别再对英文用jieba和空格分词了!NLTK才是专业处理英文文本的正确姿势
文章目录
1、中文用 jieba,英文用 word_tokenize
jieba 对中文分词已经讲过,这里跳过
你可以把 NLTK 想象成 NLP 领域的“瑞士军刀”兼“教科书”。它不仅仅是一个工具库,更是自然语言处理(NLP)入门和学术研究的基石。
- NLTK 是什么?
- 全称:Natural Language Toolkit(自然语言工具包)。
- 身份:它是 Python 编程语言中一个领先的平台,专门用于构建处理人类语言数据(文本、语音等)的程序。
- 地位:
- 学术界的标准:自 2001 年项目启动以来,它一直是全球大学 NLP 课程的首选教学工具。绝大多数经典的 NLP 论文和算法实现都基于或参考了 NLTK。
- 原型开发的利器:由于功能丰富且接口统一,研究人员和工程师常用它来快速验证想法、测试算法原型。
- 核心哲学:“教育 + 实用”。它不仅提供能运行的代码,还提供了大量的文档、教程和数据集,旨在帮助用户理解语言学原理和算法逻辑。
- NLTK 是做什么的?(核心能力版图)
NLTK 的功能覆盖了从“原始文本”到“深度语义理解”的全流程。对于你的汉译英任务,它主要承担预处理和后处理的角色。
它的核心能力可以分为以下几个层级:
A. 基础预处理层(你的训练数据最需要的)
这是 NLTK 最常用的功能,负责把杂乱的文本变成模型能读懂的结构化数据。
- 分词 (Tokenization):
- 单词分词:把句子切成单词(如
word_tokenize),智能处理标点、缩写(如将don't拆为do+n't)。 - 句子分词:把长文章切成独立的句子(
sent_tokenize),识别句号、问号等结束符。
- 单词分词:把句子切成单词(如
- 词干提取与词形还原 (Stemming & Lemmatization):
- 把
running,runs,ran还原为原形run。 - ⚠️ 注意:在机器翻译任务中,通常不使用此功能,因为时态、语态和单复数信息对翻译结果至关重要;此功能更多用于搜索或文本分类任务。
- 把
- 停用词过滤 (Stopwords Filtering):
- 识别并移除像
the,is,at,on这样高频但信息量低的词。 - ⚠️ 注意:同样,翻译任务通常保留停用词,因为它们承载了语法结构信息。
- 识别并移除像
B. 语法结构层
分析句子的内部构造,理解词与词之间的关系。
- 词性标注 (POS Tagging):
- 给每个词打上标签,区分它是名词 (NN)、动词 (VB)、形容词 (JJ) 还是标点。例如:
smiled/VBD(过去式动词)。
- 给每个词打上标签,区分它是名词 (NN)、动词 (VB)、形容词 (JJ) 还是标点。例如:
- 组块分析 (Chunking):
- 识别短语结构,如名词短语 (NP)、动词短语 (VP)。
- 句法分析 (Parsing):
- 生成句法树,展示句子的层级结构(谁修饰谁,谁是主语,谁是谓语)。
C. 语义与应用层
尝试理解文本的含义。
- 命名实体识别 (NER):
- 自动识别文本中的人名、地名、机构名、时间、货币等。
- 情感分析 (Sentiment Analysis):
- 判断一段文字是积极的、消极的还是中立的。
- 文本分类 (Text Classification):
- 将文档归类(如:垃圾邮件检测、新闻主题分类)。
- 语义相似度:
- 利用 WordNet(见下文)计算两个词的语义距离。
D. 资源与数据层(它的宝藏)
NLTK 不仅仅有代码,还内置了海量的语料库 (Corpora) 和 词典 (Lexical Resources),一键即可下载调用:
- 语料库:古腾堡计划书籍、布朗语料库、新闻文本、电影评论等,用于训练和测试。
- WordNet:一个巨大的英语词汇数据库,记录了单词之间的同义、反义、上下位关系(类似超级字典)。
- 预训练模型:如前面提到的
punkt(分词规则)、averaged_perceptron_tagger(词性标注模型) 等。
- NLTK 的安装与资源获取
安装 NLTK 分为两步:安装库本身 和 下载所需的数据包。这与其他库(如 requests 或 pandas)略有不同,需要特别注意。
第一步:安装 Python 库
使用 Python 的包管理工具 pip 进行安装。
-
命令:
pip install nltk -
验证:
在 Python 中输入import nltk,如果没有报错,说明库安装成功。
第二步:下载数据资源包(关键!)
