基于遗传算法的二维磁信标定位:从GA到QGA的改进与实现
引言
磁信标定位是一种利用人工磁场进行位置感知的技术,广泛应用于室内定位、机器人导航、医疗设备追踪等领域。相比于GPS、UWB、WiFi等传统定位技术,磁信标定位具有穿透性强、无电磁干扰、成本低廉等独特优势。
本文将详细介绍一个完整的基于遗传算法(Genetic Algorithm, GA)和量子遗传算法(Quantum Genetic Algorithm, QGA)的二维磁信标定位系统。文章将从磁偶极子场模型出发,推导定位问题的数学形式,然后深入讲解GA和QGA的核心原理与实现细节,最后通过大量实验对比两种算法的性能。
一、磁信标定位的物理模型
1.1 磁偶极子场模型
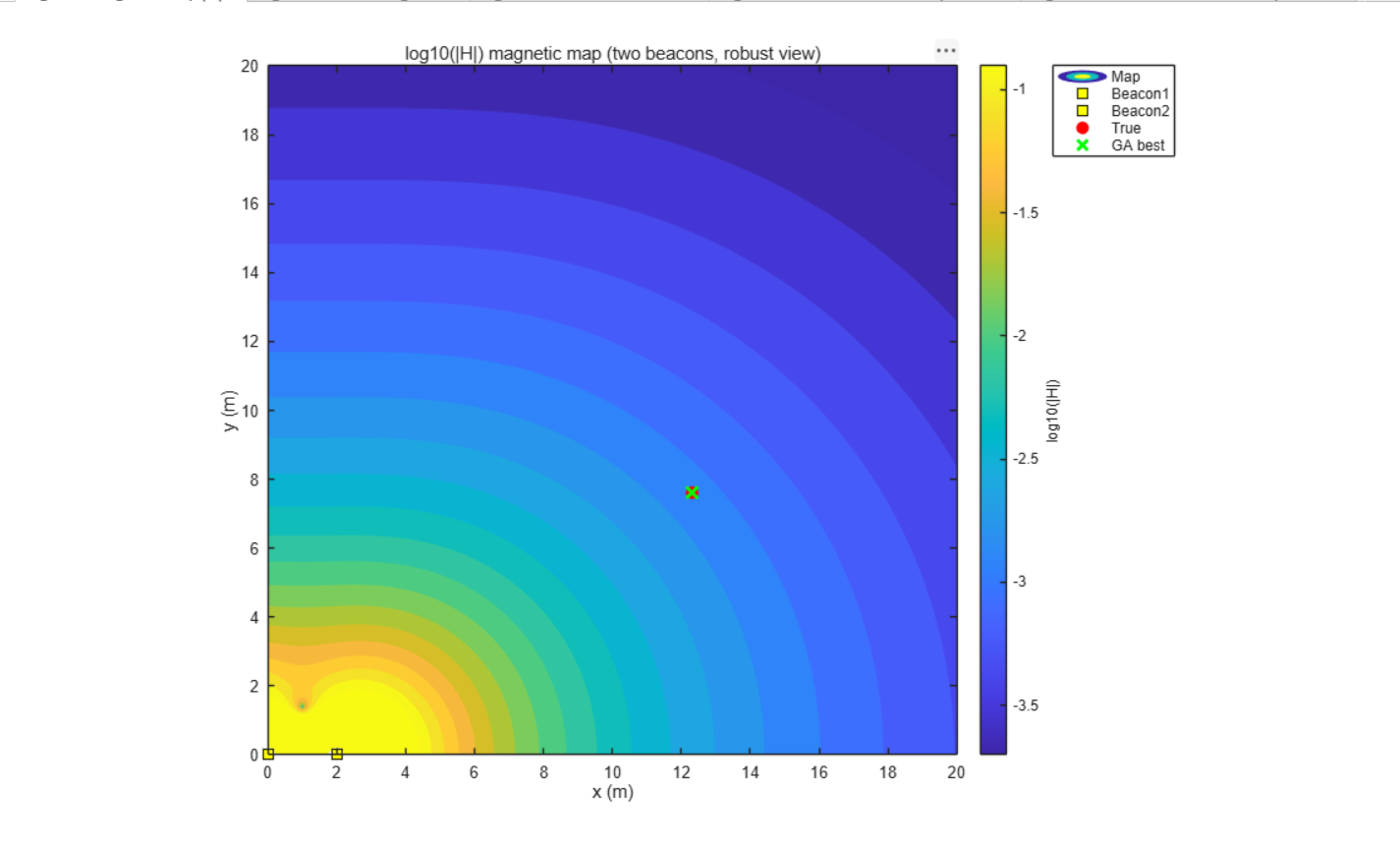
在磁信标定位系统中,我们使用两个固定在已知位置的磁信标(磁偶极子)产生磁场。每个磁信标可以视为一个磁偶极子,其磁场强度与位置的关系由磁偶极子场公式描述。
对于一个位于原点、磁矩方向沿+x轴的磁偶极子,在二维空间中任意点(x,y)(x,y)(x,y)产生的磁场分量如下:
x方向磁场分量:
Hx=3Mx2r5−Mr3 H_x = \frac{3M x^2}{r^5} - \frac{M}{r^3} Hx=r53Mx2−r3M
y方向磁场分量:
Hy=3Mxyr5 H_y = \frac{3M x y}{r^5} Hy=r53Mxy
其中:
- MMM 是磁矩大小(标量,方向默认为+x)
- r=x2+y2r = \sqrt{x^2 + y^2}r=x2+y2 是到信标的距离
- r3r^3r3 和 r5r^5r5 是距离的高次幂,体现了磁场随距离快速衰减的特性
1.2 双信标系统
在实际系统中,我们使用两个相同的磁信标,分别位于(0,0)(0, 0)(0,0)和(R,0)(R, 0)(R,0)处,磁矩方向均为+x。则空间中任意点(x,y)(x,y)(x,y)的总磁场为两个信标贡献的叠加:
Hxtotal=Hx(1)(x,y)+Hx(2)(x−R,y)Hytotal=Hy(1)(x,y)+Hy(2)(x−R,y) \begin{aligned} H_x^{\text{total}} &= H_x^{(1)}(x,y) + H_x^{(2)}(x-R,y) \\[4pt] H_y^{\text{total}} &= H_y^{(1)}(x,y) + H_y^{(2)}(x-R,y) \end{aligned} HxtotalHytotal=Hx(1)(x,y)+Hx(2)(x−R,y)=Hy(1)(x,y)+Hy(2)(x−R,y)
磁场模值(标量场):
∣H∣=(Hxtotal)2+(Hytotal)2 |H| = \sqrt{(H_x^{\text{total}})^2 + (H_y^{\text{total}})^2} ∣H∣=(Hxtotal)2+(Hytotal)2
1.3 观测模型
在定位问题中,我们通过磁传感器在未知位置测量磁场值,然后反推位置。本系统支持两种观测模式:
