把 Transformer 底层原理讲透:从输入到输出,一文看懂大模型时代最核心的基础架构
很多人知道 Transformer 很重要,也知道今天的 GPT、BERT、各类大模型都绕不开它,但一旦继续往下问:“Transformer 到底是怎么工作的?Q、K、V 是什么?为什么它能取代 RNN?” 很多文章就开始堆公式、堆术语,把人越讲越晕。
这篇文章不走“纯论文复述”的路线,而是从工程视角出发,用尽量通俗的话,把 Transformer 从外到内拆开:先讲它为什么出现,再讲它如何接收输入、如何计算注意力、如何通过编码器和解码器完成理解与生成,最后再讲它为什么成为大模型时代最核心的底座。
如果你是刚接触大模型的开发者,或者你已经听过很多次 Transformer,但总觉得“懂了一点又没完全懂”,那这篇文章就是为你准备的。
1. Transformer 为什么会出现?
在 Transformer 之前,自然语言处理里最主流的模型是 RNN、LSTM、GRU 这一类“按时间顺序一个词一个词处理”的结构。它们的思路并不难理解:第 1 个词算完,再算第 2 个词;第 2 个词算完,再算第 3 个词。这样做的好处是模型天然带有时序感,但问题也非常明显。
第一,计算过程天然串行。后面的步骤要等前面的步骤算完,难以充分发挥 GPU 的并行能力。
第二,长距离依赖不容易学。一个词和很远位置的词之间如果有关联,信息需要一层层往后传,路径长、容易衰减。
第三,模型越大、序列越长,训练速度越容易成为瓶颈。
Transformer 的核心突破在于:它不再要求模型“按时间一步一步往前走”,而是让序列中每个位置都可以直接去看其他位置,并决定谁更值得关注。换句话说,它把“按顺序传播信息”变成了“按关系聚合信息”。这正是 Transformer 改变游戏规则的地方。
2. 先看全貌:Transformer 的整体工作流
理解 Transformer 最好的方式,不是上来就盯着公式,而是先看整体流程。你可以把它想成一条生产线:文本先被切成 Token,再被转成向量,然后加入位置信息;编码器负责理解整段输入,解码器负责基于已有内容一步一步往后生成。
只要你先把这条主线装进脑子里,后面再看 Self-Attention、QKV、多头注意力、Mask,就不会觉得这些概念是碎的。
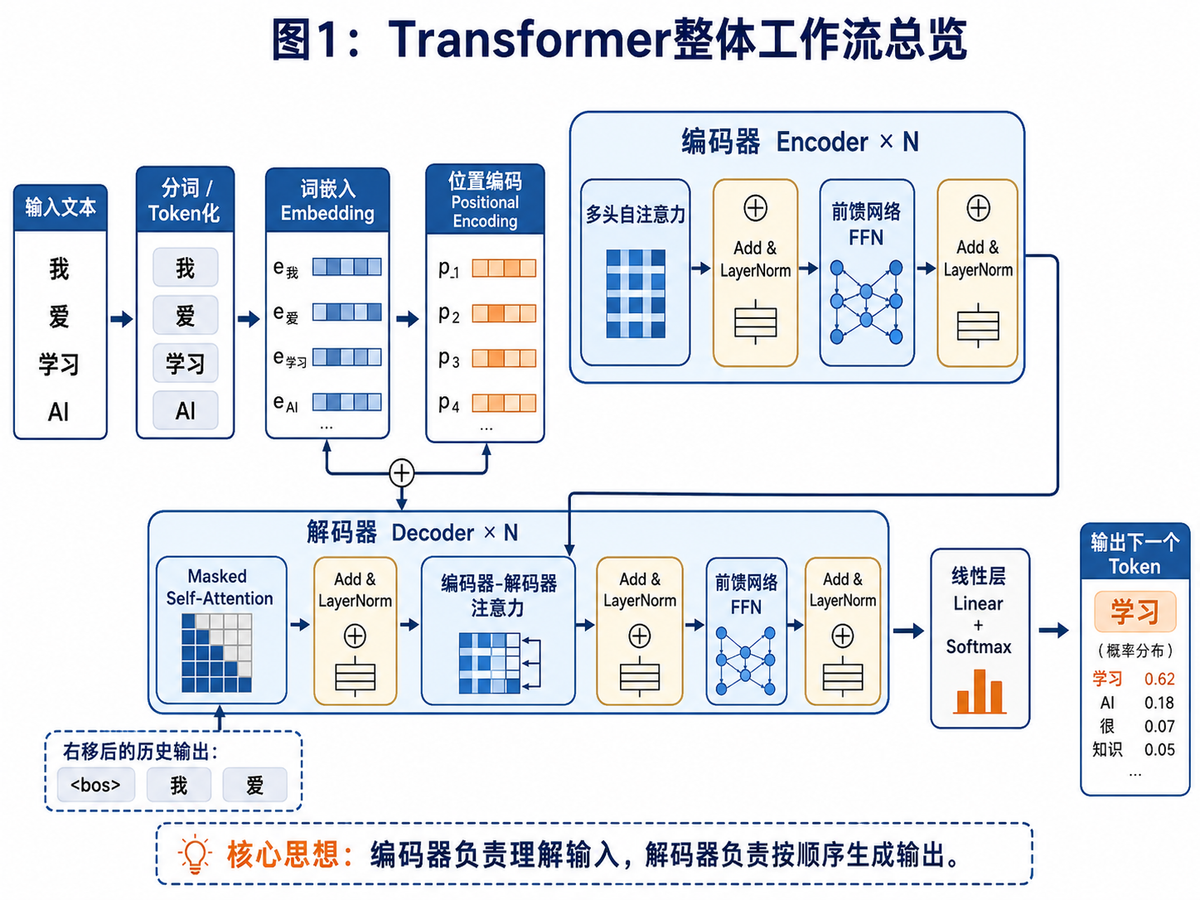
图 1 里最关键的认知点有三个:第一,Encoder 和 Decoder 的职责不同;第二,进入模型的不是文字本身,而是“带位置的向量”;第三,输出不是一下子整句蹦出来,而是一个 Token 一个 Token 往后生成。
3. 输入是怎么进入 Transformer 的?