NLTK 的核心功能依赖于外部数据文件(如分词规则、词性标注模型、语料库)。这些文件不会随库自动安装,需要手动下载。
-
存储位置:下载的文件默认存储在用户主目录下的
nltk_data文件夹中(例如~/nltk_data或C:\Users\Name\nltk_data)。 -
方法一:交互式下载(推荐初学者)
在 Python 环境中运行以下代码,会弹出一个图形化界面,你可以用鼠标勾选需要的包(如punkt,averaged_perceptron_tagger,stopwords,wordnet等)进行下载。import nltk # 可能报错 nltk.download() -
方法二:命令行指定下载(推荐服务器/自动化脚本)
如果你知道具体需要什么包(例如你只需要分词功能),可以直接下载特定的包,节省空间和时间。import nltk # 下载分词所需的 punkt 包 nltk.download('punkt') # 下载词性标注所需的包 nltk.download('averaged_perceptron_tagger') # 下载停用词列表 nltk.download('stopwords') # 下载 WordNet 词典 nltk.download('wordnet') -
方法三:下载所有数据(不推荐,体积很大)
如果你想把 NLTK 的所有功能都试用一遍,可以下载全部数据(约几 GB)。nltk.download('all')
- NLTK 的优缺点分析(帮你判断是否适合你)
为了让你更清晰地定位 NLTK,我们需要客观地看它的长处和短处。
✅ 优点(为什么选它)
- 功能极其全面:从分词到句法分析,一站式解决,无需拼凑多个库。
- 文档与教程极佳:官方提供的《NLTK Book》是公认的 NLP 入门圣经,代码示例丰富,解释详尽。
- 标准化程度高:它的分词和标注标准(Penn Treebank)是业界通用语言,使用它能保证你的数据格式与主流研究接轨。
- 易于调试和学习:因为它主要是纯 Python 编写且逻辑透明,非常适合用来理解算法原理。
❌ 缺点(需要注意的地方)
- 速度较慢:由于是纯 Python 实现且注重代码可读性,NLTK 的处理速度远不如基于 C/C++ 或 Cython 优化的库(如
spaCy或Stanza)。在处理亿级数据时可能会成为瓶颈。 - 不适合生产环境的高并发场景:在需要毫秒级响应的线上服务中,NLTK 往往不是首选。
- 深度学习支持较弱:NLTK 主要专注于传统机器学习方法和规则方法。虽然它可以作为预处理工具配合 PyTorch/TensorFlow 使用,但它本身不提供构建深度神经网络模型的功能(这点不同于
Hugging Face Transformers)。 - 多语言能力有限:虽然支持多种语言,但其核心优势主要集中在英语。对于中文等其他语言,其内置模型的效果通常不如专用工具(如中文用
jieba,多语言用spaCy或Stanza)。
- 总结:NLTK 在汉译英项目中的角色
在项目中,NLTK 不是用来“训练模型”的(那是 PyTorch/TensorFlow/Fairseq 的工作),也不是用来“部署服务”的(那是 spaCy 或 C++ 引擎的工作)。
它的角色是:数据清洗工 & 质检员。
- 输入端(预处理):它负责把原始英文句子,按照标准的学术规范,切分成干净的 Token 序列(处理标点、拆分缩写),生成高质量的训练语料。
- 输出端(后处理/Detokenization):它负责把模型预测出来的 Token 序列,智能地还原成符合人类阅读习惯的自然句子(去除多余空格、合并缩写、调整标点间距)。
一句话定位:
NLTK 是构建高质量汉译英数据集的必备预处理工具,它保证了数据“格式标准、干净规范”,从而让后续的模型训练更加高效、准确。
2、nltk.download('punkt') 介绍
关于 punkt 包的详细信息如下:
punkt的全称是什么?
它没有更长的“全称”,punkt 就是它的正式名称。
- 词源:这个名字来源于德语单词 “Punkt”,意思是 “点” 或 “句点”(即标点符号中的句号
.)。 - 命名含义:之所以叫这个名字,是因为这个包的核心算法(Punkt Sentence Tokenizer)最初是由 Kisiel 和 Palmer 在 2003 年提出的,专门用于智能地识别句子边界。它能区分作为小数点的“点”(如
3.14)、作为缩写的“点”(如Mr.)和作为句子结束的“点”(.)。 - 在 NLTK 中的路径:在 NLTK 的数据结构中,它位于
tokenizers/punkt目录下。
- 这个包适用于什么语言?
punkt 是一个多语言支持的分词/分句模型包,不仅仅适用于英语。
当你运行 nltk.download('punkt') 时,你下载的其实是一个包含多种语言预训练模型的集合包。
-
支持的语言:
它内置了超过 17+ 种语言 的无监督分句模型,包括但不限于:- 🇺🇸 英语 (
english) - 🇩🇪 德语 (
german) - 🇫🇷 法语 (
french) - 🇪🇸 西班牙语 (
spanish) - 🇮🇹 意大利语 (
italian) - 🇵🇹 葡萄牙语 (
portuguese) - 🇳🇱 荷兰语 (
dutch) - 🇸🇮 斯洛文尼亚语 (
slovene) - 🇵🇱 波兰语 (
polish) - 🇨🇿 捷克语 (
czech) - 🇷🇺 俄语 (
russian) - 🇪🇪 爱沙尼亚语 (
estonian) - 以及更多…
- 🇺🇸 英语 (
-
如何指定语言?
虽然你下载的是一个大包,但在使用时,NLTK 默认会使用英语模型。如果你想处理其他语言,需要显式指定:from nltk.tokenize import sent_tokenize, word_tokenize text = "Bonjour tout le monde. Comment ça va?" # 默认使用英语模型(效果可能不好) # sent_tokenize(text) # 指定使用法语模型 sent_tokenize(text, language='french') -
对中文的支持情况:
⚠️ 注意:punkt不支持中文分词。- 原因:中文没有像英文那样的空格分隔,且句号(。)与英文句点(.)不同。
punkt算法是基于空白字符和特定标点逻辑设计的,无法直接处理连续的中文字符串。 - 解决方案:处理中文请使用
jieba、HanLP或 NLTK 中其他特定的中文模块(如果有),但在实际生产中,中文通常专用jieba。
- 原因:中文没有像英文那样的空格分隔,且句号(。)与英文句点(.)不同。
总结
- 名称:
punkt(源自德语“句点”)。 - 用途:提供基于统计学的智能句子分割和单词分割规则。
- 语言支持:多语言(英、德、法、西等欧洲语言为主),不支持中文。
- 你的场景:在做汉译英时,你只需要用它来处理英文部分(源语言或目标语言的英文侧),此时它默认加载英语模型,完美适用。
3、nltk.download('punkt') 报错解决
import nltk
nltk.download('punkt')
运行这段代码可能报错:
F:\Anaconda\python.exe F:\Pycharm\works-space\NL\main.py
[nltk_data] Error loading punkt: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
这个错误 [Errno 11004] getaddrinfo failed 是一个非常典型的 DNS 解析失败 或 网络连接问题。
简单来说:你的 Python 程序试图连接 NLTK 的官方服务器(通常在 GitHub 或 Google Storage 上)去下载数据,但是你的电脑找不到这个服务器的地址,或者被防火墙/网络环境拦截了。这在大陆地区的网络环境下非常常见。
手动下载并离线安装
既然自动下载不行,我们就手动把文件下载下来,放到 NLTK 指定的文件夹里。这就像你去应用商店下载失败,直接去官网下载安装包安装一样。
第 1 步:下载数据包
请点击以下链接之一下载 punkt.zip 文件(如果链接失效,请搜索 “nltk punkt zip github”):
注意:下载下来的是一个
punkt.zip压缩包,不要解压。
第 2 步:找到 NLTK 的数据存储目录
你需要知道 NLTK 想把文件存在哪里。运行下面这段简短的 Python 代码,它会打印出默认路径:
import nltk
# 这会打印出类似 'C:\\Users\\YourName\\AppData\\Roaming\\nltk_data' 的路径
print(nltk.data.path)
输出示例:
['C:\\Users\\asus/nltk_data', 'F:\\Anaconda\\nltk_data', 'F:\\Anaconda\\share\\nltk_data', 'F:\\Anaconda\\lib\\nltk_data', 'C:\\Users\\asus\\AppData\\Roaming\\nltk_data', 'C:\\nltk_data', 'D:\\nltk_data', 'E:\\nltk_data']
它告诉我们 NLTK 会按顺序在这些路径中查找数据文件。只要文件存在于其中任何一个路径下,NLTK 就能成功加载!
