比 GPT-4o 小千倍,却能听说看:0.1B 全模态模型的工程秘密
Speech AI · FRONTIER — 第 2 期精读
MiniMind-O:0.1B 参数,一套权重搞定听说看全部
📄 原文:MiniMind-O Technical Report: An Open Small-Scale Speech-Native Omni Model
👥 作者:Jingyao Gong
📅 日期:2026-05-05 | 🏷️ 来源:arXiv 2605.03937 (cs.SD / cs.MM / eess.AS)
📌 一句话总结
用 0.1B 参数从零训练一个能听(ASR)、能说(TTS)、能看(图像理解)的全模态模型,全部代码、权重、训练数据开源,4 小时在 4 张 RTX 3090 上跑完。
🤔 这篇论文要解决什么问题?
痛点一:全模态模型门槛极高。 GPT-4o、Gemini 等 Omni 模型的参数量和训练成本对普通研究者几乎不可企及。学术界缺乏一个能在消费级 GPU 上完整复现的全模态基线——"听说看"能力的完整技术路线对外近乎黑箱。
痛点二:文本与语音生成的统一建模困难。 传统方案是文本 LLM + 独立 TTS 系统的级联,存在延迟累积和信息割裂。如何让同一个 LLM 骨干在一次前向传播中同时输出文字 token 和语音 codec token,是核心工程难题。
痛点三:流式语音生成缺乏可复现实现。 现有开源 Omni 模型(Mini-Omni、VITA 等)或不支持流式输出,或缺乏完整训练代码。MiniMind-O 的切入点是:在极小参数量约束下,设计一套 Thinker-Talker 双路架构,并完整开源从数据处理到推理的全链路代码。
🏗️ 核心方法
整体架构:Thinker + Talker 双路设计
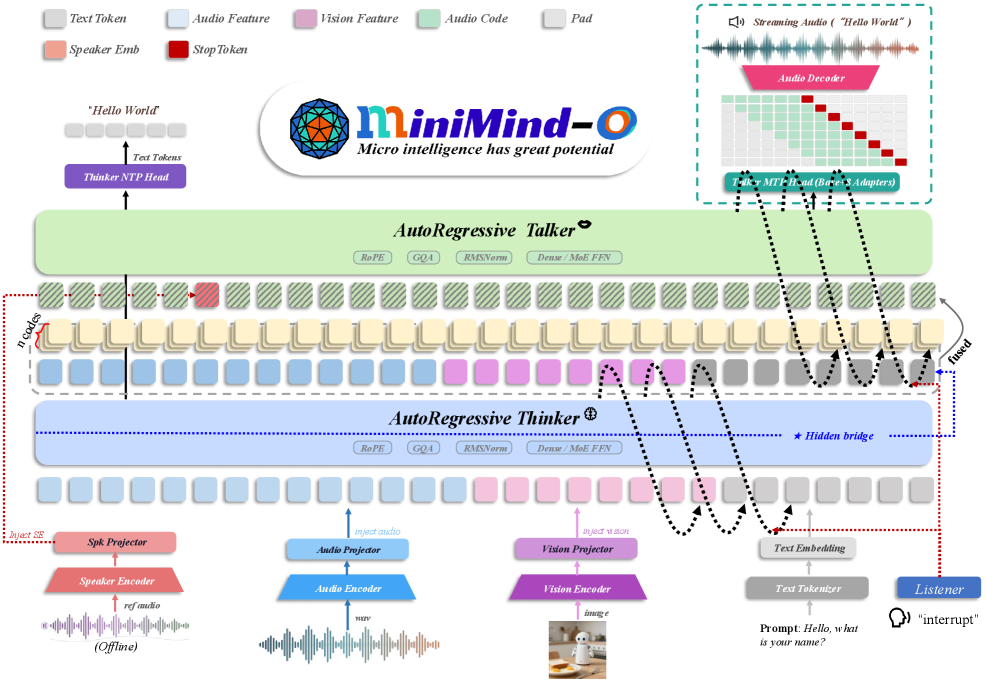
▲ 架构图详解:
整体架构由三部分组成。输入侧,音频经冻结的 SenseVoice-Small 编码器提取声学特征,图像经冻结的 SigLIP2 编码器提取视觉特征,二者各自通过一个 2 层 MLP 投影器映射到 768 维的统一隐空间,注入文本序列中的模态占位符(modality-placeholder)位置。
Thinker 是核心语义处理模块,即完整的 MiniMind Transformer:8 层、隐藏维 768、GQA(8 Query heads / 4 KV heads),可训练参数 63.91M(Dense 版)/ 198.42M(MoE 版)。Thinker 负责理解所有模态输入并生成文字回复 token。