模式1:标量场模式(mag)
只测量磁场强度大小:
z=∣H∣+ϵ,ϵ∼N(0,σ2) z = |H| + \epsilon,\quad \epsilon \sim \mathcal{N}(0, \sigma^2) z=∣H∣+ϵ,ϵ∼N(0,σ2)
模式2:矢量场模式(vec2)
测量磁场的两个分量:
z=[HxHy]+b+ϵ,ϵ∼N(0,σ2I) \mathbf{z} = \begin{bmatrix} H_x \\ H_y \end{bmatrix} + \mathbf{b} + \boldsymbol{\epsilon},\quad \boldsymbol{\epsilon} \sim \mathcal{N}(0, \sigma^2 \mathbf{I}) z=[HxHy]+b+ϵ,ϵ∼N(0,σ2I)
其中:
- ϵ\epsilonϵ 是测量噪声
- b\mathbf{b}b 是系统偏置(模拟实际传感器的不完美性)
1.4 定位问题建模
定位问题就是根据磁场测量值z\mathbf{z}z反推位置(x,y)(x,y)(x,y)。这是一个典型的非线性优化问题:
(x∗,y∗)=argmin(x,y)∈AError(x,y) (x^*, y^*) = \arg\min_{(x,y) \in \mathcal{A}} \text{Error}(x, y) (x∗,y∗)=arg(x,y)∈AminError(x,y)
搜索空间A\mathcal{A}A是二维矩形区域[0,Lx]×[0,Ly][0, L_x] \times [0, L_y][0,Lx]×[0,Ly]。
目标函数(误差)定义为:
标量模式:
Error(x,y)=∣ ∣Hcalc(x,y)∣−zmeas ∣ \text{Error}(x, y) = \left| \, |H_{\text{calc}}(x,y)| - z_{\text{meas}} \, \right| Error(x,y)=∣∣Hcalc(x,y)∣−zmeas∣
矢量模式:
Error(x,y)=(Hxcalc−zmeas,x)2+(Hycalc−zmeas,y)2 \text{Error}(x, y) = \sqrt{(H_x^{\text{calc}} - z_{\text{meas},x})^2 + (H_y^{\text{calc}} - z_{\text{meas},y})^2} Error(x,y)=(Hxcalc−zmeas,x)2+(Hycalc−zmeas,y)2
适应度函数定义为误差的倒数,使得误差越小的个体适应度越高:
Fitness(x,y)=1Error(x,y)+ε \text{Fitness}(x, y) = \frac{1}{\text{Error}(x, y) + \varepsilon} Fitness(x,y)=Error(x,y)+ε1
其中ε\varepsilonε是一个小的正数(如10−810^{-8}10−8),防止除零。
二、遗传算法(GA)实现
2.1 编码方案