注意到列表的第一个路径是:'C:\\Users\\asus/nltk_data'
通常路径是:
- Windows:
C:\Users\你的用户名\AppData\Roaming\nltk_data - Mac/Linux:
~/nltk_data或/usr/local/share/nltk_data
提示:
AppData文件夹通常是隐藏的。你可以在文件资源管理器地址栏直接输入%APPDATA%然后回车,就能快速进入Roaming文件夹。
你会发现,上面的任何一个路径都找不到 叫 “nltk_data” 的文件夹
正因为没有,所以你才需要手动创建它。
NLTK 的逻辑是:“我去这些路径找找看有没有数据,如果有就用,如果没有我就尝试联网下载”。
之前报错是因为它发现没有本地文件,于是尝试联网下载,结果网络失败了。
现在的任务就是:你手动把这个“家”建好,把文件放进去,这样它就不用联网了。
第 3 步:放置文件
- 在上述路径下,找到一个叫
nltk_data的文件夹(如果没有就新建一个)。 - 在
nltk_data里面,创建一个叫tokenizers的文件夹(如果没有就新建)。 - 把你下载的
punkt.zip文件,直接放入tokenizers文件夹中。- 最终路径结构应该是这样的:
.../nltk_data/tokenizers/punkt.zip - ⚠️ 关键点:确保
punkt.zip就在tokenizers目录下,不需要解压它!NLTK 可以直接读取 zip 包。
- 最终路径结构应该是这样的:
第 4 步:验证
重新运行你的代码:
import nltk
# 这次它会发现本地已经有文件了,不会尝试联网,直接返回 True
nltk.download('punkt')
print("成功!")
import nltk
from nltk.tokenize import word_tokenize
# 1. 不要管 download 的返回值,直接尝试使用功能
test_sentence = "Don't worry, it works!"
try:
# 尝试分词。如果本地文件正确,这步会瞬间完成,无需联网。
tokens = word_tokenize(test_sentence)
print("✅ 验证通过!NLTK 工作正常。")
print(f"原始句子: {test_sentence}")
print(f"分词结果: {tokens}")
except LookupError as e:
# 如果报这个错,说明真的没找到文件
print("❌ 验证失败:找不到 punkt 数据。")
print("错误详情:", e)
print("请再次检查文件路径是否正确:C:\\Users\\asus\\nltk_data\\tokenizers\\punkt.zip")
print("注意:必须是 punkt.zip,且不能解压,必须在 tokenizers 文件夹内。")
except Exception as e:
# 其他错误
print("❌ 发生其他错误:", e)
如果还报错,继续往下看:
报错内容:
F:\Anaconda\python.exe F:\Pycharm\works-space\NL\main.py
❌ 验证失败:找不到 punkt 数据。
错误详情:
**********************************************************************
Resource punkt_tab not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt_tab')
For more information see: https://www.nltk.org/data.html
Attempted to load tokenizers/punkt_tab/english/
Searched in:
- 'C:\\Users\\asus/nltk_data'
- 'F:\\Anaconda\\nltk_data'
- 'F:\\Anaconda\\share\\nltk_data'
- 'F:\\Anaconda\\lib\\nltk_data'
- 'C:\\Users\\asus\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************
请再次检查文件路径是否正确:C:\Users\asus\nltk_data\tokenizers\punkt.zip
注意:必须是 punkt.zip,且不能解压,必须在 tokenizers 文件夹内。
进程已结束,退出代码为 0
这是一个非常关键的发现!错误信息变了:
❌ 之前报错:Resource punkt not found
✅ 现在报错:Resource punkt_tab not found
原因揭秘:
你安装的 NLTK 版本比较新(可能是 3.9 或更高版本)。在新版本中,NLTK 升级了分词器,默认使用一个新的、更优化的数据包,名字叫 punkt_tab,而不是旧的 punkt。
你之前辛苦下载的 punkt.zip 是旧版数据,虽然还在,但新版 NLTK 优先寻找 punkt_tab,找不到就报错了。
解决方案:
你需要下载 punkt_tab.zip 而不是 punkt.zip。步骤和之前完全一样,只是文件名变了。
🚀 修正步骤(只需 2 分钟)
第 1 步:下载新的数据包 punkt_tab.zip
请使用浏览器下载这个新文件(旧的那个 punkt.zip 可以留着备用,但这次主要用新的):
- GitHub 源:点击下载 punkt_tab.zip
注意:下载后文件名必须是
punkt_tab.zip,不要解压。
第 2 步:放入正确的文件夹
路径和之前完全一样,只是把文件换成新的。
- 打开路径:
C:\Users\asus\nltk_data\tokenizers\- 如果
tokenizers文件夹还没建,请按之前的步骤新建它。
- 如果
- 将下载的
punkt_tab.zip放入该文件夹。
✅ 最终确认路径:C:\Users\asus\nltk_data\tokenizers\punkt_tab.zip
(此时你的 tokenizers 文件夹里可能既有 punkt.zip 也有 punkt_tab.zip,这没关系,只要有了 punkt_tab.zip 就能解决当前问题)
第 3 步:再次运行验证代码
不需要修改代码,直接再次运行你刚才那段验证代码:
import nltk
from nltk.tokenize import word_tokenize
test_sentence = "Don't worry, it works!"
try:
tokens = word_tokenize(test_sentence)
print("✅ 验证通过!NLTK 工作正常。")
print(f"原始句子: {test_sentence}")
print(f"分词结果: {tokens}")
except LookupError as e:
print("❌ 依然失败。请确认是否下载了 punkt_tab.zip 并放入了 tokenizers 文件夹。")
print("当前需要文件:", "C:\\Users\\asus\\nltk_data\\tokenizers\\punkt_tab.zip")
except Exception as e:
print("❌ 其他错误:", e)
💡 为什么会出现这种情况?