神经网络不能直接处理“字词”这种符号,它只能计算数字。因此,Transformer 的第一步一定是把文本转换成数字表示。但这里并不是简单把词变成一个整数就结束了,而是要经历“Token → Token ID → Embedding → Position → 最终输入向量”这一整套流程。
3.1 Token:先把文本切成可处理的最小单元
例如“我 爱 学习 AI”这句话,可以被切成 4 个 Token。不同模型的分词方式可能不同,有的按字切,有的按词切,还有的按子词切。无论如何,Token 都是模型真正接触输入的起点。
3.2 Token ID:把 Token 映射成编号
每个 Token 在词表里都有一个固定编号。这个编号本身并不携带语义,它更像一个“索引键”,帮助模型从嵌入矩阵里把对应的向量取出来。
3.3 Embedding:把编号变成有语义的向量
Embedding 的本质,是把离散的词映射成稠密向量。语义相近的词,在向量空间里通常也会更接近。对于神经网络来说,这一步非常关键,因为后续所有注意力计算、线性变换,都是在这些向量上完成的。
3.4 位置编码:补上顺序信息
Transformer 最大的一个特点,是它不像 RNN 那样天然按时间前进。所以如果只给它 Embedding,它只知道“有哪些词”,却不知道“谁在前、谁在后”。这时就必须通过位置编码把顺序信息显式加进去。
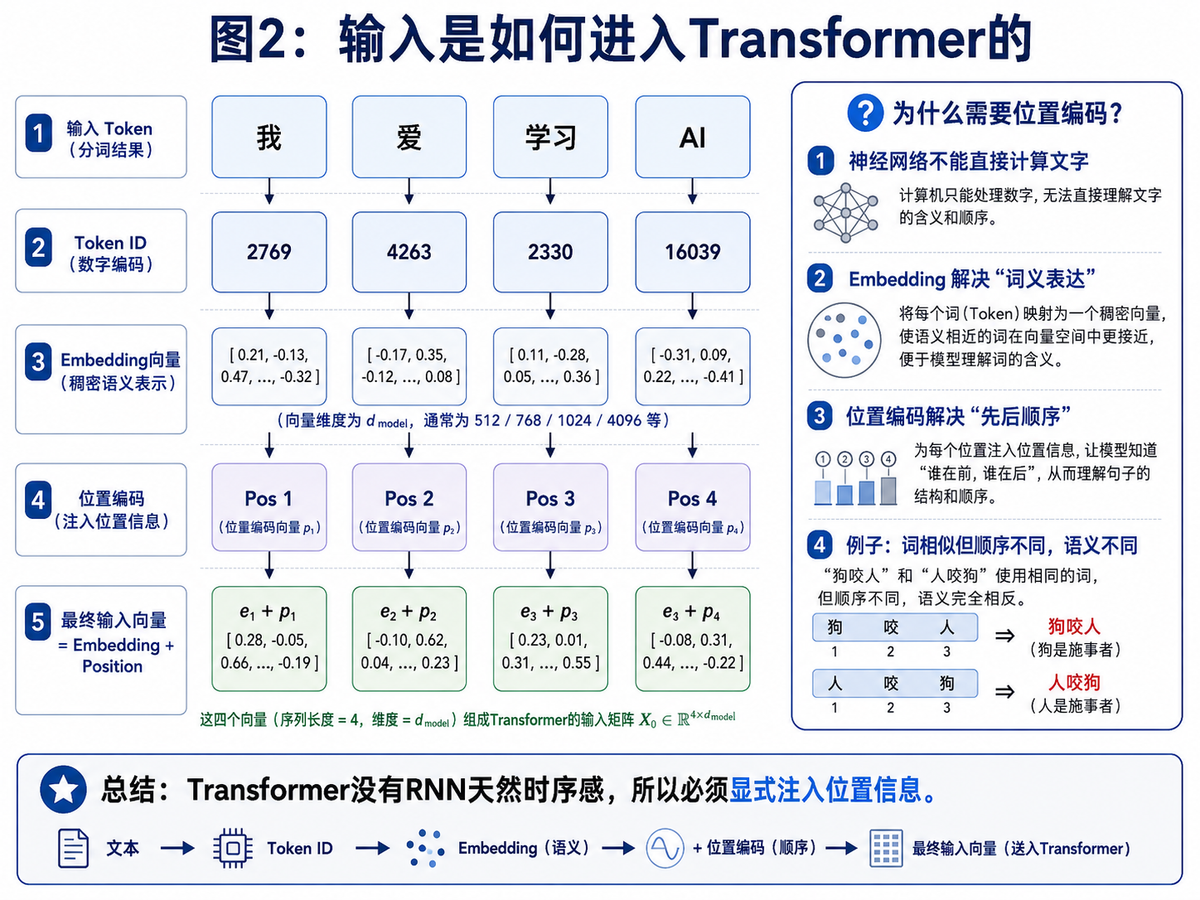
很多人第一次学到这里都会突然明白:原来 Transformer 不是“没有顺序”,而是“顺序不是靠结构天然带来的,而是靠位置编码补进去的”。这也是为什么文章里经常会强调一句话:Transformer 没有 RNN 的天然时序感,所以必须显式注入位置信息。
4. Transformer 最关键的地方:Self-Attention 自注意力
如果说 Embedding 和位置编码是在给 Transformer“准备原材料”,那 Self-Attention 就是在做最核心的“关系建模”。它解决的问题是:当前词在更新自己的表示时,到底应该参考哪些词,参考多少。
举个经典例子:The animal didn’t cross the street because it was too tired. 当模型处理 it 这个词时,它需要判断 it 指的是 animal,还是 street。自注意力就是干这件事的:它让当前词主动去看整句中其他词,并为这些词分配不同的关注权重。
4.1 自注意力到底在做什么?