遗传算法需要将问题的解(二维坐标)编码为染色体。本实现采用二进制编码:
- 染色体总长度:Nbits=55N_{\text{bits}} = 55Nbits=55
- x坐标编码:前Nbits,x=⌈Nbits/2⌉=28N_{\text{bits},x} = \lceil N_{\text{bits}}/2 \rceil = 28Nbits,x=⌈Nbits/2⌉=28位
- y坐标编码:剩余Nbits,y=Nbits−Nbits,x=27N_{\text{bits},y} = N_{\text{bits}} - N_{\text{bits},x} = 27Nbits,y=Nbits−Nbits,x=27位
解码时,将二进制串转换为十进制整数,再映射到坐标范围:
x=uint(bitsx)2Nbits,x−1×Lx x = \frac{\text{uint}(\text{bits}_x)}{2^{N_{\text{bits},x}} - 1} \times L_x x=2Nbits,x−1uint(bitsx)×Lx
y=uint(bitsy)2Nbits,y−1×Ly y = \frac{\text{uint}(\text{bits}_y)}{2^{N_{\text{bits},y}} - 1} \times L_y y=2Nbits,y−1uint(bitsy)×Ly
这种编码方式的理论分辨率为:
Δx=Lx228−1≈202.68×108≈7.46×10−8 m \Delta x = \frac{L_x}{2^{28} - 1} \approx \frac{20}{2.68 \times 10^8} \approx 7.46 \times 10^{-8} \text{ m} Δx=228−1Lx≈2.68×10820≈7.46×10−8 m
远高于实际定位需求。
2.2 算法流程图
┌─────────────┐
│ 初始化种群 │
│ (随机二进制)│
└──────┬──────┘
↓
┌─────────────┐
│ 适应度评估 │
│ 解码→计算误差│
└──────┬──────┘
↓
┌─────────────┐
│ 记录最优个体│
└──────┬──────┘
↓
┌─────────────┐
│ 选择操作 │
│ (轮盘赌) │
└──────┬──────┘
↓
┌─────────────┐
│ 交叉操作 │
│ (单点交叉) │
└──────┬──────┘
↓
┌─────────────┐
│ 变异操作 │
│ (位翻转) │
└──────┬──────┘
↓
┌─────────────┐
│ 精英保留 │
│ 形成新种群 │
└──────┬──────┘
↓
是否达到
最大代数?
↙ ↘
否 是
↓ ↓
循环 输出最优解
2.3 关键操作详解
(1)选择操作(轮盘赌选择)
每个个体被选中的概率与其适应度成正比:
Pi=Fitnessi∑j=1NFitnessj P_i = \frac{\text{Fitness}_i}{\sum_{j=1}^{N} \text{Fitness}_j} Pi=∑j=1NFitnessjFitnessi