Talker 是独立的语音生成模块:4 层 MiniMind 块、隐藏维 768,可训练参数 47.05M(Dense)/ 114.30M(MoE)。Talker 不直接读取 Thinker 最后一层输出,而是读取中间层桥接状态(详见技术点一)。Mimi codec(冻结,96.15M)负责将 8 层 codebook 预测解码为 24kHz 波形。
Talker 语音生成设计
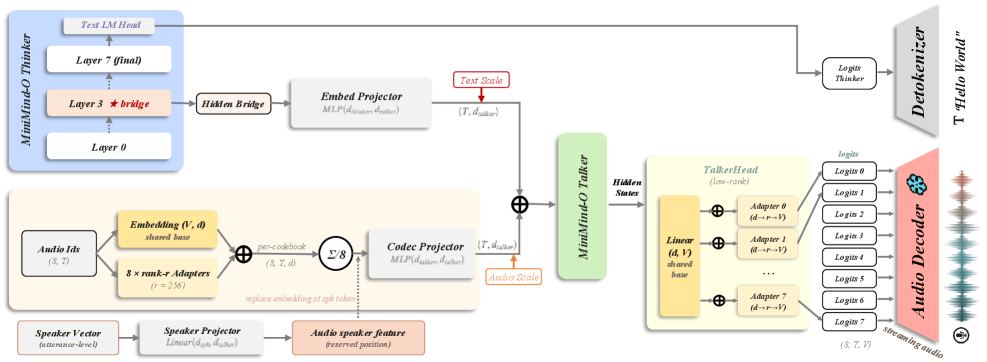
▲ Talker 详解:
Talker 的输入由四部分拼接而成:① Thinker 中间层桥接状态(经 embed_proj 投影);② 已生成的音频码嵌入(历史 codec token);③ 可选的说话人参考信息;④ 参考 codec 提示(用于声音克隆)。
输出侧,Talker 并行预测 8 个 Mimi codebook 的 logits(每层码本大小 2048),采用 9 流序列格式:1 个文本流 + 8 个音频码流,音频码流按 codebook 层级错排生成,第 q 层从 assistant_start + q + 1 位置开始。Talker 采用非全秩参数化(shared embedding + 低秩适配器 + shared head + 低秩适配器),在参数量和表达能力间取得平衡。
Mimi codec 配置:帧率 12.5Hz,输出采样率 24kHz,8 层 codebook。
训练序列格式与训练流水线
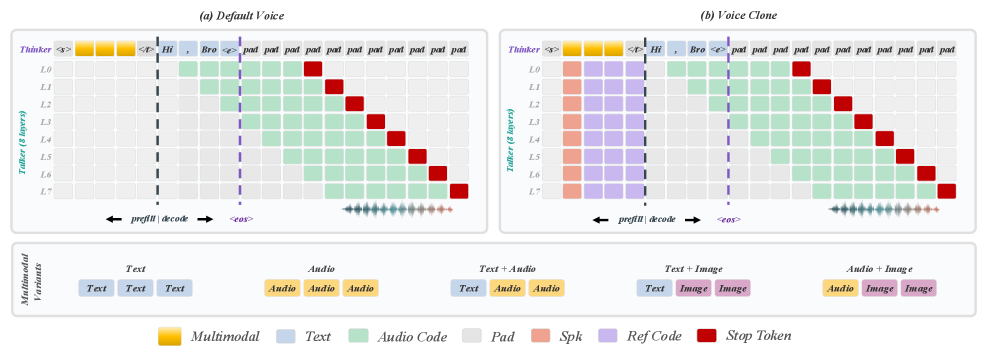
▲ 训练序列详解:
Thinker 和 Talker 使用同一条序列但施加不同的监督信号。文本监督(CE loss)只作用在 Thinker 的回复 token 位置;音频监督(CE loss on codebook logits)只作用在 Mimi 码的目标位置。两路损失解耦,互不干扰。
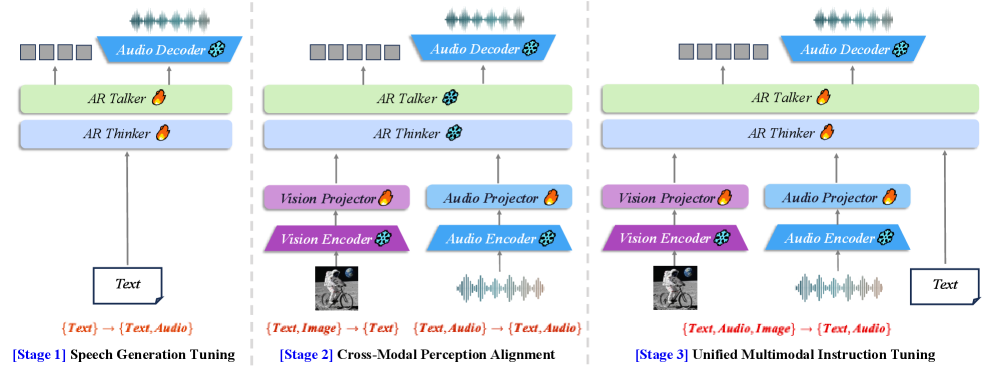
▲ 训练流水线详解:
训练分四个阶段,全程使用 bf16 混合精度、AdamW、梯度裁剪 1.0、每 GPU batch size 32:
| 阶段 | 数据 | 数据量 | 学习率 | 耗时 |
|---|---|---|---|---|
| T2A(文本→语音) | sft_t2a | 1,248,923 条 / 1636h | 5×10⁻⁶,1 epoch | ~45 min |
| A2A 投影器预热 | sft_a2a | 414,024 条 / 423h | 5×10⁻⁴,1 epoch,冻结主模型 | ~25 min |
| A2A 全模型 | sft_a2a | 同上 | 5×10⁻⁵,3 epochs | ~75 min |
| I2T(图像→文本) | 图文对 | 论文未披露 | 5×10⁻⁶,1 epoch | ~45 min |
关键技术点
技术点一:中间层桥接状态(Bridge State)