一句人话概括:每个词在更新自己时,都会动态参考整句里的其他词。谁和我更相关,我就多看谁;谁和我关系不大,我就少看谁。
4.2 Q、K、V 到底是什么?
Q、K、V 不是三种神秘物质,而是同一个输入向量经过三套不同线性变换后得到的三份表示。
Q(Query):我现在想找什么信息。
K(Key):我身上有哪些可以被匹配的特征。
V(Value):如果你关注我,我真正提供什么内容。
如果你把它类比成搜索系统,那就很好理解:Q 像搜索词,K 像标签,V 像正文内容。先用搜索词和标签匹配,判断谁更相关;再把相关对象的正文信息按权重汇总起来。
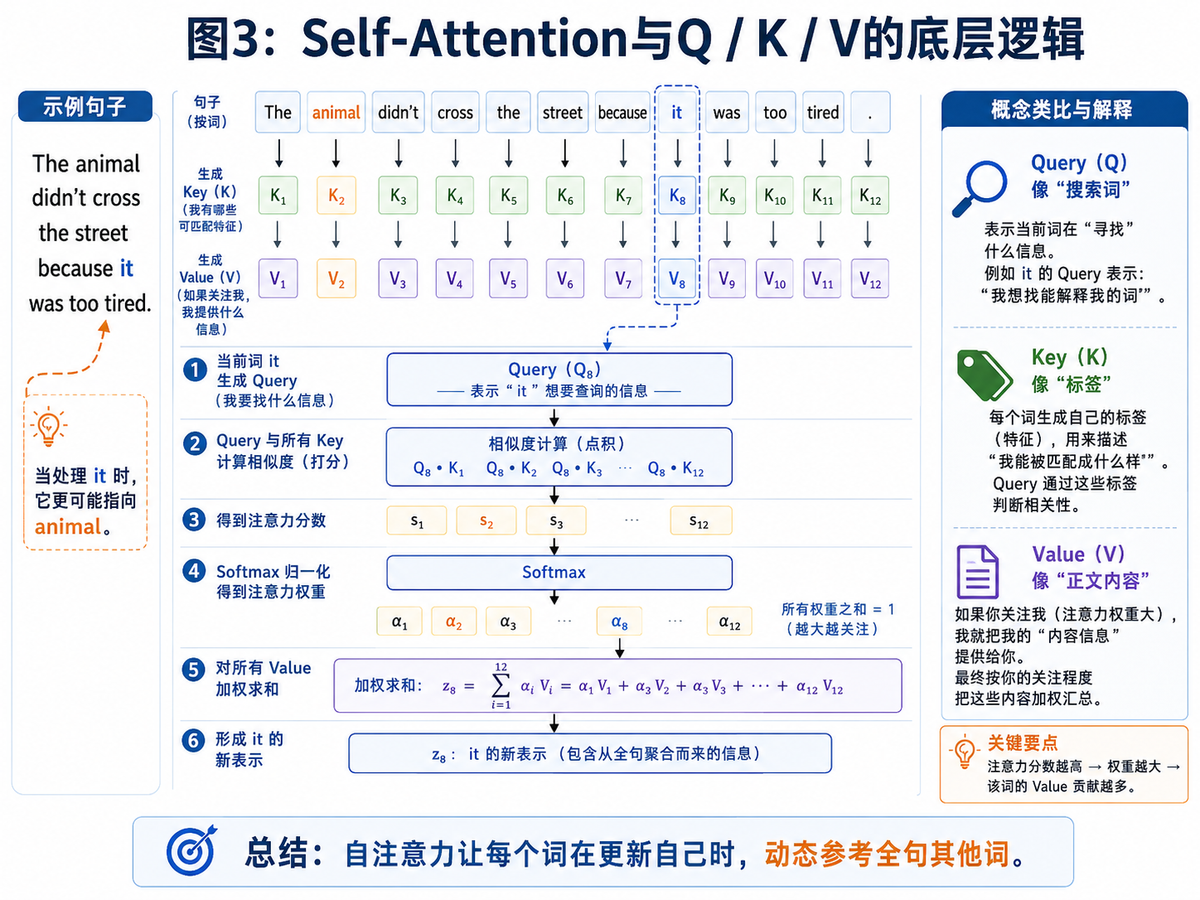
所以,自注意力的价值不在于“看见了所有词”这么简单,而在于它可以让每个词根据自己的需要,动态决定参考谁。这种“按需聚合上下文”的能力,是 Transformer 能理解复杂语义关系的核心原因。