NLTK 在 2024-2025 年期间进行了更新,引入了 punkt_tab 作为默认的英语分词模型,因为它加载速度更快、内存占用更小。老教程通常只提 punkt,导致很多新用户下载错了包。
总结:
- 下载
punkt_tab.zip。 - 放到
C:\Users\asus\nltk_data\tokenizers\。 - 搞定!
快去试试,这次应该能直接输出分词结果了!
如果,还报错!
F:\Anaconda\python.exe F:\Pycharm\works-space\NL\main.py
❌ 发生其他错误: [Errno 2] No such file or directory: 'F:\\Anaconda\\nltk_data\\tokenizers\\punkt_tab.zip\\punkt_tab\\english/collocations.tab'
就快成功了!!!笑吧,哈哈哈哈
这个错误非常具体且关键:[Errno 2] No such file or directory: '.../punkt_tab.zip\\punkt_tab\\english/collocations.tab'
问题诊断:
这说明 NLTK 找到了 punkt_tab.zip 文件,但是它试图直接读取 zip 包内部的文件结构时失败了。
通常原因有两个:
- Zip 包结构不对:你下载的 zip 包解压后,第一层文件夹名字可能不是
punkt_tab,或者里面缺少了english/collocations.tab这个具体文件。 - NLTK 版本与数据包不匹配:某些新版本的 NLTK 对 zip 包的读取逻辑变了,或者你下载的数据包版本过旧/过新,导致内部路径对不上。
- 最可能的情况:你下载的
punkt_tab.zip可能是一个包含文件夹的压缩包(例如punkt_tab/punkt_tab/...),或者 NLTK 期望的是解压后的文件夹而不是 zip 包。
🚀 终极解决方案:直接解压!
既然读取 zip 报错,我们就手动解压它。NLTK 完全支持读取文件夹形式的数据。
步骤 1:找到并解压文件
-
打开路径:
C:\Users\asus\nltk_data\tokenizers\ -
找到你刚才放入的
punkt_tab.zip。 -
右键点击 -> 解压到当前文件夹 (或者使用 WinRAR/7-Zip 解压)。
- 解压后,你应该会看到一个名为
punkt_tab的文件夹。
- 解压后,你应该会看到一个名为
-
关键检查:
- 进入
punkt_tab文件夹。 - 再进入
english文件夹。 - 确认里面有一个叫
collocations.tab的文件。 - 正确结构:
C:\Users\asus\nltk_data\tokenizers\punkt_tab\english\collocations.tab
(如果解压后发现是
punkt_tab\punkt_tab\english...,请把里面那一层punkt_tab文件夹移出来,确保english文件夹直接在punkt_tab下) - 进入
步骤 2:删除或保留 zip 包(可选)
解压成功后,你可以删除 punkt_tab.zip,也可以留着。NLTK 会优先读取文件夹。
步骤 3:再次运行验证代码
现在再次运行你的 Python 代码:
import nltk
from nltk.tokenize import word_tokenize
test_sentence = "Don't worry, it works!"
try:
tokens = word_tokenize(test_sentence)
print("✅ 验证通过!NLTK 工作正常。")
print(f"原始句子: {test_sentence}")
print(f"分词结果: {tokens}")
except LookupError as e:
print("❌ 依然找不到数据。")
print("请确认文件夹结构是否正确:")
print("C:\\Users\\asus\\nltk_data\\tokenizers\\punkt_tab\\english\\collocations.tab 必须存在")
except Exception as e:
print("❌ 发生其他错误:", e)
import traceback
traceback.print_exc()
输出:
F:\Anaconda\python.exe F:\Pycharm\works-space\NL\main.py
✅ 验证通过!NLTK 工作正常。
原始句子: Don't worry, it works!
分词结果: ['Do', "n't", 'worry', ',', 'it', 'works', '!']
进程已结束,退出代码为 0
💡 为什么之前 zip 不行?
NLTK 在某些 Windows 环境下,对嵌套 zip 包的路径解析(尤其是涉及 / 和 \ 混用时)偶尔会抽风。直接解压成文件夹是最稳定、最不容易出错的方式,相当于把“安装包”变成了“绿色版”。
只要看到 collocations.tab 文件在正确的位置,代码一定能跑通! 快去解压试试。
4、punkt_tab 数据包所支持的具体语言
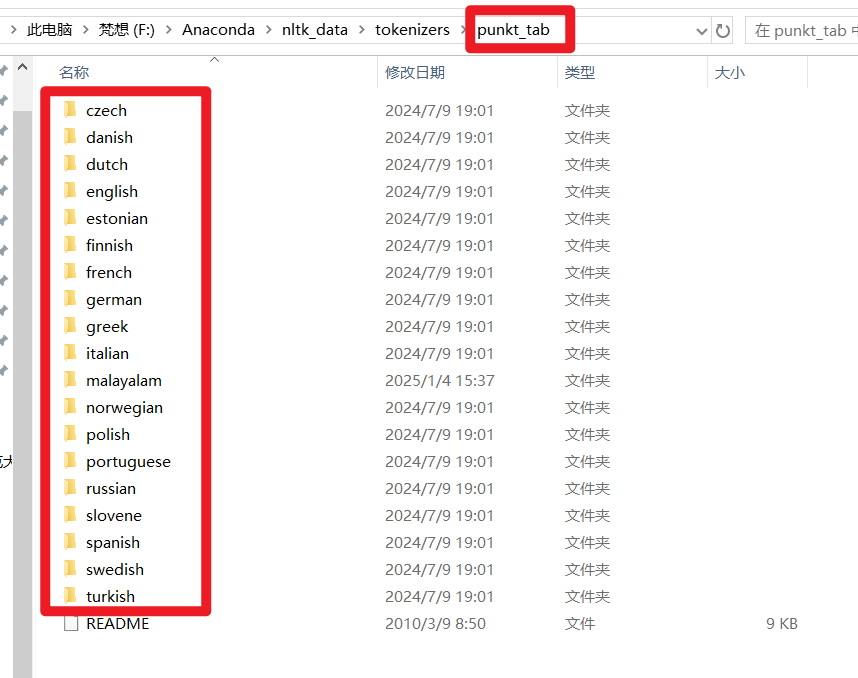
截图中的这些文件夹名字(czech, danish, english, french 等),正是 punkt_tab 数据包所支持的具体语言列表。
🔍 详细解读
-
多语言支持:
NLTK 的punkt算法是一个无监督的句子分割模型。它不需要像深度学习模型那样庞大的训练数据,而是通过分析文本中的缩写、标点频率等统计特征来工作。因此,它可以为多种语言分别训练一套规则参数。 -
文件夹的作用:
每一个文件夹(例如english)里都存放着该语言特有的统计数据文件(如.collocations.tab,.orthography_context.tab等)。- 当你调用
word_tokenize(text, language='english')时,NLTK 就会去读取english文件夹里的数据。 - 如果你处理法语文本,调用