- 是什么:Thinker 不把最后一层隐状态传给 Talker,而是提取第
num_hidden_layers // 2 - 1层(8 层模型为第 3 层)的输出,经 embed_proj 线性层投影后输入 Talker。 - 为什么有效:论文分析,最后一层隐状态已被 next-token 分类器的几何结构和噪声"塑形",丢失了发音和句法信息;嵌入层则主要包含 token 身份信息。中间层在语义抽象和声学可解性之间取得最优平衡。
- 与已有方法的区别:Mini-Omni 等直接使用最后一层,MiniMind-O 的中间层方案在消融实验中体现了更低的 CER。
技术点二:低秩非全秩 Talker 参数化
- 是什么:Talker 的 8 个音频码嵌入表(vocab=2112)和 8 个输出头,分别采用共享基础矩阵 + 低秩适配器的设计:
E_q = E_shared + U_q V_q^T(rank r)。 - 为什么有效:8 个 codebook 之间存在大量共享结构,低秩分解既减少参数量,又保留各层的个性化能力。
- 消融发现:输出头的秩比输入嵌入的秩更关键;中等秩(rank=256)即可恢复大部分收敛收益。
技术点三:9 流错排序列格式
- 是什么:将文本 token 和 8 层 Mimi codec token 交织在同一序列中,音频码流按层错排(第 q 层 codec 从第
assistant_start + q + 1位置开始),实现流式解码。 - 为什么有效:错排设计使模型在生成第 1 层 codec 时已可预测第 2 层,天然支持增量解码和流式播放,第一个 codec 帧在生成后即可立刻送入 Mimi 解码器输出音频。
📊 实验结果
Talker 隐藏维度消融
| 隐藏维度 | Dense CER | MoE CER |
|---|---|---|
| 768 | 0.0897 | 0.0900 |
| 512 | 0.1745 | 0.1265 |
| 384 | 0.2767 | 0.3280 |
📌 关键数据:768 维是唯一在 Dense 和 MoE 两种变体上均稳定的配置,512 维时 CER 翻倍,384 维时接近崩溃。
声音克隆相似度对比(CAM++ 说话人相似度)
| 场景 | Dense | MoE |
|---|---|---|
| 见过的声音 | 0.6472 | 0.6267 |
| 未见过的声音 | 0.5654 | 0.5702 |
| 平均 | 0.6063 | 0.5985 |
📌 关键数据:Dense 在已见声音上相似度更高(0.647),MoE 在未见声音上泛化略强,两者整体接近 0.60。
跨模型英文 T2A 对比
| 模型 | 平均 CER | 平均 WER |
|---|---|---|
