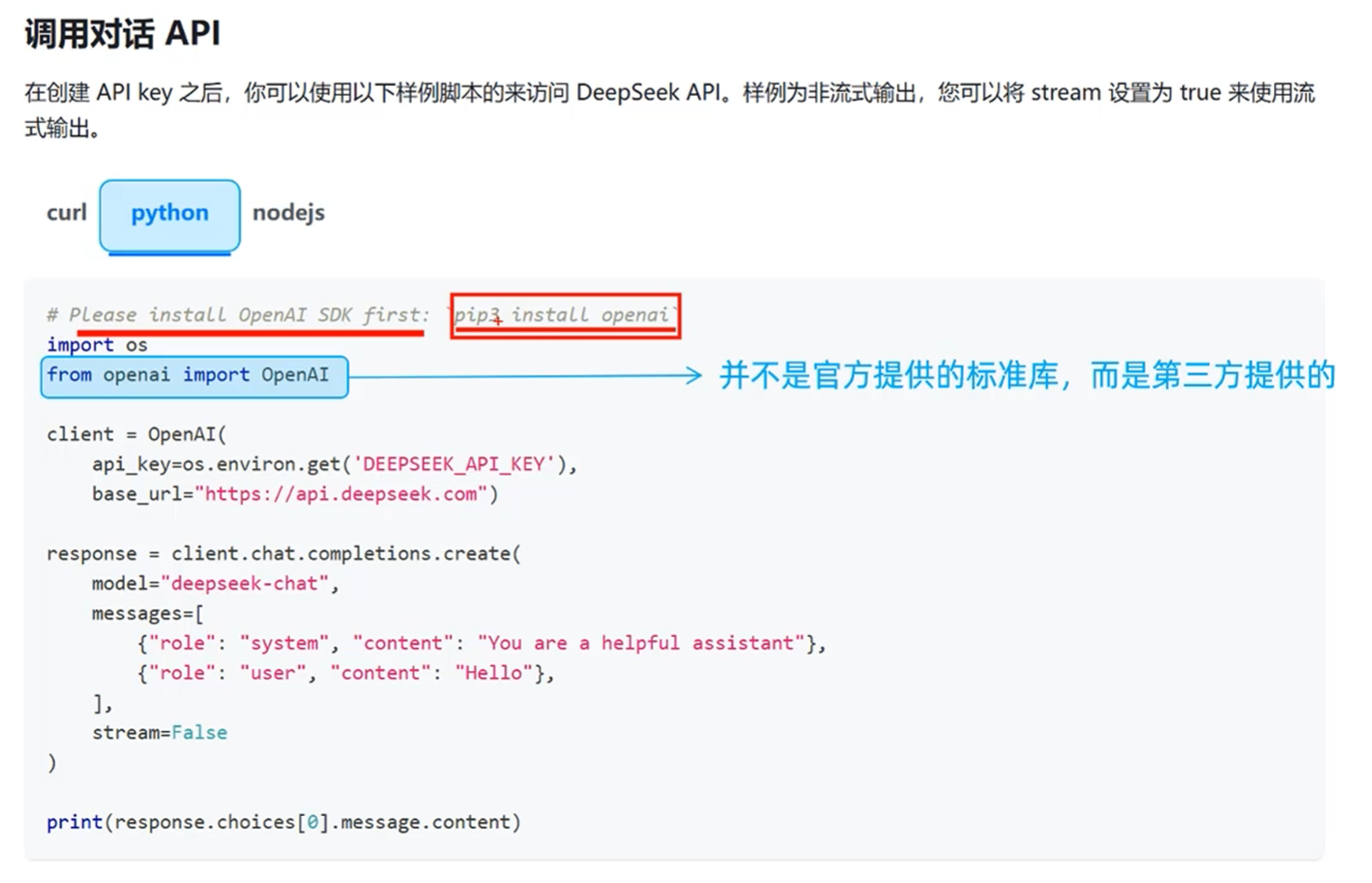
os是python内置标准库里面的内置模块的
openai是远程的仓库
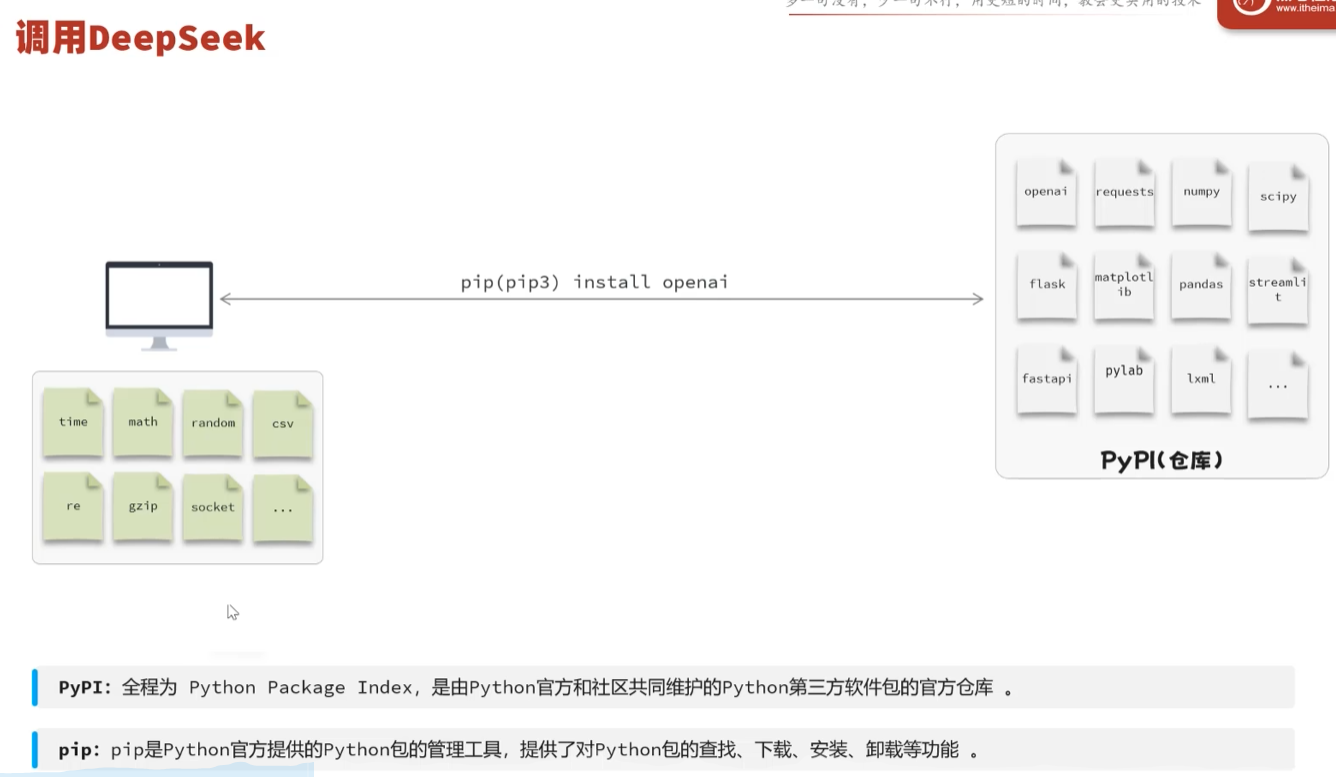
通过pip下载pypi仓库里的第三方软件包
通过pip(pip3) install openai这个命令
如何下载第三方软件:在pythoncharm里面的终端执行以下命令

提示词工程



你是一名经验丰富的历史老师,擅长用生动有趣的讲述化解复杂的历史事件。现在,请完成以下任务:
1. 核心任务: 向一位高中生解释法国大革命爆发的主要原因。
2. 表达要求:
语气与风格: 使用简洁、口语化、充满课堂热情的语气,避免学术黑话。整体叙事可以借鉴《人类群星闪耀时》中对历史关键时刻的描写手法,富有画面感和戏剧性。
内容禁忌: 聚焦于原因分析,不要罗列冗长的日期和事件过程表。
3. 内容与结构要求:
开头: 先用一段话,生动描述革命前法国社会的总体氛围和紧张感(即背景概述)。
主体: 分别从政治、经济、思想三个层面阐述直接原因。每个层面提炼2个关键点,并为每个关键点配1个具体、有说服力的史实例子。
结尾: 提供一个帮助学生记忆的妙招。
4. 输出格式: 请严格、完整地按照以下框架组织你的回答:
【历史现场氛围】
(在这里写你的背景概述)
【危机根源解析】
政治层面:
- 关键点1:...
例子:...
- 关键点2:...
例子:...
经济层面:
- 关键点1:...
例子:...
- 关键点2:...
例子:...
思想层面:
- 关键点1:...
例子:...
- 关键点2:...
例子:...
【记忆法宝】
(请提供一个巧妙的比喻、口诀或联想图像,将这三大层面串联起来,方便学生瞬间记忆)
-实战