5. Self-Attention 具体是怎么计算出来的?
当我们说“一个词更关注另一个词”时,背后其实是一整套可计算的流程。虽然论文里会写成矩阵形式,但把它拆成步骤后并不难懂。
步骤 1:输入先映射成 Q、K、V。
步骤 2:当前词的 Query 和所有词的 Key 做相似度计算。
步骤 3:得到一组分数后,先做缩放,再做 Softmax。
步骤 4:Softmax 后得到一组注意力权重。
步骤 5:再用这些权重去对所有 Value 做加权求和。
步骤 6:得到当前词新的上下文表示。
这就是经典的 Scaled Dot-Product Attention,也就是“缩放点积注意力”。
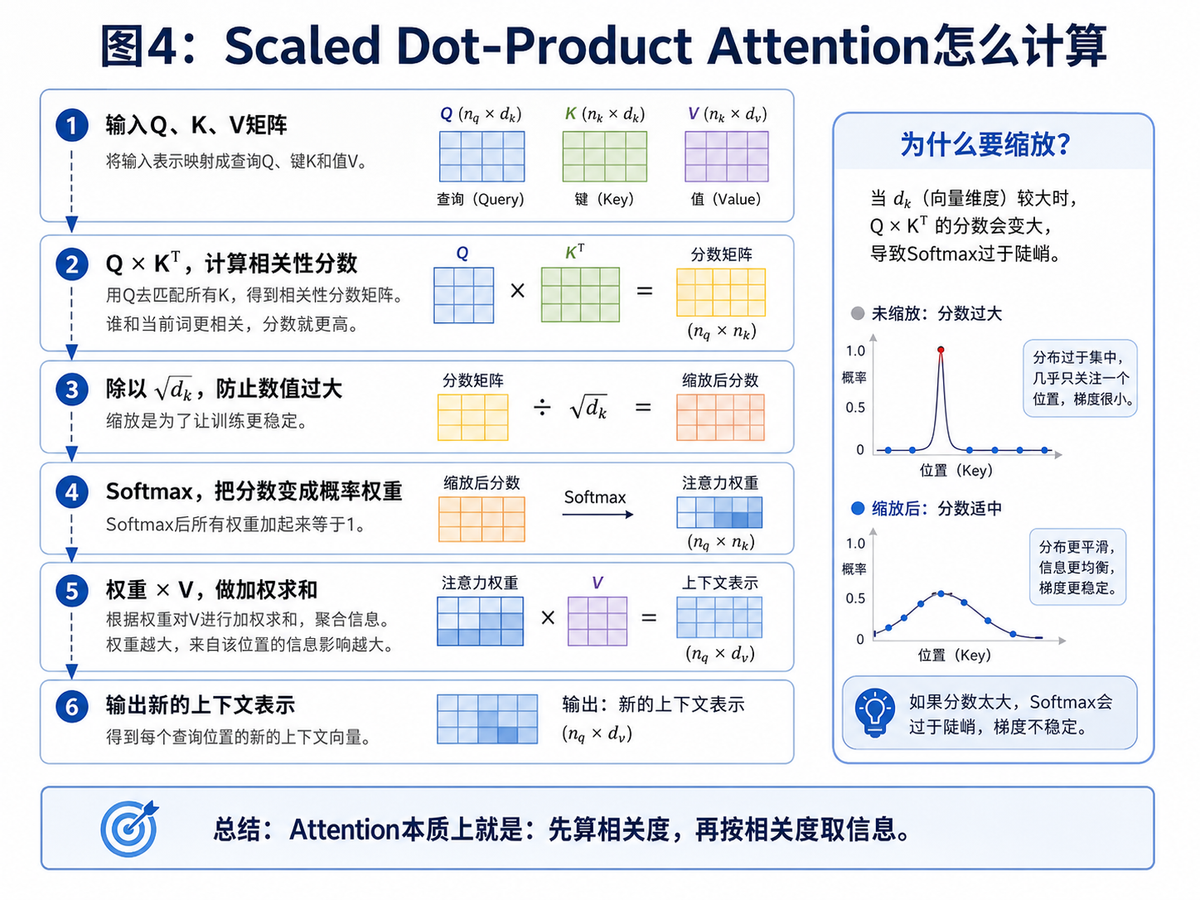
这里最容易忽视的一点是“缩放”。为什么要除以 √d_k?原因很简单:向量维度越大,点积值就越容易变得很大;如果数值过大,Softmax 会变得很陡,梯度就可能不稳定。缩放的作用,就是把这个问题压一压,让训练更平滑。
6. 为什么还要多头注意力?一个头不够吗?