language='french',它就会去读french文件夹。
- 当你调用
-
默认行为:
如果你在调用word_tokenize(text)时不指定language参数,NLTK 默认会使用english文件夹里的数据。这就是为什么我们之前必须确保english文件夹存在且完整的原因。
📝 支持的语言列表(基于我的截图)
我的 punkt_tab 包支持以下语言:
- 🇨🇿 Czech (捷克语)
- 🇩🇰 Danish (丹麦语)
- 🇳🇱 Dutch (荷兰语)
- 🇺🇸/🇬🇧 English (英语) 👈 最常用的
- 🇪🇪 Estonian (爱沙尼亚语)
- 🇫🇮 Finnish (芬兰语)
- 🇫🇷 French (法语)
- 🇩🇪 German (德语)
- 🇬🇷 Greek (希腊语)
- 🇮🇹 Italian (意大利语)
- 🇮🇳 Malayalam (马拉雅拉姆语)
- 🇳🇴 Norwegian (挪威语)
- 🇵🇱 Polish (波兰语)
- 🇵🇹 Portuguese (葡萄牙语)
- 🇷🇺 Russian (俄语)
- 🇸🇮 Slovene (斯洛文尼亚语)
- 🇪🇸 Spanish (西班牙语)
- 🇸🇪 Swedish (瑞典语)
- 🇹🇷 Turkish (土耳其语)
⚠️ 重要提示:关于中文
请注意,这个列表中没有 Chinese (中文)。
- 原因:
punkt算法依赖于空格和特定的标点逻辑来切分句子和单词。中文是连续字符,没有空格分隔,且标点习惯不同,所以punkt无法直接处理中文。 - 解决方案:这就是为什么你在处理汉译英数据时,英文部分用 NLTK (
word_tokenize),中文部分必须用 Jieba (jieba.lcut) 的原因。两者各司其职,互补使用。
💡 如何使用其他语言?
如果你将来需要处理法语数据,代码只需改一行:
# 处理法语
from nltk.tokenize import word_tokenize
french_text = "Bonjour tout le monde. Comment ça va?"
# 指定 language='french'
tokens = word_tokenize(french_text, language='french')
总结:你看到的这些文件夹就是 NLTK 内置的“多语言工具箱”,每个文件夹对应一种语言的规则库。对于你的汉译英任务,只要保证 english 文件夹完好无损即可!
5、NLTK 核心功能深度详解
专为汉译英机器翻译数据预处理场景设计,涵盖了从底层原理、函数签名深度解析、参数微调、多语言支持到工业级实战代码的全方位内容。重点聚焦 word_tokenize 和 sent_tokenize,并补充必要的辅助工具。
💡 版本提示:NLTK 3.9+ 版本默认使用
punkt_tab数据包,旧版本使用punkt。本手册基于新版编写,若遇LookupError,请确认已下载对应包(nltk.download('punkt_tab')或nltk.download('punkt'))。
- 单词分词 (Word Tokenization)
核心地位:NLP 流水线的“第一公里”。对于机器翻译,它的质量直接决定了词汇表(Vocabulary)的纯净度和模型的学习效率。
📌 函数签名
nltk.tokenize.word_tokenize(text, language='english', preserve_line=False)
底层实现类:nltk.tokenize.TreebankWordTokenizer
⚙️ 参数深度详解
| 参数名 | 类型 | 默认值 | 深度解析与内部逻辑 |
|---|---|---|---|
| text | str |
(必填) | 待处理的原始字符串。⚠️ 注意:1. 必须是 str 类型,传入 None 或 bytes 会报错。2. 确保文本编码正确(推荐 UTF-8)。 |
| language | str |
'english' |
指定语言规则包。- 机制:对应 punkt_tab (或 punkt) 数据包下的文件夹名称(如 'french', 'german')。- 作用:加载特定语言的缩写列表(如英语 don't,法语 l')和标点规则。- 限制:仅支持拉丁语系及有空格分隔的语言。不支持中文、日文、韩文(需用 jieba 等)。- 依赖:若对应文件夹不存在,抛出 LookupError。 |
| preserve_line | bool |
False |
是否强制保留换行符作为分词边界。- False (默认):\n 被视为普通空白,被忽略。适合常规句子。- True:遇到 \n 强制切断。即使句子未完也会断开。 注:在某些版本中,开启此选项可能会在结果列表中保留 \n 作为一个 token,或导致列表结构变化,需根据实际输出调整后续逻辑。适用于诗歌、歌词或多行对齐数据。 |
💻 常用操作与场景演示
A. 基础分词:处理标点与缩写 (标准模式)
遵循 Penn Treebank 标准,机器翻译首选。
from nltk.tokenize import word_tokenize
text = "I don't think it's good, do you? It costs $10.50."
tokens = word_tokenize(text)
print(tokens)
# 输出: ['I', 'do', "n't", 'think', 'it', "'s", 'good', ',', 'do', 'you', '?', 'It', 'costs', '$', '10.50', '.']
- 关键点:
don't→['do', "n't"](拆分否定后缀,助模型学习语法)。$10.50→['$', '10.50'](符号分离,数字内小数点保留)。- 标点
,?.全部独立成词。
B. 多语言分词
处理非英语数据时必须指定 language。
french_text = "L'homme est mort. Bonjour!"