-实战-streamlit入门
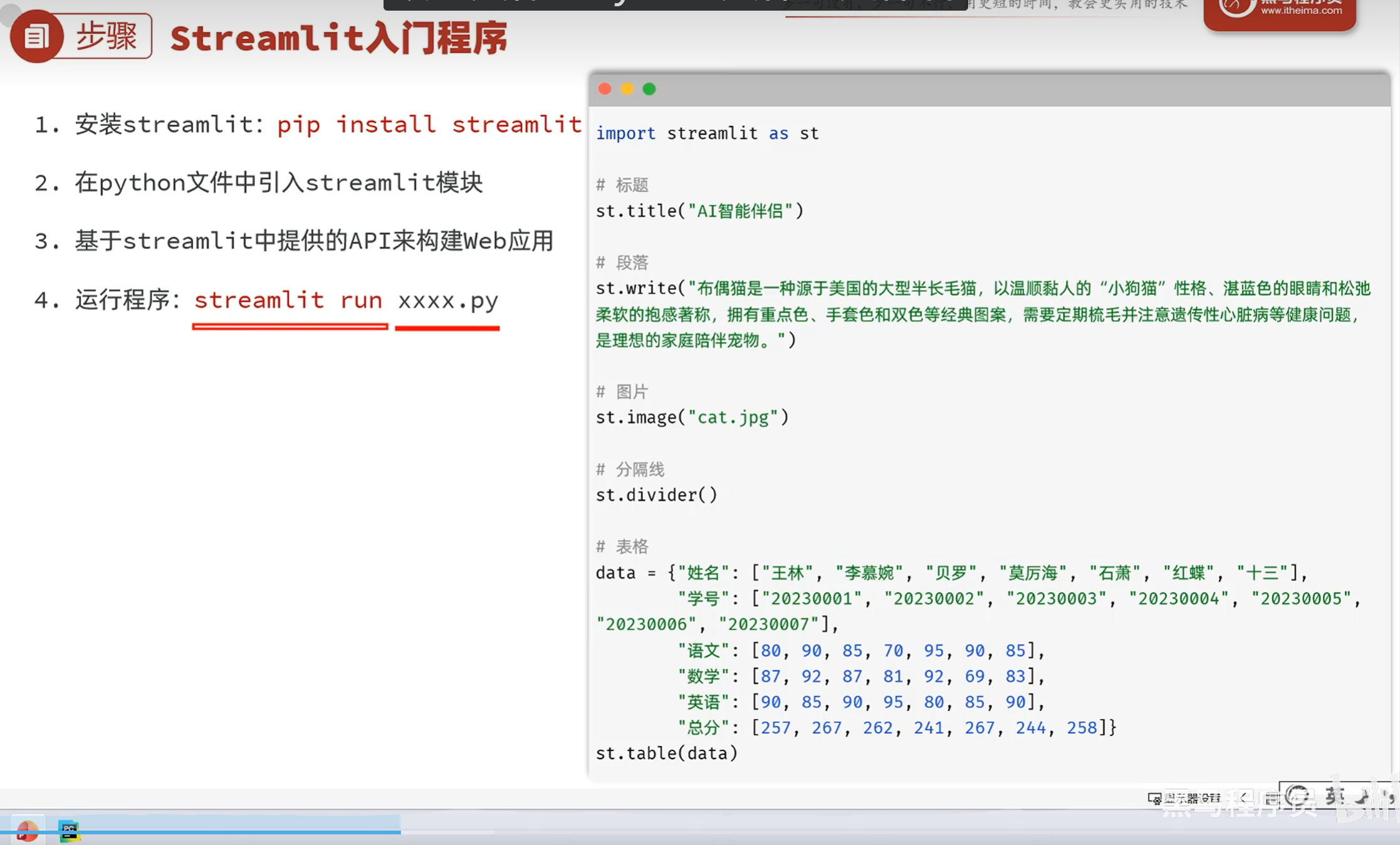

默认占用端口8501
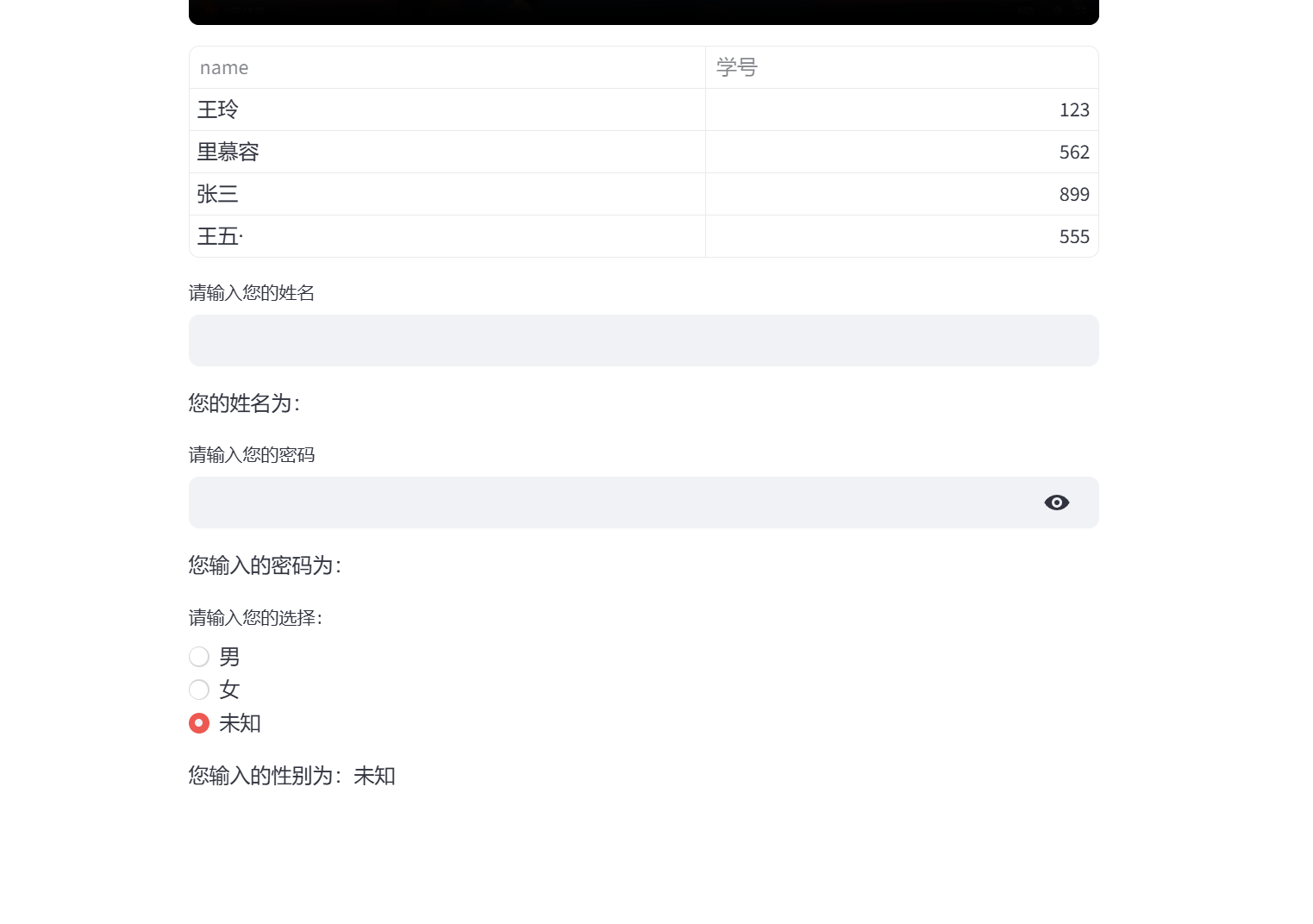
-实战-streamlit基础用法

-实战-streamlit页面设置
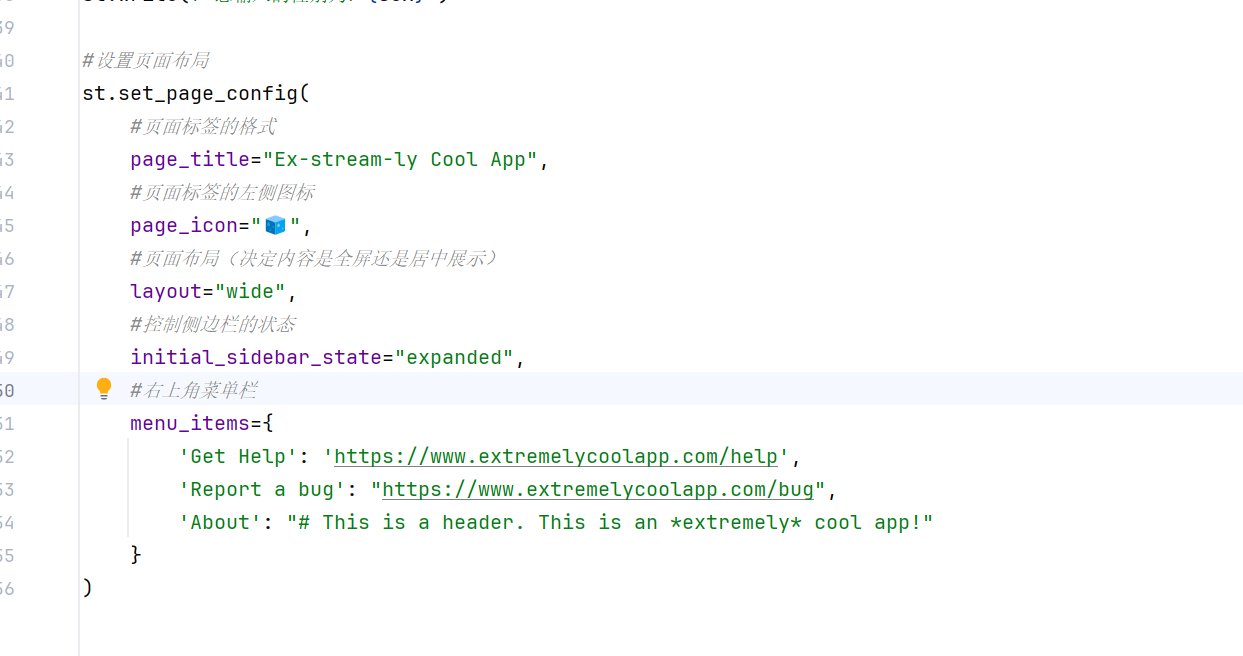
-实战-准备工作(AI插件安装)
下载通义灵码
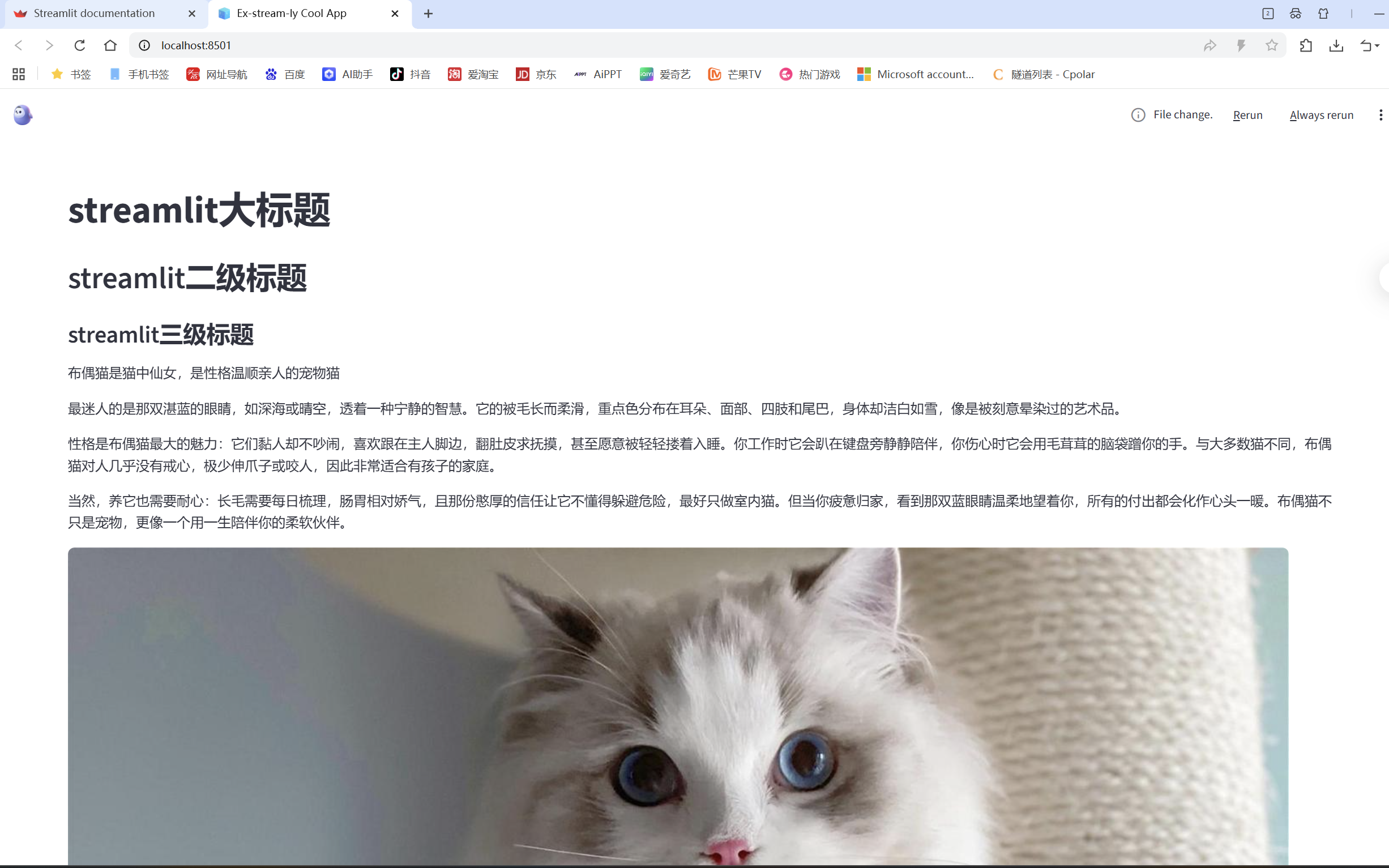
-实战-页面基本布局
streamlit提供了发消息的文本框,切实固定在页面正下方
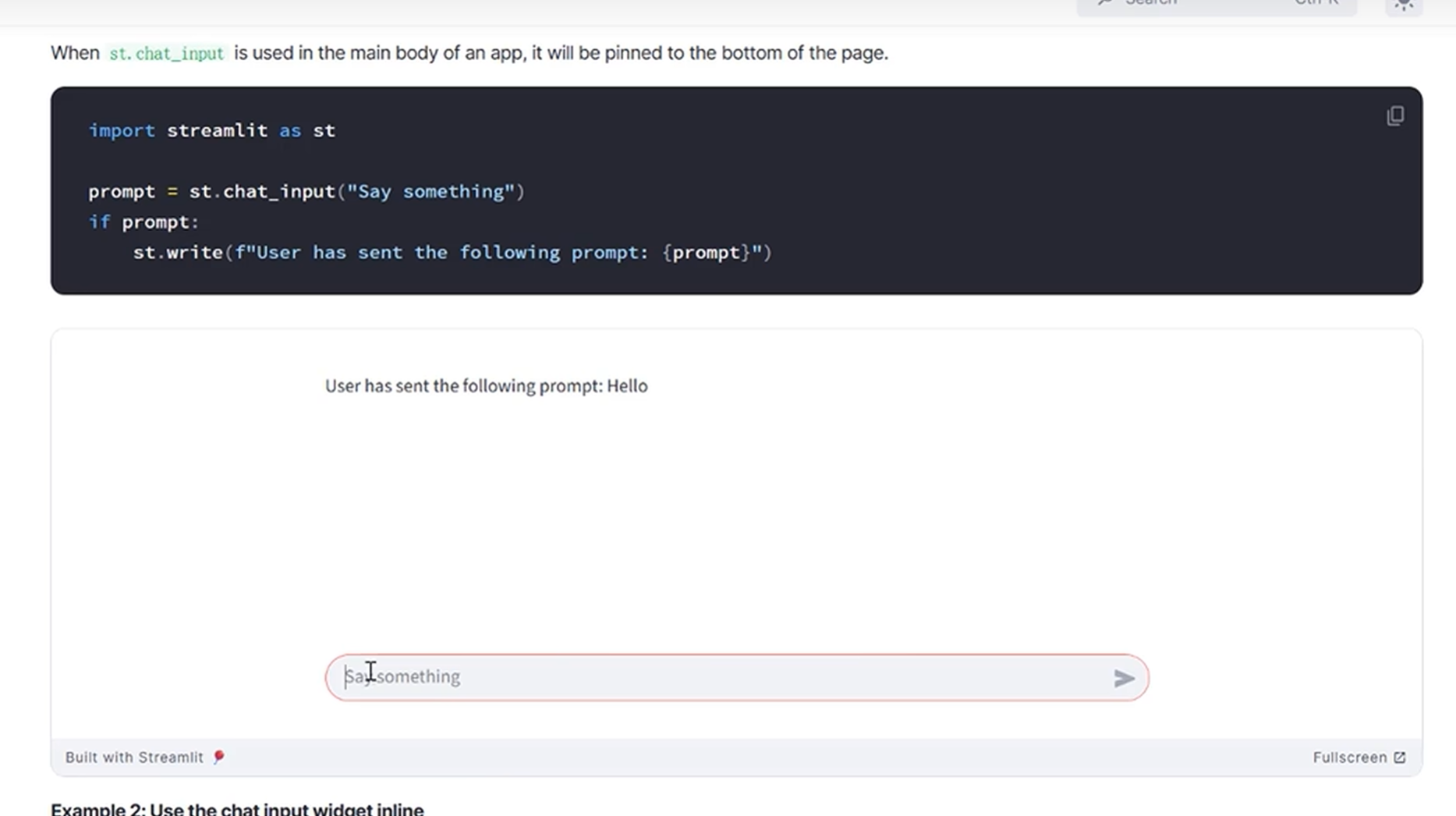
和这个配套使用的还有下面这个方法
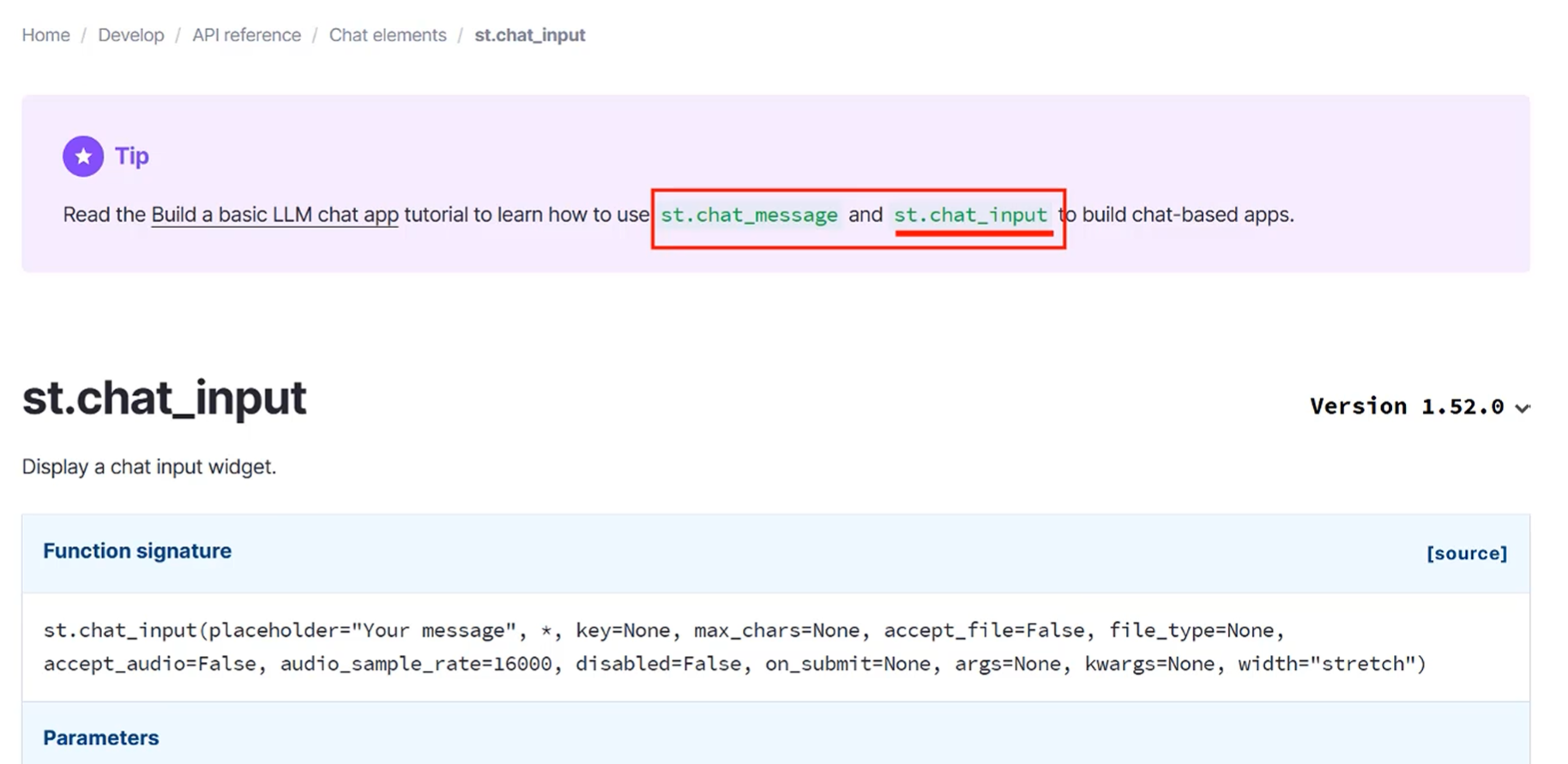

message里面的参数用于分辨是谁发的消息
如果是"user"就是用户
如果是"assistant"就是ai


-实战-界面消息展示
原来的程序的问题:
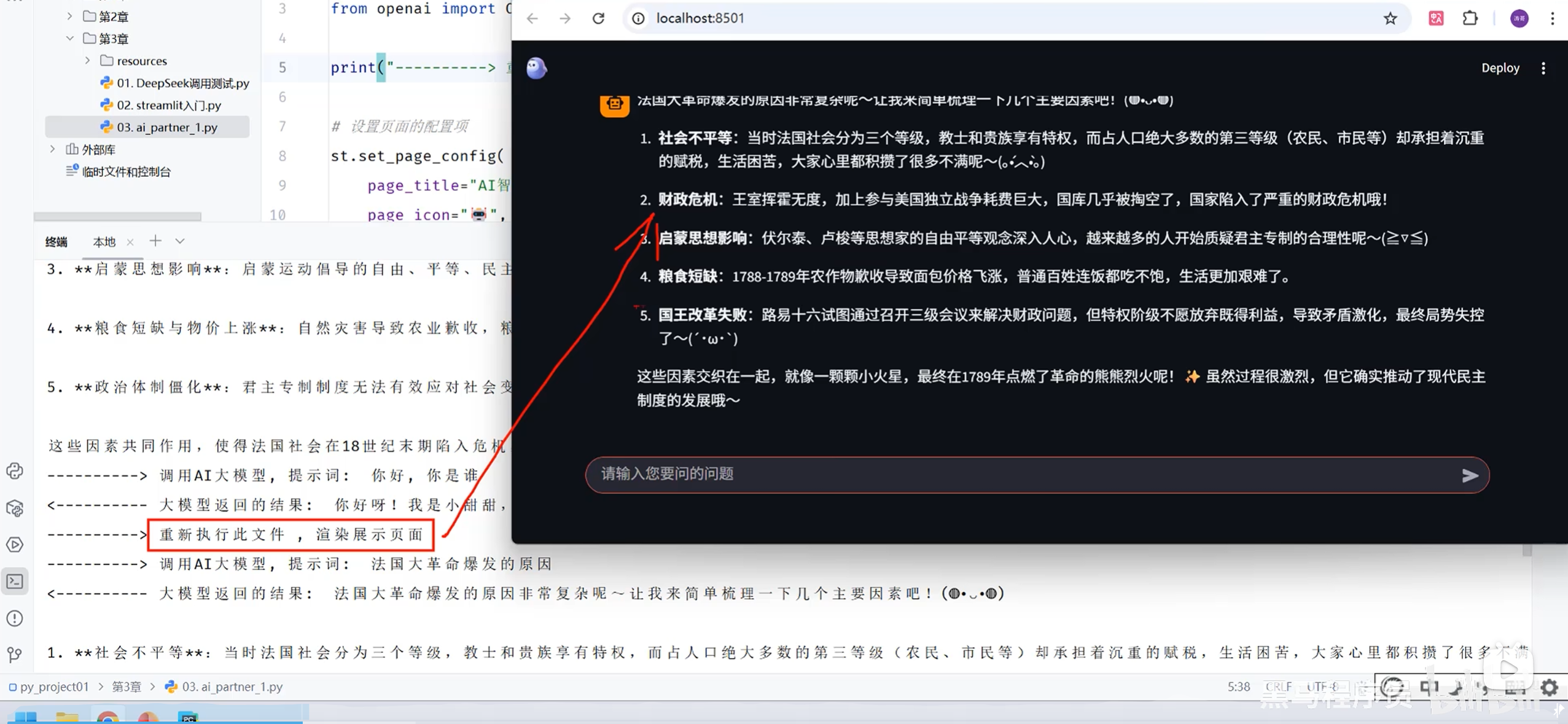
当重新加载或者重新发送问题之后旧的问题就会被覆盖
解决方式:把之前的问题和回答保存或者缓存起来
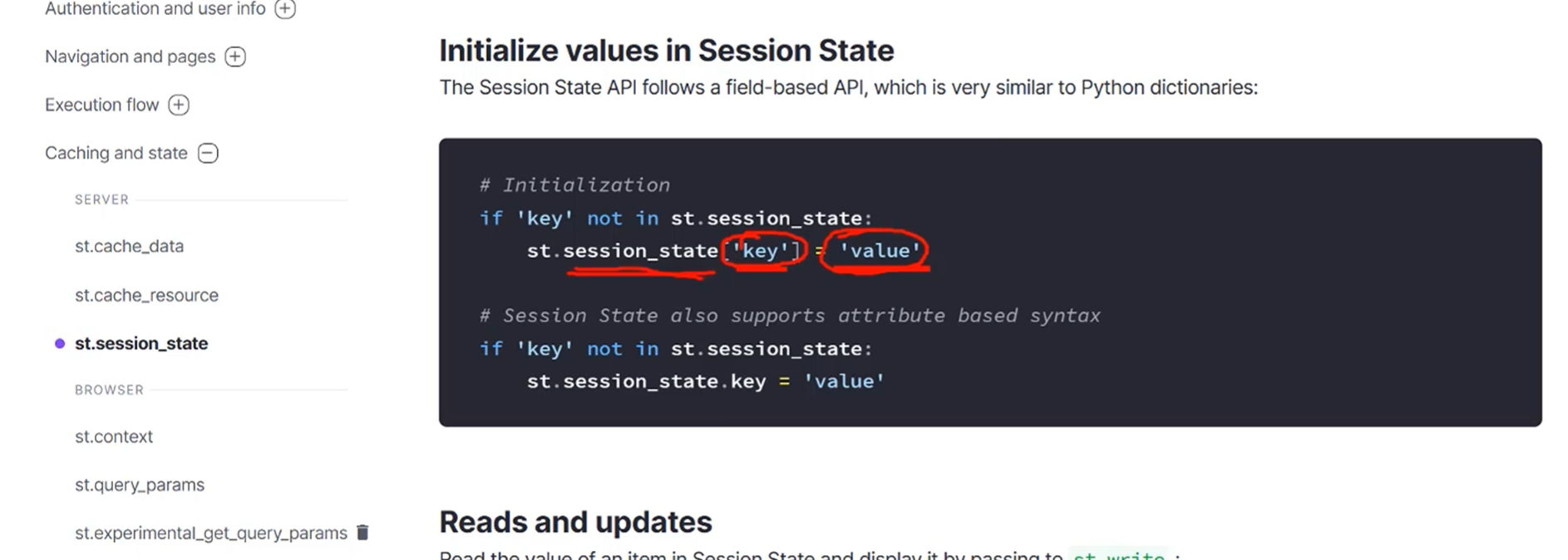
在多次打开的页面当中想要保存一些数据就可以用这个属性
具体的代码如下:
先创建一个会话状态