| Mini-Omni | 0.0101 | 0.0185 |
| Mini-Omni2 | 0.0371 | 0.0431 |
| minimind-3o(Dense) | 0.0964 | 0.0973 |
| minimind-3o(MoE) | 论文未单独列出 | 论文未单独列出 |
📌 关键数据:MiniMind-O 的 CER 高于 Mini-Omni,差距主要体现在中等长度回复(16-30 词)上,短回复(≤15 词)竞争力相当。作者指出 MiniMind-O 参数量仅为 Mini-Omni 的约 1/10,训练数据也更少。
消融实验亮点
低秩适配器秩数消融:rank=256 即可恢复大部分收敛收益,继续增大秩带来的提升边际递减。输出头秩比输入嵌入秩对 CER 影响更大。
桥接层位置:默认第 3 层(num_hidden_layers//2 - 1)在论文中被验证为最优,具体消融数据论文未完整披露。
💡 个人点评
优势:设计克制、工程务实。Thinker-Talker 双路架构和中间层桥接是技术上最有价值的贡献——用一套极轻量的结构解决了文本与语音生成的耦合问题。训练代码完整开放,4 小时可复现,是目前门槛最低的 Omni 模型入门方案。
局限:CER 与 Mini-Omni 仍有差距(~9.6% vs ~1.0%),说明 0.1B 参数在复杂语音生成上仍明显受限。声音克隆相似度 0.60 对工业级 TTS 应用不够,适合学习参考而非直接落地。
工程价值:低秩 Talker 参数化(shared embedding + LoRA-style adapter)可直接借鉴到其他多 codebook 语音生成任务。9 流错排序列格式是流式语音生成的实用设计,可复用到更大规模模型。
未来方向:用更大底座(如 Qwen2-7B)+ 相同 Thinker-Talker 架构扩展;增加中文语音训练数据;引入 flow matching 替代 codec 自回归生成以提升音质。
🔗 资源链接
- 📄 论文链接:arxiv.org/abs/2605.03937
- 💻 开源代码:github.com/jingyaogong/minimind-o
- 🎯 相关:MiniMind(纯文本底座)— github.com/jingyaogong/minimind
- 🎯 相关:Mini-Omni — arxiv.org/abs/2408.16725
- 🎯 相关:Mimi Codec(Kyutai)— arxiv.org/abs/2407.04477
Speech AI · FRONTIER · 论文精读系列
关注公众号获取最新语音 AI 论文解读
本文由 AI 辅助整理,论文解读与技术点评由作者完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)