# 指定法语规则,识别 L' 为特有缩写
fr_tokens = word_tokenize(french_text, language='french')
# 输出可能为: ['L', "'", 'homme', ...] 或 ['L\'', 'homme', ...] 视具体规则版本
C. 批量处理列表
sentences = ["Hello world.", "How are you?", "I'm fine."]
all_tokens = [word_tokenize(s) for s in sentences]
# [['Hello', 'world', '.'], ['How', 'are', 'you', '?'], ['I', "'m", 'fine', '.']]
- 句子分词 (Sentence Tokenization)
将长文本切分为独立句子列表,是处理长文档翻译的第一步。
📌 函数签名
nltk.tokenize.sent_tokenize(text, language='english')
底层实现类:nltk.tokenize.PunktSentenceTokenizer
⚙️ 参数深度详解
| 参数名 | 类型 | 默认值 | 深度解析 |
|---|---|---|---|
| text | str |
(必填) | 待处理的长文本。 |
| language | str |
'english' |
指定语言规则包。- 加载对应语言的缩写白名单(如 Mr., Dr.),防止误将缩写后的点判为句末。- 处理德语等大写名词丰富的语言时尤为重要。 |
💻 常用操作
A. 智能识别句号
from nltk.tokenize import sent_tokenize
text = "Hello world. Dr. Smith is here. Wait..."
sentences = sent_tokenize(text)
# ['Hello world.', 'Dr. Smith is here.', 'Wait...']
# Dr. 和 ... 未被误切分
B. 标准流水线:先分句,再分词
long_text = "First sentence. Second one!"
sents = sent_tokenize(long_text)
tokens_list = [word_tokenize(s) for s in sents]
# [['First', 'sentence', '.'], ['Second', 'one', '!']]
- 智能还原 (Detokenization)
至关重要:模型输出的是 Token 列表,直接拼接会出错(如 Do n't)。必须使用 Detokenizer 还原。
📌 类与方法
from nltk.tokenize.treebank import TreebankWordDetokenizer
detokenizer = TreebankWordDetokenizer()
text = detokenizer.detokenize(tokens_list)
💻 常用操作
A. 还原缩写与标点
tokens = ['I', 'do', "n't", 'know', '.', '"', 'Hello', '"']
detokenizer = TreebankWordDetokenizer()
restored_text = detokenizer.detokenize(tokens) # tokens 只能是一维列表,如果是二维列表则看下面的“预测后处理模板”
# 输出: I don't know. "Hello"
- 规则:自动合并
do+n't→don't;去除标点前空格;处理引号间距。
B. 预测后处理模板
def post_process_prediction(model_output_tokens):
detokenizer = TreebankWordDetokenizer()
return [detokenizer.detokenize(tokens) for tokens in model_output_tokens] # model_output_tokens是二维
- 辅助功能 (按需使用)
A. 停用词过滤 (Stopwords)
⚠️ 警告:机器翻译任务通常不使用,因 the, is 等词承载语法信息。移除会导致译文破碎。仅用于搜索/分类。
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
# filtered = [w for w in tokens if w.lower() not in stop_words]
B. 词性标注 (POS Tagging)
用于数据分析或特征工程。
from nltk import pos_tag
# 需下载: averaged_perceptron_tagger
tagged = pos_tag(word_tokenize("The baby smiled."))
# [('The', 'DT'), ('baby', 'NN'), ('smiled', 'VBD'), ('.', '.')]
- 综合实战:汉译英数据预处理生产级代码
此脚本整合了核心功能,包含错误处理和进度反馈,可直接用于百万级数据清洗。
import nltk
import jieba
from nltk.tokenize import word_tokenize
from nltk.tokenize.treebank import TreebankWordDetokenizer
import os
# --- 配置区域 ---
INPUT_FILE = 'raw_parallel_corpus.txt'
OUTPUT_FILE = 'processed_corpus.txt'
BATCH_SIZE = 1000
# 初始化还原器 (可选,若只需分词训练可不初始化)
detokenizer = TreebankWordDetokenizer()
def process_line(line, line_num):
"""处理单行平行语料:英文<TAB>中文"""
line = line.strip()
if not line:
return None
parts = line.split('\t')
if len(parts) != 2:
print(f"⚠️ 第 {line_num} 行: 格式错误,跳过。")
return None
en_raw, zh_raw = parts
try:
# 1. 英文分词 (NLTK)
# 自动处理标点、缩写,遵循 Penn Treebank 标准
en_tokens = word_tokenize(en_raw)
en_final = " ".join(en_tokens)
# 2. 中文分词 (Jieba)
# NLTK 不适用于中文,必须使用 Jieba
zh_tokens = jieba.lcut(zh_raw)
zh_final = " ".join(zh_tokens)
return f"{en_final}\t{zh_final}"
except Exception as e:
print(f"❌ 第 {line_num} 行: 处理异常 - {e}")
return None
def main():
if not os.path.exists(INPUT_FILE):
print(f"错误: 找不到输入文件 {INPUT_FILE}")
return
print(f"开始处理: {INPUT_FILE} ...")
success_count = 0
error_count = 0
with open(INPUT_FILE, 'r', encoding='utf-8') as f_in, \
open(OUTPUT_FILE, 'w', encoding='utf-8') as f_out:
for line_num, line in enumerate(f_in, 1):
result = process_line(line, line_num)
if result:
f_out.write(result + '\n')
success_count += 1
else:
error_count += 1
if line_num % BATCH_SIZE == 0:
print(f"🔄 进度: {line_num} 行 (成功:{success_count}, 失败:{error_count})")
print(f"\n✅ 完成! 成功:{success_count}, 失败:{error_count}")
print(f"输出至: {OUTPUT_FILE}")
if __name__ == "__main__":
# 首次运行需确保下载资源,之后可离线运行
# nltk.download('punkt_tab') # 新版
# nltk.download('punkt') # 旧版兼容
main()
📝 数据流转示例
输入:
The baby smiled at me. 宝宝对我笑了。
"I don't know," she said. 她说:“我不知道。”
输出:
The baby smiled at me . 宝宝 对 我 笑 了。
" I do n't know , " she said . 她 说: “ 我 不 知道。 ”
关键变化:
- 英文:标点分离 (
me .),缩写拆分 (do n't),引号独立 (" I)。 - 中文:Jieba 切分 (
宝宝 对 我)。
- 避坑指南与最佳实践
| 场景 | 常见错误 | ✅ 正确做法 | 原因 |
|---|---|---|---|
| 中文处理 | 用 word_tokenize 处理中文 |
用 jieba.lcut |
NLTK 基于空格,会将中文按字切开,破坏语义。 |
| 缩写处理 | 手动合并 do n't |
保持原样,预测后还原 | 训练时需拆分以学习语法;预测后用 Detokenizer 智能还原。 |
| 标点处理 | 用 split() 分词 |
用 word_tokenize() |
split() 无法分离粘连标点,导致词汇表膨胀。 |
| 多语言 | 不指定 language |
指定对应语言代码 | 不同语言缩写规则不同(如法语 L'),默认英语规则会出错。 |
| 性能 | 循环中重复 download() |
仅在启动时检查一次 | 避免不必要的 IO 和网络请求。 |
| 还原输出 | 直接用 " ".join() |
用 TreebankWordDetokenizer |
直接 join 会产生 Do n't 等错误格式,Detokenizer 能智能去空格。 |
6、英文句子什么时候转小写?