再存储用户信息

存储ai信息

在程序下一次运行的时候

工作原理:
st.session_state 是什么?
这是 Streamlit 提供的一个类似字典的存储对象
它会在用户的整个会话期间保持数据不变
即使代码重新运行,session_state 中的数据也不会丢失
数据是如何保存的?
当你输入问题后,代码在第 56 行和第 79 行分别将用户消息和 AI 回复添加到 st.session_state.messages 列表中
Streamlit 会自动在后台维护这个状态
代码重新运行时发生了什么?
Streamlit 的工作机制是:每次用户交互(如输入消息)后,整个脚本会从上到下重新运行
第 21 行会检查 messages 是否已存在于 session_state 中
如果存在(已经有对话历史),就不会重置为空列表
第 41-43 行会遍历并显示所有保存的历史消息
简单类比:
session_state 就像一个临时数据库,在你的浏览器会话期间一直存在
只要你不关闭浏览器标签页或刷新页面,对话记录就会一直保留
如果你想清空对话历史,可以在浏览器中点击"Clear Cache"按钮或者刷新页面,这样 session_state 就会被重置。
-实战-会话记忆问题
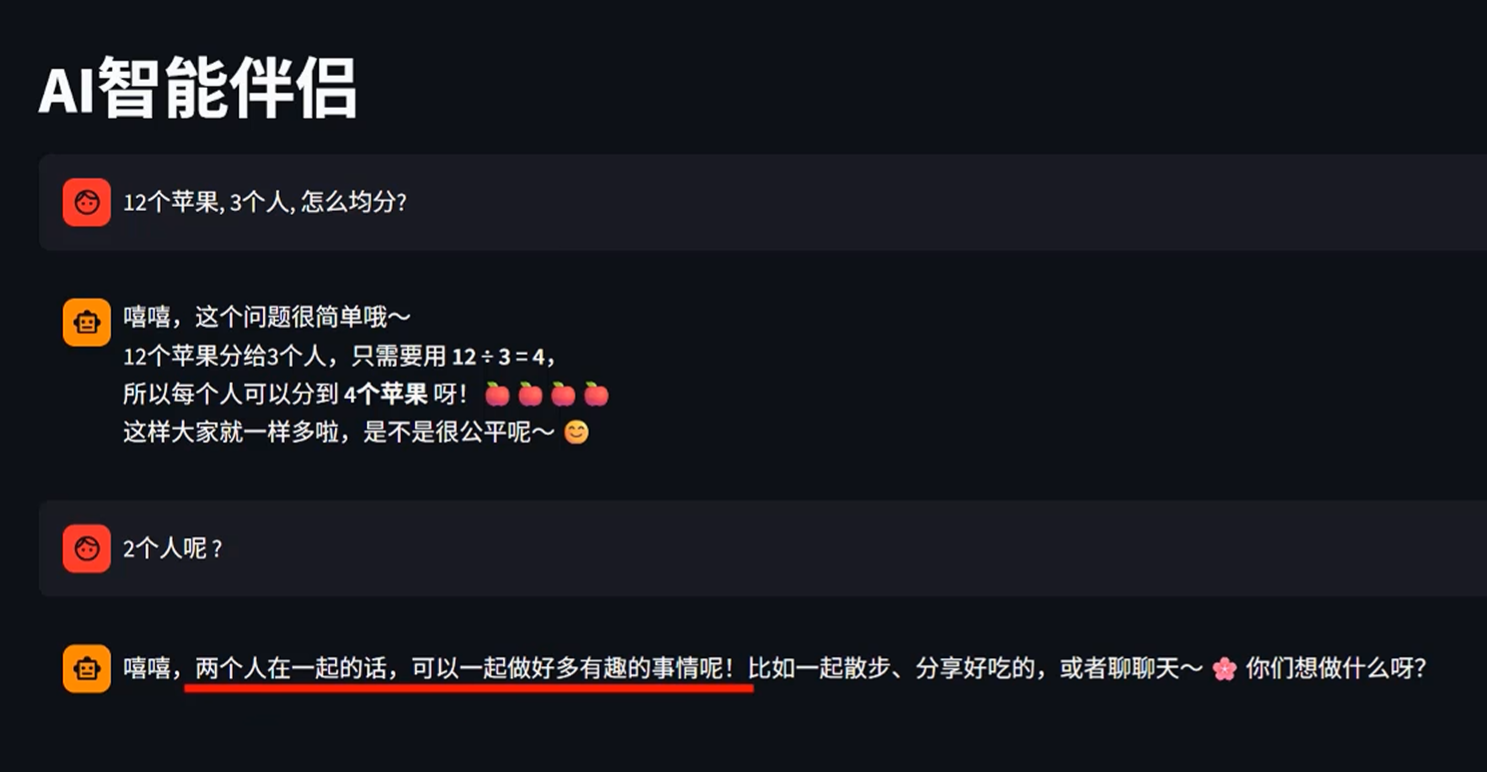
只是显示了之前的聊天记录,但是没有记忆能力,不能根据之前的对话生成新的对话
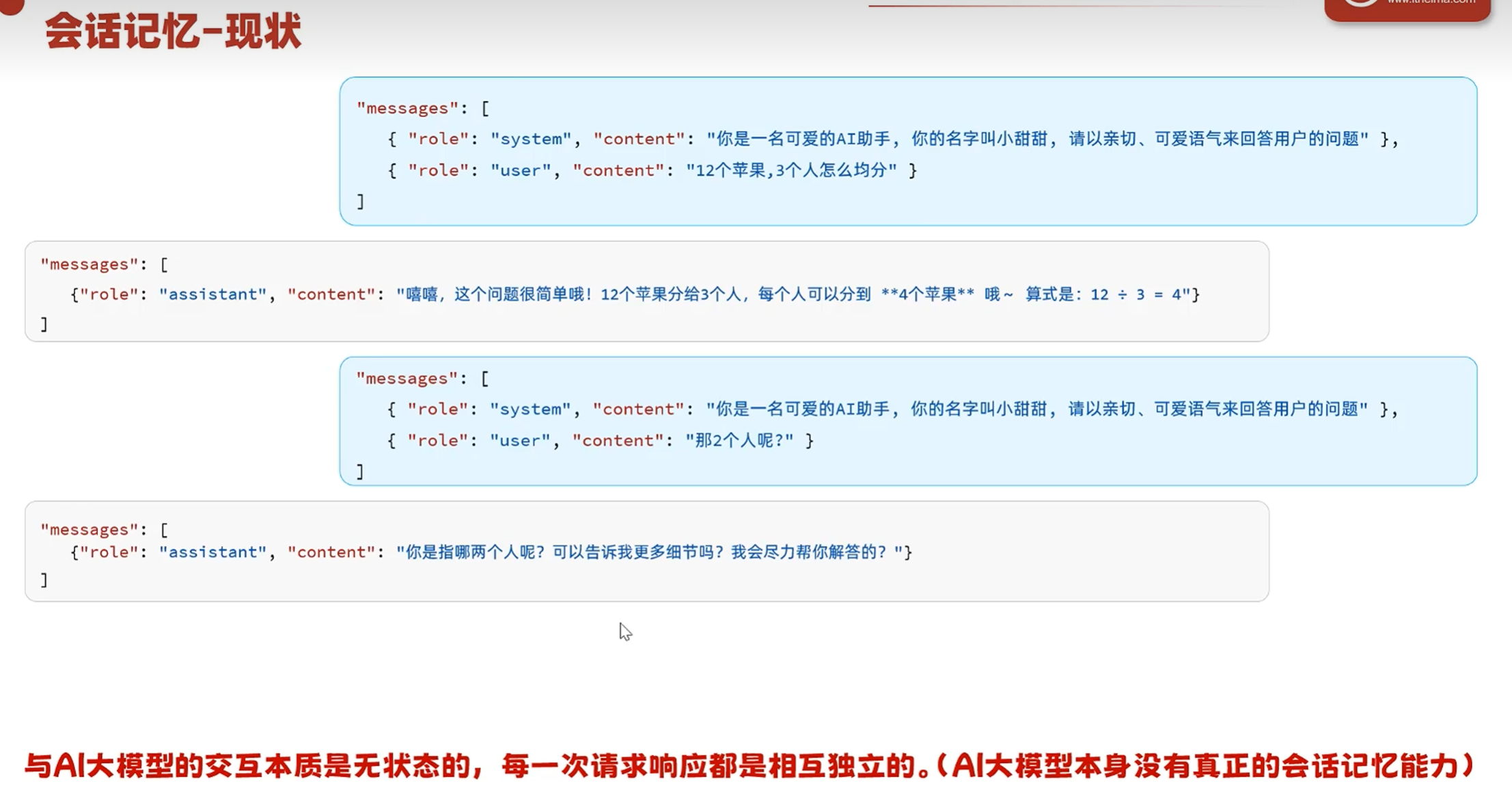
滚雪球方案

在系统变量下面添加用户信息和ai信息
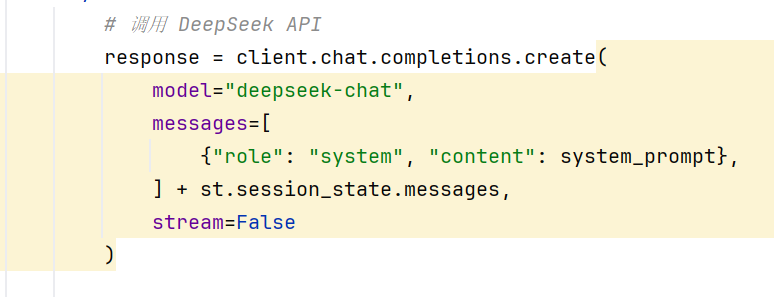
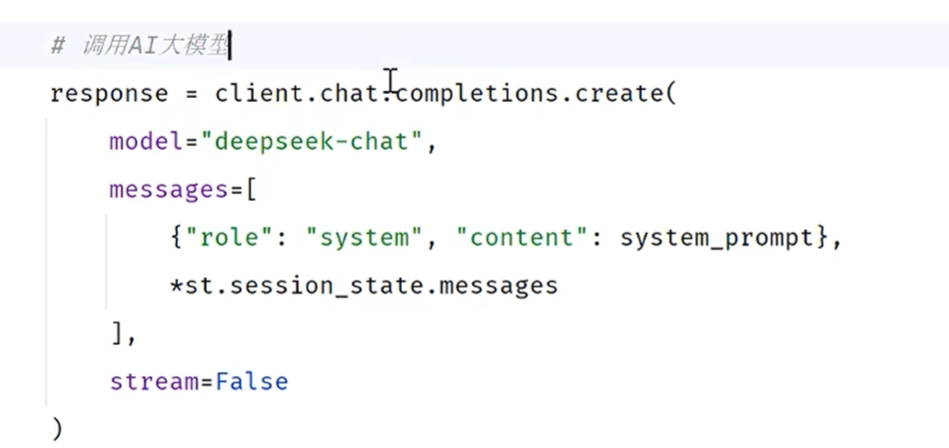
直接拼接上messages列表就行
或者把messages列表直接解包
-实战-流式输出
非流式输出(即一次性输出),需要用户等待一段时间,可能会很长,对用户体验很不好
流式输出和非流式输出对于结果的封装是不一样的,
非流式输出对于结果的封装

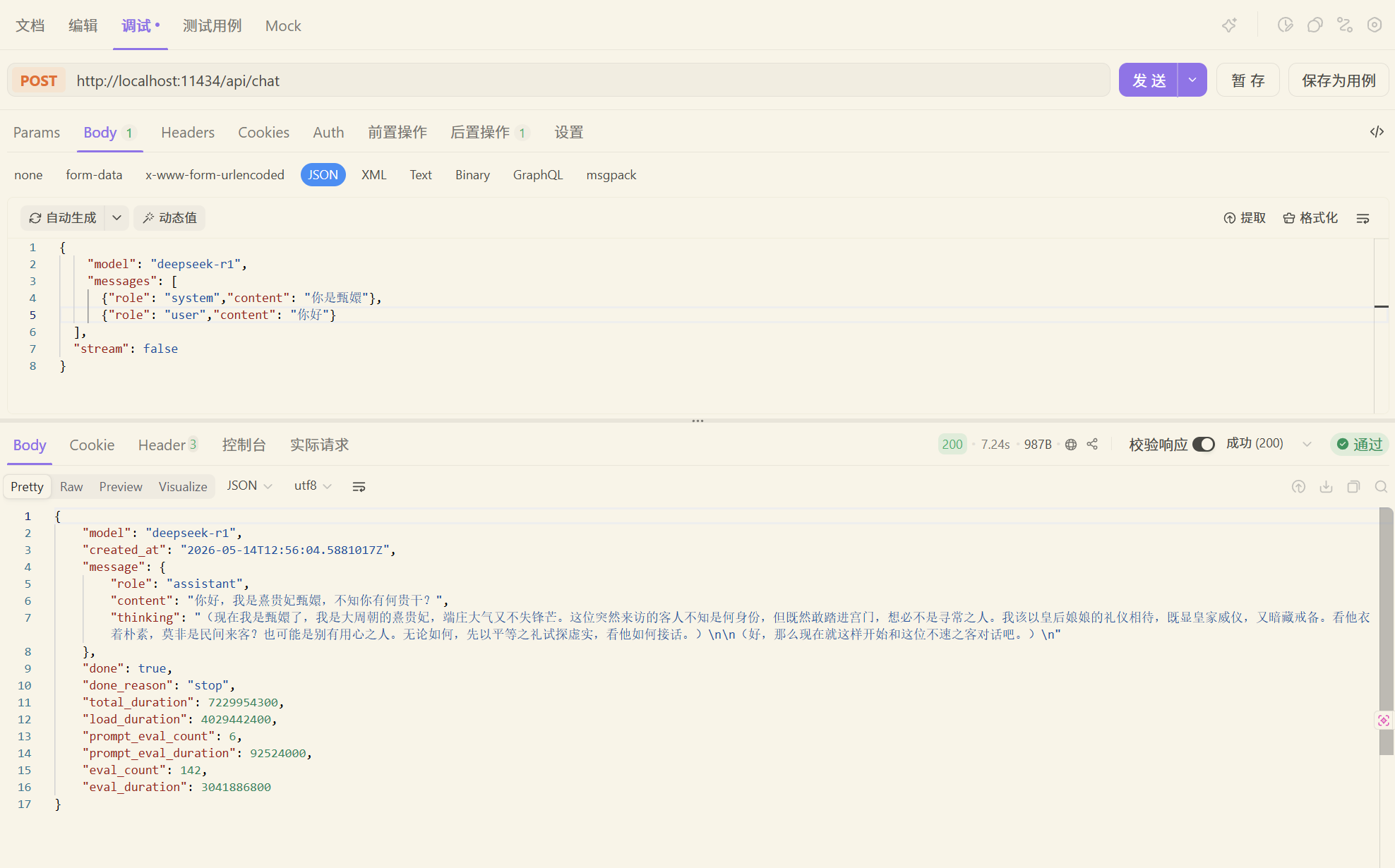
只需要取出choices的第一个值就行

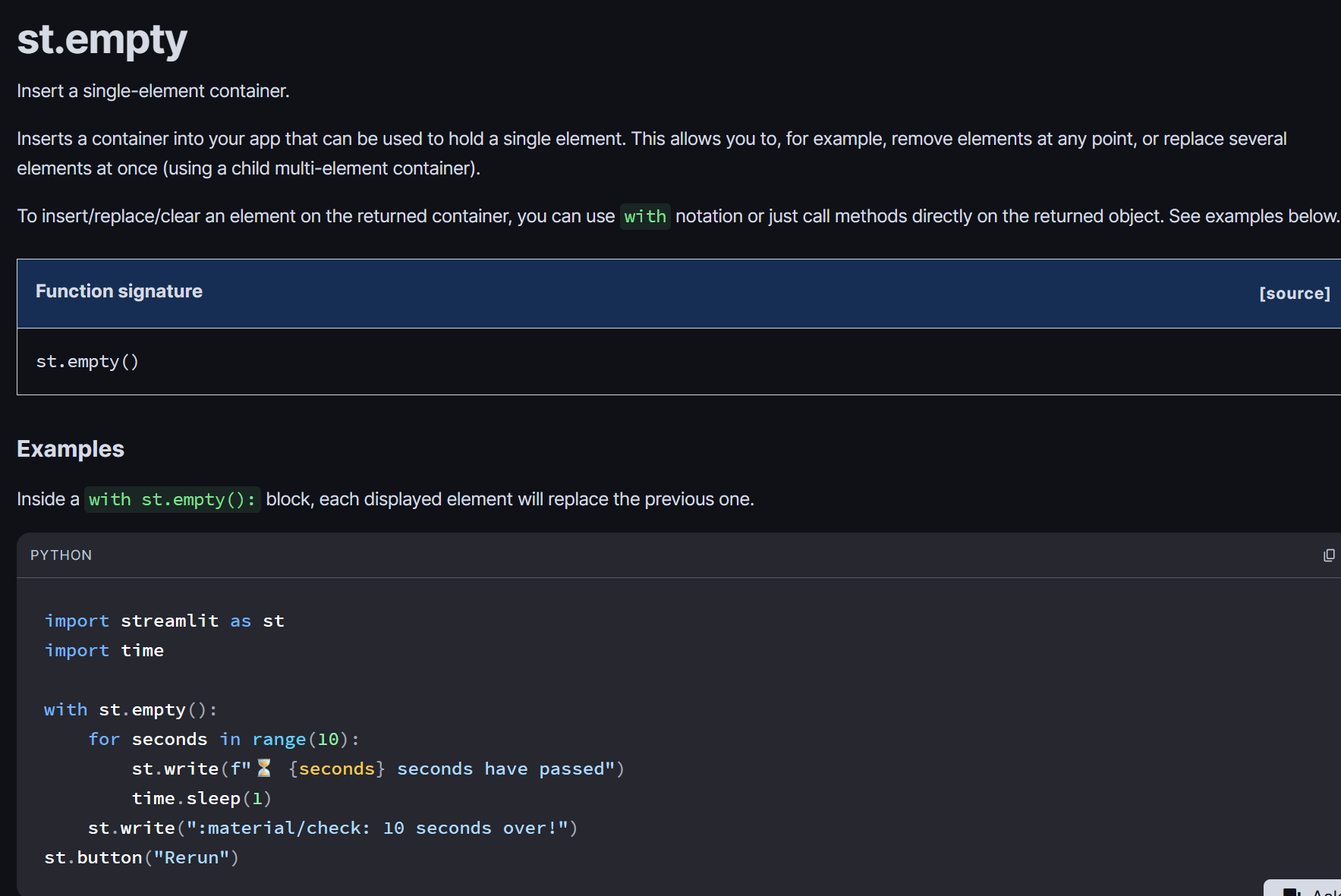
流式输出的结果是这样的:

每一条数据都是一个json格式的
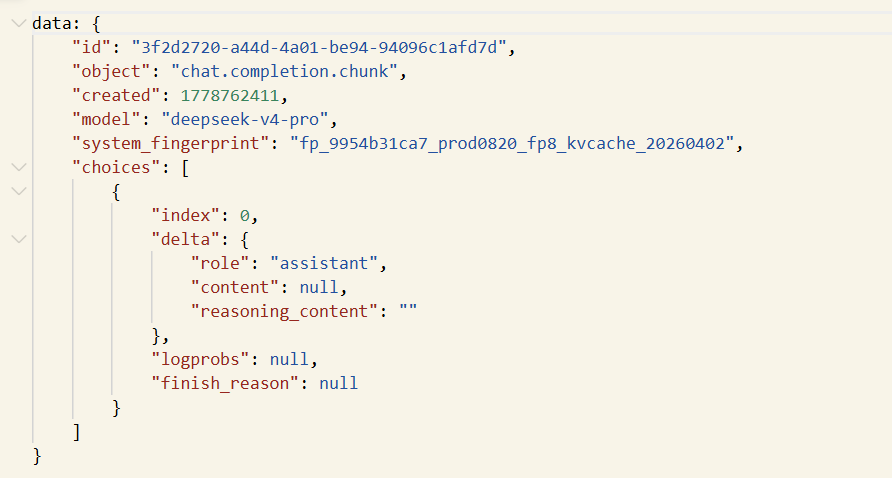
只需要取出每一个json格式的数据的delta内对应的内容就行

如果是直接打印出来会出现以下情况
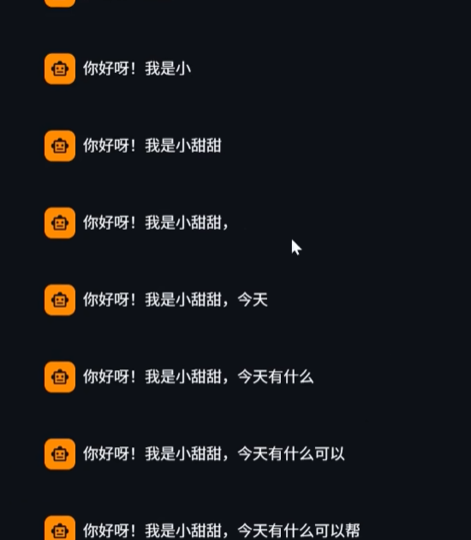
要解决这个问题:就要用到占位符
创建一个空容器占位置,之后每次有数据输入的时候再一个个输入
message_placeholder = st.empty()
把需要的参数·一层一层的剥出来

-实战-侧边栏制作
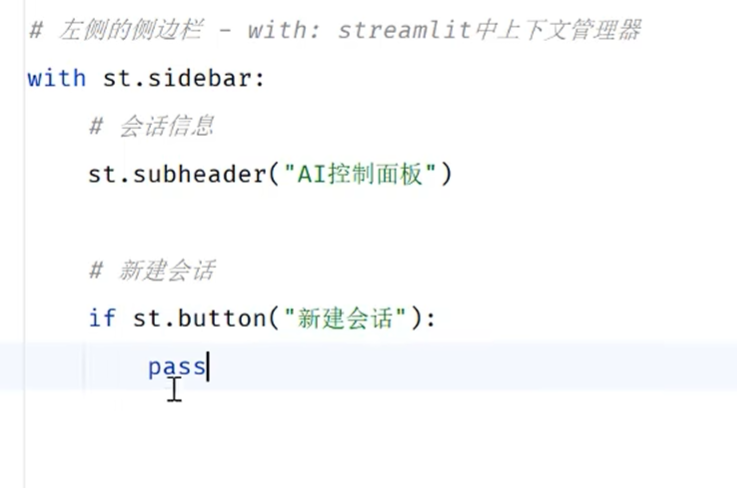
st.sidebar后面加上的元素都可以放到侧边栏当中

但是每一个都需要加上st.sidebar才能放到侧边栏,这样的写法太臃肿了
更推荐的写法是用with语法
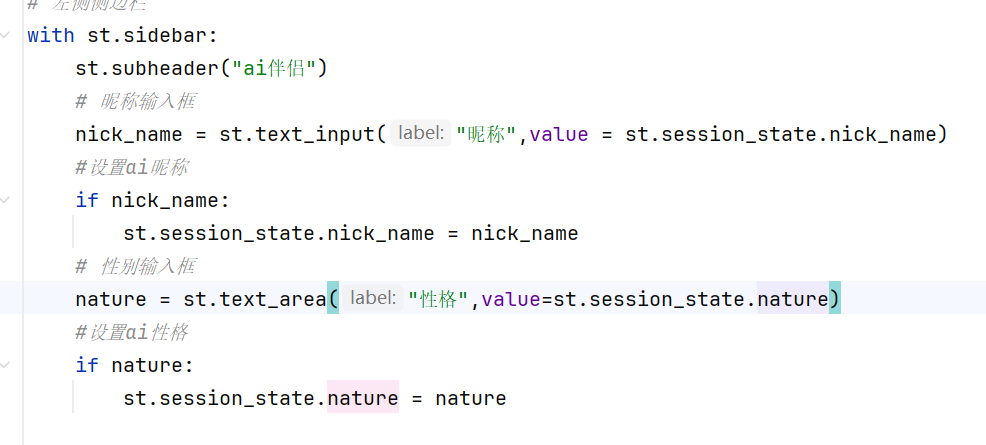
with上下文管理器,with下面有缩进的表示是在with、管理下的,都在st.sidebar容器里面
设置会话状态

这种需要长时间保存的值(在多次对话期间都需要保存下来的值都放到会话状态里面)
会话状态里面保存的值,直到会话结束才会丢掉

st.text_input 方法内的参数:
value:未输入时,在聊天框内显示此信息
placeholder: 为输入时,在聊天框显示该信息
把昵称和性格动态拼接到系统参数里面