很多人第一次接触到“多头注意力”时会困惑:既然注意力已经能算相关度了,为什么还要分成多个头?答案是:单头只能从一个角度看问题,而语言关系往往是多维的。
有的头更容易关注主谓关系。
有的头更容易关注指代关系。
有的头更容易关注局部位置关系。
有的头更容易关注更抽象的语义联系。
多头注意力的核心思想,就是让模型在不同的表示子空间里,从多个角度并行观察同一句话。每个头都独立做一遍注意力计算,最后把这些结果拼接起来,再做一次线性映射,形成最终输出。
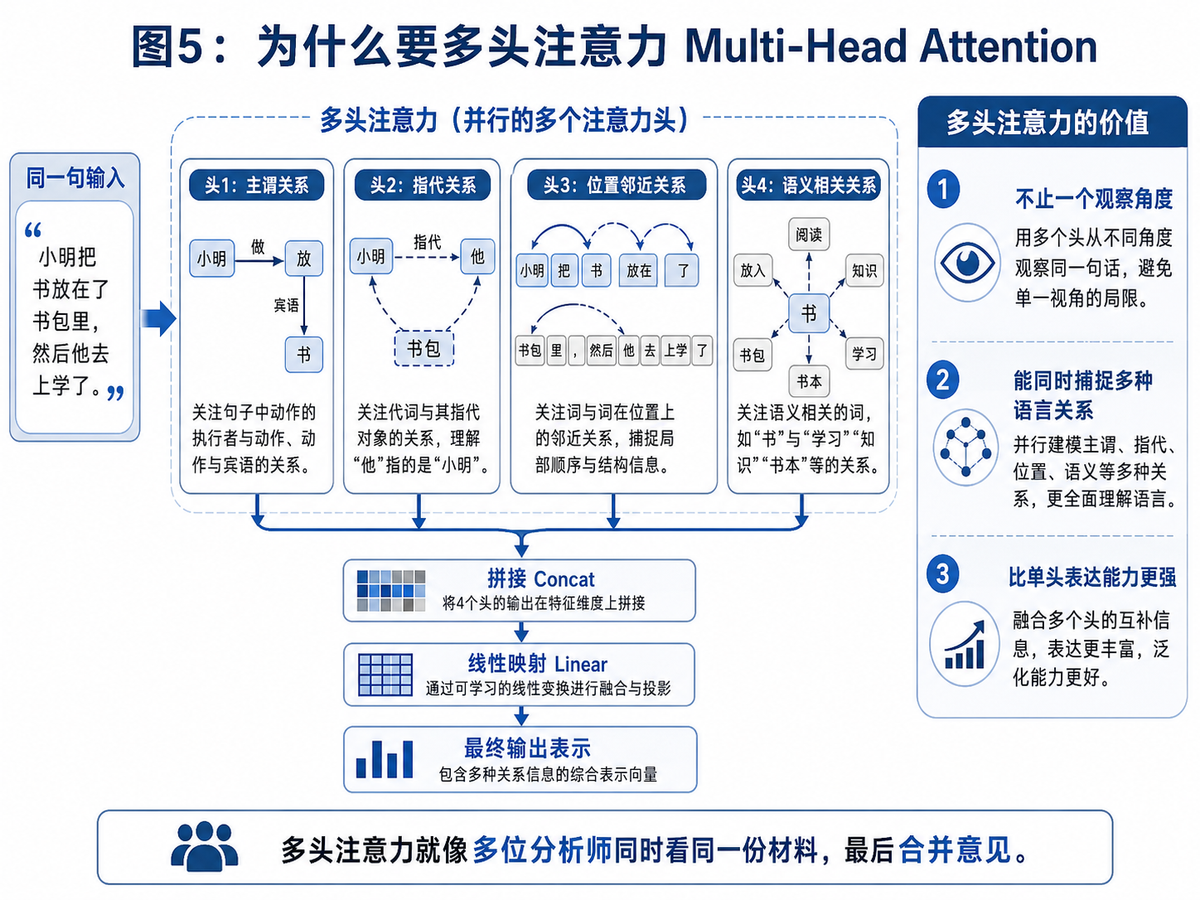
所以,多头注意力不是单纯“多算几次”,而是让模型同时捕捉不同类型的语言关系。你完全可以把它理解成“多位分析师同时看同一份材料,最后合并意见”。
7. 一个 Transformer Block 里面到底有什么?