问题:映射“token-ID”时,需要把英文词转成小写吗?
答案:强烈建议转为小写(Lowercase)。
理由:
- 减少词汇表大小(Vocabulary Size):
- 如果不转小写:
"Apple"(苹果) 和"apple"(苹果) 会被视为两个不同的词,占用两个 ID。 - 如果转小写:它们合并为一个词
"apple",只占用一个 ID。 - 好处:在 6w 条数据下,这能显著减少
<UNK>(未知词) 的出现概率,让模型更专注于学习词义而不是区分大小写形式。
- 如果不转小写:
- 符合大多数基线模型做法:
- 除非你的任务对大小写非常敏感(例如:命名实体识别,或者需要区分 “us” (我们) 和 “US” (美国)),否则在基础的机器翻译任务中,统一小写是标准操作。
- 注意一致性:
- 训练时:全部转小写。
- 推理时:输入给模型的句子也必须先转小写,再转 ID。输出结果后,如果你需要恢复首字母大写,可以后期用规则处理(比如句首字母大写),但模型内部全程用小写。
例外情况:如果你发现翻译专有名词(如人名、地名)效果很差,可以尝试保留大小写,但这会增加词汇表负担。对于初学者,先统一小写是最稳妥的选择。
在特定的句子里,转成小写会丢失部分信息,甚至改变指代的精确性。
- 原句:
Table 1,Table S3,Supplementary Appendix- 这里的大写不仅仅是语法规范,更是专有名词的一部分,用来特指文档中的某个具体对象。
- 转小写后:
table 1,table s3,supplementary appendix- 后果 1(语义模糊):
table变成了普通名词“桌子”或“表格”,失去了“特指图表编号”的强调意味。 - 后果 2(歧义风险):
s3变成小写后,可能无法区分是“附表3”(Supplementary Table 3 的缩写)还是其他含义(比如亚马逊云存储 S3,虽然语境不同,但在模型看来只是字符串)。 - 后果 3(翻译质量):在翻译成中文时,模型可能无法准确识别出这是需要保留格式的专有引用,可能会翻译成“桌子 1”或者漏翻“S3”的特殊含义。
- 后果 1(语义模糊):
🤔 那么,还要不要转小写?
这取决于你的任务目标和数据领域:
情况 A:通用机器翻译 / 日常对话 / 文学小说
- 建议:坚决转小写。
- 理由:这类数据中,大小写主要是语法规范(句首大写、人名大写)。统一小写能大幅减少词汇表,让模型更容易学习“Apple”和“apple”是同一个概念。损失的那点专有名词信息,通常可以通过上下文补全。
情况 B:生物医学 / 学术论文 / 法律文档 / 代码(你的数据属于此类!)
- 建议:保留大小写(Case-Sensitive),或者使用混合策略。
- 理由:
- 专有名词密集:如
PCR,DNA,HIV,Table S3,Figure 2A,p-value。转小写后dna和Dna(如果是拼写错误) 难以区分,p-value变成p-value(没问题) 但P(概率) 变成p可能混淆。 - 引用格式敏感:如你例子中的
Table 1,这是学术引用的标准格式,模型需要学会保留这种格式。 - 单位与变量:
m(米) vsM(摩尔浓度),s(秒) vsS(西门子),大小写完全不同。
- 专有名词密集:如
鉴于你有 6w 条数据,且看起来是生物医学领域的论文摘要(提到 “Supplementary Appendix”, “diagnosis”, “median age”),我强烈建议你:不要简单粗暴地全部转小写!
🚀 针对医学/学术数据的最佳实践方案
既然不能无脑转小写,那怎么解决词汇表爆炸的问题?有三种进阶方案:
方案 1:保留大小写(最推荐,简单有效)
- 做法:完全不转小写,原样输入。
- 优点:信息零丢失,
Table和table被区分开,模型能学到“大写的 Table 通常后面跟数字”。 - 缺点:词汇表体积会增加约 30%-50%(因为每个词都有大写和小写两个版本)。
- 可行性:你有 6w 条数据,这对于现代 Transformer 来说完全够用!词汇表稍微大一点(比如从 1万 增加到 1.5万)对显存和训练速度的影响微乎其微,但能显著提升专业术语的翻译准确度。
- 结论:对于医学数据,请放弃“转小写”的执念,直接保留原文大小写。
方案 2:使用子词分词器(Subword Tokenization,如 BPE 或 WordPiece)
- 做法:不使用简单的“按空格分词”,而是使用像
SentencePiece或 HuggingFace 的BertTokenizer。 - 原理:它会把
Table拆分成Tab+##le或者类似的子词。大小写信息会被保留在子词中(例如T和t是不同的子词),但共享大部分词根。 - 优点:既保留了大小写信息,又极大地控制了词汇表大小,还能很好地处理未登录词(如新出现的基因名
GENE-X123)。 - 操作:如果你现在是用简单的
split()分词,建议升级到SentencePiece。
方案 3:特殊标记恢复法(复杂,不推荐)
- 先转小写训练,然后在推理时通过规则把
table 1强行改回Table 1。 - 缺点:规则很难写完美,容易出错,且模型本身没学过大小写的区别,效果通常不好。
💡 最终建议与修改后的处理流程
针对 6w 条医学/学术数据,请执行以下修改后的流程:
- 不要转小写! (
sentence.lower()这行代码删掉)。 - 保留原始大小写,让模型去学习
Table和table的区别。 - 特殊标记依然要加尖括号,防止冲突(这点不变)。
- 特殊标记:
['<pad>', '<unk>', '<sos>', '<eos>'] - 真实词汇:
'Table','table','S3','s3'都会作为不同的词进入词汇表。
- 特殊标记:
总结
对于通用数据,转小写是好事;但对于医学/学术数据(尤其是包含大量 Table, Figure, Gene Name 的数据),保留大小写是必须的。你的 6w 条数据量完全支撑得起稍大一点的词汇表,请务必保留大小写以保证专业术语的准确性。
7、特殊 token 避免和英文单词冲突
问题:特殊 Tokens (PAD, UNK, SOS, EOS) 会和英语句子冲突吗?