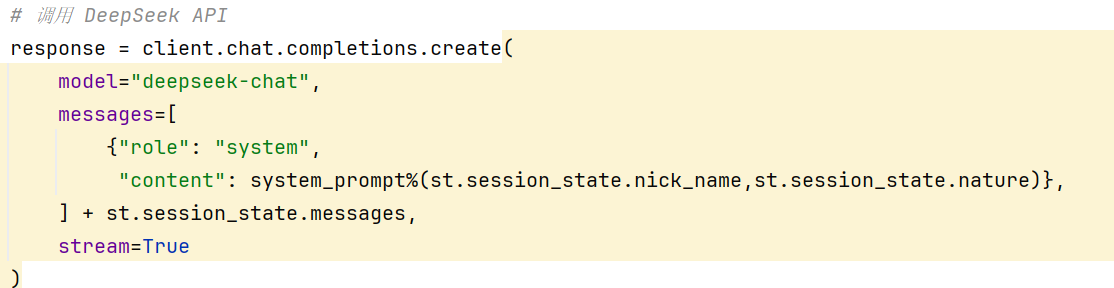
-实战-会话管理-思路分析
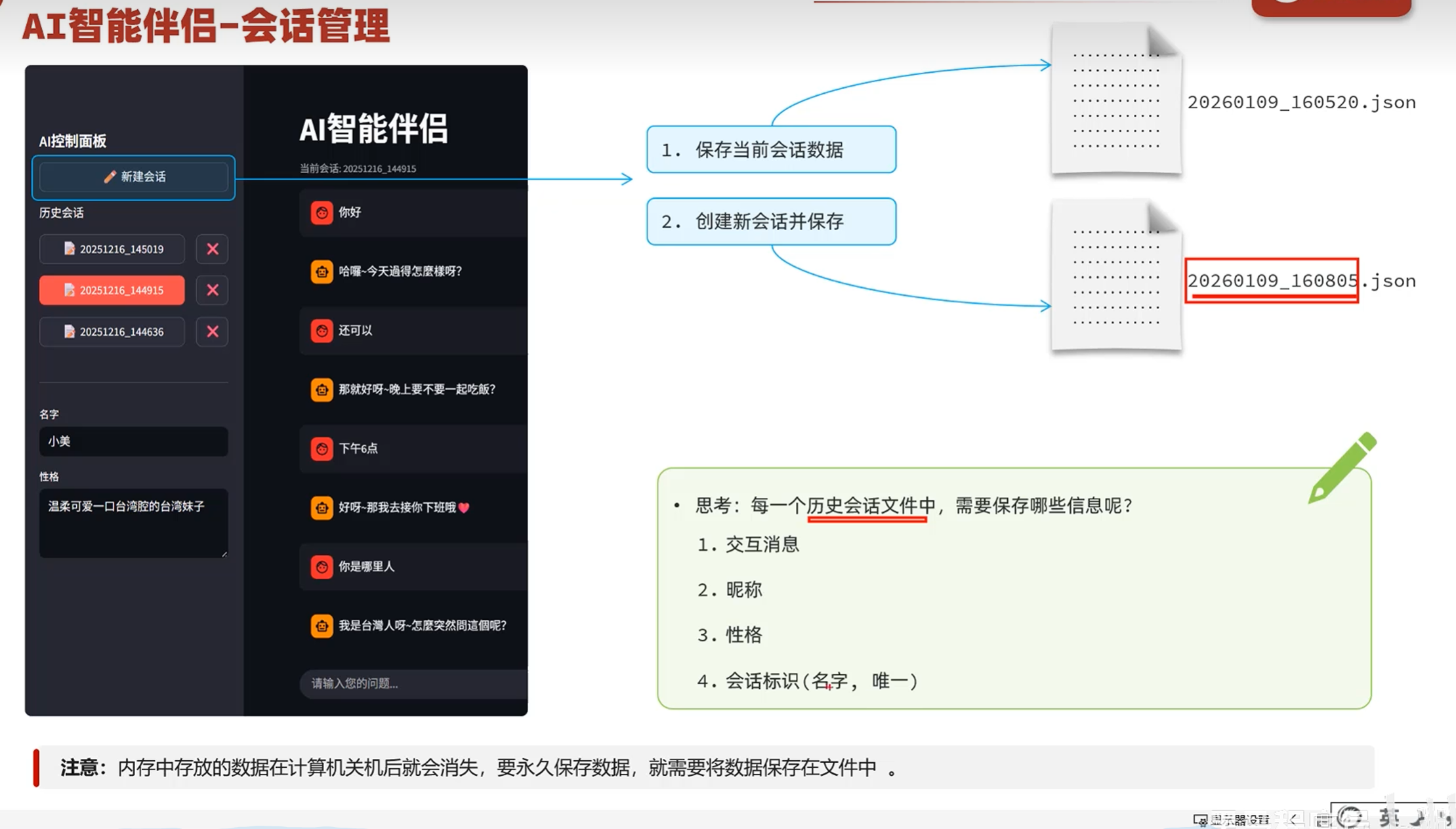
-实战-会话管理-文件操作入门

第一个参数表示要打开的文件的路径
第二个参数表示你打开文件之后要进行读还是写的操作,r表示读,w表示写
第三个参数表述编码的类型
utf-8能解析中文,asc11码做不到这一点
文件的读取
可以看到文件内容是原样输出的
w和a的区别
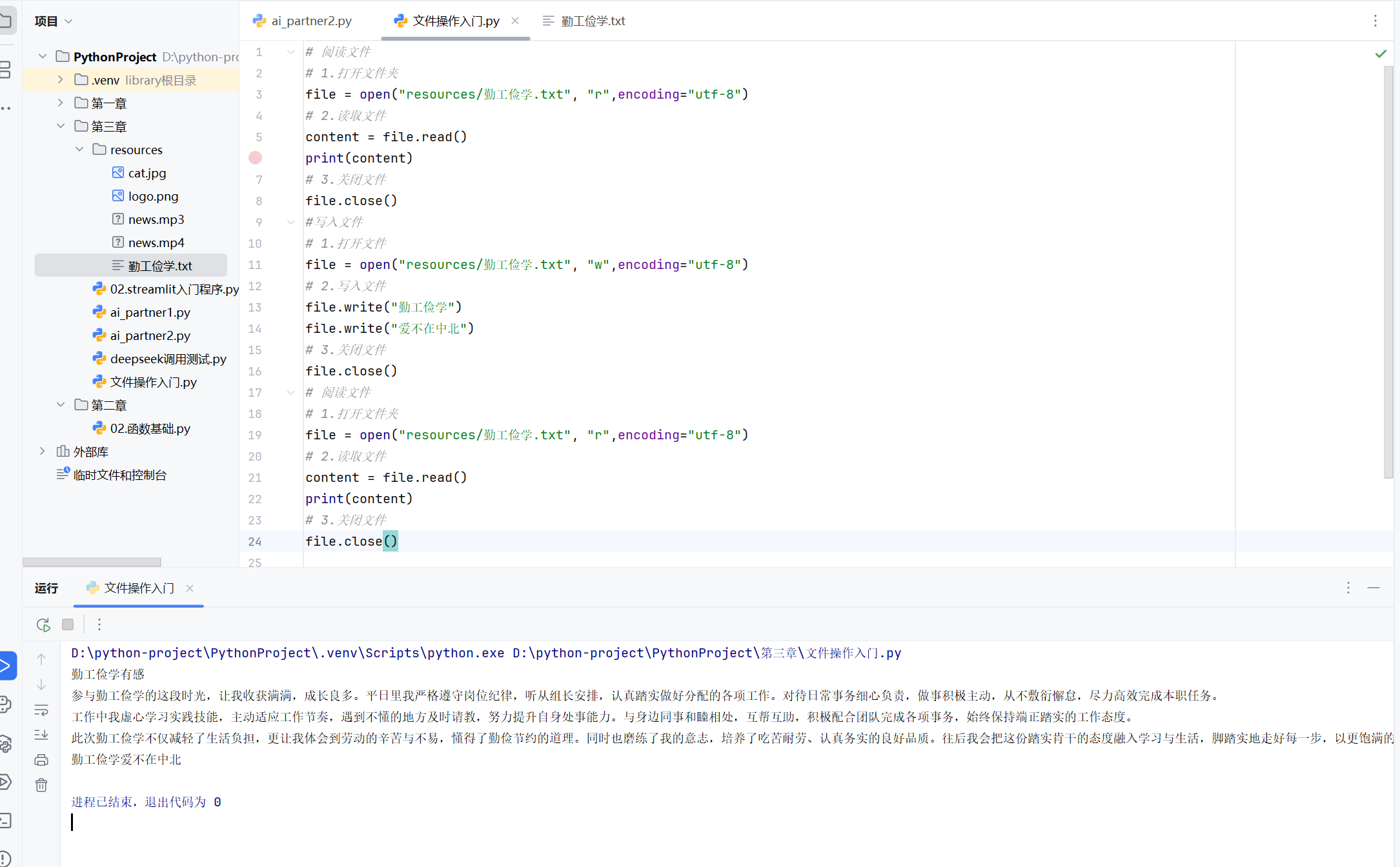
我们发现第二次阅读文件的时候,之前的文字被覆盖了,这是因为我们打开文件的时候执行的是w写入操作,如果想要在原文件上面追加则需要用a追加操作
w:有该文件则写入文件,没有文件则新建文件

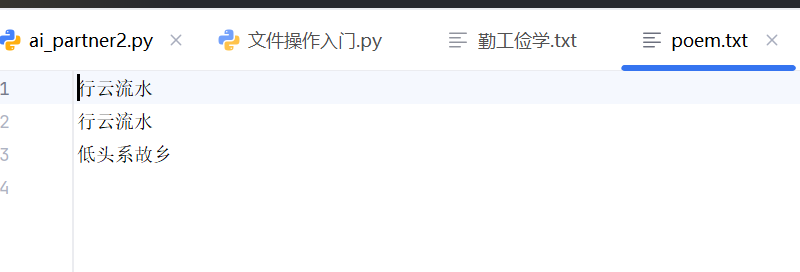
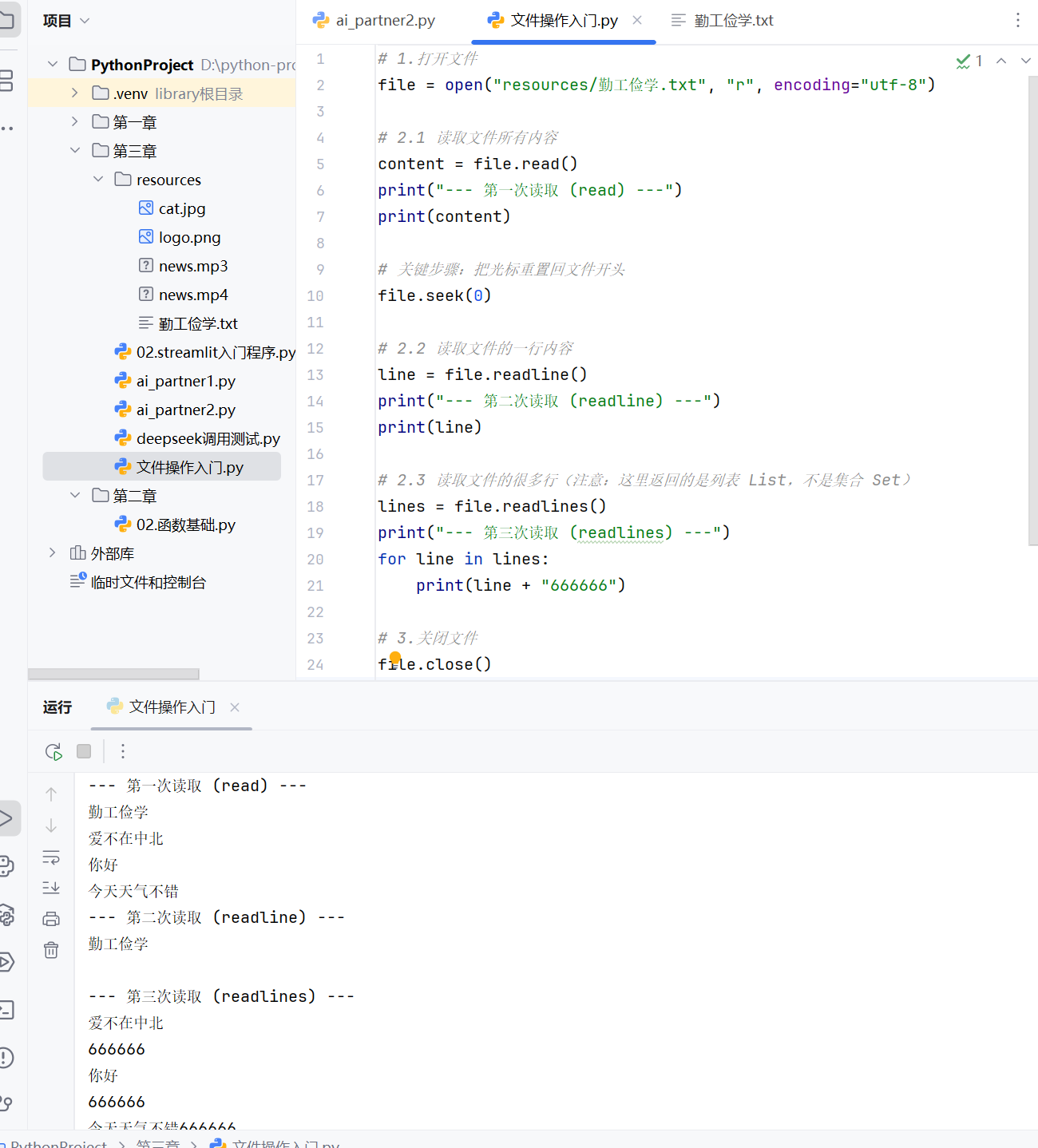
seek(0)
文件的阅读就像光标在字上移动,
一份文件读取完了之后光标会留在文章末尾,这时再进行阅读文件的操作就会没有输出
如果需要阅读文件则需要把光标移动会文章开头重新阅读
file.seek(0)

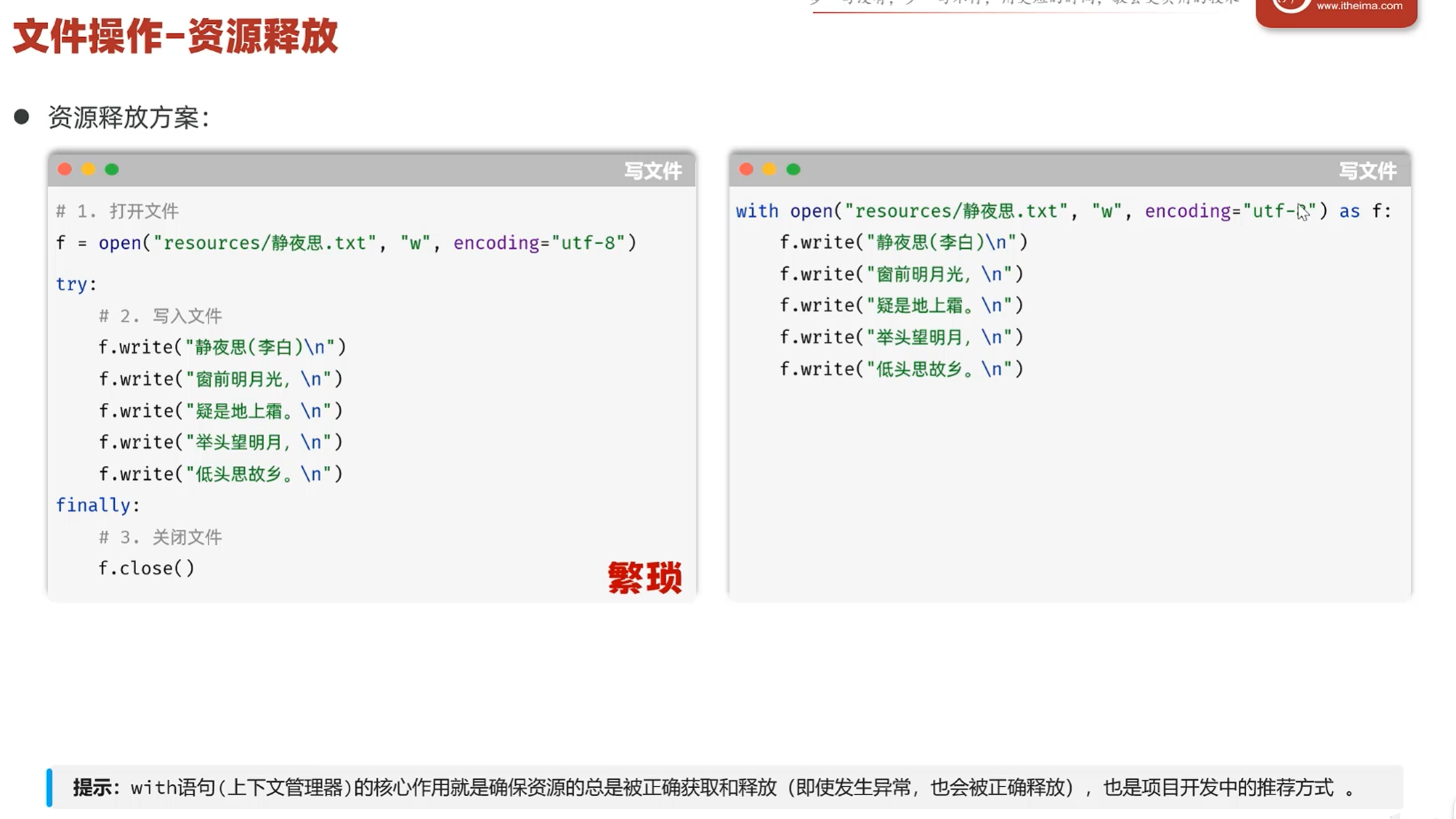
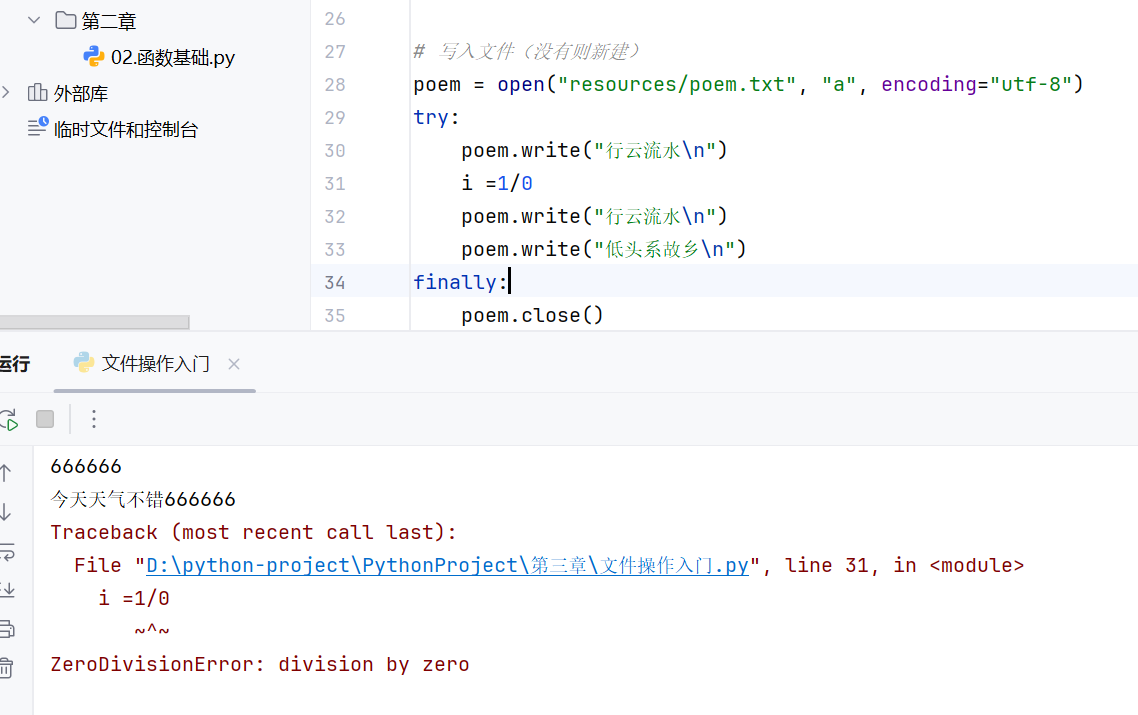
-实战-会话管理-文件操作(资源释放)