Transformer 不是只有 Attention。真正的一个标准 Block,内部一般包含注意力、前馈网络、残差连接、LayerNorm 等一整套结构。
7.1 Encoder Block:偏“理解”
一个 Encoder Block 通常包括:多头自注意力 → Add & LayerNorm → 前馈网络 FFN → Add & LayerNorm。Encoder 的特点是:它可以看到整段输入,因此更擅长做“全局理解”。
7.2 Decoder Block:偏“生成”
Decoder Block 看起来和 Encoder 有点像,但它中间多了一层“编码器-解码器注意力”,并且开头的自注意力是带 Mask 的。Decoder 的特点是:它要严格按顺序生成内容,不能偷看未来词。
7.3 FFN、残差连接、LayerNorm 分别做什么?
FFN:对每个位置再做一次更深的非线性特征提炼。
残差连接:防止信息在深层网络中轻易丢失,也更利于训练。
LayerNorm:让数值分布更稳定,训练过程更平滑。
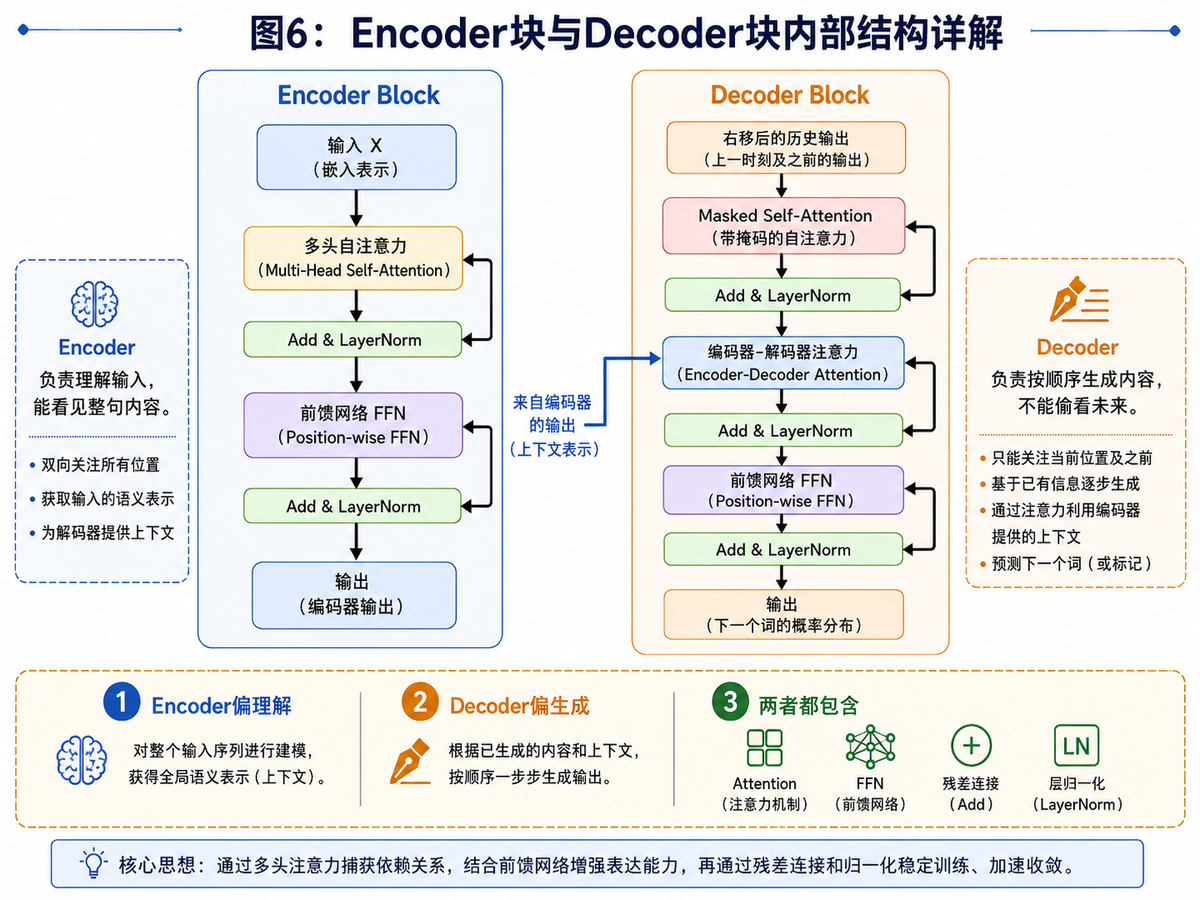
把这张图看懂,你对 Transformer 的“骨架结构”就已经建立起来了。后面不管是学 BERT,还是学 GPT,本质上都只是围绕这套骨架做取舍和扩展。
8. Decoder 为什么必须加 Mask?训练和推理有什么不同?
如果 Decoder 在生成第 3 个词的时候,直接去看第 4 个、第 5 个词,那训练就相当于作弊。因此,Decoder 侧的自注意力必须加因果 Mask,确保每个位置只能看到自己以及前面的位置,看不到未来。
8.1 训练阶段:Teacher Forcing
训练时,目标句子是已知的,因此我们通常会把“右移后的真实答案”送给 Decoder。例如目标是“我 爱 机器 学习”,那么输入给 Decoder 的往往是“<bos> 我 爱 机器”。这使得模型可以一次并行计算多个位置,因此训练速度更快。
8.2 推理阶段:自回归生成