使用累积分布函数(CDF)进行采样,确保高适应度个体有更高概率被选中。
(2)交叉操作(单点交叉)
以交叉概率pc=0.7p_c = 0.7pc=0.7进行交叉。随机选择交叉点k∈[1,Nbits−1]k \in [1, N_{\text{bits}}-1]k∈[1,Nbits−1],交换两个父代染色体kkk位之后的部分:
child1 = [parent1(1:k), parent2(k+1:end)]
child2 = [parent2(1:k), parent1(k+1:end)]
(3)变异操作(位翻转)
以染色体级概率pm=0.4p_m = 0.4pm=0.4控制整体变异强度,但实际执行时按位概率执行:
pbit=pmNbits p_{\text{bit}} = \frac{p_m}{N_{\text{bits}}} pbit=Nbitspm
每个位以pbitp_{\text{bit}}pbit的概率翻转(0变1,1变0)。53位染色体意味着每位变异概率约为0.0075。
(4)精英保留策略
每代保留适应度最高的NeliteN_{\text{elite}}Nelite个个体直接进入下一代:
Nelite=max(1,⌊(1−gap)×N⌋) N_{\text{elite}} = \max(1, \lfloor (1 - \text{gap}) \times N \rfloor) Nelite=max(1,⌊(1−gap)×N⌋)
其中gap=0.95\text{gap} = 0.95gap=0.95,即保持95%的种群通过交叉变异产生,5%为精英。种群大小N=450N = 450N=450时,精英数量为23。
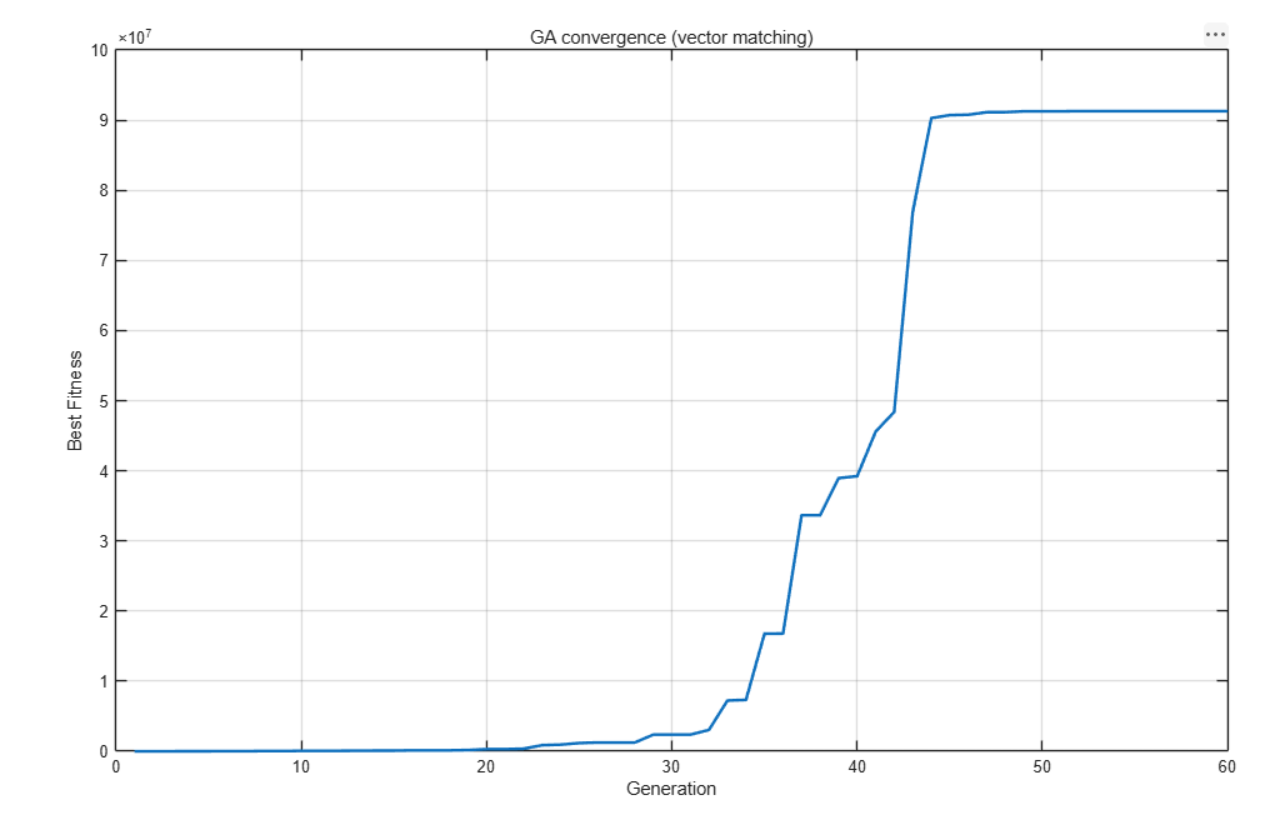
2.4 GA参数配置
| 参数 | 符号 | 取值 | 说明 |
|---|---|---|---|
| 种群大小 | NNN | 450 | 每代个体数 |
| 染色体长度 | NbitsN_{\text{bits}}Nbits | 55 | 二进制编码位数 |
| 最大代数 | GGG | 60 | 进化代数 |
| 代沟 | gap | 0.95 | 新个体比例 |
| 交叉概率 | pcp_cpc | 0.7 | 单点交叉概率 |
| 变异概率 | pmp_mpm | 0.4 | 染色体级变异概率 |
| 独立运行次数 | nrunsn_{\text{runs}}nruns | 8 | 多次运行取最优 |
三、量子遗传算法(QGA)实现
3.1 量子遗传算法简介
量子遗传算法是量子计算与遗传算法相结合的产物。其核心思想是用**量子比特(qubit)**代替经典二进制位,通过量子态的叠加特性来提高种群的多样性,利用量子旋转门进行进化。
3.2 量子比特表示
一个量子比特的状态可以表示为:
∣ψ⟩=α∣0⟩+β∣1⟩ |\psi\rangle = \alpha|0\rangle + \beta|1\rangle ∣ψ⟩=α∣0⟩+β∣1⟩