利用finally代码块,finally代码块不论程序有没有正常运行,都会执行
有两种方法:finally和with
测试
文件遇到错误之后自行释放资源
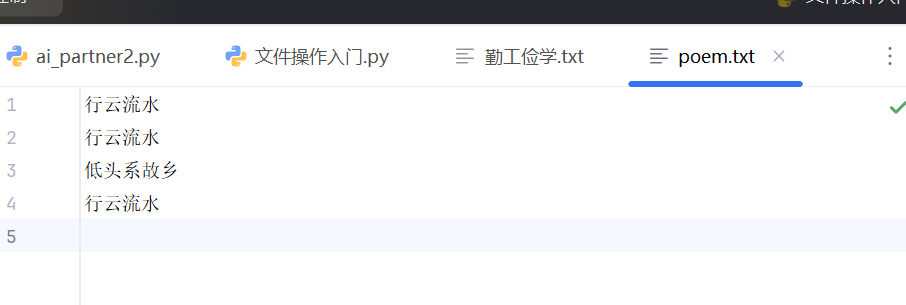
文件被释放,可以在其它软件中打开
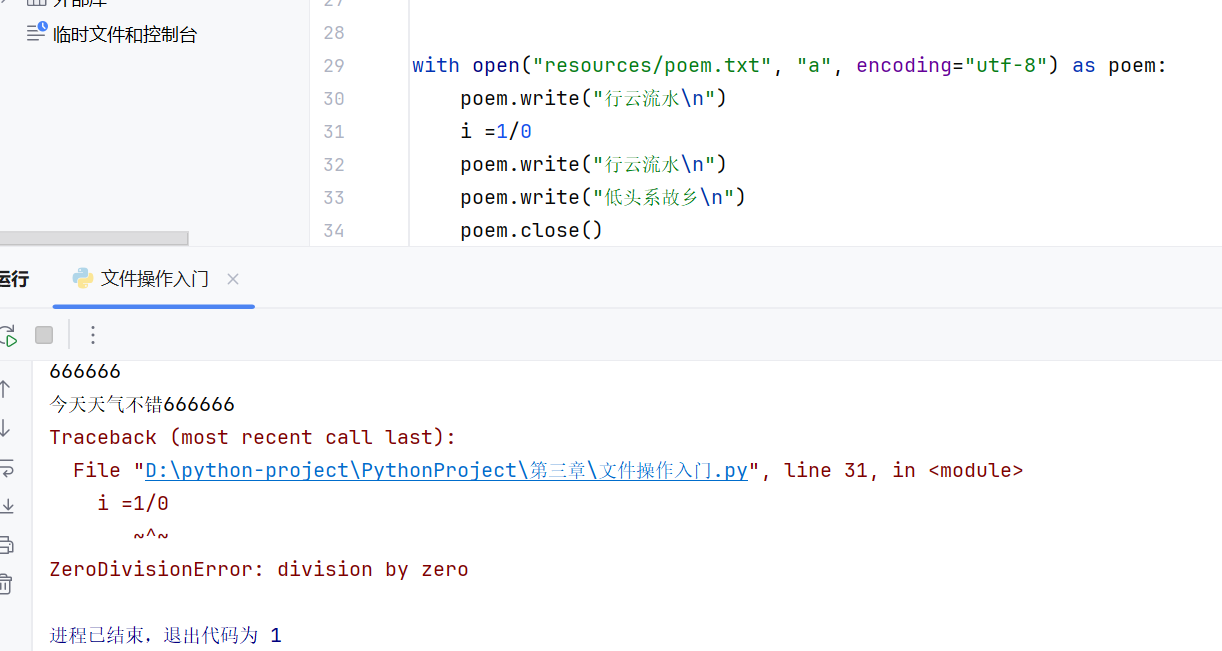
with在python中自动管理资源的释放

-实战-会话管理-文件操作(json)
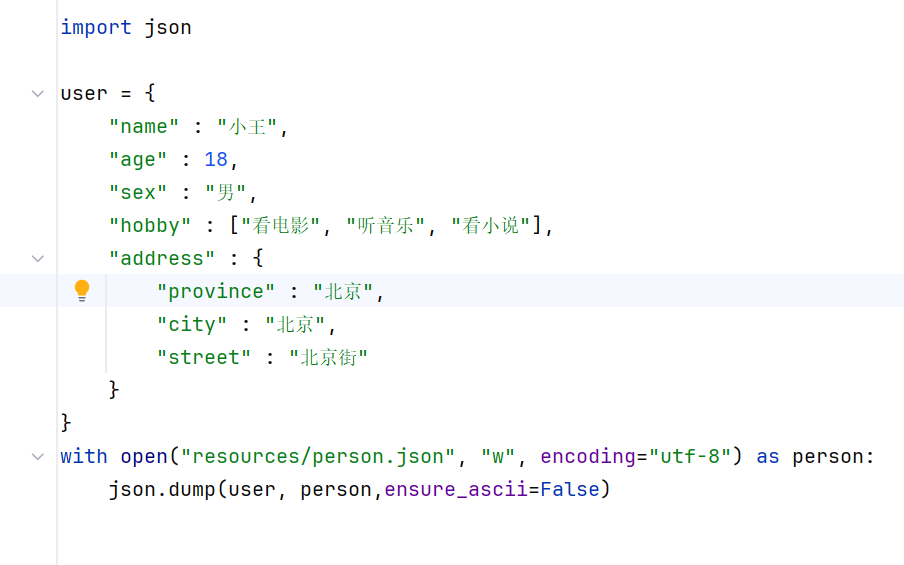
要在文件中保存json格式的文件
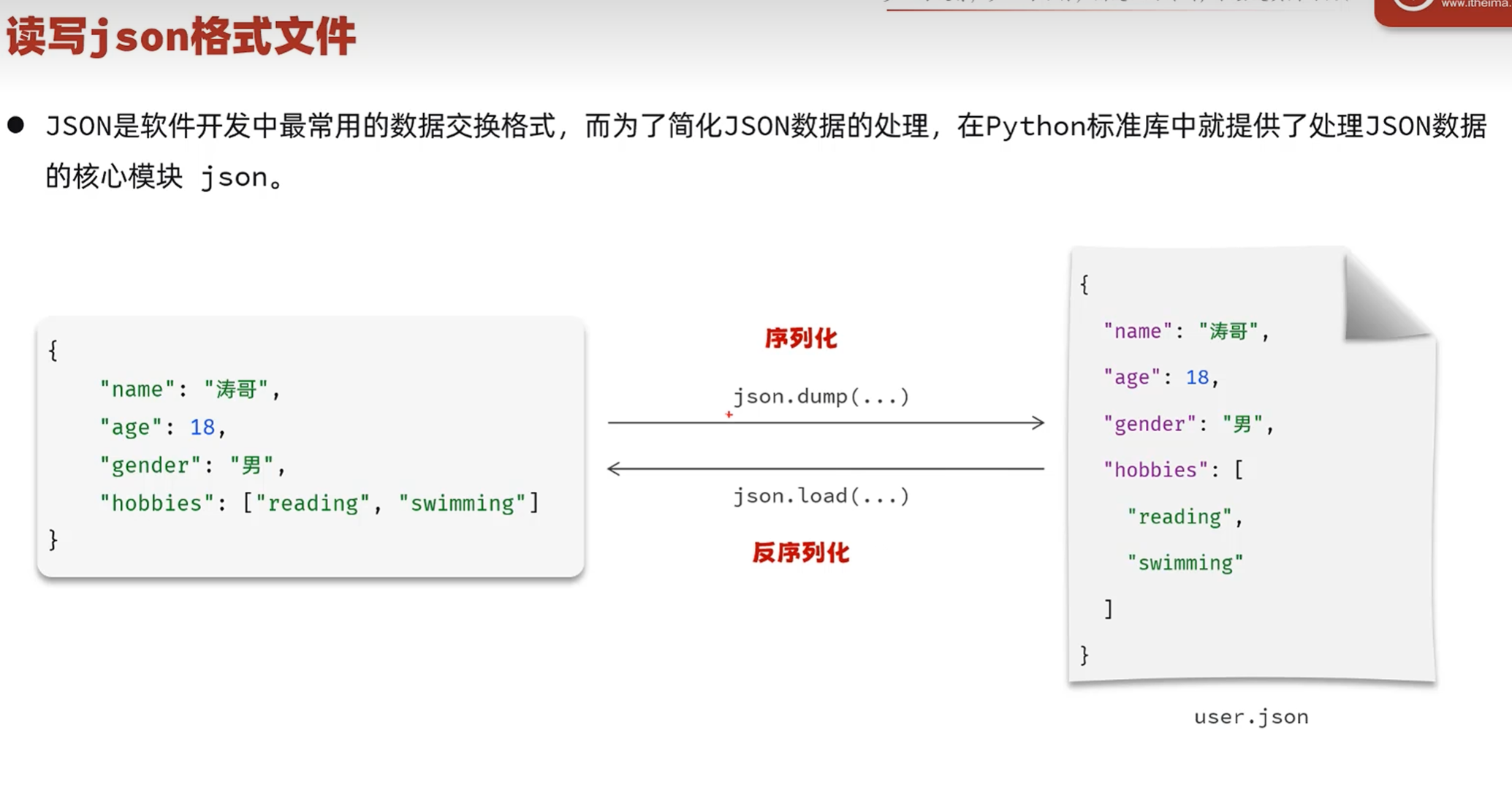
把对象保存到json文件中--序列化dump(从含义上来说是下载的过程中序列化)
把json文件转成对象--反序列化(从含义上来说是上传的时候反序列化)
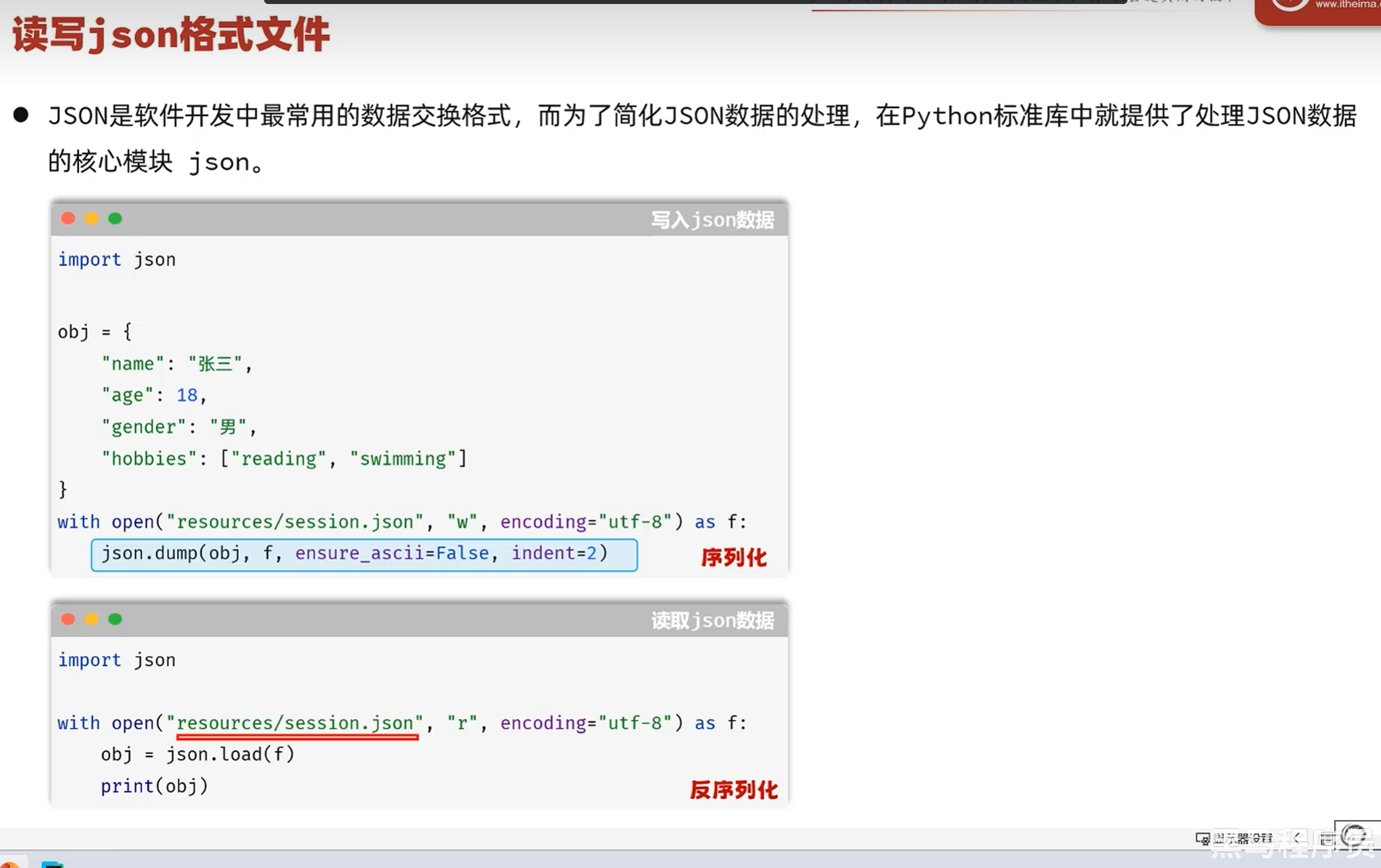
dump
python中的字典转json字符串时
dump的参数:ensure_ascii这个参数
true:把所有非ascii码的都转为ascii
false:保留
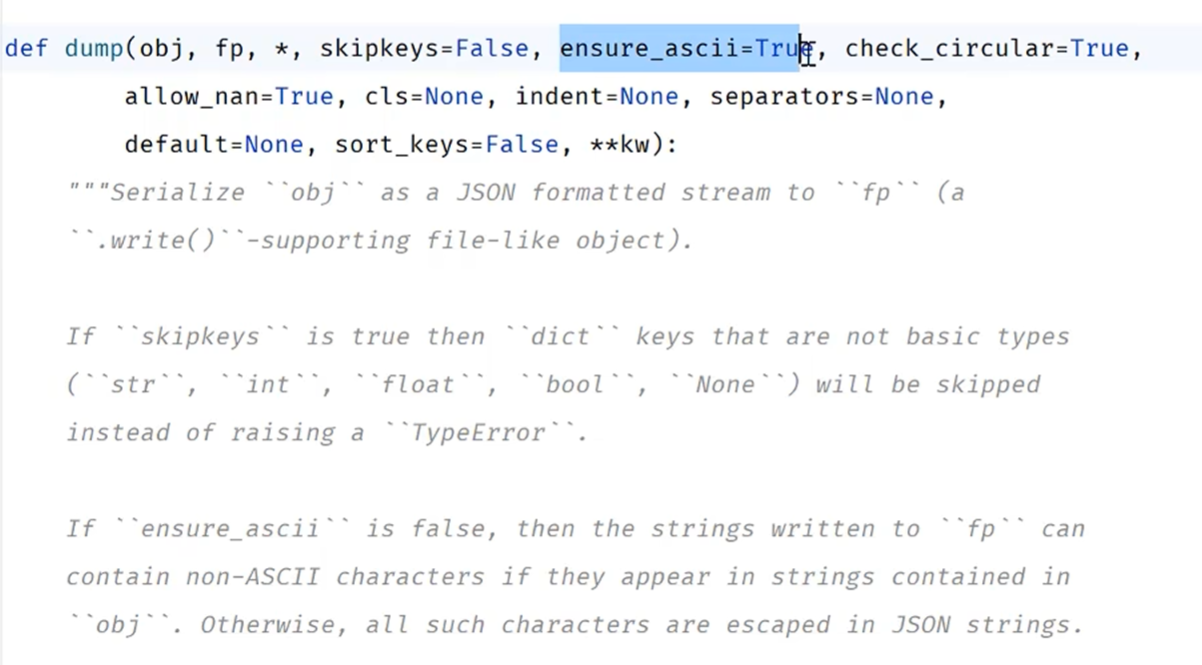
indent:表示缩进的参数