推理时就完全不同了。模型一开始只有 <bos>,先生成第一个词,再把这个词接回去,作为下一步输入;然后再生成第二个词,如此反复。也就是说,推理必须一个 Token 一个 Token 往外生成。
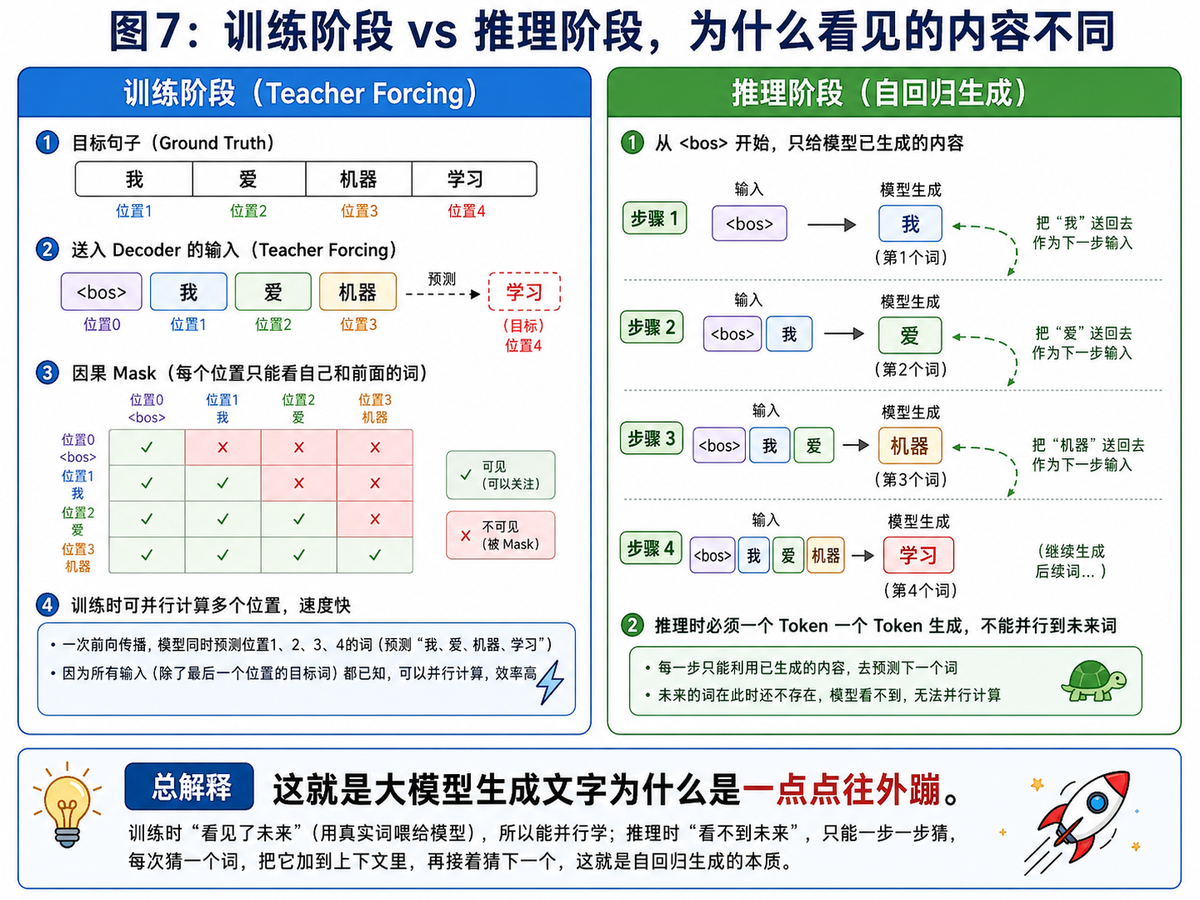
这也是为什么你看到大模型生成文字时,内容总是一点点往外蹦。不是模型故意“慢吞吞”,而是它本来就是按照“猜一个、接回去、再猜下一个”的方式工作的。
9. Transformer 为什么比 RNN / LSTM 更适合大模型时代?
经过前面的拆解,你已经能够理解 Transformer 的优势不是“因为它新”,而是因为它在计算方式上更适合现代硬件,也更适合被扩展到超大规模。
并行能力更强:同一层多个 Token 可以一起进入注意力计算。
更容易捕捉长距离依赖:任意位置之间可以直接交互。
更适合 GPU:核心计算高度矩阵化,更容易利用现代算力。
更容易扩展到超大模型:这是大模型时代最现实的工程优势。
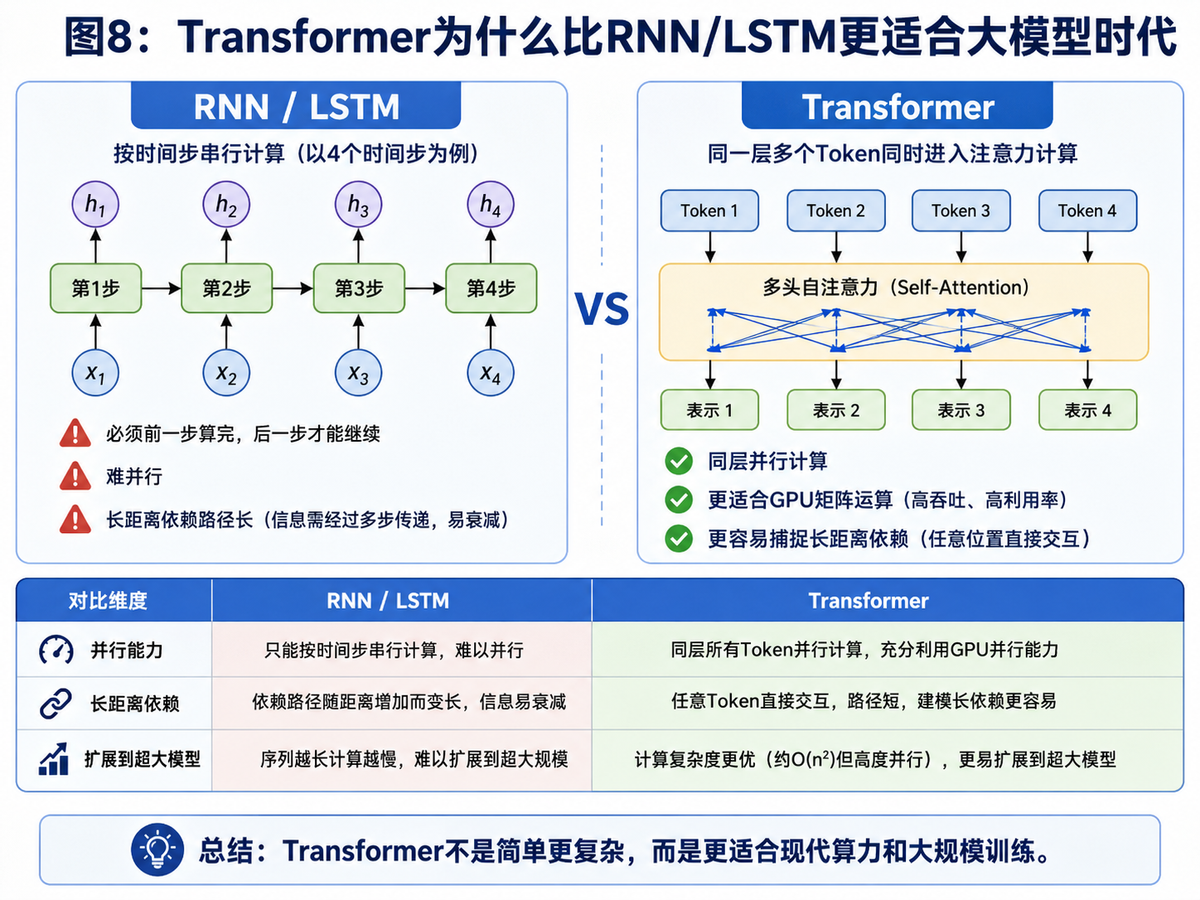
很多人会说 Attention 的复杂度是 O(n²),那它为什么还是赢了?关键就在于:虽然复杂度不低,但它高度并行;而 RNN 虽然单步结构简单,却很难并行。真正落到工程实践上,Transformer 更能吃到 GPU 和大规模训练带来的红利。
10. 从底层骨架往上看:BERT、GPT 和原始 Transformer 有什么区别?
学到这里,再去看不同模型家族会轻松很多,因为你会发现:它们差异很大,但地基其实相通。
Encoder-only:代表是 BERT,更偏“理解型任务”,例如分类、匹配、抽取、检索。
Decoder-only:代表是 GPT,更偏“生成型任务”,例如对话、续写、写作、代码生成。
Encoder-Decoder:代表是原始 Transformer,更适合“输入一段、输出一段”的映射任务,如翻译、摘要、生成式问答。
所以你可以简单记:BERT 更擅长读,GPT 更擅长写,原始 Transformer 更像“看一段、写一段”的通用序列到序列架构。