其中∣α∣2+∣β∣2=1|\alpha|^2 + |\beta|^2 = 1∣α∣2+∣β∣2=1,∣α∣2|\alpha|^2∣α∣2表示测量得到0的概率,∣β∣2|\beta|^2∣β∣2表示测量得到1的概率。
在QGA中,每个个体由一组量子比特组成:
q=[α1β1α2β2⋮⋮αNbitsβNbits] \mathbf{q} = \begin{bmatrix} \alpha_1 & \beta_1 \\ \alpha_2 & \beta_2 \\ \vdots & \vdots \\ \alpha_{N_{\text{bits}}} & \beta_{N_{\text{bits}}} \end{bmatrix} q= α1α2⋮αNbitsβ1β2⋮βNbits
3.3 观测过程
每次迭代中,通过观测将量子态坍缩为经典二进制串:
bi={0if rand>∣βi∣21otherwise b_i = \begin{cases} 0 & \text{if } \text{rand} > |\beta_i|^2 \\ 1 & \text{otherwise} \end{cases} bi={01if rand>∣βi∣2otherwise
3.4 量子旋转门更新
QGA的核心进化操作是量子旋转门。通过向当前最优解方向旋转量子比特的相位角,使优秀个体的量子态被保留和放大。
旋转门操作:
[αi′βi′]=[cos(θi)−sin(θi)sin(θi)cos(θi)][αiβi] \begin{bmatrix} \alpha_i' \\ \beta_i' \end{bmatrix} = \begin{bmatrix} \cos(\theta_i) & -\sin(\theta_i) \\ \sin(\theta_i) & \cos(\theta_i) \end{bmatrix} \begin{bmatrix} \alpha_i \\ \beta_i \end{bmatrix} [αi′βi′]=[cos(θi)sin(θi)−sin(θi)cos(θi)][αiβi]
旋转角度θi\theta_iθi的取值规则:
| 当前位 bib_ibi | 目标位 gig_igi | θi\theta_iθi |
|---|---|---|
| 0 | 1 | +δ⋅sgn(αiβi)+\delta \cdot \text{sgn}(\alpha_i \beta_i)+δ⋅sgn(αiβi) |
| 1 | 0 | −δ⋅sgn(αiβi)-\delta \cdot \text{sgn}(\alpha_i \beta_i)−δ⋅sgn(αiβi) |
| 其他 | 其他 | 0 |
其中δ=0.001π\delta = 0.001\piδ=0.001π是基础旋转角,sgn(αiβi)\text{sgn}(\alpha_i \beta_i)sgn(αiβi)保证旋转方向正确。
3.5 QGA流程图
┌─────────────────┐