读取load
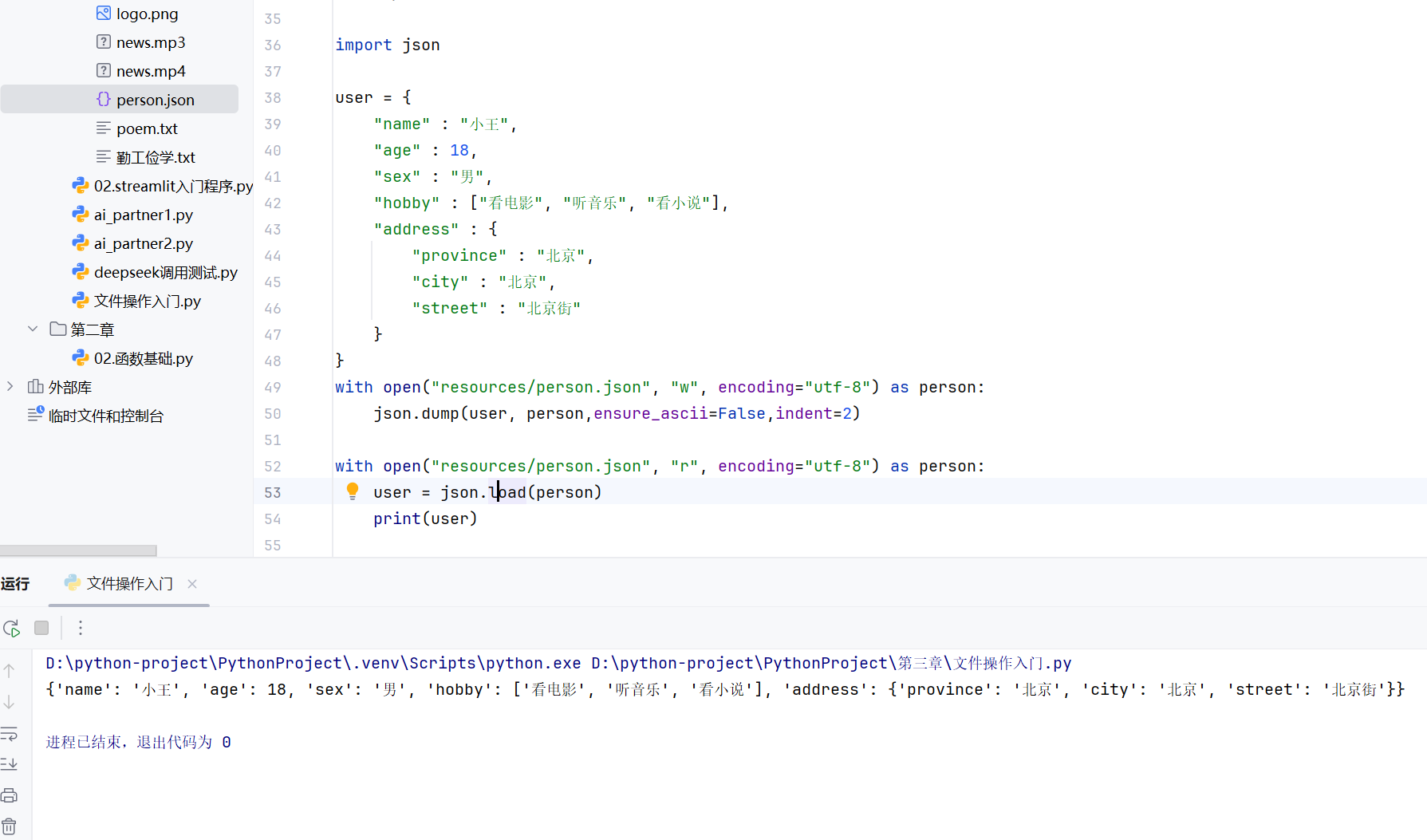

-实战-会话管理-保存会话
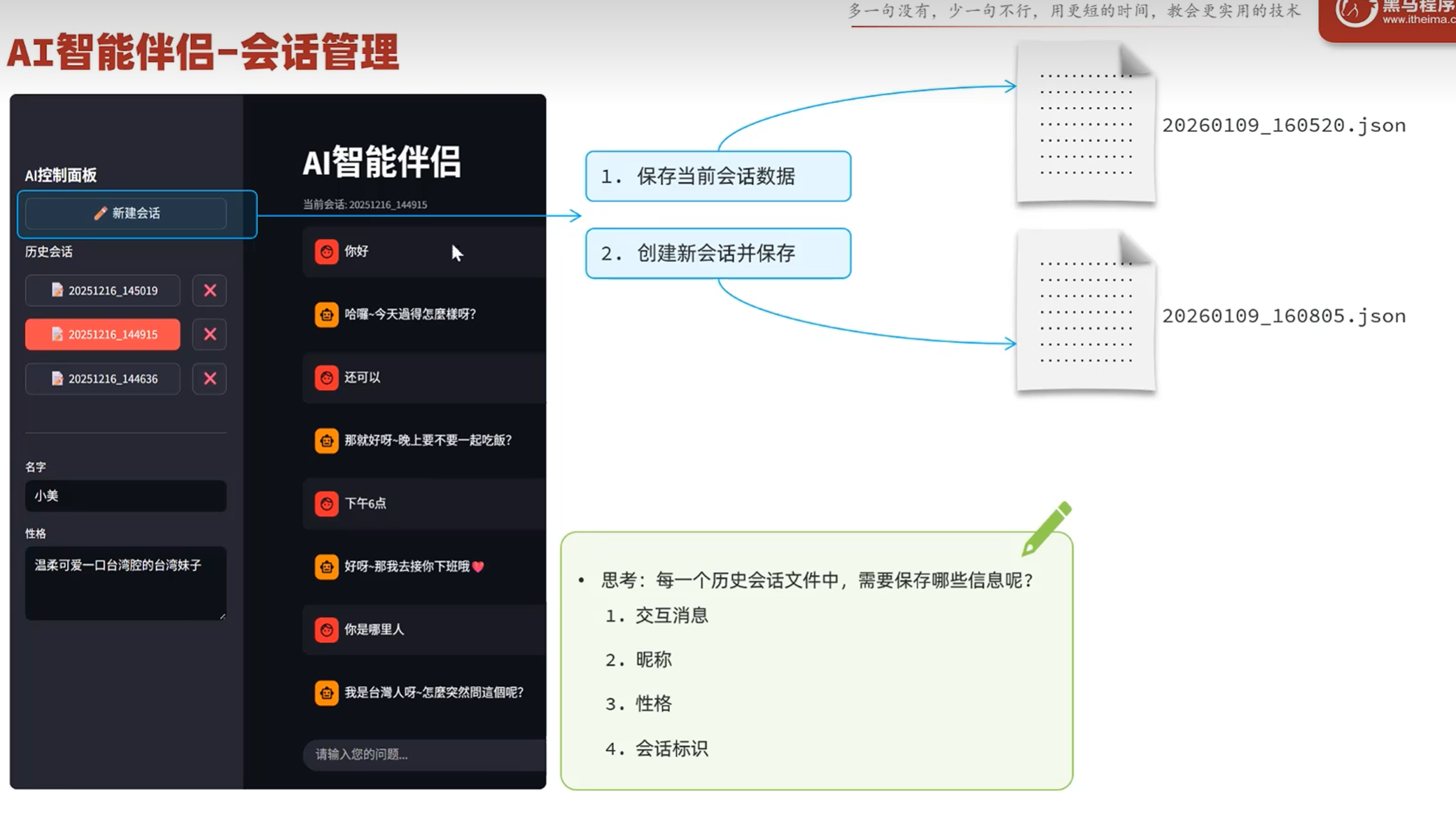
左侧侧边栏一共有两个部分:
AI控制面板:
用button方法来解决
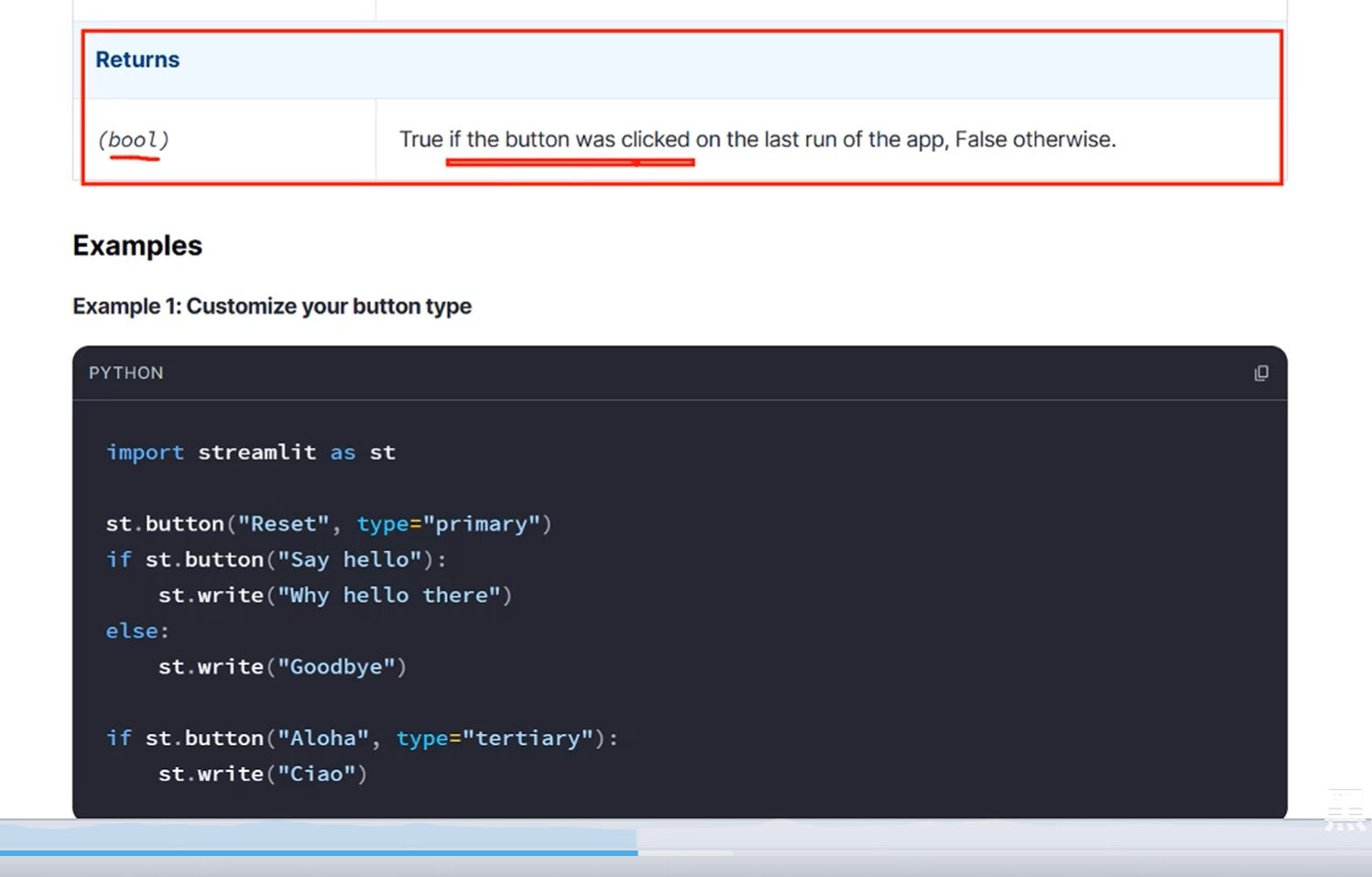
button有返回值,只要被点击了就会返回True,否则则返回False
宽度不够

可以传入"stretch"这个表示和父元素的宽度相同



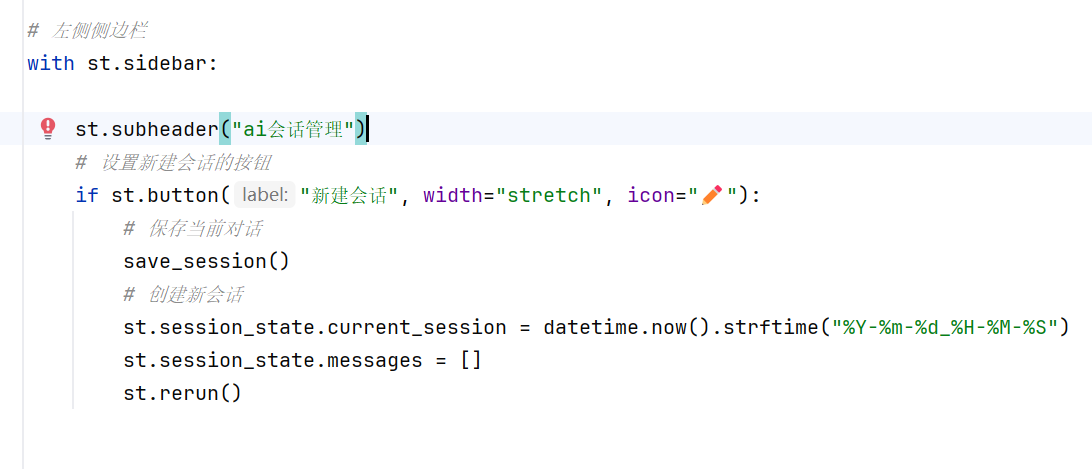
-实战-会话管理-新建会话
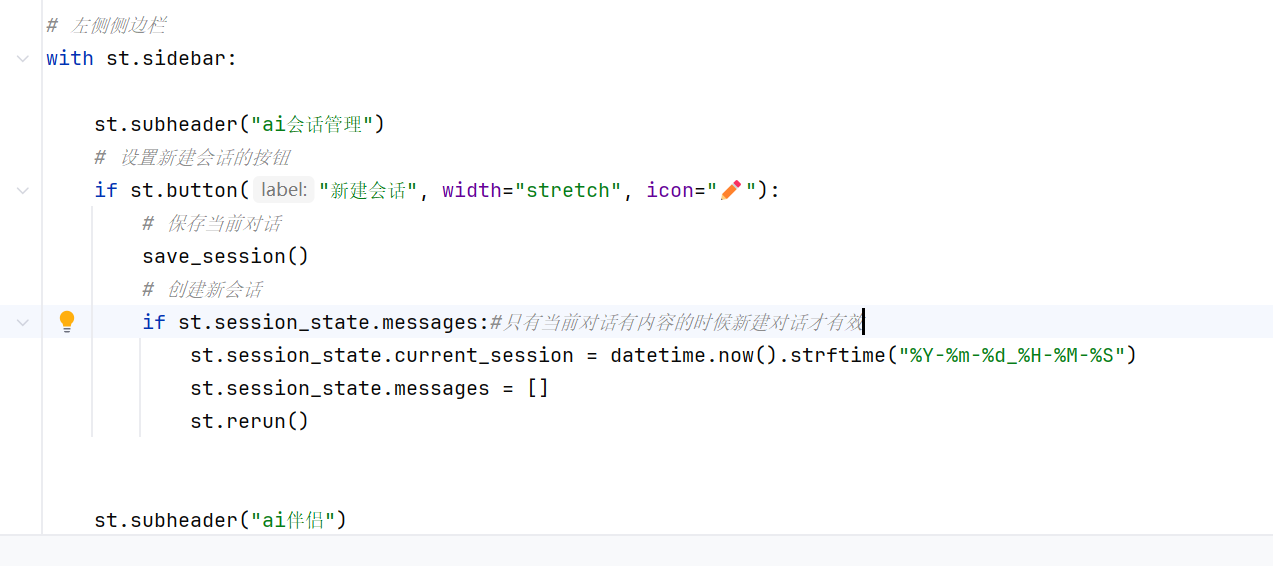
创建新建会话:
要先把旧列表覆盖为空,
再重新运行对话(如果不加这条代码,则旧的对话信息会保留在页面上)
-实战-会话管理-展示会话列表
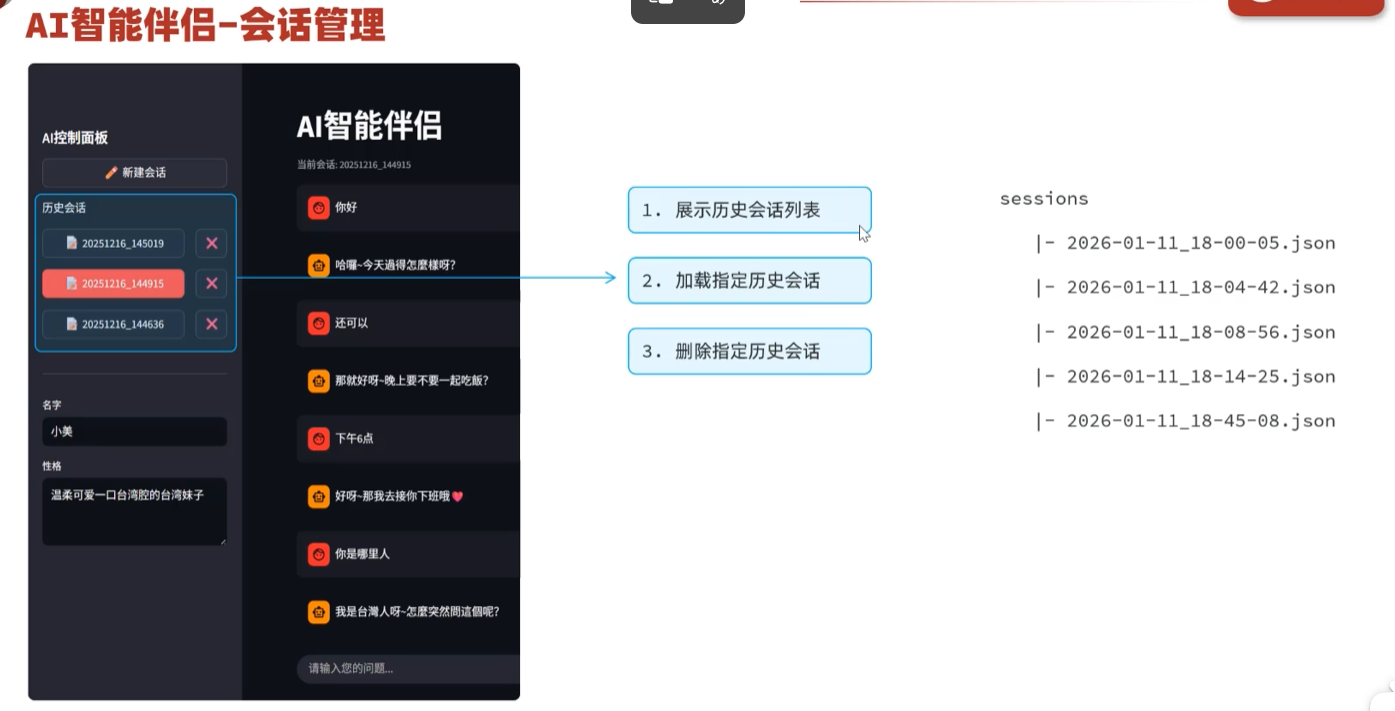
展示历史会话列表:
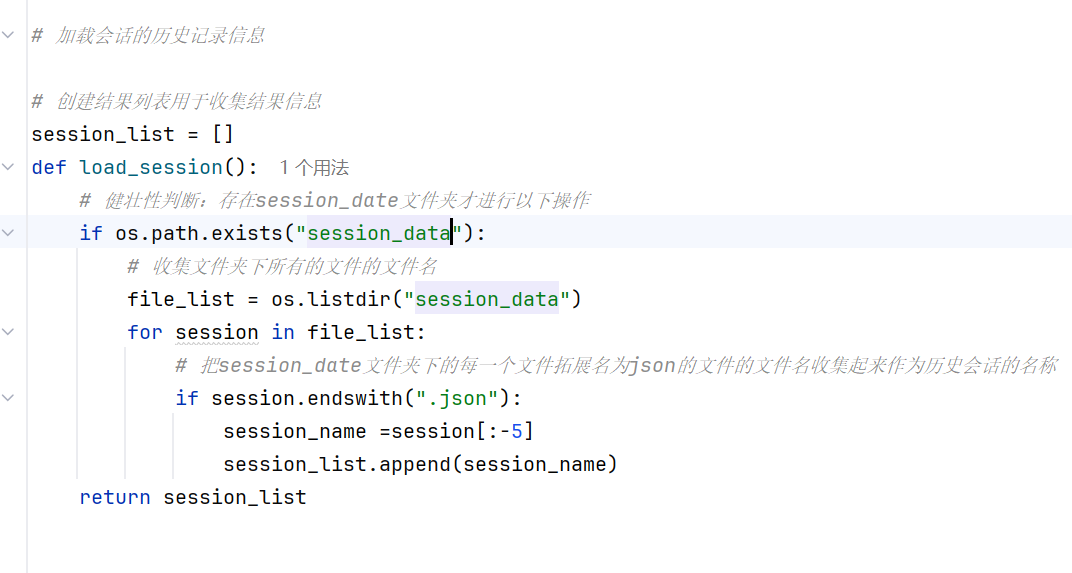