答案:会有冲突风险,必须避免!
场景举例:
假设你的特殊标记定义为:
PAD-> 字符串"pad"UNK-> 字符串"unk"SOS-> 字符串"sos"EOS-> 字符串"eos"
如果英语句子里恰好包含这些词:
- 句子:“Call the police, it’s an emergency, sos!”
- 句子:“I don’t know, it’s unk to me.” (虽然 unk 不是常用词,但 pad, sos, eos 很常见)
后果:
在构建词汇表时,程序会困惑:这个 "sos" 到底是代表“救命”这个单词,还是代表“句子开始”的特殊标记?
- 如果映射错了,模型会把真正的单词
"sos"当成控制符,导致翻译逻辑混乱。 - 或者,模型永远学不到
"sos"这个词的真实含义,因为它被特殊标记占用了。
✅ 解决方案:如何避免冲突?
业界标准的做法是使用**“不可见字符”或“特殊前缀”,确保特殊标记的字符串绝对不可能**出现在正常文本中。
方法 A:使用特殊前缀(推荐,最简单)
给所有特殊标记加上一个不会在自然语言中出现的符号,比如 < 和 >。
-
❌ 错误定义:
special_tokens = ['PAD', 'UNK', 'SOS', 'EOS'] # 风险:句子里可能有 "pad" 或 "sos" -
✅ 正确定义:
special_tokens = ['<pad>', '<unk>', '<sos>', '<eos>'] # 安全:正常英语句子里几乎不可能出现 "<pad>" 这种带尖括号的组合
方法 B:使用 Unicode 控制字符(高级,不推荐初学者)
有些库会使用 Unicode 中的私有区域字符(如 \uE000 等)作为特殊标记。这些字符在正常文本中绝对不会出现。但这种方法调试时肉眼看不见,不方便排查错误,所以**方法 A(加尖括号)**是最佳选择。
📝 总结与行动清单
-
预处理策略:
- 统一转小写:在分词和映射 ID 之前,对所有英文句子执行
.lower()。 - 特殊标记格式化:将特殊标记定义为
['<pad>', '<unk>', '<sos>', '<eos>'],务必加上尖括号。
- 统一转小写:在分词和映射 ID 之前,对所有英文句子执行
-
检查代码:
- 检查你的
build_vocab.py或数据处理脚本,确保特殊标记的字符串包含特殊符号。 - 检查你的推理代码,确保输入句子也经过了
.lower()处理。
- 检查你的
-
验证冲突:
- 你可以特意构造一个包含 “sos”, “pad”, “unknown” 的测试句子,跑一遍映射流程,打印出对应的 ID。
- 如果
"sos"映射到的 ID 不等于<sos>的 ID(通常是 2),说明冲突避免成功!
8、代码
【config.py】部分内容
# --- 特殊 Token ---
PAD = 0
UNK = 1
SOS = 2
EOS = 3
# 所有特殊标记加上一个不会在自然语言中出现的符号,比如 `<` 和 `>`。
special_tokens = {'<PAD>': PAD, '<UNK>': UNK, '<SOS>': SOS, '<EOS>': EOS}
读取数据集, 构建平行预料 代码:
# 该函数是去读 【open_access】 数据集的,这个数据集里的中文和英文都分好词了,直接按空格分隔就行了
def get_data_open_access():
with open(r'data/open_access/top90_zh.txt', mode='r', encoding='utf-8') as f:
zh_lines = f.readlines()
with open(r'data/open_access/top90_en.txt', mode='r', encoding='utf-8') as f:
en_lines = f.readlines()
zh_sentence = [] # 中文句子
en_sentence = [] # 英文句子
# 映射 词-ID
zh_word_inx = {} | config.special_tokens # 中文 词-ID
en_word_inx = {} | config.special_tokens # 英文 词-ID
zh_cn = zip(zh_lines, en_lines)
for zh, en in zh_cn:
zh_sentence.append(zh.strip())
en_sentence.append(en.strip())
# zh = zh.strip().split(' ') # 去掉两边的空白符, 按照空格分隔
# zh = ''.join(zh)
# for word in jieba.lcut(zh): # 用jieba重新分词, 但最终效果与数据集中的原始数据结果相差不大
for word in zh.strip().split(' '):
if word not in zh_word_inx:
zh_word_inx[word] = len(zh_word_inx)
for word in en.strip().split(' '):
if word not in en_word_inx:
en_word_inx[word] = len(en_word_inx)
# print(f'中文词表长度 = {len(zh_word_inx)}') # 693 【对于 6w 条的原始数据: 32683(原始数据的词表) 33715(重新合并句子, 使用jieba分词) 】
# print(f'英文词表长度 = {len(en_word_inx)}') # 716 【对于 6w 条的原始数据: 36145(原词) 32985(转小写) 】
# print(zh_word_inx) # {'<PAD>': 0, '<UNK>': 1, '<SOS>': 2, '<EOS>': 3, '也许': 4, '不能': 5, ':': 6, '分析': 7, '结果': 8, ...}
# print(en_word_inx) # {'<PAD>': 0, '<UNK>': 1, '<SOS>': 2, '<EOS>': 3, 'probably': 4, 'not': 5, ':': 6, 'analysis': 7, 'suggests': 8, ...}
# index to word
zh_inx_word = {v: k for k, v in zh_word_inx.items()}
en_inx_word = {v: k for k, v in en_word_inx.items()}
# print(zh_inx_word) # {0: '<PAD>', 1: '<UNK>', 2: '<SOS>', 3: '<EOS>', 4: '也许', 5: '不能', 6: ':', 7: '分析', 8: '结果', ...}
# print(en_inx_word) # {0: '<PAD>', 1: '<UNK>', 2: '<SOS>', 3: '<EOS>', 4: 'probably', 5: 'not', 6: ':', 7: 'analysis', 8: 'suggests', ...}
return (
zh_sentence, # 中文句子, list[str], 每个元素是个已经分好词的句子
en_sentence, # 英文句子, list[str], 每个元素是个已经分好词的句子
zh_word_inx, # 中文词 - ID
en_word_inx, # 英文词 - ID
zh_inx_word, # ID - 中文词
en_inx_word # ID - 英文词
)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)