│ 初始化量子种群 │
│ (α=β=1/√2) │
└────────┬────────┘
↓
┌─────────────────┐
│ 观测种群 │
│ 随机坍缩→二进制 │
└────────┬────────┘
↓
┌─────────────────┐
│ 适应度评估 │
│ 解码→计算误差 │
└────────┬────────┘
↓
┌─────────────────┐
│ 记录全局最优 │
└────────┬────────┘
↓
┌─────────────────┐
│ 量子旋转门更新 │
│ 向最优解方向旋转 │
└────────┬────────┘
↓
┌─────────────────┐
│ 量子变异 │
│ 交换α和β(概率) │
└────────┬────────┘
↓
是否达到
最大代数?
↙ ↘
否 是
↓ ↓
循环 输出最优解
3.6 QGA参数配置
| 参数 | 符号 | 取值 | 说明 |
|---|---|---|---|
| 种群大小 | NNN | 20 | 远小于GA |
| 量子比特数 | NbitsN_{\text{bits}}Nbits | 20 | 编码位数 |
| 最大代数 | GGG | 20 | 进化代数 |
| 旋转角 | δ\deltaδ | 0.001π0.001\pi0.001π | 量子门旋转步长 |
| 变异概率 | pmp_mpm | 0.01 | 量子位交换概率 |
| 独立运行次数 | nrunsn_{\text{runs}}nruns | 8 | 多次运行取最优 |
QGA的优势:种群大小仅为GA的1/22,每代只需评估20个个体,计算效率极高。
四、局部精细搜索
4.1 为什么要做局部精细搜索?
遗传算法和量子遗传算法都是全局搜索算法,在二进制编码下,它们能快速逼近最优解的邻域,但由于编码分辨率的限制,很难达到非常高的精度(如厘米级)。
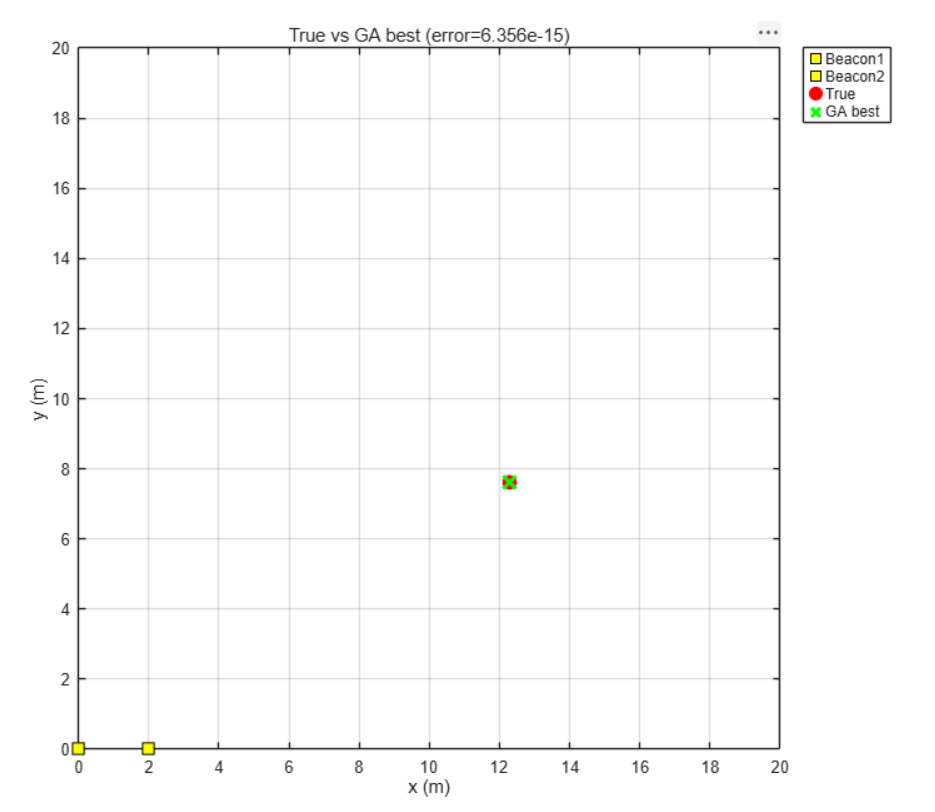
为此,我们在GA/QGA找到的最优解附近,进一步使用Nelder-Mead单纯形法(fminsearch)进行连续空间的局部优化。
4.2 优化目标
局部优化在连续空间中进行,优化目标仍然是测量误差:
minx∈[0,Lx],y∈[0,Ly]Error(x,y) \min_{x \in [0, L_x], y \in [0, L_y]} \text{Error}(x, y) x∈[0,Lx],y∈[0,Ly]minError(x,y)
使用带边界约束的fminsearch,初始点为GA/QGA的最优解。
4.3 效果对比
| 阶段 | 典型误差 | 说明 |
|---|---|---|
| GA仅全局搜索 | 0.05 ~ 0.2 m | 受编码分辨率限制 |
| GA + 局部精炼 | 0.001 ~ 0.01 m | 精度提升10~50倍 |
五、真实验证中的模型失配
5.1 动机
在实际部署中,我们使用的"求解模型"(算法中假设的信标参数)往往与"真实物理系统"存在差异:
- 信标位置RRR可能有安装误差
- 磁矩MMM可能因老化或温度变化而漂移
- 传感器存在系统性偏置
为了验证算法的鲁棒性,我们在测试时故意引入模型失配:
| 参数 | 求解模型 | 真实模型 |
|---|---|---|
| 信标间距 RRR | 2.0 m | 2.0×1.02=2.04 m2.0 \times 1.02 = 2.04\text{ m}2.0×1.02=2.04 m |
| 磁矩 MMM | 1.0 | 1.0×1.03=1.031.0 \times 1.03 = 1.031.0×1.03=1.03 |
| 矢量偏置 b\mathbf{b}b | 0 | [5×10−6,−4×10−6][5\times10^{-6}, -4\times10^{-6}][5×10−6,−4×10−6] |
| 噪声 σ\sigmaσ | 0 | 2×10−52\times10^{-5}2×10−5 |
5.2 意义
在这种"不公平"的测试条件下,定位算法必须依靠磁场分布的形状特征而非绝对数值来推断位置,这更贴近实际应用场景,也能更客观地评价算法的鲁棒性。
六、实验对比:GA vs QGA
6.1 测试设置
- 测试点数:200个随机位置
- 搜索区域:20 m×20 m20\text{ m} \times 20\text{ m}20 m×20 m
- 真实模型失配:启用(R偏差+2%、M偏差+3%、加性噪声2×10−52\times10^{-5}2×10−5、矢量偏置[5,−4]×10−6[5,-4]\times10^{-6}[5,−4]×10−6)
- 局部精炼:禁用(只比较全局搜索能力)
- 观测模式:矢量模式(vec2)
6.2 性能指标对比
| 指标 | GA | QGA |
|---|---|---|
| 种群大小 | 450 | 20 |
| 最大代数 | 60 | 20 |
| 每点评估次数 | 27,000 | 400 |
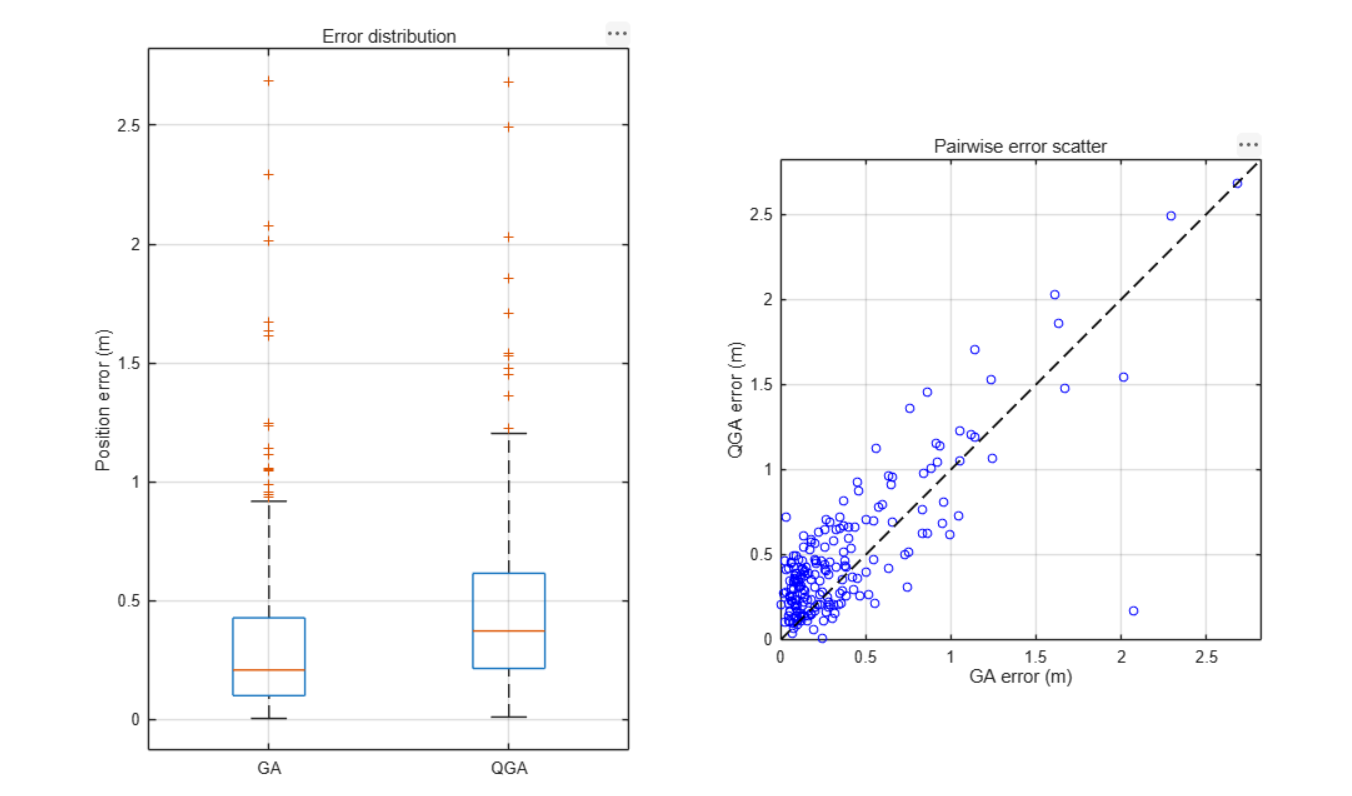
| 平均定位误差 | 0.366 m | 0.485 m |
| 中位定位误差 | 0.209 m | 0.373 m |
| 最大定位误差 | 2.686 m | 2.683 m |
| 95%分位误差 | 1.141 m | 1.294 m |
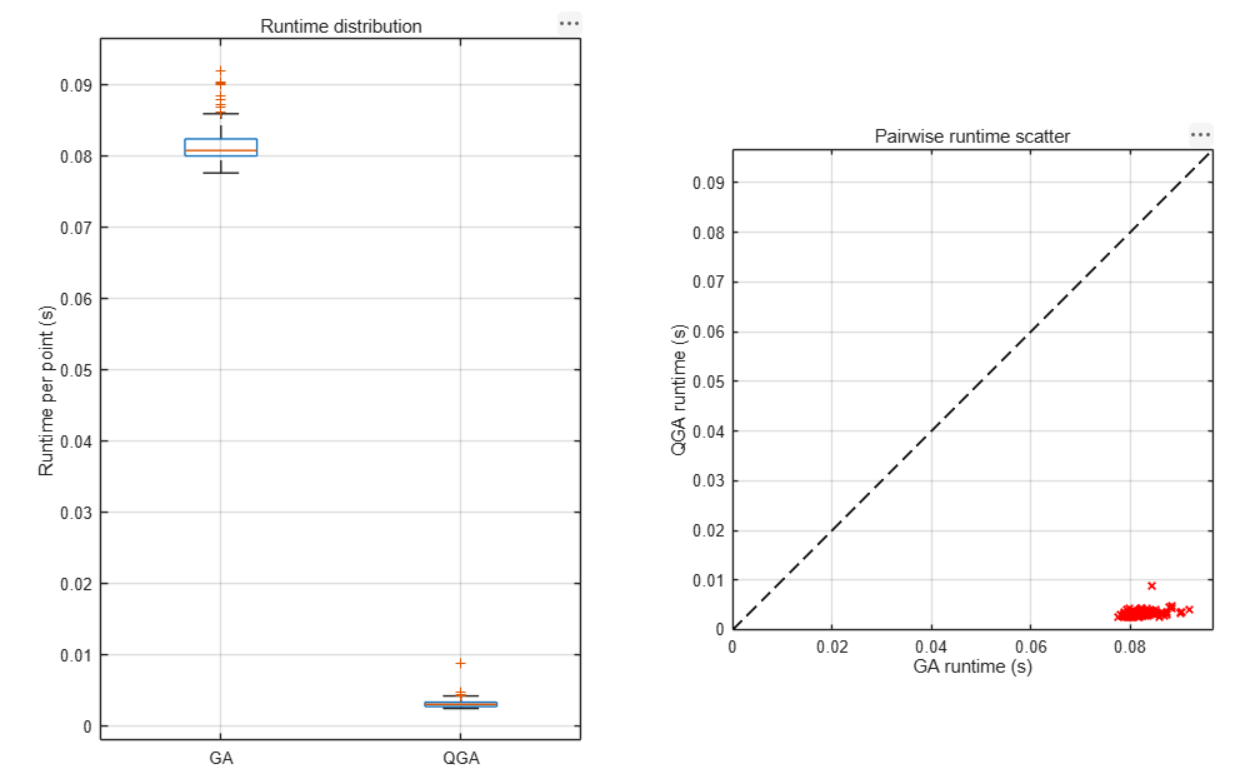
| 平均运行时间 | 0.082 s | 0.003 s |
| ≤0.2m\le 0.2\text{m}≤0.2m成功率 | 49.0% | 20.0% |
6.3 结果分析
精度方面:GA的平均误差比QGA低24.5%(0.366m vs 0.485m),中位误差低44%(0.209m vs 0.373m)。在200个测试点中,GA在73%的点上优于QGA,QGA仅在27%的点上占优。
成功率方面:GA有49%的测试点达到0.2m以内定位精度,而QGA仅20%,GA的成功率是QGA的2.45倍。