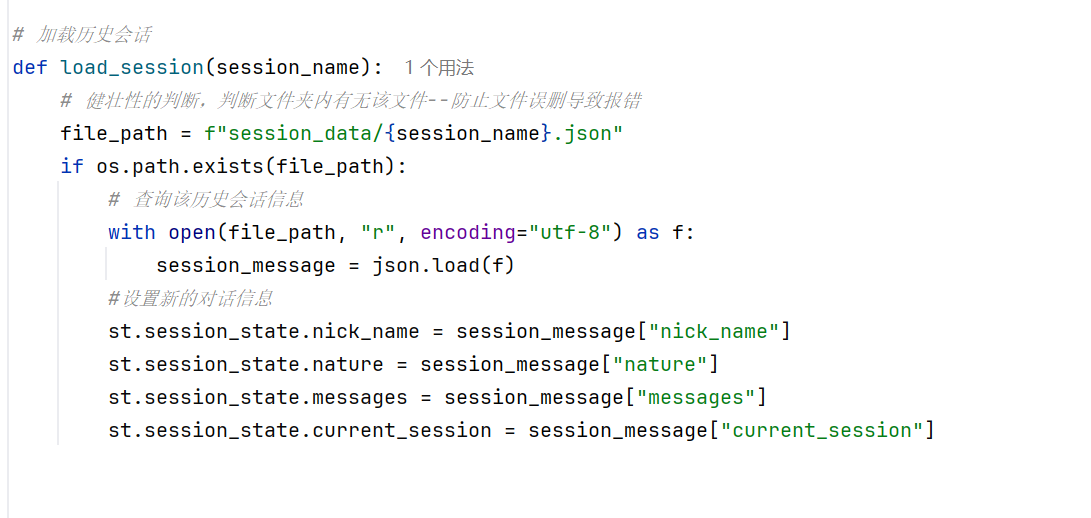
-实战-会话管理-加载会话列表
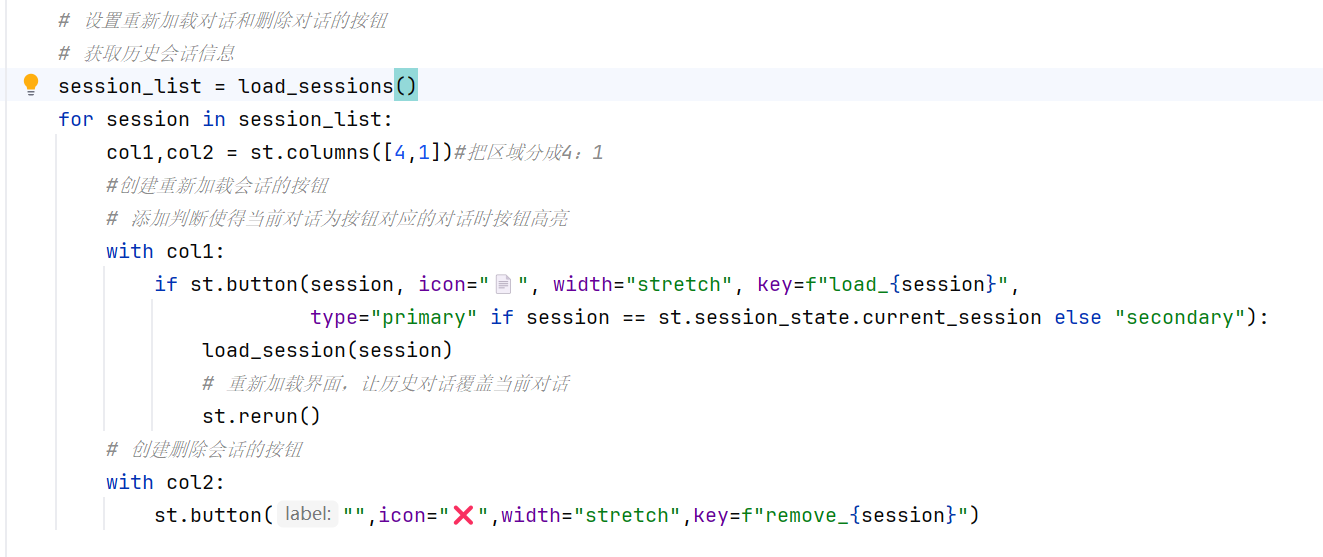
-实战-会话管理-删除会话
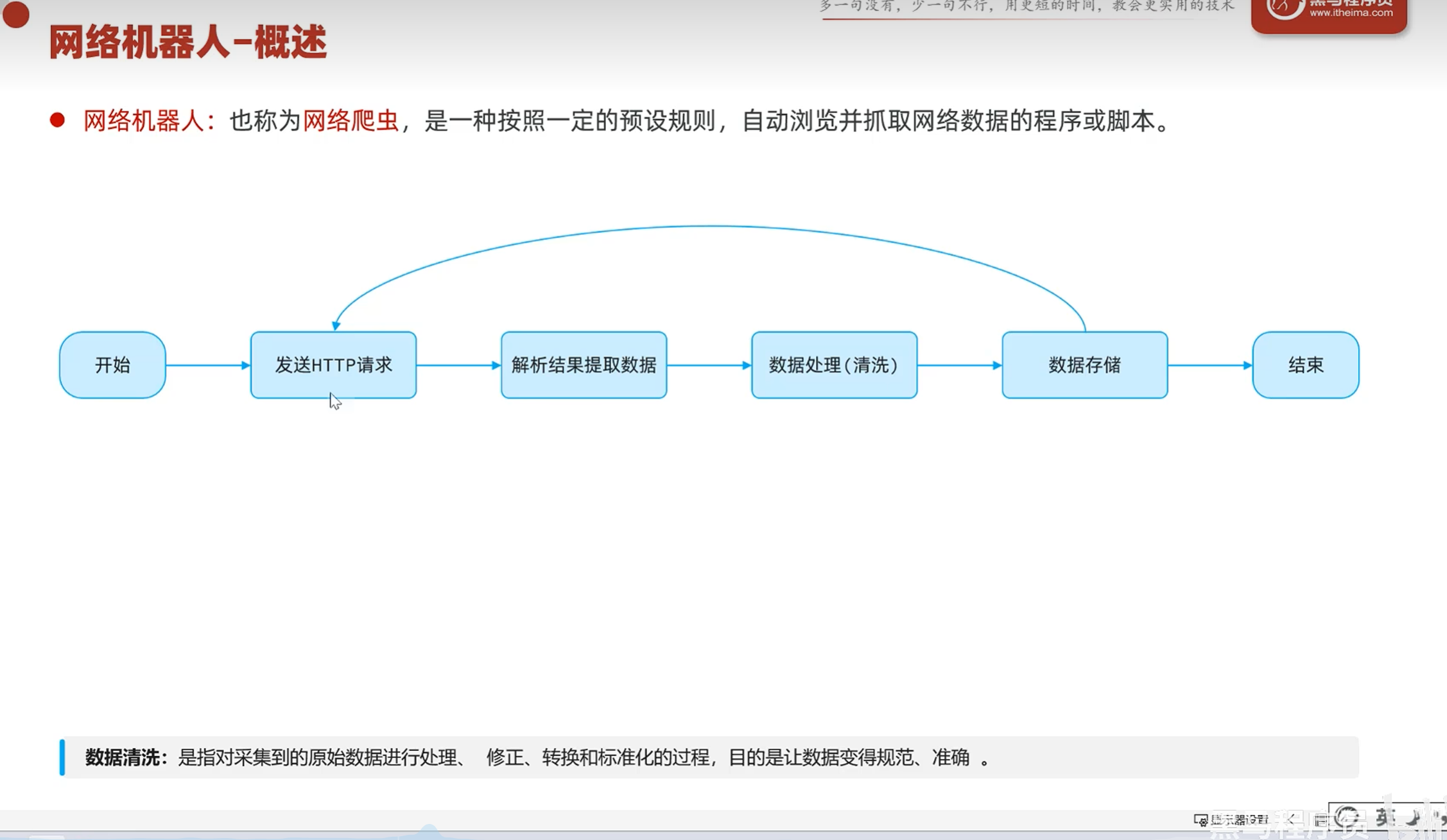
网络机器人
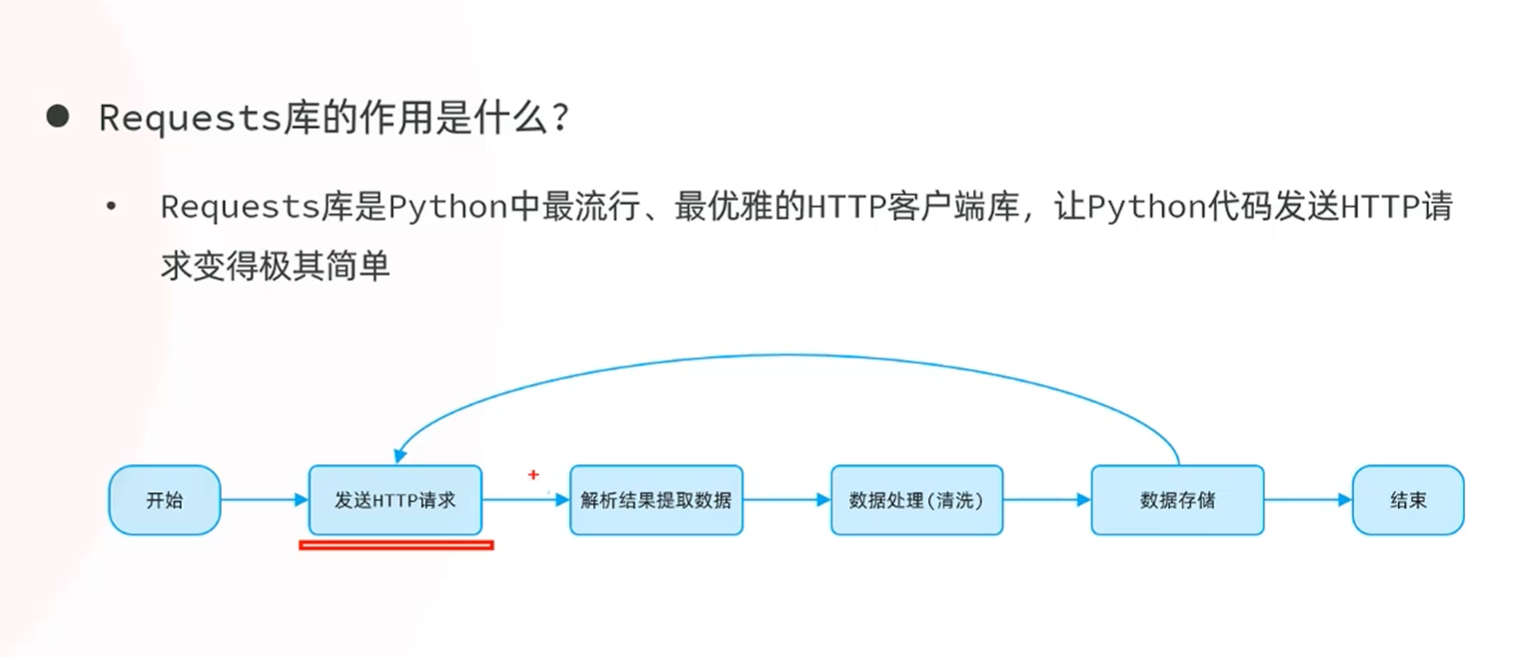
-介绍

概述(robots协议)


-入门-入门程序
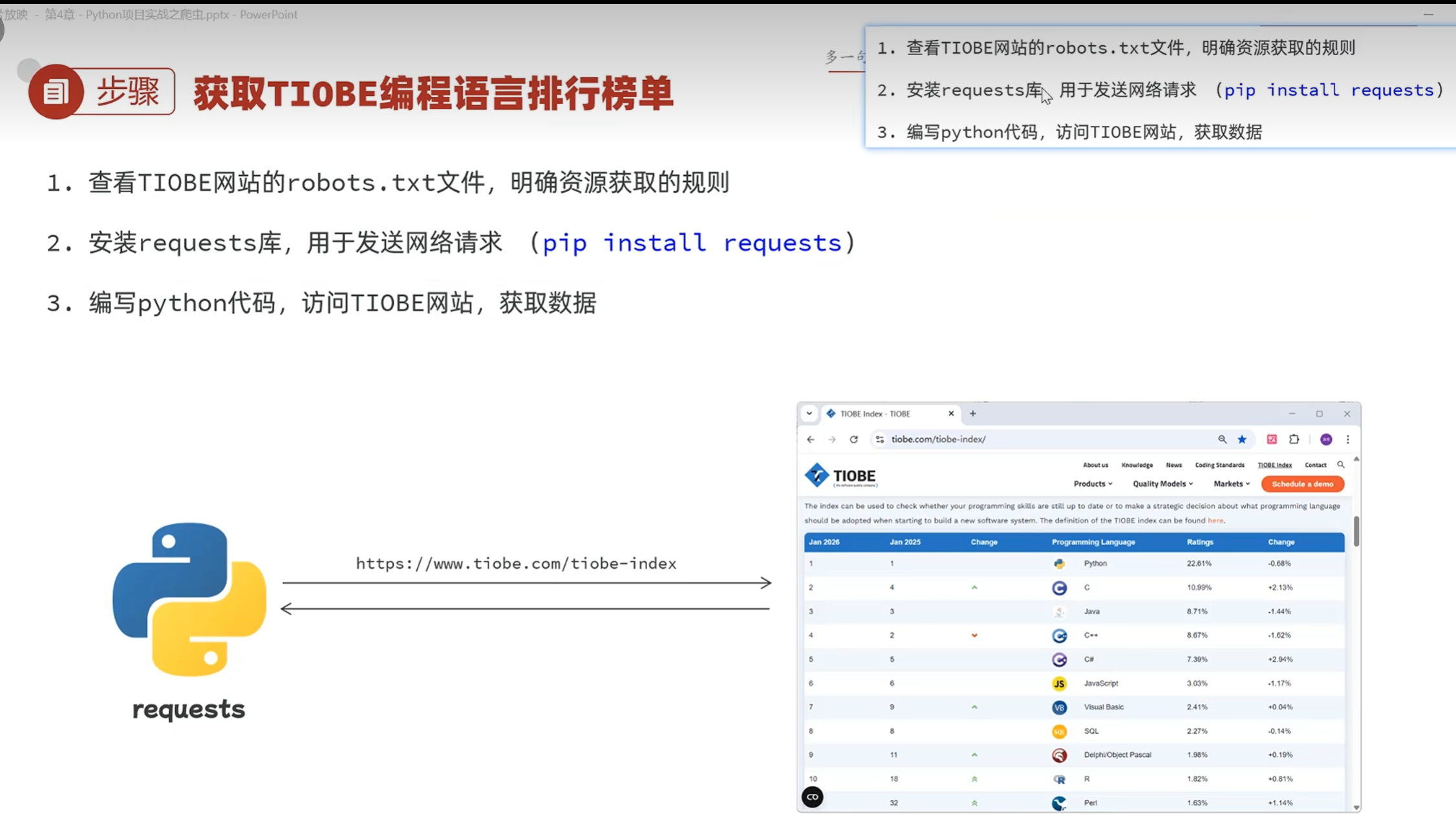
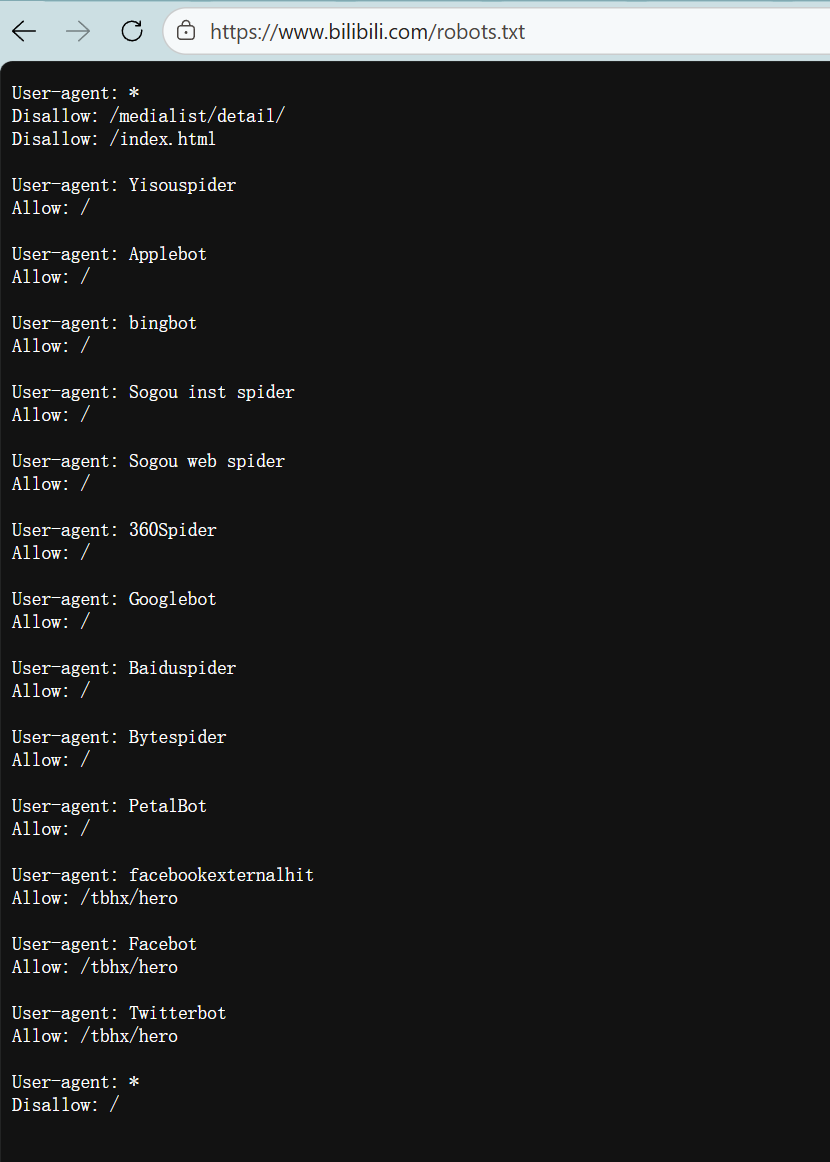
1.先查看机器人协议
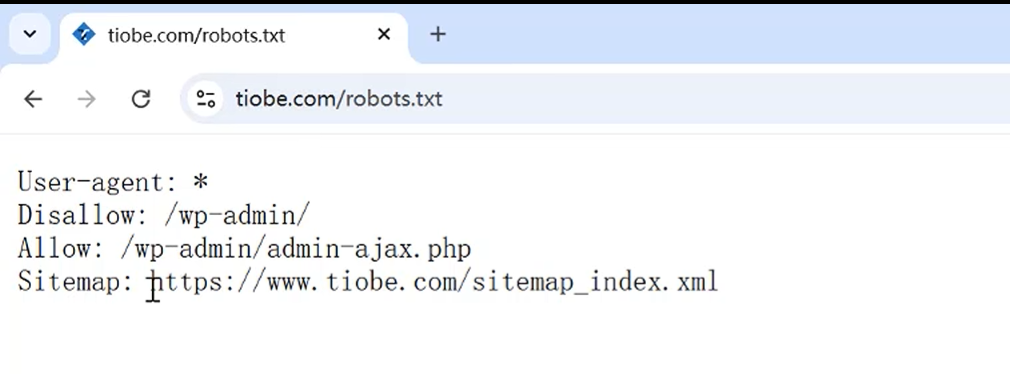
siteMap表示爬取的地址

很多网站愿意让爬虫爬取网站的相关数据,这样的话可以再搜搜应情商提高该网站的曝光率
2.安装requests库,用于访问网站
3.发送请求获取数据
(在浏览器地址栏发出的所有请求都是get请求)
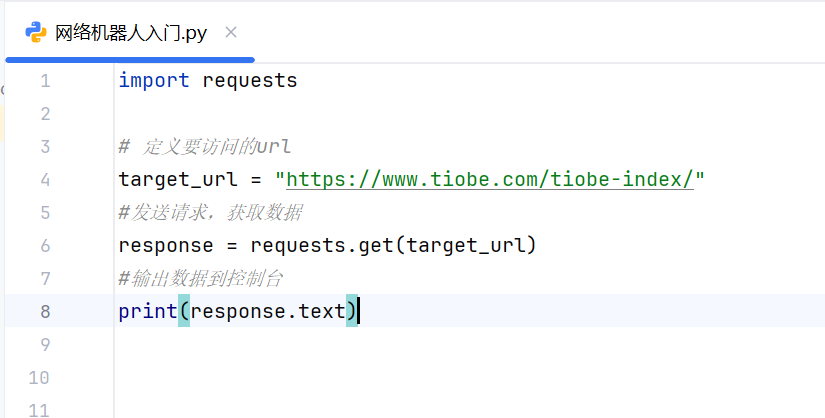
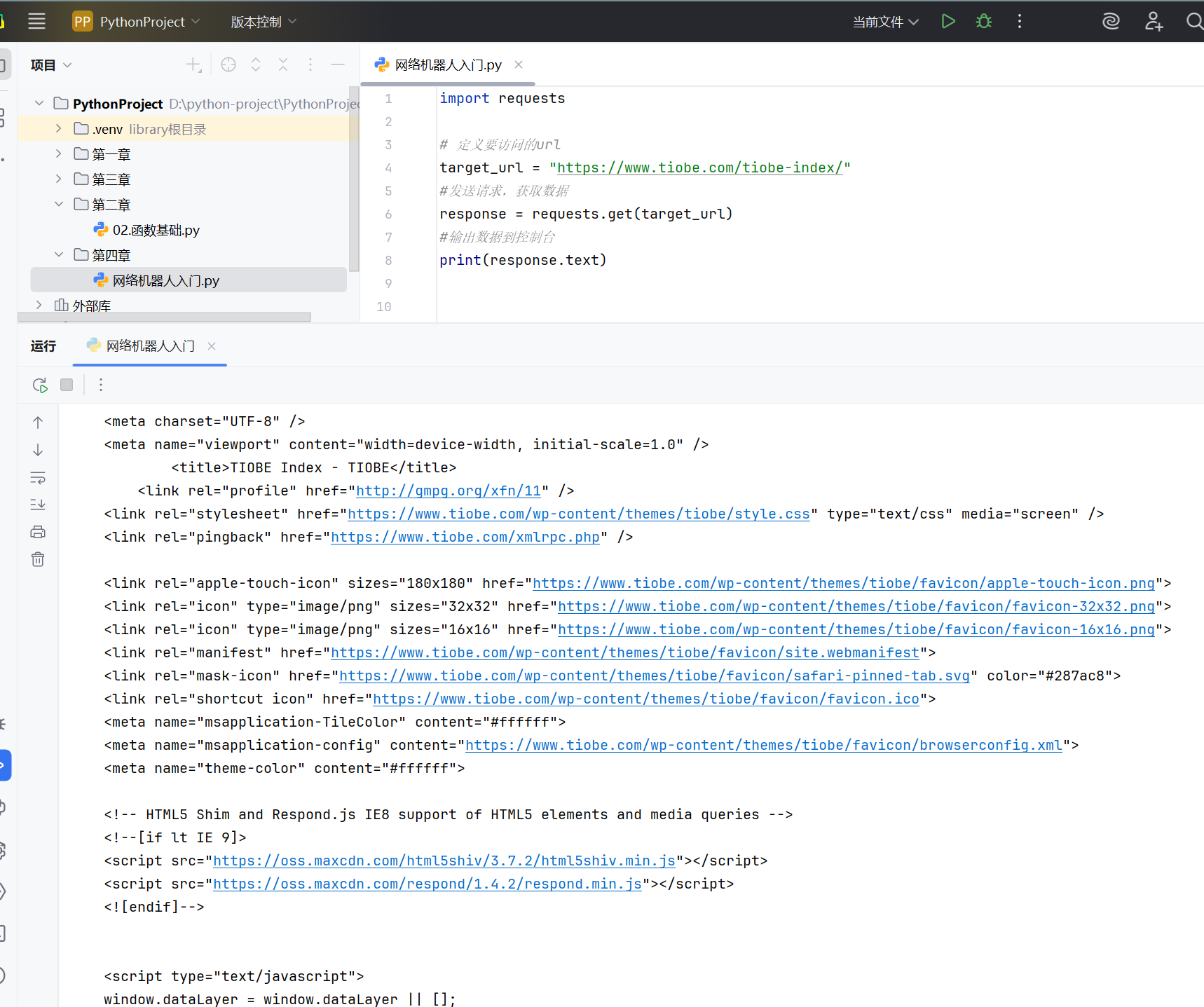
返回的数据其实是一段代码,前端开发工程师所编写的前端代码
-入门-网页结构
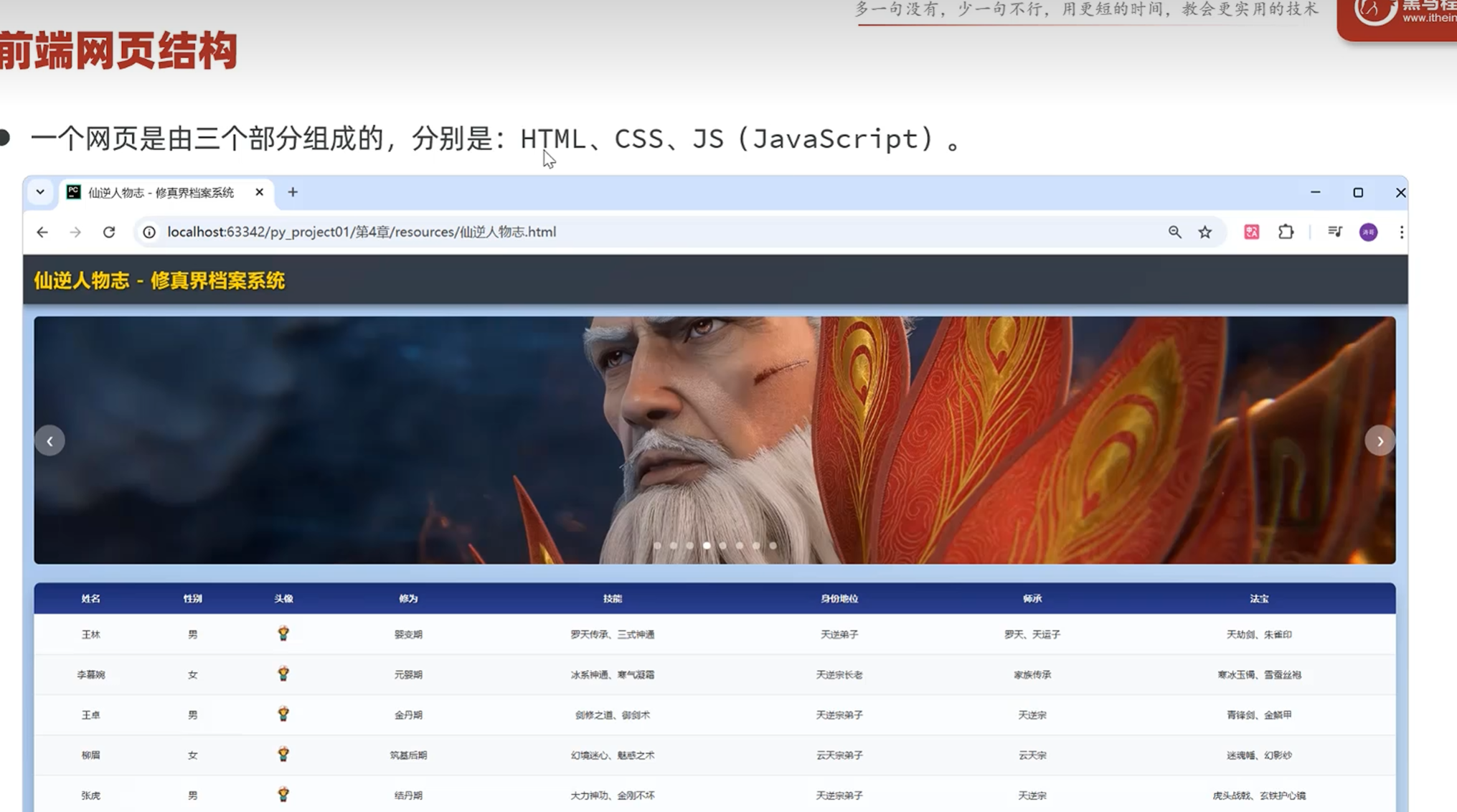