11. 学 Transformer 时最容易混淆的几个点
误区 1:注意力越大就代表“理解越深”。更准确的说法是:注意力权重表示在当前计算里参考某位置的程度。
误区 2:Q、K、V 是人为定义好的语义标签。其实它们是可学习的线性投影结果。
误区 3:Transformer 完全没有顺序概念。实际上它有顺序概念,只不过顺序依赖位置编码来注入。
误区 4:大模型就是 Transformer。更严谨的说法是:今天很多主流大模型以 Transformer 为核心骨架,但在训练方式、微调方式、推理优化上还叠加了大量工程能力。
12. 总结:你到底该怎么一句话讲清 Transformer?
如果面试官、同事,或者读者问你“Transformer 到底是什么”,你可以这样回答:
Transformer 是一种基于注意力机制的神经网络架构。它先把文本转换成带位置信息的向量,再让每个词通过自注意力动态关注其他词,通过多头注意力、前馈网络、残差连接和归一化不断更新表示;如果是生成任务,解码器还会通过 Mask 保证只能基于已知内容逐步往后生成。
最后再用最通俗的话收一下全文:
Embedding:把文字变成机器可计算的语义向量。
位置编码:告诉模型谁在前、谁在后。
Self-Attention:让每个词在更新自己时,动态参考其他词。
Q / K / V:分别负责提问、匹配、取值。
Multi-Head:让模型从多个角度同时理解一句话。
FFN:进一步做特征提炼。
Residual + LayerNorm:让深层训练更稳。
Mask:保证生成时不能偷看未来。
Encoder / Decoder:一个偏理解,一个偏生成。
说到底,Transformer 真正厉害的地方,不是某一个公式多漂亮,而是它把“全局关系建模”和“现代硬件友好型计算”这两件事做到了统一。这,才是它能撑起大模型时代的根本原因。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)