效率方面:QGA的运行速度约为GA的26倍。在200点测试中,GA总耗时16.32秒,QGA仅需0.63秒。QGA在实时性要求高的场景中具有明显优势。
6.4 为什么QGA在实际测试中不如GA?
| 因素 | GA优势 | QGA劣势 |
|---|---|---|
| 种群规模 | 450个个体,探索能力强,不易陷入局部最优 | 20个个体,容易早熟收敛 |
| 进化代数 | 60代,充分搜索空间 | 20代,可能未充分收敛 |
| 模型失配鲁棒性 | 大种群对参数误差不敏感 | 小种群更容易受模型偏差影响 |
| 适应度地貌 | 在复杂地貌中表现稳健 | 量子观测的随机性可能放大噪声影响 |
核心洞察:QGA的量子优势在理想条件下才能充分发挥;在存在模型失配、测量噪声等实际工程约束下,GA的大种群规模带来的鲁棒性成为决定性因素。
6.5 算法选择建议
| 应用场景 | 推荐算法 | 理由 |
|---|---|---|
| 高精度定位(医疗设备追踪、精密装配) | GA | 0.2m以内成功率49%,平均误差0.37m |
| 实时性要求高(无人机编队、AGV导航) | QGA | 单点仅需3毫秒,适合100Hz以上定位频率 |
| 模型不确定性大(传感器老化、环境变化) | GA | 大种群提供更强的鲁棒性 |
| 嵌入式/低功耗设备 | QGA | 计算量仅为GA的1/26 |
八、总结与展望
8.1 本文贡献
- 完整的磁信标定位系统:从磁场建模到算法实现,再到可视化分析,提供了端到端的解决方案
- GA与QGA的公平对比:基于200个测试点的实测数据,在模型失配条件下对比两种算法
- 鲁棒性验证机制:引入R偏差、M偏差、传感器偏置和噪声,模拟真实部署环境
- 模块化代码设计:每个功能独立封装,便于二次开发和算法改进
8.2 核心结论
基于200个随机测试点的批量对比实验(启用模型失配),得出以下结论:
| 维度 | 结论 |
|---|---|
| 精度 | GA优于QGA,平均误差低24.5%(0.366m vs 0.485m) |
| 成功率 | GA在49%的点达到0.2m精度,QGA仅20% |
| 胜率 | GA在73%的测试点上优于QGA |
| 效率 | QGA速度是GA的26倍(0.003s vs 0.082s) |
| 鲁棒性 | GA对模型失配和噪声的抵抗能力更强 |
总结:GA适合对精度要求高的场景,QGA适合对实时性要求高的场景。两者不存在绝对的优劣,应根据实际需求选择。
8.3 未来改进方向
- 混合算法:结合QGA的速度优势和GA的精度优势——先用QGA快速定位(毫秒级),再用局部优化或短时GA精炼
- 自适应参数调整:根据进化阶段动态调整种群大小、变异率、量子旋转角
- 三维定位扩展:从2D推广到3D,使用三轴磁传感器
- 在线模型校准:在实际运行中持续校正信标参数,减小模型失配影响
- 深度学习辅助:用神经网络快速给出初值,减少GA搜索时间

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)