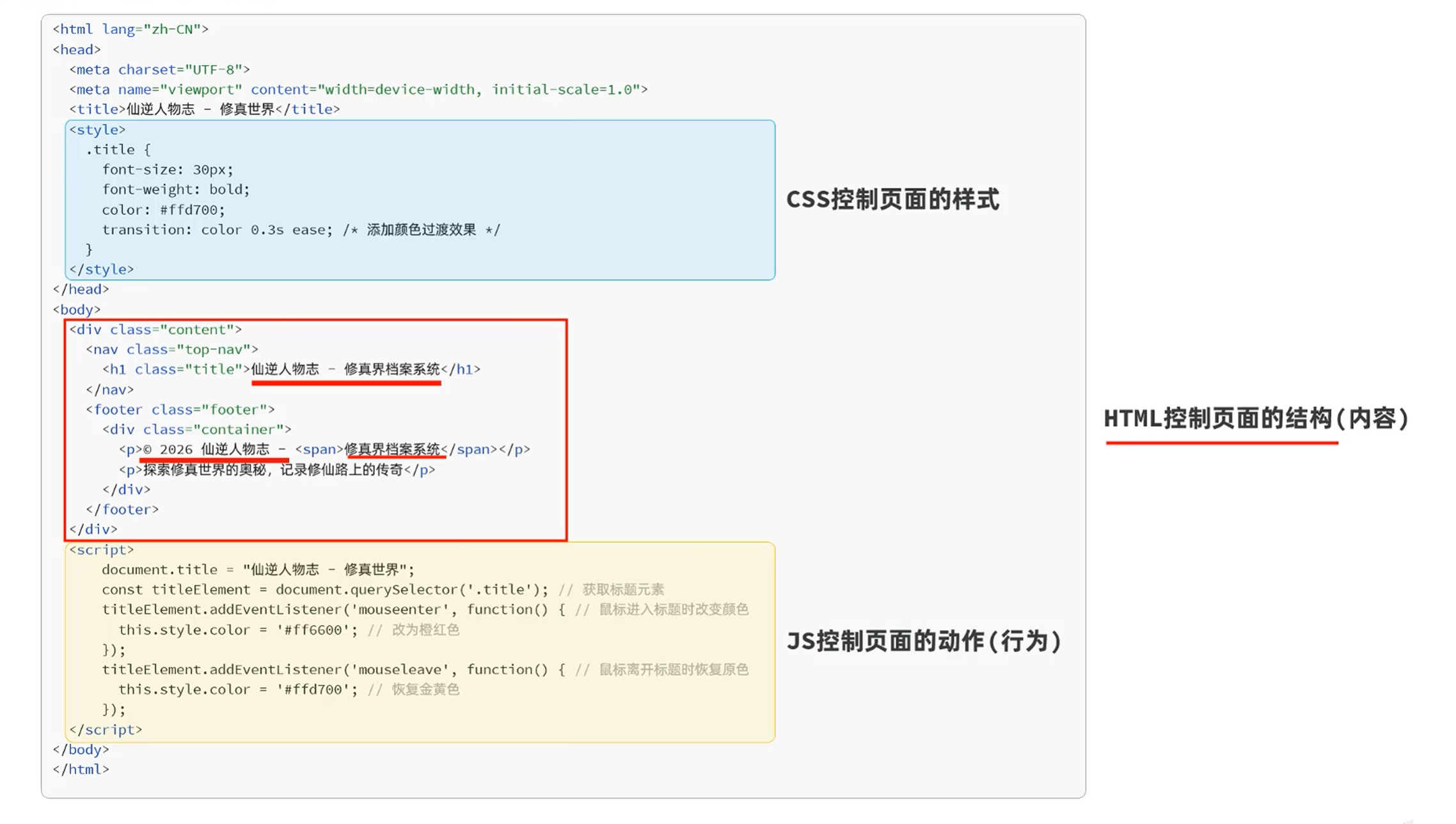
所以要重点关注的是html的部分
html控制页面的结构(内容)

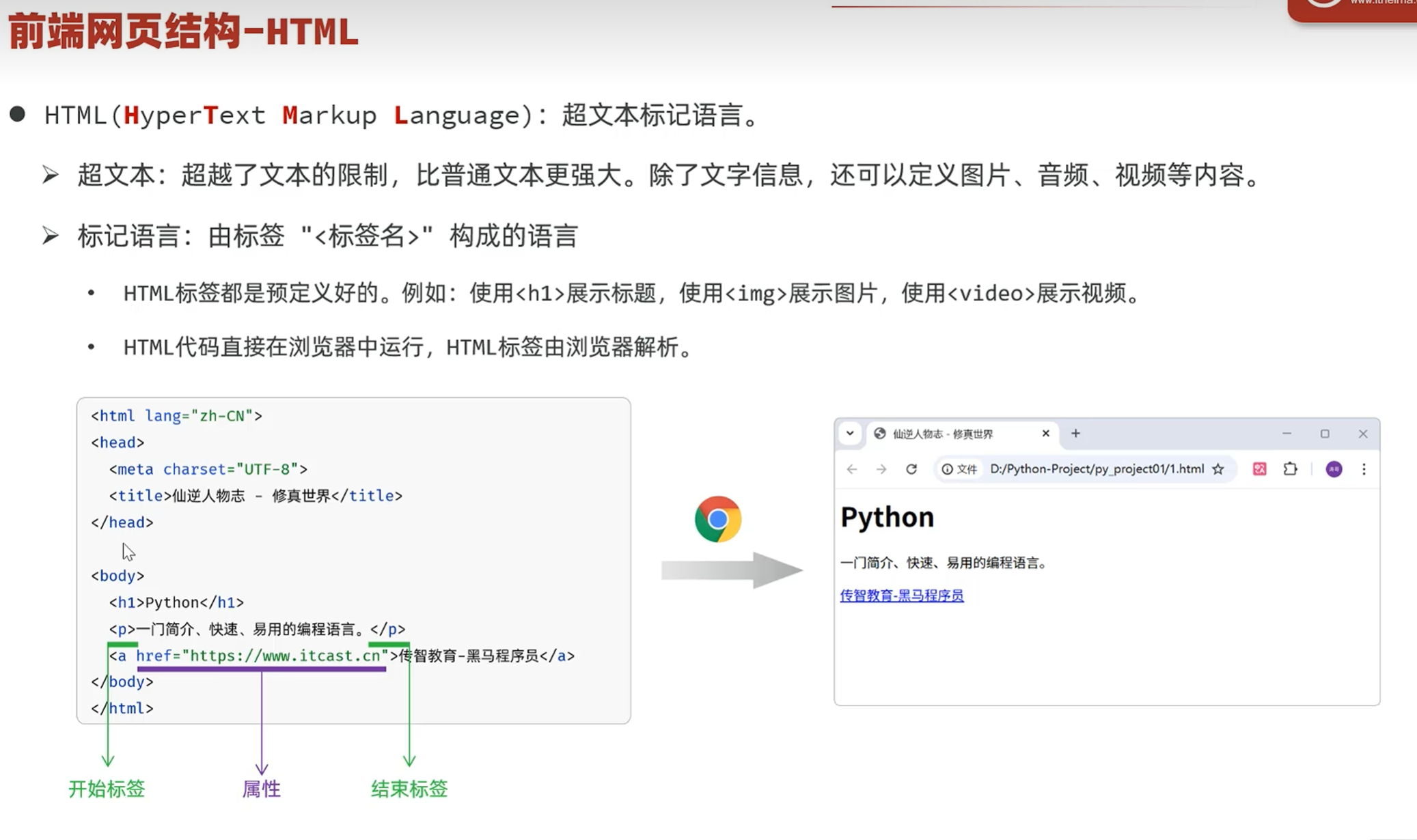
主要能分清楚标签和标签中的属性就行
开始标签和结束标签里面包含的内容就是内容

-入门-网页解析
用lxml库来解决这些问题,获取内容
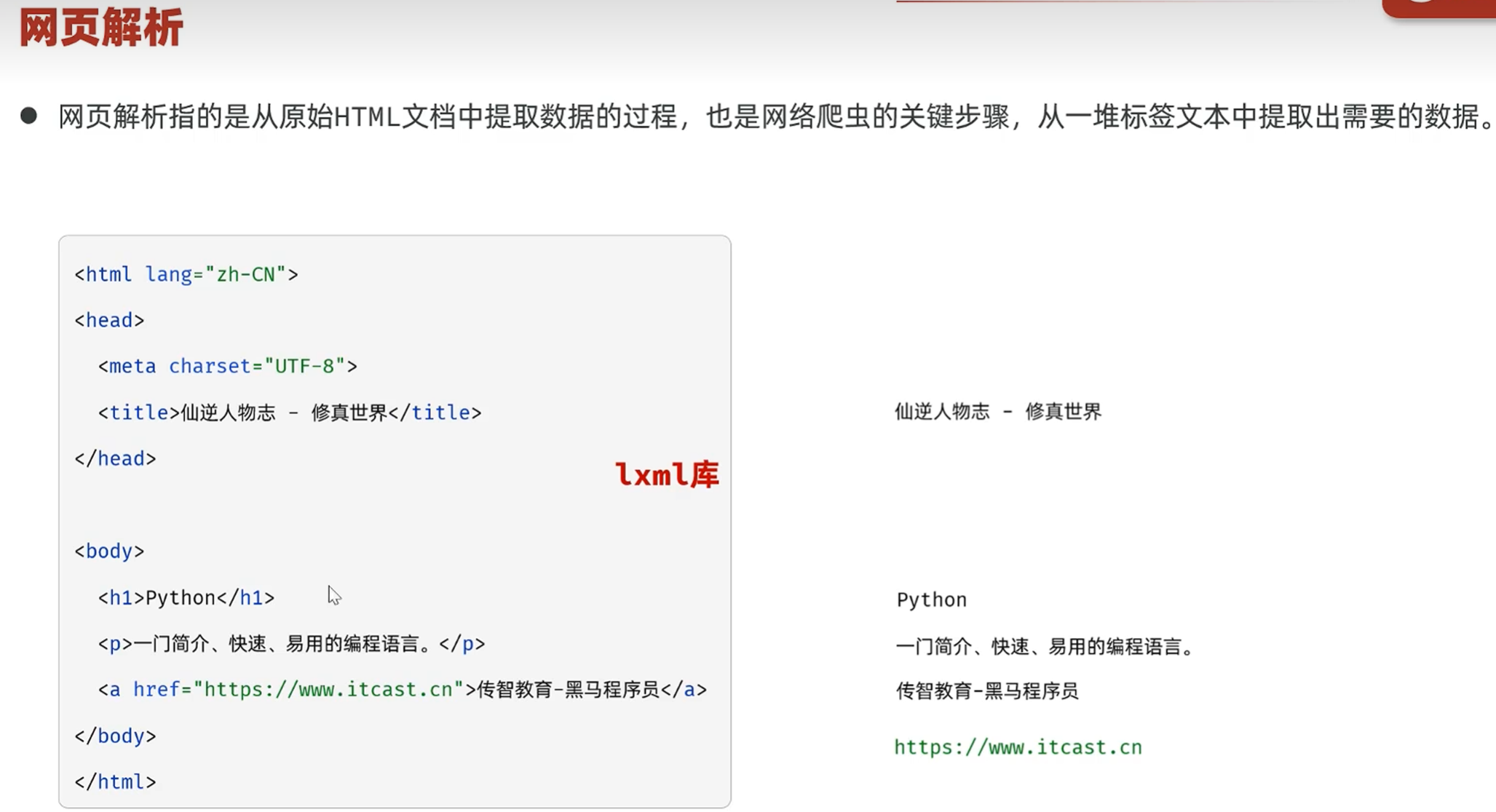
下载lxml库
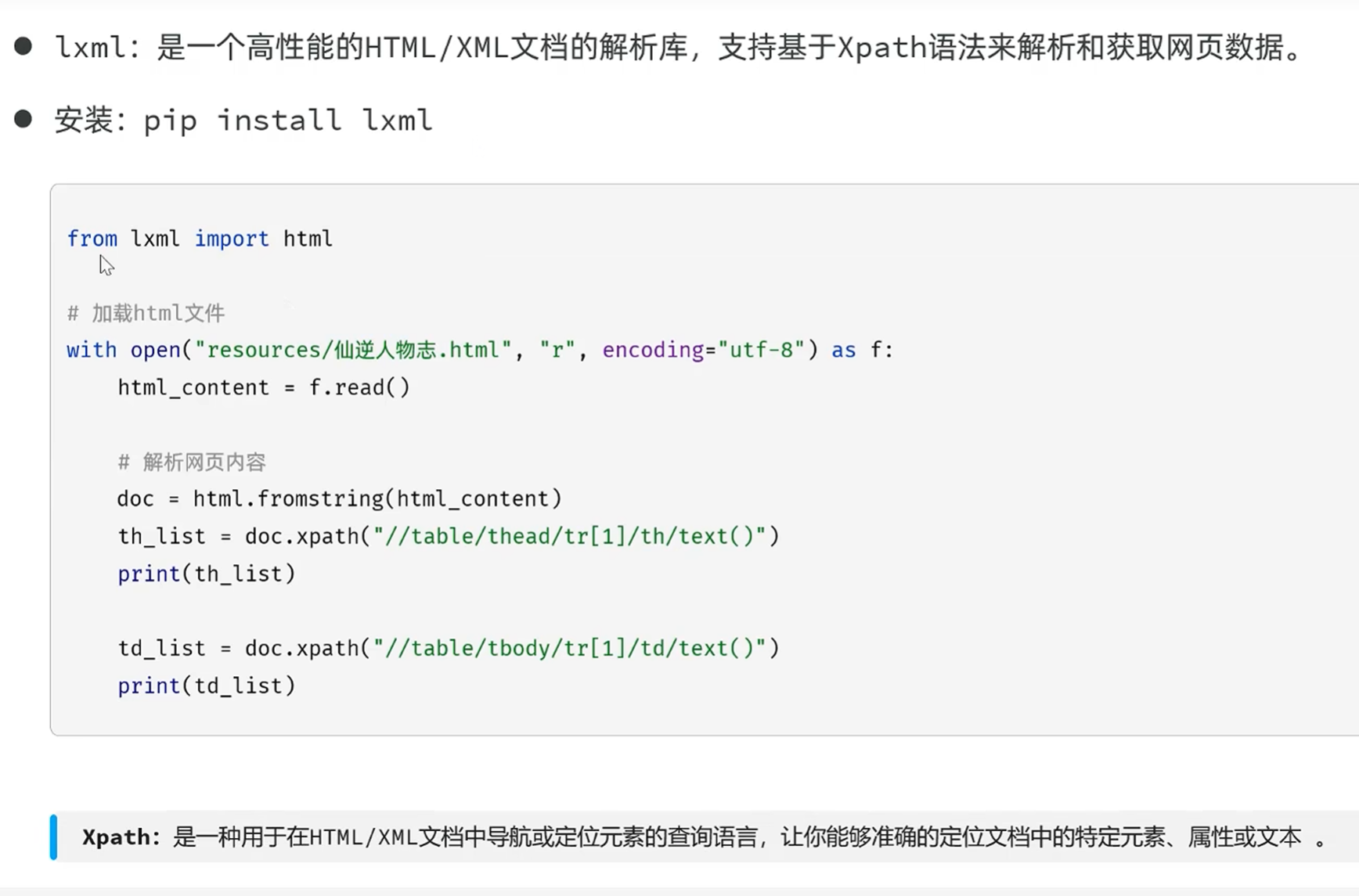
导入html功能
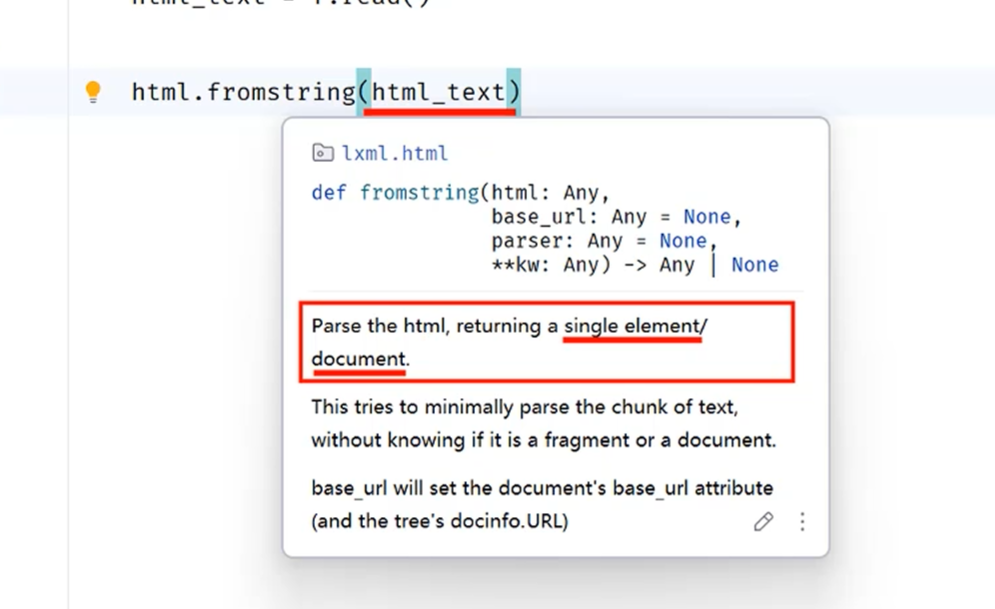
fromstring方法:接收html参数,返回doc文档类型

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)